
Article original : How to Build a Screenshot Capture API Using Terraform, AWS API Gateway, and AWS Lambda
Par Aaron Katz
Récemment, je voulais vraiment trouver un moyen de créer une API qui prendrait une URL et enregistrerait une capture d'écran.
Mon cas d'utilisation initial était simple : si j'analysais des e-mails de phishing, je voulais un moyen facile d'obtenir une capture d'écran de l'URL vers laquelle l'e-mail essayait de diriger ses cibles.
Pour construire cela, j'ai utilisé Terraform pour créer toute l'infrastructure nécessaire pour le configurer dans AWS, en utilisant Selenium, chromedriver et Chrome headless pour obtenir les captures d'écran.
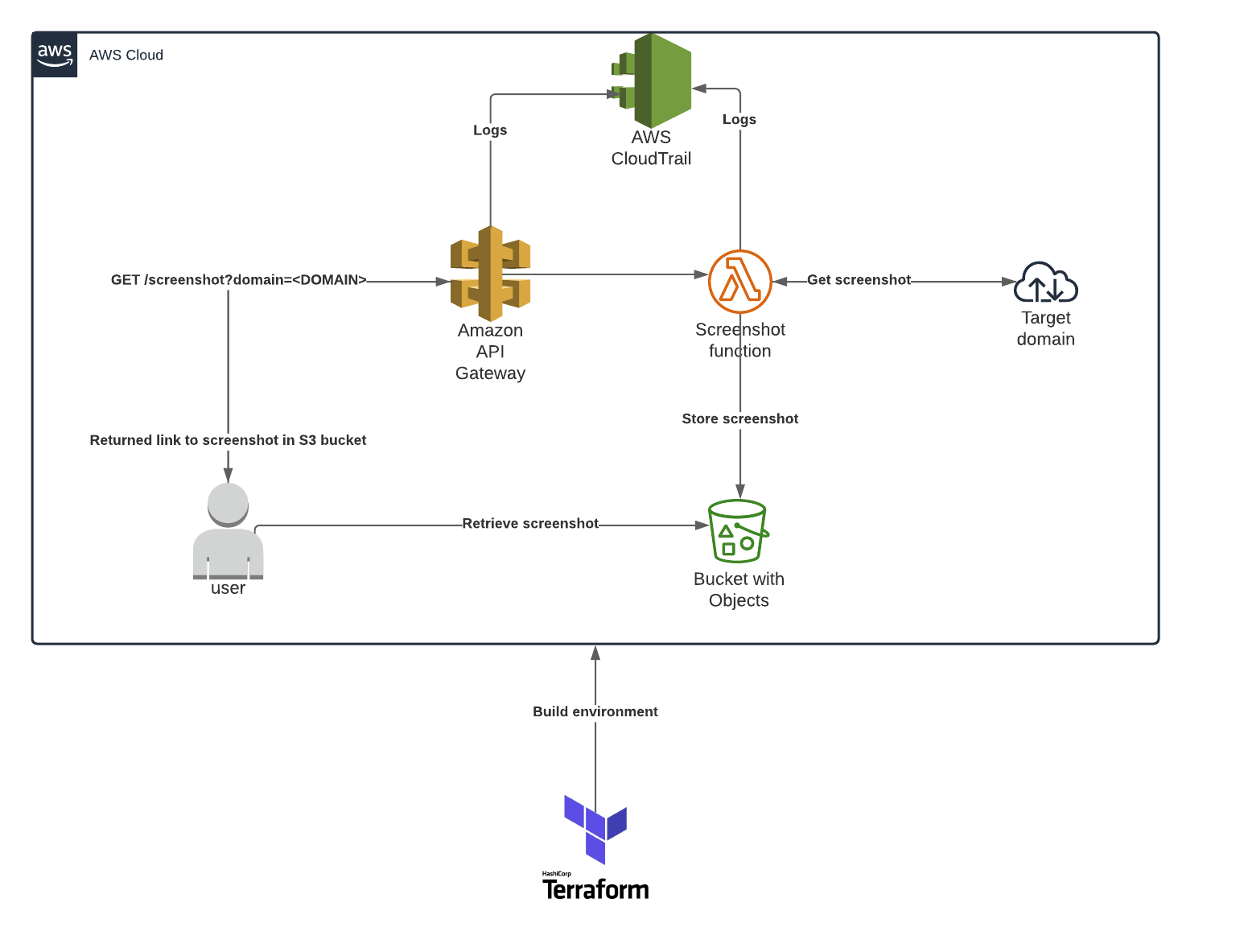 Diagramme de haut niveau illustrant ce qui sera construit dans AWS par Terraform
Diagramme de haut niveau illustrant ce qui sera construit dans AWS par Terraform
Note : Tous les exemples de code sont issus de PowerShell, donc veuillez excuser la notation ".\" .
Exigences
- Un compte AWS
- Binaire Terraform
- Un bucket S3 existant pour stocker l'état de Terraform (https://www.terraform.io/docs/backends/types/s3.html)
- Un utilisateur IAM AWS et une clé d'accès créés avec les permissions appropriées (accès programmatique, groupe administratif) pour l'utilisation de Terraform
Comment configurer le projet
Créez votre nouveau répertoire et initialisez Terraform comme ceci :
mkdir .\screenshot-service
cd .\screenshot-service
.\terraform init
Configurer le fournisseur AWS
Créez un fichier appelé provider.tf à la racine de votre répertoire de projet. Configurez-le ensuite avec les valeurs appropriées pour la clé d'accès AWS et la clé secrète, ainsi que le nom d'un bucket S3 existant qui sera utilisé pour stocker le fichier d'état Terraform.
provider "aws" {
region = "us-east-1"
access_key = "ACCESSKEY"
secret_key = "SECRETKEY"
}
terraform {
backend "s3" {
bucket = "EXISTING_BUCKET"
region = "us-east-1"
key = "KEYFORSTATE"
access_key = "ACCESSKEY"
secret_key = "SECRETKEY"
encrypt = "true"
}
}
Configurer le bucket S3
Nous utiliserons un bucket S3 pour stocker toutes nos captures d'écran. Pour configurer le service S3, créez un nouveau fichier à la racine de votre projet appelé s3.tf et ajoutez ce qui suit :
resource "aws_s3_bucket" "screenshot_bucket" {
bucket = "STORAGE_BUCKET_NAME"
force_destroy = true
acl = "public-read"
versioning {
enabled = false
}
}
Créer la couche Lambda
Commençons par créer la couche lambda qui contiendra les binaires nécessaires. Tout d'abord, à partir de la racine du projet, créez un dossier appelé chromedriver_layer : mkdir .\chromedriver_layer.
Ensuite, téléchargez les binaires chromedriver et chromium :
cd .\chromedriver_layer
wget https://chromedriver.storage.googleapis.com/2.41/chromedriver_linux64.zip -OutFile .\chromedriver.zip
wget https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-54/stable-headless-chromium-amazonlinux-2017-03.zip -OutFile .\headless-chromium.zip
Expand-Archive .\headless-chromium.zip
rm *.zip
Enfin, nous devons compresser cela proprement pour Terraform :
cd ..\
Compress-Archive .\chromedriver_layer -DestinationPath \chromedriver_layer.zip
Comment configurer Lambda
Infrastructure Lambda
Créez un fichier appelé lambda.tf à la racine de votre répertoire de projet. Tout d'abord, nous allons créer le rôle d'exécution requis pour notre fonction :
resource "aws_iam_role" "lambda_exec_role" {
name = "lambda_exec_role"
description = "Rôle d'exécution pour les fonctions Lambda"
assume_role_policy = <<EOF
{
"Version" : "2012-10-17",
"Statement": [
{
"Action" : "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid" : ""
}
]
}
EOF
}
Ensuite, nous allons ajouter quelques politiques au rôle d'exécution que nous avons créé, ce qui permettra à notre fonction d'accéder aux services requis :
resource "aws_iam_role_policy" "lambda_logging" {
name = "lambda_logging"
role = aws_iam_role.lambda_exec_role.id
policy = <<EOF
{
"Version" : "2012-10-17",
"Statement": [
{
"Effect" : "Allow",
"Resource": "*",
"Action" : [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateLogGroup"
]
}
]
}
EOF
}
resource "aws_iam_role_policy" "lambda_s3_access" {
name = "lambda_s3_access"
role = aws_iam_role.lambda_exec_role.id
# TODO: Changer la ressource pour être plus restrictive
policy = <<EOF
{
"Version" : "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBuckets",
"s3:PutObject",
"s3:PutObjectAcl",
"s3:GetObjectAcl"
],
"Resource": ["*"]
}
]
}
EOF
}
Voilà, maintenant notre fonction pourra accéder à S3 et journaliser dans CloudWatch. Définissons notre fonction :
resource "aws_lambda_function" "take_screenshot" {
filename = "./screenshot-service.zip"
function_name = "take_screenshot"
role = aws_iam_role.lambda_exec_role.arn
handler = "screenshot-service.handler"
runtime = "python3.7"
source_code_hash = filebase64sha256("./screenshot-service.zip")
timeout = 600
memory_size = 512
layers = ["${aws_lambda_layer_version.chromedriver_layer.arn}"]
environment {
variables = {
s3_bucket = "${aws_s3_bucket.screenshot_bucket.bucket}"
}
}
}
Le code ci-dessus spécifie que nous téléchargeons un package de fonction lambda utilisant un runtime Python 3.7, et que la fonction qui sera appelée s'appelle "handler".
J'ai défini le délai d'attente à 600 secondes, mais n'hésitez pas à le modifier comme vous le souhaitez. De plus, n'hésitez pas à jouer avec la taille de la mémoire - pour moi, cela a conduit à des captures d'écran super rapides.
Nous définissons également une variable d'environnement appelée s3_bucket qui sera passée à la fonction, contenant le nom du bucket utilisé pour stocker la capture d'écran.
La fonction Lambda elle-même
Créez un dossier appelé lambda à la racine du répertoire de projet et créez un fichier appelé screenshot-service.py dans ce dossier.
Ajoutez les imports suivants et la configuration de journalisation au fichier :
#!/usr/bin/env python
# -*- coding utf-8 -*-
import json
import logging
from urllib.parse import urlparse, unquote # TODO: Puis-je utiliser urllib3 ?
from selenium import webdriver
from datetime import datetime
import os
from shutil import copyfile
import boto3
import stat
import urllib.request
import tldextract
# Configurer la journalisation
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
Ensuite, nous allons créer une fonction qui copiera les binaires de notre couche lambda et les rendra exécutables :
def configure_binaries():
"""Copier les fichiers binaires de la couche lambda vers /tmp et les rendre exécutables"""
copyfile("/opt/chromedriver", "/tmp/chromedriver")
copyfile("/opt/headless-chromium", "/tmp/headless-chromium")
os.chmod("/tmp/chromedriver", 755)
os.chmod("/tmp/headless-chromium", 755)
Ensuite, nous allons créer la fonction qui prendra la capture d'écran du domaine fourni. Nous allons passer l'URL et le nom du bucket S3.
Nous allons ajouter un paramètre optionnel permettant à l'utilisateur de définir le titre de l'image. La capture d'écran est prise par Selenium en automatisant le navigateur Chrome headless que nous avons téléchargé.
def get_screenshot(url, s3_bucket, screenshot_title = None):
configure_binaries()
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument("disable-infobars")
chrome_options.add_argument("enable-automation")
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--window-size=1280x1696')
chrome_options.add_argument('--user-data-dir=/tmp/user-data')
chrome_options.add_argument('--hide-scrollbars')
chrome_options.add_argument('--enable-logging')
chrome_options.add_argument('--log-level=0')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--v=99')
chrome_options.add_argument('--single-process')
chrome_options.add_argument('--data-path=/tmp/data-path')
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument('--homedir=/tmp')
chrome_options.add_argument('--disk-cache-dir=/tmp/cache-dir')
chrome_options.add_argument(
'user-agent=Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36')
chrome_options.binary_location = "/tmp/headless-chromium"
if screenshot_title is None:
ext = tldextract.extract(url)
domain = f"{''.join(ext[:2])}:{urlparse(url).port}.{ext[2]}"
screenshot_title = f"{domain}_{datetime.utcnow().strftime('%Y%m%d_%H%M%S')}"
logger.debug(f"Titre de la capture d'écran : {screenshot_title}")
with webdriver.Chrome(chrome_options=chrome_options, executable_path="/tmp/chromedriver", service_log_path="/tmp/selenium.log") as driver:
driver.set_window_size(1024, 768)
logger.info(f"Obtention de la capture d'écran pour {url}")
driver.get(url)
driver.save_screenshot(f"/tmp/{screenshot_title}.png") # TODO: Supprimer la capture d'écran après
logger.info(f"Téléchargement de /tmp/{screenshot_title}.png vers le bucket S3 {s3_bucket}/{screenshot_title}.png")
s3 = boto3.client("s3")
s3.upload_file(f"/tmp/{screenshot_title}.png", s3_bucket, f"{screenshot_title}.png", ExtraArgs={'ContentType': 'image/png', 'ACL': 'public-read'})
return f"https://{s3_bucket}.s3.amazonaws.com/{screenshot_title}.png"
Enfin, créons notre gestionnaire, qui sera invoqué lorsque l'API Gateway recevra une requête légitime :
def handler(event, context):
logger.debug("## VARIABLES D'ENVIRONNEMENT ##")
logger.debug(os.environ)
logger.debug("## ÉVÉNEMENT ##")
logger.debug(event)
bucket_name = os.environ["s3_bucket"]
logger.debug(f"bucket_name: {bucket_name}")
logger.info("Validation de l'URL")
if event["httpMethod"] == "GET":
if event["queryStringParameters"]:
try:
url = event["queryStringParameters"]["url"]
except Exception as e:
logger.error(e)
raise e
else:
return {
"statusCode": 400,
"body": json.dumps("Aucune URL fournie...")
}
elif event["httpMethod"] == "POST":
if event["body"]:
try:
body = json.loads(event["body"])
url = body["url"]
except Exception as e:
logger.error(e)
raise e
else:
return {
"statusCode": 400,
"body": json.dumps("Aucune URL fournie...")
}
else:
return {
"statusCode": 405,
"body": json.dumps(f"Méthode HTTP invalide {event['httpMethod']} fournie")
}
logger.info(f"Décodage de {url}")
url = unquote(url)
logger.info(f"Analyse de {url}")
try:
parsed_url = urlparse(url)
if parsed_url.scheme != "http" and parsed_url.scheme != "https":
logger.info("Aucun schéma valide trouvé, par défaut http://")
parsed_url = urlparse(f"http://{url}")
if parsed_url.port is None:
if parsed_url.scheme == "http":
parsed_url = urlparse(f"{parsed_url.geturl()}:80")
elif parsed_url.scheme == "https":
parsed_url = urlparse(f"{parsed_url.geturl()}:443")
except Exception as e:
logger.error(e)
raise e
logger.info("Obtention de la capture d'écran")
try:
screenshot_url = get_screenshot(parsed_url.geturl(), bucket_name) # TODO: Variable !
except Exception as e:
logger.error(e)
raise e
response_body = {
"message": f"Capture d'écran de {parsed_url.geturl()} réussie",
"screenshot_url": screenshot_url
}
return {
"statusCode": 200,
"body" : json.dumps(response_body)
}
Ensuite, nous devons installer tous les packages utilisés par la fonction lambda dans le répertoire lambda, car ces packages ne sont pas installés par défaut dans AWS.
Ensuite, nous devons créer l'archive zip (une fois créée, Terraform continuera à la mettre à jour si vous apportez des modifications à votre code) :
cd .\lambda
pip install selenium tldextract -t .\
cd ..\
Compress-Archive .\lambda -DestinationPath .\screenshot-service.zip
Comment configurer API Gateway
Créez un fichier appelé apigw.tf à la racine de votre répertoire de projet. Tout d'abord, nous allons configurer l'API REST :
resource "aws_api_gateway_rest_api" "screenshot_api" {
name = "screenshot_api"
description = "API de capture d'écran alimentée par Lambda"
depends_on = [
aws_lambda_function.take_screenshot
]
}
Cette API sera utilisée pour diriger toutes les requêtes faites pour le service de capture d'écran. Nous utilisons la fonction depends_on pour nous assurer que la passerelle et ses composants associés ne sont créés qu'après la création de la fonction lambda.
Ensuite, créons la ressource API Gateway pour la fonction lambda :
resource "aws_api_gateway_resource" "screenshot_api_gateway" {
path_part = "screenshot"
parent_id = aws_api_gateway_rest_api.screenshot_api.root_resource_id
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
}
Nous avons maintenant défini une ressource qui répondra à l'endpoint /screenshot pour le service API.
Ensuite, nous allons créer un stage pour l'API. Un stage est un moyen élégant de nommer notre déploiement de l'API. Vous pouvez configurer la mise en cache, la journalisation, la limitation des requêtes, et plus encore en utilisant un stage.
resource "aws_api_gateway_stage" "prod_stage" {
stage_name = "prod"
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
deployment_id = aws_api_gateway_deployment.api_gateway_deployment_get.id
}
Ensuite, nous allons créer une clé API et un plan d'utilisation liés à notre stage, afin que seuls les utilisateurs connaissant la clé puissent utiliser ce service. (Note : Si vous souhaitez que cela soit accessible publiquement, ignorez cette étape.)
resource "aws_api_gateway_usage_plan" "apigw_usage_plan" {
name = "apigw_usage_plan"
api_stages {
api_id = aws_api_gateway_rest_api.screenshot_api.id
stage = aws_api_gateway_stage.prod_stage.stage_name
}
}
resource "aws_api_gateway_usage_plan_key" "apigw_usage_plan_key" {
key_id = aws_api_gateway_api_key.apigw_prod_key.id
key_type = "API_KEY"
usage_plan_id = aws_api_gateway_usage_plan.apigw_usage_plan.id
}
resource "aws_api_gateway_api_key" "apigw_prod_key" {
name = "prod_key"
}
Configurons maintenant l'API pour qu'elle réponde à une requête GET ou POST si une clé API Gateway valide est fournie (définissez la valeur sur false si vous souhaitez que la méthode soit ouverte au public) :
resource "aws_api_gateway_method" "take_screenshot_get" {
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_resource.screenshot_api_gateway.id
http_method = "GET"
authorization = "NONE"
api_key_required = true
}
resource "aws_api_gateway_method" "take_screenshot_post" {
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_resource.screenshot_api_gateway.id
http_method = "POST"
authorization = "NONE"
api_key_required = true
}
Nous devons maintenant donner à l'API Gateway la permission d'invoquer la fonction lambda que nous avons créée :
resource "aws_lambda_permission" "apigw" {
statement_id = "AllowAPIGatewayInvoke"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.take_screenshot.arn
principal = "apigateway.amazonaws.com"
source_arn = "${aws_api_gateway_rest_api.screenshot_api.execution_arn}/*/*/*"
}
Super, nous avons maintenant les permissions appropriées. Configurons notre intégration avec la fonction lambda :
resource "aws_api_gateway_integration" "lambda_integration_get" {
depends_on = [
aws_lambda_permission.apigw
]
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_method.take_screenshot_get.resource_id
http_method = aws_api_gateway_method.take_screenshot_get.http_method
integration_http_method = "POST" # https://github.com/hashicorp/terraform/issues/9271 Lambda nécessite POST comme type d'intégration
type = "AWS_PROXY"
uri = aws_lambda_function.take_screenshot.invoke_arn
}
resource "aws_api_gateway_integration" "lambda_integration_post" {
depends_on = [
aws_lambda_permission.apigw
]
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
resource_id = aws_api_gateway_method.take_screenshot_post.resource_id
http_method = aws_api_gateway_method.take_screenshot_post.http_method
integration_http_method = "POST" # https://github.com/hashicorp/terraform/issues/9271 Lambda nécessite POST comme type d'intégration
type = "AWS_PROXY"
uri = aws_lambda_function.take_screenshot.invoke_arn
}
Cette intégration indique à l'API Gateway quelle fonction lambda invoquer lorsqu'elle reçoit une requête à l'endpoint et à la méthode HTTP spécifiés.
Presque terminé avec la passerelle, je vous le promets. En dernier lieu, assurons-nous que notre API peut envoyer des logs à CloudWatch :
resource "aws_api_gateway_account" "apigw_account" {
cloudwatch_role_arn = aws_iam_role.apigw_cloudwatch.arn
}
resource "aws_iam_role" "apigw_cloudwatch" {
# https://gist.github.com/edonosotti/6e826a70c2712d024b730f61d8b8edfc
name = "api_gateway_cloudwatch_global"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "apigateway.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy" "apigw_cloudwatch" {
name = "default"
role = aws_iam_role.apigw_cloudwatch.id
policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogGroups",
"logs:DescribeLogStreams",
"logs:PutLogEvents",
"logs:GetLogEvents",
"logs:FilterLogEvents"
],
"Resource": "*"
}
]
}
EOF
}
Nous avons maintenant donné à l'API Gateway les permissions requises pour écrire des logs dans CloudWatch.
Enfin, nous déployons notre API. Nous utilisons depends_on pour nous assurer que le déploiement se produit après la création de toutes les dépendances.
resource "aws_api_gateway_deployment" "api_gateway_deployment_get" {
depends_on = [aws_api_gateway_integration.lambda_integration_get, aws_api_gateway_method.take_screenshot_get, aws_api_gateway_integration.lambda_integration_post, aws_api_gateway_method.take_screenshot_post]
rest_api_id = aws_api_gateway_rest_api.screenshot_api.id
}
Emballage Lambda
Dans main.tf, ajoutez ce qui suit :
data "archive_file" "screenshot_service_zip" {
type = "zip"
source_dir = "./lambda"
output_path = "./screenshot-service.zip"
}
data "archive_file" "screenshot_service_layer_zip" {
type = "zip"
source_dir = "./chromedriver_layer"
output_path = "./chromedriver_lambda_layer.zip"
}
Sorties
Créez un fichier appelé output.tf à la racine de votre répertoire de projet et ajoutez ce qui suit :
output "api_gateway_url" {
value = "${aws_api_gateway_stage.prod_stage.invoke_url}/${aws_api_gateway_resource.screenshot_api_gateway.path_part}"
}
output "api_key" {
value = aws_api_gateway_api_key.apigw_prod_key.value
}
Maintenant, une fois que vous exécutez .\terraform apply, vous obtiendrez une sortie avec l'URL de l'API et la clé API associée.
Félicitations ! Vous avez maintenant un service de capture d'écran fonctionnel. Pour voir le code que j'ai utilisé, n'hésitez pas à consulter mon dépôt Github.