

Article original : How to Build a Task Manager CLI Tool with Node.js
Par Krish Jaiswal
Bonjour à tous 44b Dans ce tutoriel, vous apprendrez à créer un outil CLI (Interface en Ligne de Commande) simple de gestion de tâches. Cela signifie que vous pourrez utiliser des commandes pour Créer, Voir, Mettre à jour ou Supprimer vos tâches.
Nous allons construire cet outil CLI en utilisant NodeJS. Nous utiliserons également MongoDB comme base de données pour stocker toutes nos tâches. Enfin, nous utiliserons quelques packages utiles de npm :
- commander : Cela nous aide à construire l'outil CLI.
- chalk : Cela rend les messages dans le terminal colorés et faciles à lire.
- inquirer : Cela nous permet de demander des entrées à l'utilisateur.
- ora : Cela fait apparaître de belles animations de chargement dans le terminal.
Avant de plonger dans le vif du sujet, je veux que vous sachiez que vous pouvez trouver le code complet de ce projet sur GitHub. Si vous n'êtes pas sûr de quelque chose dans le code, vous pouvez toujours vous référer à la version finale disponible là-bas.
Voici le lien vers le dépôt : Dépôt de l'outil CLI de gestion de tâches.
Table des matières :
- Installation du projet
- Comment se connecter à la base de données
- Comment créer un modèle Mongoose
- Travailler sur les opérations CRUD
- Comment écrire le point d'entrée CLI en utilisant Commander
- Comment tester l'outil CLI
- Conclusion
Installation du projet
Bienvenue dans la première section de ce manuel ! Ici, nous allons configurer notre projet.
Cela implique quelques étapes simples : créer un nouveau répertoire, configurer le fichier package.json, et installer les packages npm nécessaires comme chalk, inquirer, commander, et d'autres dont nous parlerons bientôt. Nous organiserons également le projet en créant des dossiers.
Avant de plonger dans le vif du sujet, assurons-nous que vous avez NodeJS installé sur votre système. Vous pouvez obtenir la dernière version LTS depuis ce site : https://nodejs.org/en.
Pour vérifier si Node est correctement installé, tapez cette commande : node --version. Si vous voyez un numéro de version, vous êtes prêt ! Sinon, vous devez résoudre les erreurs.
Une fois que NodeJS est opérationnel, créez un nouveau dossier nommé "todo". Vous pouvez utiliser votre éditeur de code préféré (je préfère Visual Studio Code) ou suivre ces étapes dans votre terminal :
- Créez un nouveau dossier :
mkdir todo - Allez dans le dossier :
cd todo - Ouvrez-le dans votre éditeur de code :
code .
Comment créer le fichier package.json
La première et la plus importante étape est de configurer le fichier package.json. Mais ne vous inquiétez pas de le faire manuellement. Vous pouvez gagner du temps en utilisant cette commande :
npm init --yes
Une fois cette étape terminée, passons à l'étape suivante et obtenons toutes les choses nécessaires pour notre projet.
Comment installer les dépendances
Pour construire ce projet, nous aurons besoin de quelques packages. Exécutez simplement cette commande simple pour les obtenir tous :
npm i commander inquirer chalk ora mongoose nanoid dotenv
Comment convertir les modules CommonJS en modules ES
Avant de continuer, faisons un petit changement dans le fichier package.json. Supprimez cette ligne : "main": "index.js", et ajoutez ces deux lignes à la place :
"exports": "./index.js",
"type": "module",
Avec ces changements, nous convertissons notre projet des modules CommonJS aux modules ES. Cela signifie que nous utiliserons import au lieu de require() pour importer des modules, et export au lieu de module.exports pour partager des choses entre les fichiers.
Si vous souhaitez approfondir les différents types de modules en JavaScript et leur fonctionnement, consultez ce tutoriel sur FreeCodeCamp : Modules en JavaScript - CommonJS et ESmodules Expliqués.
Comment créer la structure des dossiers
Maintenant, organisons notre projet en mettant en place une structure de dossiers intelligente. Cela signifie que nous créerons des dossiers pour contenir proprement nos fichiers JavaScript. Cette étape est vraiment importante. Elle facilite la gestion des choses et permet un développement fluide.
Nous créons 3 dossiers et 2 fichiers dans le dossier principal :
Premier dossier : commands. À l'intérieur de ce dossier, vous créerez 4 fichiers. Les noms des fichiers et la description du code qu'ils contiendront sont mentionnés ci-dessous :
addTask.js: Code pour créer une nouvelle tâche.deleteTask.js: Code pour supprimer une tâche.readTask.js: Code pour afficher toutes les tâches.updateTask.js: Code pour mettre à jour une tâche.
Deuxième dossier : db. À l'intérieur de ce dossier, ajoutez un fichier nommé connectDB.js. Ce fichier contiendra le code pour se connecter à la base de données MongoDB et se déconnecter lorsque nécessaire.
Troisième dossier : schema. À l'intérieur, créez un fichier nommé TodoSchema.js. Ce fichier stocke le schéma et le modèle Mongoose. En gros, un plan pour nos tâches, c'est-à-dire à quoi nos tâches ressembleront.
Premier fichier : .env. Créez ce fichier dans le répertoire racine/dossier principal du projet. C'est là que vous mettrez votre chaîne de connexion MongoDB.
Deuxième fichier : Créez le fichier index.js dans le répertoire racine lui-même qui servira de point d'entrée de notre projet. C'est comme la façade du projet - où tout commence.
Une fois que nous avons terminé, la structure des dossiers de votre projet devrait ressembler à ceci :
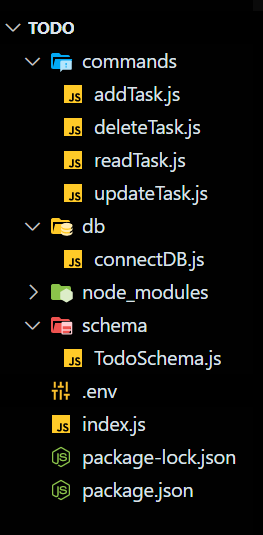 Structure des dossiers du projet
Structure des dossiers du projet
Comment se connecter à la base de données
Maintenant que vous avez configuré le projet avec succès, il est temps de plonger dans la partie excitante.
Comment obtenir une chaîne de connexion MongoDB
Pour garder une trace de toutes nos tâches, nous avons besoin d'un endroit pour les stocker. C'est là qu'intervient MongoDB Atlas. C'est comme un service spécial qui gère les bases de données pour nous. La meilleure partie ? Vous pouvez commencer à l'utiliser gratuitement (aucune carte de crédit requise).
Pour s'y connecter, tout ce dont vous avez besoin est ce qu'on appelle une chaîne de connexion. Si MongoDB Atlas est nouveau pour vous, ne vous inquiétez pas. Consultez cet article facile à suivre : Tutoriel MongoDB Atlas - Comment commencer. Il vous donne juste assez d'informations pour commencer à utiliser Atlas. À la fin, vous saurez comment obtenir ce dont vous avez besoin, y compris la chaîne de connexion.
Une fois que vous avez cette chaîne de connexion, créez une nouvelle chose appelée "variable d'environnement". C'est comme un code secret que votre projet utilise. Ouvrez le fichier .env et faites une ligne comme ceci : MONGO_URI=. Après le =, mettez votre chaîne de connexion.
Rappelez-vous : Remplacez <password> par votre mot de passe réel et <username> par le nom d'utilisateur de votre administrateur de base de données dans la chaîne de connexion. Ajoutez également todos entre /? dans la chaîne. Une fois terminé, votre fichier .env devrait ressembler à ceci :
MONGO_URI=mongodb+srv://<username>:<password>@cluster0.k5tmsld.mongodb.net/todos?retryWrites=true&w=majority
Code pour se connecter à la base de données
Maintenant, plongeons dans le code qui connecte notre outil à la base de données MongoDB. Ouvrez le fichier ./db/connectDB.js et écrivons du code pour faire fonctionner cette connexion.
Tout d'abord, nous devons importer le package dotenv que nous avons récupéré précédemment lors de la configuration du projet et invoquer la méthode config() sur dotenv. Cela nous aide à charger les variables d'environnement depuis le fichier .env. Voici comment faire :
import dotenv from 'dotenv'
dotenv.config()
Ensuite, nous voulons importer quelques packages supplémentaires que nous utiliserons ici. Il s'agit de mongoose, ora et chalk :
import mongoose from 'mongoose'
import ora from 'ora'
import chalk from 'chalk'
Note : mongoose est une bibliothèque de modélisation de données objet (ODM) pour MongoDB. Elle fournit une abstraction de niveau supérieur, ce qui facilite les opérations comme l'ajout, la lecture, la mise à jour et la suppression d'éléments dans la base de données MongoDB.
Maintenant, passons à l'action réelle. Nous allons définir deux fonctions ici : connectDB() et disconnectDB().
La fonction connectDB() contiendra le code pour aider à connecter notre application NodeJS à la base de données MongoDB en utilisant mongoose. C'est comme un appel téléphonique qui les connecte. Si nous n'établissons pas de connexion d'abord, notre application ne pourra pas interagir avec la base de données et effectuer les diverses opérations CRUD.
La fonction disconnectDB() fait l'inverse. C'est comme raccrocher le téléphone après que notre application a fini de parler à la base de données. Si nous ne nous déconnectons pas, c'est comme garder l'appel en cours même après avoir terminé.
Le fait de ne pas se déconnecter de la base de données après avoir fini d'interagir avec elle pourrait causer des fuites de ressources. Cela pourrait ralentir votre application ou potentiellement la faire planter avec le temps.
Voici le code pour les deux fonctions :
export async function connectDB(){
try {
const spinner = ora('Connexion à la base de données...').start()
await mongoose.connect(process.env.MONGO_URI)
spinner.stop()
console.log(chalk.greenBright('Connexion à la base de données réussie !!!'))
} catch (error) {
console.log(chalk.redBright('Erreur : '), error);
process.exit(1)
}
}
export async function disconnectDB(){
try {
await mongoose.disconnect()
console.log(chalk.greenBright('Déconnecté de la base de données.'))
} catch(err) {
console.log(chalk.redBright('Erreur : '), error);
process.exit(1)
}
}
C'est beaucoup de code à assimiler en une seule fois, alors laissez-moi vous expliquer cela :
Dans la fonction connectDB(), la ligne mongoose.connect(process.env.MONGO_URI) nous aide à nous connecter réellement à la base de données en utilisant la chaîne de connexion.
Vous vous souvenez du fichier .env ? Nous utilisons ses informations ici. Pour charger la variable MONGO_URI, nous utilisons le package dotenv et appelons la fonction config(), puis nous pouvons y accéder en utilisant process.env.MONGO_URI.
Puisque mongoose.connect() retourne une promesse, nous utilisons le mot-clé await avant pour nous assurer que nous ne procédons que lorsque cette promesse retournée est résolue.
Il est possible de rencontrer des erreurs lors de l'exécution de ce code, donc nous avons enveloppé tout le code dans un bloc try...catch() pour nous assurer que toute erreur qui apparaît est gérée correctement dans le bloc catch().
Le package ora nous aide à afficher un spinner pendant que nous nous connectons à la base de données. Une fois connecté avec succès, nous arrêtons le spinner et affichons un message joyeux en vert en utilisant chalk.
Si vous remarquez, nous faisons la même chose dans la fonction disconnectDB(). Mais, au lieu de nous connecter, nous nous déconnectons de la base de données en utilisant mongoose.disconnect(). Nous l'enveloppons dans un bloc try-catch similaire, et encore une fois nous affichons des messages colorés en utilisant chalk.
Nous utilisons export avant ces fonctions pour permettre à d'autres parties du projet de les utiliser. N'oubliez pas d'ajouter ces deux lignes temporaires à la fin du fichier pour l'instant :
connectDB()
disconnectDB()
Maintenant, vous pouvez exécuter le fichier connectDB.js en utilisant la commande : node ./db/connectDB.js et vous attendre à voir ceci dans la console :
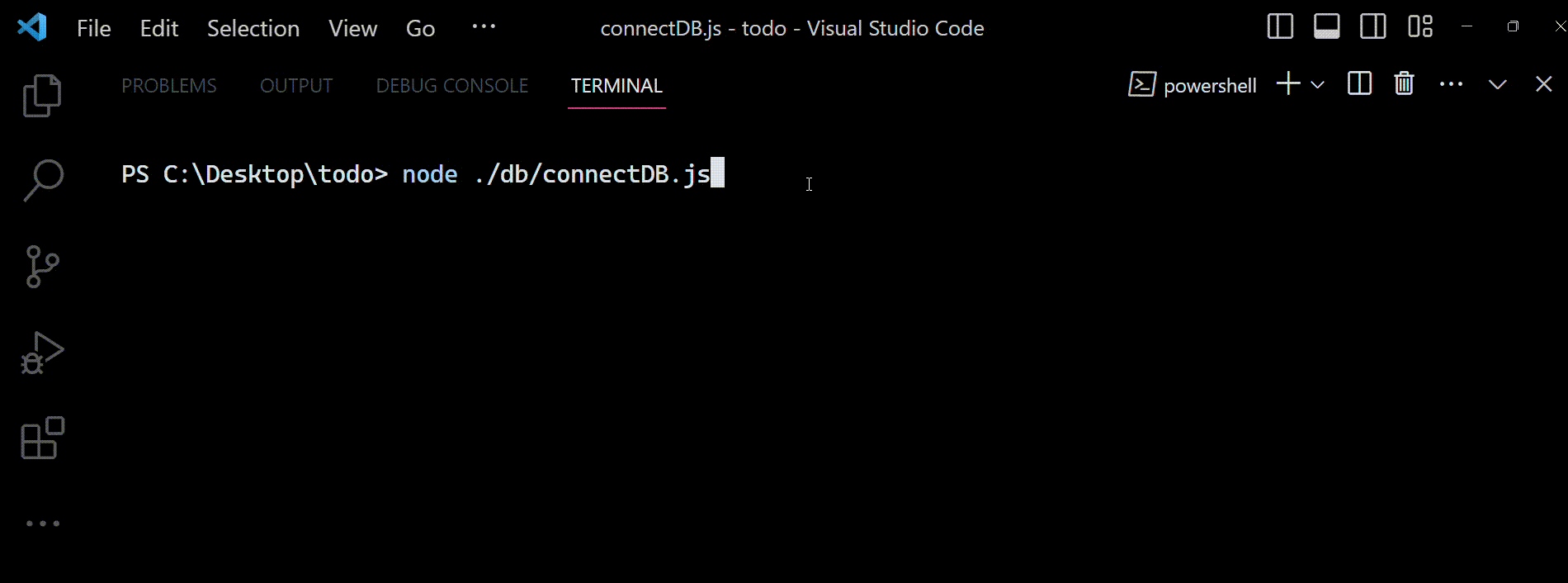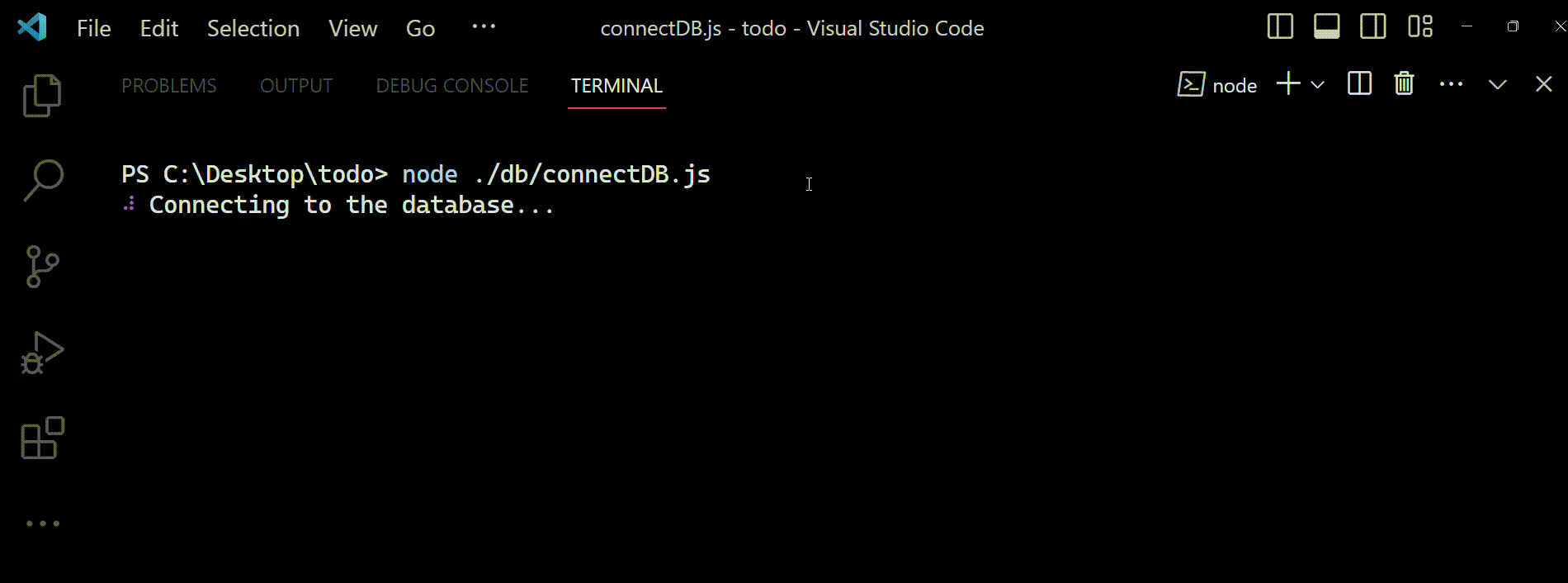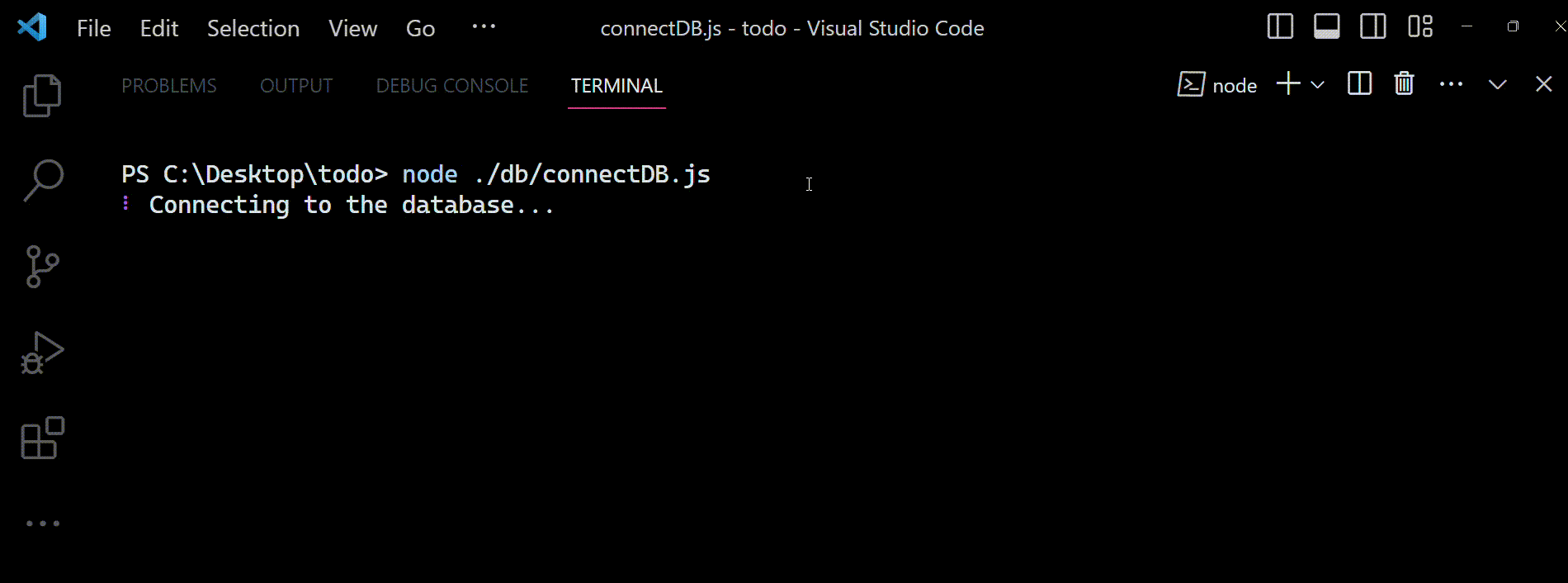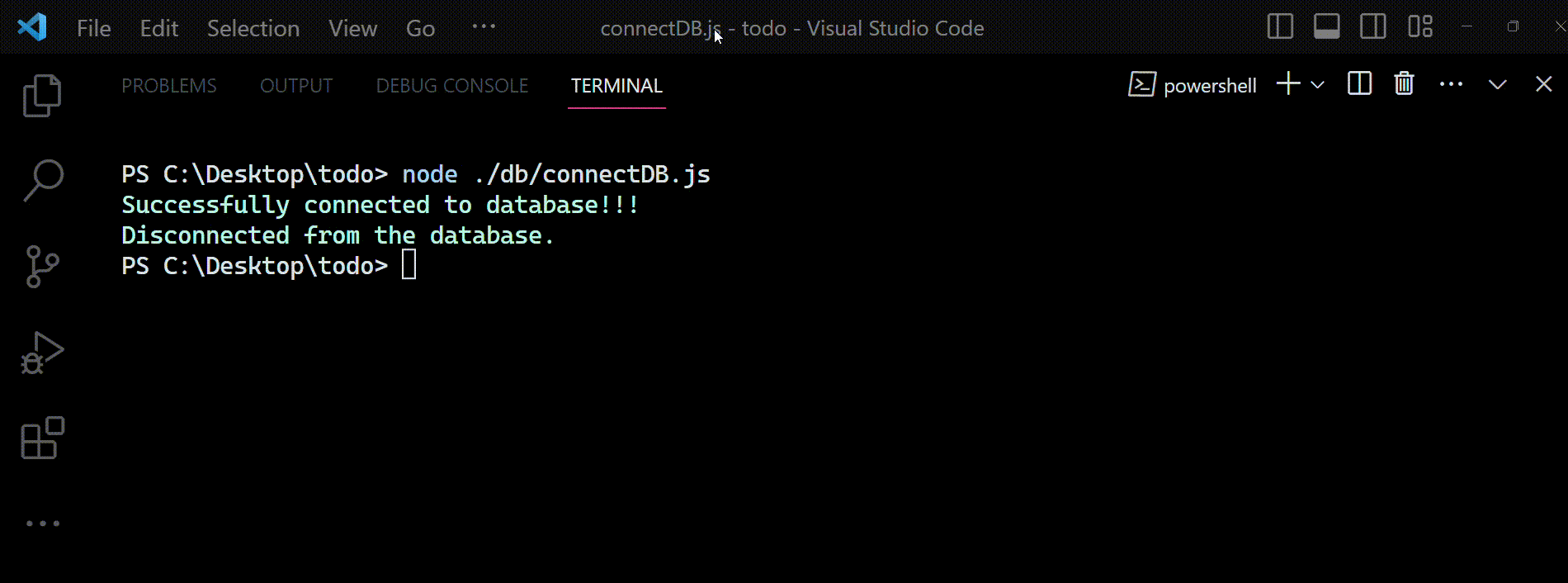 Sortie vue dans le terminal lorsque le fichier
Sortie vue dans le terminal lorsque le fichier connectDB.js est exécuté. Il montre comment notre code se connecte avec succès à la base de données et s'en déconnecte en affichant des messages de console appropriés lorsque nous invoquons les méthodes connectDB() et disconnectDB().
Se connecter à la base de données est une grande étape, mais vous faites de grands progrès ! Avant de continuer, assurez-vous de supprimer ces 2 lignes que vous avez ajoutées à la fin car elles ont été ajoutées juste pour vérifier si nos fonctions de connexion et de déconnexion fonctionnent comme prévu.
Comment créer un modèle Mongoose
Un modèle Mongoose est comme un outil qui nous aide à parler à la base de données. Avec lui, nous pouvons facilement faire des choses comme ajouter, lire, mettre à jour et supprimer des tâches. C'est comme un assistant utile qui comprend comment communiquer avec la base de données.
Pour créer ce modèle, nous avons besoin de quelque chose appelé un Schéma. Il définit essentiellement à quoi chaque tâche devrait ressembler. Pensez-y comme un plan ou un ensemble d'instructions qui guide la création de chaque tâche, quelles informations elle devrait avoir et comment ces informations sont organisées. C'est comme établir des règles pour la façon dont nos tâches sont stockées dans la base de données.
Nous allons construire ce Schéma dans le fichier ./schema/TodoSchema.js. Ouvrez-le, et plongeons-nous. Tout d'abord, nous avons besoin de deux outils spéciaux : mongoose et nanoid. Nous utiliserons nanoid pour créer des identifiants courts et uniques pour chaque tâche.
Tapez ces lignes pour importer les outils :
import mongoose from 'mongoose'
import {nanoid} from 'nanoid'
Maintenant, nous utilisons la méthode mongoose.Schema() pour créer notre Schéma. Voici le code pour cela :
const TodoSchema = new mongoose.Schema({
name: {
type: String,
required: true,
trim: true
},
detail: {
type: String,
required: true,
trim: true
},
status: {
type: String,
required: true,
enum: ['completed', 'pending'],
default: 'pending',
trim: true
},
code: {
type: String,
required: true,
default: 'code',
trim: true
}
}, {timestamps: true})
Toute tâche créée en utilisant ce Schéma aura les propriétés suivantes :
name: Il s'agit d'un titre court pour la tâche. Letype: Stringsouligne qu'il ne peut s'agir que de texte (une chaîne de caractères). Lerequired: truespécifie que nous devons fournir cela lors de la création d'une tâche et letrim: truespécifie que tout espace supplémentaire au début ou à la fin du nom de la tâche sera supprimé avant de l'enregistrer dans la base de données.detail: Il s'agit d'une description de la tâche. Il a exactement les mêmes propriétés quename.status: Cela montre si la tâche est terminée ou non. La propriétéenum: ['completed', 'pending']spécifie qu'elle ne peut être quecompletedoupending. La propriétédefault: 'pending'spécifie que si vous ne définissez pas la propriétéstatuslors de la création de la tâche, elle est supposée êtrepending.code: Il s'agit d'un identifiant court et unique pour la tâche. Nous lui donnons une valeur par défaut decode. Cette valeur est simplement un espace réservé et n'a aucune signification réelle en termes d'identification de la tâche. Ne vous inquiétez pas, nous allons la changer bientôt.- Le
{timestamps: true}est une option de configuration qui ajoute automatiquement des champs de timestamp commecreatedAtetupdatedAtaux tâches lorsqu'elles sont créées ou modifiées.
Nous avons défini avec succès notre Schéma, mais vous pourriez vous demander si la propriété code était censée être unique pour chaque tâche. Actuellement, elle stocke la même valeur, c'est-à-dire "code", pour chaque tâche. Ne vous inquiétez pas, nous allons corriger cela. Ajoutez ce code à la fin :
TodoSchema.pre('save', function(next){
this.code = nanoid(10)
next()
})
Ici, TodoSchema.pre('save', function(){....}) nous aide à définir un hook/fonction pré-enregistrement qui s'exécute chaque fois avant qu'une tâche soit enregistrée dans la base de données.
À l'intérieur de la fonction, nous utilisons nanoid(10) pour créer un identifiant unique de 10 caractères pour la tâche et mettons cet identifiant généré dans le champ code de la tâche (nous pouvons en fait accéder à n'importe quelle propriété/champ de la tâche en utilisant le mot-clé this).
La dernière ligne de code : next() indique essentiellement à l'ordinateur que nous avons terminé et qu'il peut enfin enregistrer le document maintenant. Avec cela, nous générons un identifiant unique pour chaque tâche créée en utilisant le package nanoid.
Enfin, nous allons créer un modèle Todos en utilisant ce plan TodoSchema et l'exporter. Voici comment :
const Todos = mongoose.model('Todos', TodoSchema)
export default Todos
Et voilà ! Nous avons construit notre Schéma et notre Modèle. Maintenant, passons à la section suivante de ce tutoriel.
Comment travailler sur les opérations CRUD
Félicitations pour avoir suivi jusqu'ici. Jusqu'à présent, nous avons fait 3 choses :
- Nous avons configuré le projet
- Nous nous sommes connectés à la base de données MongoDB, et
- Nous avons créé le Modèle Mongoose
Ensuite, nous allons travailler sur les différentes opérations CRUD comme la création, la lecture, la mise à jour et la suppression des tâches de notre base de données.
Comment créer des tâches
Maintenant, commençons par créer des tâches dans notre projet. Au début, j'avais prévu un processus simple où vous ajoutez une tâche à la base de données à la fois. Cela signifie que lorsque vous dites à l'outil de créer une tâche, il vous demande une fois les détails de la tâche, comme le nom et la description, puis il enregistre la tâche.
Mais ensuite, j'ai réalisé, et si quelqu'un veut ajouter plusieurs tâches rapidement ? Le faire une par une n'est pas cool. Il y a deux problèmes :
- Si vous avez, disons, 5 tâches en tête, vous devriez taper la commande de création 5 fois, une pour chaque tâche.
- Après avoir saisi les détails de la tâche, vous attendez un peu car l'enregistrement des données dans la base de données peut prendre du temps, surtout si l'internet est lent.
Ces problèmes ne sont pas amusants du tout ! Pour les résoudre, nous avons besoin d'un moyen d'ajouter plusieurs tâches en une seule fois. Voici comment nous allons faire :
Après avoir saisi le nom et la description de la tâche, nous demanderons si vous voulez ajouter plus de tâches. Si vous entrez oui, nous continuons le processus depuis le début (en vous demandant à nouveau d'entrer le nom et la description de la tâche suivante). Mais si vous entrez non, le processus de question s'arrêtera et toutes les tâches saisies seront enregistrées ensemble dans la base de données. De cette façon, vous pouvez créer plusieurs tâches sans le tracas de le faire une par une. C'est tout pour vous faciliter les choses.
Nous allons écrire du code dans le fichier ./commands/addTask.js. C'est là que la magie opère. Décomposons cela étape par étape :
Tout d'abord, nous importons les packages et fonctions nécessaires que nous avons créés précédemment. Vous pouvez ajouter ces lignes de code pour le faire :
import inquirer from "inquirer";
import { connectDB, disconnectDB } from '../db/connectDB.js'
import Todos from "../schema/TodoSchema.js";
import ora from "ora";
import chalk from "chalk";
Maintenant, nous créons une fonction asynchrone appelée input() pour recueillir le nom et les détails de la tâche auprès de l'utilisateur. Voici comment cela se passe :
async function input(){
const answers = await inquirer.prompt([
{ name: 'name', message: 'Entrez le nom de la tâche :', type: 'input' },
{ name: 'detail', message: 'Entrez les détails de la tâche :', type: 'input' },
])
return answers
}
En termes simples, input() utilise inquirer pour demander à l'utilisateur le nom et les détails de la tâche. Les réponses sont ensuite retournées sous forme d'objet.
Mais attendez, vous pourriez vous demander ce que fait inquirer.prompt(). C'est une méthode dans le package inquirer qui pose des questions et attend des réponses. Vous fournissez un tableau d'objets de questions, chacun contenant des détails comme le message à afficher à l'utilisateur et le type de question. La fonction retourne une Promesse, donc nous utilisons await pour attendre les réponses de l'utilisateur qui sont retournées sous forme d'objet.
Ici, { name: 'name', message: 'Entrez le nom de la tâche :', type: 'input' } est la première question qui sera posée à l'utilisateur. La propriété message contient la question qui sera affichée à l'utilisateur. Dans notre cas, il s'agit de : Entrez le nom de la tâche. L'utilisateur sera invité à saisir du texte (une chaîne de caractères), puisque cette question est de type: 'input'. Le name: 'name' signifie que la réponse de l'utilisateur à cette question sera assignée à une propriété nommée name dans l'objet des réponses.
Le deuxième objet est la deuxième question qui sera posée à l'utilisateur. Dans ce cas, un message sera affiché dans le terminal : Entrez les détails de la tâche et la réponse de l'utilisateur sera assignée à une propriété appelée detail dans l'objet des réponses.
Pour voir comment le code ci-dessus fonctionne, vous pouvez ajouter ces 2 lignes de code à la fin du fichier :
const output = await input()
console.log(output)
Maintenant, enregistrez le fichier et exécutez le code en utilisant la commande : node ./commands/addTask.js. Voici ce que vous verrez lorsque vous exécuterez le code :
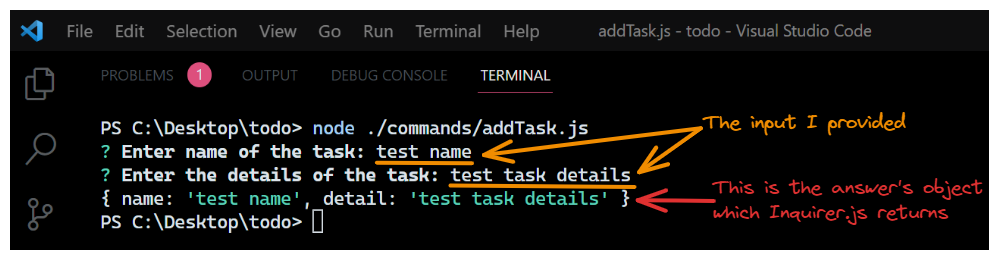 Sortie vue dans le terminal lorsque nous invoquons simplement la méthode
Sortie vue dans le terminal lorsque nous invoquons simplement la méthode input() et exécutons le code. Il montre comment inquirer.js retourne les réponses de l'utilisateur après le processus de question.
Nous pouvons maintenant procéder avec le reste du code et vous pouvez supprimer les 2 dernières lignes que vous venez d'ajouter.
Maintenant, créons une fonction nommée askQuestions() pour recueillir plusieurs tâches. Voici à quoi elle ressemble :
const askQuestions = async() => {
const todoArray = []
let loop = false
do{
const userRes = await input()
todoArray.push(userRes)
const confirmQ = await inquirer.prompt([{ name: 'confirm', message: 'Voulez-vous ajouter plus de tâches ?', type: 'confirm' }])
if(confirmQ.confirm){
loop = true
} else {
loop = false
}
} while(loop)
return todoArray
}
Dans askQuestions(), nous mettons en place une boucle qui continue à demander des tâches jusqu'à ce que l'utilisateur décide de s'arrêter. Nous recueillons chaque tâche auprès de l'utilisateur en appelant la fonction input(), et la réponse de l'utilisateur est ajoutée au todoArray.
Ensuite, nous demandons si l'utilisateur veut ajouter plus de tâches en utilisant une question de confirmation. S'il dit oui, nous définissons loop sur true et la boucle continue, sinon loop devient false, et la boucle se termine. Enfin, nous retournons le tableau des tâches, c'est-à-dire todoArray.
Vous pouvez tester cela en ajoutant ces lignes de code à la fin du fichier :
const output = await askQuestions()
console.log(output)
Lorsque vous exécutez le fichier en utilisant node ./commands/addTask.js, vous verrez un résultat similaire à ce que vous voyez ici :
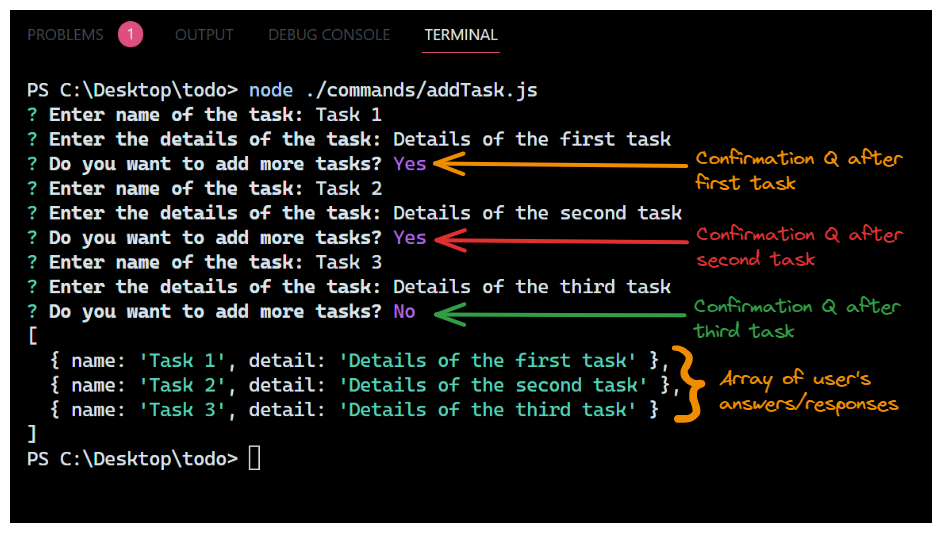 Sortie vue dans le terminal lorsque nous invoquons la méthode
Sortie vue dans le terminal lorsque nous invoquons la méthode askQuestions() et exécutons le code. Il montre le tableau des tâches retourné par la méthode lorsque l'utilisateur ne souhaite pas continuer à ajouter plus de tâches.
Nous y sommes presque ! Avant de continuer, n'oubliez pas de supprimer les 2 dernières lignes que vous venez d'ajouter. Une fois que vous avez fait cela, passons à l'étape suivante.
Jusqu'à présent, nous avons réussi à collecter toutes les tâches que l'utilisateur souhaite créer.
Maintenant, définissons la dernière pièce du puzzle : la fonction addTask(). Cette fonction rassemble tout et complète le processus de création de tâches. Voici le code complet :
export default async function addTask() {
try {
// appel de askQuestions() pour obtenir le tableau des tâches
const userResponse = await askQuestions()
// connexion à la base de données
await connectDB()
// Affichage d'un spinner avec le message de texte suivant en utilisant ora
let spinner = ora('Création des tâches...').start()
// boucle sur chaque tâche dans le tableau userResponse
// et sauvegarde chaque tâche dans la base de données
for(let i=0; i<userResponse.length; i++){
const response = userResponse[i]
await Todos.create(response)
}
// Arrêt du spinner et affichage du message de succès
spinner.stop()
console.log(
chalk.greenBright('Tâches créées !')
)
// déconnexion de la base de données
await disconnectDB()
} catch (error) {
// Gestion des erreurs
console.log('Quelque chose s'est mal passé, Erreur : ', error)
process.exit(1)
}
}
La fonction addTask() commence par appeler la fonction askQuestions() pour recueillir le tableau des tâches et l'assigner à la variable userResponse. Ensuite, elle se connecte à la base de données en utilisant connectDB(), affiche un spinner en utilisant ora pour montrer le processus de création des tâches, parcourt chaque tâche dans le tableau et la sauvegarde dans la base de données en utilisant Todos.create(response).
Une fois que toutes les tâches sont sauvegardées, le spinner s'arrête, un message de succès est affiché, puis elle se déconnecte de la base de données en utilisant disconnectDB().
L'ensemble du code est enveloppé dans un bloc try...catch pour gérer toute erreur potentielle de manière élégante.
Avec ce code, vous avez terminé le processus de création des tâches. Beau travail ! C'était probablement la partie la plus complexe du code dans tout le projet. Les opérations futures telles que la lecture, la suppression et la mise à jour des tâches vont être assez simples et faciles en comparaison. Cela dit, passons à l'opération de lecture.
Comment lire les tâches
Maintenant, nous allons explorer comment lire les tâches depuis la base de données MongoDB. Le processus est simple, et je vais vous guider à travers tout le code dans le fichier ./commands/readTask.js :
Tout d'abord, importons les packages et fonctions nécessaires au début du fichier :
// Importation des packages et fonctions
import { connectDB, disconnectDB } from '../db/connectDB.js'
import Todos from '../schema/TodoSchema.js'
import chalk from 'chalk'
import ora from 'ora'
Maintenant, définissons une fonction asynchrone nommée readTask() qui encapsule la logique pour lire les tâches. Toute la fonction est enveloppée dans un bloc try...catch pour gérer toute erreur potentielle :
export default async function readTask(){
try {
// connexion à la base de données
await connectDB()
// démarrage du spinner
const spinner = ora('Récupération de toutes les tâches...').start()
// récupération de toutes les tâches depuis la base de données
const todos = await Todos.find({})
// arrêt du spinner
spinner.stop()
// vérification si les tâches existent ou non
if(todos.length === 0){
console.log(chalk.blueBright('Vous n'avez pas encore de tâches !'))
} else {
todos.forEach(todo => {
console.log(
chalk.cyanBright('Code de la tâche : ') + todo.code + '\n' +
chalk.blueBright('Nom : ') + todo.name + '\n' +
chalk.yellowBright('Description : ') + todo.detail + '\n'
)
})
}
// déconnexion de la base de données
await disconnectDB()
} catch (error) {
// Gestion des erreurs
console.log('Quelque chose s'est mal passé, Erreur : ', error)
process.exit(1)
}
}
readTask()
Maintenant, décomposons le code étape par étape :
- Nous établissons une connexion à la base de données MongoDB en utilisant
await connectDB(). - Nous démarrons un spinner en utilisant
orapour indiquer que nous récupérons toutes les tâches. - Nous récupérons toutes les tâches depuis la base de données en utilisant
Todos.find({}). Une fois le processus terminé, la variabletodoscontiendra soit un tableau vide (si aucune tâche n'existe dans la base de données) soit un tableau de tâches. - Après la récupération, nous arrêtons le spinner en utilisant
spinner.stop(). - Nous vérifions s'il y a des tâches en vérifiant si
todos.lengthest égal à 0. Si c'est le cas, nous affichons un message en bleu disant "Vous n'avez pas encore de tâches !". S'il y a des tâches dans le tableau (ce qui signifie que la longueur du tableau n'est pas égale à 0), nous parcourons chaque tâche dans le tableau et imprimons son code, son nom et sa description en utilisantchalkpour la coloration. - Enfin, nous nous déconnectons de la base de données en utilisant
await disconnectDB().
Dans la dernière ligne de code, nous appelons la fonction readTask(). Cela est uniquement à des fins de test, et vous pouvez supprimer cette ligne comme indiqué.
Pour exécuter le code, utilisez la commande : node ./commands/readTask.js. Lorsque vous exécutez cela, vous verrez quelque chose de similaire à la sortie montrée ici :
Note : J'avais créé quelques tâches aléatoires auparavant, donc lorsque j'exécute le fichier readTask.js, j'obtiens ceci dans mon terminal :
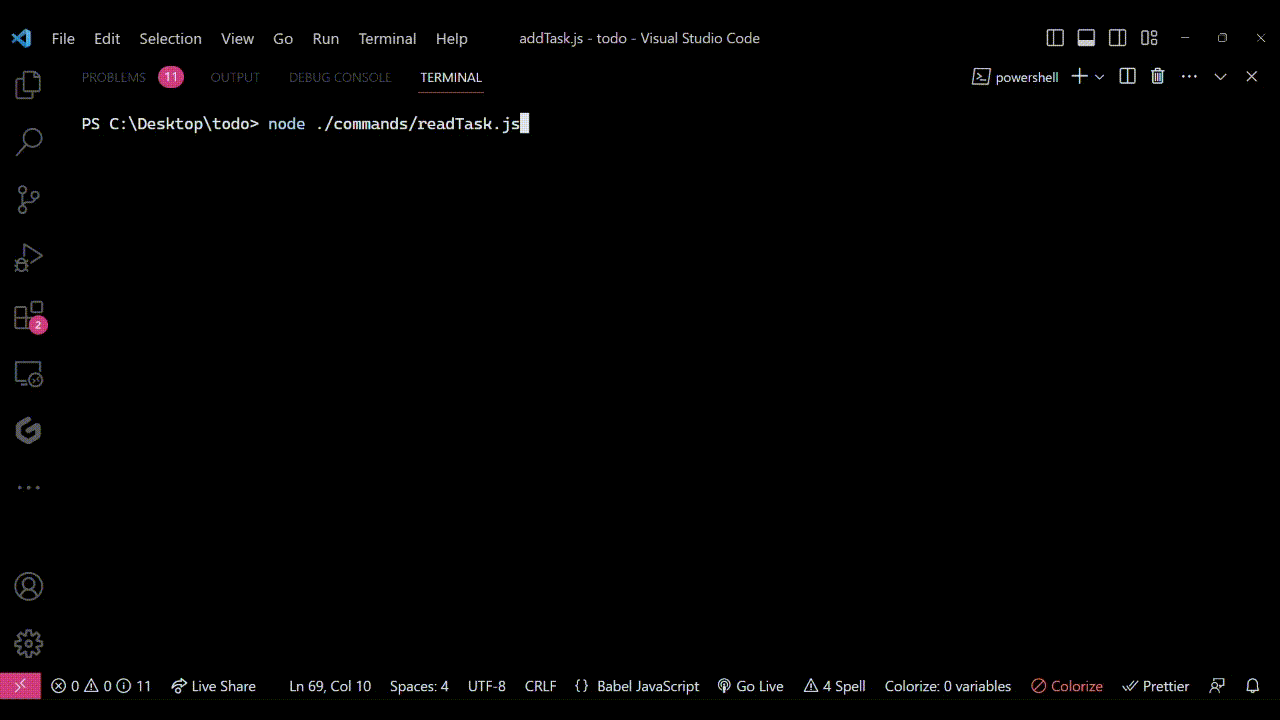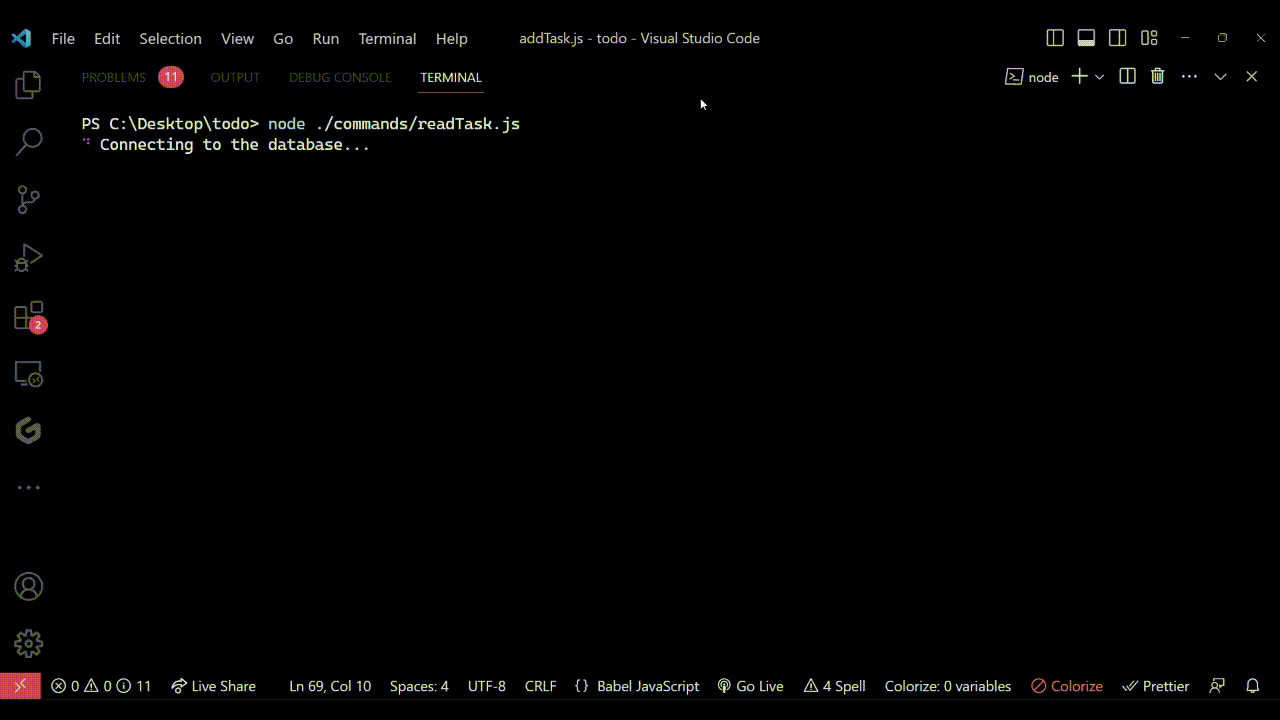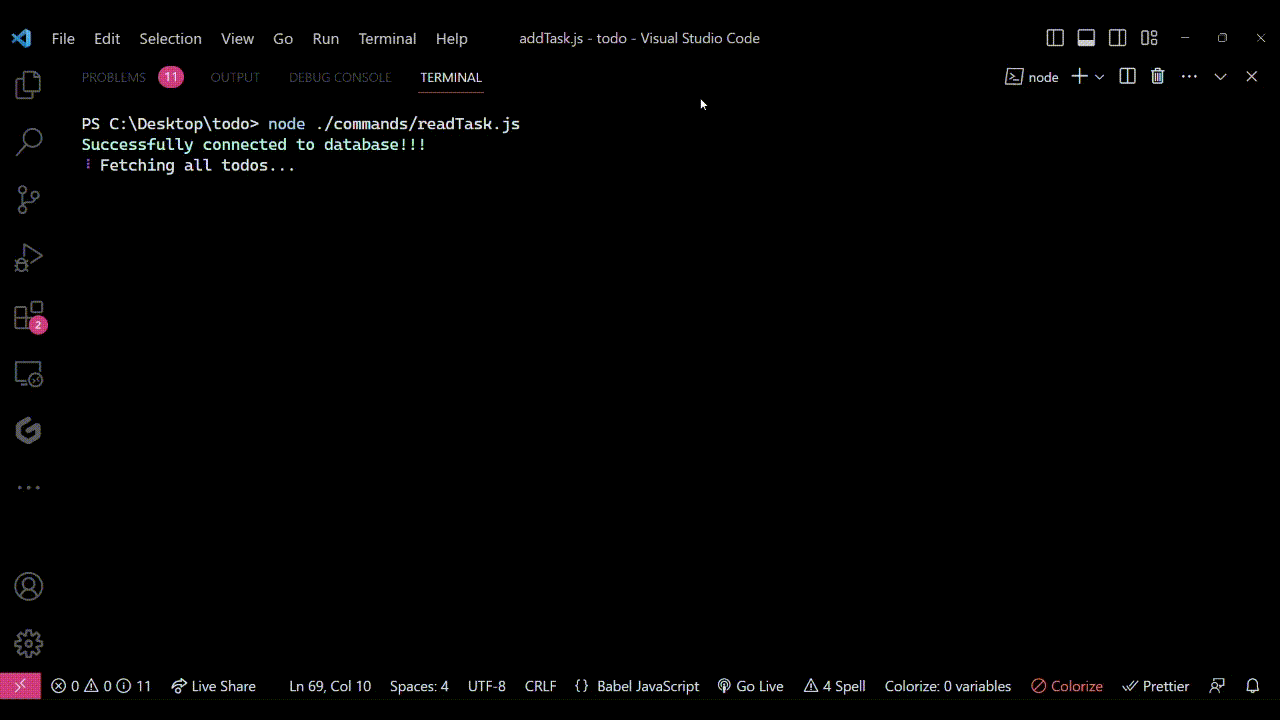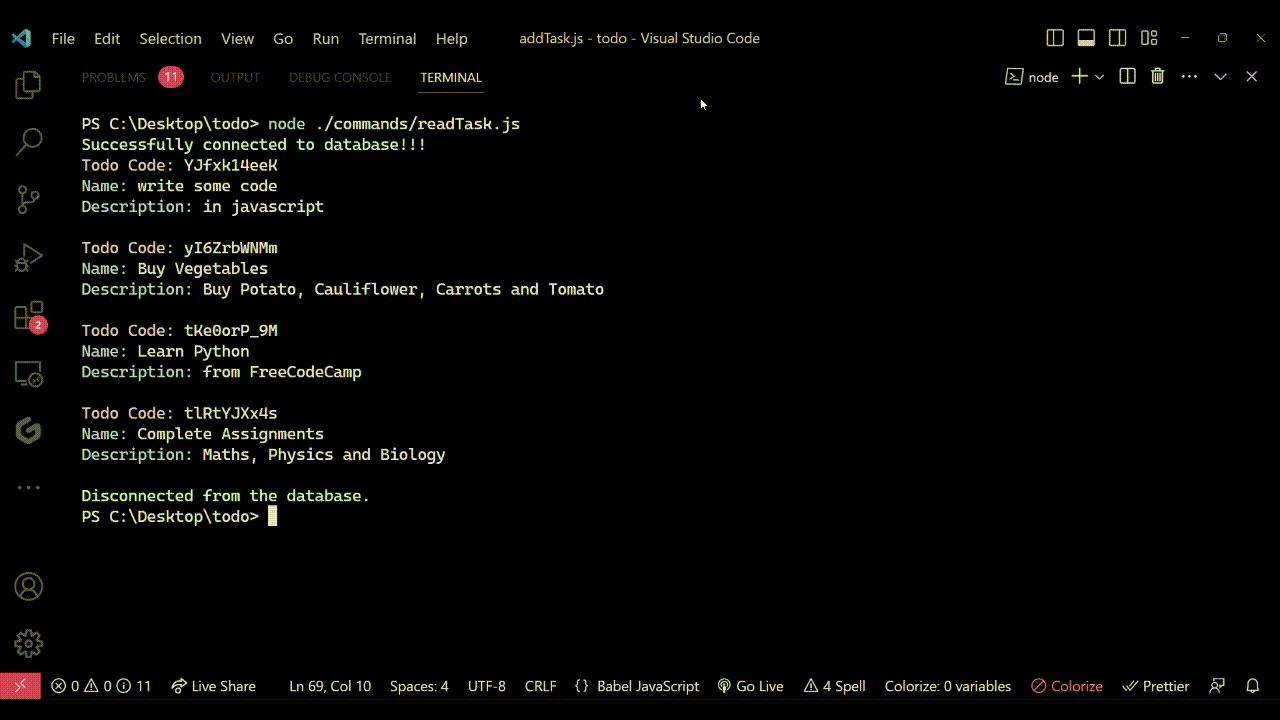 Sortie vue dans le terminal lorsque le fichier
Sortie vue dans le terminal lorsque le fichier readTask.js est exécuté. Il montre comment le code lit avec succès toutes les tâches de la base de données et les imprime dans le terminal.
Avant de continuer, n'oubliez pas de supprimer la dernière ligne de code dans le fichier readTask.js car nous n'en aurons plus besoin à l'avenir.
Avec ce code, vous avez implémenté avec succès la fonctionnalité de lecture pour votre outil CLI de gestion de tâches. Excellent travail ! Dans les sections à venir, nous explorerons comment supprimer et mettre à jour les tâches.
Comment supprimer des tâches
Cette section du tutoriel couvre le processus simple de suppression des tâches de la base de données. La logique est simple : les utilisateurs entrent le code de la tâche qu'ils veulent supprimer, et nous supprimons cette tâche de la base de données.
Plongeons dans le code pour faire cela dans le fichier ./commands/deleteTask.js.
La première étape consiste à importer les packages et fonctions nécessaires au début du fichier, y compris inquirer, le modèle Todos, connectDB(), disconnectDB(), ora et chalk.
// Importation des packages et fonctions
import inquirer from "inquirer";
import Todos from '../schema/TodoSchema.js'
import {connectDB, disconnectDB} from '../db/connectDB.js'
import ora from "ora";
import chalk from "chalk";
Ensuite, nous allons définir une fonction asynchrone appelée getTaskCode(). Le rôle de cette fonction est de demander à l'utilisateur d'entrer le code de la tâche qu'il souhaite supprimer en utilisant inquirer. La fonction trime ensuite le code entré par l'utilisateur en utilisant la méthode trim() et retourne le code trimmé. Le processus de trimage est nécessaire pour supprimer les espaces blancs de début ou de fin que le code pourrait contenir.
Voici le code pour la fonction getTaskCode() :
export async function getTaskCode(){
try {
// Demander à l'utilisateur d'entrer le code de la tâche
const answers = await inquirer.prompt([
{name: 'code', 'message': 'Entrez le code de la tâche : ', type: 'input'},
])
// Trimmer la réponse de l'utilisateur pour que le code de la tâche ne contienne aucun espace blanc au début ou à la fin
answers.code = answers.code.trim()
return answers
} catch (error) {
console.log('Quelque chose s'est mal passé...\n', error)
}
}
Maintenant, nous allons définir la fonction principale nommée deleteTask(). Voici le code complet :
export default async function deleteTask(){
try {
// Obtenir le code de la tâche fourni par l'utilisateur
const userCode = await getTaskCode()
// Connexion à la base de données
await connectDB()
// Démarrer le spinner
const spinner = ora('Recherche et suppression de la tâche...').start()
// Supprimer la tâche
const response = await Todos.deleteOne({code: userCode.code})
// Arrêter le spinner
spinner.stop()
// Vérifier l'opération de suppression
if(response.deletedCount === 0){
console.log(chalk.redBright('Impossible de trouver une tâche correspondant au nom fourni. La suppression a échoué.'))
} else {
console.log(chalk.greenBright('Tâche supprimée avec succès'))
}
// Déconnexion de la base de données
await disconnectDB()
} catch (error) {
// Gestion des erreurs
console.log('Quelque chose s'est mal passé, Erreur : ', error)
process.exit(1)
}
}
Décomposons ce code étape par étape :
- Nous obtenons l'objet de réponse qui inclut le code de la tâche entré par l'utilisateur en appelant la fonction
getTaskCode()définie ci-dessus. Nous attribuons ensuite cet objet à la variableuserCode. - Nous nous connectons à la base de données en utilisant
await connectDB(). - Nous démarrons un spinner en utilisant
orapour indiquer que nous recherchons et supprimons la tâche. - Nous utilisons
Todos.deleteOne({ code: userCode.code })pour rechercher et supprimer la tâche avec un code correspondant. La réponse indiquera si un document a été supprimé ou non. - Après l'opération, nous arrêtons le spinner en utilisant
spinner.stop(). - Nous utilisons une condition if...else pour vérifier la propriété
deletedCountdans la réponse. Si elle est à 0, nous imprimons un message indiquant que la tâche avec le code fourni n'a pas été trouvée et que la suppression a échoué. SideletedCountest supérieur à 0, nous imprimons un message de succès. - Nous nous déconnectons de la base de données en utilisant
await disconnectDB().
Si j'appelle la fonction : deleteTask() puis que je procède à l'exécution du code en utilisant la commande node /commands/deleteTask.js, je vois ceci dans ma console :
 Sortie vue dans le terminal lorsque le fichier
Sortie vue dans le terminal lorsque le fichier deleteTask.js est exécuté. Il montre comment le code supprime avec succès une seule tâche de la base de données.
Comme vous pouvez le voir dans le GIF ci-dessus, le code vous demandera de saisir un code de tâche pour la tâche que vous souhaitez supprimer. Après la suppression, vous recevrez un message de confirmation dans la console. Lorsque nous lisons toutes nos tâches après le processus de suppression, nous ne voyons pas la tâche supprimée. Cela implique que notre code réussit à faire ce qu'il est censé faire !
Comment mettre à jour les tâches
Dans cette section, nous allons examiner le code pour mettre à jour une tâche spécifique. La mise à jour d'une tâche est un peu plus complexe par rapport aux opérations précédentes. Le processus se déroule comme suit :
- Demander à l'utilisateur de saisir le code de la tâche à mettre à jour.
- Se connecter à la base de données.
- Trouver la tâche dont la propriété code correspond à la saisie de l'utilisateur.
- Si la tâche n'existe pas, afficher un message indiquant l'échec de la recherche d'une tâche correspondante.
- Si la tâche existe, demander à l'utilisateur de mettre à jour le
nom, ladescriptionet lestatutde la tâche. - Si l'utilisateur définit la propriété de statut d'une tâche sur "completed", alors cette tâche est supprimée. Si elle est définie sur "pending", le nom et la description de la tâche sont mis à jour dans la base de données.
- Afficher un message de succès dans la console après l'opération de mise à jour.
Commençons à coder ! La première chose à faire est d'importer tous les packages et fonctions dont nous aurons besoin pour effectuer ce travail.
// Importation des packages et fonctions
import {connectDB, disconnectDB} from '../db/connectDB.js'
import { getTaskCode } from './deleteTask.js'
import inquirer from 'inquirer'
import Todos from '../schema/TodoSchema.js'
import ora from 'ora'
import chalk from 'chalk'
Avant de commencer à travailler sur notre fonction updateTask(), nous allons créer une petite fonction dans le même fichier nommée askUpdateQ(). Le rôle de cette fonction est de demander à l'utilisateur de saisir les valeurs mises à jour de la tâche comme le nom de la tâche, la description et le statut. À la fin, cette fonction retournera l'objet de réponse.
Voici le code pour cela :
async function askUpdateQ(todo){
try {
// Demander à l'utilisateur de mettre à jour les données de la tâche
const update = await inquirer.prompt([
{name: 'name', message: 'Mettre à jour le nom ?', type: 'input', default: todo.name},
{name: 'detail', message: 'Mettre à jour la description ?', type: 'input', default: todo.detail},
{name: 'status', message: 'Mettre à jour le statut', type: 'list', choices: ['pending', 'completed'], default: todo.status}
])
return update
} catch (error) {
console.log('Quelque chose s'est mal passé... \n', error)
}
}
Deux choses sont à noter ici :
todoest l'objet de tâche original (la tâche que l'utilisateur souhaite mettre à jour). Cela sera passé à la fonctionaskUpdateQ()par la fonctionupdateTask().- Chaque objet de question dans le tableau passé à
inquirer.prompt()contient une propriété par défaut définie sur les valeurs originales de la tâche. Cela garantit que si l'utilisateur saute une question, la valeur par défaut reste inchangée.
Cela dit, regardons maintenant le code de la fonction updateTask() :
export default async function updateTask(){
try {
// Obtenir le code de la tâche entré par l'utilisateur en appelant la méthode getTaskCode()
const userCode = await getTaskCode()
// Connexion à la base de données
await connectDB()
// Démarrer le spinner
const spinner = ora('Recherche de la tâche...').start()
// Trouver la tâche que l'utilisateur souhaite mettre à jour
const todo = await Todos.findOne({code: userCode.code})
// Arrêter le spinner
spinner.stop()
// Vérifier si la tâche existe ou non
if(!todo){
console.log(chalk.redBright('Impossible de trouver une tâche avec le code que vous avez fourni.'))
} else{
console.log(chalk.blueBright('Tapez les propriétés mises à jour. Appuyez sur Entrée si vous ne souhaitez pas mettre à jour les données.'))
// Obtenir la réponse de l'utilisateur des données mises à jour en appelant la méthode askUpdateQ()
const update = await askUpdateQ(todo)
// Si l'utilisateur a marqué le statut comme terminé, nous supprimons la tâche, sinon nous mettons à jour les données
if(update.status === 'completed'){
// Changer le texte du spinner et le redémarrer
spinner.text = 'Suppression de la tâche...'
spinner.start()
// Supprimer la tâche
await Todos.deleteOne({_id : todo._id})
// Arrêter le spinner et afficher le message de succès
spinner.stop()
console.log(chalk.greenBright('Tâche supprimée.'))
} else {
// Mettre à jour la tâche
spinner.text = 'Mise à jour de la tâche'
spinner.start()
await Todos.updateOne({_id: todo._id}, update, {runValidators: true})
spinner.stop()
console.log(chalk.greenBright('Tâche mise à jour.'))
}
}
// Déconnexion de la base de données
await disconnectDB()
} catch (error) {
// Gestion des erreurs
console.log('Quelque chose s'est mal passé, Erreur : ', error)
process.exit(1)
}
}
Voici une décomposition du code ci-dessus :
- Obtenir le code de la tâche que l'utilisateur souhaite mettre à jour. Pour cela, nous utilisons la fonction
getTaskCode()définie dans le fichier./commands/deleteTask.js. Nous appelons simplement la fonction et attribuons l'objet de réponse retourné à la variableuserCode. - Se connecter à la base de données en utilisant
await connectDB(). - Démarrer un spinner pour indiquer que le code recherche la tâche.
- Utiliser
Todos.findOne({ code: userCode.code })pour trouver la tâche que l'utilisateur souhaite mettre à jour et l'attribuer à la variabletodo. Nous faisons cela car nous aurons besoin des valeurs originales de la tâche. - Arrêter le spinner.
- Si aucune tâche correspondante n'est trouvée, afficher un message en utilisant
chalkindiquant que la tâche n'a pas été trouvée. - Si la tâche est trouvée, demander à l'utilisateur de saisir les propriétés mises à jour en appelant la fonction
askUpdateQ()et passer l'objettodo(tâche originale) dans la fonction. Attribuer l'objet retourné à la variableupdate. - Si l'utilisateur marque le statut comme "completed", la tâche est supprimée de la base de données en utilisant
deleteOne(). Si elle est marquée comme "pending", le nom et la description de la tâche sont mis à jour en utilisantupdateOne().
La méthode updateOne() prend 3 paramètres : l'objet de requête, l'objet de mise à jour et l'objet des options. Ici, {_id: todo._id} est l'objet de requête. Mongoose recherche dans toute la collection une tâche dont la propriété id correspond à todo_.id. En trouvant la tâche, il remplace la tâche par l'objet de mise à jour, c'est-à-dire update dans notre cas. Le troisième paramètre, { runValidators: true }, garantit que Mongoose valide l'objet update par rapport aux règles du schéma avant de l'exécuter. Si la validation échoue, la mise à jour sera rejetée et vous recevrez une erreur. Si la validation est réussie, le document sera mis à jour avec succès dans la base de données.
Dans les deux cas de l'opération de suppression et de mise à jour, nous changeons le texte du spinner en utilisant spinner.text et le démarrons avant d'effectuer l'opération et une fois l'opération terminée, nous arrêtons le spinner.
- Afficher des messages de succès appropriés dans la console en fonction de l'opération effectuée.
- Se déconnecter de la base de données en utilisant
await disconnectDB().
Si j'appelle la fonction updateTask() et exécute le code en utilisant la commande : node ./commands/updateTask.js, je vois quelque chose comme ceci dans ma console :
 Sortie vue dans le terminal lorsque le fichier
Sortie vue dans le terminal lorsque le fichier updateTask.js est exécuté. Il montre comment le code récupère avec succès la tâche originale et la remplace par les valeurs mises à jour fournies par l'utilisateur.
Avec cela, vous avez implémenté avec succès toutes les opérations CRUD. Maintenant, utilisons la bibliothèque commander pour tout rassembler et créer un outil CLI entièrement fonctionnel.
Comment écrire le point d'entrée CLI en utilisant Commander
Dans les dernières étapes de notre projet, nous allons exploiter la puissance de la bibliothèque commander pour créer une interface CLI conviviale. Avec commander, nous pouvons définir différentes commandes, telles que read, add, update et delete, de manière organisée et intuitive.
Notre code résidera dans le fichier index.js, qui sert de point d'entrée de notre application. Voici le code complet :
#!/usr/bin/env node
// Importation des fonctions requises pour chaque commande
import addTask from './commands/addTask.js'
import deleteTask from './commands/deleteTask.js'
import readTask from './commands/readTask.js'
import updateTask from './commands/updateTask.js'
// Importation de la classe Command de la bibliothèque Commander.js
import { Command } from 'commander'
// Création d'une instance de la classe Command
const program = new Command()
// Définition du nom et de la description de l'outil CLI
program
.name('todo')
.description('Votre gestionnaire de tâches en terminal !')
.version('1.0.0')
// Définition d'une commande appelée 'add'
program
.command('add')
.description('Crée une nouvelle tâche.')
.action(addTask)
// Définition d'une commande appelée 'read'
program
.command('read')
.description('Lit toutes les tâches.')
.action(readTask)
// Définition d'une commande appelée 'update'
program
.command('update')
.description('Met à jour une tâche.')
.action(updateTask)
// Définition d'une commande appelée 'delete'
program
.command('delete')
.description('Supprime une tâche.')
.action(deleteTask)
// Analyse des arguments de la ligne de commande et exécution des actions correspondantes
program.parse()
- La toute première ligne,
#!/usr/bin/env node, est un "shebang". Elle informe le système d'exécuter le script en utilisant l'interpréteur Node.js. Cela nous permet d'exécuter le script directement depuis la ligne de commande sans taper explicitementnodeavant le nom du fichier de script. - Ensuite, nous importons toutes les fonctions requises qui contiennent la logique pour chaque commande.
- La ligne
import { Command } from 'commander'importe la classeCommandde la bibliothèque Commander.js. La ligne suivante,const program = new Command(), crée une instance de la classeCommand. Cette instance est essentielle pour définir et gérer les commandes de notre outil CLI. - Nous définissons ensuite les informations de l'outil CLI. Les méthodes
.name(),.description()et.version()définissent le nom, la description et la version de notre outil CLI. Ces détails sont affichés lorsque les utilisateurs invoquent l'outil avec des drapeaux spécifiques tels que--helpou--version. - Ensuite, nous définissons les différentes commandes. Chaque bloc
program.command()définit une commande pour notre outil CLI. Dans chaque bloc, le nom de la commande est défini en utilisant un argument de chaîne (par exemple,'add','read'). La méthode.description()fournit la description de la commande, tandis que la méthode.action()associe une fonction (par exemple,addTask,readTask) à une commande spécifique. Lorsque l'utilisateur entre une commande dans le terminal, cette fonction associée est exécutée. - La ligne
program.parse()est essentielle pour analyser les arguments de la ligne de commande fournis par l'utilisateur. En fonction de la commande entrée, Commander.js exécutera la fonction d'action associée.
Comment tester l'outil CLI
Nous sommes maintenant presque à la ligne d'arrivée de la création de notre outil CLI de gestion de tâches ! Avant de pouvoir installer et utiliser l'outil, nous devons simplement apporter une petite modification au fichier package.json. Ajoutez simplement l'entrée suivante au fichier JSON :
"bin": {
"todo": "index.js"
}
Si vous avez déjà construit un outil CLI et souhaitez que les utilisateurs y accèdent depuis la ligne de commande de manière similaire aux commandes comme node ou npm, alors la propriété "bin" entre en jeu.
La propriété "bin" dans le fichier package.json vous permet de spécifier des commandes qui deviennent globalement accessibles une fois votre package installé. En termes plus simples, elle vous permet de créer des raccourcis pour exécuter des scripts ou fonctions spécifiques depuis la ligne de commande.
Le code fourni indique à Node.js d'exécuter le script défini dans index.js chaque fois que quelqu'un entre todo dans le terminal. En essence, cela transforme votre script en un outil de ligne de commande globalement accessible.
La dernière étape avant de pouvoir commencer à utiliser l'outil est de l'installer globalement sur votre système ! Exécutez la commande suivante pour ce faire :
npm i -g .
Conclusion
Félicitations si vous avez suivi jusqu'ici ! Vous êtes maintenant entièrement équipé pour commencer à utiliser votre outil CLI de gestion de tâches.
Voici les commandes que vous pouvez utiliser pour faire fonctionner l'outil :
todo add– Créer une nouvelle tâchetodo read– Lire toutes vos tâches en attentetodo update– Mettre à jour une tâche spécifiquetodo delete– Supprimer une tâche
Vous pouvez également utiliser ces 2 options avec l'outil :
todo --versionoutodo -V– Pour connaître le numéro de version de cet outiltodo --helpoutodo -h– Pour afficher l'aide pour la commande
Et cela conclut ce manuel. J'espère que vous l'avez trouvé agréable et informatif.
Je vous encourage à partager votre parcours d'apprentissage sur Twitter et LinkedIn en utilisant le hashtag #LearnInPublic. Assurez-vous également de suivre freeCodeCamp pour plus de tutoriels de codage informatifs.
Si vous rencontrez des problèmes en suivant ce tutoriel, vous pouvez toujours vous référer au code complet disponible sur GitHub - Dépôt GitHub de l'outil CLI de gestion de tâches. Vous pouvez également me contacter sur Twitter (X) - @Krish4856. Mes DM sont ouverts !
À la prochaine ! 44b 496 4ae