
Article original : How to set timeouts dynamically using Lambda invocation context
Par Yan Cui
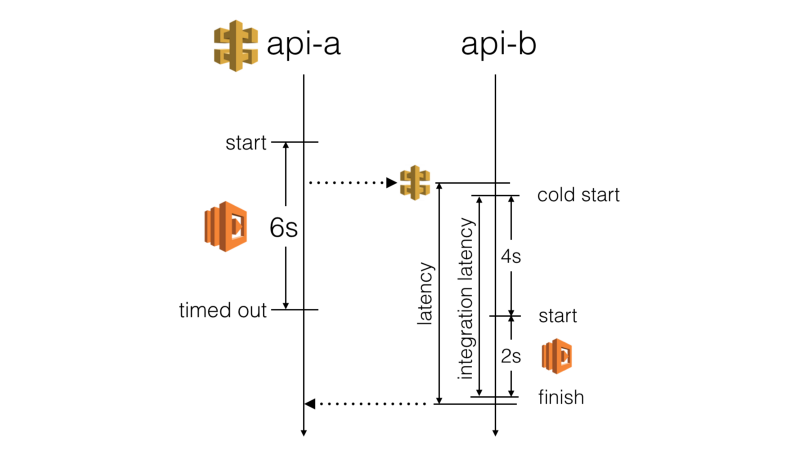
Avec API Gateway et Lambda, vous êtes obligé d'utiliser des timeouts courts côté serveur :
- API Gateway a un timeout maximum de 29s sur tous les points d'intégration
- Le framework Serverless utilise un timeout par défaut de 6s pour les fonctions AWS Lambda
Cependant, vous avez une influence limitée sur le temps de démarrage à froid d'une fonction Lambda. Et vous n'avez aucun contrôle sur la quantité de surcharge ajoutée par API Gateway. Ainsi, la latence réelle que vous pourriez attendre d'une fonction appelante est bien moins prévisible que vous pourriez le penser.
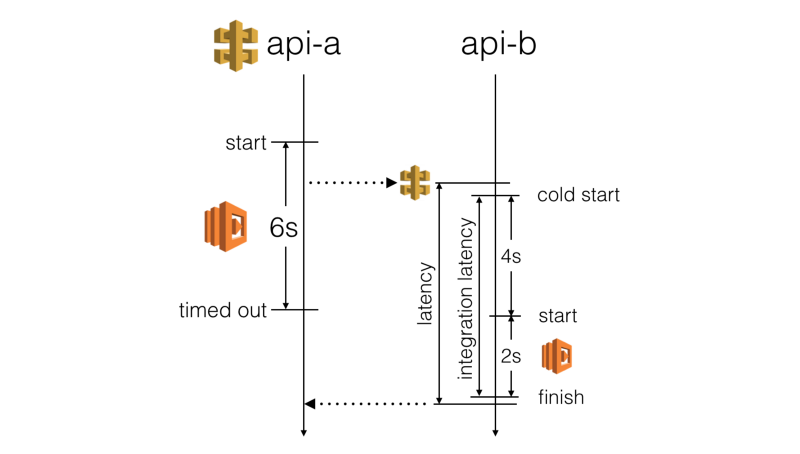

Nous ne voulons pas qu'une réponse HTTP lente provoque un timeout de la fonction appelante. Cela a un impact négatif sur l'expérience utilisateur. Au lieu de cela, nous devrions arrêter d'attendre une réponse avant que la fonction appelante ne dépasse le timeout.
« L'objectif de la stratégie de timeout est de donner aux requêtes HTTP la meilleure chance de réussir, à condition que cela ne provoque pas d'erreur de la fonction appelante elle-même. »
- Moi
La plupart du temps, je vois les gens utiliser des valeurs de timeout fixes, mais il est souvent difficile de décider :
- Trop court, et vous ne donnerez pas à la requête la meilleure chance de réussir. Par exemple, il reste 5s dans l'invocation, mais le timeout est défini à 3s.
- Trop long, et vous risquez de laisser la requête provoquer un timeout de la fonction appelante. Par exemple, il reste 5s dans l'invocation, mais le timeout est défini à 6s.
Les choses sont encore compliquées par le fait que nous effectuons souvent plus d'une requête HTTP pendant une invocation de fonction. Par exemple,
- lecture depuis DynamoDB
- exécution de la logique métier sur les données
- sauvegarde de la mise à jour dans DynamoDB
- publication d'un événement vers Kinesis
Examinons deux approches courantes pour choisir les valeurs de timeout et leurs limites.
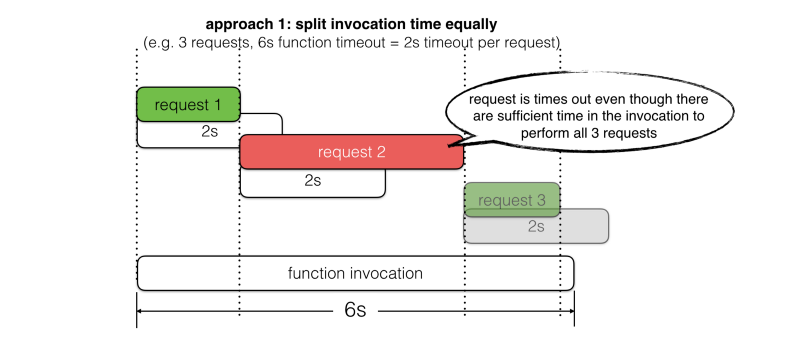
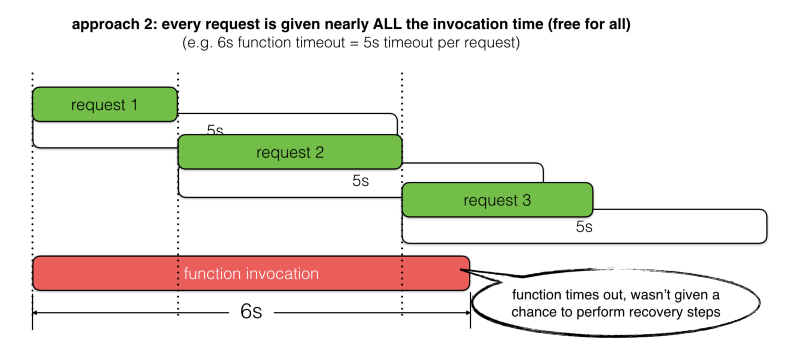
Au lieu de suivre ces approches, je propose que nous devrions définir le timeout de la requête en fonction du temps d'invocation restant. Nous devrions également réserver un peu de temps pour effectuer des étapes de récupération en cas d'échecs.
Vous pouvez savoir combien de temps il reste dans l'invocation actuelle via l'objet context.
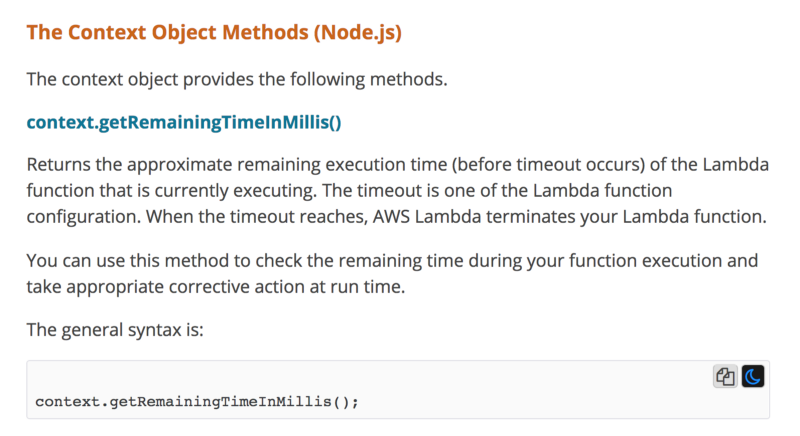
Par exemple, si le timeout d'une fonction est de 6s et que nous sommes à 1s dans l'invocation. Si nous réservons 500ms pour la récupération, il nous reste alors 4,5s pour attendre une réponse HTTP.
Avec cette approche, nous obtenons le meilleur des deux mondes :
- Permettre aux requêtes la meilleure chance de réussir en fonction du temps d'invocation réel restant
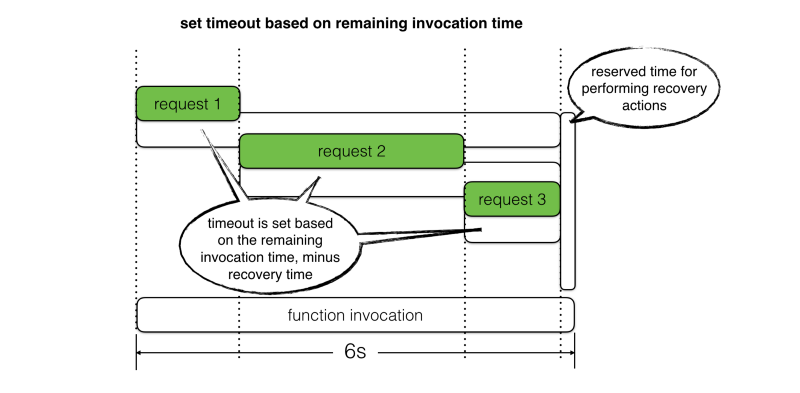
- Empêcher les réponses lentes de provoquer un timeout de la fonction, ce qui nous donne une fenêtre d'opportunité pour effectuer des actions de récupération.
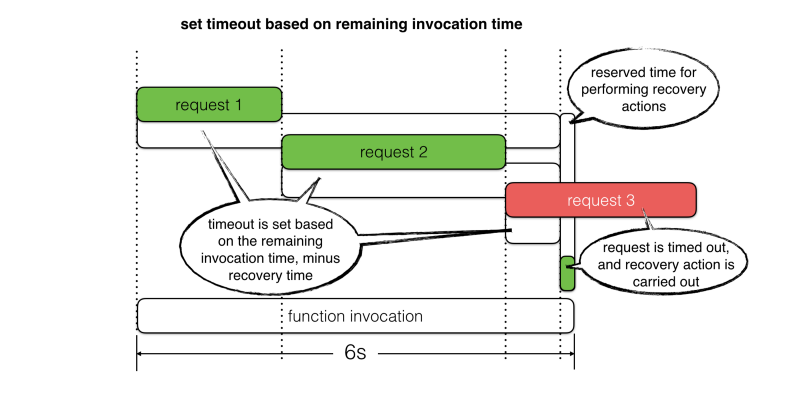
Mais que allez-vous faire après avoir interrompu ces requêtes ? N'allez-vous pas devoir répondre avec une erreur HTTP, puisque vous n'avez pas pu terminer les opérations nécessaires ?
Au minimum, les actions de récupération doivent inclure :
- Journaliser l'incident de timeout avec autant de contexte que possible. Par exemple, cible de la requête, valeur de timeout, ID de corrélation, et l'objet de la requête.
- Suivre des métriques personnalisées pour
serviceX.timedoutafin qu'elles puissent être surveillées et que l'équipe puisse être alertée si la situation s'aggrave - Retourner un code d'erreur d'application et l'ID de la requête originale dans le corps de la réponse. L'application cliente peut alors afficher un message convivial comme « Oups, il semble que cette fonctionnalité est actuellement indisponible, veuillez réessayer plus tard. Si c'est urgent, veuillez nous contacter à xxx@domain.com et mentionner l'ID de la requête f19a7dca. Merci pour votre coopération :-)
{ "errorCode": 10021, "requestId": "f19a7dca", "message": "service X timed out" }
Dans certains cas, vous pouvez également récupérer de manière encore plus élégante en utilisant des solutions de repli.
La bibliothèque Hystrix de Netflix prend en charge plusieurs types de solutions de repli via le modèle de commande qu'elle utilise largement. Je recommande de lire sa page wiki, car il y a beaucoup d'informations et d'idées utiles.

Chaque commande Hystrix vous permet de spécifier une action de repli.

Vous pouvez également enchaîner les solutions de repli ensemble en enchaînant les commandes via leurs méthodes getFallback respectives.
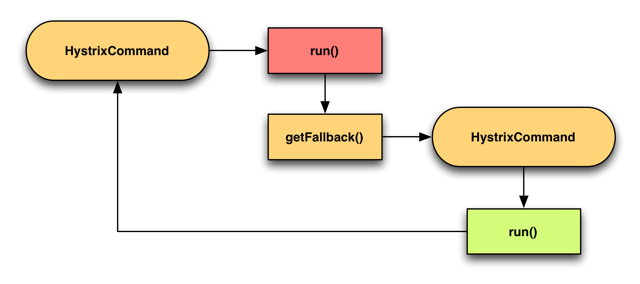
Par exemple,
- exécuter une lecture DynamoDB dans
CommandA - Dans la méthode
getFallback, exécuterCommandBqui retournerait une réponse mise en cache précédemment si disponible - Si aucune réponse mise en cache n'est disponible, alors
CommandBéchoue et déclenche sa propre méthodegetFallback - Exécuter
CommandC, qui retourne une réponse simulée
Vous devriez consulter Hystrix si vous ne l'avez pas déjà fait. La plupart des modèles intégrés à Hystrix peuvent être facilement adoptés dans nos applications serverless pour les rendre plus résistantes aux pannes.