

Article original : How to Deploy Your freeCodeCamp Project on AWS – A Beginner's Guide to the Cloud
Par Luke Miller
Une nuit en juin 2017, je suis tombé sur un site web appelé freecodecamp.org. J'étais enseignant à l'époque et je cherchais un changement de carrière. Mais je pensais que devenir programmeur était hors de ma portée.
Après tout, je ne me considérais pas comme un génie des maths, je n'ai jamais étudié l'informatique et je me sentais trop vieux pour me lancer dans la programmation.
Heureusement, freeCodeCamp m'a aidé à faire mes premiers pas pour devenir développeur, et j'ai rapidement abandonné chacune de ces pensées auto-limitantes.
Aujourd'hui, en tant qu'ingénieur logiciel chez Samsung et développeur certifié AWS à trois reprises, je repense à ces nuits et week-ends passés à travailler sur le programme freeCodeCamp et je les vois comme un contributeur majeur à ma transition professionnelle réussie et à mes accomplissements en tant que programmeur.
Avec mon cœur d'enseignant toujours présent, j'ai écrit cet article pour encourager d'autres étudiants de freeCodeCamp à continuer leur apprentissage ainsi que pour compléter leur programme freeCodeCamp.
La familiarité avec le cloud computing, comme AWS, Azure ou Google Cloud, est une exigence de plus en plus présente dans les offres d'emploi.
Cet article donnera à tout débutant qui travaille encore sur le programme de freeCodeCamp une introduction simple au vaste monde du cloud computing. Je vais vous montrer comment prendre l'un de vos projets front-end freeCodeCamp et le déployer sur AWS de diverses manières.
Profitez-en, et merci freeCodeCamp !
Prérequis
Le but de cet article est d'étendre votre apprentissage de la partie Projets de bibliothèques de développement front-end du programme freeCodeCamp en les déployant sur AWS.
Donc, les prérequis sont :
- terminer l'un des défis des projets de bibliothèques front-end
- avoir un compte AWS (allez ici pour vous inscrire)
Pourquoi déployer votre projet sur AWS ?
Alors que vous travaillez sur le programme freeCodeCamp et que vous terminez vos projets de bibliothèques front-end, vous soumettez ces projets via CodePen où freeCodeCamp a une série de tests unitaires pour vérifier que vous avez correctement complété leurs histoires utilisateur.
Des confettis tombent, vous voyez une phrase inspirante et vous êtes probablement très fier de votre projet. Vous pourriez même vouloir partager cet accomplissement avec vos amis et votre famille.
Bien sûr, vous pourriez partager votre lien CodePen avec eux, mais dans le monde réel, lorsqu'une entreprise termine un projet, elle ne le rend pas disponible via CodePen – elle le déploie. Alors, faisons de même !
Juste une petite note : lorsque je dis « déployer », je veux dire prendre votre code d'un environnement local (votre ordinateur, ou les éditeurs freeCodeCamp ou CodePen) et le mettre sur un serveur. Ce serveur, qui n'est qu'un autre ordinateur, est mis en réseau de manière à ce que le monde puisse accéder à votre site.
Si vous le souhaitiez, vous pourriez configurer un PC chez vous et faire le réseau approprié pour qu'il serve votre projet au monde. Ou, vous pourriez vous abonner à une entreprise d'hébergement pour qu'elle serve votre site web pour vous.
Il existe diverses approches pour déployer du code, mais une méthode très populaire consiste à utiliser une plateforme de cloud computing comme Amazon Web Services (AWS). Plus d'informations à ce sujet ensuite.
Qu'est-ce qu'AWS ? Une brève introduction au Cloud
Amazon Web Services (AWS) offre une « plateforme de cloud computing ». C'est un peu de jargon avec beaucoup de choses dedans. Décomposons cela.
AWS propose des services allant du stockage simple de fichiers, à l'exécution de serveurs, en passant par la conversion de la parole en texte ou du texte en parole, l'apprentissage automatique, les réseaux cloud privés, et environ 200+ autres services.
L'idée de base derrière le cloud computing est d'obtenir des ressources informatiques à la demande. L'alternative, comme nous en avons parlé plus tôt, est que vous possédez ces ressources informatiques.
Il y a un certain nombre d'avantages à utiliser une plateforme de cloud computing au lieu de posséder, l'un des principaux étant les économies de coûts.
Imaginez essayer de payer pour toutes les ressources informatiques physiques qu'il faudrait pour exécuter les 200+ services qu'AWS offre. Ce coût initial est quelque chose que la plupart des entreprises ne peuvent pas se permettre, et encore moins payer pour les ingénieurs pour les configurer.
De plus, puisque les ressources sont à la demande, les plateformes cloud permettent de lancer des ressources beaucoup plus rapidement qu'un département informatique ne le pourrait.
En bref, avec une plateforme de cloud computing comme AWS, vous économisez sur les coûts et le temps de déploiement, ainsi que de nombreux autres avantages, dont le moindre n'est pas la sécurité. Il va sans dire que le cloud computing est la nouvelle approche sexy de l'informatique et AWS mène la danse.
Pourquoi est-ce important pour vous ? Si vous envisagez de poursuivre une carrière dans le développement, quel que soit votre domaine de concentration (backend, frontend, technologies web, applications mobiles, jeux, applications de bureau, etc.), vous constaterez que de nombreuses offres d'emploi incluent une référence à l'expérience des plateformes de cloud computing.
Ainsi, plus vous pourrez vous familiariser avec l'une d'entre elles, comme AWS, plus vous vous distinguerez des autres candidats.
Comment déployer votre projet freeCodeCamp avec AWS S3
Qu'est-ce qu'AWS S3 ?
Tout au long de cet article, nous allons déployer votre projet front-end freeCodeCamp en utilisant divers services sur AWS.
Notre première approche est via le service AWS appelé S3. S3 signifie Simple Storage Solution. Comme vous l'avez peut-être deviné d'après ce nom, le service vous permet de stocker simplement des objets, plus spécifiquement des objets.
Vous pouvez trouver des tutoriels et des cours sur S3 qui durent des heures et des jours. En surface, cependant, ce n'est qu'un endroit où vous pouvez stocker des objets. Les objets peuvent être des choses comme des fichiers image, des fichiers vidéo, même des fichiers HTML, CSS et JavaScript.
Alors que vous plongez plus profondément dans S3, vous apprendrez que S3 vous permet de faire beaucoup de choses avec ces objets. Mais pour notre projet, nous voulons simplement apprendre à stocker des objets et examiner une seule de ces fonctionnalités plus approfondies – utiliser S3 comme service d'hébergement de site web.
C'est exact, AWS S3 est un service que nous pouvons utiliser pour déployer un site web.
Comment préparer votre projet pour le déploiement
Tout au long de cet article, j'utiliserai le projet Random Quote Machine. J'utilise le code de l'exemple fourni dans les instructions.
Nous devons prendre votre code CSS, HTML et JS de CodePen et les mettre dans leurs propres fichiers séparés dans un éditeur de texte.
Ouvrez votre IDE (par exemple, Visual Studio Code)
Dans l'environnement CodePen, CodePen lie votre CSS à votre code HTML, ainsi que votre fichier JS à votre HTML. Nous devons en tenir compte avant de déployer sur S3, donc nous allons d'abord tester localement.
Ouvrez votre éditeur de choix et créez un nouveau répertoire (dossier) pour contenir vos trois fichiers CodePen. J'ai appelé le mien random-quote-machine. Ensuite, créez trois nouveaux fichiers :
- index.html
- styles.css
- main.js
 Trois fichiers vides : main.js, styles.css et index.html
Trois fichiers vides : main.js, styles.css et index.html
Allez-y et copiez votre fichier HTML CodePen dans index.html, votre fichier JS CodePen dans main.js et votre fichier CSS CodePen dans styles.css.
Vérifiez vos balises
CodePen ne nécessite pas la balise <body>, mais c'est une bonne pratique de l'ajouter. Assurez-vous que votre contenu HTML en a une. Reportez-vous à votre programme fCC si vous ne vous souvenez plus où elles vont.
Ajoutez et
Vous devrez maintenant lier votre styles.css et main.js à votre index.html, puisque CodePen ne le fait plus pour vous.
Au-dessus de votre balise d'ouverture <body>, ajoutez <link rel="stylesheet" href="style.css" /> qui fera en sorte que votre css dans styles.css prenne effet.
En dessous de votre balise de fermeture </body>, ajoutez <script src="main.js"></script> qui liera votre JavaScript dans le fichier main.js de manière accessible à index.html.
Vérifiez que votre site fonctionne toujours localement
Il est temps de tester que notre code fonctionne. Ouvrez un navigateur web, puis tapez ctrl+o pour sélectionner un fichier local à afficher dans le navigateur. Naviguez jusqu'à votre dossier avec nos trois fichiers, puis double-cliquez sur index.html pour l'ouvrir.
Si tout fonctionne, super ! Ce n'était pas le cas pour moi. Le code que j'ai utilisé avait un style SASS, ce qui a nécessité quelques ajustements.
Si vous avez importé des bibliothèques via CodePen, celles-ci devraient être importées, probablement via le CDN. Une simple recherche Google pour la documentation de ces bibliothèques devrait vous aider à trouver comment les importer.
Apportons les modifications nécessaires pour que votre projet fonctionne, mais rappelez-vous, le but de cet exercice est d'apprendre à déployer un site web sur AWS S3. Donc, si vous êtes bloqué par quelque chose de petit mais que le site fonctionne principalement, continuez avec ce tutoriel pour garder le rythme et résolvez ensuite les problèmes de CSS ou de JS que vous avez.
Une fois que votre site fonctionne localement, même si ce n'est pas à 100 % à votre goût, passons à AWS.
Comment travailler avec la console de gestion S3
Après vous être connecté à AWS, dans la barre de recherche en haut, tapez « S3 » puis sélectionnez l'option qui dit « S3 », et non « S3 Glacier ».
 Recherche de S3 dans la console de gestion AWS
Recherche de S3 dans la console de gestion AWS
Alternativement, au lieu de la barre de recherche, vous pourriez développer le menu déroulant « Services » et profiter de la vue de toutes les offres de services AWS. Dans tous les cas, cliquons sur S3.
Vous devriez maintenant voir la console de gestion S3. Quelque chose comme ceci...
 La console de gestion S3
La console de gestion S3
C'est ce qu'AWS appelle la console de gestion. C'est l'interface web pour interagir avec AWS et créer des ressources et des services.
Il y a une console de gestion pour tous les services AWS, mais cette console n'est pas la seule façon d'interagir avec AWS. Il y a aussi un CLI (interface de ligne de commande), qui vous permet de scripter à AWS ce que vous souhaitez faire.
Au lieu de cliquer sur des boutons, dans le CLI vous tapez ce que vous auriez autrement cliqué (bien que moins verbeusement). Nous allons rester avec la console pour l'instant.
Ici, vous pouvez voir tous vos buckets S3. S3 est composé de buckets, et un bucket est essentiellement un grand conteneur où nous pouvons mettre des fichiers. Pensez à un bucket comme à un lecteur sur votre ordinateur (comme votre lecteur C:). Techniquement, ce n'en est pas un - c'est une méthode de routage dans S3 - mais pour l'instant, il est acceptable de voir le bucket de cette manière.
Créez votre bucket S3
Cliquez sur Créer un bucket. Ensuite, entrez un nom unique pour votre bucket (pas d'espaces autorisés).
Le nom de vos buckets doit être globalement unique. Donc, si vous essayez d'en créer un nommé test, il y a probablement quelqu'un dans le monde qui l'a déjà utilisé, donc il ne sera pas disponible.
 Entrez le nom de votre nouveau bucket S3
Entrez le nom de votre nouveau bucket S3
Après avoir saisi le nom de votre bucket, faites défiler vers le bas jusqu'à la section intitulée Paramètres de blocage de l'accès public pour ce bucket. Nous voulons décocher la case Bloquer tout l'accès public, puis plus bas, cocher pour reconnaître la boîte d'avertissement qui apparaît.
 Vos paramètres doivent correspondre à ceci
Vos paramètres doivent correspondre à ceci
La sécurité et les permissions dans AWS est un sujet long, mais, comme vous pouvez le voir par l'avertissement, vous ne voulez généralement pas débloquer l'accès public à vos fichiers.
Dans notre cas, nous voulons que les navigateurs web des visiteurs de notre site puissent accéder à notre fichier index.html afin qu'ils puissent voir notre projet.
Il existe d'autres méthodes que nous pourrions utiliser pour débloquer l'accès au contenu de notre bucket, mais pour l'instant, cela est suffisant pour notre objectif de vous introduire à S3 et de déployer un projet sur AWS.
Faites défiler jusqu'en bas du formulaire. Cliquez sur le bouton Créer un bucket en bas. Si votre nom était unique, vous venez de créer votre premier bucket AWS S3, félicitations !
C'est assez incroyable de s'arrêter et de penser qu'en si peu de temps, AWS vient de rendre de l'espace disponible pour vous dans leur réseau pour stocker une quantité illimitée de données. C'est exact, illimitée !
Bien que la taille maximale pour un seul objet dans votre bucket soit de 5 téraoctets (bonne chance pour atteindre cela), votre nouveau bucket peut contenir autant que vous le souhaitez.
Téléchargez vos fichiers dans votre bucket
Ensuite, de retour dans la vue de la console S3, cliquez sur le lien vers votre bucket S3 nouvellement créé. Une fois à l'intérieur, nous voulons cliquer sur le bouton Télécharger. Sélectionnez vos trois fichiers (index.html, styles.css et main.js).
Après avoir vu leurs noms apparaître dans la liste des éléments sur le point d'être téléchargés, faites défiler jusqu'en bas du formulaire de téléchargement.
Développez les Options de téléchargement supplémentaires, puis faites défiler jusqu'à la Liste de contrôle d'accès (ACL). Cochez les cases Lire pour Tout le monde (accès public), puis cochez la case d'accusé de réception qui apparaît en dessous, comme lorsque nous avons créé notre bucket.
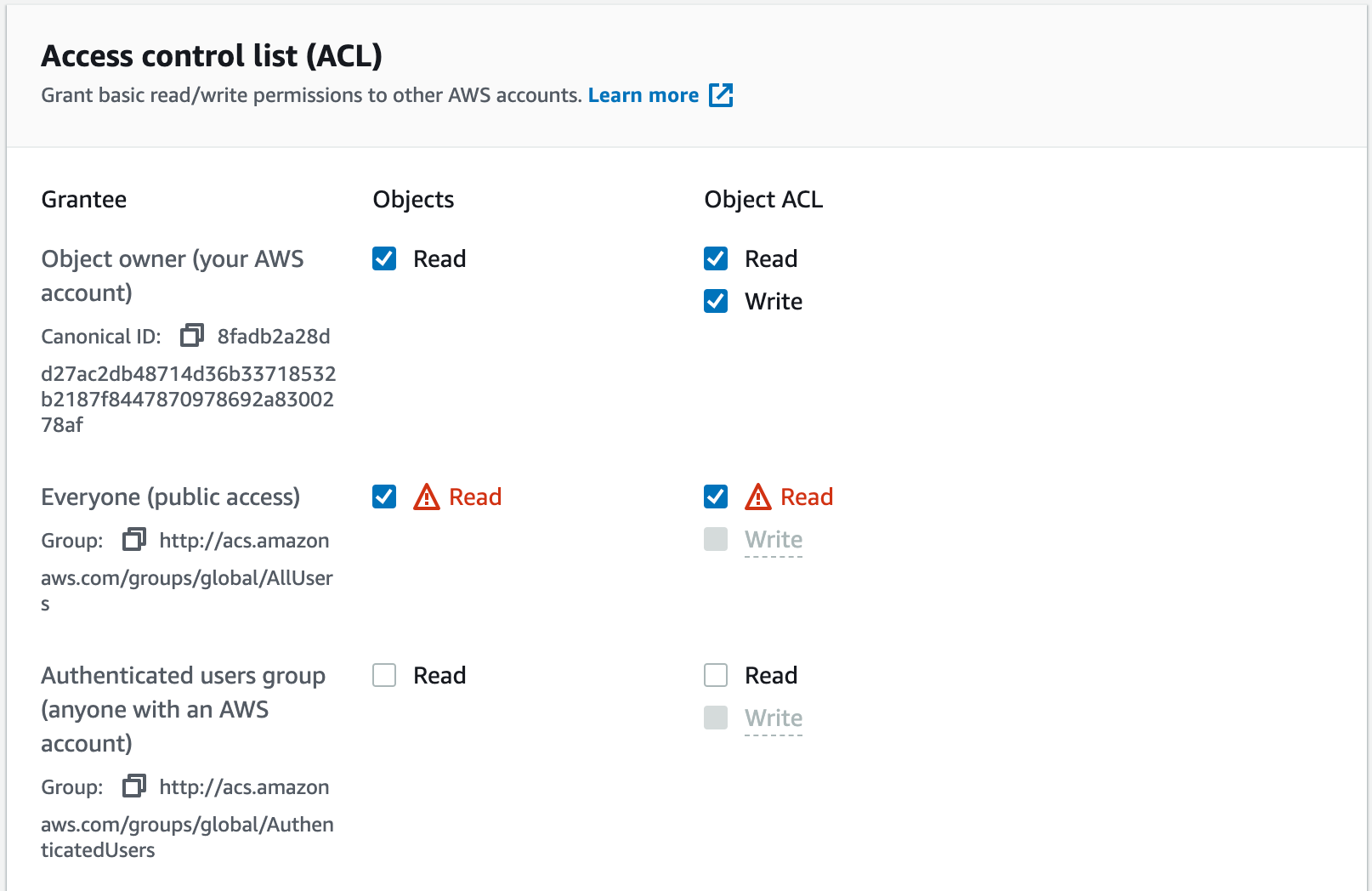 Vos sélections doivent ressembler à ceci
Vos sélections doivent ressembler à ceci
Faites défiler le reste du chemin et cliquez sur le bouton Télécharger.
Activer l'hébergement sur le bucket S3
Maintenant, nous avons notre bucket S3, nous avons nos fichiers, nous les avons rendus publics, mais nous n'avons pas tout à fait terminé.
Les buckets S3 ne sont pas configurés par défaut pour être traités comme des serveurs web. La plupart du temps, les entreprises veulent que le contenu des buckets S3 reste privé (comme les hôpitaux stockant des dossiers médicaux, ou les banques sauvegardant des relevés financiers). Pour faire en sorte que le bucket agisse comme un serveur web, nous fournissant une URL pour accéder à nos fichiers, nous devons ajuster un paramètre.
De retour à la vue principale du menu de votre bucket, cliquez sur l'onglet Propriétés.
 Sélectionnez l'onglet Propriétés
Sélectionnez l'onglet Propriétés
Faites défiler vers le bas jusqu'à ce que vous trouviez Hébergement de site web statique, et cliquez sur le bouton Modifier. Définissez Hébergement de site web statique sur Activer, puis dans les champs Document d'index et Document d'erreur, tapez index.html. Ensuite, cliquez sur le bouton Enregistrer les modifications.
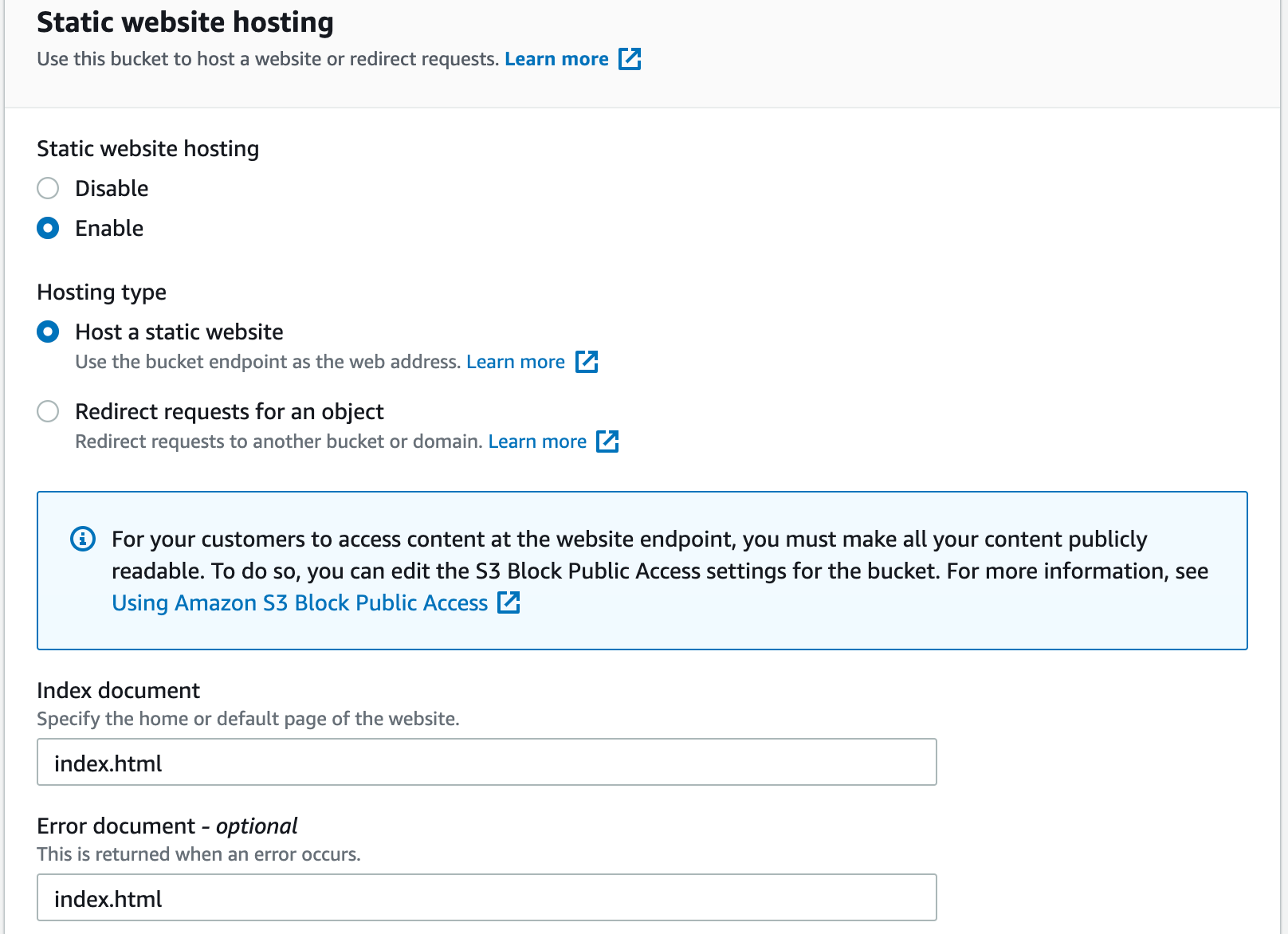 Vos sélections doivent correspondre à ceci
Vos sélections doivent correspondre à ceci
Vous reviendrez à l'onglet Propriétés de votre bucket. Faites défiler à nouveau vers le bas jusqu'à la section Hébergement de site web statique, et là vous trouverez un lien.
En lisant cette URL, vous remarquerez que le nom de votre bucket y est inclus. En tapant index.html dans les deux champs lors de la configuration, nous avons dit à AWS que lorsque l'URL de ce bucket est ouverte, utiliser la page index.html pour la charger.
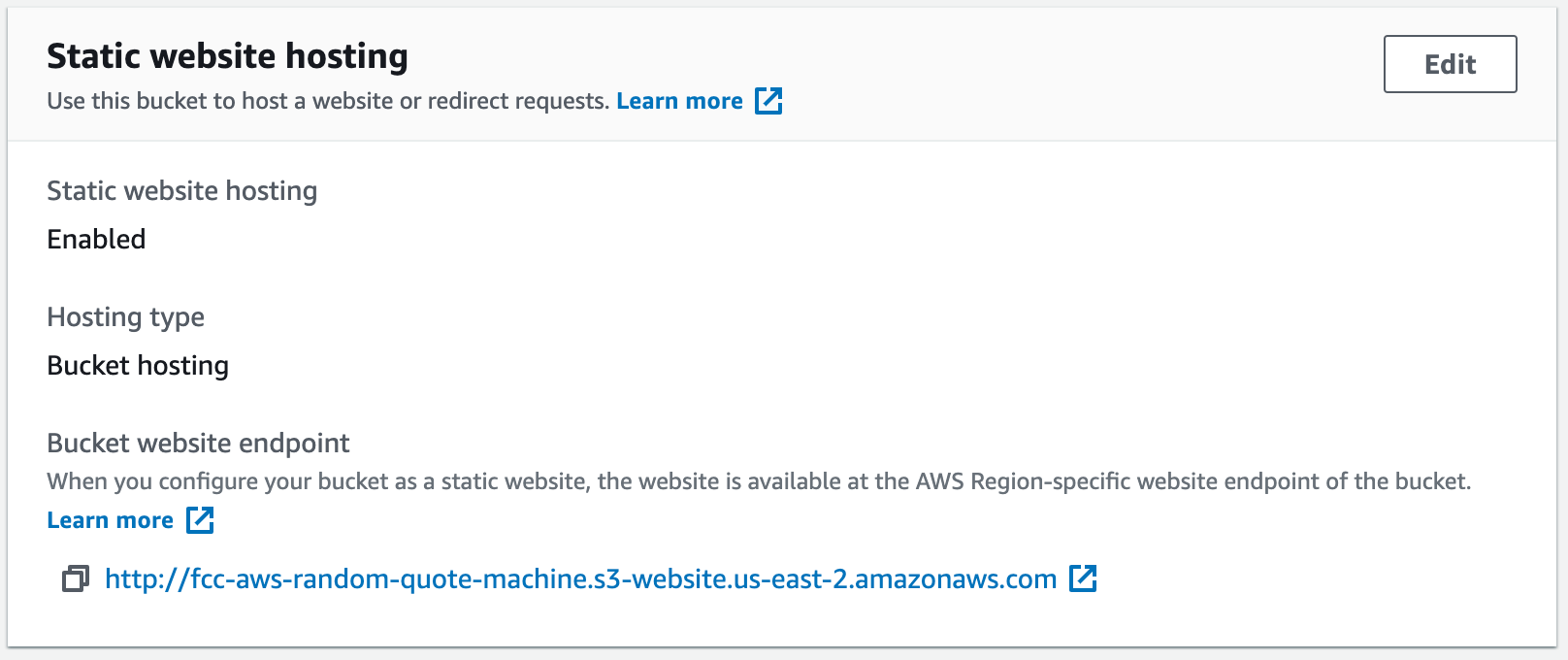 Vous devriez maintenant voir le point de terminaison du site web de votre bucket
Vous devriez maintenant voir le point de terminaison du site web de votre bucket
Si vous cliquez sur ce lien, votre projet devrait maintenant être visible.
Dépannage
Si votre site fonctionnait localement mais ne fonctionne pas lorsque vous ouvrez le lien du point de terminaison du site web S3, il y a quelques problèmes courants à essayer de résoudre.
Tout d'abord, assurez-vous d'avoir sélectionné les mêmes fichiers qui fonctionnaient localement. Rouvrez les fichiers locaux dans un navigateur web pour vous assurer qu'ils fonctionnent. Si cela fonctionne localement mais pas via S3, essayez de les retélécharger et assurez-vous de sélectionner les mêmes fichiers.
Ensuite, allez dans l'onglet Permissions de votre bucket et assurez-vous que l'option Bloquer tout l'accès public est définie sur Désactivé.
Enfin, supprimez les fichiers que vous avez téléchargés et retéléchargez-les, en vous assurant de sélectionner les cases à cocher Lire décrites ci-dessus, ainsi que la case d'accusé de réception.
Si vous avez encore des problèmes, n'hésitez pas à commenter avec votre problème et je serai heureux de vous aider. Ne vous découragez pas trop non plus. AWS peut prendre un certain temps à apprendre, alors soyez indulgent avec vous-même si les choses ne se mettent pas en place du premier coup.
Vous l'avez fait !
Maintenant, au lieu de partager une URL CodePen à vos amis et votre famille, vous avez votre propre point de terminaison de site web S3 à partager.
Certes, ce n'est toujours pas votre propre domaine personnalisé, mais hé, c'est toujours cool de savoir que vous venez de déployer un site web de la même manière que des milliers d'entreprises le font.
Vous avez maintenant non seulement appris les compétences front-end associées aux projets de bibliothèques front-end de freeCodeCamp, mais vous avez également fait vos premiers pas dans le cloud computing avec un déploiement de site web. Vous devriez être très fier !
Plus sur S3
Configurer un bucket S3 pour qu'il soit un point de terminaison de site web n'est qu'une des nombreuses façons d'utiliser S3. Nous pourrions également utiliser S3 pour stocker des données que nous voulons intégrer dans une application. Par exemple, les citations de notre Random Quote Machine pourraient être stockées dans S3 sous forme de fichier JSON, et ensuite notre front-end pourrait les demander.
Cela peut sembler un ajustement étrange à faire lorsqu'elles pourraient simplement être listées dans notre fichier main.js. Mais si nous avions d'autres applications qui avaient besoin d'accéder à ces citations, alors S3 pourrait servir de dépôt central pour elles.
C'est en fait la manière la plus populaire d'utiliser S3, comme un magasin de données pour les applications. Nous pourrions également utiliser l'option Glacier de S3 pour archiver des objets auxquels nous ne prévoyons pas d'accéder fréquemment, ce qui nous ferait économiser de l'argent par rapport à la configuration standard du bucket S3.
Une dernière idée, bien que ce ne soit pas la dernière façon d'utiliser S3, est que nous pourrions sauvegarder les journaux d'une application en cours d'exécution dans un bucket S3 afin que, s'il y avait un bug, nous pourrions inspecter ces journaux pour aider à identifier la source du problème.
Quel que soit le cas d'utilisation, le concept de S3 est le même : nous stockons des objets dans un bucket et ces objets ont des paramètres de permission pour déterminer qui peut les afficher, les modifier ou les supprimer (rappelez-vous, nous avons défini nos fichiers pour qu'ils soient lisibles publiquement).
Prochaine étape !
Comme mentionné précédemment, AWS dispose de centaines de services, ce qui signifie qu'il existe parfois plusieurs façons d'accomplir une tâche. Nous avons exploré une méthode pour héberger un site, mais il en existe deux autres qui valent la peine d'être mentionnées et qui vous aideront à acquérir une plus grande exposition à AWS dans son ensemble.
Comment déployer votre projet freeCodeCamp avec AWS Elastic Beanstalk
Maintenant, nous allons en apprendre davantage sur les services de la plateforme cloud AWS et voir une alternative pour déployer votre code afin que vous puissiez découvrir davantage ce qu'AWS a à offrir.
Plus précisément, nous allons obtenir une introduction à plusieurs des services et ressources principaux d'AWS : EC2, Load Balancers, Auto Scaling Groups et Security Groups.
Wow, c'est beaucoup de sujets à couvrir. Dans la première partie ci-dessus, nous n'avons regardé que S3 – comment allons-nous apprendre tous ces autres services ?
Eh bien, heureusement, AWS offre un service appelé Elastic Beanstalk qui bootstrap le processus de déploiement pour les applications web. En déployant votre projet freeCodeCamp via Elastic Beanstalk, vous pouvez rapidement acquérir de l'expérience avec ces services et ressources principaux d'AWS.
 Nous allons utiliser le service AWS appelé Elastic Beanstalk pour déployer
Nous allons utiliser le service AWS appelé Elastic Beanstalk pour déployer
Avant de nous replonger dans AWS
Nous avons discuté dans la partie 1 que « déployer » du code signifie configurer un ordinateur de manière à servir le projet et à le rendre accessible aux visiteurs. L'avantage des plateformes de cloud computing est que la configuration de ce serveur peut être effectuée pour nous si nous le souhaitons.
Prenons notre déploiement S3 comme exemple. Nos fichiers étaient stockés sur une machine appartenant à AWS, et AWS s'est occupé de configurer cet ordinateur pour servir la page index.html et nous donner un point de terminaison pour visualiser le projet.
Mis à part le fait de dire à S3 le nom de notre fichier index.html, nous n'avons fait aucune de ces configurations et pourtant nous sommes repartis avec un projet déployé et un point de terminaison pour le visualiser.
Lorsque nous utilisons Elastic Beanstalk, il inclura également AWS qui gérera beaucoup de configuration pour nous. Mais cette fois, nous allons également faire un peu de configuration nous-mêmes.
En faisant cela, nous verrons une méthode alternative et très populaire pour déployer une application web. Cette fois, nous ajouterons du code qui « sert » l'index.html, mais nous laisserons AWS gérer le lancement du matériel et nous donner un point de terminaison pour visualiser notre projet.
Configurons !
Nous allons ajouter du code à notre projet pour servir notre index.html. Rappelez-vous, S3 l'a fait en arrière-plan pour nous.
J'ai créé un dépôt Git pour vous à cloner ou télécharger et utiliser pour ce tutoriel. Si vous êtes familier avec Git, alors n'hésitez pas à cloner le dépôt et passez à Coller votre code. Mais si vous n'êtes pas familier avec Git, alors suivez les instructions pour télécharger ce dépôt.
Télécharger le dépôt
- Allez sur https://github.com/dalumiller/fcc-to-aws-part2
- Cliquez sur le menu déroulant vert Code puis sélectionnez Download Zip
- Décompressez/extrayez les fichiers du téléchargement zippé
Coller votre code
Dans le dossier nouvellement téléchargé/cloné (que j'appellerai le dossier fcc-to-aws-part2), nous voulons coller vos fichiers index.html, main.js et styles.css que nous avons téléchargés sur S3.
Dans le dossier fcc-to-aws-part2, il y a un autre dossier nommé public qui contient des fichiers index.html, main.js et styles.css vides. Allez-y et collez votre code dans ceux-ci.
Après avoir collé, confirmons que tout fonctionne jusqu'à présent.
Ouvrez un nouvel onglet de navigateur, puis tapez ctrl+o et naviguez jusqu'à fcc-to-aws-part2/public/index.html. Ouvrez index.html dans cet nouvel onglet. Votre application devrait fonctionner maintenant.
Si ce n'est pas le cas, arrêtez-vous et assurez-vous d'avoir collé le bon code dans les bons fichiers .html, .js et .css. Assurez-vous également d'utiliser le même code qui a fonctionné lors de votre déploiement S3.
Avec cela qui fonctionne, nous sommes maintenant prêts à discuter de ce que sont ces éléments supplémentaires dans le dossier fcc-to-aws-part2. Assurez-vous de ne pas apporter de modifications à d'autres fichiers que index.html, main.js et styles.css.
Configuration avec Node.js & Express.js
Vous vous souvenez que j'ai dit que nous allions faire un peu de configuration cette fois ? Node.js (aka Node) et Express.js sont ce que nous utilisons pour accomplir cette configuration.
freeCodeCamp a un tutoriel sur Node et Express, donc si vous souhaitez faire une pause et le parcourir, n'hésitez pas. Mais je vais également fournir une brève introduction expliquant pourquoi et comment nous utilisons Node et Express.
Pourquoi utiliser Node ?

Node.js est un environnement d'exécution JavaScript pour les applications côté serveur. C'est beaucoup de jargon, alors décomposons un peu.
« Node est un environnement d'exécution JavaScript » – un environnement d'exécution, dans le monde de la programmation, est un modèle d'exécution. En d'autres termes, c'est un processus qui implémente comment exécuter du code. Donc, Node est un processus qui implémente comment exécuter du code JavaScript.
Lorsque nous avons du code JavaScript comme ceci :
console.log("Hello World")
Node sait quoi faire avec ce code.
« ...pour les applications côté serveur » – rappelez-vous que nous essayons de déployer notre code pour qu'il soit servi par un serveur, et qu'un serveur est simplement un ordinateur. Notez également qu'un serveur est différent d'un client, et dans le cas d'un site web, le client est le navigateur web.
Lorsque vous ouvrez votre projet dans un navigateur web, le navigateur gère la lecture des fichiers index.html, main.js et styles.css. C'est exact, le navigateur (client) sait comment lire et exécuter du code JavaScript, donc lorsqu'il voit console.log("Hello World"), il sait quoi faire.
Notre fichier main.js est du code JavaScript qui est exécuté côté client, par le navigateur. Mais, Node est pour le JavaScript côté serveur. Donc, votre navigateur sait comment exécuter ce code JavaScript, mais comment l'ordinateur qui sert notre site web sait-il comment exécuter JavaScript ? Node.
 JavaScript peut s'exécuter sur le client (c'est-à-dire : navigateur web) et sur le serveur
JavaScript peut s'exécuter sur le client (c'est-à-dire : navigateur web) et sur le serveur
Donc, en résumé, « Node est un environnement d'exécution JavaScript pour les applications côté serveur » signifie que Node est un processus pour implémenter comment exécuter du code JavaScript sur un serveur, par opposition à un client comme un navigateur web.
Sans Node, l'ordinateur/serveur ne sait pas comment exécuter du code JavaScript.
Pourquoi utiliser Express ?
 Expres.js un framework d'application web pour Node.js
Expres.js un framework d'application web pour Node.js
Alors que Node nous donne l'environnement d'exécution côté serveur, qui est cet environnement où nous pouvons exécuter du code JavaScript, Express nous donne un framework pour servir des applications web.
Lorsque nous avons déployé via S3, nous avons dit à S3 le nom du fichier que nous voulions servir (index.html). Maintenant, Express sera l'endroit où nous configurerons quel fichier nous voulons servir.
Si nous avions un site web avec différentes routes (par exemple : www.example.com/home, /media, /about, /contact), alors nous pourrions avoir différents fichiers HTML pour chacune de ces pages. Nous utiliserions Express pour gérer le service de ces pages si le navigateur web les demandait.
Par exemple, lorsque le navigateur web demanderait www.example.com/contact, Express recevrait cette demande du navigateur et répondrait avec contact.html.
app.js
Maintenant que nous savons que Node est ce qui nous permet d'exécuter du code JavaScript sur le serveur et qu'Express gère nos requêtes du navigateur, examinons dans fcc-to-aws-part2 notre fichier app.js et lisons-le ligne par ligne pour comprendre ce que nous avons ajouté à notre projet.
D'abord...
const express = require("express");
Cela déclare une variable appelée express, puis le signe = signifie que nous lui attribuons une valeur. Mais qu'est-ce que ce require("express") ?
La fonction require est simplement une fonction dont Node est conscient, et lorsque Node la voit, il recherche un dossier dans le dossier node_modules avec le même nom. Vous avez ce dossier node_modules dans votre dossier fcc-to-aws-part2.
Une fois que Node trouve express à l'intérieur du dossier node_modules, il importera le code du dossier express et l'attribuera à la variable que nous avons déclarée. Cela nous permet d'utiliser le code qui provient du dossier express sans avoir à l'écrire nous-mêmes. Cette importation de code dans notre code est le concept de modules.
Un module est simplement un ensemble de code. Il peut faire une ligne de long ou beaucoup plus long. Par conséquent, un NODE_module (accentuation ajoutée à node) est un ensemble de code qui peut s'exécuter dans l'environnement d'exécution Node. Nous utilisons, ou require-ons, le module express.
Le module express est le framework d'application web Express.js dont nous avons parlé plus tôt.
Je ne vais pas entrer dans les détails de l'ajout de modules au dossier node_modules, mais pour l'instant, sachez qu'en déclarant la variable express et en utilisant la syntaxe require("express"), nous importons ce framework Express.js et le rendons accessible via la variable à laquelle nous l'avons attribué.
Il y avait beaucoup de choses dans ces quatre paragraphes précédents, je recommande de ralentir et de les relire pour vous assurer que vous les avez bien compris !
Ensuite...
const path = require("path");
Ah ! Cela devrait vous sembler familier maintenant. Nous importons un autre module, cette fois le module path. Nous l'attribuons à la variable path.
Vous avez peut-être remarqué un schéma où le nom de la variable que nous utilisons correspond au nom du module. Ce n'est pas obligatoire. Nous pourrions attribuer le module path à la variable foobar. Mais il est plus logique de le nommer pour ce qu'il est.
Que fait le module path ? C'est un module (juste un ensemble de code) qui nous permet de travailler avec les chemins de fichiers et de dossiers. De cette façon, nous pouvons utiliser une syntaxe JavaScript que Node comprend afin d'accéder aux fichiers/dossiers sur notre serveur. Cela sera utile lorsque nous voudrons référencer l'emplacement de index.html dans notre projet.
D'accord, continuons...
const app = express();
Express, encore ? C'est exact. La première fois, nous importions simplement le module, maintenant nous l'utilisons.
Pour utiliser le framework Express, nous devons l'instancier, ce qui signifie que nous devons exécuter cette fonction express, express(), et maintenant nous l'attribuons à la variable app.
"Whoa, mais Luke, pourquoi ne pas avoir cette ligne de code juste après la ligne de code express précédente ?"
Bonne question. C'est un schéma courant d'importer (ou d'utiliser require()) tous les modules dont vous aurez besoin en haut de votre code, puis de les utiliser après avoir terminé l'importation.
Maintenant, le gros morceau...
app.use(express.static(path.join(__dirname, "public")));
Whoa là ! Décomposons cela un peu.
Tout d'abord, nous appelons une fonction, la fonction app.use(). Cela indique à notre application Express que nous voulons UTILISER une autre fonction dans notre application. Cela a du sens.
La fonction que nous disons à Express que nous voulons exécuter est la fonction express.static() appelée à l'intérieur du paramètre de la fonction .use(). Donc, app.use() indique à Express que nous voulons utiliser un certain code dans l'application, et spécifiquement ici, nous voulons UTILISER express.static(path.join(__dirname, "public")).
Maintenant, express.static() est une fonction Express que nous pouvons utiliser puisqu'elle fait partie du module que nous avons importé et attribué à la variable express.
La fonction .static() gère le service des fichiers statiques. J'espère que vos oreilles se sont dressées et que vos yeux se sont ouverts ! Je vais le répéter. La fonction .static() gère le SERVICE des fichiers statiques. Service !
Rappelez-vous, dans cette approche de déploiement, nous gérons un peu plus de la configuration pour SERVIR notre projet. Voici la fonction Express que nous utilisons pour dire : « Je veux servir des fichiers statiques ». Les fichiers statiques signifient notre fichier index.html.
Donc, app.use() disait : « Hé, je veux exécuter un certain code pour cette application à l'intérieur de mon paramètre de fonction ». Plus précisément, nous voulons exécuter express.static() qui dit : « Je veux livrer des fichiers statiques, comme un index.html », et ensuite son paramètre de fonction nous indique où trouver ces fichiers statiques.
Alors regardons path.join(__dirname, "public") pour comprendre comment il nous indique où se trouvent nos fichiers statiques.
Plus tôt, nous avons importé le module path pour pouvoir accéder aux fichiers dans notre serveur/ordinateur.
Eh bien, nous voulons accéder au fichier index.html, qui se trouve dans le dossier public. Nous utilisons la fonction path .join() pour dire : « hé, à partir de notre répertoire actuel (ou dossier), allez dans le dossier public pour trouver les fichiers que je veux ». Cela retournera le index.html, main.js et styles.css à express.static(), qui retournera à la fonction app.use() qui gère les fichiers à servir (SERVIR !) à nos visiteurs.
Tout ensemble maintenant !
app.use() = « lorsque le navigateur demande l'application, je veux exécuter express.static() »
express.static() = « Je vais livrer des fichiers statiques et ils sont situés ici... »
path.join(__dirname, "public") = « prendre les fichiers dans le dossier public »
Hourra ! Nous l'avons fait ! Nous avons configuré notre application Express s'exécutant dans l'environnement d'exécution Node pour livrer les fichiers index.html, main.js et styles.css lorsque quelqu'un visite notre site.
Mais attendez... il y a plus :
const port = 8080;
app.listen(port);
Rappelez-vous que la variable app est notre instance du framework Express. La fonction .listen() est l'application qui dit à l'ordinateur : « hé, toute requête faite sur le port 8080, amenez-les à moi ! »
Les ports et les sockets sont un sujet plus avancé, donc nous n'allons pas en parler maintenant. Mais sachez simplement qu'un ordinateur/serveur a de nombreux ports, qui sont comme des points d'accès, et nous configurons l'application Node/Express pour n'écouter qu'un seul point d'accès, 8080.
Enfin...
console.log("listening on port: " + port);
C'est une pratique standard pour les applications Express, où nous enregistrons simplement sur l'ordinateur le port que nous utilisons. Cela nous donne une certaine vérification que l'application Express fonctionne.
Excellent travail ! C'était beaucoup de code à parcourir.
Maintenant, si vous êtes suffisamment familier avec la navigation via un terminal, nous pouvons tester cette application Express localement sur notre ordinateur avant de passer à AWS. Nous assurer qu'elle fonctionne localement avant d'aller sur AWS nous aidera en cas d'erreurs sur AWS, car nous saurons que les erreurs ne peuvent pas être liées au fait que notre application Express ne fonctionne pas.
Comment tester notre application Node/Express.js
Si vous ouvrez le fichier package.json, vous verrez une section « scripts ». Ce fichier package.json est des métadonnées pour notre application Node, et il peut également contenir des commandes configurables à exécuter dans la section « scripts ».
J'ai inclus le script « start », qui exécute le fichier app.js dans l'environnement Node, qui à son tour exécute notre code Express.js que nous venons de discuter. Ce script « start » est la manière dont nous exécutons notre projet.
Pour tester cela, dans votre terminal, naviguez jusqu'à notre dossier fcc-to-aws-part2, entrez npm start pour démarrer l'application.
 Commande du terminal pour exécuter notre application
Commande du terminal pour exécuter notre application
Après avoir exécuté cette commande, vous devriez immédiatement voir notre message console.log() nous informant que l'application s'exécute sur le port 8080.
 Vous devriez voir le message « listening on port: 8080 » pour savoir qu'il s'exécute
Vous devriez voir le message « listening on port: 8080 » pour savoir qu'il s'exécute
Maintenant, pour visualiser votre projet, ouvrez un navigateur web et entrez localhost:8080 dans votre barre d'adresse et cliquez sur Entrée. Vous devriez maintenant voir votre projet en cours d'exécution !
Si ce n'est pas le cas, assurez-vous d'utiliser les bons fichiers index.html, main.js et styles.css, et que vous n'avez pas modifié le code de fcc-to-aws-part2.
Hourra !
D'accord, maintenant nous avons configuré Node et Express pour servir notre projet. Notre ordinateur local agit comme le serveur pour le moment, mais nous voulons que n'importe qui dans le monde puisse voir notre projet et ils ne peuvent pas le faire via notre adresse localhost:8080.
Donc, nous allons utiliser AWS pour héberger un serveur pour nous, y mettre notre application, puis laisser AWS gérer la configuration nécessaire pour générer l'URL de point de terminaison pour que le monde puisse y accéder. C'est là que le service AWS appelé Elastic Beanstalk entre en jeu. Commençons !
Aller à AWS Elastic Beanstalk
Après vous être connecté à votre compte AWS, recherchez le service Elastic Beanstalk dans la barre de recherche en haut. Une fois là, cliquez sur le bouton Créer une application.
 La page de la console principale pour AWS Elastic Beanstalk
La page de la console principale pour AWS Elastic Beanstalk
Ensuite, nous ajouterons le nom de notre application Elastic Beanstalk.
 Entrez le nom de votre application souhaité
Entrez le nom de votre application souhaité
Sautez la section Tags, et entrons les informations pour les sections Plateforme et code de l'application.
Notre Plateforme est Node.js, la Branche de la plateforme est Node.js 14 s'exécutant sur Amazon Linux 2 64 bits (ce qui nous indique quel type de serveur exécute Node), et la Version de la plateforme est celle recommandée par AWS. Ensuite, pour le Code de l'application, nous allons télécharger notre code.
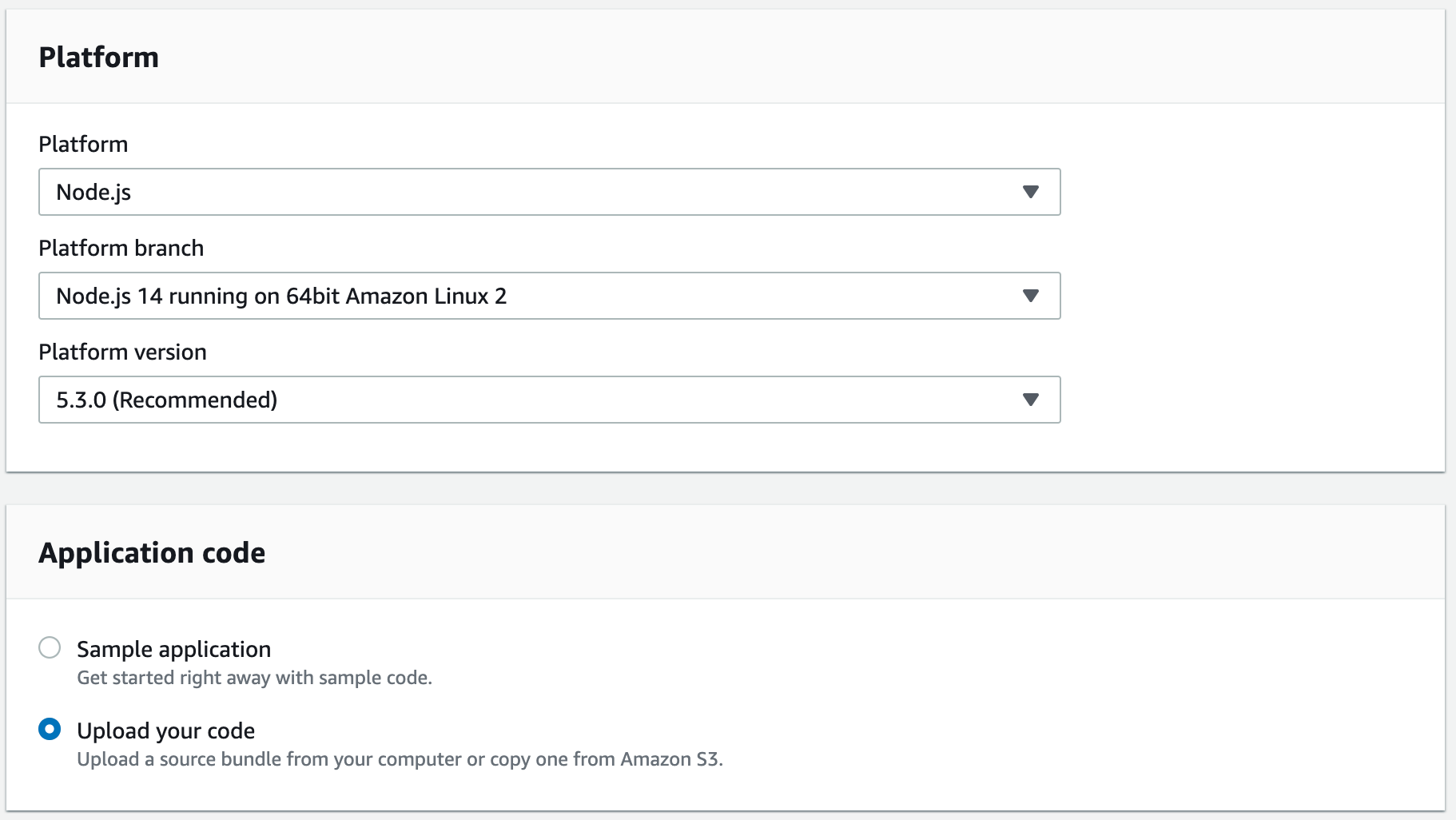 Nos paramètres pour l'application Elastic Beanstalk
Nos paramètres pour l'application Elastic Beanstalk
Cliquez sur le bouton Créer une application.
Télécharger et déployer
Avant de cliquer sur le bouton Télécharger et déployer, nous devons compresser notre projet. Ouvrez le dossier fcc-to-aws-part2, et sélectionnez tous les fichiers qu'il contient et compressez-les. NE COMpressez PAS le dossier fcc-to-aws-part2 lui-même – cela ne fonctionnera pas.
 Le contenu de fcc-to-aws-part2 compressé ensemble, pas fcc-to-aws-part2 compressé
Le contenu de fcc-to-aws-part2 compressé ensemble, pas fcc-to-aws-part2 compressé
Maintenant, avec vos fichiers compressés, cliquez sur le bouton Télécharger et déployer dans votre environnement Elastic Beanstalk. Sélectionnez votre fichier compressé.
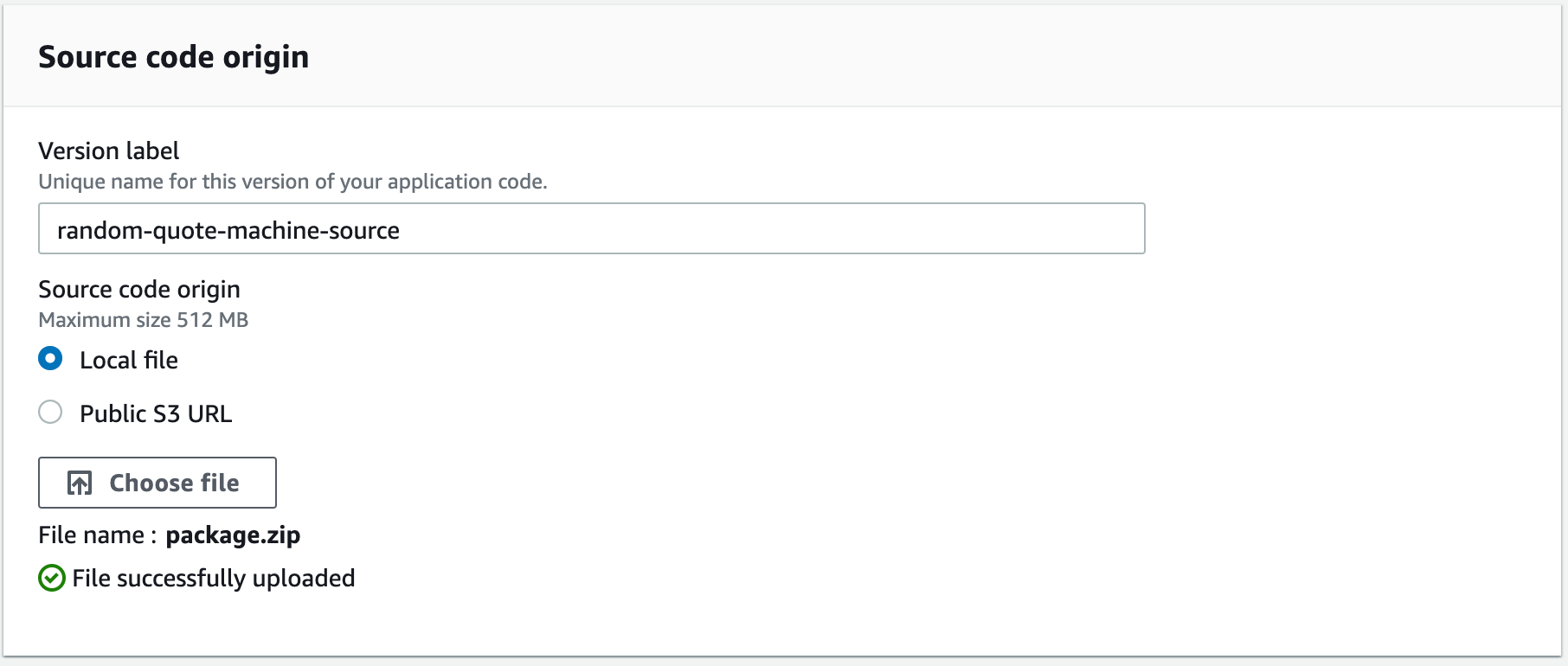 Téléchargez votre projet compressé
Téléchargez votre projet compressé
Après avoir téléchargé votre code, une boîte noire apparaîtra nous donnant une série de journaux qui sont les étapes prises pour lancer l'application Elastic Beanstalk. Réjouissez-vous du fait que chaque entrée de journal est une configuration que nous n'avons pas eu à faire.
 Le début de nos journaux
Le début de nos journaux
Une fois terminé, vous serez redirigé vers la vue principale de votre application. Vous verrez que votre environnement a un statut de santé qui est probablement rouge au début.
Ne vous alarmez pas de cela. AWS est en train de passer par le processus de configuration que nous ne voulons pas faire, à savoir le lancement du serveur, la création du point de terminaison de l'URL, puis l'exécution de notre application. Cela prend quelques minutes pour se terminer.
C'est à ce moment que Elastic Beanstalk effectue toutes ces configurations pour nous, ce qui rend les plateformes de cloud computing si pratiques !
Remarquez en haut que vous avez déjà un point de terminaison d'URL qui vous est donné. Une fois que la santé s'améliore, vous devriez pouvoir ouvrir ce lien pour voir votre projet.
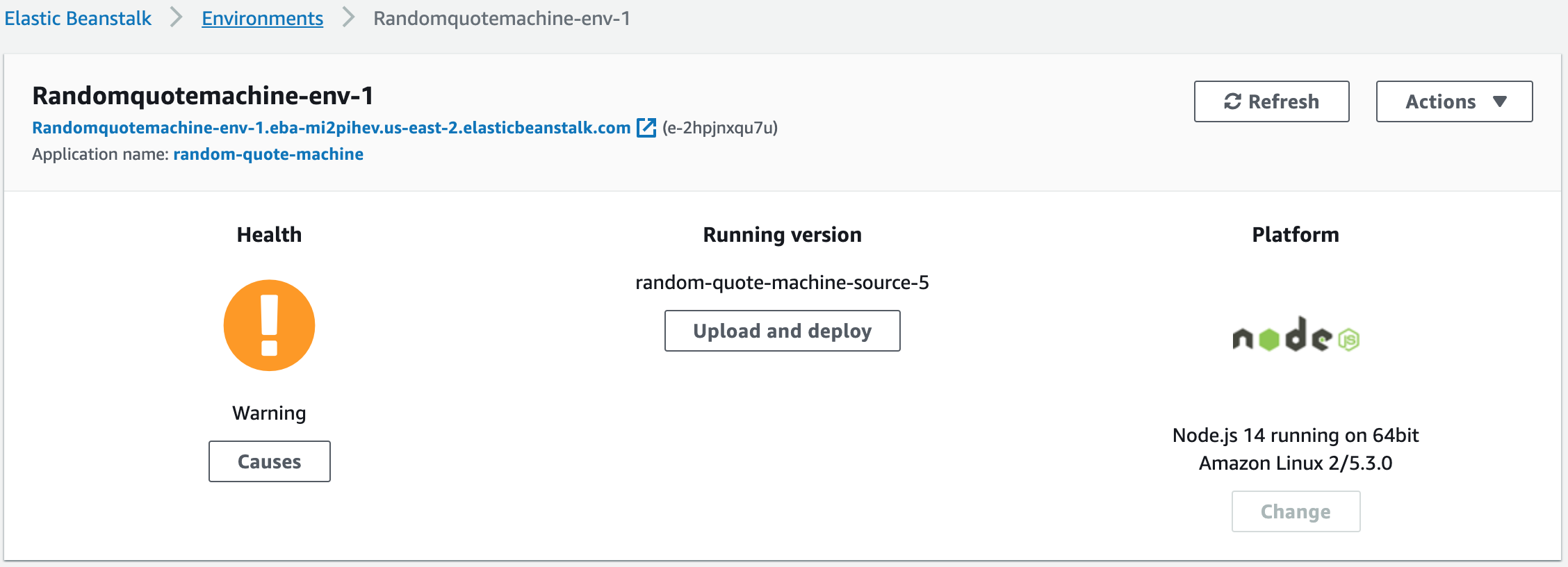 Vous pouvez trouver votre URL ici (sous Randomquotemachine-env-1)
Vous pouvez trouver votre URL ici (sous Randomquotemachine-env-1)
Si votre statut de santé ne change jamais en orange puis en vert, alors quelque chose ne va pas. La meilleure chose à faire est de retélécharger le fcc-to-aws-part2, coller votre code dedans, puis recompresser le contenu de fcc-to-aws-part2, et non le dossier fcc-to-aws-part2 lui-même, et le retélécharger sur Elastic Beanstalk.
Une fois que le statut de santé s'améliore, vous devriez pouvoir ouvrir le lien et voir votre projet. Plus important encore, n'importe qui dans le monde peut maintenant voir votre projet avec ce lien !
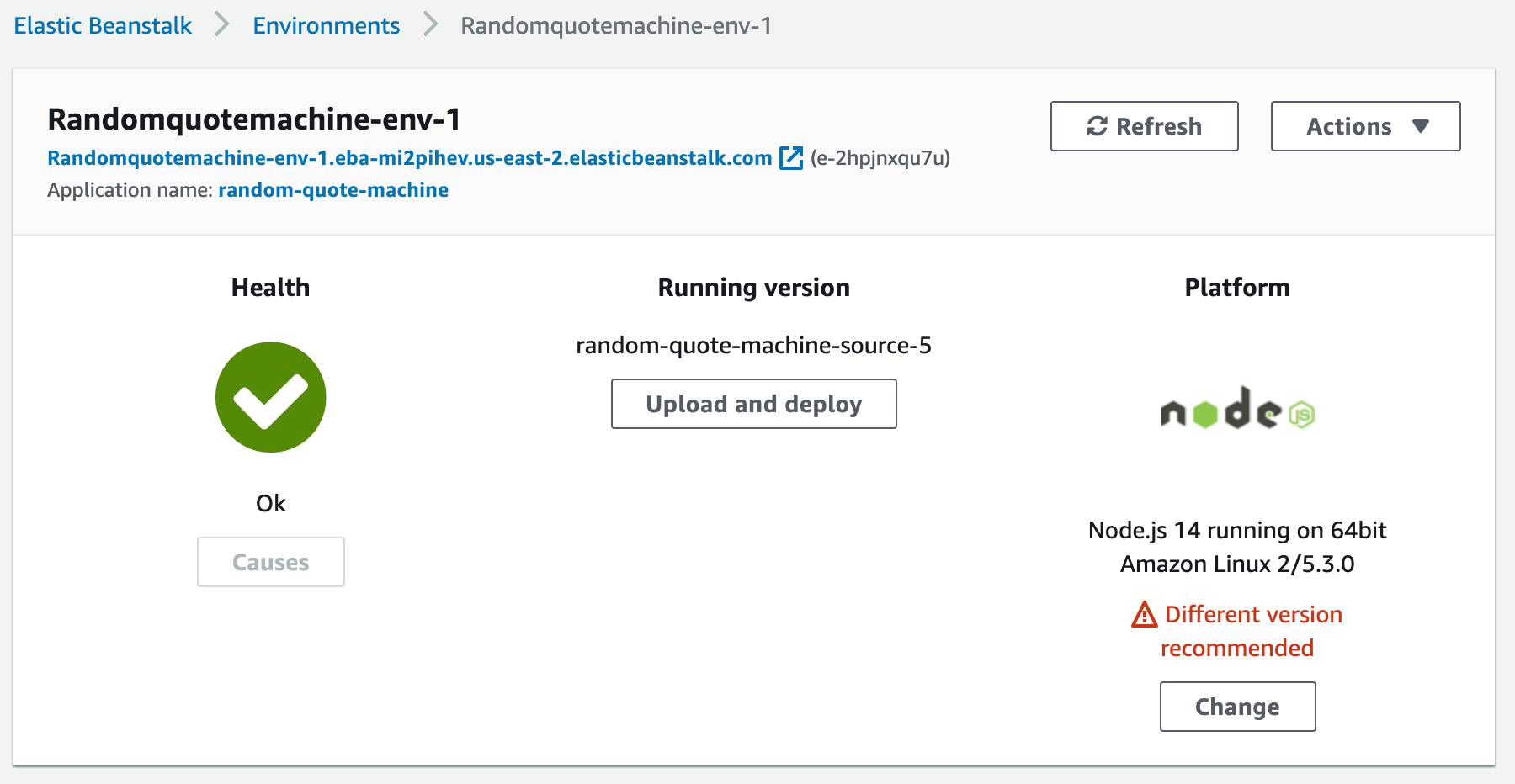 Une application saine, il est temps d'aller la vérifier !
Une application saine, il est temps d'aller la vérifier !
Vous l'avez fait !
Félicitations !
Je sais que c'était un processus plus long et plus détaillé que le déploiement S3, mais vous l'avez fait.
Nous avons pris en charge une partie de la configuration nous-mêmes cette fois en créant une application Node/Express pour servir nos fichiers statiques, mais nous avons tout de même laissé AWS gérer la création et la configuration du serveur, de son environnement et du point de terminaison pour nous afin d'exécuter notre projet et de le visualiser.
Même avec le temps passé à parcourir le code Express, le temps nécessaire pour déployer ce projet est minimal puisque AWS automatise tant de choses pour nous.
Nous n'avons pas eu à prendre le temps d'acheter un serveur, d'installer des programmes dessus, de configurer un point de terminaison d'URL pour lui, ou d'installer notre projet dessus. C'est l'avantage des plateformes de cloud computing comme AWS.
AVIS : Assurez-vous d'arrêter ou de terminer votre instance EC2, ou de supprimer votre application Elastic Beanstalk lorsque vous avez terminé avec elle. Si vous ne le faites pas, vous serez facturé pour la durée d'exécution de votre application.
Les services sous-jacents d'Elastic Beanstalk
J'ai mentionné au début de cette section que la beauté d'Elastic Beanstalk est qu'en utilisant ce service, nous obtenons en fait une introduction à de nombreux services : EC2, Load Balancers, Auto Scaling Groups, et même Cloud Watch.
Ci-dessous se trouve une brève explication de ceux-ci pour approfondir votre apprentissage sur AWS et ses services.
Pour obtenir une meilleure visualisation et voir une partie de la profondeur de configuration qu'Elastic Beanstalk a faite pour nous, naviguez vers le lien Configurations et faites défiler la page.
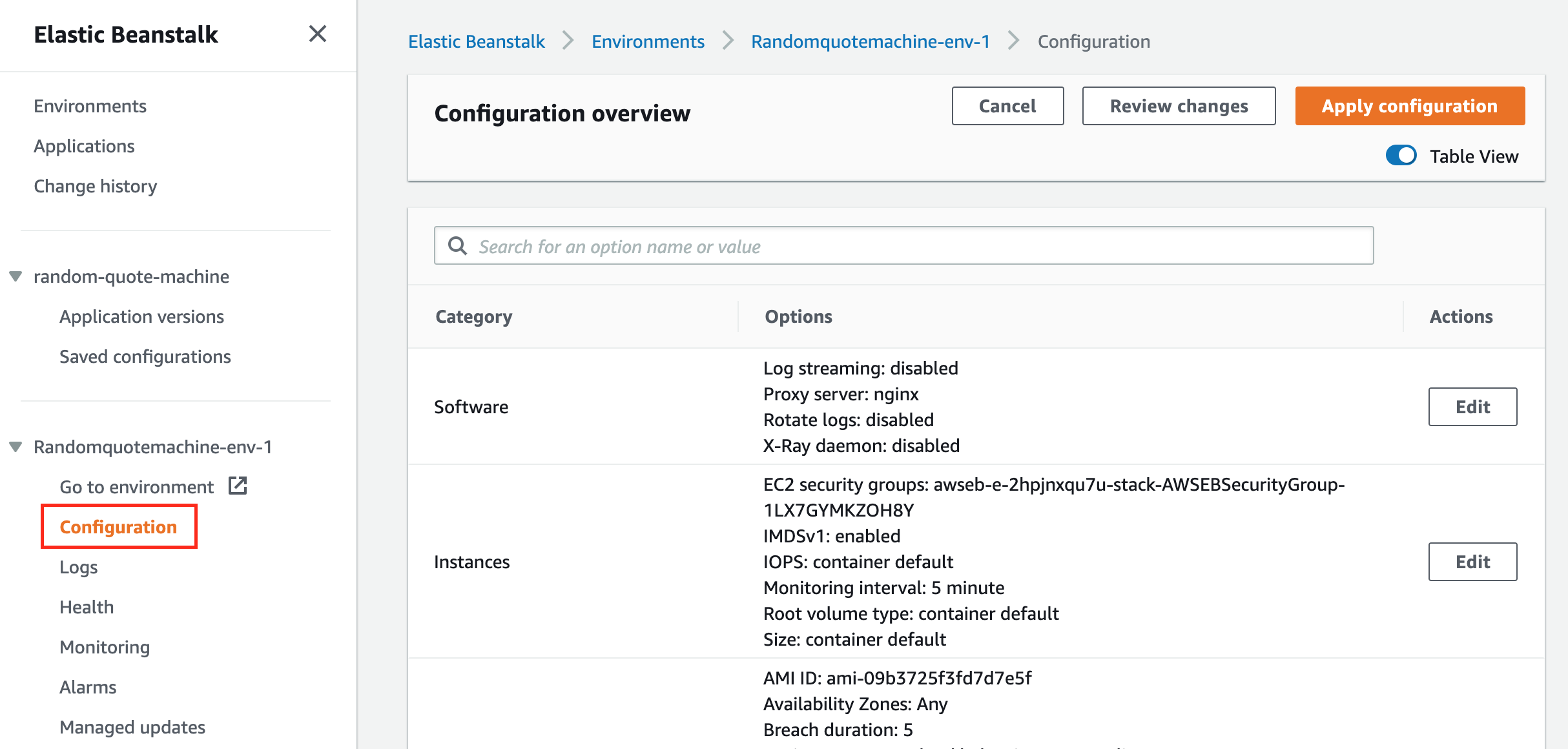 Un aperçu des configurations qu'Elastic Beanstalk fait pour nous
Un aperçu des configurations qu'Elastic Beanstalk fait pour nous
EC2
Dans l'Aperçu de la configuration, il y a une catégorie appelée Instances.
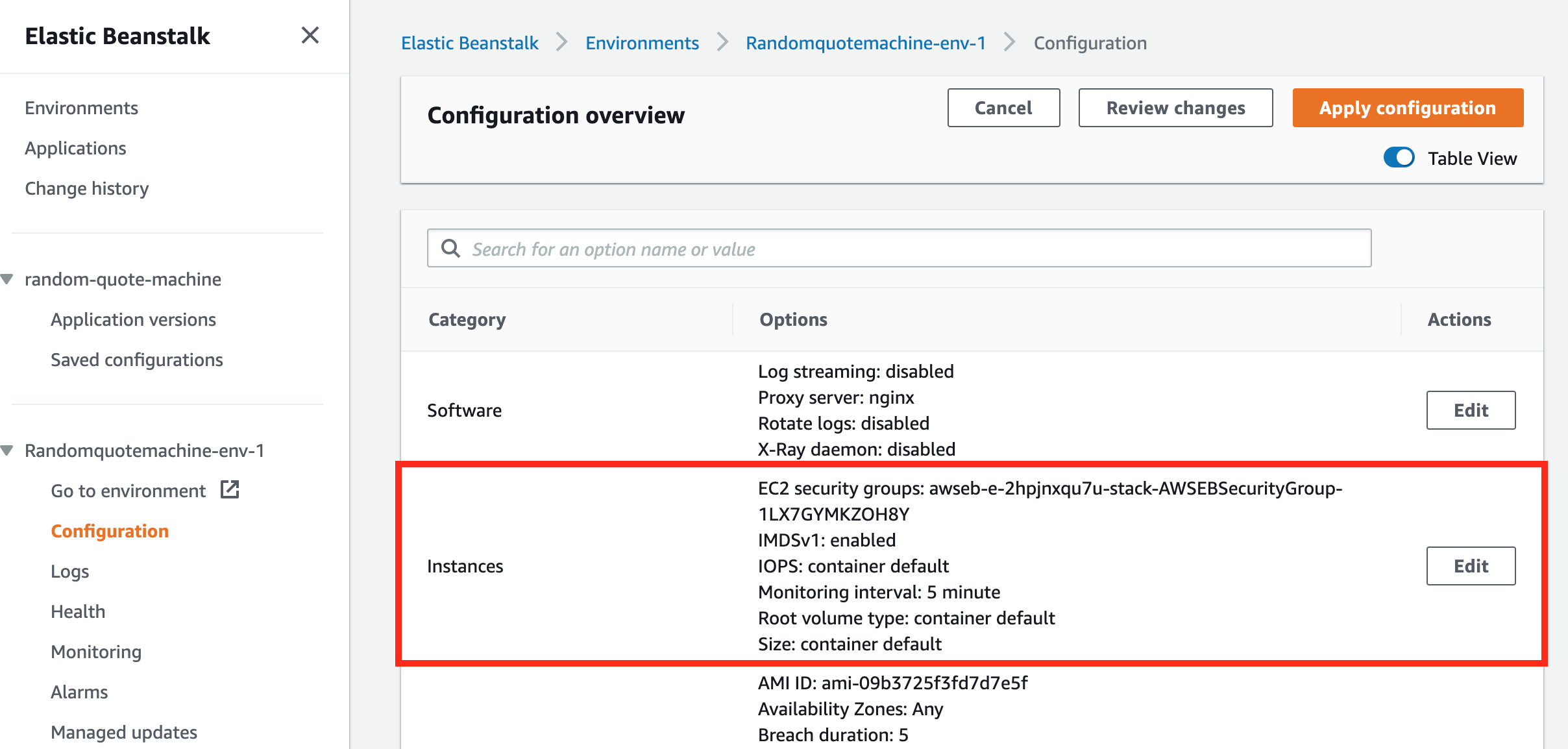 La catégorie de configuration des instances
La catégorie de configuration des instances
Instances est un autre mot utilisé pour serveur, ou ordinateur. Rappelez-vous que nous déployons notre code sur un serveur, eh bien AWS appelle ces serveurs des Instances, et plus spécifiquement, ils sont appelés Instances EC2.
EC2, abréviation de Elastic Computer Container, est un service d'AWS qui vous permet de lancer des Instances EC2 très rapidement. Nous pouvons « lancer » un serveur rapidement en utilisant EC2 et y mettre ce que nous voulons.
Dans notre cas, Elastic Beanstalk a exécuté le service EC2 pour nous et a démarré une Instance EC2 pour que notre application soit hébergée.
Si vous avez toujours votre application Elastic Beanstalk en cours d'exécution, nous pouvons aller voir votre Instance EC2. En haut de votre écran, dans la barre de recherche AWS, entrez EC2 et cliquez sur entrer.
Vous devriez voir qu'une instance est en cours d'exécution, comme ceci...
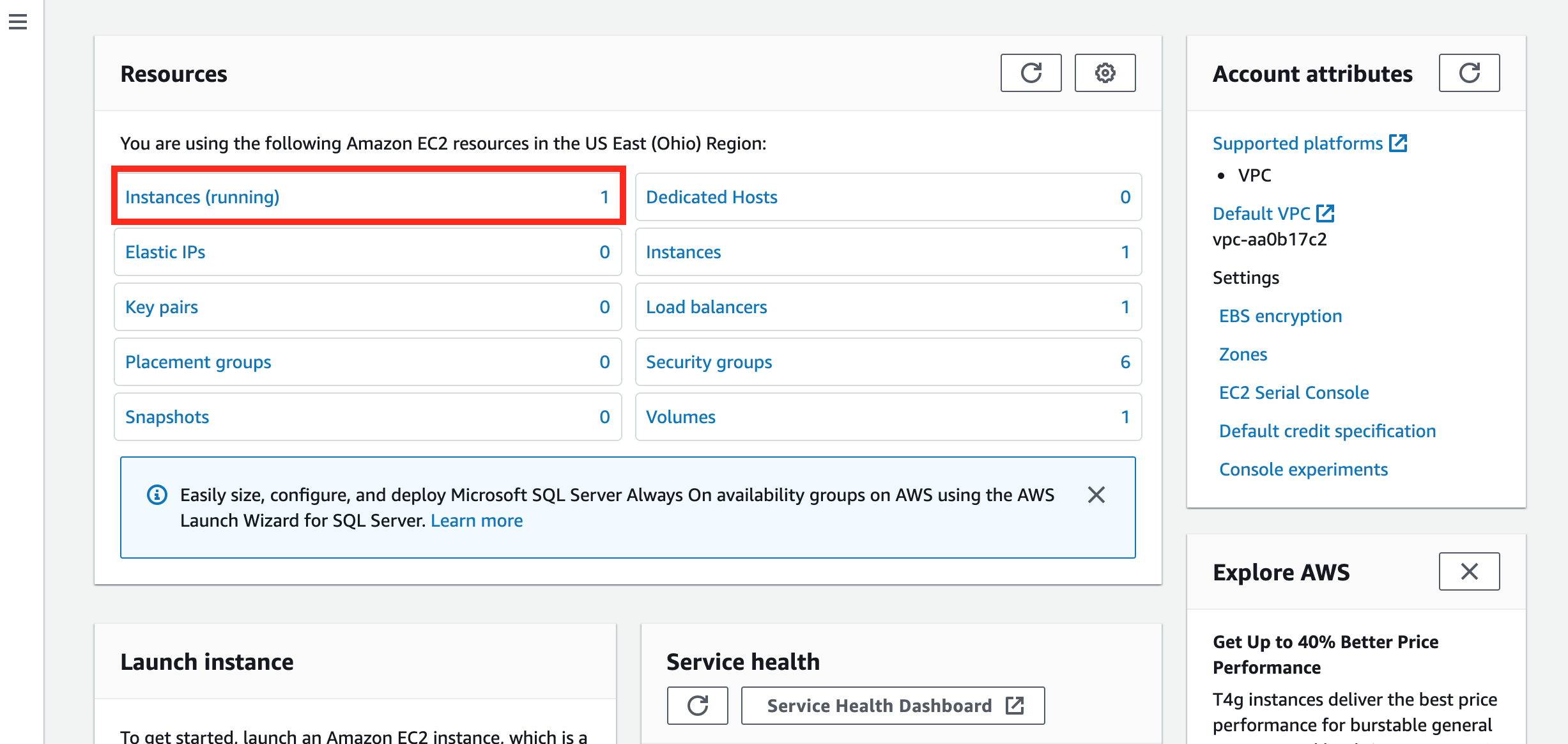 Votre console de gestion EC2
Votre console de gestion EC2
Si vous cliquez sur le lien Instances (en cours d'exécution), vous pourrez voir les détails spécifiques de l'instance EC2. Cette EC2, encore une fois, est simplement un ordinateur en cours d'exécution sur un site AWS qui contient votre code. L'EC2 a été lancé par Elastic Beanstalk pour nous.
Load Balancer
Non seulement Elastic Beanstalk a créé une Instance EC2 pour nous, mais il a également créé un Load Balancer pour nous. Dans la console de gestion EC2, dans le panneau de navigation de gauche, faites défiler vers le bas jusqu'à Load Balancers et cliquez sur le lien pour voir celui qui a été créé pour vous.
Le but d'un load balancer est de distribuer le trafic entrant sur plusieurs cibles. Cette cible dans notre cas est une EC2, mais nous n'en avons qu'une en cours d'exécution, donc un load balancer n'est pas très utile pour le moment.
Imaginons un instant que notre application devienne virale et que des dizaines de milliers de personnes essaient d'accéder au point de terminaison qu'Elastic Beanstalk nous a donné. Cette seule Instance EC2 serait submergée par le trafic. Les requêtes expireraient, les visiteurs seraient frustrés et notre site en souffrirait car nous n'avons pas assez d'EC2 pour gérer la charge.
Mais ! Si nous avions plus d'Instances EC2 en cours d'exécution, chacune avec notre projet déployé dessus, nous pourrions gérer le fait de devenir viral.
Bien qu'il y ait un problème qui survient lorsque l'on a plusieurs EC2. Nous avons besoin que chaque instance EC2 soit accessible par ce même point de terminaison Elastic Beanstalk, et c'est un réseau délicat.
C'est là que le Load Balancer entre en jeu. Il fournit un seul point d'accès pour notre Elastic Beanstalk à cibler, et le Load Balancer gère ensuite l'organisation du trafic entre les différentes EC2 et le Beanstalk.
Si vous regardez la Configuration de base de vos Load Balancers, vous verrez un Nom DNS, qui ressemble beaucoup au point de terminaison Elastic Beanstalk. Si vous l'ouvrez, votre application devrait s'exécuter. C'est parce que le point de terminaison Elastic Beanstalk pointe en réalité vers ce point de terminaison qui est capable d'équilibrer le trafic entre plusieurs points de terminaison.
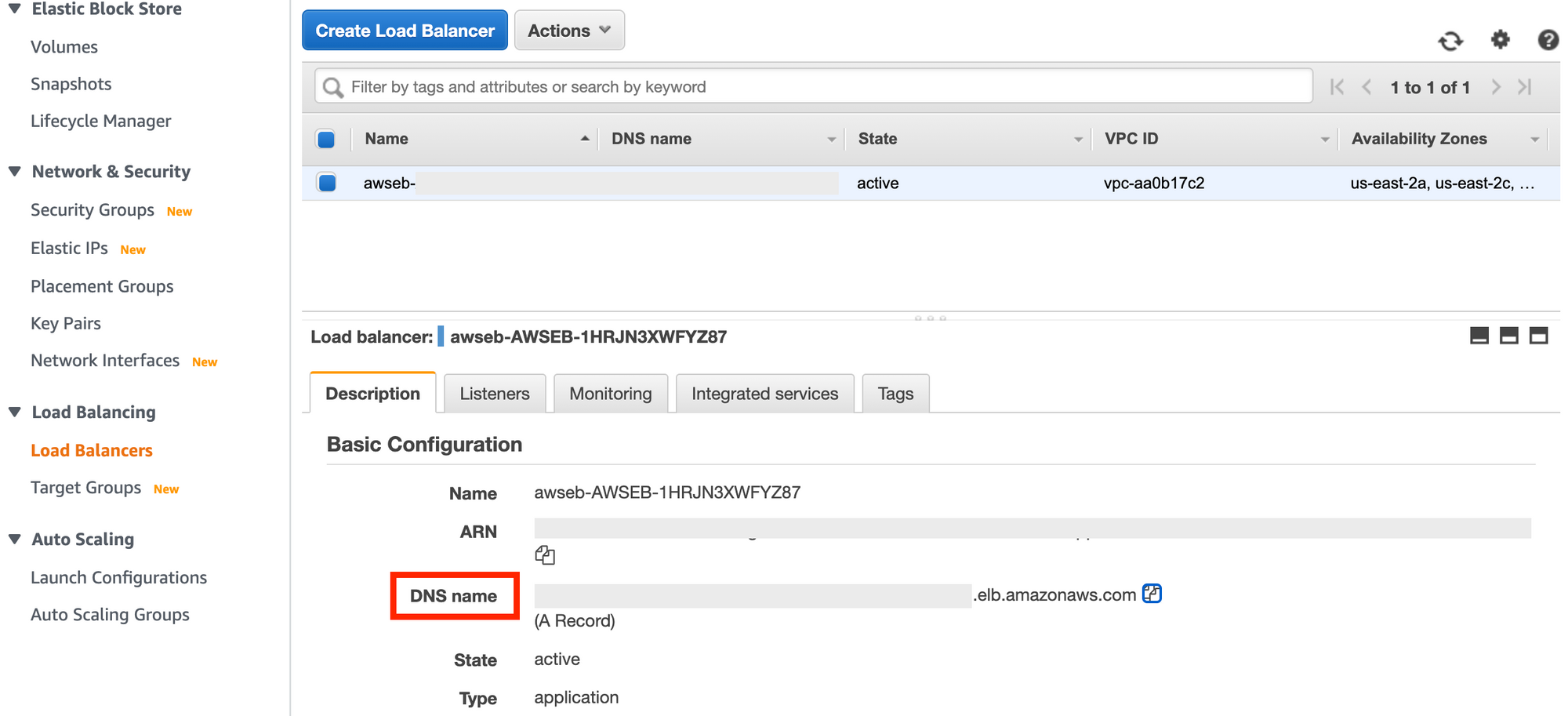 Vue du Load Balancer dans la console de gestion EC2
Vue du Load Balancer dans la console de gestion EC2
Maintenant, vous vous demandez peut-être : « Luke, comment puis-je faire pour lancer plus d'EC2 afin de pouvoir capitaliser sur cette action d'équilibrage de charge ? » Bonne question ! La réponse est les Auto Scaling Groups !
Auto Scaling Group
Comme le suggère le nom, ce service AWS met automatiquement à l'échelle un groupe d'Instances EC2 en fonction d'un ensemble de critères. Nous avons actuellement une seule Instance EC2 en cours d'exécution que notre Load Balancer cible, mais un Auto Scaling Group a des seuils configurables pour déterminer quand ajouter ou supprimer des instances.
Pour voir votre Auto Scaling Group, dans le panneau de navigation gauche de votre console de gestion EC2, faites défiler vers le bas jusqu'à ce que vous trouviez Auto Scaling Group et cliquez sur la case à cocher à côté du seul Auto Scaling Group listé.
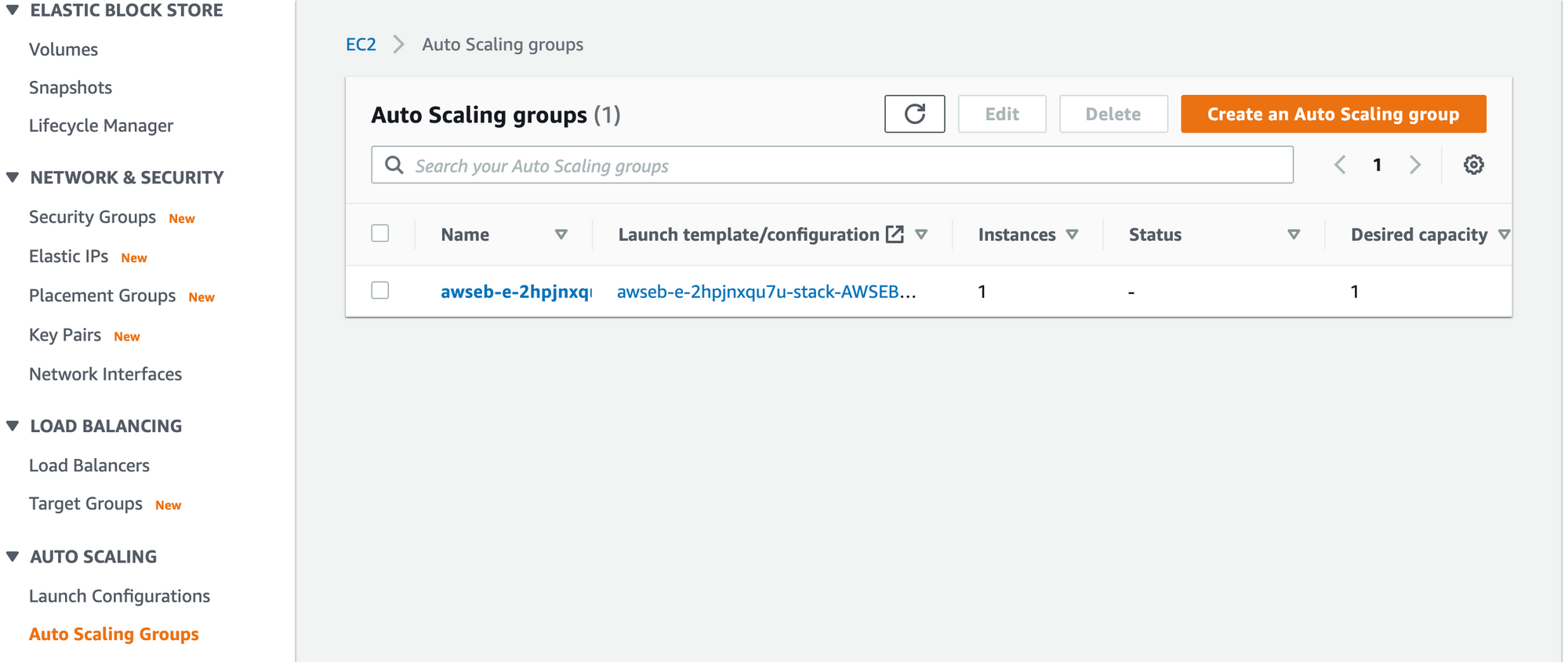 Liste des Auto Scaling Groups dans votre console de gestion EC2
Liste des Auto Scaling Groups dans votre console de gestion EC2
N'hésitez pas à parcourir les différents détails trouvés dans les onglets, mais je veux souligner quelques détails.
Tout d'abord, cliquez sur l'onglet Détails, et regardez les paramètres de capacité souhaitée, minimale et maximale. Ils devraient être par défaut à 1, 1 et 4 respectivement. Ces valeurs sont configurables et c'est notre moyen de dire à AWS combien d'Instances EC2 nous voulons en cours d'exécution.
Puisque les Instances EC2 coûtent de l'argent à exécuter, les entreprises veulent affiner la fréquence à laquelle de nouvelles instances sont ajoutées ou supprimées. Le nôtre indique que nous ne voulons qu'une seule instance en cours d'exécution, un minimum d'une instance en cours d'exécution et quatre au maximum. Si vous modifiez la valeur souhaitée à 2, vous verrez qu'une nouvelle instance sera lancée.
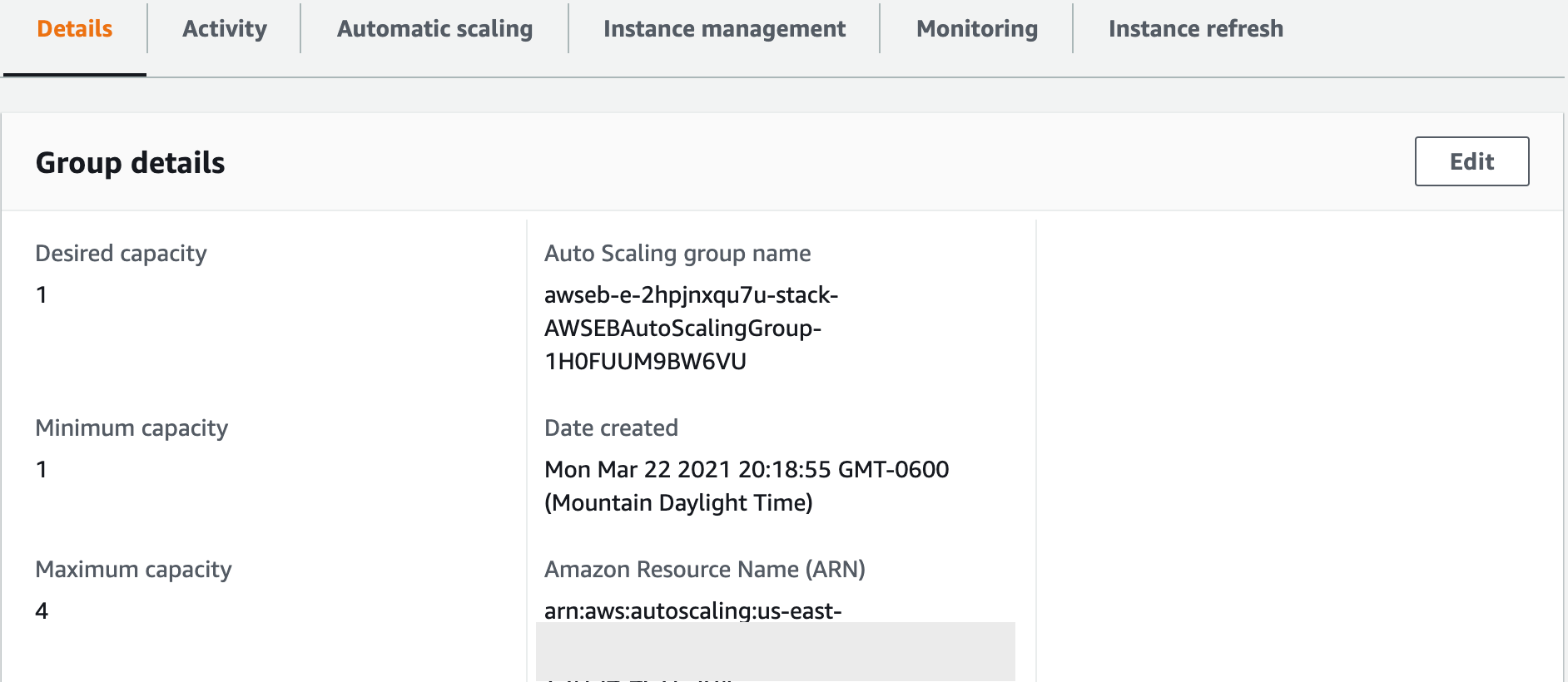 Nos paramètres de capacité de l'Auto Scaling Group
Nos paramètres de capacité de l'Auto Scaling Group
Mais comment l'Auto Scaling Group sait-il quand ajouter/supprimer des instances ? Cliquez sur l'onglet Mise à l'échelle automatique pour voir notre configuration actuelle pour déterminer quand ajouter/supprimer des instances.
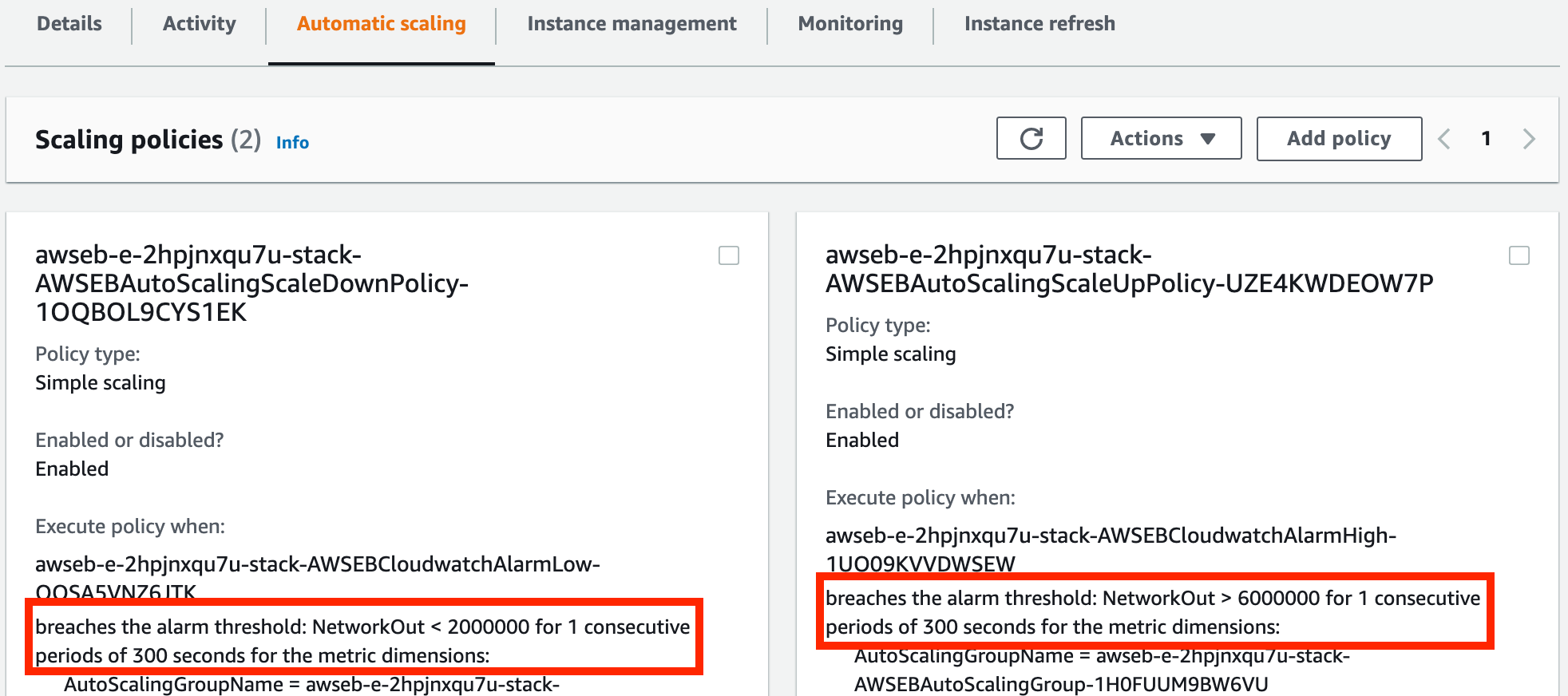 Paramètres de seuil pour notre Auto Scaling Group
Paramètres de seuil pour notre Auto Scaling Group
Ici, nous avons deux politiques : une pour la mise à l'échelle et une pour la réduction. J'ai mis en évidence le seuil actuel qui doit être atteint pour que l'une ou l'autre soit déclenchée.
Ce que cela dit, c'est « si un problème réseau survient sur une Instance EC2 pendant plus d'une période de cinq minutes, ajoutez une EC2 si nous n'avons pas atteint notre capacité maximale » et « si aucun problème réseau ne survient pendant cinq minutes, supprimez une EC2 si nous n'avons pas déjà atteint notre capacité souhaitée. »
Et voilà, notre application peut croître/réduire en fonction de nos configurations de l'Auto Scaling Group. Notre application peut maintenant gérer la charge supplémentaire de devenir virale !
Mais, une dernière question : comment l'Auto Scaling Group connaît-il les erreurs réseau de notre EC2 ? Entrez, CloudWatch.
CloudWatch
Si vous cliquez sur l'onglet Surveillance dans votre Auto Scaling Group, vous verrez des liens qui vous mèneront à CloudWatch. Une fois dans la console de gestion CloudWatch, vous verrez une variété de services et de ressources AWS listés ainsi que leurs métriques associées.
En parcourant la liste, vous trouverez EC2 et Auto Scaling Group, ainsi que les détails de surveillance pour chacun. D'où viennent toutes ces métriques ? AWS les fournit automatiquement pour vous, ainsi que ce tableau de bord utile, nous permettant de faire du réseau et de la programmation dynamiques assez cool basés sur des métriques individuelles ou composites, comme l'Auto Scaling.
L'Auto Scaling Group que nous avons a accès à ces métriques et surveille la métrique NetworkOut de nos Instances EC2 pour déterminer si une action de mise à l'échelle doit se produire.
Un autre exemple de l'avantage que nous tirons d'une plateforme de cloud computing.
Récapitulatif du déploiement ElasticBeanstalk
Nous avons examiné une deuxième méthode de déploiement d'une application : Elastic Beanstalk. Comparé à notre déploiement S3, cette méthode nous a obligés à ajouter plus de code pour configurer le service de notre index.html.
Nous avons utilisé Express.js, un framework d'application web Node.js, pour servir notre front-end, puis téléchargé notre projet nouvellement mis à jour sur Elastic Beanstalk. Cela a à son tour lancé une multitude de ressources et de services AWS pour nous.
Nous avons appris à connaître EC2, Load Balancer, Auto Scaling Group et CloudWatch, et comment ils travaillent ensemble pour livrer notre projet via un point de terminaison d'URL accessible mondialement.
Il existe encore plus de paramètres, de services et de ressources qu'Elastic Beanstalk configure et provisionne pour nous et que nous n'avons pas discutés, mais pour l'instant, vous avez fait un bon premier pas dans les avantages d'un fournisseur d'hébergement cloud et quelques-uns des principaux services AWS.
Comment déployer votre projet freeCodeCamp avec AWS Lambda
Pour la dernière partie de cet article, nous allons déployer notre code dans un environnement sans serveur. Les infrastructures sans serveur deviennent de plus en plus populaires et préférées à un serveur dédié sur site ou même un serveur hébergé (comme EC2).
Non seulement la voie sans serveur est plus rentable, mais elle se prête à une approche architecturale logicielle différente : les microservices.
Pour obtenir une introduction au monde sans serveur, nous allons déployer notre code via le service sans serveur d'AWS appelé Lambda et un autre service AWS, API Gateway. Commençons !
Qu'est-ce que le Serverless ?!
Dites, quoi ?! Tout ce temps, nous avons parlé de serveurs livrant notre code lorsque le navigateur web le demande, alors que signifie serverless ?
Pour commencer, cela ne signifie pas qu'il n'y a pas de serveur. Il doit y en avoir un, puisque un serveur est un ordinateur et nous avons besoin que notre programme s'exécute sur un ordinateur.
Donc, serverless ne signifie pas sans serveur. Cela signifie que vous et moi, les déployeurs de code, ne voyons jamais le serveur et n'avons aucune configuration à définir pour ce serveur. Le serveur appartient à AWS, et il exécute simplement notre code sans que nous fassions quoi que ce soit d'autre.
Serverless signifie que pour vous et moi, en pratique, il n'y a pas de serveur, mais en réalité, il y en a un.
Cela semble assez simple, non ? C'est le cas ! Nous n'avons pas de serveur à configurer, AWS a le serveur et gère tout. Nous fournissons simplement le code.
Vous vous demandez peut-être, en quoi cela est-il différent de EC2 ? Bonne question.
Il y a moins de configuration
Vous vous souvenez de toutes les options de configuration que nous pouvions modifier sur Elastic Beanstalk, et dans la console de gestion EC2, et le groupe de mise à l'échelle automatique, et l'équilibreur de charge ?
 Quelques-unes des configurations Elastic Beanstalk disponibles pour nous
Quelques-unes des configurations Elastic Beanstalk disponibles pour nous
Ensuite, Elastic Beanstalk a créé plus de ressources, toutes avec leurs propres configurations, comme l'équilibreur de charge et le groupe de mise à l'échelle automatique.
Eh bien, aussi agréable que ce soit que nous puissions configurer celles-ci, cela peut aussi être une corvée à mettre en place. Plus important encore, cela prend plus de temps à mettre en place, ce qui nous éloigne du temps passé à développer notre application réelle.
Avec un Lambda (un service sans serveur d'AWS), nous disons simplement : « hé, nous voulons un environnement Node.js pour exécuter notre code », et après cela, il n'y a plus de configurations à faire sur le serveur lui-même. Nous pouvons revenir à l'écriture de plus de code.
C'est moins cher
De plus, cet EC2 nous coûte de l'argent tant qu'il fonctionne. Maintenant, il est simple de le terminer ou de l'arrêter temporairement pour économiser de l'argent, et il est généralement moins cher que d'acheter votre propre serveur physique – mais il coûte toujours de l'argent à tout moment de la journée où il fonctionne, même si personne n'essaie d'accéder à votre site web.
Alors, que se passerait-il s'il y avait une option qui ne nous facture des frais que pour le temps d'exécution du code ? C'est le serverless !
Avec AWS Lambda, nous avons notre code capable de s'exécuter à tout moment, il est sur un serveur. Mais il n'exécute notre programme que lorsqu'il est demandé et nous ne payons que pour ces temps d'exécution. Les économies de coûts sont énormes.
Architecture de microservices
Parce que la plupart des programmes ont été écrits et déployés sur un serveur pour s'exécuter, tout le code de cette application a été regroupé afin que ce serveur puisse accéder et exécuter l'ensemble de l'application. Cela a du sens !
Mais, si vous avez un moyen d'exécuter du code avec une approche sans serveur, qui n'exécute que ce code demandé, vous pourriez diviser cette application en plusieurs applications. Cette division d'une application en sous-applications plus petites est l'idée des microservices.
L'un des principaux avantages d'une approche de microservices est le processus de mise à jour. Si nous avons une application monolithique (celle qui est regroupée sur un EC2), et que nous devons mettre à jour un petit morceau de code, alors nous devons redéployer l'ensemble de l'application, ce qui peut signifier des interruptions de service.
Alternativement, une approche de microservices signifie que nous ne mettons à jour que la sous-application de l'ensemble qui traite ce petit morceau de code. C'est une approche de déploiement moins abrupte, et l'un des principaux avantages d'une approche de microservices qu'AWS Lambda nous permet de faire.
Je devrais noter que le serverless a ses propres inconvénients. Pour commencer, si vous avez une architecture de microservices via serverless, alors l'intégration de ces microservices pour qu'ils communiquent entre eux nécessite un travail supplémentaire qu'une application monolithique n'a pas à gérer.
Cela dit, c'est une approche qui est massivement populaire et en croissance d'utilisation, donc cela vaut la peine de la connaître.
Avis de non-responsabilité : Maintenant, techniquement, l'utilisation de S3 dans la partie 1 était un déploiement sans serveur, mais généralement, lorsque les gens discutent du serverless et d'AWS, ils parlent de Lambda.
Comment commencer avec AWS Lambda
Donc, les Lambdas nous permettent d'exécuter du code sans nous soucier de la configuration du serveur ou des coûts. C'est tout. Ils s'exécutent sur un serveur appartenant à AWS, configuré par AWS, géré par AWS, et jamais vu par nous.
Pour la plupart, tout ce que nous contrôlons et qui nous intéresse est la fonction. C'est ce à quoi l'on fait référence comme fonction en tant que service dans le cloud computing. Cela nous permet de nous concentrer sur le code sans avoir à penser aux complexités de l'infrastructure.
Alors maintenant que nous savons que les Lambdas sont simplement des fonctions s'exécutant sur un serveur AWS que nous n'avons pas à configurer, commençons avec le nôtre.
Comment créer notre Lambda
Rendez-vous sur la console de gestion AWS Lambda. Cliquez sur le bouton Créer une fonction. Sur l'écran suivant, nous allons garder la sélection Créer à partir de zéro, entrer le nom de notre fonction (alias, le nom de notre Lambda), puis sélectionner l'environnement d'exécution Node.js 14.x.
C'est tout ce que nous devons faire pour l'instant, allez-y et cliquez sur le bouton Créer une fonction en bas à droite.
 Notre écran lors de la création de notre fonction Lambda
Notre écran lors de la création de notre fonction Lambda
L'écran suivant qui se charge sera notre console pour gérer un Lambda. Si vous faites défiler un peu vers le bas, vous trouverez un éditeur de code intégré et un système de fichiers. Un répertoire (alias dossier) avec le nom de votre Lambda est déjà présent ainsi qu'un fichier index.js. Cliquez sur Fichier et créez un nouveau fichier appelé index.html.
 Vous devriez avoir des fichiers index.js et index.html
Vous devriez avoir des fichiers index.js et index.html
Ajustez le code de votre projet
En raison de la nature de ce déploiement, nous devons ajuster un peu notre code. Au lieu d'utiliser la balise <link href="styles.css" /> et la balise <script src="main.js"></script> dans notre fichier index.html du projet freeCodeCamp qui lie notre code .css et .js à notre code HTML, nous allons les ajouter directement dans le fichier HTML.
Si nous ne faisons pas cela, alors lorsque nous essaierons d'ouvrir notre application, elle cherchera ces fichiers à une URL différente de celle que nous voulons.
Pour modifier le code afin qu'il fonctionne pour nous dans Lambda, procédez comme suit :
- Remplacez la ligne
<link href="styles.css"/>dans votre fichier index.html par<style></style>(ceci devrait être juste au-dessus de votre balise d'ouverture<body>) - Ouvrez votre fichier
styles.css, copiez tout le CSS et collez-le entre les deux balises<style>(comme<style> _votre code collé_). - Faites de même avec notre
main.js– supprimez lesrc="main.js"à l'intérieur de la balise d'ouverture<script>. - Ouvrez votre fichier main.js, copiez tout votre code JS et collez-le entre les deux balises
<script>en bas de notre fichier index.html (c'est-à-dire :<script> _votre code main.js_