

Article original : How to Develop a Reusable eCommerce Platform
Par Ramón Morcillo
Ceci est une histoire sur le travail acharné de mon équipe pour développer non pas une seule plateforme eCommerce, mais une plateforme réutilisable pour différents propriétaires. Nous avons conservé la même base de code, l'apparence et la convivialité, et l'avons rendue hautement personnalisable.
Je conclurai par ce que nous avons appris de ce processus. Je pense que nos enseignements seront une ressource d'apprentissage utile pour d'autres développeurs logiciels (et pour nous-mêmes dans les projets futurs, également).
Je vais essayer de me concentrer sur les parties pertinentes autant que possible pour faciliter la compréhension. Cela dit, un peu de contexte est nécessaire pour parcourir cet article.
Table des matières
- Contexte du projet
- Le premier MVP
- Implémentation de GraphQL
- Architecture et pile technologique
- Le deuxième MVP
- Conclusion et leçons apprises
- Réflexions finales
Contexte du projet
Le client pour lequel nous développions la plateforme était une entreprise d'eLearning composée de 3 sous-entreprises principales.
Au cours des dernières années, les sous-entreprises avaient opéré de manière principalement indépendante. Mais maintenant, elles essayaient de créer une manière standardisée de faire les choses, afin de pouvoir grandir ensemble de la meilleure façon.
Le projet était ambitieux. Créer une plateforme eCommerce qui fonctionnerait pour toutes les sous-entreprises n'était pas facile à concevoir ou à implémenter. Il y avait un grand nombre de questions non résolues, ce qui rendait très difficile l'estimation.

Le premier MVP
Pour relever ce défi difficile, nous avons commencé par le bas avec l'une des 3 sous-entreprises – appelons-la sous-entreprise H. En fait, ce n'était pas l'une des sous-entreprises principales, mais une sous-entreprise d'une sous-entreprise.
Pour mieux l'expliquer, si nous nommons les 3 sous-entreprises principales L, N et P, alors H était une sous-entreprise de N.
Le fait d'être une sous-sous-entreprise ne signifiait pas que la plateforme serait plus simple à développer. C'était plutôt le contraire, étant donné toutes les fonctionnalités proposées pour le MVP.
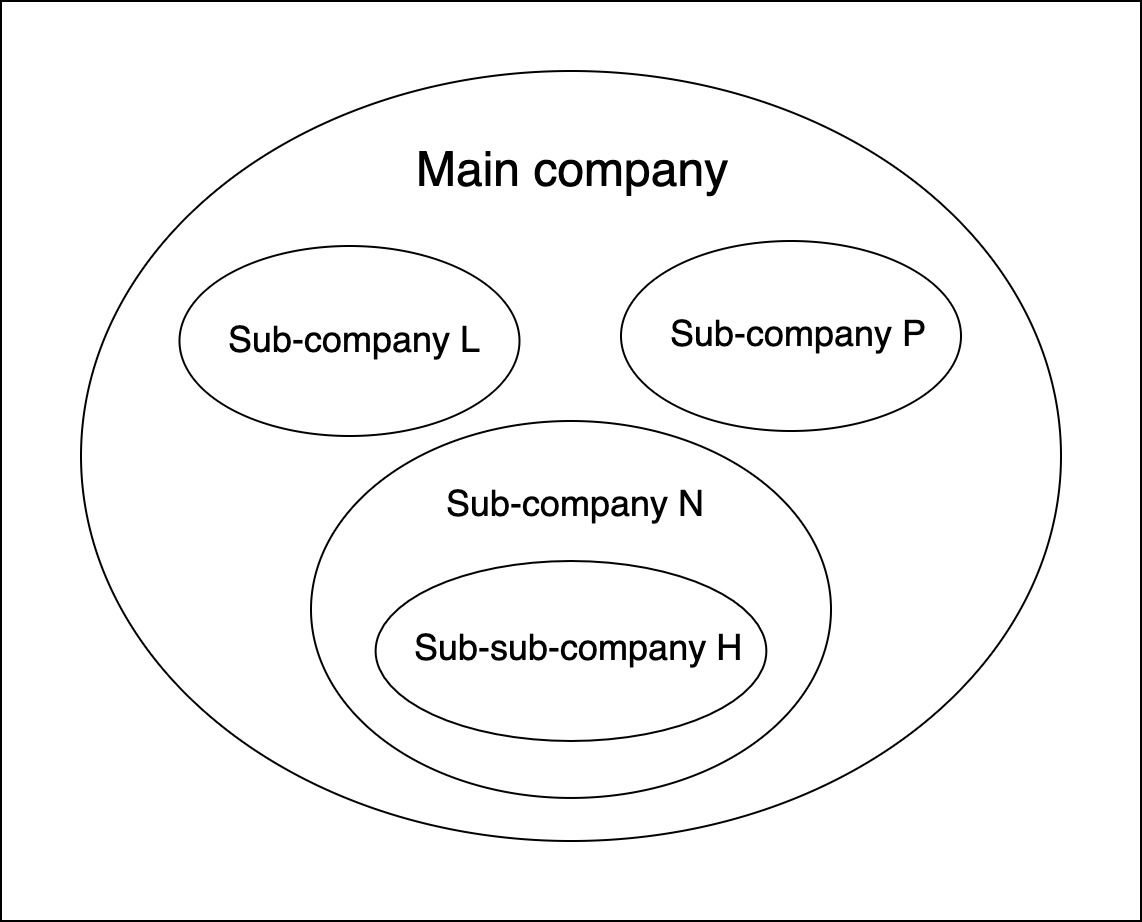 Structure de l'entreprise principale
Structure de l'entreprise principale
Bien que l'objectif principal était qu'un utilisateur puisse acheter un produit (ce qui semble assez évident), il y avait trop de dépendances avec d'autres services pour accomplir ce MVP apparemment simple.
Une partie des informations sur les produits et les commandes provenait du domaine d'une autre équipe, l'équipe des intégrations (que j'appellerai équipe In). Elles communiquaient avec Swell et Klopotek, un système eCommerce où nous stockions les informations sur les produits ainsi que le statut des commandes.
Les remises étaient également fournies par l'équipe In, à laquelle nous devions nous abonner puis calculer le prix final du produit en fonction des informations et des privilèges de l'utilisateur avant de l'afficher.
Pour rendre le contenu des produits comme les images ou les descriptions accessibles et personnalisables pour le client, nous l'avons récupéré via Contentful, une plateforme de contenu où les clients pouvaient le gérer de manière facile.
Nous avons géré les paiements avec Stripe, un service de paiement, puis nous avons communiqué avec l'équipe In pour mettre à jour le statut de la commande sur Swell.
Le service disponible pour que l'utilisateur s'authentifie devait être agnostique vis-à-vis du propriétaire et réutilisable sur toutes les sous-entreprises. Il devait être fourni par une autre équipe, mais en fin de compte, nous l'avons développé nous-mêmes.
Et pour mettre la cerise sur le gâteau, nous devions également implémenter le suivi des utilisateurs avec Segment, un service populaire pour collecter les événements des utilisateurs à partir des applications web et mobiles.
Voici un diagramme simple de ce que je viens de décrire, ce qui peut faciliter la compréhension. J'ai regroupé l'architecture des microservices en simplement Backend et Frontend pour garder cela simple.
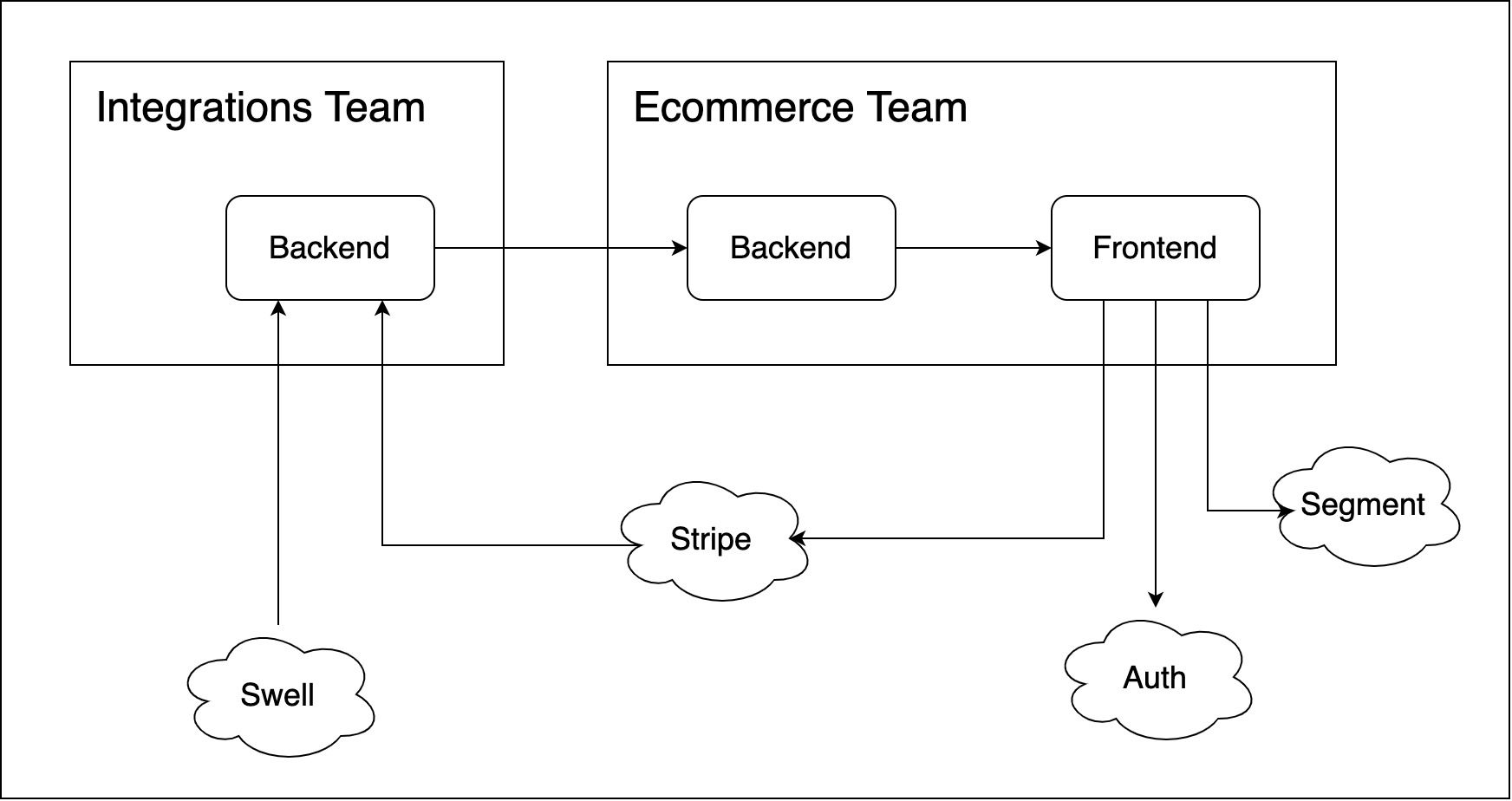 Aperçu de l'architecture du MVP
Aperçu de l'architecture du MVP
Pourquoi nous avons choisi GraphQL
Pour atteindre nos objectifs pour le projet, nous devions fournir au frontend une source unique de vérité des informations principales du produit depuis le backend.
Par conséquent, la seule chose que nous visions à avoir différente d'un frontend de magasin à un autre serait les designs et le contenu de Contentful.
Concernant ces designs et leurs implémentations sur React, nous avions prévu d'utiliser une bibliothèque de composants partagés.
Par conséquent, que fait GraphQL ici et pourquoi avons-nous décidé de l'utiliser ?
Eh bien, au cas où vous ne sauriez pas comment fonctionne GraphQL, essentiellement, il vous permet de définir un Schéma avec toutes les propriétés et requêtes qui pourraient être faites sur votre produit. Ensuite, il vous permet de le servir au frontend pour qu'il décide quoi demander sans que le backend ait à créer un endpoint pour chacune de ces requêtes (comme dans les services REST).
Pour en savoir plus, consultez ce tutoriel que j'ai écrit pour l'expliquer. Il vous apprend à l'utiliser avec Node.js. De plus, leur documentation vaut le coup d'œil.
Cela signifiait que chacun des magasins demanderait les données dont il avait besoin du produit simplement en regardant le Schéma, la source de vérité.
Grâce à ce fait, nous n'aurions pas à implémenter différentes sources de données dans le backend pour chaque magasin. Cela a donné au frontend le pouvoir et la responsabilité (le premier implique le second 💡) de demander les données du produit nécessaires à afficher à chaque interface.
Un grand pouvoir implique de grandes responsabilités. — Stan Lee
Juste pour être clair, si nous avions décidé d'utiliser REST, nous aurions dû créer différents endpoints pour chacun des magasins. Ou nous aurions dû faire en sorte que le frontend récupère toutes les données du produit dans chaque magasin puis décide quelles propriétés afficher. Cela signifie qu'il aurait dû stocker des données inutiles dans le frontend qui n'auraient ajouté que du bruit.
Ou pire encore, nous aurions eu tous les services backend des magasins déployés pour chacun des magasins frontend. Cela aurait utilisé des ressources inutiles et augmenté considérablement le coût.
Voici pourquoi nous avons pris cette approche initiale. La pire partie, à mon avis, aurait été le gaspillage de temps à maintenir et à refactoriser difficilement tout le désordre que nous aurions créé.
De plus, en faisant une seule demande à la demande, la charge utile était plus légère, et donc, la performance sur le réseau était améliorée.
Quoi qu'il en soit, comme pour tout problème, il y avait d'autres approches que nous aurions pu prendre en développant ce projet et son architecture. Mais à ce moment-là, celle-ci nous semblait être la meilleure.
Architecture et pile technologique
L'architecture des microservices consistait principalement en des services Node.js hébergés sur des clusters Azure K8s. Selon leurs besoins et les données avec lesquelles ils travaillaient, ils avaient ou non une base de données MongoDB, PostgreSQL ou Redis associée.
La communication asynchrone entre eux était principalement gérée avec les topics et abonnements Azure Service Bus via un modèle de communication de messagerie publish/subscribe.
La principale différence avec les files d'attente de messagerie courantes est que vous pouvez avoir plus d'un récepteur, donc vous n'avez pas plusieurs files d'attente pour recevoir des messages dans plus d'un service.
 Files d'attente de messagerie Azure Service Bus. Source
Files d'attente de messagerie Azure Service Bus. Source
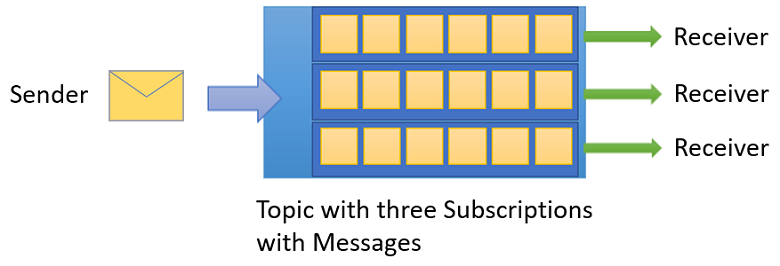 Topics de messagerie Azure Service Bus. Source
Topics de messagerie Azure Service Bus. Source
Pour la partie frontend, les sites étaient développés avec React. Parfois nous utilisions Next, et d'autres fois nous construisions à partir de zéro avec Create React App, selon la complexité et les exigences de chacun.
Nous sommes passés de Redux, utilisé dans les projets précédents, à l'API Context officielle pour gérer la plupart de l'état.
Voici les principaux services et leurs fonctionnalités pour l'architecture du premier MVP :
- shop-web-app : L'application client du magasin.
- gateway-api-service : Service proxy pour recevoir les requêtes du client et les rediriger vers les services correspondants.
- cms-api-service : Service pour récupérer et servir le contenu de Contentful.
- catalog-api-service : Service qui s'abonne aux messages de l'équipe In et persiste les données principales du produit pour les servir plus tard via GraphQL.
- orders-api-service : Service qui gère toute la logique métier des paiements.
- auth-api-service : Service provisoire pour implémenter l'authentification des utilisateurs afin de pouvoir acheter des produits.
- auth-web-app : Le client pour le service d'authentification.
- integrations-ecommerce-api-service : Service du domaine des intégrations qui gère les paiements. Bien que ce service ne soit pas dans notre domaine, nous l'avons développé ensemble pour augmenter la vitesse de livraison et les libérer de travail supplémentaire.
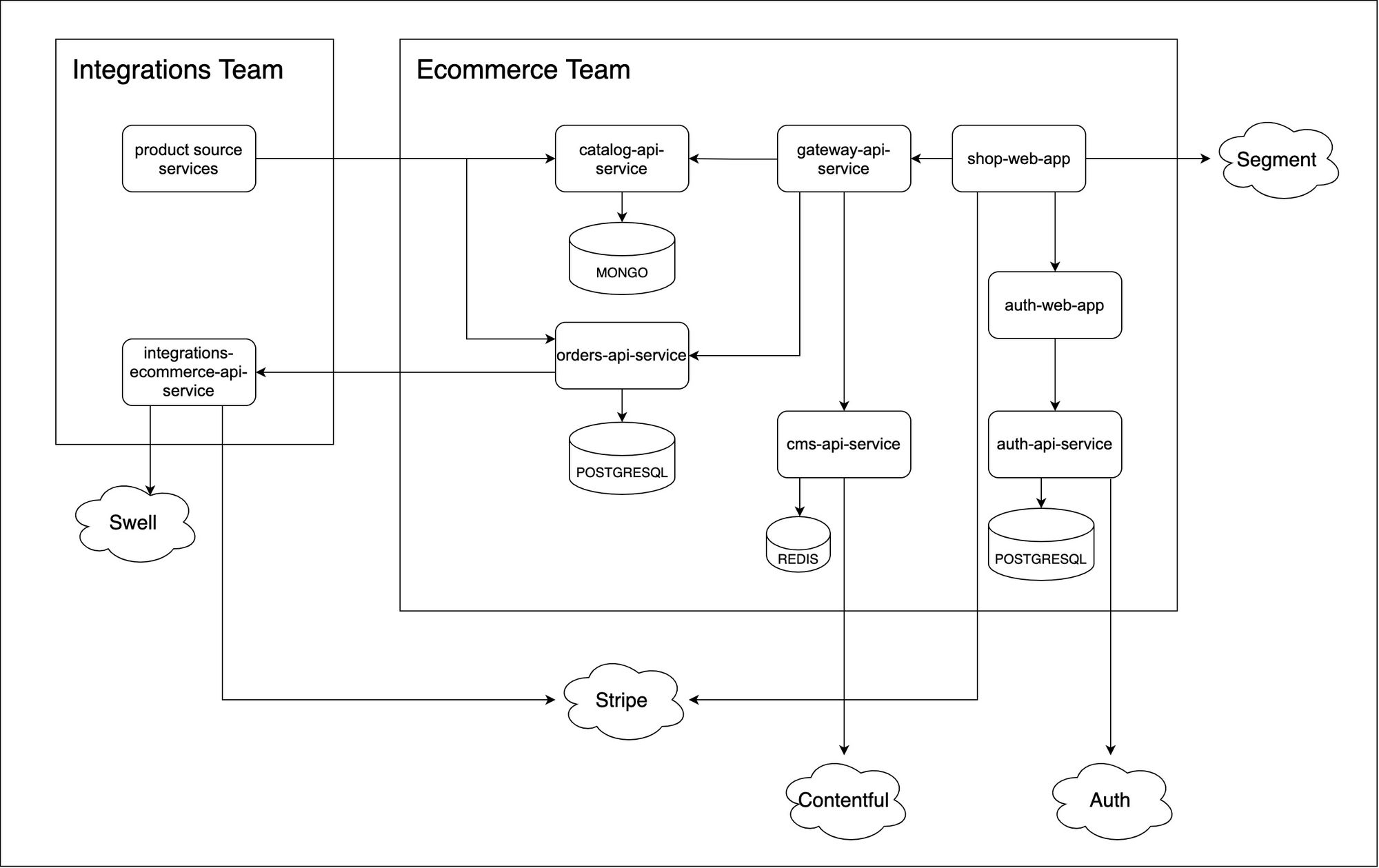 Architecture du premier MVP
Architecture du premier MVP
Pour déployer et mettre à jour les ressources nécessaires sur Azure, nous avons utilisé Terraform, qui nous a permis de définir l'infrastructure en tant que code et de gérer leurs cycles de vie sur les clusters K8s. Nous avons également travaillé avec Azure DevOps comme notre système CI & CD.
Sur les services, nous avons utilisé Systemic, un framework Node.js pour l'injection de dépendances minimale qui vous permet de créer des composants et leurs dépendances dans un système. Chaque composant gère un objet séparé du domaine tel que le routage, le contrôleur, les services, la base de données, et ainsi de suite de manière agnostique les uns des autres.
Apollo a été notre choix pour implémenter GraphQL. Il nous a fourni une couche de graphe de données pour connecter facilement le frontend et le backend.
Encore une fois, pour en savoir plus, consultez leur documentation ou ce tutoriel.
Enfin, nous avons hébergé le code sur GitHub pour utiliser des fonctionnalités comme les Pull Requests afin de réviser notre code correctement avant de l'implémenter.
Le deuxième MVP
Un MVP (Minimum Viable Product) est le premier prototype que vous créez et livrez dans un projet. Cela signifie qu'il n'y en a généralement qu'un seul, et lorsque vous le créez, vous commencez à implémenter de nouvelles fonctionnalités.
Alors, pourquoi nous sommes-nous concentrés sur un deuxième MVP pour le même projet ? Eh bien, lorsque nous avons atteint une version "stable" du premier, le client a réalisé que nous devions commencer avec les magasins de la sous-entreprise principale. Ils ont décidé d'arrêter le développement du magasin de la sous-sous-entreprise H pour se concentrer sur le développement des nouveaux.
Cela était principalement dû au fait que certains services mettaient fin à leur support pour les sous-entreprises dans les mois à venir, ce qui signifiait que leurs magasins devaient être développés en premier.
 Représentation graphique de ce que nous avons ressenti avec le deuxième MVP
Représentation graphique de ce que nous avons ressenti avec le deuxième MVP
Bien que nous ayons essayé de faire une estimation correcte pour le premier MVP, nous avons dépassé son délai en raison de certains problèmes imprévus apparus en cours de route. Ainsi, lorsque nous avons été informés que le nouveau délai serait encore plus court, nous avons décidé de prendre une approche différente pour l'atteindre à temps.
Nous avons décidé de développer plus d'un magasin en même temps, ce qui était une approche à double tranchant.
D'une part, nous verrions en cours de route à quel point l'aspect réutilisabilité de notre plateforme fonctionnait bien tout en la refactorisant. Nous aurions également plus d'un magasin à la fin.
D'autre part, nous devrions configurer et maintenir les environnements et les ressources de plusieurs magasins. De plus, nous devrions implémenter leurs designs, ce qui nous ralentirait, ce qui signifie que nous pourrions ne pas atteindre le délai à temps, encore une fois.
Nous avons vu ce MVP comme une opportunité de recommencer et d'améliorer notre base de code. Nous avons donc ajouté TypeScript et Styled-Components à notre application React.
Je dois admettre que j'étais très heureux lorsque nous avons fait ces choix car j'avais travaillé avec cette pile sur mes propres projets. Maintenant, j'étais en mesure d'en apprendre davantage et de devenir encore meilleur.
Heureusement, nous avons pu réutiliser la plupart du code du MVP précédent pour les applications React et les services backend. Mais tout n'était pas un lit de roses.
Nous n'étions pas tous habitués à travailler avec cette nouvelle pile et cela nous a ralentis au début. De plus, avec la même pile, nous avons commencé à développer une bibliothèque de composants React pour toutes les plateformes, qui, bien qu'elle ait été prévue pour le premier MVP, n'a jamais vu le jour.
À cette époque, l'équipe en charge du service d'authentification des utilisateurs a commencé à travailler dessus, donc nous avons arrêté son développement et l'avons simplement implémenté sur le site.
De plus, nous avons commencé le développement d'un service de recherche de produits (search-api-service) avec Azure Cognitive Search.
Après tous les changements mentionnés ci-dessus, l'architecture a évolué de cette manière.
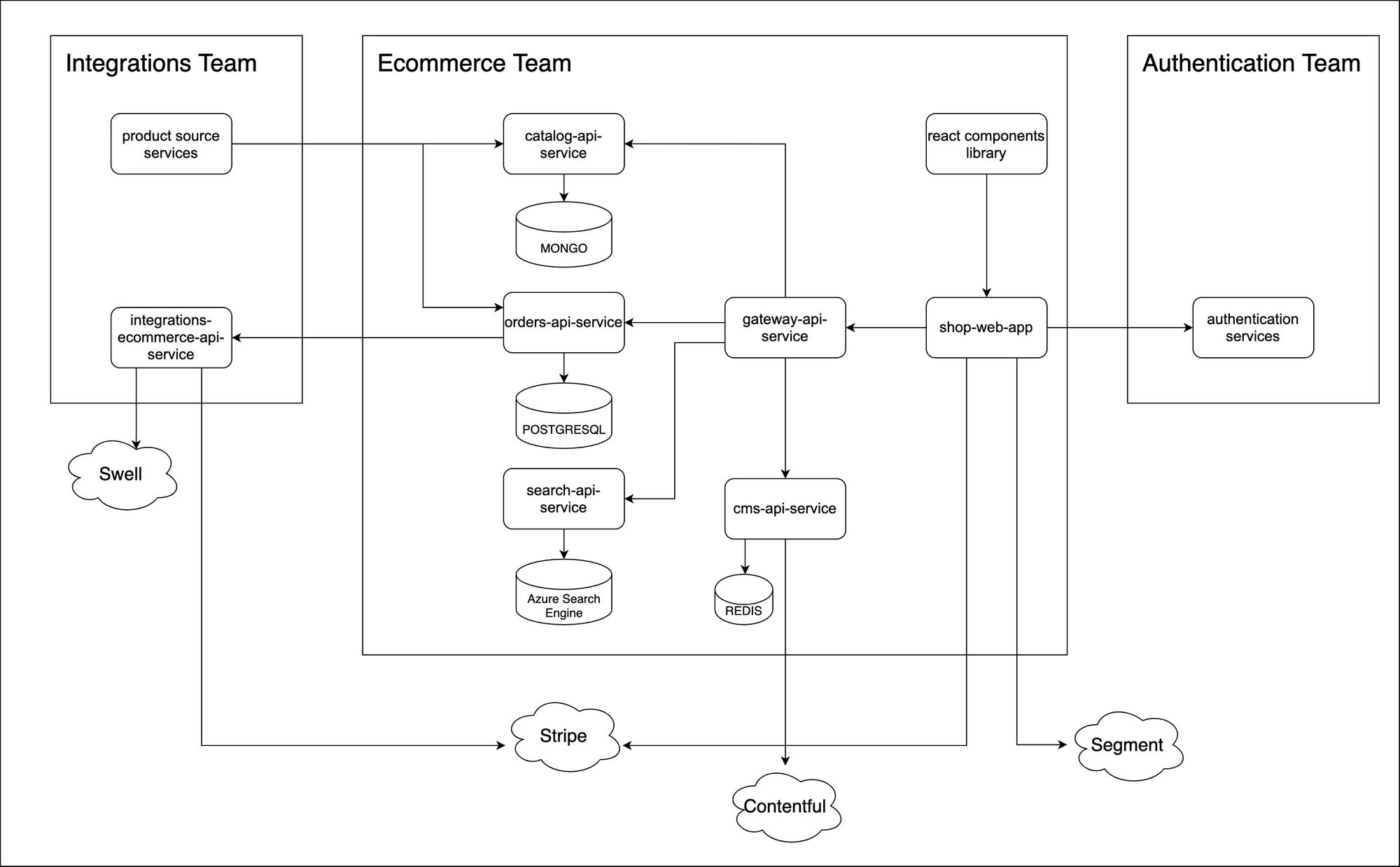 Architecture du deuxième MVP
Architecture du deuxième MVP
Conclusion et leçons apprises
Alors que j'écris ceci, la plateforme n'est pas encore terminée. Mais ce fut un grand défi d'en arriver là où nous en sommes.
Nous avons appris des leçons précieuses qui peuvent être utiles aux autres, non seulement sur la pile technologique et l'architecture décrites ci-dessus, mais aussi sur la manière dont nous avons travaillé en équipe.
Innover la pile technologique
Travailler avec de nouvelles technologies peut être risqué et moins confortable que de rester avec des technologies anciennes et bien connues. Mais l'innovation et l'adaptabilité sont la bonne voie à suivre pour ne pas être laissé pour compte dans le développement logiciel.
L'un des points les plus importants lorsque vous mettez à niveau votre pile technologique ou en adoptez une nouvelle, en plus de vérifier la bonne manière de le faire en suivant les normes, est de s'assurer que l'équipe est à l'aise de travailler avec, non seulement au début, mais pendant tout le processus pour faciliter la transition.
Ne pas sous-estimer, promettre moins, livrer plus
Nous avons estimé avec enthousiasme le premier MVP et convenu de livrer un grand nombre de fonctionnalités. Nous avons fini par avoir besoin de plus de temps en raison de tous les problèmes qui sont apparus en cours de route et avons dû apprendre à dire « non » parfois.
Pour le deuxième MVP, nous n'avons pas estimé aussi loin dans le temps et ne nous sommes pas engagés à des fonctionnalités dont nous n'étions pas sûrs de pouvoir livrer dans le temps imparti.
Grâce à cela, nous avons pu travailler moins stressés, avoir une meilleure humeur, livrer un meilleur code et améliorer les sentiments du client à propos du projet, car ils n'étaient pas déçus par les progrès.
Travail d'équipe au sein de l'équipe
Nous avons réalisé que la meilleure façon de progresser et de se développer était de se sentir à l'aise – non seulement avec les technologies, mais surtout avec nos coéquipiers. Certaines des mesures qui ont amélioré notre relation et notre travail d'équipe étaient :
Démocratie d'équipe
Peu importe le travail que nous faisions à ce moment-là, nous avions tous la même voix et notre opinion comptait autant lors de la prise de décision. Cela a été clé lorsque nous avons discuté de l'adoption de la nouvelle pile technologique et des pratiques que nous allions suivre.
Révision du code
Le feedback est l'un des meilleurs moyens de s'améliorer, non seulement le code lui-même, mais aussi la manière dont vous l'écrivez. C'est pourquoi nous avons décidé de travailler avec les Pull Requests de GitHub pour implémenter la plupart des fonctionnalités.
Travailler avec elles a non seulement amélioré notre base de code, mais nous a également permis de savoir comment les fonctionnalités étaient implémentées dans d'autres domaines, évitant ainsi les réunions de rattrapage et nous aidant à suivre l'ensemble du périmètre du projet.
Nous avons affiné ce système peu à peu avec des fonctionnalités comme un nombre minimum de relecteurs pour les fusionner ou s'y abonner via Slack.
Aider et demander de l'aide
À mon avis, c'est un must. L'équipe doit perdre la peur de demander de l'aide si elle est bloquée. En même temps, elle doit être prête à aider les autres lorsqu'ils en font la demande.
Je suis heureux de dire que nous avons pu atteindre cet équilibre et notre travail s'est amélioré à bien des égards. Le point suivant, le pair programming, a été clé pour perdre la peur de demander de l'aide et pour mieux se connaître.
Pair programming autant que possible
À ce stade du développement logiciel, les avantages du pair programming sont assez bien connus. Nous avons fait du pair programming non seulement pour livrer les fonctionnalités plus rapidement et de meilleure manière, mais aussi pour apprendre des méthodes de codage des autres.
Chaque semaine, nous décisions des tâches de pair programming et des coéquipiers pour les implémenter. Mais si quelqu'un avait besoin ou voulait faire du pair programming, nous demandions simplement et quelques instants après, un coéquipier proposait son aide.
Prêter attention aux feedbacks
Les rétrospectives de sprint étaient le moment parfait pour passer en revue toutes les choses qui se sont bien passées, celles qui se sont mal passées, pour proposer des changements et pour envisager des améliorations. Par conséquent, plus nous partagions nos opinions, plus nous pouvions aborder et résoudre de problèmes.

Travail d'équipe avec d'autres partenaires
Nous dépendions du travail d'autres équipes – donc avoir une bonne relation avec elles était également un point important dans notre processus de développement.
La communication était le point clé : plus nous communiquions, plus nous nous améliorions. Et grâce à cela, notre objectif était de former une seule équipe. Voici quelques actions que nous avons suivies afin d'améliorer cette communication :
- Avoir un espace privé rien que pour nous. Nous avons créé un canal séparé pour parler des progrès et résoudre toute question ou doute dès que possible sans réunions supplémentaires.
- Réunions rapides. Une réunion par semaine fonctionnait bien pour vérifier les progrès sur les principaux problèmes. Mais nous n'attendions pas toujours cette réunion, et avions un appel rapide chaque fois qu'un problème devait être discuté.
- Rester informé des progrès globaux. Nous avions un coéquipier de notre équipe assistant à leurs stand-ups quotidiens et l'un d'eux aux nôtres qui mettait à jour le reste de l'équipe si nécessaire.
Voici quelques images réelles de nous et de l'équipe des intégrations :

Faire sentir le client comme faisant partie de l'équipe
Au début du premier MVP, il y avait trop d'indices et trop peu de communication pour les clarifier, donc nous étions parfois bloqués ou devions organiser des réunions chronophages pour ces problèmes.
Le cœur du problème, comme la plupart des problèmes dans la vie, était un manque de communication. Nous l'avons donc résolu en augmentant notre communication, en posant des questions directement au client, en les invitant aux rétrospectives, aux stand-ups quotidiens et à d'autres réunions même lorsqu'ils n'étaient pas requis.
Cela a aidé à tenir le client informé autant que possible. En fin de compte, plus nous communiquions, plus nous les faisions sentir comme faisant partie de l'équipe, et mieux nous travaillions ensemble.
Réflexions finales
Je tiens d'abord à remercier mes coéquipiers. Ce fut un plaisir de travailler avec eux, de commencer chaque jour avec enthousiasme pour s'amuser ensemble en développant le projet.
Sur le même plan, merci aux coéquipiers des autres équipes qui ont toujours donné un coup de main lorsque cela était demandé.
Je suis également reconnaissant pour l'opportunité de participer à l'implémentation complète de bout en bout du projet, d'où j'ai tant appris. J'ai résolu des problèmes sur le Front, le Back et le DevOps, tels que la configuration des environnements, des pipelines, la messagerie entre les services, la persistance et la récupération des données, leur service au frontend, et l'implémentation des interfaces pour les afficher.
Enfin, je suis reconnaissant d'avoir eu la chance de travailler et de me perfectionner sur des technologies que j'utilisais sur des projets parallèles comme GraphQL ou TypeScript.
J'espère que vous avez apprécié cet article. Vous pouvez également le lire sur mon site ainsi que d'autres ! Si vous avez des questions, des suggestions ou des commentaires en général, n'hésitez pas à me contacter sur l'un des réseaux sociaux de mon site.