

Article original : How to Stream File Uploads to S3 Object Storage and Reduce Costs
Par Austin Gil
Pour prendre en charge les téléchargements de fichiers dans votre application, vous devrez apprendre à envoyer des fichiers depuis le frontend et à recevoir des fichiers sur le backend.
Ce tutoriel va faire un pas en arrière et explorer les changements architecturaux qui vous aideront à réduire les coûts lors de l'ajout de téléchargements de fichiers à vos applications.
Voici ce que nous allons couvrir :
- Qu'est-ce que le stockage d'objets ?
- Qu'est-ce que S3 ?
- Commencer avec une application Node.js existante
- Configurer le client S3
- Comment modifier formidable
- Parcours de l'ensemble du flux
- Avertissements
- Réflexions finales
Et voici une vidéo que vous pouvez utiliser pour compléter ce tutoriel si vous le souhaitez :
Avant d'aller plus loin, vous devriez déjà être familier avec l'envoi et la réception d'une requête multipart/form-data, l'analyse de la requête, l'accès au flux de fichiers et l'écriture de ce fichier sur le disque sur le serveur d'application.
Notez que le flux décrit ci-dessus écrit les fichiers sur le serveur d'application. C'est assez courant, mais il y a quelques problèmes avec cette approche.
Premièrement, cette approche ne fonctionne pas pour les systèmes distribués qui peuvent dépendre de plusieurs machines différentes. Si un utilisateur télécharge un fichier, il peut être difficile (ou impossible) de savoir quelle machine a reçu la requête, et donc, où le fichier est enregistré. Cela est particulièrement vrai si vous utilisez du serverless ou du edge compute.
Deuxièmement, stocker les téléchargements sur le serveur d'application peut entraîner un manque d'espace disque sur le serveur. À ce stade, nous devrions mettre à niveau notre serveur. Cela pourrait être beaucoup plus coûteux que d'autres solutions rentables.
Et c'est là que le stockage d'objets entre en jeu.
Qu'est-ce que le stockage d'objets ?
Vous pouvez penser au stockage d'objets comme à un dossier sur un ordinateur. Vous pouvez y mettre tous les fichiers (aka "objets") que vous voulez, mais les dossiers (aka "buckets") vivent dans un fournisseur de services cloud. Vous pouvez également accéder aux fichiers via une URL.
Le stockage d'objets offre plusieurs avantages :
- C'est un endroit central unique pour stocker et accéder à tous vos téléchargements.
- Il est conçu pour être hautement disponible, facilement scalable et très rentable.
Par exemple, si vous considérez les serveurs CPU partagés, vous pourriez exécuter une application pour 5 $/mois et obtenir 25 Go d'espace disque. Si votre serveur commence à manquer d'espace, vous pourriez mettre à niveau votre serveur pour obtenir 25 Go supplémentaires, mais cela vous coûtera 7 $/mois de plus.
Alternativement, vous pourriez mettre cet argent dans le stockage d'objets et vous obtiendriez 250 Go pour 5 $/mois. Donc 10 fois plus d'espace de stockage pour un coût moindre.
Bien sûr, il y a d'autres raisons de mettre à niveau votre serveur d'application. Vous pourriez avoir besoin de plus de RAM ou de CPU, mais si nous parlons uniquement d'espace disque, le stockage d'objets est une solution beaucoup moins chère.
Avec cela à l'esprit, le reste de cet article couvrira la connexion d'une application Node.js existante à un fournisseur de stockage d'objets. Nous utiliserons formidable pour analyser les requêtes multipart, mais nous le configurerons pour télécharger les fichiers vers le stockage d'objets au lieu d'écrire sur le disque.
Si vous souhaitez suivre, vous devrez avoir un bucket de stockage d'objets configuré, ainsi que les clés d'accès. Tout fournisseur de stockage d'objets compatible S3 devrait fonctionner.
Aujourd'hui, j'utiliserai les services de cloud computing d'Akamai (anciennement Linode). Si vous souhaitez faire de même, voici un guide qui vous montre comment commencer.
Et voici un lien pour obtenir 100 $ de crédits gratuits pendant 60 jours.
Qu'est-ce que S3 ?
Nous allons bientôt nous mettre au travail avec du code, mais avant cela, il y a un autre concept que je devrais expliquer : S3. S3 signifie "Simple Storage Service", et c'est un produit de stockage d'objets initialement développé chez AWS.
Avec leur produit, AWS a inventé un protocole de communication standard pour interagir avec leur solution de stockage d'objets.
Alors que de plus en plus d'entreprises ont commencé à offrir des services de stockage d'objets, elles ont également décidé d'adopter le même protocole de communication S3 pour leur service de stockage d'objets, et S3 est devenu une norme.
En conséquence, nous avons plus d'options pour choisir parmi les fournisseurs de stockage d'objets et moins d'options à explorer pour les outils. Nous pouvons utiliser les mêmes bibliothèques (maintenues par AWS) avec d'autres fournisseurs. C'est une excellente nouvelle car cela signifie que le code que nous écrivons aujourd'hui devrait fonctionner avec n'importe quel service compatible S3.
Aujourd'hui, nous allons travailler avec une application Node.js et les bibliothèques dont nous aurons besoin sont @aws-sdk/client-s3 et @aws-sdk/lib-storage :
npm install @aws-sdk/client-s3 @aws-sdk/lib-storage
Ces bibliothèques nous aideront à télécharger des objets dans nos buckets.
D'accord, écrivons un peu de code !
Commencer avec une application Node.js existante
Nous allons commencer avec un exemple de gestionnaire d'événements Nuxt.js qui écrit des fichiers sur le disque en utilisant formidable. Il vérifie si une requête contient multipart/form-data et, si c'est le cas, il passe l'objet de requête Node.js sous-jacent (aka IncomingMessage) à une fonction personnalisée parseMultipartNodeRequest. Puisque cette fonction utilise la requête Node.js, elle fonctionnera dans n'importe quel environnement Node.js et avec des outils comme formidable.
import formidable from 'formidable';
/* global defineEventHandler, getRequestHeaders, readBody */
/**
* @see https://nuxt.com/docs/guide/concepts/server-engine
* @see https://github.com/unjs/h3
*/
export default defineEventHandler(async (event) => {
let body;
const headers = getRequestHeaders(event);
if (headers['content-type']?.includes('multipart/form-data')) {
body = await parseMultipartNodeRequest(event.node.req);
} else {
body = await readBody(event);
}
console.log(body);
return { ok: true };
});
/**
* @param {import('http').IncomingMessage} req
*/
function parseMultipartNodeRequest(req) {
return new Promise((resolve, reject) => {
const form = formidable({ multiples: true });
form.parse(req, (error, fields, files) => {
if (error) {
reject(error);
return;
}
resolve({ ...fields, ...files });
});
});
}
Nous allons modifier ce code pour envoyer les fichiers vers un bucket S3 au lieu de les écrire sur le disque.
Configurer le client S3
La première chose que nous devons faire est de configurer un client S3 pour effectuer les requêtes de téléchargement pour nous, afin de ne pas avoir à les écrire manuellement. Nous allons importer le constructeur S3Client de @aws-sdk/client-s3 ainsi que la commande Upload de @aws-sdk/lib-storage. Nous allons également importer le module stream de Node pour l'utiliser plus tard.
import stream from 'node:stream';
import { S3Client } from '@aws-sdk/client-s3';
import { Upload } from '@aws-sdk/lib-storage';
Ensuite, nous devons configurer notre client en utilisant l'endpoint de notre bucket S3, la clé d'accès, la clé d'accès secrète, et la région. Encore une fois, vous devriez déjà avoir configuré un bucket S3 et savoir où trouver ces informations. Si ce n'est pas le cas, consultez ce guide (100 $ de crédit).
J'aime stocker ces informations dans des variables d'environnement et ne pas les coder en dur dans le code source. Nous pouvons accéder à ces variables en utilisant process.env pour les utiliser dans notre application.
const { S3_URL, S3_ACCESS_KEY, S3_SECRET_KEY, S3_REGION } = process.env;
Si vous n'avez jamais utilisé de variables d'environnement, c'est un bon endroit pour mettre des informations secrètes telles que les identifiants d'accès. Vous pouvez en lire plus à ce sujet ici.
Avec nos variables configurées, je peux maintenant instancier le client S3 que nous utiliserons pour communiquer avec notre bucket.
const s3Client = new S3Client({
endpoint: `https://${S3_URL}`,
credentials: {
accessKeyId: S3_ACCESS_KEY,
secretAccessKey: S3_SECRET_KEY,
},
region: S3_REGION,
});
Il est important de noter que l'endpoint doit inclure le protocole HTTPS. Dans le tableau de bord du stockage d'objets d'Akamai, lorsque vous copiez l'URL du bucket, elle n'inclut pas le protocole (bucket-name.bucket-region.linodeobjects.com). Je l'ajoute donc ici comme préfixe.
Avec notre client S3 configuré, nous pouvons commencer à l'utiliser.
Comment modifier formidable
Dans notre application, nous passons toute requête multipart Node à notre fonction personnalisée, parseMultipartNodeRequest. Cette fonction retourne une promesse et passe la requête à formidable, qui analyse la requête, écrit les fichiers sur le disque et résout la promesse avec les données des champs de formulaire et des fichiers.
function parseMultipartNodeRequest(req) {
return new Promise((resolve, reject) => {
const form = formidable({ multiples: true });
form.parse(req, (error, fields, files) => {
if (error) {
reject(error);
return;
}
resolve({ ...fields, ...files });
});
});
}
C'est la partie qui doit changer. Au lieu de traiter la requête et d'écrire les fichiers sur le disque, nous voulons rediriger les flux de fichiers vers une requête de téléchargement S3. Ainsi, chaque fragment de fichier reçu est passé par notre gestionnaire à la requête de téléchargement S3.
Nous allons toujours retourner une promesse et utiliser formidable pour analyser le formulaire, mais nous devons changer les options de configuration de formidable. Nous allons définir l'option fileWriteStreamHandler sur une fonction appelée fileWriteStreamHandler que nous allons écrire prochainement.
/** @param {import('formidable').File} file */
function fileWriteStreamHandler(file) {
// TODO
}
const form = formidable({
multiples: true,
fileWriteStreamHandler: fileWriteStreamHandler,
});
Voici ce que dit leur documentation sur fileWriteStreamHandler :
options.fileWriteStreamHandler{function} – par défautnull, ce qui par défaut écrit sur le système de fichiers de la machine hôte chaque fichier analysé ; La fonction doit retourner une instance d'un flux Writable qui recevra les données du fichier téléchargé. Avec cette option, vous pouvez avoir n'importe quel comportement personnalisé concernant l'endroit où les données du fichier téléchargé seront diffusées. Si vous souhaitez écrire le fichier téléchargé dans d'autres types de stockages cloud (AWS S3, Azure blob storage, Google cloud storage) ou de stockage de fichiers privé, c'est l'option que vous recherchez. Lorsque cette option est définie, le comportement par défaut d'écriture du fichier dans le système de fichiers de la machine hôte est perdu.
Alors que formidable analyse chaque fragment de données de la requête, il redirigera ce fragment vers le flux Writable qui est retourné par cette fonction. Ainsi, notre fonction fileWriteStreamHandler est l'endroit où la magie opère.
Avant d'écrire le code, comprenons quelques choses :
- Cette fonction doit retourner un flux Writable pour écrire chaque fragment de téléchargement.
- Elle doit également rediriger chaque fragment de données vers un stockage d'objets S3.
- Nous pouvons utiliser la commande
Uploadde@aws-sdk/lib-storagepour créer la requête. - Le corps de la requête peut être un flux, mais il doit être un flux Readable, et non un flux Writable.
- Un flux Passthrough peut être utilisé à la fois comme flux Readable et Writable.
- Chaque requête que formidable analysera peut contenir plusieurs fichiers, donc nous devons peut-être suivre plusieurs requêtes de téléchargement S3.
fileWriteStreamHandlerreçoit un paramètre de typeformidable.Fileinterface avec des propriétés commeoriginalFilename,size,mimetype, et plus encore.
D'accord, écrivons maintenant le code. Nous allons commencer par un Array pour stocker et suivre toutes les requêtes de téléchargement S3 en dehors de la portée de fileWriteStreamHandler.
À l'intérieur de fileWriteStreamHandler, nous allons créer le flux Passthrough qui servira à la fois de corps Readable du téléchargement S3 et de valeur de retour Writable de cette fonction.
Nous allons créer la requête Upload en utilisant les bibliothèques S3, et lui indiquer le nom de notre bucket, la clé de l'objet (qui peut inclure des dossiers), le type de contenu de l'objet, le niveau de contrôle d'accès pour cet objet, et le flux Passthrough comme corps de la requête.
Nous allons instancier la requête en utilisant Upload.done() et ajouter la Promise retournée à notre Array de suivi. Nous pourrions vouloir ajouter la propriété Location de la réponse à l'objet file lorsque le téléchargement est terminé, afin de pouvoir utiliser cette information plus tard.
Enfin, nous allons retourner le flux Passthrough de cette fonction :
/** @type {Promise<any>[]} */
const s3Uploads = [];
/** @param {import('formidable').File} file */
function fileWriteStreamHandler(file) {
const body = new stream.PassThrough();
const upload = new Upload({
client: s3Client,
params: {
Bucket: 'austins-bucket',
Key: `files/${file.originalFilename}`,
ContentType: file.mimetype,
ACL: 'public-read',
Body: body,
},
});
const uploadRequest = upload.done().then((response) => {
file.location = response.Location;
});
s3Uploads.push(uploadRequest);
return body;
}
Quelques points à noter :
Keyest le nom et l'emplacement où l'objet existera. Il peut inclure des dossiers qui seront créés s'ils n'existent pas actuellement. Si un fichier existe avec le même nom et le même emplacement, il sera écrasé (ce qui me convient aujourd'hui). Vous pouvez éviter les collisions en utilisant des noms hachés ou des horodatages.ContentTypen'est pas obligatoire, mais il est utile de l'inclure. Il permet aux navigateurs de créer la réponse de téléchargement de manière appropriée en fonction du type de contenu.ACL: est également facultatif, mais par défaut, chaque objet est privé. Si vous voulez que les gens puissent accéder aux fichiers via une URL (comme un élément<img>), vous devrez le rendre public.- Bien que
@aws-sdk/client-s3prenne en charge les téléchargements, vous avez besoin de@aws-sdk/lib-storagepour prendre en charge les flux Readable. - Vous pouvez en lire plus sur les paramètres sur NPM.
De cette manière, formidable devient la plomberie qui connecte la requête cliente entrante à la requête de téléchargement S3.
Il ne reste plus qu'un changement à faire. Nous suivons toutes les requêtes de téléchargement, mais nous n'attendons pas qu'elles se terminent.
Nous pouvons corriger cela en modifiant la fonction parseMultipartNodeRequest. Elle doit continuer à utiliser formidable pour analyser la requête cliente, mais au lieu de résoudre la promesse immédiatement, nous pouvons utiliser Promise.all pour attendre que toutes les requêtes de téléchargement soient résolues.
La fonction complète ressemble à ceci :
/**
* @param {import('http').IncomingMessage} req
*/
function parseMultipartNodeRequest(req) {
return new Promise((resolve, reject) => {
/** @type {Promise<any>[]} */
const s3Uploads = [];
/** @param {import('formidable').File} file */
function fileWriteStreamHandler(file) {
const body = new PassThrough();
const upload = new Upload({
client: s3Client,
params: {
Bucket: 'austins-bucket',
Key: `files/${file.originalFilename}`,
ContentType: file.mimetype,
ACL: 'public-read',
Body: body,
},
});
const uploadRequest = upload.done().then((response) => {
file.location = response.Location;
});
s3Uploads.push(uploadRequest);
return body;
}
const form = formidable({
multiples: true,
fileWriteStreamHandler: fileWriteStreamHandler,
});
form.parse(req, (error, fields, files) => {
if (error) {
reject(error);
return;
}
Promise.all(s3Uploads)
.then(() => {
resolve({ ...fields, ...files });
})
.catch(reject);
});
});
}
La valeur résolue files contiendra également la propriété location que nous avons incluse, pointant vers l'URL du stockage d'objets.
Parcours de l'ensemble du flux
Nous avons couvert beaucoup de choses, et je pense qu'il est bon de revoir comment tout fonctionne ensemble. Si nous regardons en arrière le gestionnaire d'événements original, nous pouvons voir que toute requête multipart/form-data sera reçue et passée à notre fonction parseMultipartNodeRequest. La valeur résolue de cette fonction sera enregistrée dans la console :
export default defineEventHandler(async (event) => {
let body;
const headers = getRequestHeaders(event);
if (headers['content-type']?.includes('multipart/form-data')) {
body = await parseMultipartNodeRequest(event.node.req);
} else {
body = await readBody(event);
}
console.log(body);
return { ok: true };
});
Avec cela à l'esprit, décomposons ce qui se passe si je veux télécharger une photo mignonne de Nugget faisant un grand bâillement.
- Pour que le navigateur envoie le fichier sous forme de données binaires, il doit faire une requête
multiplart/form-dataavec un formulaire HTML ou avec JavaScript. - Notre application Nuxt.js reçoit la requête
multipart/form-dataet passe l'objet de requête Node.js sous-jacent à notre fonction personnaliséeparseMultipartNodeRequest. parseMultipartNodeRequestretourne unePromisequi sera éventuellement résolue avec les données. À l'intérieur de cettePromise, nous instancions la bibliothèque formidable et passons l'objet de requête à formidable pour l'analyse.- Alors que formidable analyse la requête, lorsqu'il rencontre un fichier, il écrit les fragments de données du flux de fichiers dans le flux
Passthroughqui est retourné par la fonctionfileWriteStreamHandler. - À l'intérieur de
fileWriteStreamHandler, nous configurons également une requête pour télécharger le fichier vers notre bucket compatible S3, et nous utilisons le même fluxPassthroughcomme corps de la requête. Ainsi, alors que formidable écrit des fragments de données de fichiers dans le fluxPassthrough, ils sont également lus par la requête de téléchargement S3. - Une fois que formidable a terminé l'analyse de la requête, tous les fragments de données des flux de fichiers sont pris en charge, et nous attendons que la liste des requêtes S3 termine le téléchargement.
- Après que tout cela est fait, nous résolvons la
PromisedeparseMultipartNodeRequestavec les données modifiées de formidable. La variablebodyest assignée à la valeur résolue. - Les données représentant les champs et les fichiers (pas les fichiers eux-mêmes) sont enregistrées dans la console.
Donc maintenant, si notre requête de téléchargement originale contenait un seul champ appelé "file1" avec la photo de Nugget, nous pourrions voir quelque chose comme ceci :
{
file1: {
_events: [Object: null prototype] { error: [Function (anonymous)] },
_eventsCount: 1,
_maxListeners: undefined,
lastModifiedDate: null,
filepath: '/tmp/93374f13c6cab7a01f7cb5100',
newFilename: '93374f13c6cab7a01f7cb5100',
originalFilename: 'nugget.jpg',
mimetype: 'image/jpeg',
hashAlgorithm: false,
createFileWriteStream: [Function: fileWriteStreamHandler],
size: 82298,
_writeStream: PassThrough {
_readableState: [ReadableState],
_events: [Object: null prototype],
_eventsCount: 6,
_maxListeners: undefined,
_writableState: [WritableState],
allowHalfOpen: true,
[Symbol(kCapture)]: false,
[Symbol(kCallback)]: null
},
hash: null,
location: 'https://austins-bucket.us-southeast-1.linodeobjects.com/files/nugget.jpg',
[Symbol(kCapture)]: false
}
}
Cela ressemble beaucoup à l'objet que formidable retourne lorsqu'il écrit directement sur le disque. Mais cette fois, il a une propriété supplémentaire, location, qui est l'URL du stockage d'objets pour notre fichier téléchargé.
Jetez ce truc dans votre navigateur et qu'obtenez-vous ?
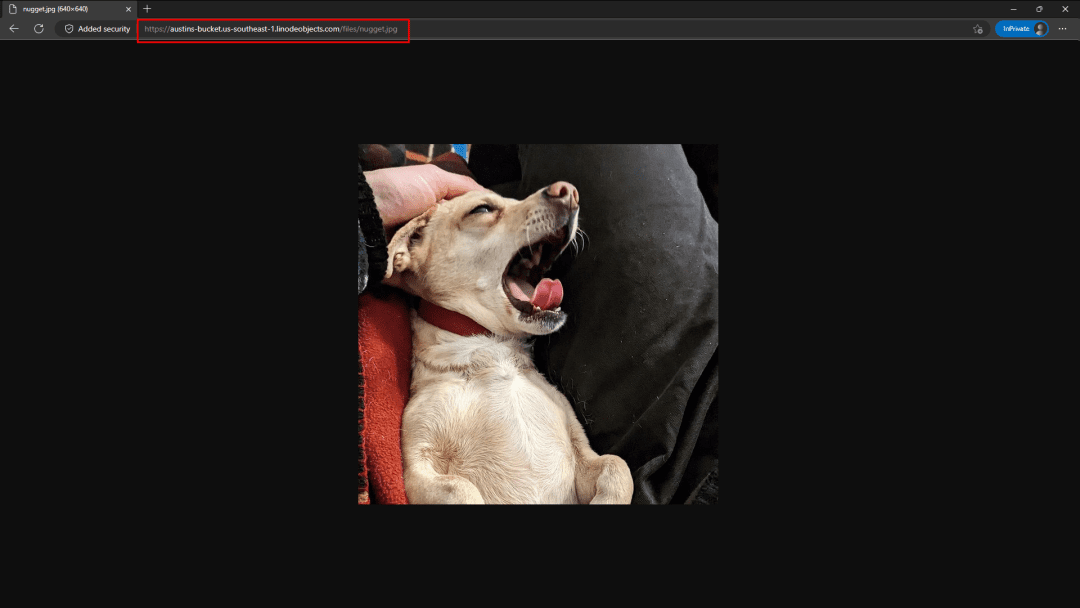
C'est ça ! Une photo mignonne de Nugget faisant un grand bâillement 😊
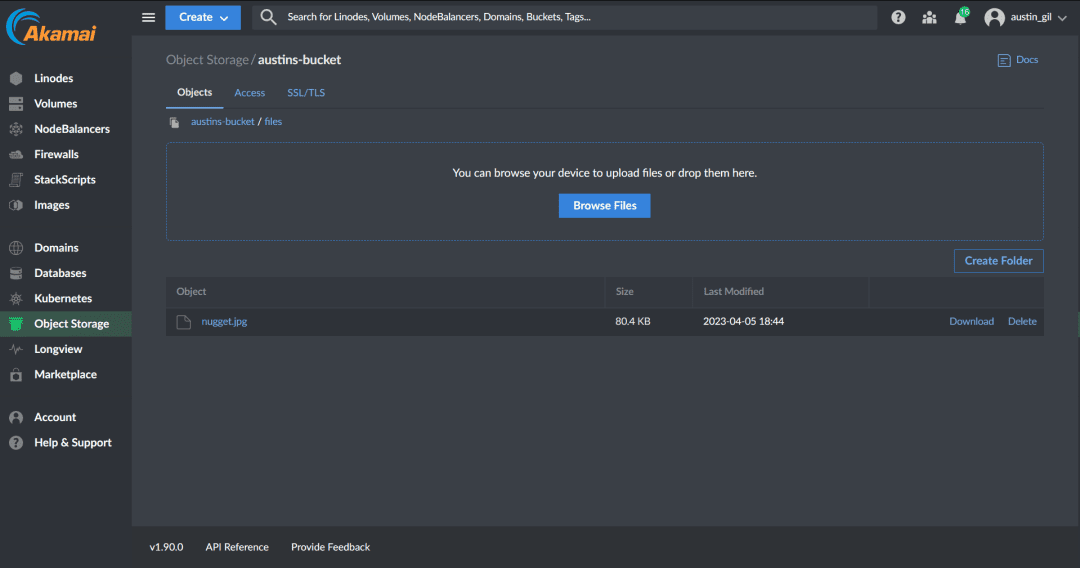
Je peux également aller dans mon bucket dans mon tableau de bord Object Storage et voir que j'ai maintenant un dossier appelé "files" contenant un fichier appelé "nugget.jpg".
Avertissements
Je serais négligent si je ne mentionnais pas ce qui suit. (En fait, j'ai été négligent parce que je ne l'ai pas mentionné jusqu'à ce que quelqu'un me l'ait fait remarquer 😳)
Le streaming des téléchargements via votre backend vers le stockage d'objets n'est pas la seule façon de télécharger des fichiers vers S3. Vous pouvez également utiliser des URL signées.
Les URL signées sont essentiellement la même URL dans le bucket où le fichier vivra, mais elles incluent une signature d'authentification qui peut être utilisée par n'importe qui pour télécharger un fichier, tant que la signature n'a pas expiré (généralement très bientôt).
Voici comment le flux fonctionne généralement :
- Le frontend fait une requête au backend pour une URL signée.
- Le backend fait une requête authentifiée au fournisseur de stockage d'objets pour une URL signée avec une expiration donnée.
- Le fournisseur de stockage d'objets fournit une URL signée au backend.
- Le backend retourne l'URL signée au frontend.
- Le frontend télécharge le fichier directement vers le stockage d'objets grâce à l'URL signée.
- Optionnel : Le frontend peut faire une autre requête au backend si vous devez mettre à jour une base de données indiquant que le téléchargement est terminé.
Ce flux nécessite un peu plus de chorégraphie que Frontend -> Backend -> Stockage d'objets, mais il a quelques avantages.
- Il déplace le travail de vos serveurs, ce qui peut réduire la charge et améliorer les performances.
- Il déplace la bande passante de téléchargement de fichiers de votre serveur. Si vous payez pour l'ingress et que vous avez plusieurs téléchargements de gros fichiers tout le temps, cela peut s'additionner.
Cela comporte également ses propres coûts.
- Vous avez beaucoup moins de contrôle sur ce que les utilisateurs peuvent télécharger. Cela peut inclure des logiciels malveillants.
- Si vous devez effectuer des fonctions sur les fichiers comme l'optimisation, vous ne pouvez pas le faire avec des URL signées.
- Le flux complexe rend beaucoup plus difficile la construction d'un flux de téléchargement avec une amélioration progressive à l'esprit.
Comme pour la plupart des choses en développement web, il n'y a pas une seule solution correcte. Cela dépendra largement de votre cas d'utilisation. J'aime passer par mon backend, afin d'avoir plus de contrôle sur les fichiers et de simplifier le frontend.
Je voulais partager cette option de streaming, largement parce qu'il y a à peine du contenu sur le streaming. La plupart du contenu utilise des URL signées (peut-être que je manque quelque chose). Si vous souhaitez en savoir plus sur l'utilisation des URL signées, voici une documentation et voici un tutoriel pratique par Mary Gathoni.
Réflexions finales
D'accord, nous avons couvert beaucoup de choses aujourd'hui. J'espère que tout cela avait du sens. Si ce n'est pas le cas, n'hésitez pas à me contacter avec vos questions. De plus, contactez-moi et faites-moi savoir si vous l'avez fait fonctionner dans votre propre application.
J'adorerais avoir de vos nouvelles, car l'utilisation du stockage d'objets est une excellente décision architecturale si vous avez besoin d'un endroit unique et rentable pour stocker des fichiers.
Merci beaucoup d'avoir lu. Si vous avez aimé cet article et souhaitez me soutenir, les meilleures façons de le faire sont de le partager, de vous inscrire à ma newsletter, et de me suivre sur Twitter.