


Article original : How to Create a Real-Time Gesture-to-Text Translator Using Python and Mediapipe
Les langages de signes et de symboles, comme le Makaton et l'American Sign Language (ASL), sont de puissants outils de communication. Cependant, ils peuvent poser des défis lors de la communication avec des personnes qui ne les comprennent pas.
En tant que chercheur travaillant sur l'IA pour l'accessibilité, j'ai voulu explorer comment l'apprentissage automatique (machine learning) et la vision par ordinateur pourraient combler ce fossé. Le résultat est un traducteur de gestes en texte en temps réel construit avec Python et Mediapipe, capable de détecter les gestes de la main et de les convertir instantanément en texte.
Dans ce tutoriel, vous apprendrez à construire votre propre version à partir de zéro, même si vous n'avez jamais utilisé Mediapipe auparavant.
À la fin, vous saurez comment :
Détecter et suivre les mouvements de la main en temps réel.
Classifier les gestes à l'aide d'un modèle simple d'apprentissage automatique.
Convertir les gestes reconnus en texte.
Étendre le système pour des applications axées sur l'accessibilité.
Prérequis
Avant de suivre ce tutoriel, vous devriez avoir :
Des connaissances de base en Python – Vous devez être à l'aise pour écrire et exécuter des scripts Python.
Une familiarité avec la ligne de commande – Vous l'utiliserez pour exécuter des scripts et installer des dépendances.
Une webcam fonctionnelle – Nécessaire pour capturer et reconnaître les gestes en temps réel.
Python installé (3.8 ou plus récent) – Avec
pippour l'installation des paquets.Une certaine compréhension des bases du machine learning – Savoir ce que sont les données d'entraînement et les modèles vous aidera, mais j'expliquerai les parties clés en cours de route.
Une connexion internet – Pour installer les bibliothèques telles que Mediapipe et OpenCV.
Si vous êtes complètement nouveau sur Mediapipe ou OpenCV, ne vous inquiétez pas, je passerai en revue les parties essentielles que vous devez connaître pour faire fonctionner ce projet.
Table des matières
Pourquoi cela est important
La communication accessible est un droit, pas un privilège. Les traducteurs de gestes en texte peuvent :
Aider les personnes n'utilisant pas la langue des signes à communiquer avec les utilisateurs de langages de signes/symboles.
Aider dans les contextes éducatifs pour les enfants ayant des difficultés de communication.
Soutenir les personnes ayant des troubles de l'élocution.
Note : Ce projet est une preuve de concept et doit être testé avec des ensembles de données diversifiés avant un déploiement en conditions réelles.
Outils et technologies
Nous utiliserons :
| Outil | Objectif |
| Python | Langage de programmation principal |
| Mediapipe | Suivi des mains et détection de gestes en temps réel |
| OpenCV | Entrée webcam et affichage vidéo |
| NumPy | Traitement des données |
| Scikit-learn | Classification des gestes |
Étape 1 : Comment installer les bibliothèques requises
Avant d'installer les dépendances, assurez-vous d'avoir installé la version 3.8 de Python ou une version supérieure (par exemple, Python 3.8, 3.9, 3.10 ou plus récent). Vous pouvez vérifier votre version actuelle de Python en ouvrant un terminal (Invite de commandes sur Windows, ou Terminal sur macOS/Linux) et en tapant :
python --version
ou
python3 --version
Vous devez confirmer que votre version de Python est 3.8 ou supérieure car Mediapipe et certaines dépendances nécessitent des fonctionnalités de langage modernes et des binary wheels. Si les commandes ci-dessus affichent une version antérieure à 3.8, vous devrez installer une version plus récente de Python avant de continuer.
Windows :
Appuyez sur Touche Windows + R
Tapez
cmdet appuyez sur Entrée pour ouvrir l'invite de commandesTapez l'une des commandes ci-dessus et appuyez sur Entrée
macOS/Linux :
Ouvrez votre application Terminal
Tapez l'une des commandes ci-dessus et appuyez sur Entrée
Si votre version de Python est antérieure à 3.8, vous devrez télécharger et installer une version plus récente sur le site officiel de Python.
Une fois que Python est prêt, vous pouvez installer les bibliothèques requises à l'aide de pip :
pip install mediapipe opencv-python numpy scikit-learn pandas
Cette commande installe toutes les bibliothèques dont vous aurez besoin pour le projet :
Mediapipe – suivi des mains et détection des points de repère (landmarks) en temps réel.
OpenCV – lecture des images de votre webcam et dessin des superpositions.
Pandas – stockage des données de points de repère collectées dans un fichier CSV pour l'entraînement.
Scikit-learn – entraînement et évaluation du modèle de classification des gestes.
Étape 2 : Comment Mediapipe suit les mains
La solution Hand Tracking de Mediapipe détecte 21 points de repère (landmarks) clés pour chaque main, y compris le bout des doigts, les articulations et le poignet, jusqu'à 30+ FPS, même sur du matériel modeste.
Voici un diagramme conceptuel des points de repère :

Et voici à quoi ressemble le suivi en temps réel :
![]()
Chaque point de repère possède des coordonnées (x, y, z) relatives à la taille de l'image, ce qui facilite la mesure des angles et des positions pour la classification des gestes.
Étape 3 : Pipeline du projet
Voici comment le système fonctionne, de la webcam à la sortie texte :

Capture : Les images de la webcam sont capturées via OpenCV.
Détection : Mediapipe localise les points de repère de la main.
Vectorisation : Les points de repère sont aplatis en un vecteur numérique.
Classification : Un modèle d'apprentissage automatique prédit le geste.
Sortie : Le geste reconnu est affiché sous forme de texte.
Exemple de détection de main de base :
import cv2
import mediapipe as mp
mp_hands = mp.solutions.hands
mp_draw = mp.solutions.drawing_utils
cap = cv2.VideoCapture(0)
with mp_hands.Hands(max_num_hands=1) as hands:
while True:
ret, frame = cap.read()
if not ret:
break
results = hands.process(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
mp_draw.draw_landmarks(frame, hand_landmarks, mp_hands.HAND_CONNECTIONS)
cv2.imshow("Hand Tracking", frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
Le code ci-dessus ouvre la webcam et traite chaque image avec la solution Hands de Mediapipe. L'image est ensuite convertie en RGB (comme l'attend Mediapipe), lance la détection et, si une main est trouvée, dessine les 21 points de repère et leurs connexions sur l'image. Vous pouvez appuyer sur q pour fermer la fenêtre. Ce fragment de code vérifie votre configuration et vous permet de voir que le suivi des points de repère fonctionne avant de continuer.
Étape 4 : Comment collecter les données de gestes
Avant de pouvoir entraîner notre modèle, nous avons besoin d'un ensemble de données de gestes étiquetés. Chaque geste sera stocké dans un fichier CSV (gesture_data.csv) contenant les coordonnées 3D des points de repère pour tous les points de main détectés.
Par exemple, nous collecterons des données pour trois gestes :
thumbs_up – la pose classique du pouce levé.
open_palm – une main plate, doigts tendus (comme un "high five").
ok – le signe "OK", formé en touchant le pouce et l'index.
Vous pouvez collecter des échantillons pour chaque geste en exécutant :
python src/collect_data.py --label thumbs_up --samples 200
python src/collect_data.py --label open_palm --samples 200
python src/collect_data.py --label ok --samples 200
Explication de la commande :
--label→ le nom du geste que vous enregistrez. Cette étiquette sera stockée à côté de chaque ligne de coordonnées dans le CSV.--samples→ le nombre d'images à capturer pour ce geste. Plus d'échantillons mènent généralement à une meilleure précision.
Comment fonctionne le processus :
Lorsque vous lancez une commande, votre webcam s'ouvre.
Faites le geste spécifié devant la caméra.
Le script utilisera MediaPipe Hands pour détecter les 21 points de repère de la main (chacun avec des coordonnées
x,y,z).Ces 63 nombres (21 × 3) sont stockés dans une ligne du fichier CSV, avec l'étiquette du geste.
Le compteur en haut suivra le nombre d'échantillons collectés.
Lorsque le nombre d'échantillons atteint votre cible (
--samples), le script se fermera automatiquement.
Exemple de ce à quoi ressemble le CSV :
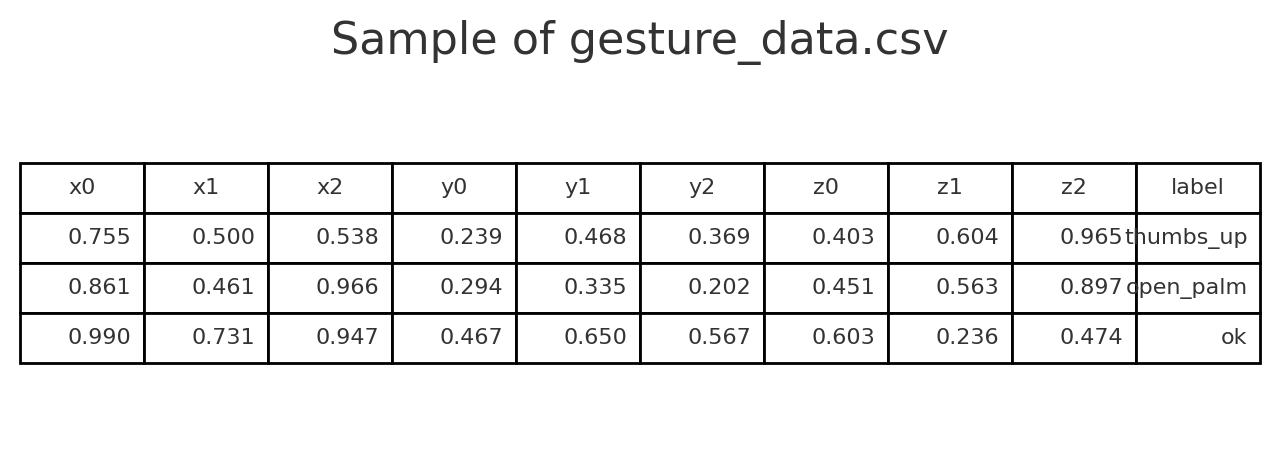
Chaque ligne contient :
x0, y0, z0 … x20, y20, z20 → coordonnées de chaque point de repère de la main.
label → le nom du geste.
Exemple de collecte de données en cours :

Dans la capture d'écran ci-dessus, le script capture 10 sur 10 échantillons thumbs_up.
📌 Astuce : Assurez-vous que votre main est bien visible et bien éclairée. Répétez le processus pour tous les gestes que vous souhaitez entraîner.
Étape 5 : Comment entraîner un classificateur de gestes
Une fois que vous avez assez d'échantillons pour chaque geste, entraînez un modèle :
python src/train_model.py --data data/gesture_data.csv --label palm_open
Ce script :
Charge l'ensemble de données CSV.
Divise les données en ensembles d'entraînement et de test.
Entraîne un Random Forest Classifier.
Affiche la précision et un rapport de classification.
Sauvegarde le modèle entraîné.
Logique d'entraînement principale :
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
import pickle
# Charger le dataset
df = pd.read_csv("data/gesture_data.csv")
# Séparer les caractéristiques et les étiquettes
X = df.drop("label", axis=1)
y = df["label"]
# Initialiser et entraîner le Random Forest Classifier
model = RandomForestClassifier()
model.fit(X, y)
# Sauvegarder le modèle entraîné dans un fichier
with open("data/gesture_model.pkl", "wb") as f:
pickle.dump(model, f)
Ce bloc charge l'ensemble de données de gestes depuis data/gesture_data.csv et le divise en :
X– les caractéristiques d'entrée (les coordonnées 3D des points de repère pour chaque échantillon de geste).y– les étiquettes (noms des gestes commethumbs_up,open_palm,ok).
Nous avons ensuite créé un Random Forest Classifier, qui est bien adapté aux données numériques et fonctionne de manière fiable sans trop de réglages. Le modèle apprend des motifs dans les positions des points de repère qui correspondent à chaque geste.
Enfin, nous avons sauvegardé le modèle entraîné sous le nom data/gesture_model.pkl afin qu'il puisse être chargé plus tard pour la reconnaissance de gestes en temps réel sans réentraînement.
Étape 6 : Traduction de gestes en texte en temps réel
Chargez le modèle et lancez le traducteur :
python src/gesture_to_text.py --model data/gesture_model.pkl
Cette commande exécute le script de reconnaissance de gestes en temps réel.
L'argument
--modelindique au script quel fichier de modèle entraîné charger — dans ce cas,gesture_model.pklque nous avons sauvegardé précédemment.Une fois lancé, le script ouvre votre webcam, détecte les points de repère de votre main et utilise le modèle pour prédire le geste.
Le nom du geste prédit apparaît sous forme de texte sur le flux vidéo.
Appuyez sur
qpour quitter la fenêtre quand vous avez terminé.
Logique de prédiction principale :
with open("data/gesture_model.pkl", "rb") as f:
model = pickle.load(f)
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
coords = []
for lm in hand_landmarks.landmark:
coords.extend([lm.x, lm.y, lm.z])
gesture = model.predict([coords])[0]
cv2.putText(frame, gesture, (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
Ce code charge le modèle de reconnaissance de gestes entraîné depuis gesture_model.pkl.
Si des mains sont détectées (results.multi_hand_landmarks), il boucle à travers chaque main détectée et :
Extrait les coordonnées – pour chacun des 21 points de repère, il ajoute les valeurs
x,yetzà la listecoords.Effectue une prédiction – transmet
coordsà la méthodepredictdu modèle pour obtenir l'étiquette de geste la plus probable.Affiche le résultat – utilise
cv2.putTextpour dessiner le nom du geste prédit sur le flux vidéo.
C'est l'étape de prise de décision en temps réel qui transforme les données brutes des points de repère de Mediapipe en une étiquette de geste lisible.
Vous devriez voir le geste reconnu en haut du flux vidéo :

Étape 7 : Étendre le projet
Vous pouvez aller plus loin avec ce projet en :
Ajoutant la synthèse vocale : Utilisez
pyttsx3pour faire prononcer les mots reconnus.Prenant en charge plus de gestes : Élargissez votre ensemble de données.
Déployant dans le navigateur : Utilisez TensorFlow.js pour une reconnaissance basée sur le Web.
Testant avec de vrais utilisateurs : Particulièrement dans des contextes d'accessibilité.
Considérations éthiques et d'accessibilité
Avant le déploiement :
Diversité des données : Entraînez avec des gestes provenant de différentes teintes de peau, tailles de mains et conditions d'éclairage.
Confidentialité : Ne stockez que les coordonnées des points de repère, sauf si vous avez le consentement pour le stockage vidéo.
Contexte culturel : Certains gestes ont des significations différentes selon les cultures.
Conclusion
Dans ce tutoriel, nous avons exploré comment utiliser Python, Mediapipe et l'apprentissage automatique pour construire un traducteur de gestes en texte en temps réel. Cette technologie présente un potentiel passionnant pour l'accessibilité et la communication inclusive et, avec un développement plus poussé, pourrait devenir un outil puissant pour briser les barrières linguistiques.
Vous pouvez trouver le code complet et les ressources ici :
Dépôt GitHub – Gesture_Article