

Article original : How to Build a Job Board Scraper with Python
Par Jess Wilk
Si vous souhaitez apprendre à naviguer sur le marché de l'emploi en constante évolution en extrayant des données de sites d'offres d'emploi comme Indeed.com, alors ce guide est fait pour vous.
Qu'est-ce qu'un Job Scraper ?
À l'ère numérique, des outils connus sous le nom de Job Board Scrapers (ou simplement Job Scrapers) sont devenus indispensables pour les personnes cherchant à automatiser le processus de collecte de données à partir de sites d'offres d'emploi.
Les tableaux d'offres d'emploi sont des plateformes en ligne qui présentent de nombreuses offres d'emploi de divers secteurs. Certains exemples populaires incluent Indeed.com et ZipRecruiter.com. Ces tableaux sont le pouls du marché de l'emploi, reflétant les tendances actuelles de l'emploi, les besoins des entreprises et les compétences très demandées.
L'objectif principal d'un Job Scraper est de collecter méticuleusement des détails tels que les titres de poste, les descriptions, les noms des entreprises, les lieux et parfois les données salariales à partir des annonces sur ces sites. Ces informations servent un double objectif : elles aident les chercheurs d'emploi dans leur recherche en leur fournissant un aperçu complet du marché, et les analystes peuvent également les utiliser pour suivre les tendances de l'emploi et la dynamique du marché.
Ce que vous apprendrez ici
Ce tutoriel utilisera le langage de programmation Python, l'outil le plus populaire et polyvalent pour les tâches de web scraping. L'écosystème riche de Python en bibliothèques, telles que BeautifulSoup et Scrapy, en fait un choix idéal pour développer des Job Scrapers efficaces et performants.
Si vous êtes nouveau dans Python, vous pouvez consulter le cours Introduction à Python sur Hyperskill, où je contribue en tant qu'expert.
À la fin de ce guide, vous serez équipé pour créer votre propre Job Scraper et aurez une compréhension plus approfondie du paysage de la recherche d'emploi et de la manière de le naviguer en utilisant des insights basés sur les données.
Que vous soyez un chercheur d'emploi cherchant à obtenir un avantage dans votre recherche, un analyste de données suivant les tendances du marché de l'emploi, ou un développeur intéressé par les aspects techniques du web scraping, ce tutoriel vous fournira des connaissances et des compétences précieuses.
Bons Frameworks Python pour le travail
Il existe plusieurs frameworks et bibliothèques Python que vous pouvez utiliser pour extraire les détails des offres d'emploi d'un site d'offres d'emploi. Ceux-ci sont :
- Beautiful Soup
- Scrapy
- Selenium
- Pyppeteer
Nous utiliserons Pyppeteer pour cet article car il présente certains avantages clés par rapport aux autres bibliothèques. Si vous n'avez pas encore entendu parler de Pyppeteer, il s'agit du port Python du populaire framework Puppeteer. Vous pouvez en apprendre davantage sur Puppeteer à partir du site officiel.
Pyppeteer possède la plupart des fonctionnalités de Puppeteer et est écrit pour les programmeurs Python. Voici quelques-unes de ses fonctionnalités les plus utiles :
- Pyppeteer contrôle un vrai navigateur. De nombreux sites web bloquent les robots d'accès à leurs sites. Comme Pyppeteer utilise un vrai navigateur, vous pouvez éviter de nombreux blocages de ce type.
- Avec Pyppeteer, vous pouvez imiter de manière programmatique des actions utilisateur telles que des clics, des soumissions de formulaires et des entrées clavier. Cela permet de naviguer dans des flux utilisateur complexes, comme nous le ferons dans cet article.
- Parce que Pyppeteer utilise un navigateur complet, il prend naturellement en charge les fonctionnalités web modernes telles que les sélecteurs CSS, XPath et WebSockets. Bien que nous n'ayons besoin que de certaines de ces fonctionnalités modernes pour cet article, il est préférable d'apprendre le scraping avec un tel outil, car vous aurez probablement besoin de ces fonctionnalités lorsque vous effectuerez des tâches de scraping plus complexes.
Voici ce que nous allons couvrir :
- Prérequis
- Comment commencer avec Pyppeteer
- Comment extraire les offres d'emploi avec Pyppeteer
- Comment écrire le code de scraping
- Quelles sont les prochaines étapes ?
Prérequis
Le seul prérequis pour ce tutoriel est d'avoir Python installé sur votre machine. Si ce n'est pas encore fait, allez-y et installez Python à partir du site officiel, et vous êtes prêt à procéder avec le reste de l'article.
Comment commencer avec Pyppeteer
Créer un environnement virtuel
Avant de commencer avec Pyppeteer, créons un environnement virtuel pour ce projet.
python -m venv env
Cette commande créera un nouveau dossier nommé env dans votre répertoire de projet, contenant une installation séparée de Python.
Vous devez activer l'environnement virtuel. Sur Windows, vous pouvez activer l'environnement en utilisant la commande suivante :
.\env\Scripts\activate
Sur MacOS et Linux, vous devez le faire en utilisant la commande suivante :
source env/bin/activate
Installer Pyppeteer
Avec l'environnement virtuel actif, nous pouvons installer Pyppeteer en utilisant pip, le gestionnaire de paquets. Pip est déjà installé lorsque vous installez Python.
pip install pyppeteer
Après avoir exécuté la commande ci-dessus, pip téléchargera et installera Pyppeteer et ses dépendances.
N'oubliez pas que Pyppeteer téléchargera une version récente de Chromium compatible avec la version de l'API qu'il utilise.
Supposons que vous avez déjà une installation locale de Chrome/Chromium, et que vous souhaitez que Pyppeteer utilise celle-ci à la place. Dans ce cas, vous pouvez définir la variable d'environnement PYPPETEER_CHROMIUM_REVISION à une chaîne vide avant d'installer Pyppeteer. Cela empêchera Pyppeteer de télécharger Chromium.
export PYPPETEER_CHROMIUM_REVISION=""
pip install pyppeteer
Cependant, la définition des variables d'environnement est différente sur Windows. Vous devez utiliser la commande suivante pour cela :
set PYPPETEER_CHROMIUM_REVISION=
pip install pyppeteer
Comment extraire les offres d'emploi avec Pyppeteer
Identifier les données cibles sur les tableaux d'offres d'emploi
Avant d'écrire votre code de scraping, examinez le site web que vous prévoyez de scraper.
Visitez des sites d'offres d'emploi comme Indeed.com et ZipRecruiter.com. Inspectez les éléments de la page où les détails des offres d'emploi sont affichés (cliquez avec le bouton droit sur la page et sélectionnez "Inspecter" dans la plupart des navigateurs). Prenez note de la structure HTML et des noms de classe des éléments contenant les titres de poste, les descriptions, les noms des entreprises, les lieux et autres informations pertinentes.
Dans cet article, vous apprendrez à scraper Indeed.com. Allez sur Indeed.com, et vous verrez la page d'accueil suivante :
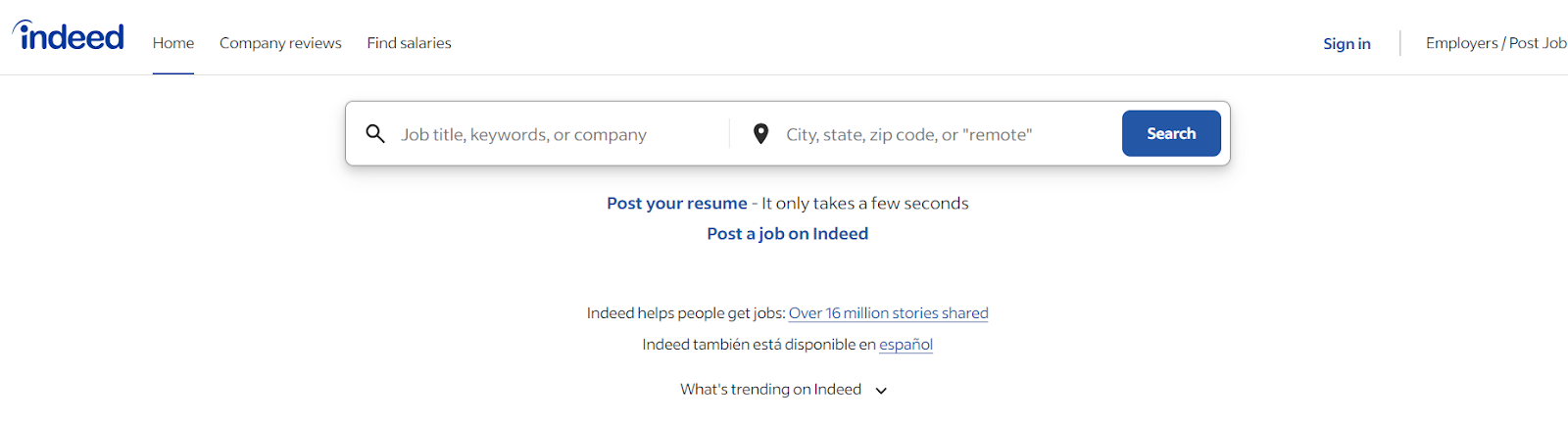
Il y a un bouton de recherche avec deux champs de saisie. Vous pouvez taper le titre du poste dans le premier champ de saisie et le pays dans le deuxième champ de saisie.
Tapons "Software Engineer" pour le titre du poste et "USA" pour le pays, puis cliquons sur "Search". Vous serez alors redirigé vers une nouvelle page qui contient toutes les offres d'emploi liées aux ingénieurs logiciels aux États-Unis. Maintenant, nous pouvons extraire les détails des offres d'emploi de cette page redirigée.
Alors, quelles sont les étapes pour automatiser ce processus ?
- Ouvrir une instance de navigateur.
- Aller sur Indeed.com.
- Ajouter "Software Engineer" au premier champ de saisie.
- Ajouter "USA" au deuxième champ de saisie.
- Cliquer sur le bouton "Search".
Pour accomplir les étapes 3 et 4, nous devons inspecter la page web et trouver des valeurs d'attributs uniques pour ces éléments HTML.
En examinant le code source HTML de la page, vous remarquerez que l'ID du champ de saisie du titre du poste est "text-input-what", et l'ID du deuxième champ de saisie, où vous entrez l'emplacement, est "text-input-where".
Après avoir cliqué sur "Search", nous serons redirigés vers une nouvelle page.
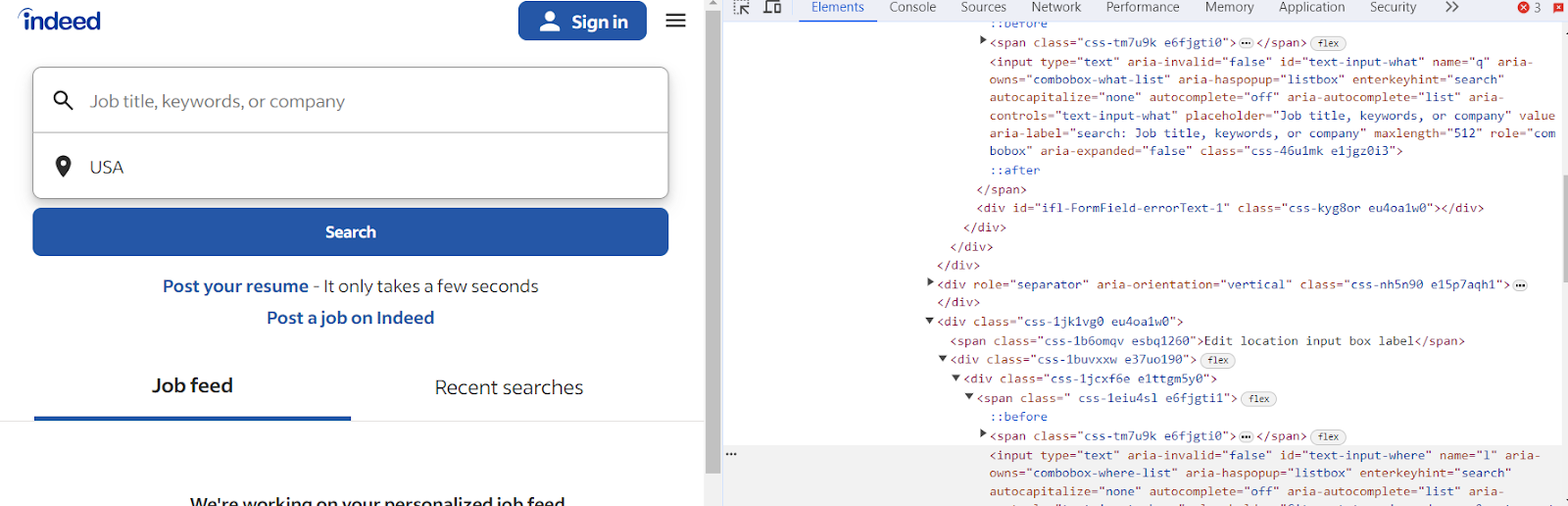
Sur cette page, notre objectif est d'extraire des détails comme le titre du poste, le nom de l'entreprise et l'emplacement du poste. Un examen attentif du code HTML révèle ce qui suit :
- Les titres de poste sont enfermés dans des balises h2 qui ont la classe jobTitle.
- Les noms des entreprises sont situés à l'intérieur d'une balise span imbriquée dans une div portant l'attribut data-testid= "company-name".
- Les emplacements peuvent être trouvés dans une balise span et à l'intérieur d'une div, mais celle-ci a l'attribut data-testid= "text-location".
Avec cette compréhension, procédons à l'écriture de notre code.
Comment écrire le code de scraping
Dans Pyppeteer, nous pouvons utiliser les lignes de code suivantes pour exécuter les étapes mentionnées ci-dessus.
Tout d'abord, lancez l'instance du navigateur.
browser = await launch(headless=False)
page = await browser.newPage()
Ensuite, allez sur indeed.com.
await page.goto('https://www.indeed.com')
Attendez que les éléments de champ de saisie se chargent. Cette étape est cruciale car le code s'exécute souvent plus rapidement que la page ne se charge.
await page.waitForSelector('#text-input-what')
await page.waitForSelector('#text-input-where')
Tapez 'Software Engineer' dans le champ de saisie du titre du poste et tapez 'USA' dans le champ de saisie de l'emplacement.
await page.type('#text-input-what', 'Software Engineer')
await page.type('#text-input-where', 'USA')
Cliquez sur le bouton de recherche.
await page.click('button[type="submit"]')
Attendez que la page suivante se charge
await page.waitForNavigation()
Extrayez le titre du poste, le nom de l'entreprise et l'emplacement du poste et imprimez les informations.
job_listings = await page.querySelectorAll('.resultContent')
for job in job_listings:
# Extrayez le titre du poste
title_element = await job.querySelector('h2.jobTitle span[title]')
title = await page.evaluate('(element) => element.textContent', title_element)
# Extrayez le nom de l'entreprise
company_element = await job.querySelector('div.company_location [data-testid="company-name"]')
company = await page.evaluate('(element) => element.textContent', company_element)
# Extrayez l'emplacement
location_element = await job.querySelector('div.company_location [data-testid="text-location"]')
location = await page.evaluate('(element) => element.textContent', location_element)
print({'title': title, 'company': company, 'location': location})
Fermez le navigateur.
await browser.close()
Une fois que nous avons assemblé le code complet, nous obtenons le code que vous voyez ci-dessous. async et await sont des mots-clés utilisés en programmation asynchrone. Si vous souhaitez en apprendre davantage à ce sujet, vous pouvez lire cet article. La programmation asynchrone est utile pour rendre le scraping plus efficace.
import asyncio
from pyppeteer import launch
async def scrape_indeed():
browser = await launch(headless=False)
page = await browser.newPage()
await page.goto('https://www.indeed.com')
await page.waitForSelector('#text-input-what')
await page.waitForSelector('#text-input-where')
await page.type('#text-input-what', 'Software Engineer')
await page.type('#text-input-where', 'USA')
await page.click('button[type="submit"]')
await page.waitForNavigation()
job_listings = await page.querySelectorAll('.resultContent')
for job in job_listings:
# Extrayez le titre du poste
title_element = await job.querySelector('h2.jobTitle span[title]')
title = await page.evaluate('(element) => element.textContent', title_element)
# Extrayez le nom de l'entreprise
company_element = await job.querySelector('div.company_location [data-testid="company-name"]')
company = await page.evaluate('(element) => element.textContent', company_element)
# Extrayez l'emplacement
location_element = await job.querySelector('div.company_location [data-testid="text-location"]')
location = await page.evaluate('(element) => element.textContent', location_element)
print({'title': title, 'company': company, 'location': location})
await browser.close()
# Exécutez la coroutine
if __name__ == '__main__':
asyncio.run(scrape_indeed())
À mesure que vous vous familiarisez avec chaque ligne de ce code, vous pouvez l'expérimenter de diverses manières. Par exemple, vous pouvez ajouter différentes villes et titres de poste pour extraire des résultats diversifiés.
Le scraping de tout autre site suit un processus similaire. Tout ce que vous avez à faire est d'identifier les éléments HTML pertinents et leurs attributs uniques liés aux détails que vous souhaitez extraire, puis d'ajuster le code en conséquence.
Quelles sont les prochaines étapes ?
En tant que prochaines étapes, vous pouvez faire ce qui suit :
Stocker les données extraites
Au lieu de simplement imprimer les données extraites, vous pouvez les stocker dans un fichier CSV ou JSON pour une utilisation ultérieure. Vous pouvez le faire avec l'extrait de code suivant, qui sauvegarde les données au format CSV.
with open('jobs.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Title', 'Company', 'Location'])
Nettoyer et organiser les données
Une fois que vous avez extrait les données nécessaires, le nettoyage et l'organisation efficaces de ces données constituent l'étape critique suivante.
Ce processus implique la suppression des entrées en double pour garantir que chaque annonce est unique, la standardisation des titres de poste à un format standard pour une comparaison facile, ou le filtrage des annonces qui ne répondent pas à vos critères spécifiques. Cette étape est cruciale pour créer une liste raffinée d'offres d'emploi pertinentes et précieuses pour les utilisateurs.
De plus, envisagez de catégoriser les données dans différents champs comme 'Liste des entreprises' et 'Entreprise pertinente', ce qui peut aider à structurer les données de manière plus cohérente et à les rendre conviviales pour l'analyse et la récupération.
Créer une interface de tableau d'offres d'emploi
Après avoir nettoyé et organisé vos données, il est temps de décider d'un framework ou d'un outil pour présenter votre liste curée d'offres d'emploi.
Que vous optiez pour une page web basique pour un affichage simple des annonces, une application web complexe avec des capacités de recherche et de filtrage avancées, ou une application mobile pour un accès en déplacement, l'essentiel est de garantir que votre portail d'offres d'emploi est convivial et accessible.
Votre interface doit permettre aux utilisateurs de naviguer facilement à travers la 'Liste des offres d'emploi' et d'explorer les opportunités par catégories telles que le titre du poste, la taille de l'entreprise, l'emplacement et autres critères pertinents.
Considérer les aspects légaux et éthiques
Comprendre les implications légales et éthiques du web scraping est primordial. Cela inclut le respect du fichier robots.txt de chaque site web que vous scrapez et l'adhésion à leurs conditions d'utilisation.
Les pratiques de scraping éthiques ne concernent pas seulement la conformité – elles visent à garantir que vos activités de scraping n'ont pas d'impact préjudiciable sur le fonctionnement du site web ou n'exploitent pas de manière injuste les données fournies.
Lorsque vous collectez des données à partir de sites d'entreprises et de portails d'offres d'emploi, donnez toujours la priorité à la transparence et au respect de la source de données, en équilibrant la collecte de données et les normes éthiques.
Conclusion
Avec ces étapes, vous devriez avoir un scraper de tableau d'offres d'emploi fonctionnel utilisant Python et Pyppeteer. N'oubliez pas que le web scraping peut être complexe en raison de la nature dynamique des pages web, alors attendez-vous à faire des ajustements à mesure que les sites web changent leur structure au fil du temps.
Merci d'avoir lu ! Je suis Jess, et je suis un expert chez Hyperskill. Vous pouvez consulter un cours Introduction à Python sur la plateforme.