


Article original : How to Develop an End-to-End Machine Learning Project and Deploy it to Heroku with Flask
Il y a une question que l'on me pose toujours concernant la Data Science :
Quelle est la meilleure façon de maîtriser la Data Science ? Qu'est-ce qui me fera embaucher ?
Ma réponse reste constante : il n'y a pas d'alternative à travailler sur des projets dignes d'un portfolio.
Même après avoir réussi l'examen du Certificat de Développeur TensorFlow, je dirais que vous ne pouvez vraiment prouver votre compétence qu'avec des projets qui mettent en valeur vos recherches, vos compétences en programmation, votre formation mathématique, et ainsi de suite.
Dans mon article comment construire un portfolio de Data Science efficace, j'ai partagé de nombreuses idées de projets et d'autres conseils pour préparer un portfolio impressionnant. Cet article est dédié à l'une de ces idées : construire un projet de data science/ML de bout en bout.
Agenda
Ce tutoriel est destiné à vous guider à travers toutes les étapes majeures impliquées dans la réalisation d'un projet de Machine Learning de bout en bout. Pour ce projet, j'ai choisi un problème de régression d'apprentissage supervisé.
Voici les principaux sujets abordés :
Prérequis et Ressources
Collecte de données et Énoncé du problème
Analyse exploratoire des données avec Pandas et NumPy
Préparation des données avec Sklearn
Sélection et Entraînement de quelques modèles de Machine Learning
Validation croisée et Réglage des hyperparamètres avec Sklearn
Déploiement du Modèle Final Entraîné sur Heroku via une Application Flask
Commençons à construire...
Prérequis et Ressources
Pour suivre ce projet et ce tutoriel, vous devez être familier avec les algorithmes de Machine Learning, la configuration de l'environnement Python et les terminologies courantes en ML. Voici quelques ressources pour vous aider à démarrer :
Lisez les 2-3 premiers chapitres du livre de ML de cent pages : http://themlbook.com/wiki/doku.php
Liste des tâches pour presque tous les projets de Machine Learning — Continuez à vous référer à cette liste tout en travaillant sur ce projet (ou tout autre) de ML.
Vous avez besoin d'un environnement Python configuré — un environnement virtuel dédié à ce projet.
Vous devez être familier avec Jupyter Notebook.
C'est tout, alors assurez-vous de bien comprendre ces concepts et outils et vous êtes prêt à partir !
Collecte de données et Énoncé du problème

La première étape est de mettre la main sur les données. Mais si vous avez accès aux données (comme la plupart des entreprises basées sur des produits), alors la première étape est de définir le problème que vous souhaitez résoudre. Nous n'avons pas encore les données, donc nous allons d'abord collecter les données.
Nous utilisons le jeu de données Auto MPG du UCI Machine Learning Repository. Voici le lien vers le jeu de données :
Les données concernent la consommation de carburant en ville en miles par gallon, à prédire en termes de 3 attributs discrets multivalués et 5 attributs continus.
Une fois que vous avez téléchargé les données, déplacez-les dans votre répertoire de projet, activez votre virtualenv et démarrez le serveur local Jupyter.
Vous pouvez également télécharger les données dans votre projet à partir du notebook en utilisant wget :
!wget "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data"

L'étape suivante consiste à charger ce fichier .data dans un datagramme pandas. Pour cela, assurez-vous d'avoir installé pandas et d'autres bibliothèques d'usage général. Importez toutes les bibliothèques d'usage général comme suit :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
Ensuite, lisez et chargez le fichier dans un dataframe en utilisant la méthode read_csv() :
# définition des noms de colonnes
cols = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']
# lecture du fichier .data en utilisant pandas
df = pd.read_csv('./auto-mpg.data', names=cols, na_values = "?",
comment = '\t',
sep= " ",
skipinitialspace=True)
# création d'une copie du dataframe
data = df.copy()
Ensuite, regardez quelques lignes du dataframe et lisez la description de chaque attribut sur le site web. Cela vous aide à définir l'énoncé du problème.
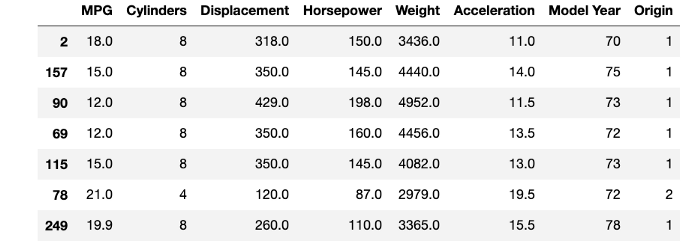
Énoncé du problème — Les données contiennent la variable MPG (Miles Per Gallon) qui est une donnée continue et nous informe sur l'efficacité de la consommation de carburant d'un véhicule dans les années 70 et 80.
Notre objectif ici est de prédire la valeur MPG pour un véhicule, étant donné que nous avons d'autres attributs de ce véhicule.
Analyse exploratoire des données avec Pandas et NumPy
Pour ce jeu de données plutôt simple, l'exploration est divisée en une série d'étapes :
Vérification du type de données des colonnes
## vérification des informations sur les données
data.info()
Vérification des valeurs nulles.
## vérification de toutes les valeurs nulles
data.isnull().sum()

La colonne horsepower a 6 valeurs manquantes. Nous devons étudier un peu plus cette colonne.
Vérification des valeurs aberrantes dans la colonne horsepower
## statistiques récapitulatives des variables quantitatives
data.describe()
## visualisation du box plot de la puissance
sns.boxplot(x=data['Horsepower'])
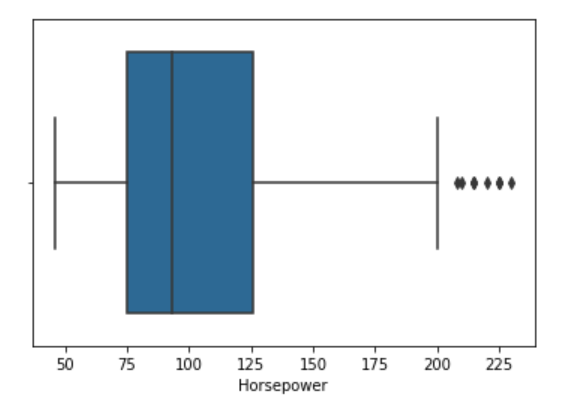
Puisqu'il y a quelques valeurs aberrantes, nous pouvons utiliser la médiane de la colonne pour imputer les valeurs manquantes en utilisant la méthode median() de pandas.
## imputation des valeurs avec la médiane
median = data['Horsepower'].median()
data['Horsepower'] = data['Horsepower'].fillna(median)
data.info()
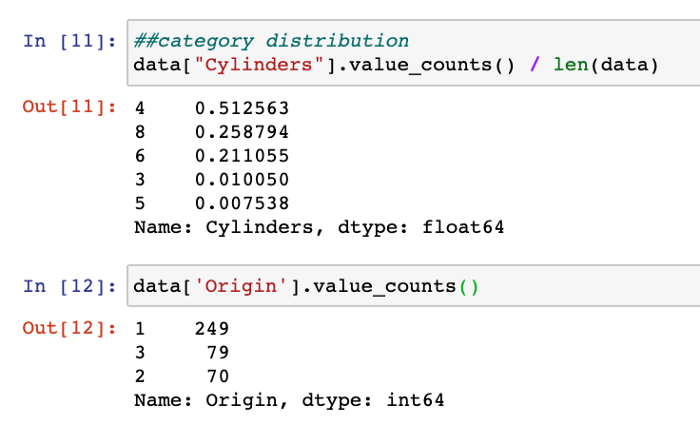
Recherche de la distribution des catégories dans les colonnes catégorielles
## distribution des catégories
data["Cylinders"].value_counts() / len(data)
data['Origin'].value_counts()
Les 2 colonnes catégorielles sont Cylinders et Origin, qui n'ont que quelques catégories de valeurs. Regarder la distribution des valeurs parmi ces catégories nous dira comment les données sont distribuées :
Tracé pour la corrélation
## pairplots pour obtenir une intuition des corrélations potentielles
sns.pairplot(data[["MPG", "Cylinders", "Displacement", "Weight", "Horsepower"]], diag_kind="kde")
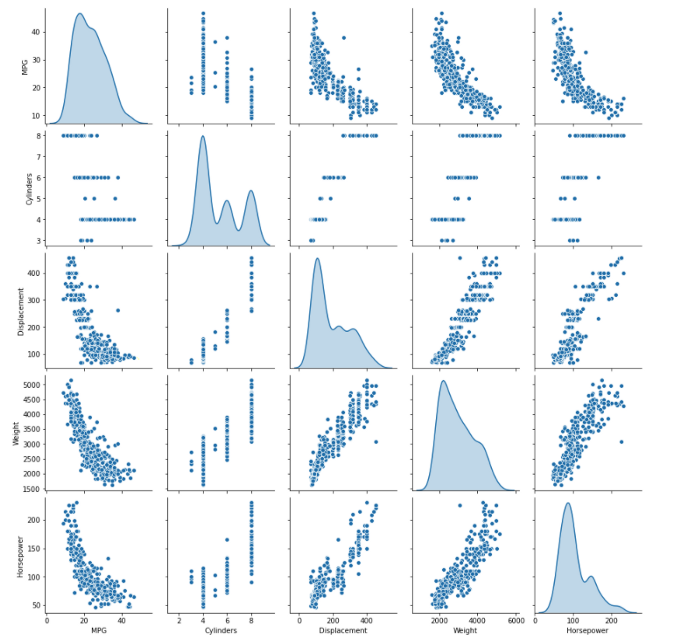
Le pair plot vous donne un aperçu rapide de la façon dont chaque variable se comporte par rapport à toutes les autres variables.
Par exemple, la colonne MPG (notre variable cible) est négativement corrélée avec les caractéristiques de déplacement, de poids et de puissance.
Mise de côté de l'ensemble de données de test
C'est l'une des premières choses que nous devrions faire, car nous voulons tester notre modèle final sur des données non vues/non biaisées.
Il existe de nombreuses façons de diviser les données en ensembles d'entraînement et de test, mais nous voulons que notre ensemble de test représente la population globale et non seulement quelques catégories spécifiques. Ainsi, au lieu d'utiliser la méthode simple et courante train_test_split() de sklearn, nous utilisons l'échantillonnage stratifié.
Échantillonnage stratifié — Nous créons des sous-groupes homogènes appelés strates à partir de la population globale et échantillonnons le bon nombre d'instances pour chaque strate afin de garantir que l'ensemble de test est représentatif de la population globale.
Dans la tâche 4, nous avons vu comment les données sont distribuées sur chaque catégorie de la colonne Cylinder. Nous utilisons la colonne Cylinder pour créer les strates :
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(data, data["Cylinders"]):
strat_train_set = data.loc[train_index]
strat_test_set = data.loc[test_index]
Vérification de la distribution dans l'ensemble d'entraînement :
## vérification de la distribution des catégories de cylindres dans l'ensemble d'entraînement
strat_train_set['Cylinders'].value_counts() / len(strat_train_set)

Ensemble de test :
strat_test_set["Cylinders"].value_counts() / len(strat_test_set)

Vous pouvez comparer ces résultats avec la sortie de train_test_split() pour découvrir laquelle produit les meilleures divisions.
Vérification de la colonne Origin
La colonne Origin concernant l'origine du véhicule a des valeurs discrètes qui ressemblent au code d'un pays.
Pour ajouter une complication et la rendre plus explicite, j'ai converti ces nombres en chaînes de caractères :
## conversion des classes entières en pays dans Origin
columntrain_set['Origin'] = train_set['Origin'].map({1: 'India', 2: 'USA', 3 : 'Germany'})
train_set.sample(10)
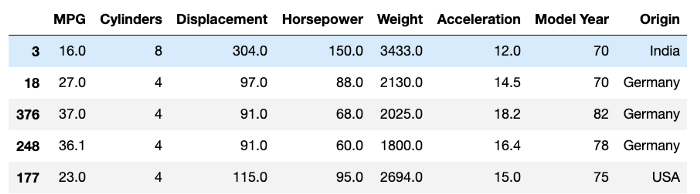
Nous devons pré-traiter cette colonne catégorielle en encodant ces valeurs avec un encodage one-hot :
## encodage one-hot
train_set = pd.get_dummies(train_set, prefix='', prefix_sep='')
train_set.head()

Test pour de nouvelles variables — Analyse de la corrélation de chaque variable avec la variable cible
## test de nouvelles variables en vérifiant leur corrélation par rapport à MPG
data['displacement_on_power'] = data['Displacement'] / data['Horsepower']
data['weight_on_cylinder'] = data['Weight'] / data['Cylinders']
data['acceleration_on_power'] = data['Acceleration'] / data['Horsepower']
data['acceleration_on_cyl'] = data['Acceleration'] / data['Cylinders']
corr_matrix = data.corr()
corr_matrix['MPG'].sort_values(ascending=False)
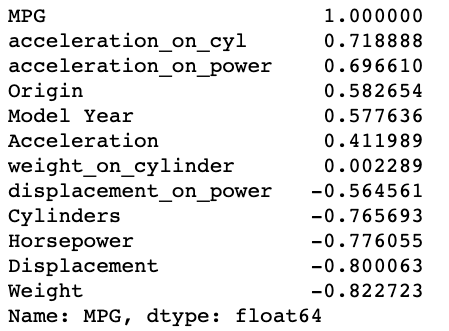
Nous avons trouvé acceleration_on_power et acceleration_on_cyl comme deux nouvelles variables qui se sont avérées plus positivement corrélées que les variables originales.
Cela nous amène à la fin de l'analyse exploratoire. Nous sommes prêts à passer à l'étape suivante de préparation des données pour le Machine Learning.
Préparation des données avec Sklearn
L'un des aspects les plus importants de la préparation des données est que nous devons continuer à automatiser nos étapes sous forme de fonctions et de classes. Cela nous facilite l'intégration des méthodes et des pipelines dans le produit principal.
Voici les principales tâches pour préparer les données et encapsuler les fonctionnalités :
Prétraitement de l'attribut catégoriel — Conversion de l'Oval
## encodage one-hot des valeurs catégorielles
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
data_cat_1hot = cat_encoder.fit_transform(data_cat)
data_cat_1hot # retourne une matrice creuse
data_cat_1hot.toarray()[:5]

Nettoyage des données — Imputer
Nous allons utiliser la classe SimpleImputer du module impute de la bibliothèque Sklearn :
## gestion des valeurs manquantes
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")imputer.fit(num_data)
Ajout d'attributs — Ajout de transformation personnalisée
Afin d'apporter des modifications aux ensembles de données et de créer de nouvelles variables, sklearn offre la classe BaseEstimator. En l'utilisant, nous pouvons développer de nouvelles fonctionnalités en définissant notre propre classe.
Nous avons créé une classe pour ajouter deux nouvelles fonctionnalités comme trouvé dans l'étape EDA ci-dessus :
acc_on_power — Accélération divisée par la puissance
acc_on_cyl — Accélération divisée par le nombre de cylindres
from sklearn.base import BaseEstimator, TransformerMixin
acc_ix, hpower_ix, cyl_ix = 4, 2, 0
## classe personnalisée héritant de BaseEstimator et TransformerMixin
class CustomAttrAdder(BaseEstimator, TransformerMixin):
def __init__(self, acc_on_power=True):
self.acc_on_power = acc_on_power # nouvelle variable optionnelle
def fit(self, X, y=None):
return self # rien d'autre à faire
def transform(self, X):
acc_on_cyl = X[:, acc_ix] / X[:, cyl_ix] # nouvelle variable requise
if self.acc_on_power:
acc_on_power = X[:, acc_ix] / X[:, hpower_ix]
return np.c_[X, acc_on_power, acc_on_cyl] # retourne un tableau 2D
return np.c_[X, acc_on_cyl]
attr_adder = CustomAttrAdder(acc_on_power=True)
data_tr_extra_attrs = attr_adder.transform(data_tr.values)
data_tr_extra_attrs[0]
Configuration du pipeline de transformation des données pour les attributs numériques et catégoriques
Comme je l'ai dit, nous voulons automatiser autant que possible. Sklearn offre un grand nombre de classes et de méthodes pour développer de tels pipelines automatisés de transformations de données.
Les principales transformations doivent être effectuées sur les colonnes numériques, alors créons le pipeline numérique en utilisant la classe Pipeline :
def num_pipeline_transformer(data):
'''
Fonction pour traiter les transformations numériques
Argument :
data: dataframe original
Retourne :
num_attrs: dataframe numérique
num_pipeline: objet pipeline numérique
'''
numerics = ['float64', 'int64']
num_attrs = data.select_dtypes(include=numerics)
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attrs_adder', CustomAttrAdder()),
('std_scaler', StandardScaler()),
])
return num_attrs, num_pipeline
Dans l'extrait de code ci-dessus, nous avons cascadé un ensemble de transformations :
Imputation des valeurs manquantes — en utilisant la classe
SimpleImputerdiscutée ci-dessus.Ajout d'attributs personnalisés — en utilisant la classe d'attributs personnalisée définie ci-dessus.
Mise à l'échelle standard de chaque attribut — toujours une bonne pratique de mettre à l'échelle les valeurs avant de les alimenter dans le modèle ML, en utilisant la classe
standardScaler.
Pipeline combiné pour les colonnes numériques et catégoriques
Nous avons la transformation numérique prête. La seule colonne catégorielle que nous avons est Origin pour laquelle nous devons encoder les valeurs en one-hot.
Voici comment nous pouvons utiliser la classe ColumnTransformer pour capturer ces deux tâches en une seule fois.
def pipeline_transformer(data):
'''
Pipeline de transformation complet pour les données
numériques et catégorielles.
Argument :
data: dataframe original
Retourne :
prepared_data: données transformées, prêtes à l'emploi
'''
cat_attrs = ["Origin"]
num_attrs, num_pipeline = num_pipeline_transformer(data)
full_pipeline = ColumnTransformer([
("num", num_pipeline, list(num_attrs)),
("cat", OneHotEncoder(), cat_attrs),
])
prepared_data = full_pipeline.fit_transform(data)
return prepared_data
À l'instance, fournissez l'objet pipeline numérique créé à partir de la fonction définie ci-dessus. Ensuite, appelez la classe OneHotEncoder() pour traiter la colonne Origin.
Automatisation finale
Avec ces classes et fonctions définies, nous devons maintenant les intégrer dans un seul flux qui va être simplement deux appels de fonction.
- Prétraitement de la colonne Origin pour convertir les entiers en noms de pays :
## prétraitement de la colonne Origin dans les données
def preprocess_origin_cols(df):
df["Origin"] = df["Origin"].map({1: "India", 2: "USA", 3: "Germany"})
return df
- Appel de la fonction finale
pipeline_transformerdéfinie ci-dessus :
## des données brutes aux données traitées en 2 étapes
preprocessed_df = preprocess_origin_cols(data)
prepared_data = pipeline_transformer(preprocessed_df)prepared_data
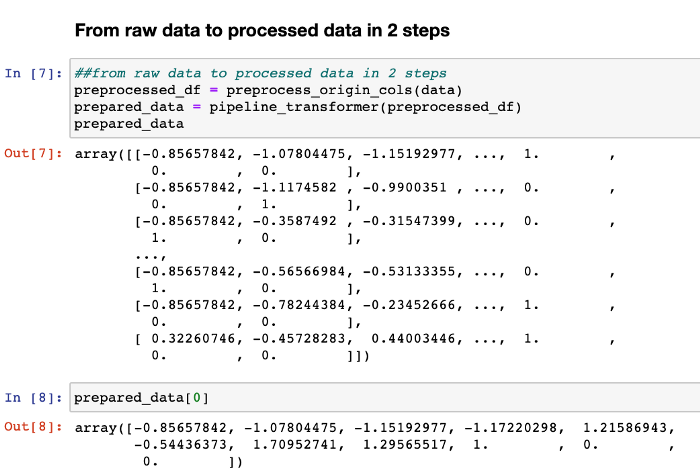
Voilà, vos données sont prêtes à être utilisées en seulement deux étapes !
L'étape suivante est de commencer à entraîner nos modèles ML.
Sélection et Entraînement de Modèles de Machine Learning
Puisque c'est un problème de régression, j'ai choisi d'entraîner les modèles suivants :
Régression Linéaire
Arbre de Décision Régressif
Forêt Aléatoire Régressif
Régressif SVM
Je vais expliquer le flux pour la Régression Linéaire et ensuite vous pouvez suivre le même pour tous les autres.
C'est un processus simple en 4 étapes :
Créer une instance de la classe de modèle.
Entraîner le modèle en utilisant la méthode fit().
Faire des prédictions en passant d'abord les données par le transformateur de pipeline.
Évaluer le modèle en utilisant l'erreur quadratique moyenne (métrique de performance typique pour les problèmes de régression)
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(prepared_data, data_labels)
## test des prédictions avec les 5 premières lignes
sample_data = data.iloc[:5]
sample_labels = data_labels.iloc[:5]
sample_data_prepared = pipeline_transformer(sample_data)
print("Prédiction des échantillons : ", lin_reg.predict(sample_data_prepared))
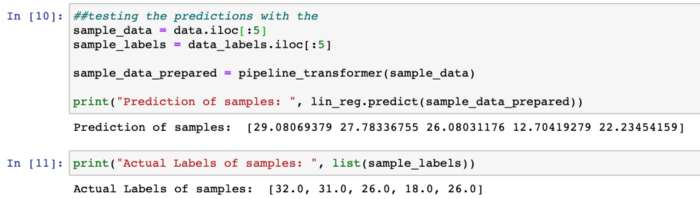
Évaluation du modèle :
from sklearn.metrics import mean_squared_error
mpg_predictions = lin_reg.predict(prepared_data)
lin_mse = mean_squared_error(data_labels, mpg_predictions)
lin_rmse = np.sqrt(lin_mse)lin_rmse
RMSE pour la régression linéaire : 2.95904
Validation Croisée et Réglage des Hyperparamètres avec Sklearn
Maintenant, si vous effectuez la même chose pour l'arbre de décision, vous verrez que vous avez obtenu une valeur RMSE de 0.0, ce qui n'est pas possible — il n'existe pas de modèle de Machine Learning "parfait" (nous n'avons pas encore atteint ce point).
Problème : nous testons notre modèle sur les mêmes données sur lesquelles nous l'avons entraîné, ce qui pose un problème. Maintenant, nous ne pouvons pas encore utiliser les données de test jusqu'à ce que nous finalisions notre meilleur modèle prêt à être mis en production.
Solution : Validation Croisée
La fonctionnalité de validation croisée K-fold de Scikit-Learn divise aléatoirement l'ensemble d'entraînement en K sous-ensembles distincts appelés folds. Ensuite, elle entraîne et évalue le modèle K fois, en choisissant un fold différent pour l'évaluation à chaque fois et en s'entraînant sur les autres K-1 folds.
Le résultat est un tableau contenant les K scores d'évaluation. Voici comment je l'ai fait pour 10 folds :
from sklearn.model_selection import cross_val_score
scores = cross_val_score(tree_reg,
prepared_data,
data_labels,
scoring="neg_mean_squared_error",
cv = 10)
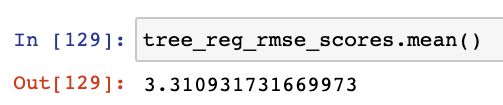
tree_reg_rmse_scores = np.sqrt(-scores)
La méthode de scoring vous donne des valeurs négatives pour désigner les erreurs. Donc, lors du calcul de la racine carrée, nous devons ajouter la négation explicitement.
Pour l'arbre de décision, voici la liste de tous les scores :

Prenez la moyenne de ces scores :
Réglage des Hyperparamètres
Après avoir testé tous les modèles, vous constaterez que RandomForestRegressor a donné les meilleurs résultats, mais il doit encore être affiné.
Un modèle est comme une station de radio avec beaucoup de boutons à manipuler et à régler. Maintenant, vous pouvez soit régler tous ces boutons manuellement, soit fournir une plage de valeurs/combinaisons que vous souhaitez tester.
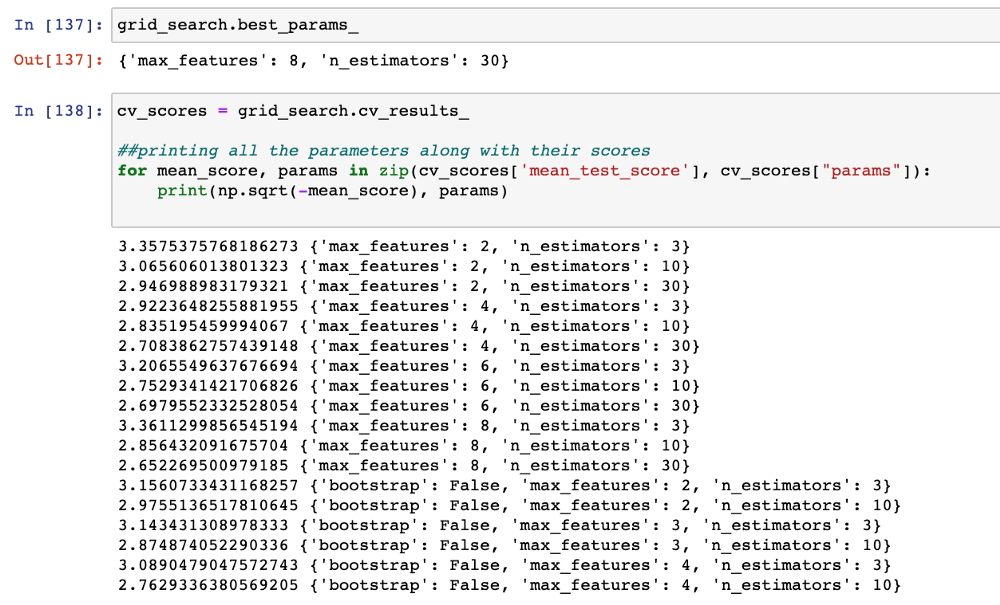
Nous utilisons GridSearchCV pour trouver la meilleure combinaison d'hyperparamètres pour le modèle RandomForest :
from sklearn.model_selection import GridSearchCV
param_grid = [
{'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]},
{'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]},
]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg, param_grid,
scoring='neg_mean_squared_error',
return_train_score=True,
cv=10,
)
grid_search.fit(prepared_data, data_labels)
GridSearchCV vous demande de passer la grille de paramètres. Il s'agit d'un dictionnaire Python avec les noms des paramètres comme clés mappées avec la liste des valeurs que vous souhaitez tester pour ce paramètre.
Nous pouvons passer le modèle, la méthode de scoring et les folds de validation croisée.
Entraînez le modèle et il retourne les meilleurs paramètres et résultats pour chaque combinaison de paramètres :
Vérification de l'importance des caractéristiques
Nous pouvons également vérifier l'importance des caractéristiques en listant les caractéristiques et en les associant avec l'attribut d'importance des caractéristiques du meilleur estimateur comme suit :
# importances des caractéristiques
feature_importances = grid_search.best_estimator_.feature_importances_
extra_attrs = ["acc_on_power", "acc_on_cyl"]
numerics = ['float64', 'int64']
num_attrs = list(data.select_dtypes(include=numerics))
attrs = num_attrs + extra_attrs
sorted(zip(attrs, feature_importances), reverse=True)

Nous voyons que acc_on_power, qui est la caractéristique dérivée, s'est avérée être la caractéristique la plus importante.
Vous pourriez vouloir itérer quelques fois avant de finaliser la meilleure configuration.
Le modèle est maintenant prêt avec la meilleure configuration.
Évaluation de l'ensemble du système
Il est temps d'évaluer l'ensemble de ce système :
## capture de la meilleure configuration
final_model = grid_search.best_estimator_
## séparation de la variable cible de l'ensemble de test
X_test = strat_test_set.drop("MPG", axis=1)
y_test = strat_test_set["MPG"].copy()
## prétraitement de la colonne d'origine des données de test
X_test_preprocessed = preprocess_origin_cols(X_test)
## préparation des données avec la transformation finale
X_test_prepared = pipeline_transformer(X_test_preprocessed)
## réalisation des prédictions finales
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)

Si vous souhaitez consulter mon projet complet, voici le dépôt GitHub :
Avec cela, vous avez votre modèle final prêt à être mis en production.
Pour le déploiement, nous sauvegardons notre modèle dans un fichier en utilisant le modèle pickle et développons un service web Flask à déployer sur Heroku. Voyons comment cela fonctionne maintenant.
De quoi avez-vous besoin pour déployer l'application ?
Pour déployer un modèle entraîné, vous avez besoin des éléments suivants :
Un modèle entraîné prêt à être déployé — sauvegardez le modèle dans un fichier pour qu'il soit chargé et utilisé par le service web.
Un service web — qui donne un but à votre modèle pour être utilisé en pratique. Pour notre modèle de consommation de carburant, cela peut être l'utilisation de la configuration du véhicule pour prédire son efficacité. Nous allons utiliser Flask pour développer ce service.
Un fournisseur de services cloud — vous avez besoin de serveurs cloud spécifiques pour déployer l'application. Pour simplifier, nous allons utiliser Heroku pour cela (je couvrirai AWS et GCP dans d'autres articles).
Commençons par examiner chacun de ces processus un par un.
Sauvegarde du modèle entraîné
Une fois que vous êtes suffisamment confiant pour emmener votre modèle entraîné et testé dans un environnement prêt pour la production, la première étape consiste à le sauvegarder dans un fichier .h5 ou .bin en utilisant une bibliothèque comme pickle.
Assurez-vous d'avoir pickle installé dans votre environnement.
Ensuite, importons le module et sauvegardons le modèle dans un fichier .bin :
import pickle
## sauvegarde du modèle dans un fichier
with open("model.bin", 'wb') as f_out:
pickle.dump(final_model, f_out) # écrit final_model dans le fichier .bin
f_out.close() # ferme le fichier
Cela sauvegardera votre modèle dans votre répertoire de travail actuel, sauf si vous spécifiez un autre chemin.
Il est temps de tester si nous sommes capables d'utiliser ce fichier pour charger notre modèle et faire des prédictions. Nous allons utiliser la même configuration de véhicule que nous avons définie ci-dessus :
## configuration du véhicule
vehicle_config = {
'Cylinders': [4, 6, 8],
'Displacement': [155.0, 160.0, 165.5],
'Horsepower': [93.0, 130.0, 98.0],
'Weight': [2500.0, 3150.0, 2600.0],
'Acceleration': [15.0, 14.0, 16.0],
'Model Year': [81, 80, 78],
'Origin': [3, 2, 1]
}
Chargeons le modèle à partir du fichier :
## chargement du modèle à partir du fichier sauvegardé
with open('model.bin', 'rb') as f_in:
model = pickle.load(f_in)
Faisons des prédictions sur vehicle_config :
## défini dans prev_blog
predict_mpg(vehicle_config, model)
## sortie : array([34.83333333, 18.50666667, 20.56333333])
La sortie est la même que celle que nous avons prédite précédemment en utilisant final_model.
Développement d'un service web
L'étape suivante consiste à empaqueter ce modèle dans un service web qui, lorsqu'il reçoit les données via une requête POST, retourne les prédictions MPG (Miles per Gallon) en réponse.
J'utilise le framework web Flask, un framework léger couramment utilisé pour développer des services web en Python. À mon avis, c'est probablement le moyen le plus simple de mettre en œuvre un service web.
Flask vous permet de démarrer avec très peu de code et vous n'avez pas à vous soucier de la complexité de la gestion des requêtes et réponses HTTP.
Voici les étapes :
Créez un nouveau répertoire pour votre application Flask.
Configurez un environnement dédié avec les dépendances installées en utilisant pip.
Installez les packages suivants :
pandas
numpy
sklearn
flask
gunicorn
seaborn
L'étape suivante consiste à activer cet environnement et à commencer à développer un endpoint simple pour tester l'application :
Créez un nouveau fichier, main.py et importez le module Flask :
from flask import Flask
Créez une application Flask en instanciant la classe Flask :
## création d'une application Flask et nommez-la "app"
app = Flask('app')
Créez une route et une fonction correspondante qui retournera une simple chaîne :
@app.route('/test', methods=['GET'])
def test():
return 'Pinging Model Application!!'
Le code ci-dessus utilise des décorateurs — une fonctionnalité avancée de Python. Vous pouvez en lire plus sur les décorateurs ici.
Nous n'avons pas besoin d'une compréhension approfondie des décorateurs, juste que l'ajout d'un décorateur @app.route au-dessus de la fonction test() assigne cette adresse de service web à cette fonction.
Maintenant, pour exécuter l'application, nous avons besoin de ce dernier morceau de code :
if __name__ == 'main':
app.run(debug=True, host='0.0.0.0', port=9696)
La méthode run démarre notre service d'application Flask. Les 3 paramètres spécifient :
debug=True— redémarre l'application automatiquement lorsqu'elle rencontre un changement dans le codehost='0.0.0.0'— rend le service web publicport=9696— le port que nous utilisons pour accéder à l'application
Maintenant, dans votre terminal, exécutez main.py :
python main.py

Ouvrir l'URL http://0.0.0.0:9696/test dans votre navigateur imprimera la chaîne de réponse sur la page web :

Avec l'application maintenant en cours d'exécution, exécutons le modèle.
Créez un nouveau répertoire model_files pour stocker tout le code lié au modèle.
Dans ce répertoire, créez un fichier ml_model.py qui contiendra le code de préparation des données et la fonction de prédiction que nous avons écrite ici.
Copiez et collez les bibliothèques que vous avez importées précédemment dans l'article et les fonctions de prétraitement/transformation. Le fichier devrait ressembler à ceci :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
## fonctions
def preprocess_origin_cols(df):
df["Origin"] = df["Origin"].map({1: "India", 2: "USA", 3: "Germany"})
return df
acc_ix, hpower_ix, cyl_ix = 3, 5, 1
class CustomAttrAdder(BaseEstimator, TransformerMixin):
def __init__(self, acc_on_power=True): # pas de *args ou **kargs
self.acc_on_power = acc_on_power
def fit(self, X, y=None):
return self # rien d'autre à faire
def transform(self, X):
acc_on_cyl = X[:, acc_ix] / X[:, cyl_ix]
if self.acc_on_power:
acc_on_power = X[:, acc_ix] / X[:, hpower_ix]
return np.c_[X, acc_on_power, acc_on_cyl]
return np.c_[X, acc_on_cyl]
def num_pipeline_transformer(data):
numerics = ['float64', 'int64']
num_attrs = data.select_dtypes(include=numerics)
num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy="median")),
('attrs_adder', CustomAttrAdder()),
('std_scaler', StandardScaler()),
])
return num_attrs, num_pipeline
def pipeline_transformer(data):
cat_attrs = ["Origin"]
num_attrs, num_pipeline = num_pipeline_transformer(data)
full_pipeline = ColumnTransformer([
("num", num_pipeline, list(num_attrs)),
("cat", OneHotEncoder(), cat_attrs),
])
full_pipeline.fit_transform(data)
return full_pipeline
def predict_mpg(config, model):
if type(config) == dict:
df = pd.DataFrame(config)
else:
df = config
preproc_df = preprocess_origin_cols(df)
print(preproc_df)
pipeline = pipeline_transformer(preproc_df)
prepared_df = pipeline.transform(preproc_df)
print(len(prepared_df[0]))
y_pred = model.predict(prepared_df)
return y_pred
Dans le même répertoire, ajoutez également votre fichier model.bin sauvegardé.
Maintenant, dans le fichier main.py, nous allons importer la fonction predict_mpg pour faire des prédictions. Mais pour cela, nous devons créer un fichier __init__.py vide pour indiquer à Python que le répertoire est un package.
Votre répertoire devrait avoir cette arborescence :

Ensuite, définissez la route predict/ qui acceptera la vehicle_config d'une requête HTTP POST et retournera les prédictions en utilisant le modèle et la méthode predict_mpg().
Dans votre fichier main.py, importez d'abord :
import pickle
from flask import Flask, request, jsonify
from model_files.ml_model import predict_mpg
Ensuite, ajoutez la route predict et la fonction correspondante :
@app.route('/predict', methods=['POST'])
def predict():
vehicle = request.get_json()
print(vehicle)
with open('./model_files/model.bin', 'rb') as f_in:
model = pickle.load(f_in)
f_in.close()
predictions = predict_mpg(vehicle, model)
result = {
'mpg_prediction': list(predictions)
}
return jsonify(result)
Ici, nous n'accepterons que les requêtes POST pour notre fonction et nous avons donc methods=['POST'] dans le décorateur.
Tout d'abord, nous capturons les données (vehicle_config) de notre requête en utilisant la méthode
get_json()et les stockons dans la variable vehicle.Ensuite, nous chargeons le modèle entraîné dans la variable model à partir du fichier que nous avons dans le dossier
model_files.Maintenant, nous faisons les prédictions en appelant la fonction predict_mpg et en passant le
vehicleet lemodel.Nous créons une réponse JSON de ce tableau retourné dans la variable predictions et retournons ce JSON comme réponse de la méthode.
Nous pouvons tester cette route en utilisant Postman ou le package requests puis démarrer le serveur en exécutant main.py. Ensuite, dans votre notebook, ajoutez ce code pour envoyer une requête POST avec le vehicle_config :
import requests
url = "http://localhost:9696/predict"
r = requests.post(url, json = vehicle_config)
r.text.strip()
## sortie : '{"mpg_predictions":[34.60333333333333,19.32333333333333,14.893333333333333]}'
Super ! Maintenant, vient la dernière partie : cette même fonctionnalité devrait fonctionner lorsqu'elle est déployée sur un serveur distant.
Déploiement de l'application sur Heroku

Pour déployer cette application Flask sur Heroku, vous devez suivre ces étapes très simples :
Créez un
Procfiledans le répertoire principal — celui-ci contient la commande pour exécuter l'application sur le serveur.Ajoutez ce qui suit dans votre
Procfile:
web: gunicorn wsgi:app
Nous utilisons gunicorn (installé précédemment) pour déployer l'application :
Gunicorn est un serveur HTTP pur-Python pour les applications WSGI. Il vous permet d'exécuter toute application Python de manière concurrente en exécutant plusieurs processus Python au sein d'un seul dyno. Il offre un équilibre parfait entre performance, flexibilité et simplicité de configuration.
Maintenant, créez un fichier wsgi.py et ajoutez :
## importation de l'application depuis le fichier principal
from main import app
if __name__ == "__main__":
app.run()
Assurez-vous de supprimer le code d'exécution de main.py.
Écrivez toutes les dépendances Python dans requirements.txt.
Vous pouvez utiliser pip freeze > requirements.txt ou simplement mettre la liste des packages mentionnés ci-dessus + tout autre package que votre application utilise.
Maintenant, en utilisant le terminal,
initialisez un dépôt git vide,
ajoutez les fichiers à la zone de staging,
et commitez les fichiers dans le dépôt local :
$ git init
$ git add .
$ git commit -m "Initial Commit"
Ensuite, créez un compte Heroku si vous n'en avez pas déjà un. Ensuite, connectez-vous à l'interface de ligne de commande Heroku :
heroku login
Approuvez la connexion depuis le navigateur lorsque la page s'ouvre.
Maintenant, créez une application Flask :
heroku create <nom de votre application>
Je l'ai nommée mpg-flask-app. Cela créera une application Flask et nous donnera une URL sur laquelle l'application sera déployée.
Enfin, poussez tout votre code vers le dépôt distant Heroku :
$ git push heroku master
Et voilà ! Votre service web est maintenant déployé sur https://mpg-flask-app.herokuapp.com/predict.
Testez à nouveau l'endpoint en utilisant le package request en envoyant la même configuration de véhicule :

Avec cela, vous avez toutes les compétences majeures nécessaires pour commencer à construire des applications ML plus complexes.
Vous pouvez vous référer à mon dépôt GitHub pour ce projet.
Et vous pouvez développer ce projet entier avec moi :
Prochaines étapes
C'était encore un projet simple. Pour les prochaines étapes, je vous recommande de prendre un ensemble de données plus complexe — peut-être de choisir un problème de classification et de répéter ces tâches jusqu'au déploiement.
Consultez Data Science avec Harshit — Ma chaîne YouTube
Voici le tutoriel complet (sous forme de playlist) sur ma chaîne YouTube où vous pouvez me suivre tout en travaillant sur ce projet.
Avec cette chaîne, je prévois de lancer quelques séries couvrant tout l'espace de la science des données. Voici pourquoi vous devriez vous abonner à la chaîne :
Ces séries couvriraient tous les tutoriels de qualité requis/demandés sur chacun des sujets et sous-sujets comme les fondamentaux de Python pour la Data Science.
Explication des mathématiques et dérivations de pourquoi nous faisons ce que nous faisons en ML et Deep Learning.
Podcasts avec des Data Scientists et Ingénieurs chez Google, Microsoft, Amazon, etc., et PDG de grandes entreprises axées sur les données.
Projets et instructions pour mettre en œuvre les sujets appris jusqu'à présent. Apprenez les nouvelles certifications, Bootcamp et ressources pour réussir ces certifications comme cet examen de certificat de développeur TensorFlow par Google.
Si ce tutoriel vous a été utile, vous devriez consulter mes cours de data science et de machine learning sur Wiplane Academy. Ils sont complets mais compacts et vous aident à construire une base solide de travail à présenter.