


Article original : How to Detect Outliers in Machine Learning – 4 Methods for Outlier Detection
Avez-vous déjà entraîné un modèle de machine learning sur un ensemble de données réel ? Si oui, vous avez probablement rencontré des valeurs aberrantes.
Les valeurs aberrantes sont ces points de données qui sont significativement différents du reste de l'ensemble de données. Ce sont souvent des observations anormales qui faussent la distribution des données, et qui apparaissent en raison de saisies de données incohérentes ou d'observations erronées.
Pour s'assurer que le modèle entraîné généralise bien à la plage valide des entrées de test, il est important de détecter et de supprimer les valeurs aberrantes.
Dans ce guide, nous explorerons quelques techniques statistiques largement utilisées pour la détection et la suppression des valeurs aberrantes.
Pourquoi Devriez-Vous Détecter les Valeurs Aberrantes ?
Dans le pipeline de machine learning, le nettoyage des données et le prétraitement sont une étape importante car ils vous aident à mieux comprendre les données. Au cours de cette étape, vous traitez les valeurs manquantes, détectez les valeurs aberrantes, et plus encore.
Comme les valeurs aberrantes sont des valeurs très différentes—anormalement basses ou anormalement élevées—theur présence peut souvent fausser les résultats des analyses statistiques sur l'ensemble de données. Cela pourrait conduire à des modèles moins efficaces et moins utiles.
Mais traiter les valeurs aberrantes nécessite souvent une expertise du domaine, et aucune des techniques de détection des valeurs aberrantes ne doit être appliquée sans comprendre la distribution des données et le cas d'utilisation.
Par exemple, dans un ensemble de données de prix de maisons, si vous trouvez quelques maisons à environ 1,5 million de dollars—beaucoup plus élevé que le prix médian des maisons, elles sont probablement des valeurs aberrantes. Cependant, si l'ensemble de données contient un nombre significativement élevé de maisons à 1 million de dollars et plus—elles peuvent indiquer une tendance à la hausse des prix des maisons. Il serait donc incorrect de les étiqueter toutes comme des valeurs aberrantes. Dans ce cas, vous avez besoin de certaines connaissances dans le domaine de l'immobilier.
Le but de la détection des valeurs aberrantes est de supprimer les points—qui sont vraiment des valeurs aberrantes—afin que vous puissiez construire un modèle qui performe bien sur des données de test invisibles. Nous allons passer en revue quelques techniques qui nous aideront à détecter les valeurs aberrantes dans les données.
Comment Détecter les Valeurs Aberrantes en Utilisant l'Écart-Type
Lorsque les données, ou certaines caractéristiques de l'ensemble de données, suivent une distribution normale, vous pouvez utiliser l'écart-type des données, ou le score z équivalent pour détecter les valeurs aberrantes.
En statistiques, l'écart-type mesure la dispersion des données autour de la moyenne, et en essence, il capture à quel point les points de données sont éloignés de la moyenne.
Pour des données normalement distribuées, environ 68,2 % des données se situent dans un écart-type de la moyenne. Près de 95,4 % et 99,7 % des données se situent dans deux et trois écarts-types de la moyenne, respectivement.
Désignons l'écart-type de la distribution par σ, et la moyenne par μ.
Une approche pour la détection des valeurs aberrantes consiste à fixer la limite inférieure à trois écarts-types en dessous de la moyenne (μ - 3σ), et la limite supérieure à trois écarts-types au-dessus de la moyenne (μ + 3σ). Tout point de données qui se situe en dehors de cette plage est détecté comme une valeur aberrante.
Comme 99,7 % des données se situent généralement dans trois écarts-types, le nombre de valeurs aberrantes sera proche de 0,3 % de la taille de l'ensemble de données.
Code pour la Détection des Valeurs Aberrantes en Utilisant l'Écart-Type
Maintenant, créons un ensemble de données normalement distribué de notes d'étudiants, et effectuons une détection des valeurs aberrantes sur celui-ci.
En premier lieu, nous importerons les modules nécessaires.
import numpy as np
import pandas as pd
import seaborn as sns
Ensuite, définissons la fonction generate_scores() qui retourne un ensemble de données normalement distribué de notes d'étudiants contenant 200 enregistrements. Nous appellerons la fonction et stockerons le tableau retourné dans la variable scores_data.
def generate_scores(mean=60,std_dev=12,num_samples=200):
np.random.seed(27)
scores = np.random.normal(loc=mean,scale=std_dev,size=num_samples)
scores = np.round(scores, decimals=0)
return scores
scores_data = generate_scores()
Vous pouvez utiliser la fonction displot() de Seaborn pour visualiser la distribution des données. Dans ce cas, l'ensemble de données suit une distribution normale, comme le montre la figure ci-dessous.
sns.set_theme()
sns.displot(data=scores_data).set(title="Distribution des Notes", xlabel="Notes")

Ensuite, chargeons les données dans un DataFrame Pandas pour une analyse plus approfondie.
df_scores = pd.DataFrame(scores_data,columns=['score'])
Pour obtenir la moyenne et l'écart-type des données dans le DataFrame df_scores, vous pouvez utiliser les méthodes .mean() et .std(), respectivement.
df_scores.mean()
# Output
score 61.005
dtype: float64
df_scores.std()
# Output
score 11.854434
dtype: float64
Comme discuté précédemment, fixez la limite inférieure (lower_limit) à trois écarts-types en dessous de la moyenne, et la limite supérieure (upper_limit) à trois écarts-types au-dessus de la moyenne.
lower_limit = df_scores.mean() - 3*df_scores.std()
upper_limit = df_scores.mean() + 3*df_scores.std()
print(lower_limit)
print(upper_limit)
# Output
25.530716709142666
96.47928329085734
Maintenant que vous avez défini les limites inférieure et supérieure, vous pouvez filtrer le DataFrame df_scores pour ne conserver que les points de données dans l'intervalle [lower_limit, upper_limit], comme montré ci-dessous.
df_scores_filtered=df_scores[(df_scores['score']>lower_limit)&(df_scores['score']<upper_limit)]
print(df_scores_filtered)
# Output
score
0 75.0
1 56.0
2 67.0
3 65.0
4 63.0
.. ...
194 42.0
195 76.0
196 67.0
197 74.0
199 53.0
[198 rows x 1 columns]
D'après la sortie ci-dessus, vous pouvez voir que deux enregistrements ont été supprimés, et df_scores_filtered contient 198 enregistrements.
Comment Détecter les Valeurs Aberrantes en Utilisant le Score Z
Maintenant, explorons le concept du score z. Pour une distribution normale avec une moyenne μ et un écart-type σ, le score z pour une valeur x dans l'ensemble de données est donné par :
z = (x - μ)/σ
D'après l'équation ci-dessus, nous avons ce qui suit :
- Lorsque x = μ, la valeur du score z est 0.
- Lorsque x = μ ± 1, μ ± 2, ou μ ± 3, le score z est ± 1, ± 2, ou ± 3, respectivement.
Remarquez comment cette technique est équivalente aux scores basés sur l'écart-type que nous avions précédemment. Sous cette transformation, tous les points de données qui se situent en dessous de la limite inférieure, μ - 3*σ, se mappent maintenant à des points qui sont inférieurs à -3 sur l'échelle du score z.
De même, tous les points qui se situent au-dessus de la limite supérieure, μ + 3*σ se mappent à une valeur supérieure à 3 sur l'échelle du score z. Ainsi, [lower_limit, upper_limit] devient [-3, 3].
Utilisons cette technique sur notre ensemble de données de notes.
Code pour la Détection des Valeurs Aberrantes en Utilisant le Score Z
Calculons les scores z pour tous les points de l'ensemble de données, et ajoutons z_score comme une colonne au DataFrame df_scores.
df_scores['z_score']=(df_scores['score'] - df_scores['score'].mean())/df_scores['score'].std()
df_scores.head()
# Output
score z_score
0 75.0 1.180571
1 56.0 -0.422205
2 67.0 0.505718
3 65.0 0.337005
4 63.0 0.168291
Vous pouvez filtrer le DataFrame df_scores pour conserver les points dont les scores z sont dans la plage [-3, 3], comme montré ci-dessous. Le DataFrame filtré contient 198 enregistrements, comme prévu.
df_scores_filtered= df_scores[(df_scores['z_score']>-3) & (df_scores['z_score']<3)]
print(df_scores_filtered)
# Output
score z_score
0 75.0 1.180571
1 56.0 -0.422205
2 67.0 0.505718
3 65.0 0.337005
4 63.0 0.168291
.. ... ...
194 42.0 -1.603198
195 76.0 1.264928
196 67.0 0.505718
197 74.0 1.096214
199 53.0 -0.675275
[198 rows x 2 columns]
Les méthodes impliquant l'écart-type et les scores z ne peuvent être utilisées que lorsque l'ensemble de données, ou la caractéristique que vous examinez, suit une distribution normale.
Ensuite, nous discuterons de deux techniques de détection des valeurs aberrantes qui peuvent être utilisées indépendamment de la distribution des données.
Comment Détecter les Valeurs Aberrantes en Utilisant l'Écart Interquartile (IQR)
En statistiques, l'écart interquartile ou IQR est une quantité qui mesure la différence entre le premier et le troisième quartile dans un ensemble de données donné.
- Le premier quartile est également appelé le quartile un-quart, ou le quartile 25 %.
- Si
q25est le premier quartile, cela signifie que 25 % des points de l'ensemble de données ont des valeurs inférieures àq25. - Le troisième quartile est également appelé le quartile trois-quarts, ou le quartile 75 %.
- Si
q75est le troisième quartile, 75 % des points ont des valeurs inférieures àq75. - En utilisant les notations ci-dessus,
IQR = q75 - q25.
Code pour la Détection des Valeurs Aberrantes en Utilisant l'Écart Interquartile (IQR)
Vous pouvez utiliser le box plot, ou le diagramme en boîte à moustaches, pour explorer l'ensemble de données et visualiser la présence de valeurs aberrantes. Les points qui se situent au-delà des moustaches sont détectés comme des valeurs aberrantes.
Vous pouvez générer des box plots dans Seaborn en utilisant la fonction boxplot.
sns.boxplot(data=scores_data).set(title="Box Plot des Notes")
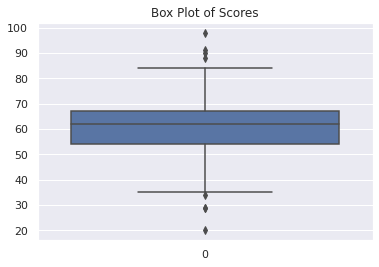
Maintenant, appelez la méthode describe sur le DataFrame df_scores.
df_scores.describe()
# Output
score
count 200.000000
mean 61.005000
std 11.854434
min 20.000000
25% 54.000000
50% 62.000000
75% 67.000000
max 98.000000
Nous utilisons les valeurs des quartiles 25 % et 75 % du résultat ci-dessus pour calculer l'IQR, et ensuite fixer les limites inférieure et supérieure pour filtrer df_scores.
IQR = 67-54
lower_limit = 54 - 1.5*IQR
upper_limit = 67 + 1.5*IQR
print(upper_limit)
print(lower_limit)
# Output
86.5
34.5
Ensuite, filtrez le DataFrame df_scores pour conserver les enregistrements qui se situent dans la plage autorisée.
df_scores_filtered = df_scores[(df_scores['score']>lower_limit) & (df_scores['score']<upper_limit)]
print(df_scores_filtered)
# Output
score
0 75.0
1 56.0
2 67.0
3 65.0
4 63.0
.. ...
194 42.0
195 76.0
196 67.0
197 74.0
199 53.0
[192 rows x 1 columns]
Comme le montre la sortie, cette méthode étiquette huit points comme des valeurs aberrantes, et le DataFrame filtré contient 192 enregistrements.
Vous n'avez pas toujours besoin d'appeler la méthode describe pour identifier les quartiles. Vous pouvez plutôt utiliser la fonction percentile() dans NumPy. Elle prend deux arguments, a : un tableau ou un DataFrame et q : une liste de quartiles.
La cellule de code ci-dessous montre comment vous pouvez calculer le premier et le troisième quartile en utilisant la fonction percentile.
q25,q75 = np.percentile(a = df_scores,q=[25,75])
IQR = q75 - q25
print(IQR)
# Output
13.0
Comment Détecter les Valeurs Aberrantes en Utilisant le Percentile
Dans la section précédente, nous avons exploré le concept d'écart interquartile et son application à la détection des valeurs aberrantes. Vous pouvez considérer le percentile comme une extension de l'écart interquartile.
Comme discuté précédemment, l'écart interquartile fonctionne en supprimant tous les points qui sont en dehors de la plage [q25 - 1.5*IQR, q75 + 1.5*IQR] comme des valeurs aberrantes. Mais supprimer les valeurs aberrantes de cette manière peut ne pas être le choix le plus optimal lorsque vos observations ont une distribution large. Et vous pouvez supprimer plus de points—que vous ne le devriez réellement—comme des valeurs aberrantes.
Selon le domaine, vous pouvez vouloir élargir la plage des valeurs autorisées pour mieux estimer les valeurs aberrantes. Ensuite, revisitons l'ensemble de données des notes et utilisons le percentile pour détecter les valeurs aberrantes.
Code pour la Détection des Valeurs Aberrantes en Utilisant le Percentile
Définissons une plage personnalisée qui accommode tous les points de données qui se situent entre le 0,5 et le 99,5 percentile de l'ensemble de données. Pour ce faire, fixez q = [0.5, 99.5] dans la fonction percentile, comme montré ci-dessous.
lower_limit, upper_limit = np.percentile(a=df_scores,q=[0.5,99.5])
print(upper_limit)
print(lower_limit)
# Output
91.035
28.955
Ensuite, vous pouvez filtrer le DataFrame en utilisant les limites inférieure et supérieure obtenues à l'étape précédente.
df_scores_filtered = df_scores[(df_scores['score']>lower_limit) & (df_scores['score']<upper_limit)]
print(df_scores_filtered)
# Output
score
0 75.0
1 56.0
2 67.0
3 65.0
4 63.0
.. ...
194 42.0
195 76.0
196 67.0
197 74.0
199 53.0
[198 rows x 1 columns]
D'après la cellule de code ci-dessus, vous pouvez voir qu'il y a deux valeurs aberrantes, et le DataFrame filtré contient 198 enregistrements de données.
Conclusion
Dans ce guide, nous avons couvert ce que sont les valeurs aberrantes et pourquoi nous devons les détecter. Nous avons ensuite passé en revue les techniques les plus courantes pour la détection des valeurs aberrantes.
Voici un résumé :
- Si les données, ou la caractéristique d'intérêt, sont normalement distribuées, vous pouvez utiliser l'écart-type et le score z pour étiqueter les points qui sont plus éloignés que trois écarts-types de la moyenne comme des valeurs aberrantes.
- Si les données ne sont pas normalement distribuées, vous pouvez utiliser la plage interquartile ou les méthodes de pourcentage pour détecter les valeurs aberrantes.
De plus, nous avons discuté des meilleures pratiques en matière de détection des valeurs aberrantes. Lorsque qu'une grande fraction de données est étiquetée comme des valeurs aberrantes, elles ne sont pas vraiment des valeurs aberrantes mais peuvent être attribuées à une distribution de données plus large.
En appliquant toutes les techniques ci-dessus, il est également important d'être conscient de la tendance actuelle pour identifier comment certaines valeurs évoluent, et de vérifier les limites inférieure et supérieure autorisées en utilisant les connaissances du domaine.