
Article original : How to Create Auto-Updating Data Visualizations in Python with IEX Cloud, Matplotlib, and AWS
Par Nick McCullum
Python est un excellent langage de programmation pour créer des visualisations de données.
Cependant, travailler avec un langage de programmation brut comme Python (au lieu de logiciels plus sophistiqués comme, disons, Tableau) présente certains défis. Les développeurs créant des visualisations doivent accepter une plus grande complexité technique en échange d'un contrôle bien plus important sur l'apparence de leurs visualisations.
Dans ce tutoriel, je vais vous apprendre à créer des visualisations Python à mise à jour automatique. Nous utiliserons des données d'IEX Cloud, ainsi que la bibliothèque matplotlib et quelques offres de produits simples d'Amazon Web Services.
Étape 1 : Rassembler vos données
Les graphiques à mise à jour automatique semblent attrayants. Mais avant d'investir du temps pour les construire, il est important de comprendre si vous avez réellement besoin que vos graphiques soient mis à jour automatiquement.
Pour être plus précis, il n'est pas nécessaire que vos visualisations se mettent à jour automatiquement si les données qu'elles présentent ne changent pas au fil du temps.
Écrire un script Python qui met à jour automatiquement un graphique des points par match annuels de Michael Jordan serait inutile - sa carrière est terminée, et cet ensemble de données ne changera jamais.
Les meilleurs candidats d'ensembles de données pour les visualisations à mise à jour automatique sont les données de séries temporelles où de nouvelles observations sont ajoutées régulièrement (par exemple, chaque jour).
Dans ce tutoriel, nous allons utiliser des données boursières de l' API IEX Cloud. Plus précisément, nous allons visualiser les prix historiques des actions de quelques-unes des plus grandes banques des États-Unis :
- JPMorgan Chase (JPM)
- Bank of America (BAC)
- Citigroup (C)
- Wells Fargo (WFC)
- Goldman Sachs (GS)
La première chose que vous devrez faire est de créer un compte IEX Cloud et de générer un jeton API.
Pour des raisons évidentes, je ne vais pas publier ma clé API dans cet article. Stocker votre propre clé API personnalisée dans une variable appelée IEX API Key sera suffisant pour que vous puissiez suivre.
Ensuite, nous allons stocker notre liste de tickers dans une liste Python :
tickers = [
'JPM',
'BAC',
'C',
'WFC',
'GS',
]
L'API IEX Cloud accepte des tickers séparés par des virgules. Nous devons sérialiser notre liste de tickers en une chaîne de tickers séparés. Voici le code que nous utiliserons pour faire cela :
# Créer une chaîne vide nommée `ticker_string` à laquelle nous ajouterons les tickers et les virgules
ticker_string = ''
# Parcourir chaque élément de `tickers` et les ajouter avec une virgule à ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
# Supprimer la dernière virgule de `ticker_string`
ticker_string = ticker_string[:-1]
La tâche suivante que nous devons gérer est de sélectionner le point de terminaison (endpoint) de l'API IEX Cloud que nous devons interroger.
Un examen rapide de la documentation d'IEX Cloud révèle qu'ils ont un endpoint Historical Prices, auquel nous pouvons envoyer une requête HTTP en utilisant le mot-clé charts.
Nous devrons également spécifier la quantité de données que nous demandons (mesurée en années).
Pour cibler cet endpoint pour la plage de données spécifiée, j'ai stocké l'endpoint charts et la durée dans des variables séparées. Ces endpoints sont ensuite interpolés dans l'URL sérialisée que nous utiliserons pour envoyer notre requête HTTP.
Voici le code :
# Créer les chaînes pour l'endpoint et les années
endpoints = 'chart'
years = '10'
# Interpoler les chaînes d'endpoint dans la chaîne HTTP_request
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range={years}y&token={IEX_API_Key}'
Cette chaîne interpolée est importante car elle nous permet de changer facilement la valeur de notre chaîne à une date ultérieure sans modifier chaque occurrence de la chaîne dans notre code.
Il est maintenant temps de faire réellement notre requête HTTP et de stocker les données dans une structure de données sur notre machine locale.
Pour ce faire, je vais utiliser la bibliothèque pandas pour Python. Plus précisément, les données seront stockées dans un DataFrame pandas.
Nous devrons d'abord importer la bibliothèque pandas. Par convention, pandas est généralement importé sous l'alias pd. Ajoutez le code suivant au début de votre script pour importer pandas sous l'alias souhaité :
import pandas as pd
Une fois que nous avons importé pandas dans notre script Python, nous pouvons utiliser sa méthode read_json pour stocker les données d'IEX Cloud dans un DataFrame pandas :
bank_data = pd.read_json(HTTP_request)
L'affichage de ce DataFrame à l'intérieur d'un Jupyter Notebook génère la sortie suivante :

Il est clair que ce n'est pas ce que nous voulons. Nous devrons analyser ces données pour générer un DataFrame qui vaut la peine d'être tracé.
Pour commencer, examinons une colonne spécifique de bank_data - par exemple, bank_data['JPM'] :

Il est clair que la prochaine couche d'analyse devra être l'endpoint chart :

Nous avons maintenant une structure de données de type JSON où chaque cellule est une date accompagnée de divers points de données sur le prix de l'action de JPM à cette date.
Nous pouvons envelopper cette structure de type JSON dans un DataFrame pandas pour la rendre beaucoup plus lisible :
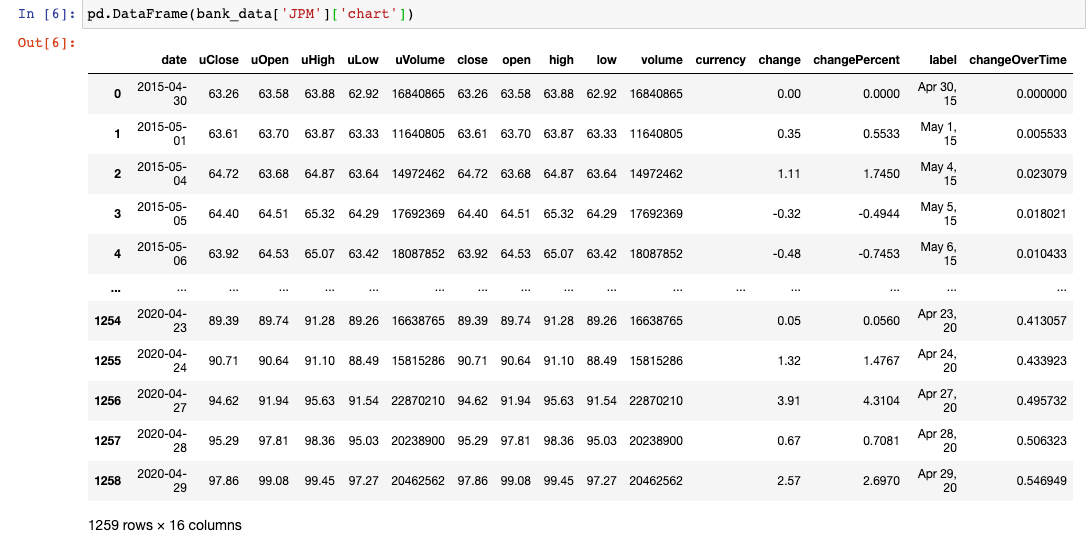
C'est quelque chose avec lequel nous pouvons travailler !
Écrivons une petite boucle qui utilise une logique similaire pour extraire la série temporelle du prix de clôture pour chaque action sous forme de Series pandas (ce qui équivaut à une colonne d'un DataFrame pandas). Nous stockerons ces Series pandas dans un dictionnaire (avec le ticker comme clé) pour un accès facile plus tard.
for ticker in tickers:
series_dict.update( {ticker : pd.DataFrame(bank_data[ticker]['chart'])['close']} )
Nous pouvons maintenant créer notre DataFrame pandas finalisé qui a la date comme index et une colonne pour le prix de clôture de chaque action de grande banque sur les 5 dernières années :
series_list = []
for ticker in tickers:
series_list.append(pd.DataFrame(bank_data[ticker]['chart'])['close'])
series_list.append(pd.DataFrame(bank_data['JPM']['chart'])['date'])
column_names = tickers.copy()
column_names.append('Date')
bank_data = pd.concat(series_list, axis=1)
bank_data.columns = column_names
bank_data.set_index('Date', inplace = True)
Une fois tout cela fait, notre DataFrame bank_data ressemblera à ceci :
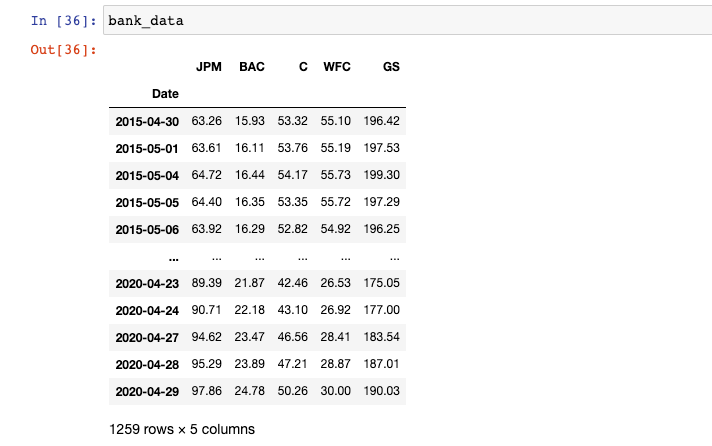
Notre collecte de données est terminée. Nous sommes maintenant prêts à commencer à créer des visualisations avec cet ensemble de données de prix boursiers pour les banques cotées en bourse. En guise de rappel rapide, voici le script que nous avons construit jusqu'à présent :
import pandas as pd
import matplotlib.pyplot as plt
IEX_API_Key = ''
tickers = [
'JPM',
'BAC',
'C',
'WFC',
'GS',
]
# Créer une chaîne vide nommée `ticker_string` à laquelle nous ajouterons les tickers et les virgules
ticker_string = ''
# Parcourir chaque élément de `tickers` et les ajouter avec une virgule à ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
# Supprimer la dernière virgule de `ticker_string`
ticker_string = ticker_string[:-1]
# Créer les chaînes pour l'endpoint et les années
endpoints = 'chart'
years = '5'
# Interpoler les chaînes d'endpoint dans la chaîne HTTP_request
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range={years}y&cache=true&token={IEX_API_Key}'
# Envoyer la requête HTTP à l'API IEX Cloud et stocker la réponse dans un DataFrame pandas
bank_data = pd.read_json(HTTP_request)
# Créer une liste vide dans laquelle nous ajouterons les Series pandas de données de prix boursiers
series_list = []
# Parcourir chacun de nos tickers et analyser une Series pandas de leurs prix de clôture sur les 5 dernières années
for ticker in tickers:
series_list.append(pd.DataFrame(bank_data[ticker]['chart'])['close'])
# Ajouter une colonne de dates
series_list.append(pd.DataFrame(bank_data['JPM']['chart'])['date'])
# Copier la liste 'tickers' du début du script et ajouter un nouvel élément nommé 'Date'.
# Ces éléments seront les noms de colonnes de notre DataFrame pandas plus tard.
column_names = tickers.copy()
column_names.append('Date')
# Concaténer les Series pandas ensemble dans un seul DataFrame
bank_data = pd.concat(series_list, axis=1)
# Nommer les colonnes du DataFrame et définir la colonne 'Date' comme index
bank_data.columns = column_names
bank_data.set_index('Date', inplace = True)
Étape 2 : Créer le graphique que vous souhaitez mettre à jour
Dans ce tutoriel, nous allons travailler avec la bibliothèque de visualisation matplotlib pour Python.
Matplotlib est une bibliothèque extrêmement sophistiquée et les gens passent des années à la maîtriser pleinement. Par conséquent, gardez à l'esprit que nous ne faisons qu'effleurer la surface des capacités de matplotlib dans ce tutoriel.
Nous allons commencer par importer la bibliothèque matplotlib.
Comment importer Matplotlib
Par convention, les data scientists importent généralement la bibliothèque pyplot de matplotlib sous l'alias plt.
Voici l'instruction d'importation complète :
import matplotlib.pyplot as plt
Vous devrez inclure ceci au début de tout fichier Python utilisant matplotlib pour générer des visualisations de données.
Il existe également d'autres arguments que vous pouvez ajouter à l'importation de votre bibliothèque matplotlib pour rendre vos visualisations plus faciles à manipuler.
Si vous suivez ce tutoriel dans un Jupyter Notebook, vous voudrez peut-être inclure l'instruction suivante, qui permettra à vos visualisations d'apparaître sans avoir besoin d'écrire une instruction plt.show() :
%matplotlib inline
Si vous travaillez dans un Jupyter Notebook sur un MacBook avec un écran Retina, vous pouvez utiliser les instructions suivantes pour améliorer la résolution de vos visualisations matplotlib dans le notebook :
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('retina')
Cela étant dit, commençons à créer nos premières visualisations de données en utilisant Python et matplotlib !
Fondamentaux du formatage Matplotlib
Dans ce tutoriel, vous apprendrez à créer des boîtes à moustaches (boxplots), des nuages de points (scatterplots) et des histogrammes en Python à l'aide de matplotlib. Je souhaite passer en revue quelques bases du formatage dans matplotlib avant de commencer à créer de réelles visualisations de données.
Premièrement, presque tout ce que vous faites dans matplotlib implique l'invocation de méthodes sur l'objet plt, qui est l'alias sous lequel nous avons importé matplotlib.
Deuxièmement, vous pouvez ajouter des titres aux visualisations matplotlib en appelant plt.title() et en passant le titre souhaité sous forme de chaîne.
Troisièmement, vous pouvez ajouter des étiquettes à vos axes x et y en utilisant les méthodes plt.xlabel() et plt.ylabel().
Enfin, avec les trois méthodes que nous venons de mentionner - plt.title(), plt.xlabel() et plt.ylabel() - vous pouvez modifier la taille de la police du titre avec l'argument fontsize.
Plongeons sérieusement dans la création de nos premières visualisations matplotlib.
Comment créer des boîtes à moustaches (boxplots) dans Matplotlib
Les boîtes à moustaches (boxplots) sont l'une des visualisations de données les plus fondamentales à la disposition des data scientists.
Matplotlib nous permet de créer des boîtes à moustaches avec la fonction boxplot.
Comme nous allons créer des boîtes à moustaches le long de nos colonnes (et non le long de nos lignes), nous voudrons également transposer notre DataFrame à l'intérieur de l'appel de la méthode boxplot.
plt.boxplot(bank_data.transpose())

C'est un bon début, mais nous devons ajouter un peu de style pour rendre cette visualisation facilement interprétable par un utilisateur externe.
Tout d'abord, ajoutons un titre au graphique :
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)', fontsize = 20)

De plus, il est utile d'étiqueter les axes x et y, comme mentionné précédemment :
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices', fontsize = 20)
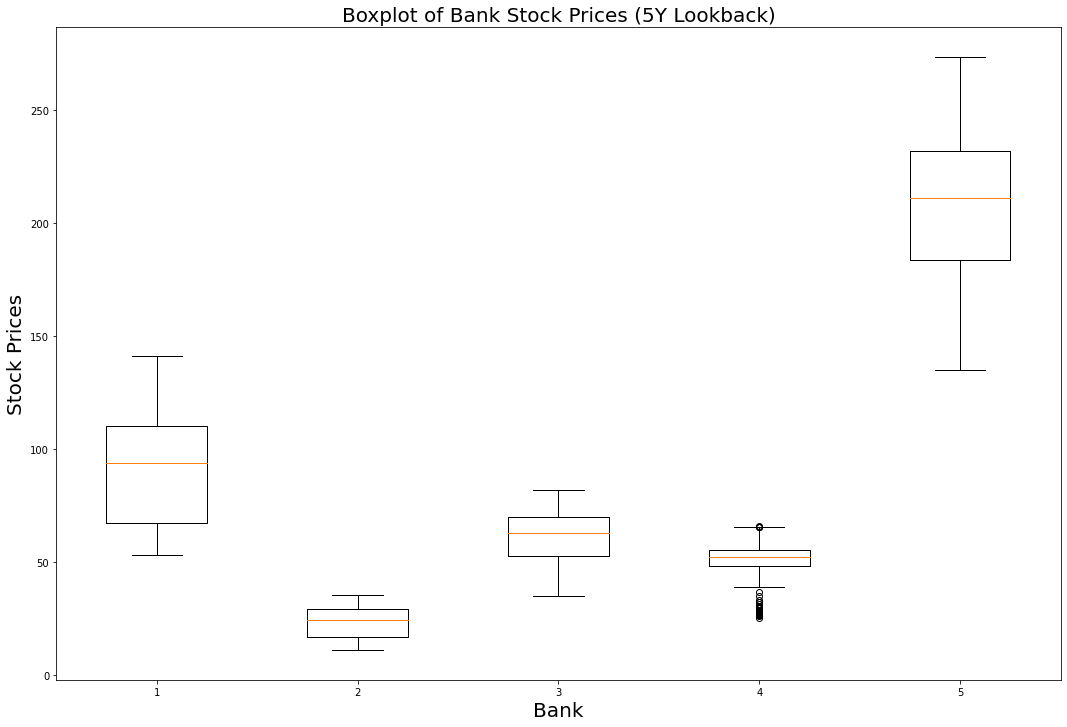
Nous devrons également ajouter des étiquettes spécifiques aux colonnes sur l'axe x afin qu'il soit clair quelle boîte à moustaches appartient à chaque banque.
Le code suivant fait l'affaire :
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
plt.xticks(ticks,labels, fontsize = 20)

Et voilà, nous avons une boîte à moustaches qui présente des visualisations utiles dans matplotlib ! Il est clair que Goldman Sachs s'est négocié au prix le plus élevé au cours des 5 dernières années, tandis que l'action de Bank of America s'est négociée au plus bas. Il est également intéressant de noter que Wells Fargo présente le plus grand nombre de points de données aberrants (outliers).
En guise de rappel, voici le code complet que nous avons utilisé pour générer nos boîtes à moustaches :
########################
# Créer une boîte à moustaches (boxplot) Python
########################
# Définir la taille du canevas matplotlib
plt.figure(figsize = (18,12))
# Générer la boîte à moustaches
plt.boxplot(bank_data.transpose())
# Ajouter des titres au graphique et aux axes
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)', fontsize = 20)
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices', fontsize = 20)
# Ajouter des étiquettes à chaque boîte à moustaches individuelle sur le canevas
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
plt.xticks(ticks,labels, fontsize = 20)
Comment créer des nuages de points (scatterplots) dans Matplotlib
Les nuages de points (scatterplots) peuvent être créés dans matplotlib en utilisant la méthode plt.scatter.
La méthode scatter a deux arguments obligatoires - une valeur x et une valeur y.
Traçons le prix de l'action de Wells Fargo au fil du temps en utilisant la méthode plt.scatter().
La première chose que nous devons faire est de créer notre variable d'axe x, appelée dates :
dates = bank_data.index.to_series()
Ensuite, nous allons isoler les prix des actions de Wells Fargo dans une variable séparée :
WFC_stock_prices = bank_data['WFC']
Nous pouvons maintenant tracer la visualisation en utilisant la méthode plt.scatter :
plt.scatter(dates, WFC_stock_prices)

Attendez une minute - les étiquettes x de ce graphique sont impossibles à lire !
Quel est le problème ?
Eh bien, matplotlib ne reconnaît pas actuellement que l'axe x contient des dates, il n'espace donc pas les étiquettes correctement.
Pour corriger cela, nous devons transformer chaque élément de la Series dates en un type de données datetime. La commande suivante est la manière la plus lisible de le faire :
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
Après avoir exécuté à nouveau la méthode plt.scatter, vous générerez la visualisation suivante :

C'est beaucoup mieux !
Notre dernière étape consiste à ajouter des titres au graphique et à l'axe. Nous pouvons le faire avec les instructions suivantes :
plt.title("Wells Fargo Stock Price (5Y Lookback)", fontsize=20)
plt.ylabel("Stock Price", fontsize=20)
plt.xlabel("Date", fontsize=20)
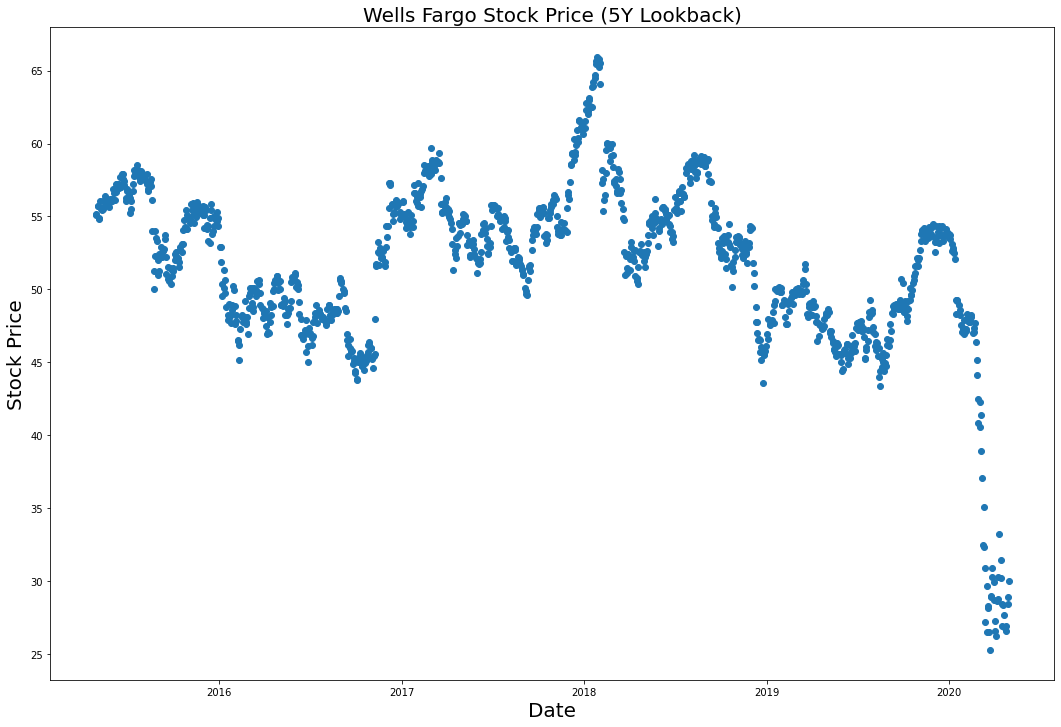
En guise de rappel, voici le code que nous avons utilisé pour créer ce nuage de points :
########################
# Créer un nuage de points (scatterplot) Python
########################
# Définir la taille du canevas matplotlib
plt.figure(figsize = (18,12))
# Créer les données de l'axe x
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
# Créer les données de l'axe y
WFC_stock_prices = bank_data['WFC']
# Générer le nuage de points
plt.scatter(dates, WFC_stock_prices)
# Ajouter des titres au graphique et aux axes
plt.title("Wells Fargo Stock Price (5Y Lookback)", fontsize=20)
plt.ylabel("Stock Price", fontsize=20)
plt.xlabel("Date", fontsize=20)
Comment créer des histogrammes dans Matplotlib
Les histogrammes sont des visualisations de données qui vous permettent de voir la distribution des observations au sein d'un ensemble de données.
Les histogrammes peuvent être créés dans matplotlib en utilisant la méthode plt.hist.
Créons un histogramme qui nous permet de voir la distribution des différents prix d'actions au sein de notre ensemble de données bank_data (notez que nous devrons utiliser la méthode transpose à l'intérieur de plt.hist tout comme nous l'avons fait avec plt.boxplot précédemment) :
plt.hist(bank_data.transpose())
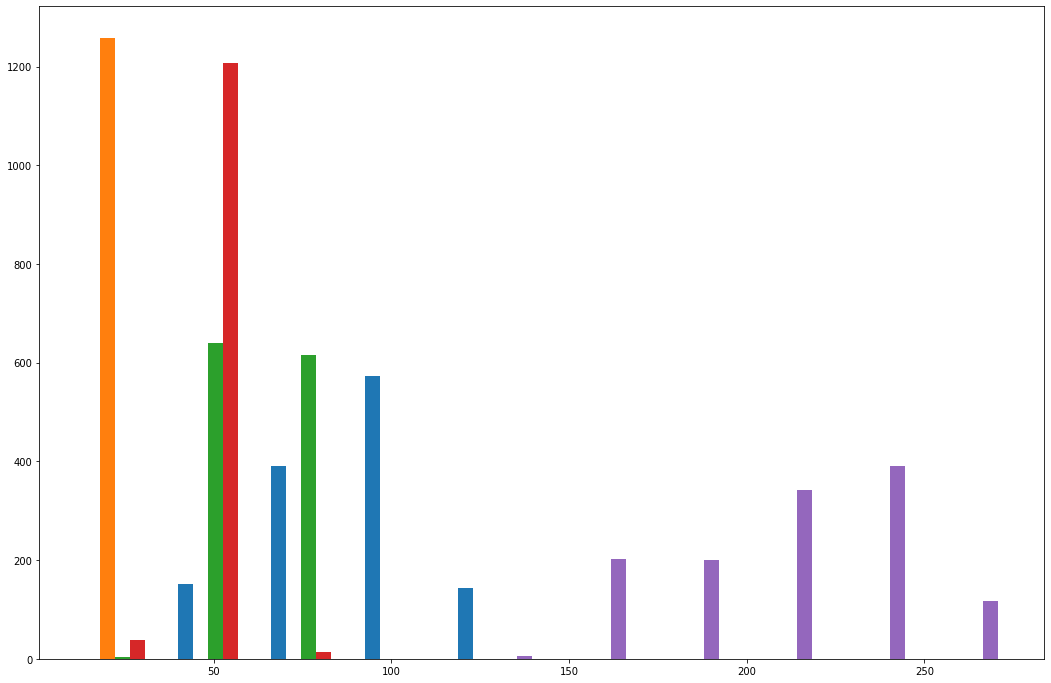
C'est une visualisation intéressante, mais nous avons encore beaucoup à faire.
La première chose que vous avez probablement remarquée est que les différentes colonnes de l'histogramme ont des couleurs différentes. C'est intentionnel. Les couleurs divisent les différentes colonnes au sein de notre DataFrame pandas.
Cela dit, ces couleurs n'ont aucun sens sans légende. Nous pouvons ajouter une légende à notre histogramme matplotlib avec l'instruction suivante :
plt.legend(bank_data.columns,fontsize=20)

Vous voudrez peut-être également modifier le bin count de l'histogramme, ce qui change le nombre de tranches (bins) en lesquelles l'ensemble de données est divisé lors du regroupement des observations dans les colonnes de l'histogramme.
À titre d'exemple, voici comment changer le nombre de bins dans l'histogramme à 50 :
plt.hist(bank_data.transpose(), bins = 50)
Enfin, nous ajouterons des titres à l'histogramme et à ses axes en utilisant les mêmes instructions que celles utilisées dans nos autres visualisations :
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)", fontsize = 20)
plt.ylabel("Observations", fontsize = 20)
plt.xlabel("Stock Prices", fontsize = 20)

En guise de rappel, voici le code complet nécessaire pour générer cet histogramme :
########################
# Créer un histogramme Python
########################
# Définir la taille du canevas matplotlib
plt.figure(figsize = (18,12))
# Générer l'histogramme
plt.hist(bank_data.transpose(), bins = 50)
# Ajouter une légende à l'histogramme
plt.legend(bank_data.columns,fontsize=20)
# Ajouter des titres au graphique et aux axes
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)", fontsize = 20)
plt.ylabel("Observations", fontsize = 20)
plt.xlabel("Stock Prices", fontsize = 20)
Comment créer des sous-graphiques (subplots) dans Matplotlib
Dans matplotlib, les sous-graphiques (subplots) sont le nom que nous utilisons pour désigner plusieurs graphiques créés sur le même canevas à l'aide d'un seul script Python.
Les sous-graphiques peuvent être créés avec la commande plt.subplot. La commande prend trois arguments :
- Le nombre de lignes dans une grille de sous-graphiques
- Le nombre de colonnes dans une grille de sous-graphiques
- Quel sous-graphique vous avez actuellement sélectionné
Créons une grille de sous-graphiques 2x2 contenant les graphiques suivants (dans cet ordre spécifique) :
- La boîte à moustaches que nous avons créée précédemment
- Le nuage de points que nous avons créé précédemment
- Un nuage de points similaire utilisant les données
BACau lieu des donnéesWFC - L'histogramme que nous avons créé précédemment
Tout d'abord, créons la grille de sous-graphiques :
plt.subplot(2,2,1)
plt.subplot(2,2,2)
plt.subplot(2,2,3)
plt.subplot(2,2,4)

Maintenant que nous avons un canevas de sous-graphiques vide, il nous suffit de copier/coller le code dont nous avons besoin pour chaque graphique après chaque appel de la méthode plt.subplot.
À la fin du bloc de code, nous ajoutons la méthode plt.tight_layout, qui corrige de nombreux problèmes de formatage courants survenant lors de la génération de sous-graphiques matplotlib.
Voici le code complet :
################################################
################################################
# Créer des sous-graphiques en Python
################################################
################################################
########################
# Sous-graphique 1
########################
plt.subplot(2,2,1)
# Générer la boîte à moustaches
plt.boxplot(bank_data.transpose())
# Ajouter des titres au graphique et aux axes
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)')
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices')
# Ajouter des étiquettes à chaque boîte à moustaches individuelle sur le canevas
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
plt.xticks(ticks,labels)
########################
# Sous-graphique 2
########################
plt.subplot(2,2,2)
# Créer les données de l'axe x
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
# Créer les données de l'axe y
WFC_stock_prices = bank_data['WFC']
# Générer le nuage de points
plt.scatter(dates, WFC_stock_prices)
# Ajouter des titres au graphique et aux axes
plt.title("Wells Fargo Stock Price (5Y Lookback)")
plt.ylabel("Stock Price")
plt.xlabel("Date")
########################
# Sous-graphique 3
########################
plt.subplot(2,2,3)
# Créer les données de l'axe x
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
# Créer les données de l'axe y
BAC_stock_prices = bank_data['BAC']
# Générer le nuage de points
plt.scatter(dates, BAC_stock_prices)
# Ajouter des titres au graphique et aux axes
plt.title("Bank of America Stock Price (5Y Lookback)")
plt.ylabel("Stock Price")
plt.xlabel("Date")
########################
# Sous-graphique 4
########################
plt.subplot(2,2,4)
# Générer l'histogramme
plt.hist(bank_data.transpose(), bins = 50)
# Ajouter une légende à l'histogramme
plt.legend(bank_data.columns,fontsize=20)
# Ajouter des titres au graphique et aux axes
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)")
plt.ylabel("Observations")
plt.xlabel("Stock Prices")
plt.tight_layout()

Comme vous pouvez le voir, avec quelques connaissances de base, il est relativement facile de créer de magnifiques visualisations de données à l'aide de matplotlib.
La dernière chose que nous devons faire est d'enregistrer la visualisation sous forme de fichier .png dans notre répertoire de travail actuel. Matplotlib possède une excellente fonctionnalité intégrée pour faire cela. Ajoutez simplement l'instruction suivante immédiatement après la finalisation du quatrième sous-graphique :
################################################
# Enregistrer la figure sur notre machine locale
################################################
plt.savefig('bank_data.png')
Dans la suite de ce tutoriel, vous apprendrez comment planifier la mise à jour automatique de cette matrice de sous-graphiques sur votre site web en direct chaque jour.
Étape 3 : Créer un compte Amazon Web Services
Jusqu'à présent dans ce tutoriel, nous avons appris comment :
- Sourcer les données boursières que nous allons visualiser à partir de l'API IEX Cloud
- Créer de magnifiques visualisations en utilisant ces données avec la bibliothèque matplotlib pour Python
Dans la suite de ce tutoriel, vous apprendrez comment automatiser ces visualisations de manière à ce qu'elles soient mises à jour selon un calendrier spécifique.
Pour ce faire, nous utiliserons les capacités de cloud computing d'Amazon Web Services. Vous devrez d'abord créer un compte AWS.
Accédez à cette URL et cliquez sur "Créer un compte AWS" dans le coin supérieur droit :
L'application web d'AWS vous guidera à travers les étapes de création d'un compte.
Une fois votre compte créé, nous pouvons commencer à travailler avec les deux services AWS dont nous aurons besoin pour nos visualisations : AWS S3 et AWS EC2.
Étape 4 : Créer un compartiment (bucket) AWS S3 pour stocker vos visualisations
AWS S3 signifie Simple Storage Service. C'est l'une des offres de cloud computing les plus populaires disponibles dans Amazon Web Services. Les développeurs utilisent AWS S3 pour stocker des fichiers et y accéder plus tard via des URL publiques.
Pour stocker ces fichiers, nous devons d'abord créer ce qu'on appelle un bucket AWS S3, qui est un terme sophistiqué pour désigner un dossier stockant des fichiers dans AWS. Pour ce faire, accédez d'abord au tableau de bord S3 au sein d'Amazon Web Services.
Sur le côté droit du tableau de bord Amazon S3, cliquez sur Créer un compartiment (Create bucket), comme illustré ci-dessous :
Sur l'écran suivant, AWS vous demandera de choisir un nom pour votre nouveau compartiment S3. Pour les besoins de ce tutoriel, nous utiliserons le nom de compartiment nicks-first-bucket.
Ensuite, vous devrez faire défiler vers le bas et définir les autorisations de votre compartiment. Étant donné que les fichiers que nous allons télécharger sont conçus pour être accessibles au public (après tout, nous allons les intégrer dans des pages d'un site web), vous voudrez rendre les autorisations aussi ouvertes que possible.
Voici un exemple spécifique de ce à quoi devraient ressembler vos autorisations AWS S3 :
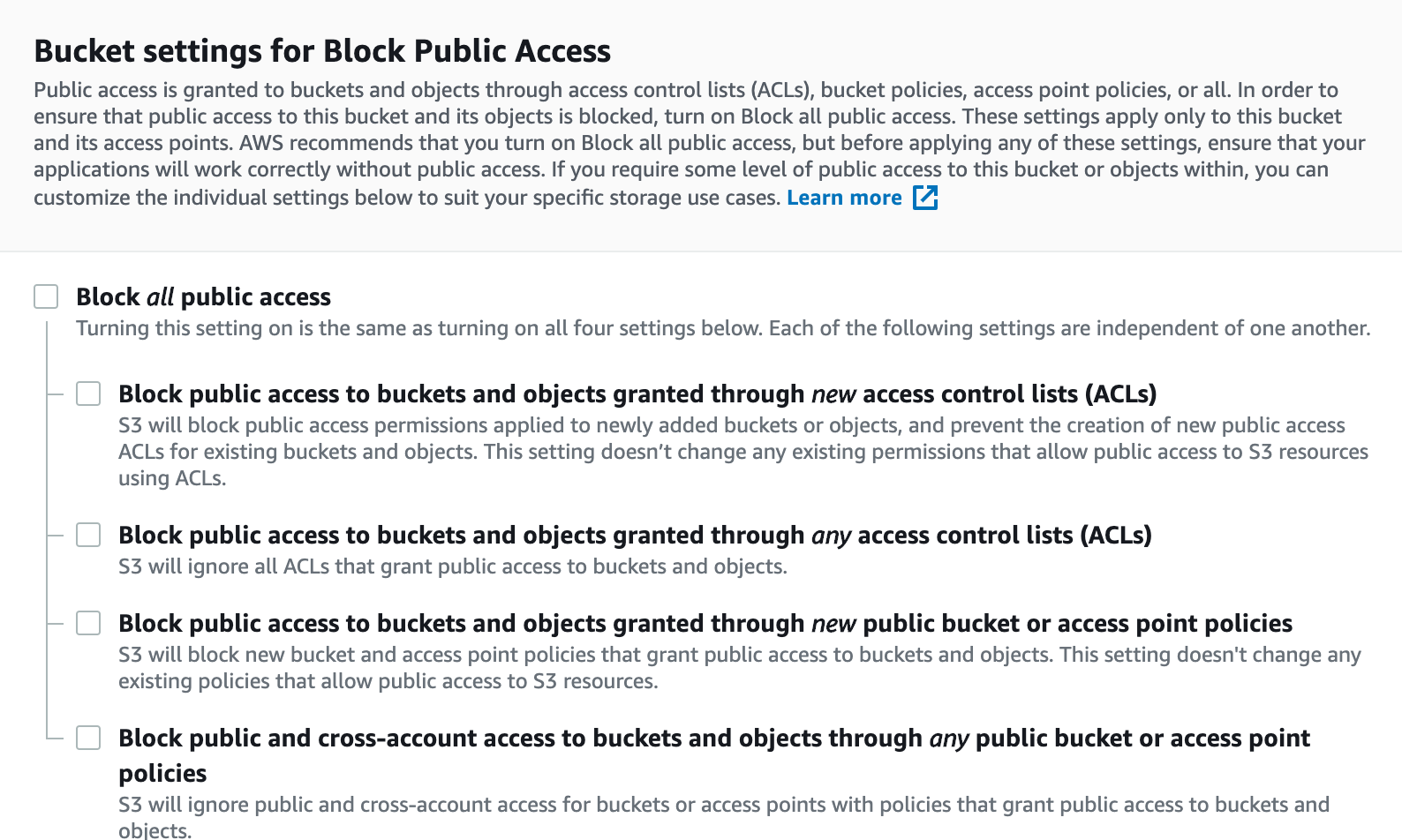
Ces autorisations sont très laxistes et, pour de nombreux cas d'utilisation, ne sont pas acceptables (bien qu'elles répondent effectivement aux exigences de ce tutoriel). Pour cette raison, AWS vous demandera de reconnaître l'avertissement suivant avant de créer votre compartiment AWS S3 :

Une fois tout cela fait, vous pouvez faire défiler jusqu'au bas de la page et cliquer sur Créer le compartiment (Create Bucket). Vous êtes maintenant prêt à continuer !
Étape 5 : Modifier le script Python pour enregistrer vos visualisations sur AWS S3
Notre script Python, dans sa forme actuelle, est conçu pour créer une visualisation puis enregistrer cette visualisation sur notre ordinateur local. Nous devons maintenant modifier notre script pour enregistrer plutôt le fichier .png dans le compartiment AWS S3 que nous venons de créer (qui, pour rappel, s'appelle nicks-first-bucket).
L'outil que nous utiliserons pour télécharger notre fichier vers notre compartiment AWS S3 s'appelle boto3, qui est le kit de développement logiciel (SDK) d'Amazon Web Services pour Python.
Tout d'abord, vous devrez installer boto3 sur votre machine. Le moyen le plus simple de le faire est d'utiliser le gestionnaire de paquets pip :
pip3 install boto3
Ensuite, nous devons importer boto3 dans notre script Python. Nous le faisons en ajoutant l'instruction suivante près du début de notre script :
import boto3
Compte tenu de la profondeur et de l'étendue des offres de produits d'Amazon Web Services, boto3 est une bibliothèque Python incroyablement complexe.
Heureusement, nous n'avons besoin d'utiliser que certaines des fonctionnalités les plus basiques de boto3.
Le bloc de code suivant téléchargera notre visualisation finale sur Amazon S3.
################################################
# Envoyer le fichier vers le compartiment (bucket) AWS S3
################################################
s3 = boto3.resource('s3')
s3.meta.client.upload_file('bank_data.png', 'nicks-first-bucket', 'bank_data.png', ExtraArgs={'ACL':'public-read'})
Comme vous pouvez le voir, la méthode upload_file de boto3 prend plusieurs arguments. Décomposons-les un par un :
bank_data.pngest le nom du fichier sur notre machine locale.nicks-first-bucketest le nom du compartiment S3 vers lequel nous voulons effectuer le téléchargement.bank_data.pngest le nom que nous voulons donner au fichier après son téléchargement dans le compartiment AWS S3. Dans ce cas, il est identique au premier argument, mais ce n'est pas obligatoire.ExtraArgs={'ACL':'public-read'}signifie que le fichier doit être lisible par le public une fois qu'il est poussé vers le compartiment AWS S3.
L'exécution de ce code maintenant entraînera une erreur. Plus précisément, Python lèvera l'exception suivante :
S3UploadFailedError: Failed to upload bank_data.png to nicks-first-bucket/bank_data.png: An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Pourquoi cela ?
Eh bien, c'est parce que nous n'avons pas encore configuré notre machine locale pour interagir avec Amazon Web Services via boto3.
Pour ce faire, nous devons exécuter la commande aws configure depuis notre interface de ligne de commande et ajouter nos clés d'accès. Cette documentation d'Amazon partage plus d'informations sur la configuration de votre interface de ligne de commande AWS.
Si vous préférez ne pas quitter freecodecamp.org, voici les étapes rapides pour configurer votre CLI AWS.
Tout d'abord, passez votre souris sur votre nom d'utilisateur dans le coin supérieur droit, comme ceci :
Cliquez sur Mes identifiants de sécurité (My Security Credentials).
Sur l'écran suivant, vous allez cliquer sur le menu déroulant Clés d'accès (ID de clé d'accès et clé d'accès secrète), puis cliquer sur Créer une nouvelle clé d'accès (Create New Access Key).
Cela vous invitera à télécharger un fichier .csv contenant à la fois votre clé d'accès et votre clé d'accès secrète. Enregistrez-les dans un emplacement sûr.
Ensuite, déclenchez l'interface de ligne de commande Amazon Web Services en tapant aws configure sur votre ligne de commande. Cela vous invitera à saisir votre clé d'accès et votre clé d'accès secrète.
Une fois cela fait, votre script devrait fonctionner comme prévu. Réexécutez le script et vérifiez que votre visualisation Python a été correctement téléchargée sur AWS S3 en regardant à l'intérieur du compartiment que nous avons créé précédemment :
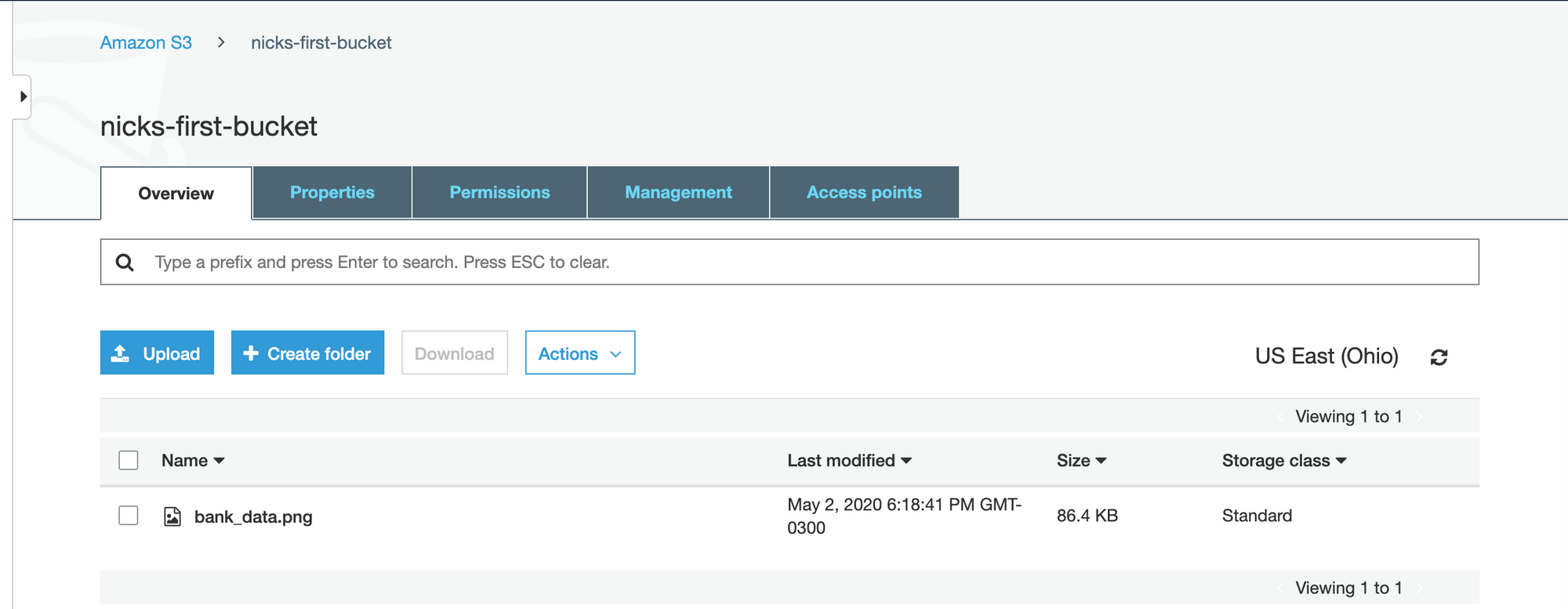
La visualisation a été téléchargée avec succès. Nous sommes maintenant prêts à intégrer la visualisation sur notre site web !
Étape 6 : Intégrer la visualisation sur votre site web
Une fois que la visualisation de données a été téléchargée sur AWS S3, vous voudrez l'intégrer quelque part sur votre site web. Cela pourrait être dans un article de blog ou toute autre page de votre site.
Pour ce faire, nous devrons récupérer l'URL de l'image à partir de notre compartiment S3. Cliquez sur le nom de l'image dans le compartiment S3 pour accéder à la page spécifique de cet élément. Elle ressemblera à ceci :
Si vous faites défiler vers le bas de la page, il y aura un champ appelé URL de l'objet (Object URL) qui ressemble à ceci :
https://nicks-first-bucket.s3.us-east-2.amazonaws.com/bank_data.png
Si vous copiez et collez cette URL dans un navigateur web, elle téléchargera effectivement le fichier bank_data.png que nous avons téléchargé plus tôt !
Pour intégrer cette image sur une page web, vous devrez la passer dans une balise HTML img en tant qu'attribut src. Voici comment nous intégrerions notre image bank_data.png dans une page web en utilisant HTML :
<img src="https://nicks-first-bucket.s3.us-east-2.amazonaws.com/bank_data.png">
Note : Dans une image réelle intégrée sur un site web, il serait important d'inclure une balise alt à des fins d'accessibilité.
Dans la section suivante, nous apprendrons comment planifier l'exécution périodique de notre script Python afin que les données de bank_data.png soient toujours à jour.
Étape 7 : Créer une instance AWS EC2
Nous utiliserons AWS EC2 pour planifier l'exécution périodique de notre script Python.
AWS EC2 signifie Elastic Compute Cloud et, avec S3, c'est l'un des services de cloud computing les plus populaires d'Amazon.
Il vous permet de louer de petites unités de puissance de calcul (appelées instances) sur des ordinateurs dans les centres de données d'Amazon et de programmer ces ordinateurs pour effectuer des tâches pour vous.
AWS EC2 est un service assez remarquable car si vous louez certains de leurs plus petits ordinateurs, vous êtes en fait éligible à l'offre gratuite d'AWS (AWS free tier). Autrement dit, une utilisation diligente de la tarification au sein d'AWS EC2 vous permettra d'éviter de payer quoi que ce soit.
Pour commencer, nous devrons créer notre première instance EC2. Pour ce faire, accédez au tableau de bord EC2 dans la console de gestion AWS et cliquez sur Lancer l'instance (Launch Instance) :

Cela vous amènera à un écran contenant tous les types d'instances disponibles dans AWS EC2. Il y a un nombre presque incroyable d'options ici. Nous voulons un type d'instance éligible à l' offre gratuite (Free tier eligible) - plus précisément, j'ai choisi Amazon Linux 2 AMI (HVM), SSD Volume Type :

Cliquez sur Sélectionner (Select) pour continuer.
Sur la page suivante, AWS vous demandera de sélectionner les spécifications de votre machine. Les champs que vous pouvez sélectionner incluent :
Famille(Family)Type(Type)vCPUsMémoire(Memory)Stockage de l'instance (Go)(Instance Storage (GB))Optimisé pour EBS(EBS-Optimized)Performances réseau(Network Performance)Prise en charge d'IPv6(IPv6 Support)
Pour les besoins de ce tutoriel, nous voulons simplement sélectionner la machine unique éligible à l'offre gratuite. Elle est caractérisée par une petite étiquette verte qui ressemble à ceci :

Cliquez sur Vérifier et lancer (Review and Launch) au bas de l'écran pour continuer.
L'écran suivant présentera les détails de votre nouvelle instance pour examen.
Examinez rapidement les spécifications de la machine, puis cliquez sur Lancer (Launch) dans le coin inférieur droit.
Cliquer sur le bouton Lancer (Launch) déclenchera une fenêtre contextuelle vous demandant de Sélectionner une paire de clés existante ou créer une nouvelle paire de clés.
Une paire de clés est composée d'une clé publique détenue par AWS et d'une clé privée que vous devez télécharger et stocker dans un fichier .pem.
You must have access to that .pem file in order to access your EC2 instance (typically via SSH). You also have the option to proceed without a key pair, but this is not recommended for security reasons.
Vous devez avoir accès à ce fichier .pem pour accéder à votre instance EC2 (généralement via SSH). Vous avez également la possibilité de continuer sans paire de clés, mais cela n'est pas recommandé pour des raisons de sécurité.
Une fois cela fait, votre instance sera lancée ! Félicitations pour le lancement de votre première instance sur l'un des services d'infrastructure les plus importants d'Amazon Web Services.
Ensuite, vous devrez pousser votre script Python dans votre instance EC2.
Voici une instruction de commande générique qui vous permet de déplacer un fichier vers une instance EC2 :
scp -i path/to/.pem_file path/to/file username@host_address.amazonaws.com:/path_to_copy
Exécutez cette instruction avec les remplacements nécessaires pour déplacer bank_stock_data.py dans l'instance EC2.
Vous pourriez penser que vous pouvez maintenant exécuter votre script Python depuis votre instance EC2. Malheureusement, ce n'est pas le cas. Votre instance EC2 n'est pas livrée avec les packages Python nécessaires.
To install the packages we used, you can either export a requirements.txt file and import the proper packages using pip, or you can simply run the following:
Pour installer les packages que nous avons utilisés, vous pouvez soit exporter un fichier requirements.txt et importer les packages appropriés à l'aide de pip, soit simplement exécuter ce qui suit :
sudo yum install python3-pip
pip3 install pandas
pip3 install boto3
Nous sommes maintenant prêts à planifier l'exécution périodique de notre script Python sur notre instance EC2 ! Nous explorons cela dans la section suivante de notre article.
Étape 8 : Planifier l'exécution périodique du script Python sur AWS EC2
La seule étape restante dans ce tutoriel est de planifier l'exécution périodique de notre fichier bank_stock_data.py dans notre instance EC2.
Nous pouvons utiliser un utilitaire de ligne de commande appelé cron pour faire cela.
cron fonctionne en vous demandant de spécifier deux choses :
- La fréquence à laquelle vous souhaitez qu'une tâche (appelée
tâche cron) soit effectuée, exprimée via une expression cron - Ce qui doit être exécuté lorsque la tâche cron est planifiée
Tout d'abord, commençons par créer une expression cron.
Les expressions cron peuvent sembler être du charabia pour un profane. Par exemple, voici l'expression cron qui signifie "chaque jour à midi" :
00 12 * * *
Personnellement, j'utilise le site web crontab guru, qui est une excellente ressource vous permettant de voir (en termes simples) ce que signifie votre expression cron.
Voici comment vous pouvez utiliser le site crontab guru pour planifier une tâche cron tous les dimanches à 7h du matin :

Nous avons maintenant un outil (crontab guru) que nous pouvons utiliser pour générer notre expression cron. Nous devons maintenant donner l'instruction au démon cron de notre instance EC2 d'exécuter notre fichier bank_stock_data.py tous les dimanches à 7h du matin.
Pour ce faire, nous allons d'abord créer un nouveau fichier dans notre instance EC2 appelé bank_stock_data.cron. Comme j'utilise l'éditeur de texte vim, la commande que j'utilise pour cela est :
vim bank_stock_data.cron
À l'intérieur de ce fichier .cron, il devrait y avoir une ligne qui ressemble à ceci : (expression cron) (instruction à exécuter). Notre expression cron est 00 7 * * 7 et notre instruction à exécuter est python3 bank_stock_data.py.
En mettant tout cela ensemble, voici ce que devrait être le contenu final de bank_stock_data.cron :
00 7 * * 7 python3 bank_stock_data.py
La dernière étape de ce tutoriel consiste à importer le fichier bank_stock_data.cron dans la crontab de notre instance EC2. La crontab est essentiellement un fichier qui regroupe les tâches que le démon cron doit effectuer périodiquement.
Prenons d'abord un moment pour vérifier cela dans notre crontab. La commande suivante affiche le contenu de la crontab sur notre console :
crontab -l
Comme nous n'avons rien ajouté à notre crontab et que nous n'avons créé notre instance EC2 qu'il y a quelques instants, cette instruction ne devrait rien afficher.
Maintenant, importons bank_stock_data.cron dans la crontab. Voici l'instruction pour faire cela :
crontab bank_stock_data.cron
Maintenant, nous devrons être en mesure d'afficher le contenu de notre crontab et de voir le contenu de bank_stock_data.cron.
Pour tester cela, exécutez la commande suivante :
crontab -l
Elle devrait afficher :
00 7 * * 7 python3 bank_stock_data.py
Réflexions finales
Dans ce tutoriel, vous avez appris à créer de magnifiques visualisations de données à l'aide de Python et Matplotlib qui se mettent à jour périodiquement. Plus précisément, nous avons abordé :
- Comment télécharger et analyser des données à partir d'IEX Cloud, l'une de mes sources de données préférées pour des données financières de haute qualité
- Comment formater les données au sein d'un DataFrame pandas
- Comment créer des visualisations de données en Python à l'aide de matplotlib
- Comment créer un compte avec Amazon Web Services
- Comment télécharger des fichiers statiques sur AWS S3
- Comment intégrer des fichiers
.pnghébergés sur AWS S3 dans des pages d'un site web - Comment créer une instance AWS EC2
- Comment planifier l'exécution périodique d'un script Python à l'aide d'AWS EC2 avec
cron
Cet article a été publié par Nick McCullum, qui enseigne aux gens comment coder sur son site web.