
Article original : How to Create Auto-Updating Excel Spreadsheets of Stock Market Data with Python, AWS, and IEX Cloud
Par Nick McCullum
De nombreux développeurs Python dans le monde financier sont chargés de créer des documents Excel pour analyse par des utilisateurs non techniques.
Cela est en réalité beaucoup plus difficile que cela n'y paraît. De la collecte des données à la mise en forme de la feuille de calcul en passant par le déploiement du document final dans un emplacement central, il y a de nombreuses étapes impliquées dans le processus.
Dans ce tutoriel, je vais vous montrer comment créer des feuilles de calcul Excel en utilisant Python qui :
- Utilisent les données boursières de IEX Cloud
- Sont déployées dans un bucket S3 centralisé afin que toute personne disposant de la bonne URL puisse y accéder
- Se mettent à jour automatiquement chaque jour en utilisant l'utilitaire de ligne de commande
cron
Étape 1 : Créer un compte avec IEX Cloud
IEX Cloud est le fournisseur de données filiale de la bourse IEX.
Au cas où vous ne connaîtriez pas IEX, il s'agit d'un acronyme pour "The Investor's Exchange". IEX a été fondée par Brad Katsuyama pour construire une meilleure bourse qui évite les comportements peu favorables aux investisseurs comme le front-running et le trading haute fréquence. Les exploits de Katsuyama ont été célèbrement chroniqués dans le livre à succès de Michael Lewis Flash Boys.
J'ai étudié de nombreux fournisseurs de données financières et IEX Cloud offre la meilleure combinaison de :
- Données de haute qualité
- Prix abordable
Leurs prix sont les suivants :
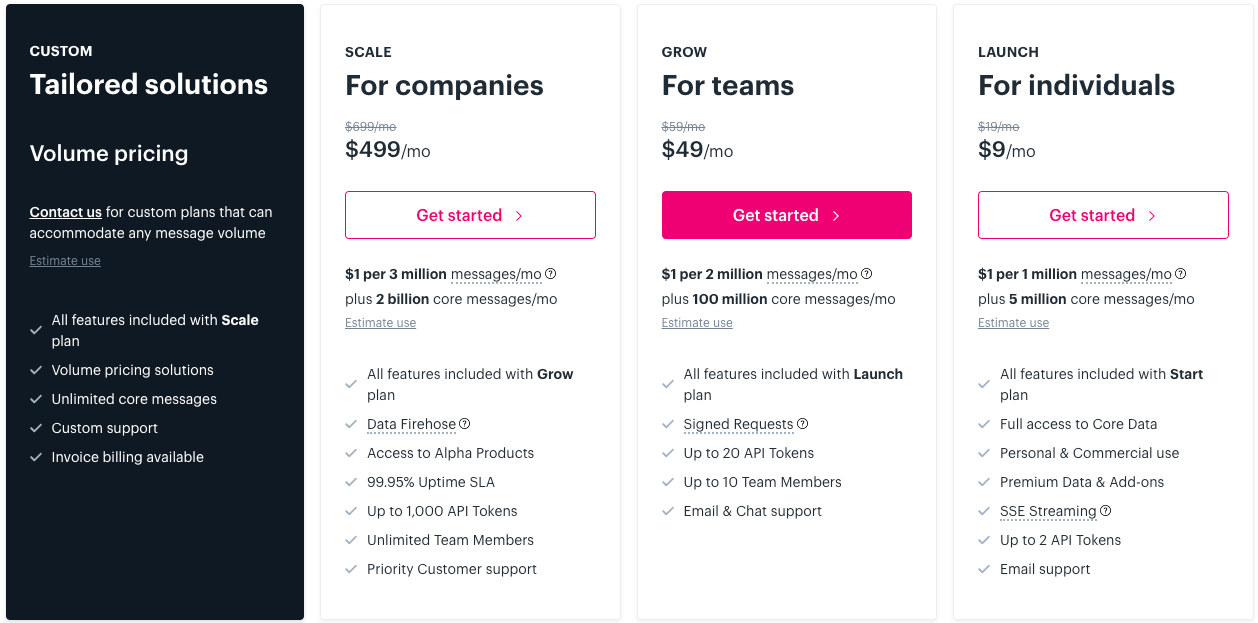
Le plan Launch à 9 $/mois est largement suffisant pour de nombreux cas d'utilisation.
Un avertissement sur l'utilisation de IEX Cloud (et de tout autre fournisseur de données payant à l'utilisation) : il est très important que vous définissiez des budgets d'utilisation dès le début. Ces budgets vous bloquent l'accès à votre compte une fois que vous avez atteint un certain coût en dollars pour le mois.
Lorsque j'ai commencé à utiliser IEX Cloud, j'ai accidentellement créé une boucle infinie un vendredi après-midi qui contenait un appel API à IEX Cloud. Ces appels API sont facturés sur une base de coût par appel... ce qui a résulté en un email terrifiant de IEX :

C'est un témoignage de l'orientation client de IEX qu'ils ont accepté de réinitialiser mon utilisation à condition que je définisse des budgets d'utilisation à l'avenir. Bravo IEX !
Comme pour la plupart des abonnements API, le principal avantage de créer un compte IEX Cloud est d'avoir une clé API.
Pour des raisons évidentes, je ne partagerai pas de clé API dans cet article.
Cependant, vous pouvez toujours suivre ce tutoriel avec votre propre clé API tant que vous l'assignez au nom de variable suivant :
IEX_API_Key
Vous verrez la variable IEX_API_Key vide dans mes blocs de code tout au long du reste de ce tutoriel.
Étape 2 : Écrire votre script Python
Maintenant que vous avez accès à la clé API dont vous aurez besoin pour collecter des données financières, il est temps d'écrire votre script Python.
Ce sera la section la plus longue de ce tutoriel. C'est aussi la plus flexible - nous allons créer un script Python qui satisfait certains critères pré-spécifiés, mais vous pourriez modifier cette section pour vraiment créer n'importe quelle feuille de calcul que vous voulez !
Pour commencer, définissons nos objectifs. Nous allons écrire un script Python qui génère un fichier Excel de données boursières avec les caractéristiques suivantes :
- Il inclura les 10 plus grandes actions des États-Unis
- Il contiendra quatre colonnes : symbole boursier, nom de l'entreprise, prix de l'action et rendement du dividende.
- Il sera formaté de sorte que l'arrière-plan de l'en-tête soit
#135485et le texte blanc, tandis que l'arrière-plan du corps de la feuille de calcul soit#DADADAet la couleur de la police noire (par défaut).
Commençons par importer notre premier package.
Puisque les feuilles de calcul sont essentiellement des structures de données avec des lignes et des colonnes, la bibliothèque pandas - y compris son objet DataFrame intégré - est un candidat parfait pour manipuler des données dans ce tutoriel.
Nous commencerons par importer pandas sous l'alias pd comme ceci :
import pandas as pd
Ensuite, nous spécifierons notre clé API IEX Cloud. Comme je l'ai mentionné auparavant, je ne vais pas vraiment inclure ma clé API, donc vous devrez obtenir votre propre clé API depuis votre compte IEX et l'inclure ici :
IEX_API_Key = ''
Notre prochaine étape est de déterminer les dix plus grandes entreprises des États-Unis.
Vous pouvez répondre à cette question avec une rapide recherche Google.
Pour faire court, j'ai inclus les entreprises (ou plutôt, leurs symboles boursiers) dans la liste Python suivante :
tickers = [
'MSFT',
'AAPL',
'AMZN',
'GOOG',
'FB',
'BRK.B',
'JNJ',
'WMT',
'V',
'PG'
]
Ensuite, il est temps de déterminer comment interagir avec l'API IEX Cloud pour obtenir les métriques dont nous avons besoin pour chaque entreprise.
L'API IEX Cloud retourne des objets JSON en réponse aux requêtes HTTP. Puisque nous travaillons avec plus d'un symbole dans ce tutoriel, nous utiliserons la fonctionnalité d'appel API par lot de IEX Cloud, qui permet de demander des données sur plus d'un symbole à la fois. L'utilisation des appels API par lot présente deux avantages :
- Cela réduit le nombre de requêtes HTTP que vous devez faire, ce qui rendra votre code plus performant.
- Le prix des appels API par lot est légèrement meilleur avec la plupart des fournisseurs de données.
Voici un exemple de ce à quoi la requête HTTP pourrait ressembler, avec quelques mots de remplissage où nous devrons personnaliser la requête :
https://cloud.iexapis.com/stable/stock/market/batch?symbols=TICKERS&types=ENDPOINTS&range=RANGE&token=IEX_API_Key
Dans cette URL, nous remplacerons ces variables par les valeurs suivantes :
TICKERSsera remplacé par une chaîne contenant chacun de nos symboles séparés par une virgule.ENDPOINTSsera remplacé par une chaîne contenant chacun des points de terminaison IEX Cloud que nous voulons atteindre, séparés par une virgule.RANGEsera remplacé par1y. Ces points de terminaison contiennent chacun des données ponctuelles et non des données de séries temporelles, donc cette plage peut vraiment être ce que vous voulez.
Mettons cette URL dans une variable appelée HTTP_request pour que nous puissions la modifier plus tard :
HTTP_request = 'https://cloud.iexapis.com/stable/stock/market/batch?symbols=TICKERS&types=ENDPOINTS&range=RANGE&token=IEX_API_Key'
Travaillons chacune de ces variables une par une pour déterminer l'URL exacte dont nous avons besoin.
Pour la variable TICKERS, nous pouvons générer une vraie variable Python (et non juste un mot de remplissage) avec une simple boucle for :
#Créer une chaîne vide appelée `ticker_string` à laquelle nous ajouterons des symboles et des virgules
ticker_string = ''
#Boucler à travers chaque élément de `tickers` et les ajouter ainsi qu'une virgule à ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
#Supprimer la dernière virgule de `ticker_string`
ticker_string = ticker_string[:-1]
Nous pouvons maintenant interpoler notre variable ticker_string dans la variable HTTP_request que nous avons créée précédemment en utilisant une f-string :
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types=ENDPOINTS&range=RANGE&token=IEX_API_Key'
Ensuite, nous devons déterminer quels points de terminaison IEX Cloud nous devons interroger.
Une rapide investigation dans la documentation de IEX Cloud révèle que nous n'avons besoin que des points de terminaison price et stats pour créer notre feuille de calcul.
Ainsi, nous pouvons remplacer le mot de remplissage ENDPOINTS de notre requête HTTP initiale par la variable suivante :
endpoints = 'price,stats'
Comme nous l'avons fait avec notre variable ticker_string, substituons la variable endpoints dans la variable ticker_string :
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=RANGE&token=IEX_API_Key'
Le dernier mot de remplissage que nous devons remplacer est RANGE. Nous ne le remplacerons pas par une variable. Au lieu de cela, nous pouvons coder en dur un 1y directement dans le chemin de l'URL comme ceci :
https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=1y&token=IEX_API_Key
Nous avons fait beaucoup jusqu'à présent, alors faisons un récapitulatif de notre base de code :
import pandas as pd
IEX_API_Key = ''
#Spécifier les symboles boursiers qui seront inclus dans notre feuille de calcul
tickers = [
'MSFT',
'AAPL',
'AMZN',
'GOOG',
'FB',
'BRK.B',
'JNJ',
'WMT',
'V',
'PG'
]
#Créer une chaîne vide appelée `ticker_string` à laquelle nous ajouterons des symboles et des virgules
ticker_string = ''
#Boucler à travers chaque élément de `tickers` et les ajouter ainsi qu'une virgule à ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
#Supprimer la dernière virgule de `ticker_string`
ticker_string = ticker_string[:-1]
#Créer les chaînes de points de terminaison
endpoints = 'price,stats'
#Interpoler les chaînes de points de terminaison dans la chaîne HTTP_request
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=1y&token={IEX_API_Key}'
Il est maintenant temps d'interroger l'API et de sauvegarder ses données dans une structure de données au sein de notre application Python.
Nous pouvons lire des objets JSON avec la méthode read_json de pandas. Dans notre cas, nous sauvegarderons les données JSON dans un pandas DataFrame appelé raw_data, comme ceci :
raw_data = pd.read_json(HTTP_request)
Prenons un moment maintenant pour nous assurer que les données ont été importées dans un format agréable pour notre application.
Si vous travaillez sur ce tutoriel dans un Jupyter Notebook, vous pouvez simplement taper le nom de la variable pandas DataFrame sur la dernière ligne d'une cellule de code, et Jupyter rendra joliment une image des données, comme ceci :

Comme vous pouvez le voir, le pandas DataFrame contient une colonne pour chaque symbole boursier et deux lignes : une pour le point de terminaison stats et une pour le point de terminaison price. Nous devrons analyser ce DataFrame pour obtenir les quatre métriques que nous voulons. Travaillons les métriques une par une dans les étapes ci-dessous.
Métrique 1 : Symbole boursier
Cette étape est très simple puisque les symboles boursiers sont contenus dans les colonnes du pandas DataFrame. Nous pouvons y accéder via l'attribut columns du pandas DataFrame comme ceci :
raw_data.columns
Pour accéder aux autres métriques dans raw_data, nous créerons une boucle for qui parcourt chaque symbole dans raw_data.columns. À chaque itération de la boucle, nous ajouterons les données à un nouvel objet pandas DataFrame appelé output_data.
Tout d'abord, nous devrons créer output_data, qui doit être un pandas DataFrame vide avec quatre colonnes. Voici comment faire :
output_data = pd.DataFrame(pd.np.empty((0,4)))
Cela crée un pandas DataFrame vide avec 0 lignes et 4 colonnes.
Maintenant que cet objet a été créé, voici comment nous pouvons structurer cette boucle for :
for ticker in raw_data.columns:
#Analyser le nom de l'entreprise - pas encore terminé
company_name = ''
#Analyser le prix de l'action de l'entreprise - pas encore terminé
stock_price = 0
#Analyser le rendement du dividende de l'entreprise - pas encore terminé
dividend_yield = 0
new_column = pd.Series([ticker, company_name, stock_price, dividend_yield])
output_data = output_data.append(new_column, ignore_index = True)
Ensuite, déterminons comment analyser la variable company_name à partir de l'objet raw_data.
Métrique 2 : Nom de l'entreprise
La variable company_name est la première variable que nous devrons analyser à partir de l'objet raw_data. Pour un rapide récapitulatif, voici à quoi ressemble raw_data :

La variable company_name est contenue dans le point de terminaison stats sous la clé de dictionnaire companyName. Pour analyser ce point de données à partir de raw_data, nous pouvons utiliser ces index :
raw_data[ticker]['stats']['companyName']
En incluant cela dans notre boucle for précédente, cela donne :
output_data = pd.DataFrame(pd.np.empty((0,4)))
for ticker in raw_data.columns:
#Analyser le nom de l'entreprise - pas encore terminé
company_name = raw_data[ticker]['stats']['companyName']
#Analyser le prix de l'action de l'entreprise - pas encore terminé
stock_price = 0
#Analyser le rendement du dividende de l'entreprise - pas encore terminé
dividend_yield = 0
new_column = pd.Series([ticker, company_name, stock_price, dividend_yield])
output_data = output_data.append(new_column, ignore_index = True)
Passons maintenant à l'analyse de stock_price.
Métrique 3 : Prix de l'action
La variable stock_price est contenue dans le point de terminaison price, qui retourne uniquement une seule valeur. Cela signifie que nous n'avons pas besoin d'enchaîner des index comme nous l'avons fait avec company_name.
Voici comment nous pourrions analyser stock_price à partir de raw_data :
raw_data[ticker]['price']
En incluant cela dans notre boucle for, cela nous donne :
output_data = pd.DataFrame(pd.np.empty((0,4)))
for ticker in raw_data.columns:
#Analyser le nom de l'entreprise - pas encore terminé
company_name = raw_data[ticker]['stats']['companyName']
#Analyser le prix de l'action de l'entreprise - pas encore terminé
stock_price = raw_data[ticker]['price']
#Analyser le rendement du dividende de l'entreprise - pas encore terminé
dividend_yield = 0
new_column = pd.Series([ticker, company_name, stock_price, dividend_yield])
output_data = output_data.append(new_column, ignore_index = True)
La dernière métrique que nous devons analyser est dividend_yield.
Métrique 4 : Rendement du dividende
Comme company_name, dividend_yield est contenu dans le point de terminaison stats. Il est contenu sous la clé de dictionnaire dividendYield.
Voici comment nous pourrions l'analyser à partir de raw_data :
raw_data[ticker]['stats']['dividendYield']
En ajoutant cela à notre boucle for, cela nous donne :
output_data = pd.DataFrame(pd.np.empty((0,4)))
for ticker in raw_data.columns:
#Analyser le nom de l'entreprise - pas encore terminé
company_name = raw_data[ticker]['stats']['companyName']
#Analyser le prix de l'action de l'entreprise - pas encore terminé
stock_price = raw_data[ticker]['price']
#Analyser le rendement du dividende de l'entreprise - pas encore terminé
dividend_yield = raw_data[ticker]['stats']['dividendYield']
new_column = pd.Series([ticker, company_name, stock_price, dividend_yield])
output_data = output_data.append(new_column, ignore_index = True)
Affichons notre objet output_data pour voir à quoi ressemblent les données :
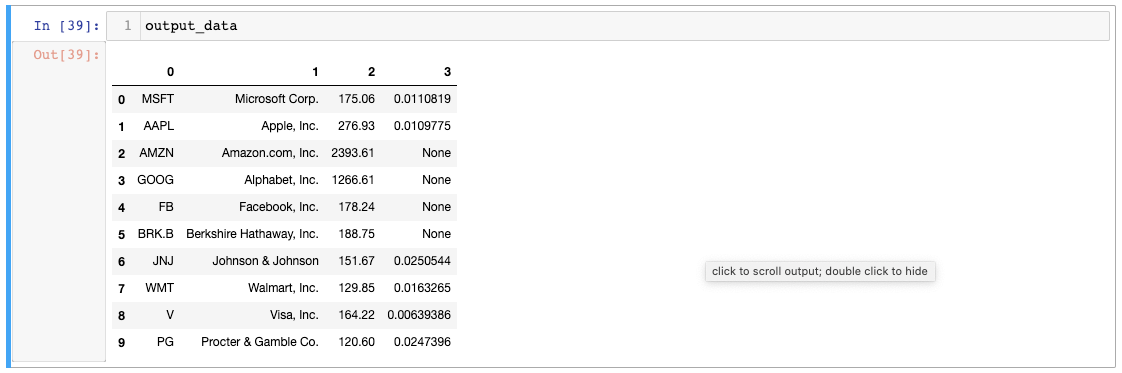
Jusqu'à présent, tout va bien ! Les deux prochaines étapes consistent à nommer les colonnes du pandas DataFrame et à changer son index.
Comment nommer les colonnes d'un DataFrame Pandas
Nous pouvons mettre à jour les noms des colonnes de notre objet output_data en créant une liste de noms de colonnes et en l'assignant à l'attribut output_data.columns, comme ceci :
output_data.columns = ['Ticker', 'Company Name', 'Stock Price', 'Dividend Yield']
Affichons notre objet output_data pour voir à quoi ressemblent les données :
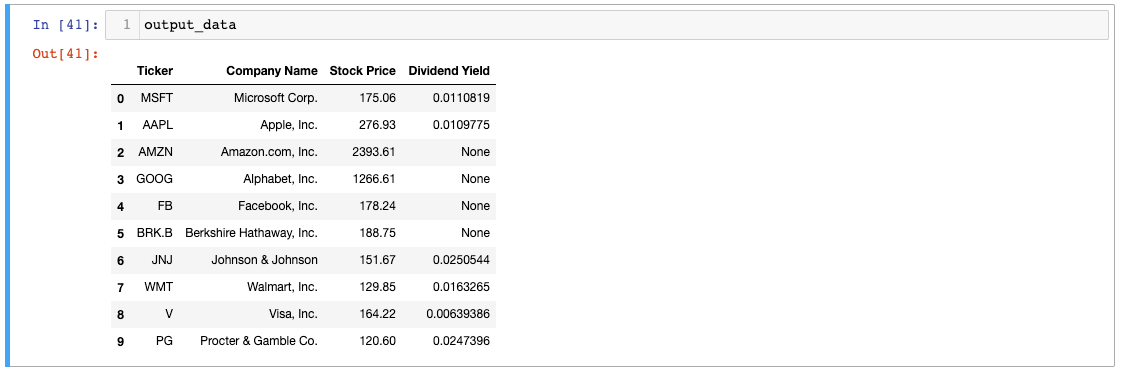
Bien mieux ! Changeons l'index de output_data ensuite.
Comment changer l'index d'un DataFrame Pandas
L'index d'un pandas DataFrame est une colonne spéciale qui est quelque peu similaire à la clé primaire d'une table de base de données SQL. Dans notre objet output_data, nous voulons définir la colonne Ticker comme index du DataFrame.
Voici comment nous pouvons faire cela en utilisant la méthode set_index :
output_data.set_index('Ticker', inplace=True)
Affichons notre objet output_data pour voir à quoi ressemblent les données :
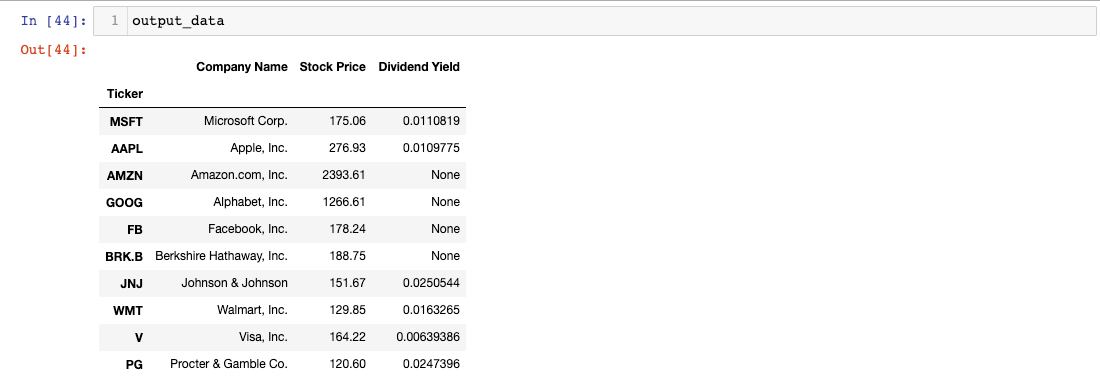
Une autre amélioration incrémentale !
Ensuite, traitons les données manquantes dans output_data.
Comment gérer les données manquantes dans les DataFrames Pandas
Si vous regardez de près output_data, vous remarquerez qu'il y a plusieurs valeurs None dans la colonne Dividend Yield :
Ces valeurs None indiquent simplement que l'entreprise de cette ligne ne verse actuellement pas de dividende. Bien que None soit une façon de représenter une action sans dividende, il est plus courant de montrer un Dividend Yield de 0.
Heureusement, la solution à ce problème est assez simple. La bibliothèque pandas inclut une excellente méthode fillna qui nous permet de remplacer les valeurs manquantes dans un pandas DataFrame.
Voici comment nous pouvons utiliser la méthode fillna pour remplacer les valeurs None de la colonne Dividend Yield par 0 :
output_data['Dividend Yield'].fillna(0,inplace=True)
L'objet output_data a maintenant une apparence beaucoup plus propre :
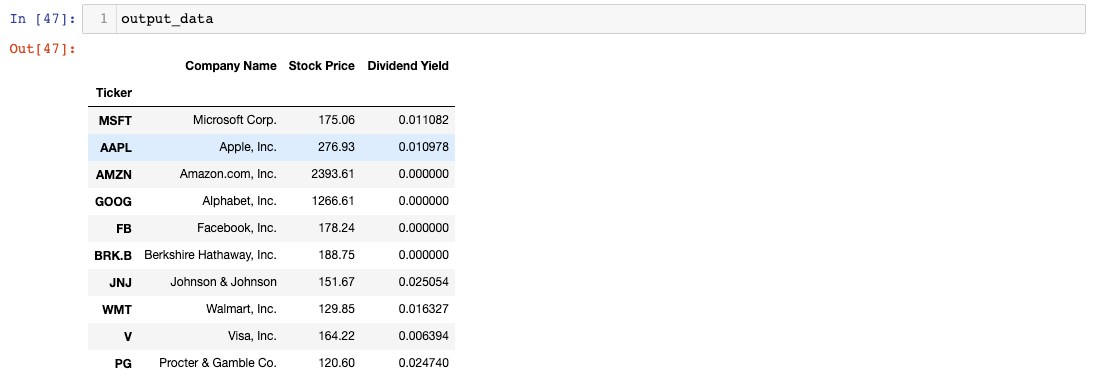
Nous sommes maintenant prêts à exporter notre DataFrame vers un document Excel ! Pour un rapide récapitulatif, voici notre script Python à ce jour :
import pandas as pd
IEX_API_Key = ''
#Spécifier les symboles boursiers qui seront inclus dans notre feuille de calcul
tickers = [
'MSFT',
'AAPL',
'AMZN',
'GOOG',
'FB',
'BRK.B',
'JNJ',
'WMT',
'V',
'PG'
]
#Créer une chaîne vide appelée `ticker_string` à laquelle nous ajouterons des symboles et des virgules
ticker_string = ''
#Boucler à travers chaque élément de `tickers` et les ajouter ainsi qu'une virgule à ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
#Supprimer la dernière virgule de `ticker_string`
ticker_string = ticker_string[:-1]
#Créer les chaînes de points de terminaison
endpoints = 'price,stats'
#Interpoler les chaînes de points de terminaison dans la chaîne HTTP_request
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range=1y&token={IEX_API_Key}'
#Créer un DataFrame pandas vide pour ajouter nos valeurs analysées pendant notre boucle for
output_data = pd.DataFrame(pd.np.empty((0,4)))
for ticker in raw_data.columns:
#Analyser le nom de l'entreprise
company_name = raw_data[ticker]['stats']['companyName']
#Analyser le prix de l'action de l'entreprise
stock_price = raw_data[ticker]['price']
#Analyser le rendement du dividende de l'entreprise
dividend_yield = raw_data[ticker]['stats']['dividendYield']
new_column = pd.Series([ticker, company_name, stock_price, dividend_yield])
output_data = output_data.append(new_column, ignore_index = True)
#Changer les noms des colonnes de output_data
output_data.columns = ['Ticker', 'Company Name', 'Stock Price', 'Dividend Yield']
#Changer l'index de output_data
output_data.set_index('Ticker', inplace=True)
#Remplacer les valeurs manquantes de la colonne 'Dividend Yield' par 0
output_data['Dividend Yield'].fillna(0,inplace=True)
#Afficher le DataFrame
output_data
Comment exporter un document Excel stylisé à partir d'un DataFrame Pandas en utilisant XlsxWriter
Il existe plusieurs façons d'exporter un fichier xlsx à partir d'un pandas DataFrame.
La manière la plus simple est d'utiliser la fonction intégrée to_excel. Par exemple, voici comment nous pourrions exporter output_data vers un fichier Excel :
output_data.to_excel('my_excel_document.xlsx)
Le problème avec cette approche est que le fichier Excel n'a aucun format. La sortie ressemble à ceci :
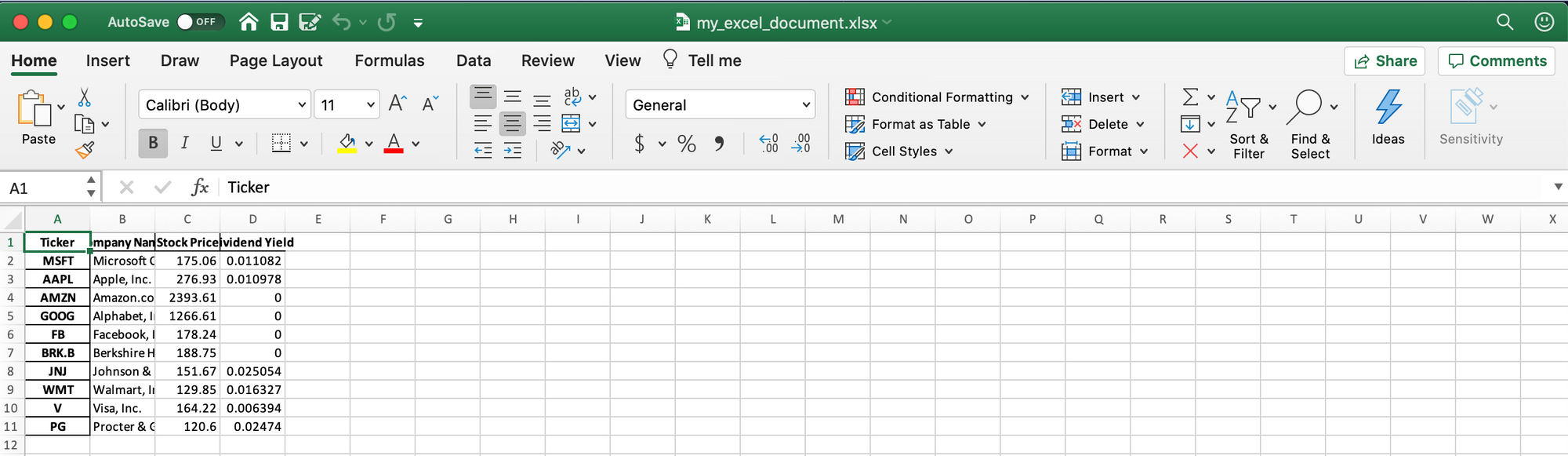
Le manque de formatage dans ce document le rend difficile à interpréter.
Quelle est la solution ?
Nous pouvons utiliser le package Python XlsxWriter pour générer des fichiers Excel bien formatés. Pour commencer, nous voudrons ajouter l'importation suivante au début de notre script Python :
import xlsxwriter
Ensuite, nous devons créer notre fichier Excel réel. Le package XlsxWriter a en fait une page de documentation dédiée sur la façon de travailler avec les pandas DataFrames, qui est disponible ici.
Notre première étape consiste à appeler la fonction pd.ExcelWriter et à passer le nom souhaité de notre fichier xlsx comme premier argument et engine='xlsxwriter' comme deuxième argument. Nous assignerons cela à une variable appelée writer :
writer = pd.ExcelWriter('stock_market_data.xlsx', engine='xlsxwriter')
À partir de là, nous devons appeler la méthode to_excel sur notre pandas DataFrame. Cette fois, au lieu de passer le nom du fichier que nous essayons d'exporter, nous passerons l'objet writer que nous venons de créer :
output_data.to_excel(writer, sheet_name='Sheet1')
Enfin, nous appellerons la méthode save sur notre objet writer, qui sauvegarde le fichier xlsx dans notre répertoire de travail actuel. Lorsque tout cela est fait, voici la section de notre script Python qui sauvegarde output_data dans un fichier Excel.
writer = pd.ExcelWriter('stock_market_data.xlsx', engine='xlsxwriter')
output_data.to_excel(writer, sheet_name='Sheet1')
writer.save()
Tout le code de formatage que nous inclurons dans notre fichier xlsx doit être contenu entre la création de l'objet ExcelWriter et l'instruction writer.save().
Comment styliser un fichier xlsx créé avec Python
Il est en réalité plus difficile que vous ne le pensez de styliser un fichier Excel en utilisant Python.
Cela est partiellement dû à certaines des limitations du package XlsxWriter. Sa documentation indique :
'XlsxWriter et Pandas fournissent très peu de support pour formater les données de sortie d'un dataframe en dehors du formatage par défaut tel que les cellules d'en-tête et d'index et toute cellule contenant des dates ou des datetimes. De plus, il n'est pas possible de formater les cellules qui ont déjà un format par défaut appliqué.'
'Si vous avez besoin d'un formatage très contrôlé de la sortie du dataframe, vous seriez probablement mieux de utiliser Xlsxwriter directement avec des données brutes prises de Pandas. Cependant, certaines options de formatage sont disponibles.'
Dans mon expérience, la manière la plus flexible de styliser les cellules dans un fichier xlsx créé par XlsxWriter est d'utiliser le formatage conditionnel qui n'applique le style que lorsqu'une cellule n'est pas égale à None.
Cela présente trois avantages :
- Cela offre plus de flexibilité de style que les options de formatage normales disponibles dans XlsxWriter.
- Vous n'avez pas besoin de boucler manuellement à travers chaque point de données et de les importer dans l'objet
writerun par un. - Cela vous permet de voir facilement lorsque des valeurs
Noneont trouvé leur chemin dans vos fichiersxlsxfinalisés, puisque ils manqueront le formatage requis.
Pour appliquer le style en utilisant le formatage conditionnel, nous devons d'abord créer quelques modèles de style. Plus précisément, nous aurons besoin de quatre modèles :
- Un
header_templatequi sera appliqué aux noms des colonnes en haut de la feuille de calcul - Un
string_templatequi sera appliqué aux colonnesTickeretCompany Name - Un
dollar_templatequi sera appliqué à la colonneStock Price - Un
percent_templatequi sera appliqué à la colonneDividend Yield
Chacun de ces modèles de format doit être ajouté à l'objet writer dans des dictionnaires qui ressemblent à la syntaxe CSS. Voici ce que je veux dire :
header_template = writer.book.add_format(
{
'font_color': '#ffffff',
'bg_color': '#135485',
'border': 1
}
)
string_template = writer.book.add_format(
{
'bg_color': '#DADADA',
'border': 1
}
)
dollar_template = writer.book.add_format(
{
'num_format':'$0.00',
'bg_color': '#DADADA',
'border': 1
}
)
percent_template = writer.book.add_format(
{
'num_format':'0.0%',
'bg_color': '#DADADA',
'border': 1
}
)
Pour appliquer ces formats à des cellules spécifiques dans notre fichier xlsx, nous devons appeler la méthode conditional_format du package sur writer.sheets['Stock Market Data']. Voici un exemple :
writer.sheets['Stock Market Data'].conditional_format('A2:B11',
{
'type': 'cell',
'criteria': '<>',
'value': '"None"',
'format': string_template
}
)
Si nous généralisons ce formatage aux trois autres formats que nous appliquons, voici à quoi ressemble la section de formatage de notre script Python :
writer = pd.ExcelWriter('stock_market_data.xlsx', engine='xlsxwriter')
output_data.to_excel(writer, sheet_name='Stock Market Data')
header_template = writer.book.add_format(
{
'font_color': '#ffffff',
'bg_color': '#135485',
'border': 1
}
)
string_template = writer.book.add_format(
{
'bg_color': '#DADADA',
'border': 1
}
)
dollar_template = writer.book.add_format(
{
'num_format':'$0.00',
'bg_color': '#DADADA',
'border': 1
}
)
percent_template = writer.book.add_format(
{
'num_format':'0.0%',
'bg_color': '#DADADA',
'border': 1
}
)
#Formater l'en-tête de la feuille de calcul
writer.sheets['Stock Market Data'].conditional_format('A1:D1',
{
'type': 'cell',
'criteria': '<>',
'value': '"None"',
'format': header_template
}
)
#Formater les colonnes 'Ticker' et 'Company Name'
writer.sheets['Stock Market Data'].conditional_format('A2:B11',
{
'type': 'cell',
'criteria': '<>',
'value': '"None"',
'format': string_template
}
)
#Formater la colonne 'Stock Price'
writer.sheets['Stock Market Data'].conditional_format('C2:C11',
{
'type': 'cell',
'criteria': '<>',
'value': '"None"',
'format': dollar_template
}
)
#Formater la colonne 'Dividend Yield'
writer.sheets['Stock Market Data'].conditional_format('D2:D11',
{
'type': 'cell',
'criteria': '<>',
'value': '"None"',
'format': percent_template
}
)
writer.save()
Jetons un coup d'œil à notre document Excel pour voir à quoi il ressemble :
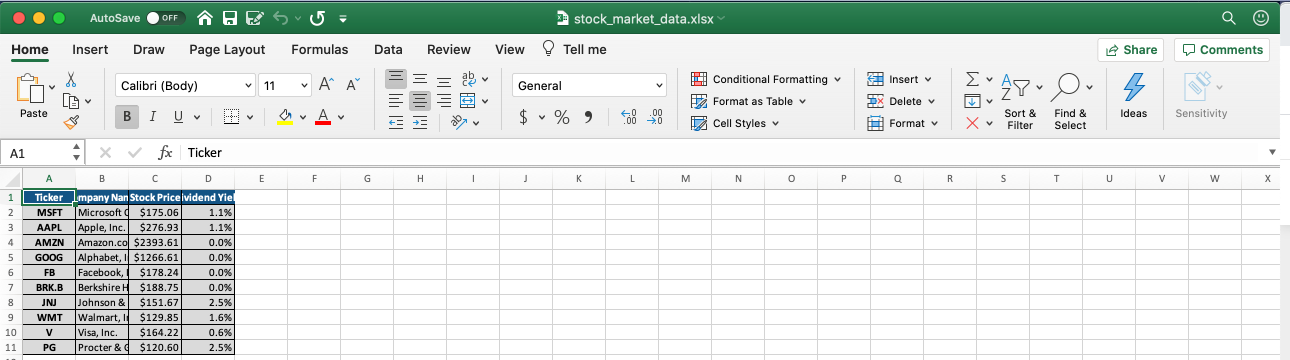
Jusqu'à présent, tout va bien ! La dernière amélioration incrémentale que nous pouvons apporter à ce document est d'élargir un peu ses colonnes.
Nous pouvons spécifier la largeur des colonnes en appelant la méthode set_column sur writer.sheets['Stock Market Data'].
Voici ce que nous ajouterons à notre script Python pour faire cela :
#Spécifier toutes les largeurs de colonnes
writer.sheets['Stock Market Data'].set_column('B:B', 32)
writer.sheets['Stock Market Data'].set_column('C:C', 18)
writer.sheets['Stock Market Data'].set_column('D:D', 20)
Voici la version finale de la feuille de calcul :
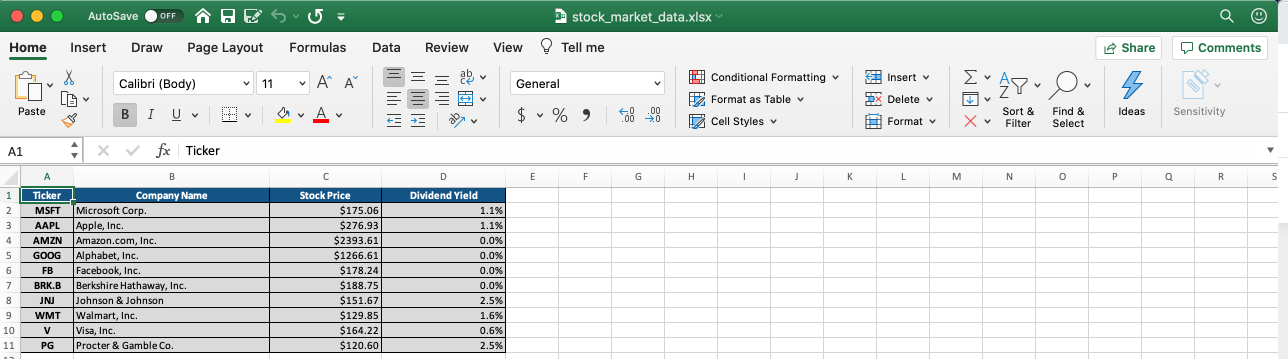
Et voilà ! Nous sommes prêts à partir ! Vous pouvez accéder à la version finale de ce script Python sur GitHub ici. Le fichier s'appelle stock_market_data.py.
Étape 3 : Configurer une machine virtuelle AWS EC2 pour exécuter votre script Python
Votre script Python est finalisé et prêt à être exécuté.
Cependant, nous ne voulons pas simplement l'exécuter sur notre machine locale de manière ponctuelle.
Au lieu de cela, nous allons configurer une machine virtuelle en utilisant le service Amazon Web Services' Elastic Compute Cloud (EC2).
Vous devrez d'abord créer un compte AWS si vous n'en avez pas déjà un. Pour ce faire, naviguez vers cette URL et cliquez sur "Create an AWS Account" dans le coin supérieur droit :
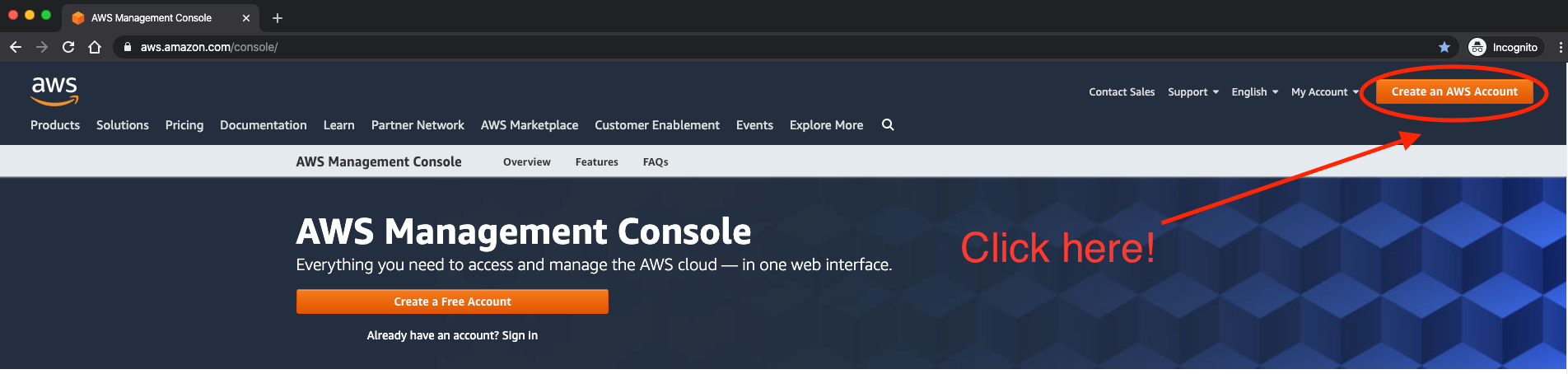
L'application web d'AWS vous guidera à travers les étapes pour créer un compte.
Une fois votre compte créé, vous devrez créer une instance EC2. Il s'agit simplement d'un serveur virtuel pour exécuter du code sur l'infrastructure AWS.
Les instances EC2 sont disponibles dans divers systèmes d'exploitation et tailles, allant de très petits serveurs qui qualifient pour le niveau gratuit d'AWS à de très grands serveurs capables d'exécuter des applications complexes.
Nous utiliserons le plus petit serveur d'AWS pour exécuter le script Python que nous avons écrit dans cet article. Pour commencer, naviguez vers EC2 dans la console de gestion AWS. Une fois arrivé dans EC2, cliquez sur Launch Instance :
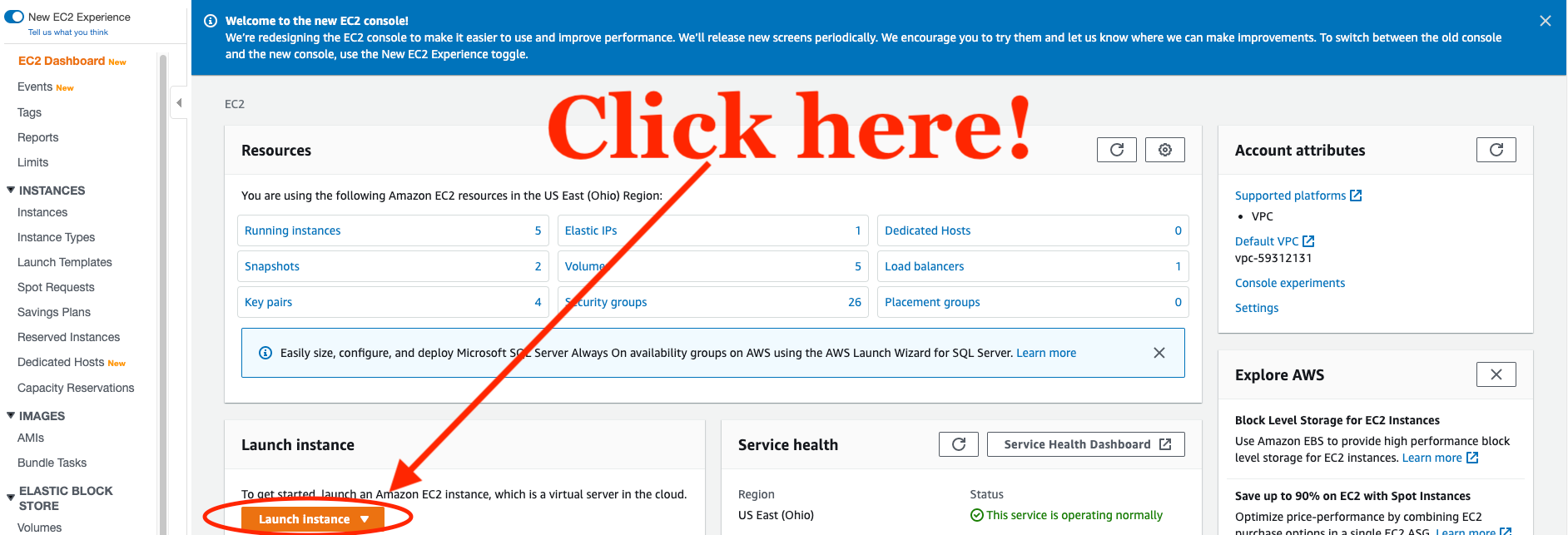
Cela vous amènera à un écran qui contient tous les types d'instances disponibles dans AWS EC2. Toute machine qui qualifie pour le niveau gratuit d'AWS sera suffisante.
J'ai choisi le Amazon Linux 2 AMI (HVM) :

Cliquez sur Select pour continuer.
Sur la page suivante, AWS vous demandera de sélectionner les spécifications de votre machine. Les champs que vous pouvez sélectionner incluent :
FamilyTypevCPUsMemoryInstance Storage (GB)EBS-OptimizedNetwork PerformanceIPv6 Support
Pour les besoins de ce tutoriel, nous voulons simplement sélectionner la seule machine éligible au niveau gratuit. Elle est caractérisée par une petite étiquette verte qui ressemble à ceci :

Une fois que vous avez sélectionné une machine éligible au niveau gratuit, cliquez sur Review and Launch en bas de l'écran pour continuer. L'écran suivant présentera les détails de votre nouvelle instance pour que vous puissiez les examiner. Examinez rapidement les spécifications de la machine, puis cliquez sur Launch dans le coin inférieur droit.
Le fait de cliquer sur le bouton Launch déclenchera une fenêtre contextuelle qui vous demandera de Select an existing key pair or create a new key pair. Une paire de clés est composée d'une clé publique qu'AWS détient et d'une clé privée que vous devez télécharger et stocker dans un fichier .pem. Vous devez avoir accès à ce fichier .pem afin d'accéder à votre instance EC2 (généralement via SSH). Vous avez également la possibilité de continuer sans paire de clés, mais cela n'est pas recommandé pour des raisons de sécurité.
Une fois que vous avez sélectionné ou créé une paire de clés pour cette instance EC2 et que vous avez coché la case I acknowledge that I have access to the selected private key file (data-feeds.pem), and that without this file, I won't be able to log into my instance, vous pouvez cliquer sur Launch Instances pour continuer.
Votre instance va maintenant commencer à se lancer. Cela peut prendre un certain temps pour que ces instances démarrent, mais une fois qu'elle est prête, son Instance State affichera running dans votre tableau de bord EC2.
Ensuite, vous devrez pousser votre script Python dans votre instance EC2. Voici une instruction de commande générique qui vous permet de déplacer un fichier dans une instance EC2 :
scp -i path/to/.pem_file path/to/file username@host_address.amazonaws.com:/path_to_copy
Exécutez cette instruction avec les remplacements nécessaires pour déplacer stock_market_data.py dans l'instance EC2.
Essayer d'exécuter stock_market_data.py à ce stade entraînera en réalité une erreur car l'instance EC2 ne dispose pas des packages Python nécessaires.
Pour corriger cela, vous pouvez soit exporter un fichier requirements.txt et importer les packages appropriés en utilisant pip, soit simplement exécuter ce qui suit :
sudo yum install python3-pip
pip3 install pandas
pip3 install xlsxwriter
Une fois cela fait, vous pouvez vous connecter en SSH à l'instance EC2 et exécuter le script Python à partir de la ligne de commande avec l'instruction suivante :
python3 stock_market_data.py
Étape 4 : Créer un bucket AWS S3 pour stocker le script Python finalisé
Avec le travail que nous avons accompli jusqu'à présent, notre script Python peut être exécuté à l'intérieur de notre instance EC2.
Le problème avec cela est que le fichier xlsx sera sauvegardé sur le serveur virtuel AWS.
Il n'est accessible à personne d'autre que nous sur ce serveur, ce qui limite son utilité.
Pour corriger cela, nous allons créer un bucket public sur AWS S3 où nous pourrons sauvegarder le fichier xlsx. Toute personne disposant de la bonne URL pourra télécharger ce fichier une fois ce changement effectué.
Pour commencer, naviguez vers AWS S3 depuis la console de gestion AWS. Cliquez sur Create bucket en haut à droite :

Sur l'écran suivant, vous devrez choisir un nom pour votre bucket et une région AWS pour que le bucket soit hébergé. Le nom du bucket doit être unique et ne peut pas contenir d'espaces ou de lettres majuscules. La région n'a pas beaucoup d'importance pour les besoins de ce tutoriel, donc j'utiliserai la région par défaut US East (Ohio) us-east-2).
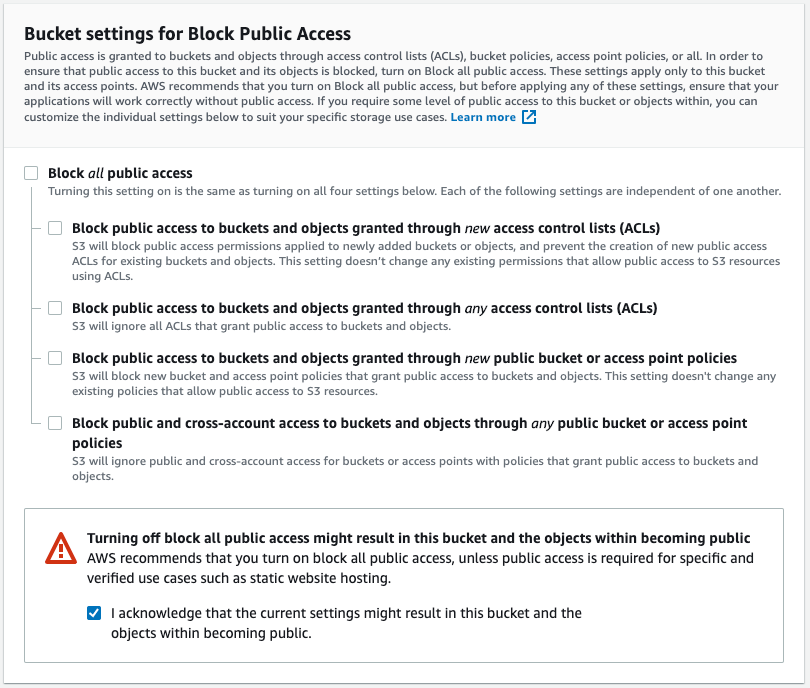
Vous devrez modifier les paramètres d'accès public dans la section suivante pour correspondre à cette configuration :
Cliquez sur Create bucket pour créer votre bucket et conclure cette étape de ce tutoriel !
Étape 5 : Modifier votre script Python pour pousser le fichier xlsx vers AWS S3
Notre bucket AWS S3 est maintenant prêt à contenir notre document xlsx finalisé. Nous allons maintenant apporter une petite modification à notre fichier stock_market_data.py pour pousser le document finalisé vers notre bucket S3.
Nous devrons utiliser le package boto3 pour cela. boto3 est le kit de développement logiciel (SDK) AWS pour Python, permettant aux développeurs Python d'écrire des logiciels qui se connectent aux services AWS. Pour commencer, vous devrez installer boto3 sur votre machine virtuelle EC2. Exécutez l'instruction de ligne de commande suivante pour ce faire :
pip3 install boto3
Vous devrez également importer la bibliothèque dans stock_market_data.py en ajoutant l'instruction suivante en haut du script Python.
import boto3
Nous devrons ajouter quelques lignes de code à la fin de stock_market_data.py pour pousser le document final vers AWS S3.
s3 = boto3.resource('s3')
s3.meta.client.upload_file('stock_market_data.xlsx', 'my-S3-bucket', 'stock_market_data.xlsx', ExtraArgs={'ACL':'public-read'})
La première ligne de ce code, s3 = boto3.resource('s3'), permet à notre script Python de se connecter à Amazon Web Services.
La deuxième ligne de code appelle une méthode de boto3 qui télécharge réellement notre fichier vers S3. Elle prend quatre arguments :
stock_market_data.xlsx- le nom du fichier sur notre machine locale.my-S3-bucket- le nom du bucket S3 dans lequel nous téléchargeons notre fichier.stock_market_data.xlsx- le nom souhaité du fichier dans le bucket S3. Dans la plupart des cas, cela aura la même valeur que le premier argument passé à cette méthode.ExtraArgs={'ACL':'public-read'}- il s'agit d'un argument optionnel qui indique à AWS de rendre le fichier téléchargé accessible au public.
Étape 6 : Planifier l'exécution périodique de votre script Python à l'aide de Cron
Jusqu'à présent, nous avons accompli les étapes suivantes :
- Construit notre script Python
- Créé une instance EC2 et déployé notre code dessus
- Créé un bucket S3 où nous pouvons pousser le document
xlsxfinal - Modifié le script Python original pour télécharger le fichier finalisé
stock_market_data.xlsxvers un bucket AWS S3
La seule étape qui reste est de planifier l'exécution périodique du script Python.
Nous pouvons le faire en utilisant un utilitaire de ligne de commande appelé cron. Pour commencer, nous devrons créer une expression cron qui indique à l'utilitaire quand exécuter le code. Le site crontab guru est une excellente ressource pour cela.
Voici comment vous pouvez utiliser crontab guru pour obtenir une expression cron qui signifie tous les jours à midi :
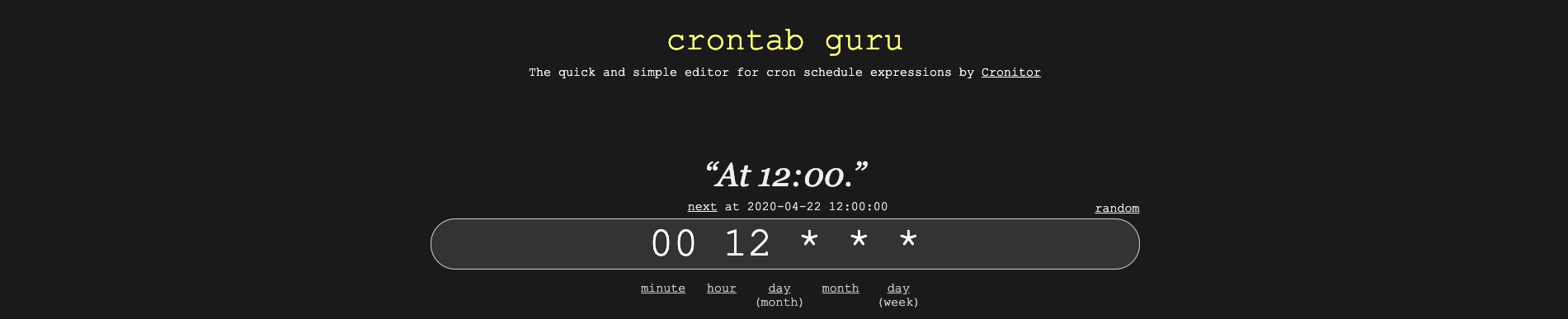
Maintenant, nous devons instruire le démon cron de notre instance EC2 pour exécuter stock_market_data.py à cette heure chaque jour.
Pour ce faire, nous allons d'abord créer un nouveau fichier dans notre instance EC2 appelé stock_market_data.cron.
Ouvrez ce fichier et tapez notre expression cron suivie de l'instruction qui doit être exécutée à la ligne de commande à l'heure spécifiée.
Notre instruction de ligne de commande est python3 stock_market_data.py, donc voici ce qui doit être contenu dans stock_market_data.cron :
00 12 * * * python3 stock_market_data.py
Si vous exécutez une commande ls dans votre instance EC2, vous devriez maintenant voir deux fichiers :
stock_market_data.py stock_market_data.cron
La dernière étape de ce tutoriel consiste à charger stock_market_data.cron dans le crontab. Vous pouvez considérer le crontab comme un fichier qui contient des commandes et des instructions pour que le démon cron les exécute. En d'autres termes, le crontab contient des lots de travaux cron.
Tout d'abord, voyons ce qu'il y a dans notre crontab. Il devrait être vide puisque nous n'y avons rien mis ! Vous pouvez afficher le contenu de votre crontab avec la commande suivante :
crontab -l
Pour charger stock_market_data.cron dans le crontab, exécutez l'instruction suivante sur la ligne de commande :
crontab stock_market_data.cron
Maintenant, lorsque vous exécutez crontab -l, vous devriez voir :
00 12 * * * python3 stock_market_data.py
Notre script stock_market_data.py s'exécutera maintenant tous les jours à midi sur notre machine virtuelle AWS EC2 !
Réflexions finales
Dans cet article, vous avez appris comment créer des feuilles de calcul Excel à mise à jour automatique de données financières en utilisant Python, IEX Cloud et Amazon Web Services.
Voici les étapes spécifiques que nous avons couvertes dans ce tutoriel :
- Comment créer un compte avec IEX Cloud
- Comment écrire un script Python qui génère de beaux documents Excel en utilisant pandas et XlsxWriter
- Comment lancer une instance AWS EC2 et déployer du code dessus
- Comment créer un bucket AWS S3
- Comment pousser des fichiers vers un bucket AWS S3 à partir d'un script Python
- Comment planifier l'exécution de code en utilisant l'utilitaire logiciel
cron
Cet article a été publié par Nick McCullum, qui apprend aux gens à coder sur son site web.