

Article original : How to make your own sentiment analyzer using Python and Google’s Natural Language API
Par Dzaky Widya Putra
Imaginez que vous êtes un propriétaire de produit qui souhaite savoir ce que les gens disent de votre produit sur les réseaux sociaux. Peut-être que votre entreprise a lancé un nouveau produit et vous voulez savoir comment les gens ont réagi. Vous pourriez vouloir utiliser un analyseur de sentiment comme MonkeyLearn ou Talkwalker. Mais ne serait-ce pas cool si nous pouvions créer notre propre analyseur de sentiment ? Faisons-le alors !
Dans ce tutoriel, nous allons créer un bot Telegram qui effectuera l'analyse de sentiment des tweets liés au mot-clé que nous définissons.
Si c'est la première fois que vous construisez un bot Telegram, vous pourriez vouloir lire cet article d'abord.
Pour commencer
1. Installer les bibliothèques
Nous allons utiliser tweepy pour collecter les données des tweets. Nous utiliserons nltk pour nous aider à nettoyer les tweets. Google Natural Language API effectuera l'analyse de sentiment. python-telegram-bot enverra le résultat via le chat Telegram.
pip3 install tweepy nltk google-cloud-language python-telegram-bot
2. Obtenir les clés de l'API Twitter
Pour pouvoir collecter les tweets depuis Twitter, nous devons créer un compte développeur pour obtenir les clés de l'API Twitter.
Allez sur le site Twitter Developer et créez un compte si vous n'en avez pas.
Ouvrez la page Apps, cliquez sur "Create an app", remplissez le formulaire et cliquez sur "Create".
Cliquez sur l'onglet "Keys and tokens", copiez la clé API et la clé secrète API dans la section "Consumer API keys".
Cliquez sur le bouton "Create" sous la section "Access token & access token secret". Copiez le jeton d'accès et le secret du jeton d'accès qui ont été générés.

Super ! Maintenant, vous devriez avoir quatre clés — Clé API, Clé secrète API, Jeton d'accès et Secret du jeton d'accès. Enregistrez ces clés pour une utilisation ultérieure.
3. Activer l'API Google Natural Language
Nous devons activer l'API Google Natural Language si nous voulons utiliser le service.
Allez sur Google Developers Console et créez un nouveau projet (ou sélectionnez celui que vous avez).
Dans le tableau de bord du projet, cliquez sur "ENABLE APIS AND SERVICES", et recherchez Cloud Natural Language API.
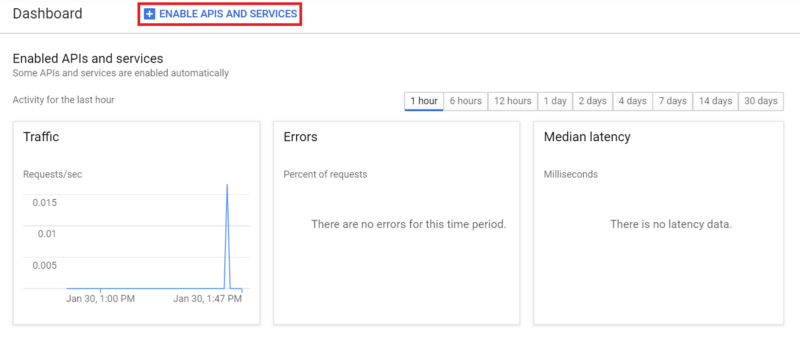
Cliquez sur "ENABLE" pour activer l'API.
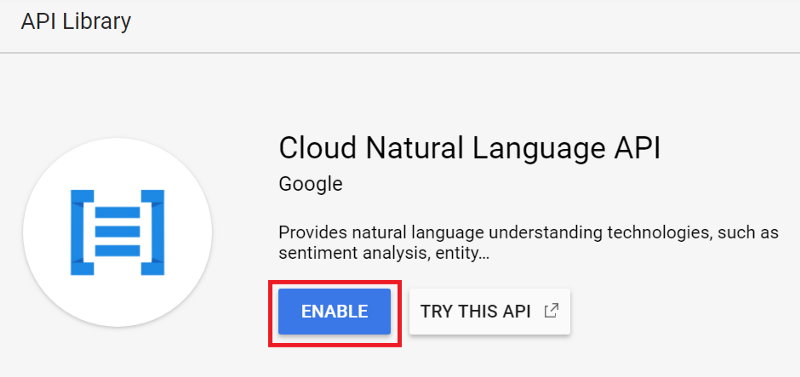
4. Créer une clé de compte de service
Si nous voulons utiliser les services Google Cloud comme Google Natural Language, nous avons besoin d'une clé de compte de service. C'est comme notre identifiant pour utiliser les services de Google.
Allez sur Google Developers Console, cliquez sur l'onglet "Credentials", choisissez "Create credentials" et cliquez sur "Service account key".
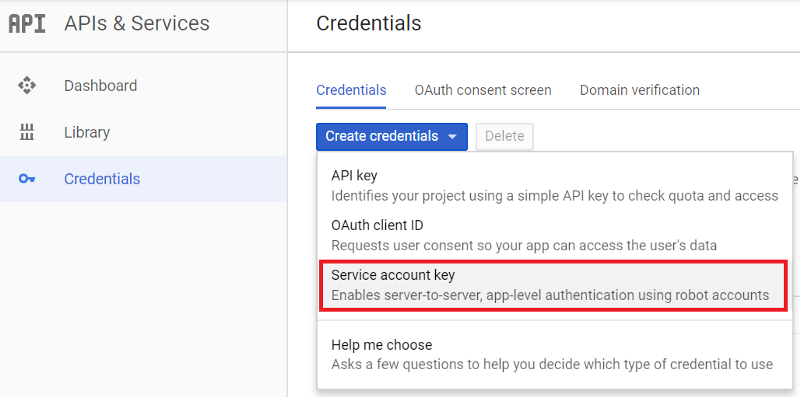
Choisissez "App Engine default service account" et JSON comme type de clé, puis cliquez sur "Create".
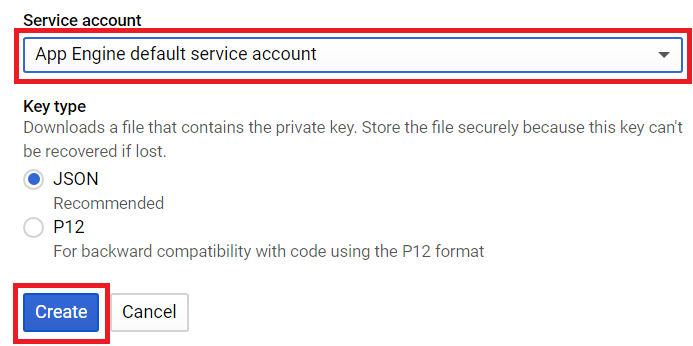
Un fichier .json sera automatiquement téléchargé, nommez-le creds.json.
Définissez la variable GOOGLE_APPLICATION_CREDENTIALS avec le chemin de notre fichier creds.json dans le terminal.
export GOOGLE_APPLICATION_CREDENTIALS='[PATH_TO_CREDS.JSON]'
Si tout est bon, alors il est temps d'écrire notre programme.
Écrire le programme
Ce programme collectera tous les tweets contenant le mot-clé défini dans les dernières 24 heures avec un maximum de 50 tweets. Ensuite, il analysera les sentiments des tweets un par un. Nous enverrons le résultat (score de sentiment moyen) via le chat Telegram.
Voici un flux de travail simple de notre programme.
connecter à l'API Twitter -> rechercher des tweets basés sur le mot-clé -> nettoyer tous les tweets -> obtenir le score de sentiment du tweet -> envoyer le résultat
Créons une fonction unique pour définir chaque flux.
1. Se connecter à l'API Twitter
La première chose que nous devons faire est de collecter les données des tweets, donc nous devons nous connecter à l'API Twitter.
Importez la bibliothèque tweepy.
import tweepy
Définissez les clés que nous avons générées précédemment.
ACC_TOKEN = 'YOUR_ACCESS_TOKEN'
ACC_SECRET = 'YOUR_ACCESS_TOKEN_SECRET'
CONS_KEY = 'YOUR_CONSUMER_API_KEY'
CONS_SECRET = 'YOUR_CONSUMER_API_SECRET_KEY'
Créez une fonction appelée authentication pour se connecter à l'API, avec quatre paramètres qui sont toutes les clés.
def authentication(cons_key, cons_secret, acc_token, acc_secret):
auth = tweepy.OAuthHandler(cons_key, cons_secret)
auth.set_access_token(acc_token, acc_secret)
api = tweepy.API(auth)
return api
2. Rechercher les tweets
Nous pouvons rechercher les tweets avec deux critères, basés sur le temps ou la quantité. Si c'est basé sur le temps, nous définissons l'intervalle de temps et si c'est basé sur la quantité, nous définissons le nombre total de tweets que nous voulons collecter. Puisque nous voulons collecter les tweets des dernières 24 heures avec un maximum de 50 tweets, nous utiliserons les deux critères.
Puisque nous voulons collecter les tweets des dernières 24 heures, prenons la date d'hier comme paramètre de temps.
from datetime import datetime, timedelta
today_datetime = datetime.today().now()
yesterday_datetime = today_datetime - timedelta(days=1)
today_date = today_datetime.strftime('%Y-%m-%d')
yesterday_date = yesterday_datetime.strftime('%Y-%m-%d')
Connectez-vous à l'API Twitter en utilisant une fonction que nous avons définie précédemment.
api = authentication(CONS_KEY,CONS_SECRET,ACC_TOKEN,ACC_SECRET)
Définissez nos paramètres de recherche. q est l'endroit où nous définissons notre mot-clé, since est la date de début pour notre recherche, result_type='recent' signifie que nous allons prendre les tweets les plus récents, lang='en' va prendre uniquement les tweets en anglais, et items(total_tweets) est l'endroit où nous définissons le nombre maximum de tweets que nous allons prendre.
search_result = tweepy.Cursor(api.search,
q=keyword,
since=yesterday_date,
result_type='recent',
lang='en').items(total_tweets)
Enveloppez ces codes dans une fonction appelée search_tweets avec keyword et total_tweets comme paramètres.
def search_tweets(keyword, total_tweets):
today_datetime = datetime.today().now()
yesterday_datetime = today_datetime - timedelta(days=1)
today_date = today_datetime.strftime('%Y-%m-%d')
yesterday_date = yesterday_datetime.strftime('%Y-%m-%d')
api = authentication(CONS_KEY,CONS_SECRET,ACC_TOKEN,ACC_SECRET)
search_result = tweepy.Cursor(api.search,
q=keyword,
since=yesterday_date,
result_type='recent',
lang='en').items(total_tweets)
return search_result
3. Nettoyer les tweets
Avant d'analyser le sentiment des tweets, nous devons nettoyer un peu les tweets afin que l'API Google Natural Language puisse mieux les identifier.
Nous allons utiliser les bibliothèques nltk et regex pour nous aider dans ce processus.
import re
from nltk.tokenize import WordPunctTokenizer
Nous supprimons le nom d'utilisateur dans chaque tweet, donc essentiellement nous pouvons supprimer tout ce qui commence par @ et nous utilisons regex pour le faire.
user_removed = re.sub(r'@[A-Za-z0-9]+','',tweet.decode('utf-8'))
Nous supprimons également les liens dans chaque tweet.
link_removed = re.sub('https?://[A-Za-z0-9./]+','',user_removed)
Les nombres sont également supprimés de tous les tweets.
number_removed = re.sub('[^a-zA-Z]',' ',link_removed)
Enfin, convertissez tous les caractères en minuscules, puis supprimez chaque espace inutile.
lower_case_tweet = number_removed.lower()
tok = WordPunctTokenizer()
words = tok.tokenize(lower_case_tweet)
clean_tweet = (' '.join(words)).strip()
Enveloppez ces codes dans une fonction appelée clean_tweets avec tweet comme paramètre.
def clean_tweets(tweet):
user_removed = re.sub(r'@[A-Za-z0-9]+','',tweet.decode('utf-8'))
link_removed = re.sub('https?://[A-Za-z0-9./]+','',user_removed)
number_removed = re.sub('[^a-zA-Z]', ' ', link_removed)
lower_case_tweet= number_removed.lower()
tok = WordPunctTokenizer()
words = tok.tokenize(lower_case_tweet)
clean_tweet = (' '.join(words)).strip()
return clean_tweet
4. Obtenir le score de sentiment du tweet
Pour pouvoir obtenir le score de sentiment d'un tweet, nous allons utiliser l'API Google Natural Language.
L'API fournit l'analyse de sentiment, l'analyse des entités et l'analyse syntaxique. Nous n'utiliserons que l'analyse de sentiment pour ce tutoriel.
Dans l'analyse de sentiment de Google, il y a score et magnitude. Score est le score du sentiment allant de -1.0 (très négatif) à 1.0 (très positif). Magnitude est la force du sentiment et va de 0 à l'infini.
Pour simplifier ce tutoriel, nous ne considérerons que le score. Si vous envisagez de faire une analyse NLP approfondie, vous devriez également considérer la magnitude.
Importez la bibliothèque Google Natural Language.
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import types
Créez une fonction appelée get_sentiment_score qui prend tweet comme paramètre et retourne le score de sentiment.
def get_sentiment_score(tweet):
client = language.LanguageServiceClient()
document = types\
.Document(content=tweet,
type=enums.Document.Type.PLAIN_TEXT)
sentiment_score = client\
.analyze_sentiment(document=document)\
.document_sentiment\
.score
return sentiment_score
5. Analyser les tweets
Créons une fonction qui parcourra la liste des tweets que nous obtenons de la fonction search_tweets et obtiendra le score de sentiment de chaque tweet en utilisant la fonction get_sentiment_score. Ensuite, nous calculerons la moyenne. Le score moyen déterminera si le mot-clé donné a un sentiment positif, neutre ou négatif.
Définissez score égal à 0, puis utilisez la fonction search_tweets pour obtenir les tweets liés au mot-clé que nous définissons.
score = 0
tweets = search_tweets(keyword, total_tweets)
Parcourez la liste des tweets et effectuez le nettoyage en utilisant la fonction clean_tweets que nous avons créée précédemment.
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
Obtenez le score de sentiment en utilisant la fonction get_sentiment_score et incrémentez le score en ajoutant sentiment_score.
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_score
Affichons chaque tweet et son sentiment afin que nous puissions voir le détail de la progression dans le terminal.
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_score
print('Tweet: {}'.format(cleaned_tweet))
print('Score: {}\n'.format(sentiment_score))
Calculez le score moyen et passez-le à la variable final_score. Enveloppez tous les codes dans la fonction analyze_tweets, avec keyword et total_tweets comme paramètres.
def analyze_tweets(keyword, total_tweets):
score = 0
tweets = search_tweets(keyword, total_tweets)
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_score
print('Tweet: {}'.format(cleaned_tweet))
print('Score: {}\n'.format(sentiment_score))
final_score = round((score / float(total_tweets)),2)
return final_score
6. Envoyer le score de sentiment du tweet
Créons la dernière fonction du flux de travail. Cette fonction prendra le mot-clé de l'utilisateur et calculera le score moyen du sentiment. Ensuite, nous l'enverrons via Telegram Bot.
Obtenez le mot-clé de l'utilisateur.
keyword = update.message.text
Utilisez la fonction analyze_tweets pour obtenir le score final, keyword comme paramètre, et définissez total_tweets = 50 puisque nous voulons collecter 50 tweets.
final_score = analyze_tweets(keyword, 50)
Nous définissons si un score donné est considéré comme négatif, neutre ou positif en utilisant la plage de scores de Google, comme nous le voyons dans l'image ci-dessous.

if final_score <= -0.25:
status = 'NÉGATIF ❌'
elif final_score <= 0.25:
status = 'NEUTRE ?'
else:
status = 'POSITIF ✅'
Enfin, envoyez le final_score et le status via Telegram Bot.
bot.send_message(chat_id=update.message.chat_id,
text='Score moyen pour '
+ str(keyword)
+ ' est '
+ str(final_score)
+ ' '
+ status)
Enveloppez les codes dans une fonction appelée send_the_result.
def send_the_result(bot, update):
keyword = update.message.text
final_score = analyze_tweets(keyword, 50)
if final_score <= -0.25:
status = 'NÉGATIF ❌'
elif final_score <= 0.25:
status = 'NEUTRE ?'
else:
status = 'POSITIF ✅'
bot.send_message(chat_id=update.message.chat_id,
text='Score moyen pour '
+ str(keyword)
+ ' est '
+ str(final_score)
+ ' '
+ status)
7. Programme principal
Enfin, créez une autre fonction appelée main pour exécuter notre programme. N'oubliez pas de changer YOUR_TOKEN par le jeton de votre bot.
from telegram.ext import Updater, MessageHandler, Filters
def main():
updater = Updater('YOUR_TOKEN')
dp = updater.dispatcher
dp.add_handler(MessageHandler(Filters.text, send_the_result))
updater.start_polling()
updater.idle()
if __name__ == '__main__':
main()
À la fin, votre code devrait ressembler à ceci
import tweepy
import re
from telegram.ext import Updater, MessageHandler, Filters
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import types
from datetime import datetime, timedelta
from nltk.tokenize import WordPunctTokenizer
ACC_TOKEN = 'YOUR_ACCESS_TOKEN'
ACC_SECRET = 'YOUR_ACCESS_TOKEN_SECRET'
CONS_KEY = 'YOUR_CONSUMER_API_KEY'
CONS_SECRET = 'YOUR_CONSUMER_API_SECRET_KEY'
def authentication(cons_key, cons_secret, acc_token, acc_secret):
auth = tweepy.OAuthHandler(cons_key, cons_secret)
auth.set_access_token(acc_token, acc_secret)
api = tweepy.API(auth)
return api
def search_tweets(keyword, total_tweets):
today_datetime = datetime.today().now()
yesterday_datetime = today_datetime - timedelta(days=1)
today_date = today_datetime.strftime('%Y-%m-%d')
yesterday_date = yesterday_datetime.strftime('%Y-%m-%d')
api = authentication(CONS_KEY,CONS_SECRET,ACC_TOKEN,ACC_SECRET)
search_result = tweepy.Cursor(api.search,
q=keyword,
since=yesterday_date,
result_type='recent',
lang='en').items(total_tweets)
return search_result
def clean_tweets(tweet):
user_removed = re.sub(r'@[A-Za-z0-9]+','',tweet.decode('utf-8'))
link_removed = re.sub('https?://[A-Za-z0-9./]+','',user_removed)
number_removed = re.sub('[^a-zA-Z]', ' ', link_removed)
lower_case_tweet= number_removed.lower()
tok = WordPunctTokenizer()
words = tok.tokenize(lower_case_tweet)
clean_tweet = (' '.join(words)).strip()
return clean_tweet
def get_sentiment_score(tweet):
client = language.LanguageServiceClient()
document = types\
.Document(content=tweet,
type=enums.Document.Type.PLAIN_TEXT)
sentiment_score = client\
.analyze_sentiment(document=document)\
.document_sentiment\
.score
return sentiment_score
def analyze_tweets(keyword, total_tweets):
score = 0
tweets = search_tweets(keyword,total_tweets)
for tweet in tweets:
cleaned_tweet = clean_tweets(tweet.text.encode('utf-8'))
sentiment_score = get_sentiment_score(cleaned_tweet)
score += sentiment_score
print('Tweet: {}'.format(cleaned_tweet))
print('Score: {}\n'.format(sentiment_score))
final_score = round((score / float(total_tweets)),2)
return final_score
def send_the_result(bot, update):
keyword = update.message.text
final_score = analyze_tweets(keyword, 50)
if final_score <= -0.25:
status = 'NÉGATIF ❌'
elif final_score <= 0.25:
status = 'NEUTRE ?'
else:
status = 'POSITIF ✅'
bot.send_message(chat_id=update.message.chat_id,
text='Score moyen pour '
+ str(keyword)
+ ' est '
+ str(final_score)
+ ' '
+ status)
def main():
updater = Updater('YOUR_TOKEN')
dp = updater.dispatcher
dp.add_handler(MessageHandler(Filters.text, send_the_result))
updater.start_polling()
updater.idle()
if __name__ == '__main__':
main()
Enregistrez le fichier et nommez-le main.py, puis exécutez le programme.
python3 main.py
Allez sur votre bot Telegram en accédant à cette URL : [https://telegram.me/YOUR_BOT_USERNAME](https://telegram.me/YOUR_BOT_USERNAME.). Tapez n'importe quel produit, nom de personne, ou ce que vous voulez et envoyez-le à votre bot. Si tout fonctionne, il devrait y avoir un score de sentiment détaillé pour chaque tweet dans le terminal. Le bot répondra avec le score de sentiment moyen.
Les images ci-dessous sont un exemple si je tape valentino rossi et l'envoie au bot.

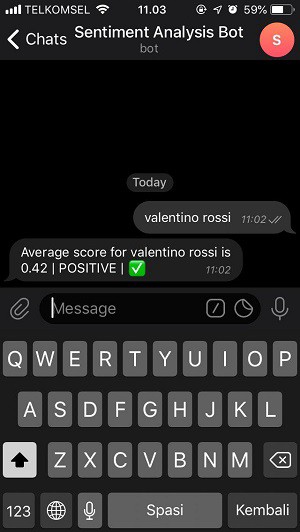
Si vous avez réussi à suivre les étapes jusqu'à la fin de ce tutoriel, c'est génial ! Vous avez maintenant votre analyseur de sentiment, n'est-ce pas cool ?
Vous pouvez également consulter mon GitHub pour obtenir le code. N'hésitez pas à me contacter et à laisser un message sur mon profil Linkedin si vous voulez poser des questions.
Veuillez laisser un commentaire si vous pensez qu'il y a des erreurs dans mon code ou mon écriture.
Merci et bonne chance ! 😊