

Article original : How to Debug Your Code Like a Competitive Programmer – Automate and Save Time
Par Alberto Gonzalez Rosales
Je suis un programmeur compétitif depuis de nombreuses années. Et pendant tout ce temps, j'ai été confronté au processus de débogage à de nombreuses reprises.
Dans cet article, je vais essayer de décrire comment le débogage fonctionne dans de tels environnements, au lieu de le dépeindre dans les activités régulières de développement logiciel que nous faisons chaque jour.
Mais pourquoi ? Vous pourriez demander.
La raison est que, en raison de la limite de temps courte fixée dans ces compétitions, les participants doivent trouver des idées créatives pour résoudre tous les problèmes auxquels ils sont confrontés. Il n'y a pas de lendemain pour eux. C'est soit "crack or go home".
Et parfois, ces idées peuvent être extrapolées au développement logiciel du "monde réel".
Sans plus attendre, voyons de quoi je parle.
Contexte
Les concours de programmation compétitive sont un type de compétition dans lequel chaque concurrent reçoit un ensemble de problèmes. L'idée est pour eux de résoudre le maximum de problèmes qu'ils peuvent dans la limite de temps fixée pour le concours, qui est généralement d'environ deux à cinq heures.
Chaque problème spécifie le format de l'entrée, et attend une certaine sortie en réponse. Par exemple, nous pourrions avoir un problème indiquant que vous devez trouver la somme des nombres dans une liste. Dans ce cas, l'entrée serait une liste de nombres, et la sortie serait un seul nombre.
Habituellement, ces compétitions se déroulent sur des plateformes automatisées qui peuvent recevoir des solutions pour chaque problème et évaluer ces solutions par rapport à un ensemble de données complet caché aux concurrents. Si une solution retourne la valeur attendue pour chaque ensemble de données, elle est dite "Acceptée", sinon elle est "Rejetée".
Comme vous pouvez l'imaginer, élaborer et soumettre des solutions précises est une compétence importante pour chaque participant, mais la rapidité l'est aussi. Trouver le bon équilibre entre la justesse et la vitesse est ce qui fait qu'un concurrent se hisse en haut du classement avec plus de problèmes résolus que ses rivaux.
Pas si loin de la "vie réelle", n'est-ce pas ?
Il est courant de voir des entreprises logicielles se battre pour voir laquelle est la plus rapide à atteindre certains objectifs ou laquelle donne de meilleurs résultats en regardant un sujet particulier. L'équilibre entre faire quelque chose correctement et le faire rapidement est toujours critique lorsqu'on travaille dans le développement logiciel.
Et c'est là que le débogage apparaît comme un facteur clé, car :
- Il garantit la justesse une fois les "bugs" traités.
- Il peut affecter la vitesse si le processus de recherche d'erreurs prend trop de temps.
Voyons ce qui se passe réellement pendant les concours de programmation compétitive, alors !
Le "Bug" contre-attaque
Lors de la participation à des concours de programmation, les bugs apparaissent souvent lorsque la performance est un facteur déterminant dans la solution d'un problème. C'est-à-dire, non seulement la sortie correcte est prise en compte, mais aussi le temps que votre solution prend pour retourner cette sortie pour l'ensemble de données.
Le cas suivant est le plus courant :
Nous lisons un problème, et nous connaissons une solution qui résout ce problème correctement. Mais malheureusement, elle ne sera pas assez rapide. Pas de souci, nous réfléchissons davantage au problème et nous trouvons une solution qui est également correcte, mais cette fois elle respectera la limite de temps fixée pour le problème.
Nous nous précipitons pour coder notre solution, la testons un peu avec quelques cas de test manuels, la soumettons, et... finissons par recevoir un verdict "Rejeté". Ce qui signifie que notre solution a retourné la mauvaise sortie pour une certaine entrée.
Que faites-vous dans ce cas ?
L'approche que la plupart des concurrents adoptent est de continuer à tester leurs solutions contre certains cas de test artisanaux qu'ils créent. Ils essaient de chercher des cas limites où la solution pourrait retourner la mauvaise sortie, mais ce n'est pas toujours facile à faire.
La frustration de voir votre programme retourner la sortie correcte pour chaque entrée que vous donnez, mais de savoir qu'il y a un cas de test caché dans lequel votre solution échoue, peut vous amener à arrêter d'essayer un problème dont vous êtes presque certain de connaître la solution.
Cela affectera, bien sûr, votre performance dans la compétition parce que vous avez investi du temps dans un problème que vous ne finirez pas par résoudre.
Donc, lorsque le processus de débogage prend trop de temps, il est bon de se tourner vers l'approche "faire trouver les bugs par l'ordinateur".
Voyons comment cela fonctionne !
Déboguer plus intelligemment, pas plus
Tout d'abord, bien sûr, l'ordinateur ne trouvera pas les bugs pour vous. Les bugs sont les vôtres et vous serez responsable de les trouver. Mais ce que l'ordinateur peut faire, c'est vous aider à générer suffisamment de données en peu de temps pour vous aider à trouver où votre solution échoue.
Vous souvenez-vous de cette solution dont nous avons parlé qui donnerait la sortie correcte mais qui n'était pas assez rapide ? Il est temps de l'utiliser.
Habituellement, cette solution sera plus facile à coder et moins sujette aux bugs. Disons que nous pouvons nous fier à elle parce que nous savons que nous sommes assez compétents pour résoudre n'importe quel problème en utilisant une approche sans réfléchir.
Vous souvenez-vous du processus de débogage précédent ?
- Générer une entrée artisanale.
- Exécuter votre solution avec cette entrée.
- Vérifier manuellement si la sortie retournée est correcte.
- Si elle n'est pas correcte, vous avez un cas de test à déboguer minutieusement. Sinon, répétez l'étape 1.
Cela est très inefficace pour une personne à faire. Surtout les étapes 1 et 3.
Ce que nous pouvons faire pour accélérer ce processus est de changer les vérifications que nous faisons à l'étape 3 pour qu'elles soient automatiques au lieu de manuelles. Et le moyen le plus facile de le faire est de comparer les sorties retournées par nos deux solutions (sans réfléchir et buggée) étant donné la même entrée.
Si nous avons codé notre solution sans réfléchir correctement (ce que nous sommes assez compétents pour faire, bien sûr), alors nous pouvons nous assurer que le moment où les sorties diffèrent, nous avons trouvé un cas de test qui mérite un examen plus approfondi.
D'accord. Mais qu'en est-il de l'étape 1 ?
Le processus de génération de cas de test peut être difficile, surtout si ce que nous essayons de faire est de trouver celui qui fait que notre solution retourne la mauvaise sortie. Je veux dire, si nous pouvions le faire facilement, alors nous aurions déjà corrigé notre solution 😅.
Heureusement, la solution à ce problème est de s'appuyer sur l'aléatoire. Oui, vous m'avez bien entendu. L'aléatoire offre un moyen spectaculaire de générer des entrées non biaisées et cela fonctionne surprenamment bien et rapidement dans la plupart des cas.
Nous pouvons remplacer notre processus artisanal de création de cas de test par un processus aléatoire automatisé, facile à coder, qui fera le travail pour nous.
Maintenant, le processus de débogage sera :
- Générer une entrée aléatoire.
- Exécuter les deux solutions avec cette entrée.
- Vérifier si les sorties diffèrent.
- Si elles diffèrent, vous avez un cas de test à déboguer minutieusement. Sinon, répétez l'étape 1.
La différence entre les deux approches est que la seconde peut être entièrement automatisée, et nous verrons comment le faire ensuite.
Mode de débogage automatisé
Automatisons notre processus de débogage, alors !
Nous commencerons avec ce code modèle en Python, que nous remplirons avec le code approprié pour nous aider à atteindre nos objectifs.
def no_brainer():
pass
def solution():
pass
def generate_input():
pass
def debug():
pass
if __name__ == "__main__":
debug()
Le but de cette implémentation est d'avoir la fonction debug générer un nouveau cas de test en utilisant la fonction generate_input, et de le fournir à notre solution et à notre solution no_brainer tant que les résultats sont les mêmes. Le moment où les résultats diffèrent, nous pouvons arrêter de générer de nouveaux cas de test et analyser celui qui fait échouer notre solution.
Un exemple réel
Rendons cela plus intéressant en résolvant un problème algorithmique classique :
"Étant donné un tableau trié d'entiers, et un entier x, trouver le premier indice du tableau contenant le nombre x, ou retourner -1 si le nombre n'apparaît pas dans le tableau".
Maintenant, parce que nous sommes intelligents, nous savons comment résoudre ce problème en utilisant une recherche linéaire sur le tableau. L'implémentation en Python pourrait être quelque chose comme ceci :
def no_brainer(a, x):
for i in range(len(a)):
if a[i] == x:
return i
return -1
C'est notre solution no_brainer. Juste une boucle for simple jusqu'à ce que nous trouvions l'élément que nous cherchons. Le moment où nous le trouvons, nous retournons l'indice où l'élément peut être trouvé. Et, au cas où nous ne le trouvons pas, nous retournons -1, comme demandé dans l'énoncé du problème.
Supposons que cette solution ne soit pas assez rapide. Peut-être est-ce parce que la taille du tableau est trop grande et, dans le pire des cas, notre solution finira par itérer à travers tous les éléments juste pour découvrir que le nombre que nous cherchions n'est pas présent dans le tableau du tout.
Mais, puisque le tableau est trié, peut-être pouvons-nous utiliser l'algorithme de recherche binaire, qui accélérera effectivement le processus de recherche. Cela semble être une bonne idée, n'est-ce pas ? Essayons-le !
def solution(a, x):
l = 0
r = len(a) - 1
while l <= r:
m = (l + r) // 2
if a[m] == x:
return m
elif a[m] < x:
l = m + 1
else:
r = m - 1
return -1
Le code ci-dessus essaie de trouver le nombre x dans le tableau, et il retourne également -1 s'il ne le trouve pas. Maintenant, il ne effectue pas une recherche linéaire, donc nous ne nous attendons pas à ce qu'il dépasse le temps, mais pour une raison quelconque, lorsque nous le soumettons pour révision, nous recevons un verdict "Rejeté".
Comme nous l'avons dit auparavant, nous ne nous précipiterons pas dans le débogage manuel. Au lieu de cela, commençons par créer un générateur aléatoire pour fournir des entrées aux deux solutions, espérant que nous trouverons bientôt le bug. Notre fonction de génération pourrait être quelque chose comme ceci :
import random
def generate_input():
n = random.randint(1, 10)
a = [random.randint(1, 10) for _ in range(n)]
a.sort()
x = a[random.randint(0, n - 1)]
return a, x
Nous générons des tableaux avec des tailles d'au plus 10, ce qui est un nombre gérable d'éléments. Nous nous assurons également que les éléments sont triés, et nous prenons le nombre x comme l'un des nombres présents dans le tableau.
Ce qui nous manque maintenant, c'est simplement de mettre toutes les pièces ensemble, comme ceci :
def debug():
test_cases = 10000
for _ in range(test_cases):
a, x = generate_input()
no_brainer_output = no_brainer(a, x)
solution_output = solution(a, x)
if no_brainer_output != solution_output:
print("Test Case:")
print(a, x)
print("Solution Output:", solution_output)
print("No-Brainer Output:", no_brainer_output)
exit()
print("All test cases passed succesfully")
En jetant un coup d'œil au code, nous pouvons voir les avantages d'avoir cela dans notre processus de débogage.
Remarquez que nous avons fixé une limite de 10000 cas de test. Ce nombre n'est pas réaliste pour une seule personne à générer, et il semble certainement être un nombre suffisamment grand qui pourrait garantir que nous trouverons un cas de test où nos solutions diffèrent.
D'autre part, une fois que nous avons corrigé notre solution, nous pouvons exécuter à nouveau ces 10000 cas à la recherche de nouveaux bugs. Le moment où toutes les sorties sont les mêmes, nous aurions une croyance plus forte en la justesse de notre algorithme après avoir passé autant de tests.
Voici la version complète de l'implémentation, au cas où vous voudriez voir le tableau complet :
import random
def no_brainer(a, x):
for i in range(len(a)):
if a[i] == x:
return i
return -1
def solution(a, x):
l = 0
r = len(a) - 1
while l <= r:
m = (l + r) // 2
if a[m] == x:
return m
elif a[m] < x:
l = m + 1
else:
r = m - 1
return -1
def generate_input():
n = random.randint(1, 10)
a = [random.randint(1, 10) for _ in range(n)]
a.sort()
x = a[random.randint(0, n - 1)]
return a, x
def debug():
test_cases = 10000
for _ in range(test_cases):
a, x = generate_input()
no_brainer_output = no_brainer(a, x)
solution_output = solution(a, x)
if no_brainer_output != solution_output:
print("Test Case:")
print(a, x)
print("Solution Output:", solution_output)
print("No-Brainer Output:", no_brainer_output)
exit()
print("All test cases passed succesfully")
if __name__ == "__main__":
debug()
Après avoir exécuté ce script, nous obtiendrons un résultat comme suit :
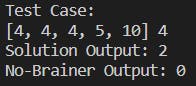
Dans ce cas, l'entrée consiste en le tableau [4, 4, 4, 5, 10] et le nombre 4. Cela signifie que nous devons trouver le premier indice où le nombre 4 apparaît dans le tableau.
Comme vous pouvez le voir, notre solution utilisant la recherche binaire retourne la valeur 2, qui est un indice où le nombre 4 est présent, mais ce n'est pas le premier. D'autre part, notre solution no-brainer retourne la valeur 0, qui est le premier indice dont la valeur est égale à 4.
Et, tout simplement, en quelques secondes, nous avons généré un cas de test qui montre que notre solution échoue. Maintenant, nous pouvons procéder à son analyse approfondie et corriger notre code.
Note : En guise d'exercice pour vous, je vais sauter la partie où j'explique ce qui ne va pas avec l'implémentation ci-dessus. Si vous réalisez quel est le problème, faites-le moi savoir afin que nous puissions commencer une discussion et continuer à apprendre en tant que communauté.
Une correction possible à notre implémentation est la suivante :
def solution(a, x):
l = 0
r = len(a) - 1
pos = -1
while l <= r:
m = (l + r) // 2
if a[m] >= x:
pos = m
r = m - 1
else:
l = m + 1
return pos
Voyons que lorsque nous exécutons le script, maintenant que nous avons modifié notre solution, nous obtenons le résultat gratifiant :
![]()
Ce qui nous donnera le courage de soumettre à nouveau notre implémentation.
Conclusion
Dans cet article, nous avons vu une approche efficace pour générer des cas de test afin de soumettre nos solutions à des tests de résistance. Nous avons automatisé le processus de création de chaque cas et de vérification de la justesse, ce qui rend la recherche de bugs dans le code moins chronophage.
L'approche vue ici est l'une des plus efficaces utilisées en programmation compétitive, mais elle peut certainement être extrapolée à des cas d'utilisation dans le développement logiciel du "monde réel".
Elle montre également comment vous pouvez tirer parti de la puissance de calcul présente dans les appareils que nous utilisons chaque jour pour accélérer le processus de débogage et livrer des fonctionnalités qui ont été testées minutieusement tout en étant encore en mesure de respecter vos délais.
Au cours de mon parcours en programmation compétitive à l'université, j'ai implémenté ce type de débogage non seulement dans des compétitions individuelles, mais aussi dans des concours en équipe. En conséquence, mes coéquipiers et moi avons gagné en vitesse lors des compétitions et avons pu obtenir des résultats impressionnants.
Nous sommes tous d'accord pour dire que cette méthode de débogage a joué un rôle important dans nos réalisations en tant que programmeurs compétitifs. Nous sommes passés d'enthousiastes de la programmation à finalistes mondiaux de l'ICPC en nous assurant que nous étions les plus productifs possible pendant le temps limité dont nous disposions dans chaque concours. Et je vous assure : il n'y a pas de concours sans débogage.
Je vous recommande d'essayer. Faites-moi savoir vos résultats !
👋 Bonjour, je suis Alberto, Développeur Logiciel chez doWhile, Programmeur Compétitif, Enseignant et Passionné de Fitness.
🏆 Si vous avez aimé cet article, envisagez de le partager.
🔗 Tous les liens | Twitter | LinkedIn