Article original : How to Build a Local RAG App with Ollama and ChromaDB in the R Programming Language
Un grand modèle de langage (LLM) est un type de modèle d'apprentissage automatique qui est formé pour comprendre et générer du texte similaire à celui des humains. Ces modèles sont formés sur de vastes ensembles de données pour capturer les nuances du langage humain, leur permettant de générer des réponses cohérentes et contextuellement pertinentes.
Vous pouvez améliorer les performances d'un LLM en fournissant du contexte - des données structurées ou non structurées, telles que des documents, des articles ou des bases de connaissances - adaptées au domaine ou aux informations que vous souhaitez que le modèle spécialise. En utilisant des techniques comme l'ingénierie des prompts et l'injection de contexte, vous pouvez construire un chatbot intelligent capable de naviguer dans des ensembles de données étendus, de récupérer des informations pertinentes et de fournir des réponses.
Qu'il s'agisse de stocker des recettes, de la documentation de code, des articles de recherche ou de répondre à des requêtes spécifiques à un domaine, un chatbot basé sur un LLM peut s'adapter à vos besoins avec personnalisation et confidentialité. Vous pouvez le déployer localement pour créer un assistant conversationnel hautement spécialisé qui respecte vos données.
Dans cet article, vous apprendrez à construire une application locale de génération augmentée par récupération (RAG) en utilisant Ollama et ChromaDB dans R. À la fin, vous aurez un assistant conversationnel personnalisé avec une interface Shiny qui récupère efficacement les informations tout en maintenant la confidentialité et la personnalisation.
Table des matières
Comment configurer la base de données vectorielle pour le stockage des embeddings
Comment écrire la fonction d'embedding de requête d'entrée utilisateur
Comment initialiser le système de chat, concevoir des prompts et intégrer des outils
Comment interagir avec votre chatbot en utilisant une application Shiny
Qu'est-ce que le RAG ?
La génération augmentée par récupération (RAG) est une méthode qui intègre des systèmes de récupération avec l'IA générative, permettant aux chatbots d'accéder à des informations récentes et spécifiques à partir de sources externes.
En utilisant un pipeline de récupération, le chatbot peut récupérer des données à jour et pertinentes et les combiner avec les capacités linguistiques du modèle génératif, produisant des réponses à la fois précises et contextuellement enrichies. Cela rend le RAG particulièrement utile pour les applications nécessitant une livraison de connaissances factuelles et en temps réel.
Aperçu du projet
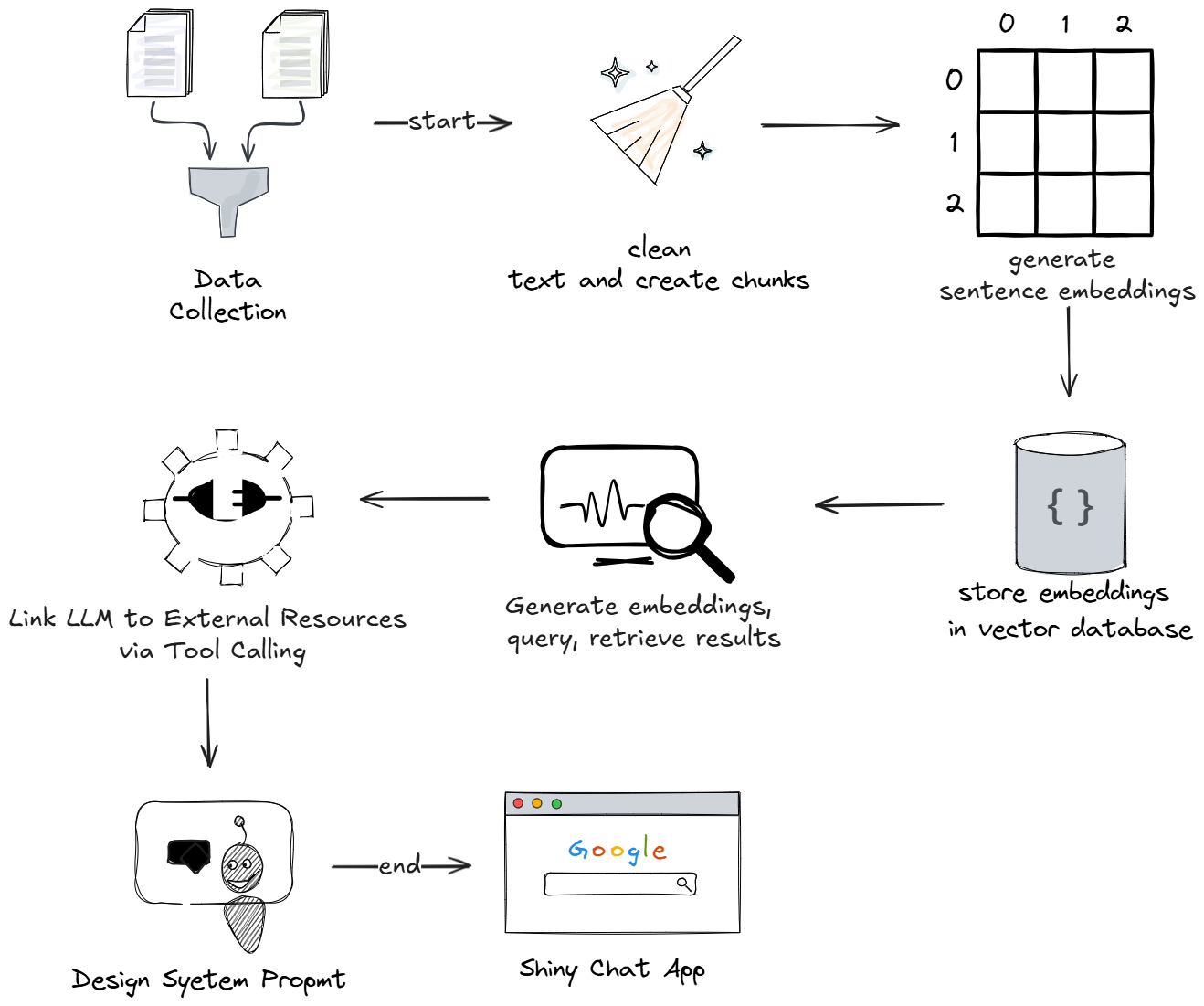
Installation du projet
Prérequis
Avant de commencer, assurez-vous d'avoir installé la dernière version des éléments listés ici :
RStudio : L'IDE - RStudio est l'espace de travail principal où vous écriverez et testerez votre code R. Son interface conviviale, ses outils de débogage et son environnement intégré en font un outil idéal pour l'analyse de données et le développement de chatbots.
R : Le langage de programmation - R est l'épine dorsale de votre projet. Vous l'utiliserez pour manipuler des données, appliquer des modèles statistiques et intégrer les composants de votre chatbot de recettes de manière transparente.
Python - Certaines bibliothèques, comme la bibliothèque d'embedding que vous utiliserez pour la vectorisation de texte, sont construites sur Python. Il est vital d'avoir Python installé pour activer ces fonctionnalités en parallèle de votre code R.
Java - Java sert d'élément fondamental pour certaines bibliothèques d'embedding. Il assure un traitement efficace et une compatibilité pour les tâches d'embedding de texte nécessaires à l'entraînement de votre chatbot.
Docker Desktop - Docker Desktop vous permet d'exécuter ChromaDB, la base de données vectorielle, localement sur votre machine. Cela permet un stockage rapide et fiable des embeddings, garantissant que votre chatbot récupère rapidement les informations pertinentes.
Ollama - Ollama apporte des modèles de langage puissants (LLMs) directement sur votre ordinateur local, éliminant le besoin de ressources cloud. Il vous permet d'accéder à plusieurs modèles, de personnaliser les sorties et de les intégrer dans votre chatbot sans effort.
Installation d'Ollama
Ollama est un outil open-source que vous pouvez utiliser pour exécuter et gérer des LLMs sur votre ordinateur. Une fois installé, vous pouvez accéder à divers LLMs selon vos besoins. Vous utiliserez le modèle llama3.2:3b-instruct-q4_K_M pour construire ce chatbot.
Un modèle quantifié est une version d'un modèle d'apprentissage automatique qui a été optimisée pour utiliser moins de mémoire et de puissance de calcul en réduisant la précision des nombres qu'il utilise. Cela vous permet d'utiliser un LLM localement, surtout lorsque vous n'avez pas accès à un GPU (unité de traitement graphique - un processeur spécialisé qui effectue des calculs complexes).
Pour commencer, vous pouvez télécharger et installer le logiciel Ollama ici.
Ensuite, vous pouvez confirmer l'installation en exécutant cette commande :
ollama --version
Exécutez la commande suivante pour démarrer Ollama :
ollama serve
Ensuite, exécutez la commande suivante pour télécharger la quantification Q4_K_M de llama3.2:3b-instruct :
ollama pull llama3.2:3b-instruct-q4_K_M
Ensuite, confirmez que le modèle a été extrait avec ceci :
ollama list
Si l'extraction du modèle a réussi, une liste contenant le nom, l'ID et la taille du modèle sera retournée, comme ceci :

Maintenant, vous pouvez discuter avec le modèle :
ollama run llama3.2:3b-instruct-q4_K_M
Si tout se passe bien, vous devriez recevoir une invite que vous pouvez tester en posant une question et en obtenant une réponse. Par exemple :
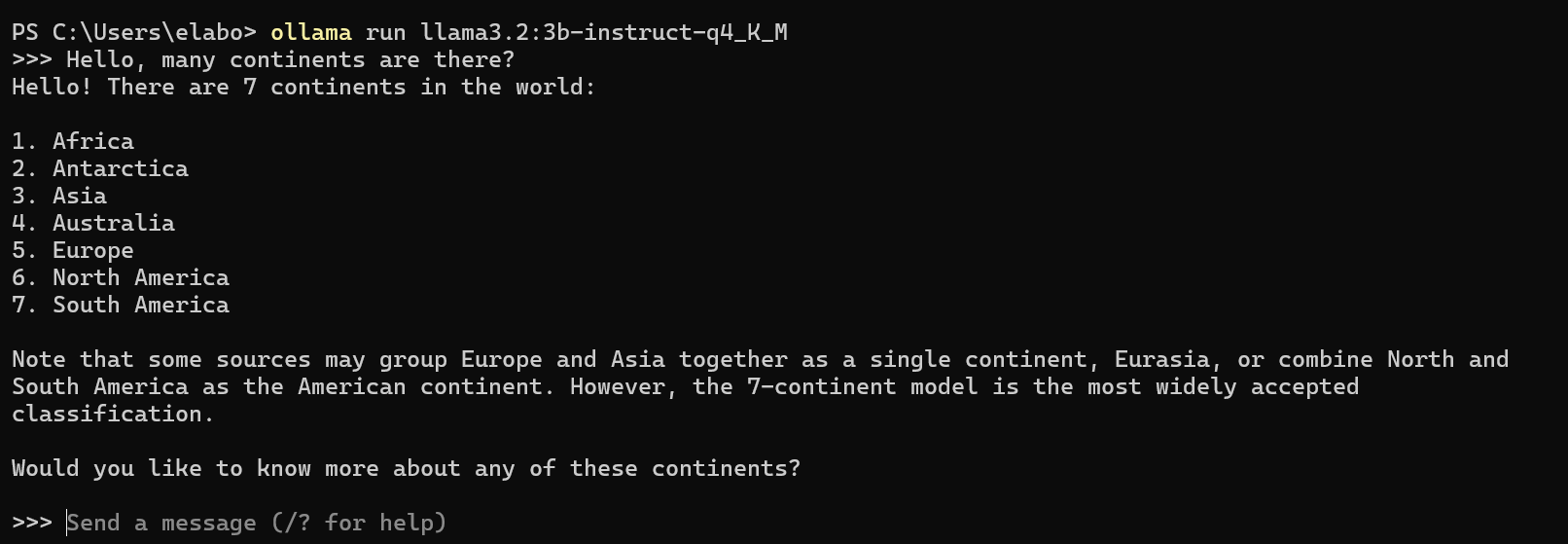
Ensuite, vous pouvez quitter la console en tapant /bye ou ctrl + D
Collecte et nettoyage des données
Le chatbot que vous construisez sera un assistant culinaire qui suggère des recettes en fonction des ingrédients disponibles, de ce que vous voulez manger et de la quantité de nourriture qu'une recette produit.
Vous devez d'abord obtenir les données pour entraîner le modèle. Vous utiliserez un ensemble de données qui contient des recettes de Kaggle.
Pour commencer, chargez les bibliothèques nécessaires :
# chargement des bibliothèques requises
library(xml2) # lire, analyser et manipuler des documents XML, HTML
library(jsonlite) # manipuler des objets JSON
library(RKaggle) # télécharger des ensembles de données depuis Kaggle
library(dplyr) # manipulation de données
Ensuite, téléchargez et sauvegardez l'ensemble de données de recettes :
# Télécharger et lire l'ensemble de données "recipe" depuis Kaggle
recipes_list <- RKaggle::get_dataset("thedevastator/better-recipes-for-a-better-life")
Inspectez le dataframe et extrayez le premier élément comme ceci :
# inspecter l'ensemble de données
class(recipes_list)
str(recipes_list)
head(recipes_list)
# extraire le premier tibble
recipes_df <- recipes_list[[1]]
Un rapide examen de l'objet recipes_list montre qu'il contient deux objets de type tibble. Vous n'utiliserez que le premier élément pour ce projet. Un tibble est un type de structure de données utilisé pour stocker et manipuler des données. Il est similaire à un dataframe traditionnel, mais il est conçu pour appliquer des règles plus strictes et effectuer moins d'actions automatiques par rapport aux dataframes traditionnels.
Nous utiliserons un dataframe régulier dans ce projet car plus de personnes sont susceptibles de le connaître. Il peut également gérer efficacement l'indexation des lignes, ce qui est crucial pour accéder et manipuler des lignes spécifiques dans notre ensemble de données de recettes.
Dans le bloc de code ci-dessous, vous allez convertir le tibble en dataframe puis supprimer la première colonne, qui est la colonne d'index. Ensuite, vous allez inspecter le dataframe nouvellement converti et supprimer les colonnes inutiles.
Les colonnes inutiles sont mieux supprimées pour rationaliser l'ensemble de données et se concentrer sur les fonctionnalités pertinentes. Dans ce projet, nous allons supprimer certaines colonnes qui ne sont pas particulièrement utiles pour entraîner le chatbot. Cela garantit que le modèle se concentre sur des données significatives pour améliorer sa précision et sa fonctionnalité.
# convertir en dataframe et supprimer la première colonne
recipes_df <- as.data.frame(recipes_df[, -1])
# inspecter le dataframe converti
head(recipes_df)
class(recipes_df)
colnames(recipes_df)
# supprimer les colonnes inutiles
cleaned_recipes_df <- subset(recipes_df, select = -c(yield,rating,url,cuisine_path,nutrition,timing,img_src))
Maintenant, vous devez identifier les lignes avec des valeurs NA (manquantes), que vous pouvez faire comme ceci :
# Identifier les lignes et colonnes avec des valeurs NA
which(is.na(cleaned_recipes_df), arr.ind = TRUE)
# une rapide inspection révèle que les colonnes [2:4] ont des valeurs manquantes
subset_column_names <- colnames(cleaned_recipes_df)[2:4]
subset_column_names
Il est important de gérer les valeurs NA pour s'assurer que vos données sont complètes, pour prévenir les erreurs et pour préserver le contexte.
Maintenant, remplacez les valeurs NA et confirmez qu'il n'y a pas de valeurs manquantes :
# Remplacer les valeurs NA dynamiquement en fonction des conditions
cols_to_modify <- c("prep_time", "cook_time", "total_time")
cleaned_recipes_df[cols_to_modify] <- lapply(
cleaned_recipes_df[cols_to_modify],
function(x, df) {
# Remplacer NA dans prep_time et cook_time où les deux sont NA
replace(x, is.na(df$prep_time) & is.na(df$cook_time), "unknown")
},
df = cleaned_recipes_df # Passer le dataframe entier pour les conditions
)
cleaned_recipes_df <- cleaned_recipes_df %>%
mutate(
prep_time = case_when(
# Si cook_time est présent mais prep_time est NA, remplacer par "no preparation required"
!is.na(cook_time) & is.na(prep_time) ~ "no preparation required",
# Sinon, conserver la valeur originale
TRUE ~ as.character(prep_time)
),
cook_time = case_when(
# Si prep_time est présent mais cook_time est NA, remplacer par "no cooking required"
!is.na(prep_time) & is.na(cook_time) ~ "no cooking required",
# Sinon, conserver la valeur originale
TRUE ~ as.character(cook_time)
)
)
# confirmer qu'il n'y a pas de valeurs manquantes
any(is.na(cleaned_recipes_df))
)
# confirmer que la logique de remplacement des NA fonctionne en inspectant des lignes spécifiques
cleaned_recipes_df[1081,]
cleaned_recipes_df[1,]
cleaned_recipes_df[405,]
Pour ce tutoriel, nous allons sous-ensemble le dataframe aux 250 premières lignes à des fins de démonstration. Cela permet de gagner du temps lors de la génération des embeddings.
# recommandé pour des fins de démonstration/apprentissage
cleaned_recipes_df <- head(cleaned_recipes_df,250)
Comment créer des chunks
Pour comprendre pourquoi le découpage est important avant l'embedding, vous devez comprendre ce qu'est un embedding.
Un embedding est une représentation vectorielle d'un mot ou d'une phrase. Les machines ne comprennent pas le texte humain - elles comprennent les nombres. Les LLMs fonctionnent en transformant le texte humain en représentations numériques afin de donner des réponses. Le processus de génération des embeddings nécessite beaucoup de calcul, et la décomposition des données à embedder optimise le processus d'embedding.
Nous allons donc maintenant diviser le dataframe en chunks plus petits d'une taille spécifiée pour permettre un traitement et une itération efficaces par lots.
# Définir la taille de chaque chunk (nombre de lignes par chunk)
chunk_size <- 1
# Obtenir le nombre total de lignes dans le dataframe
n <- nrow(cleaned_recipes_df)
# Créer un vecteur de numéros de groupe pour le découpage
# Chaque numéro de groupe se répète pour 'chunk_size' lignes
# Assurez-vous que le vecteur correspond au nombre total de lignes
r <- rep(1:ceiling(n/chunk_size), each = chunk_size)[1:n]
# Diviser le dataframe en chunks plus petits (sous-ensembles) en fonction des numéros de groupe
chunks <- split(cleaned_recipes_df, r)
Comment générer des embeddings de phrases
Comme mentionné précédemment, les embeddings sont des représentations vectorielles de mots ou de phrases. Les embeddings peuvent être générés à partir de mots et de phrases. La manière dont vous choisissez de générer des embeddings dépend de l'application prévue du LLM.
Les embeddings de mots sont des représentations numériques de mots individuels dans un espace vectoriel continu. Ils capturent les relations sémantiques entre les mots, permettant aux mots similaires d'avoir des vecteurs proches les uns des autres.
Les embeddings de mots peuvent être utilisés dans les moteurs de recherche car ils supportent les requêtes au niveau des mots en faisant correspondre les embeddings pour récupérer des documents pertinents. Ils peuvent également être utilisés dans la classification de texte pour classer des documents, des emails ou des tweets en fonction de caractéristiques au niveau des mots (par exemple, détecter des emails de spam ou analyser les sentiments).
Les embeddings de phrases sont des représentations numériques de phrases entières dans un espace vectoriel, conçues pour capturer le sens global et le contexte de la phrase. Ils sont utilisés dans des contextes où les phrases fournissent un meilleur contexte, comme les systèmes de réponse aux questions où les requêtes des utilisateurs sont mises en correspondance avec des phrases ou des documents pertinents pour une récupération plus précise.
Pour notre chatbot de recettes, l'embedding de phrases est le meilleur choix.
Tout d'abord, créez un dataframe vide qui contient trois colonnes.
# dataframe vide
recipe_sentence_embeddings <- data.frame(
recipe = character(),
recipe_vec_embeddings = I(list()),
recipe_id = character()
)
La première colonne contiendra la recette réelle sous forme de texte, la colonne recipe_vec_embeddings contiendra les embeddings de phrases générés, et recipe_id contiendra un identifiant unique pour chaque recette. Cela aidera à l'indexation et à la récupération depuis la base de données vectorielle.
Ensuite, il est utile de définir une barre de progression, que vous pouvez faire comme ceci :
# créer une barre de progression
pb <- txtProgressBar(min = 1, max = length(chunks), style = 3)
L'embedding peut prendre un certain temps, il est donc important de suivre l'avancement du processus.
Maintenant, il est temps de générer des embeddings et de remplir le dataframe.
Écrivez une boucle for qui exécute le bloc de code tant que la longueur des chunks.
for (i in 1:length(chunks)) {}
Le champ de la recette est le texte au chunk qui est actuellement en cours d'exécution et l'identifiant unique du chunk est généré en collant l'index du chunk et le texte "chunk".
for (i in 1:length(chunks)) {
recipe <- as.character(chunks[i])
recipe_id <- paste0("recipe",i)
}
La fonction text embed de la bibliothèque text génère des embeddings de phrases ou de mots. Elle prend une variable de caractère ou un dataframe et produit un tibble d'embeddings. Vous pouvez lire les instructions de chargement ici pour un fonctionnement fluide de la bibliothèque text.
Le batch_size définit combien de lignes sont embeddées à la fois depuis l'entrée. La définition de keep_token_embeddings supprime les embeddings pour les tokens individuels après le traitement, et aggregation_from_layers_to_tokens "concatène" ou combine les embeddings de couches spécifiées pour créer des embeddings détaillés pour chaque token. Un token est la plus petite unité de texte qu'un modèle peut traiter.
for (i in 1:length(chunks)) {
recipe <- as.character(chunks[i])
recipe_id <- paste0("recipe",i)
recipe_embeddings <- textEmbed(as.character(recipe),
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE,
batch_size = 1
)
}
Pour spécifier les embeddings de phrases, vous devez définir l'argument du paramètre aggregation_from_tokens_to_texts comme "mean".
aggregation_from_tokens_to_texts = "mean"
L'opération "mean" fait la moyenne des embeddings de tous les tokens dans une phrase pour générer un seul vecteur qui représente toute la phrase. Cet embedding au niveau de la phrase capture le sens global et la sémantique du texte, indépendamment de la longueur de ses tokens.
# convertir tibble en vecteur
recipe_vec_embeddings <- unlist(recipe_embeddings, use.names = FALSE)
recipe_vec_embeddings <- list(recipe_vec_embeddings)
La fonction d'embedding retourne un objet tibble. Pour obtenir un embedding vectoriel, vous devez d'abord dé-lister le tibble et supprimer les noms de lignes, puis lister le résultat pour former un vecteur simple.
# Ajouter les données du chunk actuel au dataframe
recipe_sentence_embeddings <- recipe_sentence_embeddings %>%
add_row(
recipe = recipe,
recipe_vec_embeddings = recipe_vec_embeddings,
recipe_id = recipe_id
)
Enfin, mettez à jour le dataframe vide après chaque itération avec les nouvelles données générées.
# suivre la progression de l'embedding
setTxtProgressBar(pb, i)
Pour suivre la progression de l'embedding, vous pouvez utiliser la barre de progression définie précédemment à l'intérieur de la boucle. Elle se mettra à jour à la fin de chaque itération.
Bloc de code complet :
# charger la bibliothèque requise
library(text)
# # assurez-vous de lire les instructions de chargement ici pour un fonctionnement fluide de la bibliothèque 'text'
# # https://www.r-text.org/
# données d'embedding
for (i in 1:length(chunks)) {
recipe <- as.character(chunks[i])
recipe_id <- paste0("recipe",i)
recipe_embeddings <- textEmbed(as.character(recipe),
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE,
batch_size = 1
)
# convertir tibble en vecteur
recipe_vec_embeddings <- unlist(recipe_embeddings, use.names = FALSE)
recipe_vec_embeddings <- list(recipe_vec_embeddings)
# Ajouter les données du chunk actuel au dataframe
recipe_sentence_embeddings <- recipe_sentence_embeddings %>%
add_row(
recipe = recipe,
recipe_vec_embeddings = recipe_vec_embeddings,
recipe_id = recipe_id
)
# suivre la progression de l'embedding
setTxtProgressBar(pb, i)
}
Comment configurer la base de données vectorielle pour le stockage des embeddings
Une base de données vectorielle est un type spécial de base de données qui stocke des embeddings et vous permet d'interroger et de récupérer des informations pertinentes. Il existe de nombreuses bases de données vectorielles disponibles, mais pour ce projet, vous utiliserez ChromaDB, une option open-source qui s'intègre à l'environnement R via la bibliothèque rchroma.
ChromaDB s'exécute localement dans un conteneur Docker. Assurez-vous simplement que Docker est installé et en cours d'exécution sur votre appareil.
Ensuite, chargez la bibliothèque rchroma et exécutez votre instance ChromaDB :
# charger la bibliothèque rchroma
library(rchroma)
# exécuter l'instance ChromaDB.
chroma_docker_run()
Si cela a réussi, vous devriez voir ceci dans la console :
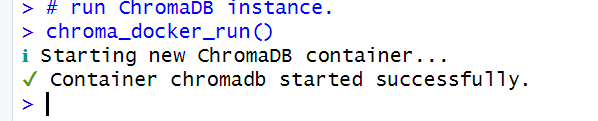
Ensuite, connectez-vous à une instance locale ChromaDB et vérifiez la connexion :
# Se connecter à une instance locale ChromaDB
client <- chroma_connect()
# Vérifier la connexion
heartbeat(client)
version(client)
Maintenant, vous devrez créer une collection et confirmer qu'elle a été créée. Les collections dans ChromaDB fonctionnent de manière similaire aux tables dans les bases de données conventionnelles.
# Créer une nouvelle collection
create_collection(client, "recipes_collection")
# Lister toutes les collections
list_collections(client)
Maintenant, ajoutez des embeddings à la collection. Pour ajouter des embeddings à la recipes_collection, utilisez la fonction add_documents.
# Ajouter des documents à la collection
add_documents(
client,
"recipes_collection",
documents = recipe_sentence_embeddings$recipe,
ids = recipe_sentence_embeddings$recipe_id,
embeddings = recipe_sentence_embeddings$recipe_vec_embeddings
)
La fonction add_documents() est utilisée pour ajouter des données de recettes à la recipes_collection. Voici une ventilation de ses arguments et de la manière dont les données correspondantes sont accessibles :
documents: Cet argument représente le texte de la recette. Il est sourcé à partir de la colonnerecipedu dataframerecipe_sentence_embeddings.ids: Il s'agit de l'identifiant unique pour chaque recette. Il est extrait de la colonnerecipe_iddu même dataframe.embeddings: Cela contient les embeddings de phrases, qui ont été précédemment générés pour chaque recette. Ces embeddings sont accessibles à partir de la colonnerecipe_vec_embeddingsdu dataframe.
Les trois arguments—documents, ids, et embeddings—sont obtenus en sous-ensemblant leurs colonnes respectives à partir du dataframe recipe_sentence_embeddings.
Comment écrire la fonction d'embedding de requête d'entrée utilisateur
Pour récupérer des informations à partir d'une base de données vectorielle, vous devez d'abord embedder votre texte de requête. La base de données compare l'embedding de votre requête avec ses embeddings stockés pour trouver et récupérer le document le plus pertinent.
Il est important de s'assurer que les dimensions (lignes × colonnes) de votre embedding de requête correspondent à celles des embeddings de la base de données. Cet alignement est réalisé en utilisant le même modèle d'embedding pour générer votre requête.
La correspondance des embeddings implique de calculer la similarité (par exemple, la similarité cosinus) entre la requête et les embeddings stockés, en identifiant la correspondance la plus proche pour une récupération efficace.
Écrivons une fonction qui nous permet d'embedder une requête qui interroge ensuite des documents similaires en utilisant les embeddings générés. L'envelopper dans une fonction la rend réutilisable.
# fonction d'embeddings de phrases et requête
question <- function(sentence){
sentence_embeddings <- textEmbed(sentence,
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE
)
# convertir tibble en vecteur
sentence_vec_embeddings <- unlist(sentence_embeddings, use.names = FALSE)
sentence_vec_embeddings <- list(sentence_vec_embeddings)
# Interroger des documents similaires en utilisant des embeddings
results <- query(
client,
"recipes_collection",
query_embeddings = sentence_vec_embeddings ,
n_results = 2
)
results
}
Ce bloc de code est similaire à la manière dont nous avons précédemment utilisé la fonction text_embed(). La fonction query() est ajoutée pour permettre l'interrogation de la base de données vectorielle, en particulier la collection de recettes, et retourne les deux premiers documents qui correspondent étroitement à une requête utilisateur.
Notre fonction prend donc une phrase comme argument et embedde la phrase pour générer des embeddings de phrases. Elle interroge ensuite la base de données et retourne deux documents qui correspondent le plus à la requête.
Appel d'outil
Pour interagir avec Ollama dans R, vous utiliserez la bibliothèque ellmer. Cette bibliothèque simplifie l'utilisation des grands modèles de langage (LLMs) en offrant une interface qui permet un accès et une interaction transparents avec une variété de fournisseurs de LLMs.
Pour améliorer l'utilisation du LLM, nous devons lui fournir du contexte. Vous pouvez le faire par l'appel d'outil. L'appel d'outil permet à un LLM d'accéder à des ressources externes afin d'améliorer sa fonctionnalité.
Pour ce projet, nous mettons en œuvre Retrieval-Augmented Generation (RAG), qui combine la récupération d'informations pertinentes à partir d'une base de données vectorielle et la génération de réponses en utilisant un LLM. Cette approche améliore la capacité du chatbot à fournir des réponses précises et contextuellement pertinentes.
Maintenant, définissez une fonction qui se lie au LLM pour fournir du contexte en utilisant la fonction tool() de la bibliothèque ellmer.
# charger la bibliothèque ellmer
library(ellmer)
# fonction qui se lie au llm pour fournir du contexte
tool_context <- tool(
question,
"obtient le bon contexte pour une question donnée",
sentence = type_string()
)
La fonction tool() prend la fonction question qui retourne les documents pertinents que nous utiliserons comme contexte en tant que premier argument. Nous utiliserons les documents pour aider le LLM à répondre aux questions en conséquence.
Le texte, "obtient le bon contexte pour une question donnée", est une description de ce que l'outil fera.
Enfin, sentence = type_string() définit le type d'objet que la fonction question() attend.
Comment initialiser le système de chat, concevoir des prompts et intégrer des outils
Ensuite, vous allez configurer un système d'IA conversationnelle en définissant son rôle et sa fonctionnalité. En utilisant la conception de prompts système, vous allez façonner le comportement, le ton et le focus de l'assistant en tant qu'assistant culinaire. Vous allez également intégrer des outils externes pour étendre les capacités du chatbot en enregistrant des outils. Plongeons-nous.
Tout d'abord, vous devez initialiser un objet de chat :
# Initialiser le système de chat avec des instructions de prompt.
chat <- chat_ollama(system_prompt = "Vous êtes un assistant culinaire compétent spécialisé dans les recommandations de recettes.
Vous fournissez des suggestions de repas sur mesure en fonction des ingrédients disponibles de l'utilisateur et de la quantité de nourriture ou de portions souhaitée.
Assurez-vous que les recettes correspondent étroitement aux entrées de l'utilisateur et produisent la quantité attendue.",
model = "llama3.2:3b-instruct-q4_K_M")
Vous pouvez le faire en utilisant la fonction chat_ollama(). Cela configure un agent conversationnel avec le prompt système et le modèle spécifiés.
Le prompt système définit le comportement conversationnel, le ton et le focus du LLM tandis que l'argument du modèle spécifie le modèle de langage (llama3.2:3b-instruct-q4_K_M) que le système de chat utilisera pour générer des réponses.
Ensuite, vous devez enregistrer un outil.
# enregistrer l'outil
chat$register_tool(tool_context)
Nous devons informer notre objet de chat de notre fonction tool_context(). Faites cela en enregistrant un outil en utilisant la fonction register_tool().
Comment interagir avec votre chatbot en utilisant une application Shiny
Pour interagir avec le chatbot que vous venez de créer, nous utiliserons Shiny, un framework pour construire des applications web interactives en R. Shiny fournit une interface graphique conviviale qui permet une interaction transparente avec le chatbot.
À cette fin, nous utiliserons la bibliothèque shinychat, qui simplifie le processus de construction d'une interface de chat dans une application Shiny. Cela implique de définir deux composants clés :
Interface utilisateur (UI) :
Responsable de la disposition visuelle et de ce que l'utilisateur voit.
Dans ce cas,
chat_ui("chat")est utilisé pour créer l'interface de chat interactive.
Fonction serveur :
Gère la fonctionnalité et la logique de l'application.
Elle connecte le chatbot à des outils externes et gère des processus comme l'embedding des requêtes, la récupération des réponses pertinentes et la gestion des entrées utilisateur.
# charger la bibliothèque requise
library(shinychat)
# envelopper le code de chat dans une application Shiny
ui <- bslib::page_fluid(
chat_ui("chat")
)
server <- function(input, output, session) {
# Se connecter à une instance locale ChromaDB en cours d'exécution sur docker avec des embeddings chargés
client <- chroma_connect()
# fonction d'embeddings de phrases et requête
question <- function(sentence){
sentence_embeddings <- textEmbed(sentence,
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE
)
# convertir tibble en vecteur
sentence_vec_embeddings <- unlist(sentence_embeddings, use.names = FALSE)
sentence_vec_embeddings <- list(sentence_vec_embeddings)
# Interroger des documents similaires en utilisant des embeddings
results <- query(
client,
"recipes_collection",
query_embeddings = sentence_vec_embeddings ,
n_results = 2
)
results
}
# fonction qui fournit du contexte
tool_context <- tool(
question,
"obtient le bon contexte pour une question donnée",
sentence = type_string()
)
# Initialiser le système de chat avec le premier chunk
chat <- chat_ollama(system_prompt = "Vous êtes un assistant culinaire compétent spécialisé dans les recommandations de recettes.
Vous fournissez des suggestions de repas sur mesure en fonction des ingrédients disponibles de l'utilisateur et de la quantité de nourriture ou de portions souhaitée.
Assurez-vous que les recettes correspondent étroitement aux entrées de l'utilisateur et produisent la quantité attendue.",
model = "llama3.2:3b-instruct-q4_K_M")
# enregistrer l'outil
chat$register_tool(tool_context)
observeEvent(input$chat_user_input, {
stream <- chat$stream_async(input$chat_user_input)
chat_append("chat", stream)
})
}
shinyApp(ui, server)
D'accord, comprenons comment cela fonctionne :
Surveillance des entrées utilisateur avec
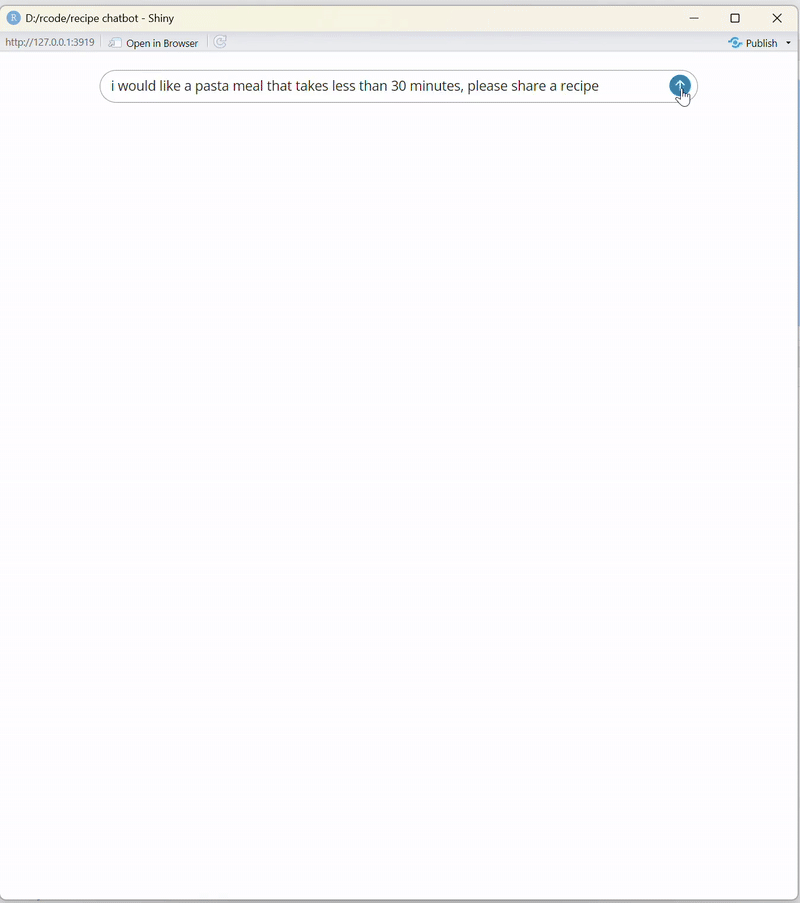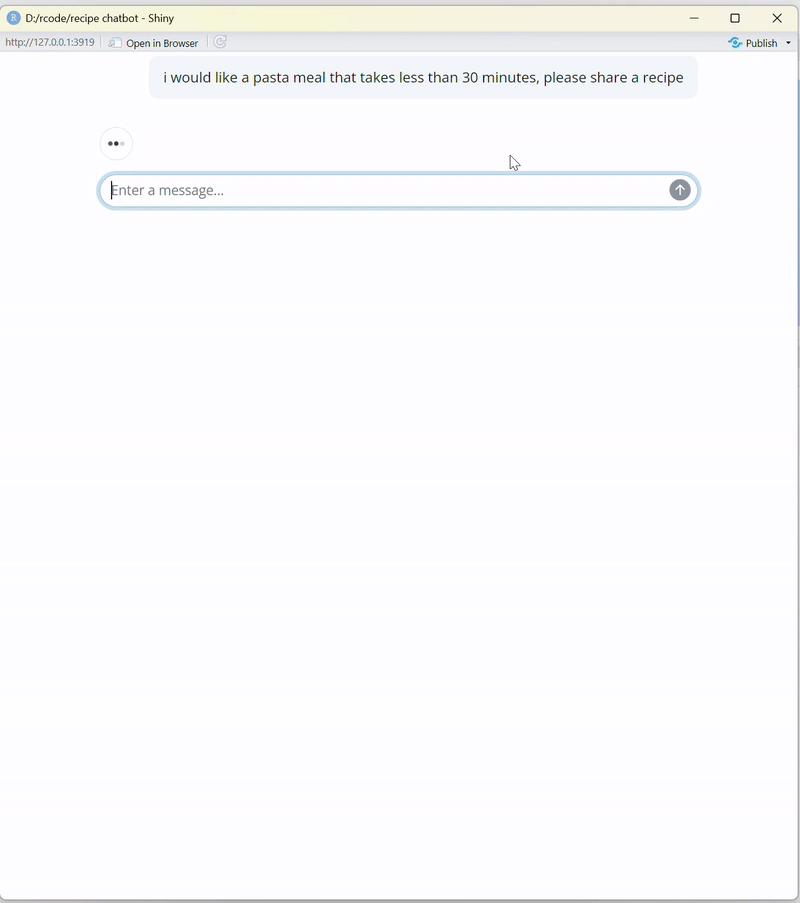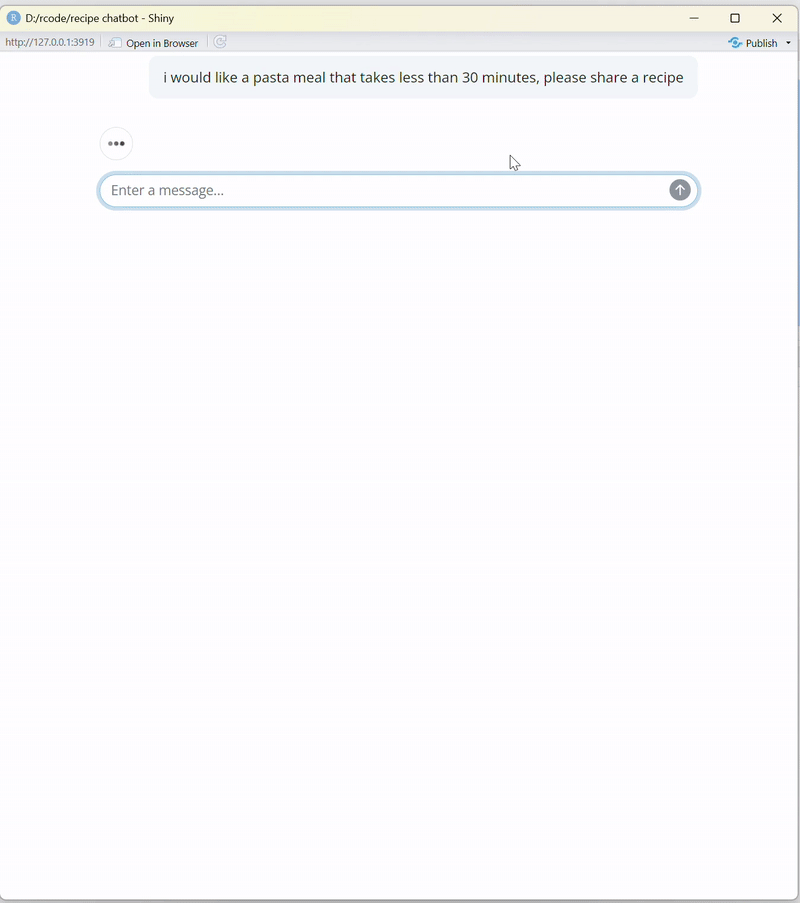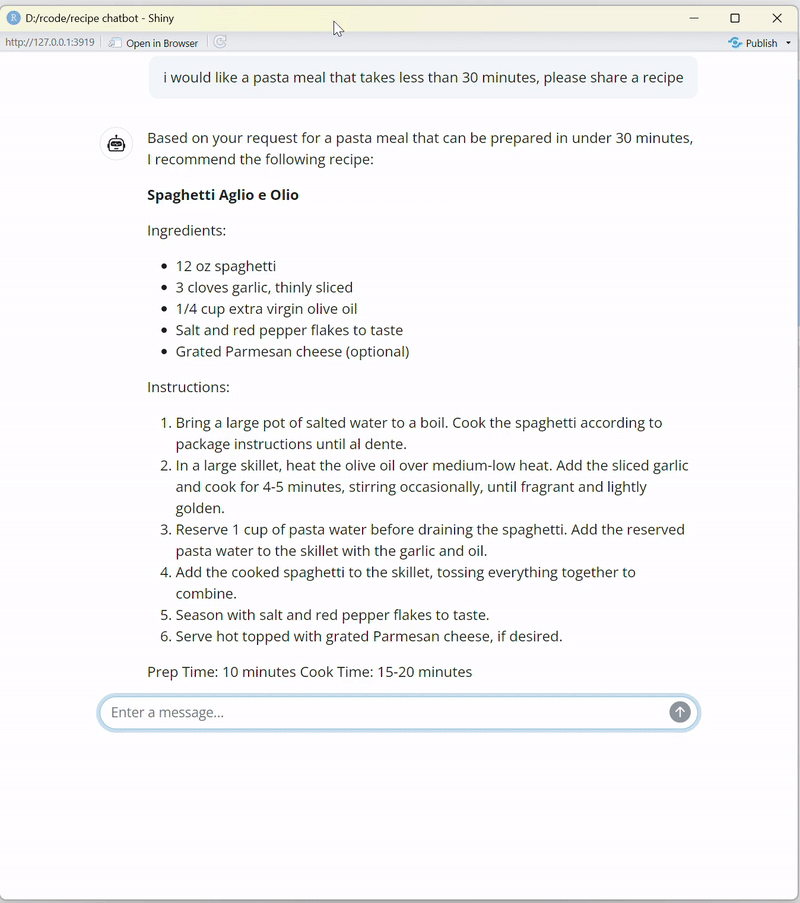
observeEvent(): Le blocobserveEvent()surveille les entrées utilisateur depuis l'interface de chat (input$chat_user_input). Lorsque l'utilisateur envoie un message, le chatbot le traite, récupère le contexte pertinent en utilisant les embeddings, et diffuse la réponse dynamiquement à l'interface de chat.Appel d'outil pour le contexte : Le chatbot utilise l'appel d'outil pour interagir avec des ressources externes (comme la base de données vectorielle) et améliorer sa fonctionnalité. Dans ce projet, la génération augmentée par récupération (RAG) garantit que le chatbot fournit des réponses précises et riches en contexte en intégrant de manière transparente la récupération et la génération.
Cette approche donne vie au chatbot, permettant aux utilisateurs d'interagir avec lui dynamiquement via une application Shiny réactive.
Code complet
Les scripts R ont été divisés en deux, avec data.R contenant le code qui gère la collecte et le nettoyage des données, le découpage de texte, la génération d'embeddings de phrases, la création d'une base de données vectorielle et le chargement de documents.
Le script chat.R contient le code qui gère l'interrogation des entrées utilisateur, la récupération de contexte, l'initialisation du chat, la conception des prompts système, l'intégration des outils et une application Shiny de chat.
data.R
# installer et charger les packages requis
# installer devtools depuis CRAN
install.packages('devtools')
devtools::install_github("benyamindsmith/RKaggle")
library(text)
library(rchroma)
library(RKaggle)
library(dplyr)
# exécuter l'instance ChromaDB.
chroma_docker_run()
# Se connecter à une instance locale ChromaDB
client <- chroma_connect()
# Vérifier la connexion
heartbeat(client)
version(client)
# Créer une nouvelle collection
create_collection(client, "recipes_collection")
# Lister toutes les collections
list_collections(client)
# Télécharger et lire l'ensemble de données "recipe" depuis Kaggle
recipes_list <- RKaggle::get_dataset("thedevastator/better-recipes-for-a-better-life")
# extraire le premier tibble
recipes_df <- recipes_list[[1]]
# convertir en dataframe et supprimer la première colonne
recipes_df <- as.data.frame(recipes_df[, -1])
# supprimer les colonnes inutiles
cleaned_recipes_df <- subset(recipes_df, select = -c(yield,rating,url,cuisine_path,nutrition,timing,img_src))
## Remplacer les valeurs NA dynamiquement en fonction des conditions
# Remplacer NA lorsque toutes les colonnes ont des valeurs NA
cols_to_modify <- c("prep_time", "cook_time", "total_time")
cleaned_recipes_df[cols_to_modify] <- lapply(
cleaned_recipes_df[cols_to_modify],
function(x, df) {
# Remplacer NA dans prep_time et cook_time où les deux sont NA
replace(x, is.na(df$prep_time) & is.na(df$cook_time), "unknown")
},
df = cleaned_recipes_df
)
# Remplacer NA lorsque l'une ou l'autre des colonnes a des valeurs NA
cleaned_recipes_df <- cleaned_recipes_df %>%
mutate(
prep_time = case_when(
# Si cook_time est présent mais prep_time est NA, remplacer par "no preparation required"
!is.na(cook_time) & is.na(prep_time) ~ "no preparation required",
# Sinon, conserver la valeur originale
TRUE ~ as.character(prep_time)
),
cook_time = case_when(
# Si prep_time est présent mais cook_time est NA, remplacer par "no cooking required"
!is.na(prep_time) & is.na(cook_time) ~ "no cooking required",
# Sinon, conserver la valeur originale
TRUE ~ as.character(cook_time)
)
)
# découper l'ensemble de données
chunk_size <- 1
n <- nrow(cleaned_recipes_df)
r <- rep(1:ceiling(n/chunk_size),each = chunk_size)[1:n]
chunks <- split(cleaned_recipes_df,r)
# dataframe vide
recipe_sentence_embeddings <- data.frame(
recipe = character(),
recipe_vec_embeddings = I(list()),
recipe_id = character()
)
# créer une barre de progression
pb <- txtProgressBar(min = 1, max = length(chunks), style = 3)
# données d'embedding
for (i in 1:length(chunks)) {
recipe <- as.character(chunks[i])
recipe_id <- paste0("recipe",i)
recipe_embeddings <- textEmbed(as.character(recipe),
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE,
batch_size = 1
)
# convertir tibble en vecteur
recipe_vec_embeddings <- unlist(recipe_embeddings, use.names = FALSE)
recipe_vec_embeddings <- list(recipe_vec_embeddings)
# Ajouter les données du chunk actuel au dataframe
recipe_sentence_embeddings <- recipe_sentence_embeddings %>%
add_row(
recipe = recipe,
recipe_vec_embeddings = recipe_vec_embeddings,
recipe_id = recipe_id
)
# suivre la progression de l'embedding
setTxtProgressBar(pb, i)
}
# Ajouter des documents à la collection
add_documents(
client,
"recipes_collection",
documents = recipe_sentence_embeddings$recipe,
ids = recipe_sentence_embeddings$recipe_id,
embeddings = recipe_sentence_embeddings$recipe_vec_embeddings
)
chat.R
# Charger les packages requis
library(ellmer)
library(text)
library(rchroma)
library(shinychat)
ui <- bslib::page_fluid(
chat_ui("chat")
)
server <- function(input, output, session) {
# Se connecter à une instance locale ChromaDB en cours d'exécution sur docker avec des embeddings chargés
client <- chroma_connect()
# fonction d'embeddings de phrases et requête
question <- function(sentence){
sentence_embeddings <- textEmbed(sentence,
layers = 10:11,
aggregation_from_layers_to_tokens = "concatenate",
aggregation_from_tokens_to_texts = "mean",
keep_token_embeddings = FALSE
)
# convertir tibble en vecteur
sentence_vec_embeddings <- unlist(sentence_embeddings, use.names = FALSE)
sentence_vec_embeddings <- list(sentence_vec_embeddings)
# Interroger des documents similaires
results <- query(
client,
"recipes_collection",
query_embeddings = sentence_vec_embeddings ,
n_results = 2
)
results
}
# fonction qui fournit du contexte
tool_context <- tool(
question,
"obtient le bon contexte pour une question donnée",
sentence = type_string()
)
# Initialiser le système de chat
chat <- chat_ollama(system_prompt = "Vous êtes un assistant culinaire compétent spécialisé dans les recommandations de recettes.
Vous fournissez des suggestions de repas sur mesure en fonction des ingrédients disponibles de l'utilisateur et de la quantité de nourriture ou de portions souhaitée.
Assurez-vous que les recettes correspondent étroitement aux entrées de l'utilisateur et produisent la quantité attendue.",
model = "llama3.2:3b-instruct-q4_K_M")
# enregistrer l'outil
chat$register_tool(tool_context)
observeEvent(input$chat_user_input, {
stream <- chat$stream_async(input$chat_user_input)
chat_append("chat", stream)
})
}
shinyApp(ui, server)
Vous pouvez trouver le code complet ici.
Conclusion
Construire une application locale de génération augmentée par récupération (RAG) en utilisant Ollama et ChromaDB dans le langage de programmation R offre une manière puissante de créer un assistant conversationnel spécialisé.
En exploitant les capacités des grands modèles de langage et des bases de données vectorielles, vous pouvez gérer et récupérer efficacement des informations pertinentes à partir de vastes ensembles de données.
Cette approche non seulement améliore les performances des modèles de langage, mais garantit également la personnalisation et la confidentialité en exécutant l'application localement.
Que vous développiez un assistant culinaire ou tout autre chatbot spécifique à un domaine, cette méthode fournit un cadre robuste pour fournir des réponses intelligentes et contextuellement conscientes.