
![Comment éviter le problème des requêtes N+1 dans les API GraphQL et REST [avec benchmarks]](https://www.freecodecamp.org/news/content/images/size/w2000/2023/07/N-1-Query-Problem.png)
Article original : How to Avoid the N+1 Query Problem in GraphQL and REST APIs [with Benchmarks]
Par Mohamed Mayallo
Le problème des requêtes N+1 est un problème de performance que vous pourriez rencontrer lors de la création d'API, qu'il s'agisse d'API GraphQL ou REST.
En fait, ce problème se produit lorsque votre application doit retourner un ensemble de données qui inclut des données imbriquées liées – par exemple, un article qui inclut des commentaires.
Mais comment pouvez-vous résoudre ce problème ? Pour éviter ce problème, vous devez comprendre ce qu'il est et comment il se produit.
Ainsi, dans ce tutoriel, vous apprendrez ce qu'est le problème des requêtes N+1, pourquoi il est facile d'y tomber, et comment vous pouvez l'éviter.
Avant de commencer, il est bon de savoir :
- Les exemples dans cet article sont juste pour la simplicité.
SELECT *est très mauvais, et vous devriez l'éviter.- Vous devriez vous soucier de la pagination si vous travaillez avec de grands ensembles de données.
Vous pouvez trouver les exemples de cet article dans ce dépôt. Plongeons-nous dans le sujet.
Comprendre le problème des requêtes N+1
Le problème N+1 se produit lorsque votre application doit retourner un ensemble de données qui inclut des données liées existant dans :
- Une autre table.
- Une autre base de données (dans le cas de microservices, par exemple)
- Ou même un autre service tiers.
En d'autres termes, vous devez exécuter des requêtes de base de données supplémentaires ou des requêtes externes pour retourner les données imbriquées.
Si vous vous demandez ce que signifie le nom (N+1), suivez l'exemple ci-dessous, qui utilise une seule base de données :
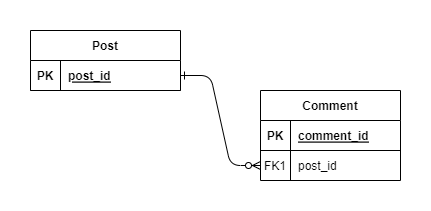 Illustration du problème N+1
Illustration du problème N+1
Comme vous pouvez le voir, la relation entre Post et Comment est respectivement de un à plusieurs.
Ainsi, si votre application doit retourner une liste d'articles et leurs commentaires associés, vous pourriez finir avec ce code :
const posts = await rawSql('SELECT * FROM "Post"'); // Obtenir tous les articles (1 requête de base de données)
for (const post in posts) {
// Bien sûr, vous pouvez remplacer la requête suivante par une requête externe si vous devez récupérer les commentaires de l'article depuis un autre service
const comments = await rawSql(`SELECT * FROM "Comment" WHERE "post_id" = ${post.id}`); // Obtenir tous les commentaires pour chaque article (n requêtes de base de données pour n articles)
post.comments = comments;
}
Ainsi, vous avez exécuté N requêtes pour récupérer les commentaires de chaque article et 1 requête pour récupérer tous les articles (N requêtes de commentaires + 1 requête d'articles).
Mais pourquoi devriez-vous être conscient de ce problème ?
Pourquoi le problème des requêtes N+1 est-il un problème sérieux ?
Voici quelques raisons pour lesquelles le problème des requêtes N+1 peut causer de sérieux problèmes de performance dans votre application :
- Votre application effectue de nombreuses requêtes de base de données ou requêtes externes pour récupérer une liste de données comme des articles.
- Plus votre application récupère de données, plus votre requête sera lente et plus votre application consommera de ressources.
- Un grand ensemble de données pourrait entraîner une latence réseau notable.
- Il sera difficile de mettre à l'échelle l'application pour gérer de plus grands ensembles de données.
En plus de cela, vous allez voir l'impact sur la performance en chiffres dans la section des benchmarks plus tard dans cet article.
Maintenant que vous comprenez le problème des requêtes N+1 et son impact sur votre application, introduisons quelques moyens efficaces pour éviter ce problème.
Stratégies pour éviter le problème des requêtes N+1
Heureusement, il existe quelques stratégies simples que vous pouvez suivre pour éviter le problème des requêtes N+1.
Appliquons-les à notre exemple précédent.
1) Chargement anticipé (en utilisant des jointures SQL, par exemple)
Dans cette stratégie, au lieu de retourner les commentaires de l'article séparément pour chaque article, vous pouvez utiliser des jointures SQL.
const postsAndComments = await rawSql(`
SELECT *
FROM "Post"
JOIN "Comment"
ON "Comment"."post_id" = "Post"."post_id"
`);
Lorsque vous utilisez cette stratégie, il est bon de savoir que :
- Il n'y a qu'une seule requête de base de données pour retourner tous les articles et leurs commentaires imbriqués.
- Vous ne pouvez pas appliquer cette stratégie si vous consommez vos ensembles de données à partir d'une base de données ou d'un service différent.
2) Chargement par lots
Dans cette stratégie, votre code doit suivre les étapes suivantes :
- Exécuter une requête pour récupérer tous les articles.
- Exécuter une autre requête pour charger un lot de commentaires d'articles au lieu de charger les commentaires de chaque article séparément.
- Associer chaque commentaire à son article parent correspondant.
Passons à un exemple :
const posts = await rawSql('SELECT * FROM "Post"'), // 1- Récupérer tous les articles en une requête
postsIds = posts.map(post => post.id),
postsComments = await rawSql(`SELECT * FROM "Comment" WHERE "post_id" IN (${postsIds})`); // 2- récupérer tous les commentaires des articles en une autre requête
for (const post in posts) { // 3- Associer chaque commentaire à son article parent
const comments = postsComments.filter(comment => comment.post_id === post.id);
post.comments = comments;
}
Comme vous pouvez le voir, dans cette stratégie, il n'y a que deux requêtes : une pour récupérer tous les articles et une autre pour récupérer leurs commentaires.
3) Mise en cache
Vous êtes peut-être familier avec la mise en cache et son impact sur les performances de toute application.
Vous pouvez implémenter la mise en cache côté client ou côté serveur en utilisant Redis, Memcached, ou tout autre outil similaire. Où que vous puissiez utiliser correctement la mise en cache, elle améliore considérablement les performances de votre application.
Revenons à notre exemple et mettons en cache les commentaires des articles dans un stockage Redis.
const posts = await rawSql('SELECT * FROM "Post"'),
postsIds = posts.map(post => post.id),
cachedPostsComments = getPostsCommentsFromRedis(postsIds);
for (const post in posts) {
const comments = cachedPostsComments.filter(comment => comment.post_id === post.id);
post.comments = comments;
}
Comme vous pouvez le deviner, vous pouvez mettre en cache les commentaires des articles ou même les articles eux-mêmes, ce qui minimise considérablement la charge sur les bases de données.
4) Chargement paresseux
Dans cette stratégie, vous répartissez la responsabilité entre le côté serveur et le côté client.
Vous ne devez pas retourner toutes les données en une seule fois depuis le côté serveur. Au lieu de cela, vous préparez deux endpoints pour le côté client comme ceci :
GET /api/posts: Récupère tous les articles.GET /api/comments/:postId: Récupère les commentaires d'un article à la demande.
Et maintenant, la récupération des données dépend du côté client.
Cette stratégie est très utile car :
- Elle permet au côté client de charger d'abord l'article parent et d'afficher son contenu, puis de charger ses commentaires associés de manière paresseuse. Ainsi, les utilisateurs n'ont pas à attendre que l'ensemble des données soit retourné depuis le côté serveur.
- Vous avez un contrôle total sur le tri, le filtrage, la pagination et ainsi de suite sur chaque endpoint.
Le point clé de cette stratégie est qu'elle se débarrasse des données imbriquées comme les commentaires et aplatit tous les ensembles de données dans leur propre endpoint.
5) GraphQL Dataloader
Comme vous pouvez le deviner, cette stratégie fonctionne avec les API GraphQL.
Dataloader est un utilitaire GraphQL qui fonctionne en regroupant plusieurs requêtes de base de données en une seule requête. Ainsi, il utilise la stratégie de chargement par lots sous le capot.
Passons à notre exemple :
const DataLoader = require('dataloader');
// 1- Définition du schéma GraphQL
const typeDefs = gql`
type Post {
post_id: ID!
comments: [Comment]
}
type Comment {
comment_id: ID!
post_id: ID!
}
type Query {
posts: [Post]
}
`;
// 2- Résolution du schéma GraphQL
const resolvers = {
Query: {
posts: async () => {
const posts = await rawSql('SELECT * FROM "Post"');
return posts;
}
},
Post: {
comments: (post, args, { dataLoaders }) => {
return dataLoaders.commentsLoader.load(post.id);
}
}
};
// 3- Définir les Dataloaders
const commentsBatchFunction = async postsIds => {
const comments = await rawSql(`SELECT * FROM "Comment" WHERE "post_id" IN (${postsIds})`);
const groupedComments = comments.reduce((tot, cur) => {
if (!tot[cur.post_id]) {
tot[cur.post_id] = [cur];
} else {
tot[cur.post_id].push(cur);
}
return tot;
}, {});
return postsIds.map((postId) => groupedComments[postId]);
},
createCommentsLoader = new DataLoader(commentsBatchFunction),
createDataloaders = () => ({
commentsLoader: createCommentsLoader()
});
// 4- Injecter les Dataloaders dans le contexte GraphQL
const server = new ApolloServer({
typeDefs,
resolvers,
context: () => {
return {
dataLoaders: createDataloaders(),
}
}
});
Alors, comment cela fonctionne-t-il ? Pour obtenir des informations plus détaillées, vous pouvez consulter la documentation. Mais nous allons passer en revue les bases ici.
Le point clé du Dataloader est la Fonction de lot. Ici, la fonction de lot commentsBatchFunction prend un tableau de clés postsIds et retourne une Promesse qui se résout en un tableau de valeurs comments, [ [post1comment1, post1comment2], [post2comment1], ... ].
En plus de cela, la fonction de lot a deux contraintes :
- La taille du tableau de clés
postsIdsdoit être égale à celle du tableau de valeurscomments. En d'autres termes, cette expression doit être vraie :postsIds.length === comments.length. - Chaque index dans le tableau de clés
postsIdsdoit correspondre au tableau de valeurscomments. Ainsi, vous pourriez noter que j'ai parcouru lespostsIdspour mapper chaque commentaire correspondant.
En conséquence, vous pouvez voir que GraphQL Dataloader utilise la deuxième stratégie (Chargement par lots) sous le capot.
Revenons à notre exemple pour parcourir son implémentation :
- Tout d'abord, nous avons défini le schéma GraphQL.
- Ensuite, nous avons résolu le schéma GraphQL. Gardez à l'esprit, si vous avez résolu les commentaires dans le type
Posten utilisant cette requêteawait rawSql('SELECT * FROM "Comment" WHERE "post_id" = ' + post.id);, vous allez tomber dans le problème des requêtes N+1. - Ensuite, nous avons défini la fonction de lot des commentaires puis créé le dataloader des commentaires.
- Enfin, nous avons injecté les dataloaders dans le Contexte GraphQL pour pouvoir les utiliser dans les résolveurs.
Ainsi, en utilisant GraphQL Dataloader, si vous avez 10 articles et que chaque article a 5 commentaires, vous finirez avec deux requêtes – une pour récupérer les 10 articles et une autre pour récupérer leurs commentaires.
Jetez un coup d'œil à la capture d'écran suivante :
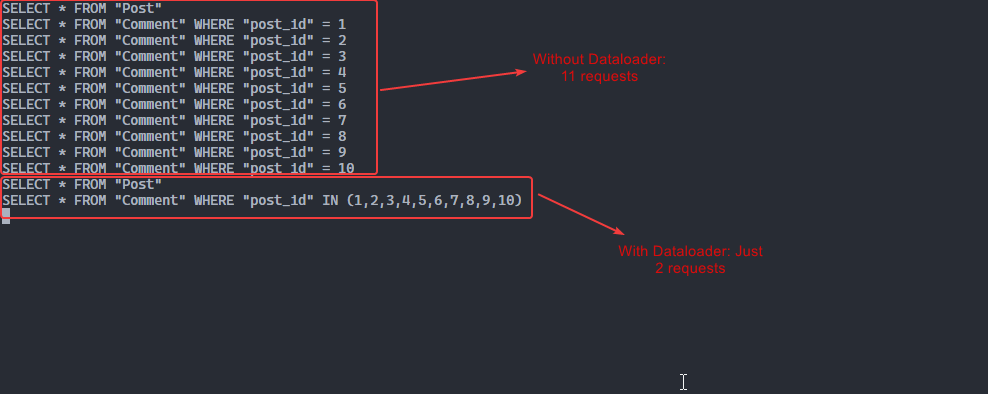 Illustration du processus avec et sans Dataloader
Illustration du processus avec et sans Dataloader
Benchmarks sur le problème des requêtes N+1
Dans cette section, comparons chaque stratégie en termes de performance.
| N+1 dans l'API REST | Stratégie de chargement anticipé | Stratégie de chargement par lots | Stratégie de mise en cache | N+1 dans l'API GraphQL | GraphQL Dataloader |
|---|---|---|---|---|---|
| 2.139 | 0.065 | 0.048 | 0.019 | 2.44 | 0.397 |
| 2.147 | 0.081 | 0.068 | 0.024 | 2.38 | 0.483 |
| 2.152 | 0.062 | 0.065 | 0.035 | 2.67 | 0.372 |
| 2.17 | 0.053 | 0.047 | 0.031 | 2.71 | 0.377 |
| 2.181 | 0.052 | 0.069 | 0.031 | 2.38 | 0.364 |
| 2.14 | 0.076 | 0.043 | 0.017 | 2.53 | 0.346 |
| 2.321 | 0.073 | 0.045 | 0.018 | 2.60 | 0.451 |
| 2.13 | 0.061 | 0.06 | 0.015 | 2.35 | 0.369 |
| 2.149 | 0.064 | 0.04 | 0.015 | 2.65 | 0.368 |
| 2.361 | 0.065 | 0.045 | 0.016 | 2.54 | 0.424 |
| 2.190 | 0.065 | 0.053 | 0.022 | 2.525 | 0.395 |
Notez que les résultats de la stratégie de mise en cache arrivent juste après la mise en cache de l'ensemble de données. La première requête est ignorée car la mise en cache est manquante.
Ces résultats ont été générés à partir de l'environnement suivant :
- Données ensemencées : 1000 articles et 50 commentaires pour chaque article.
- CPU : AMD Ryzen 5 3600 6-Core Processor 3.60 GHz.
- RAM : 32.0 GB.
- OS : Windows 10 Pro.
Pour pouvoir retester ces stratégies dans votre environnement, suivez ces étapes :
- Clonez ce dépôt.
- Ensuite, exécutez
docker-compose up. - Pour GraphQL, ouvrez
http://localhost:3000/graphql. - Une requête souffre du problème N+1 : interrogez uniquement
commentsWithNPlusOnedans le typePost. - Stratégie Dataloader : interrogez uniquement
commentsWithDataloaderdans le typePost. - Pour REST, suivez ces endpoints :
- Une requête souffre du problème N+1 :
http://localhost:3000/api/postsWithNPlusOne. - Stratégie de chargement anticipé :
http://localhost:3000/api/postsWithEagerLoading. - Stratégie de chargement par lots :
http://localhost:3000/api/postsWithBatchLoading. - Stratégie de mise en cache :
http://localhost:3000/api/postsWithCache.
Mes notes sur ces benchmarks :
- Ces stratégies sont beaucoup trop efficaces.
- Vous pourriez remarquer que la stratégie la plus lente dans REST, la stratégie de chargement anticipé, est environ 34 fois plus rapide que la requête N+1 dans l'API REST.
- La stratégie Dataloader est environ 6.4 fois plus rapide que la requête N+1 dans l'API GraphQL.
- Si vous avez comparé les résultats des API REST et GraphQL, vous pourriez remarquer que REST est plus rapide que GraphQL. Je pense que cela est dû aux implémentations internes de GraphQL, ce qui est logique.
Conclusion
Dans cet article, vous avez appris que le problème des requêtes N+1 est un problème de performance que vous pourriez rencontrer lors de la création d'API.
Vous avez ensuite appris quelques stratégies que vous pouvez suivre pour éviter ce problème comme :
- Le chargement anticipé en utilisant des jointures SQL
- Le chargement par lots en exécutant moins de requêtes puis en mappant chaque élément correspondant à son parent.
- La mise en cache en utilisant Redis
- Le Dataloader dans le monde GraphQL.
Enfin, nous avons créé quelques benchmarks sur le problème des requêtes N+1 afin de voir à quel point ces stratégies améliorent efficacement les performances de notre API.
Avant de partir
Si vous avez trouvé cet article utile, vous pouvez consulter certains de mes autres articles sur mon blog personnel.
Merci beaucoup de m'avoir suivi jusqu'à ce point. J'espère que vous avez apprécié la lecture de cet article.