

Article original : How to avoid scope creep, and other software design lessons learned the hard way
Par Dror Berel
D'un point de vue scientifique des données.
Vous avez un tout nouveau projet sur votre bureau, des données passionnantes, une compétition Kaggle stimulante, un nouveau client que vous souhaitez impressionner, et vous êtes pleinement motivé. Au début, le problème semble bien défini, et vous vous sentez même à l'aise avec la tâche en main. Vous venez de terminer une tâche similaire. Celle-ci ne devrait pas être très différente. Peut-être même juste quelques copier/coller avec quelques modifications aux extrémités.
Mais ensuite, cela arrive... Le client / collaborateur / patron a juste une simple demande supplémentaire... Cela se passe généralement comme ceci :
« Hmmmm, je me demande comment les résultats seraient si au lieu de x, nous faisons seulement un petit changement, juste faire y, ou... vous savez quoi, essayons les deux et voyons comment cela affecte les résultats ».
L'outil/solution initial que vous avez choisi peut-il gérer un tel ajustement ? Il peut être facile de le copier/coller avec quelques modifications, mais que faire si vous devez le faire encore et encore ? Pendant combien de temps allez-vous vous en tenir à votre plan initial ?
Dans le contexte de l'apprentissage automatique, voici quelques exemples :
Réglage « voyons comment un paramètre de modèle différent l'affecte »
Benchmarking « voyons comment divers modèles l'affectent »
Ensemble « essayons de combiner les meilleurs modèles ensemble »
Rééchantillonnage / validation croisée « nous devons inspecter le sur-apprentissage »
Imaginez ajouter à cela des données génomiques complexes, désordonnées, multicouches, à haut débit qui peuvent facilement atteindre un niveau de résolution très fine (expression génique / mutation / séquence, ...), ET ENSUITE ajouter plusieurs couches de diverses données multi-génomiques les unes sur les autres, ET ENSUITE le faire pour plusieurs cohortes / études à un niveau de méta-analyse... vous pourriez vous retrouver avec un VRAI... GROS... LAID... BORDEL !
Ça vous dit quelque chose ? Malheureusement, je me suis retrouvé dans cette situation plus d'une fois. Autant j'étais motivé à satisfaire mes collaborateurs, à ces moments-là, mes outils étaient... limités, et insuffisants pour répondre à la résolution de la portée plus large. À cette époque, je n'aurais peut-être même pas été conscient qu'un niveau de portée plus élevé était pertinent.

Beaucoup de choses ont été écrites sur l'extension de portée dans le contexte de la gestion de projet. Mais qu'aurait à dire un scientifique, qui a été principalement formé pour se soucier de la justesse de l'analyse / des outils, plutôt que de la « gestion » de l'ensemble du projet ?
La bonne nouvelle, mon ami, c'est qu'il n'est jamais trop tard pour apprendre des erreurs des autres. Voici quelques leçons, apprises à la dure. (Ne vous inquiétez pas, ce n'est pas un autre article de blog sur la recherche reproductible).
Leçon #1 : Commencez par la fin ! Définissez ce qu'est votre portée. Devez-vous l'étendre ?
Assurez-vous de comprendre quelle est la résolution la plus élevée attendue ! Faites un remue-méninges sur les résultats les plus fous de votre projet, puis convenez d'attentes raisonnables dans votre délai et votre budget.
Ayez une définition très détaillée et claire de la portée du projet. Par exemple, votre solution va-t-elle gérer un seul ensemble de données, ou plus ? Comment allez-vous valider vos résultats ? Il y aura toujours plus de méthodes/ensembles de données pour cela, mais qu'est-ce qui serait juste suffisant ?
Le défi délicat avec l'extension de portée est que le client ne se soucie pas vraiment ou ne pense pas en termes de « portée ». Leur objectif est d'obtenir une solution qui résout une hypothèse, ou un besoin commercial. Que leur demande soit dans ou hors de la portée est entièrement votre problème ! GÉREZ ÇA !
Dans le contexte de l'apprentissage automatique, à l'époque, j'utilisais des packages R ad-hoc qui ne font qu'un seul modèle multivarié. Ils faisaient bien le travail, mais étaient trop spécifiques au domaine des développeurs, et manquaient de la résolution plus élevée pour les comparer avec d'autres modèles, ou pour agréger d'autres modèles, ou manquaient de mise en œuvre de rééchantillonnage. Ce n'est que plus tard que j'ai appris à utiliser des packages de méta/agrégateur d'apprentissage automatique tels que mlr, tidymodels (anciennement caret), ou SuperLearner pour étendre ma portée. Lisez plus à ce sujet ici.
Leçon #2 : Ne réinventez pas la roue ! Il y a d'autres experts qui savent comment le faire mieux que vous !
Dans un rôle où vous êtes censé être multidisciplinaire, et où de nouveaux outils/méthodes apparaissent quotidiennement, accessibles à tous, il peut être facile de tomber dans un terrier très profond en explorant une nouvelle approche. Et devinez quoi, personne ne veut que vous gaspilliez leur temps/argent là-dessus.
Comment parier sur le bon outil ? Demandez-vous, que font les experts dans ce domaine ? À quel point l'outil qu'ils ont développé est-il mature ? Va-t-il être maintenu, ou obsolète ? Ils ont bien sûr eu leur propre courbe d'apprentissage, et avec le temps, ont perfectionné leurs outils pour surmonter les pièges courants que vous êtes sur le point de découvrir.
Pour moi, avec les données génomiques, c'était les classes Bioconductor Orientées Objet S4. Lisez plus ici sur pourquoi c'était le meilleur outil pour mon besoin. Bien sûr, ce n'était pas trivial à apprendre, mais je me sentais à l'aise de parier dessus lorsque j'ai vu comment il est implémenté dans les meilleures organisations académiques et industrielles. Je savais aussi que ce n'était pas une autre ressource open source qui pourrait mourir. Au lieu de cela, c'est un projet financé par le gouvernement et l'académie, alimenté par les meilleurs experts du domaine, ouvert et gratuit, pour que nous puissions tous l'utiliser.
Leçon #3 : Trouvé un vide ? Soyez créatif, mais gardez-le simple !
Mais que faire si quelque chose dans le pipeline analytique n'est toujours pas en place ? Un maillon manquant, introuvable, qui aurait mieux convenu au besoin spécifique que vous avez, comblant le vide ?
Ici, vous devrez peut-être faire un peu de travail salissant, et arrêter de dépendre des autres pour vous fournir la solution. Un autre terrier potentiellement glissant d'extension de portée ? Peut-être... si vous n'êtes pas assez prudent !
Comment l'éviter ? Très facile : Gardez-le Simple !
Voici un exemple très simple. Supposons que vous devez résoudre un problème non supervisé. Il y a définitivement plus d'une façon de le faire. Laquelle choisir ? La plus simple, supposons « clustering hiérarchique », serait-elle juste assez bonne pour commencer ? Implémentez-la, voyez comment elle fonctionne avec le reste de vos composants analytiques (données, évolutivité, reproductibilité), et plus tard, après que les choses se soient bien passées comme vous l'aviez prévu, relâchez cette simplification dans une méthode plus complexe. Faites-le très soigneusement et progressivement.
Plus d'exemples à suivre.
Leçon #4 : N'ayez pas peur de refactoriser !
Fatigué de corriger et de déboguer un code mal cohésif et mal conçu que quelqu'un d'autre, peut-être même votre patron, a écrit il y a longtemps, avant que de meilleurs outils ne deviennent disponibles ? Vous vous demandez, GRRRRR, c'est un tel contournement laid, pourquoi ne pas simplement utiliser cette nouvelle approche qui a été conçue spécifiquement pour cette tâche ? (voir leçon #2).
Oui, il est risqué de tout recommencer à zéro, et parfois vous n'aurez peut-être pas les ressources pour le faire, mais peut-être est-il temps de faire un bilan de la réalité.
Mais que faire si la solution de refactorisation nous donne des résultats différents de ceux sur lesquels nos collaborateurs comptent déjà ? Eh bien, s'il y avait effectivement une erreur/passée/bug/erreur, il est préférable de la reconnaître et de l'admettre maintenant, avant que davantage de dégâts ne soient causés. Mais rappelez-vous aussi la leçon #3 : Si vous vous en tenez à des solutions simples au cœur, leur refactorisation sous une solution d'emballage plus large devrait aider à produire des résultats similaires.
Leçon #5 : retour à la leçon #1.
Études de cas :
Voici deux études de cas tirées de ma propre expérience de travail avec des données multi-génomiques. (Pourrait facilement s'étendre à d'autres types de données, mais peut-être que c'est un sujet pour un futur article).
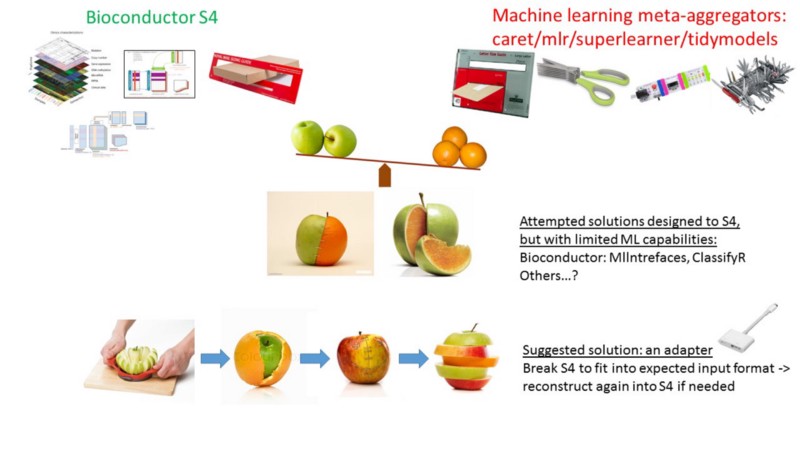
Étude de cas #1 : Bioc2mlr : Une fonction utilitaire pour transformer les classes omic S4 de Bioconductor en tâche et CPO de mlr.
https://drorberel.github.io/Bioc2mlr/
J'adore utiliser les conteneurs de données Bioconductor pour les données génomiques, mais j'adore aussi les boîtes à outils de méta-agrégateur d'apprentissage automatique pour l'analyse à un niveau de portée plus élevé. Le seul problème était qu'ils n'étaient pas nécessairement compatibles les uns avec les autres.
L'orienté objet S4 avait plusieurs dimensions (slots), liées ensemble dans des contraintes complexes, qui étaient intentionnellement conçues pour répondre à un certain but. Mais l'approche d'apprentissage automatique était conçue pour une structure d'entrée simplifiée, plate, à deux dimensions, de type matrice : des colonnes pour les caractéristiques/variables, et des lignes pour les sujets/observations.
J'avais besoin d'un moyen de briser les liens contraints de S4, et de l'aplatir. Mais malheureusement, à ma connaissance, je n'ai pas trouvé de moyen de le faire. Que devrais-je avoir fait ?
Rappelez-vous la leçon #3 : Devrais-je passer mon temps sur cette tâche ? Eh bien... oui, pourquoi pas ? Je me sentais suffisamment à l'aise avec les deux approches, j'avais déjà expérimenté les tenants et aboutissants, les points faibles, et j'appréciais définitivement la valeur énorme des deux approches séparément, mais aussi conjointement. En fait, la création de ce package adaptateur, Bioc2mlr, n'a pas demandé trop d'efforts, et si vous regardez le code lui-même, vous verrez des étapes relativement simples.
Conclusion de l'étude de cas 1 : Lorsque vous avez quelques bons outils, mais qu'ils ne sont pas compatibles, créez un nouvel adaptateur simple pour les lier.
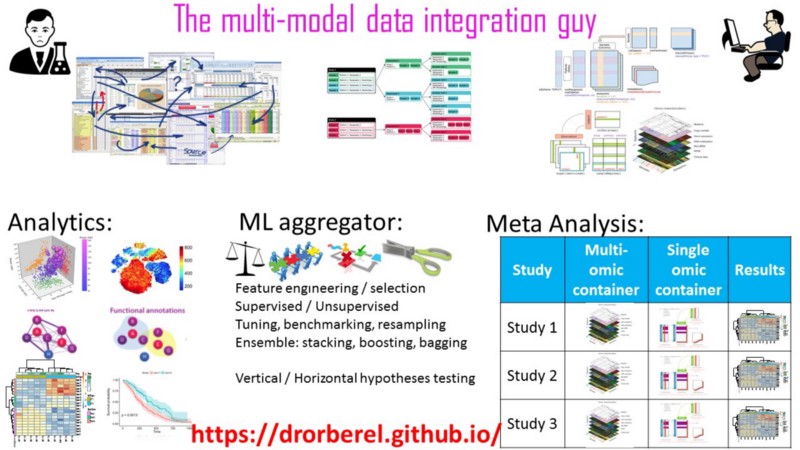
Étude de cas #2 : méta-analyse
Mais cela ne suffisait pas pour moi... (voir leçon #5).
Mon extension de portée m'a obligé à fournir une solution à un niveau d'analyse encore plus élevé. Méta-analyse de plusieurs études/cohortes, chacune avec un cube de données multi-omiques, chacune avec un pipeline analytique d'apprentissage automatique en aval, implémentant le rééchantillonnage, et tout ce jazz, à travers toutes les études, et à l'échelle. Phewww !
Un vrai défi ! Comment devrais-je l'aborder en mettant en œuvre les leçons ci-dessus ?
Leçon #1 : J'ai commencé par la fin. Mon « unité d'observation », ligne, à la manière tidy n'est pas le sujet, ni le gène, ni juste l'une des omiques. C'est l'étude/cohorte entière (c'est-à-dire un cube de données entier) bien compressée en un seul objet en R. Plus d'une cohorte ? Pas de problème du tout. Ajoutez autant de lignes que vous avez besoin pour plus de cohortes.
Leçon #2 : Je n'ai pas eu à inventer un nouvel outil. Les experts dans notre domaine l'ont déjà compris pour nous. Ils n'ont peut-être pas eu cette implémentation en tête lorsqu'ils l'ont fait, mais si je peux le faire, vous le pouvez aussi. Essayez simplement.
Leçon #3 : J'ai trouvé une solution simple. Devrais-je inventer/étendre une nouvelle classe orientée objet S4 pour ce type de données multi-cohortes, multi-omiques ? Bien sûr que non. Il doit y avoir une solution simple. Ma solution simple : une structure de données tidy / imbriquée, avec des objets non atomiques dans chaque cellule. Lisez plus à ce sujet ici.
Leçon #4 : Refactoriser ? Eh bien. Peut-être que je n'en suis pas encore là maintenant, puisque jusqu'à présent ma portée (actuelle) peut gérer tous mes rêves les plus fous. Mais si vous me montrez une meilleure approche, peut-être une approche data.table (je sais), ou même en python (que Dieu nous en préserve), je n'hésiterais pas à essayer, même si cela dépasse ma zone de confort.
Leçon #5 : Méta-méta-analyse ? (Ce n'est pas une faute de frappe). Qui sait. Peut-être un jour.
Conclusion de l'étude de cas 2 : mettez tout en ordre ! Même les objets non atomiques.
Un dernier conseil : Obtenez l'avis d'un expert, au moins jusqu'à ce que vous deveniez vous-même un expert.
« Si seulement j'avais su cela avant. Cela m'aurait fait gagner tant de temps et d'efforts... »
Pour l'expert, vos défis actuels sont la résolution d'hier. Ils l'avaient déjà compris lorsque nous étions encore à la maternelle. Ils ont passé toute leur carrière là-dessus. Envoyez-leur un e-mail, posez une question très claire, sans dépendances, preuves de concept ou études de cas pour démontrer votre défi. Mon expérience est qu'ils seraient heureux de vous aider si vous respectez leur temps et leur autorité.
Mots de la fin
Lorsque vous découvrez quel type d'outil/solution vous passionne, faites-le ! Ne vous trompez pas avec des excuses sur pourquoi ce n'est pas le bon moment pour que votre nouvel outil soit créé. Faites-le simplement !
Ne renoncez pas. Concentrez-vous. Décidez ce que vous voulez accomplir. N'ayez pas peur d'étendre votre portée, mais faites-le avec des solutions simples ! Refactorisez. Cela en vaudra la peine. Peut-être pas immédiatement, mais dans les jours à venir. Soyez créatif !
Et enfin, ne soyez pas timide. Parlez-en à tout le monde. Partagez-le avec votre communauté. Rendez l'univers meilleur avec votre solution. Vous pourriez même gagner un peu d'argent supplémentaire. Qui sait ?
p.s.
Cet article est dédié avec amour à tous mes anciens collaborateurs / clients / patrons anxieux. J'apprécie votre patience, et j'aurais souhaité connaître ce qui précède avant. Vous étiez là pour m'aider et me soutenir dans l'apprentissage de ces leçons à la dure, pour le meilleur et pour le pire. Laissez-moi me rattraper. Envoyez-moi un e-mail et je refairai mon ancien travail en quelques lignes de code, reflétant mon niveau actuel de portée.
Consultez d'autres sujets liés ici : https://drorberel.github.io/
Consultant : actuellement en train d'accepter de nouveaux projets !
Référence utile :
Blog Clean Coder
_On the Diminished Capacity to Discuss Things Rationally_blog.cleancoder.comScope Creep in Project Management: Definition, Causes & Solutions
_When a project stretches far beyond its original vision, it is called "scope creep". Scope creep in project management
..._www.workamajig.com