
Article original : How to make Beautiful Ruby Plots with Galaaz
Par Rodrigo Botafogo
Par Rodrigo Botafogo & Daniel Mossé
Selon Wikipedia, « Ruby est un langage de programmation dynamique, interprété, réflexif, orienté objet et généraliste. Il a été conçu et développé au milieu des années 1990 par Yukihiro "Matz" Matsumoto au Japon. » Il a atteint une grande popularité avec le développement de Ruby on Rails (RoR) par David Heinemeier Hansson.
RoR est un framework d'application web sorti pour la première fois vers 2005. Il utilise de manière extensive les fonctionnalités de méta-programmation de Ruby. Avec RoR, Ruby est devenu très populaire. Selon l'index Tiobe de Ruby, il a atteint son pic de popularité vers 2008, puis a décliné jusqu'en 2015, date à laquelle il a commencé à reprendre de l'essor.
Au moment de la rédaction de cet article (novembre 2018), l'index Tiobe place Ruby en 16e position des langages les plus populaires.
Python, un langage similaire à Ruby, se classe 4e dans l'index. Java, C et C++ occupent les trois premières positions. Ruby est souvent critiqué pour son orientation vers les applications web. Mais Ruby peut faire beaucoup plus que des applications web. Pourtant, pour le calcul scientifique, Ruby est loin derrière Python et R. Python dispose du framework Django pour le web, NumPy pour les tableaux numériques et Pandas pour l'analyse de données. R est un environnement logiciel libre pour le calcul statistique et les graphiques avec des milliers de bibliothèques pour l'analyse de données.
Jusqu'à récemment, il n'existait aucun moyen réel pour Ruby de combler cet écart. La mise en œuvre d'une infrastructure complète de calcul scientifique prendrait trop de temps. Voici Oracle's GraalVM :
GraalVM est une machine virtuelle universelle pour exécuter des applications écrites en JavaScript, Python 3, Ruby, R, des langages basés sur la JVM comme Java, Scala, Kotlin, et des langages basés sur LLVM tels que C et C++.
GraalVM supprime l'isolement entre les langages de programmation et permet l'interopérabilité dans un environnement d'exécution partagé. Il peut fonctionner soit de manière autonome, soit dans le contexte d'OpenJDK, Node.js, Oracle Database ou MySQL.
GraalVM vous permet d'écrire des applications polyglottes avec un moyen transparent de passer des valeurs d'un langage à un autre. Avec GraalVM, il n'est pas nécessaire de copier ou de marshaler comme c'est le cas avec d'autres systèmes polyglottes. Cela vous permet d'atteindre des performances élevées lorsque les frontières des langages sont franchies. La plupart du temps, il n'y a aucun coût supplémentaire pour franchir une frontière de langage.
Souvent, les développeurs doivent faire des compromis inconfortables qui les obligent à réécrire leur logiciel dans d'autres langages. Par exemple :
« Cette bibliothèque n'est pas disponible dans mon langage. Je dois la réécrire. »
« Ce langage serait parfait pour mon problème, mais nous ne pouvons pas l'exécuter dans notre environnement. »
« Ce problème est déjà résolu dans mon langage, mais le langage est trop lent. »
Avec GraalVM, nous visons à permettre aux développeurs de choisir librement le bon langage pour la tâche à accomplir sans faire de compromis.
Comme indiqué ci-dessus, GraalVM est une machine virtuelle universelle qui permet à Ruby et R (et à d'autres langages) de s'exécuter dans le même environnement. GraalVM permet aux applications polyglottes d'interagir de manière transparente les unes avec les autres et de passer des valeurs d'un langage à l'autre.
GraalVM est un environnement très puissant. Pourtant, il nécessite encore que les développeurs d'applications connaissent plusieurs langages. Pour éliminer cette exigence, nous avons créé Galaaz, une gem pour Ruby, pour coupler étroitement Ruby et R et permettre à ces langages d'interagir de manière à ce que l'utilisateur ne soit pas conscient de cette interaction. En d'autres termes, un programmeur Ruby pourra utiliser toutes les capacités de R sans connaître la syntaxe de R.
L'encapsulation de bibliothèques est une méthode courante pour apporter des fonctionnalités d'un langage à un autre. Pour améliorer les performances, Python encapsule souvent des bibliothèques C plus efficaces. Pour le développeur Python, l'existence de telles bibliothèques C est cachée. Le problème avec l'encapsulation de bibliothèques est que pour chaque nouvelle bibliothèque, il est nécessaire de créer manuellement un nouveau wrapper, ce qui nécessite un haut niveau d'expertise et de temps.
Galaaz, au lieu d'encapsuler une seule bibliothèque C ou R, encapsule tout le langage R dans Ruby. Ainsi, toutes les milliers de bibliothèques R sont immédiatement disponibles pour les développeurs Ruby sans aucun nouvel effort d'encapsulation.
Pour montrer la puissance de Galaaz, nous montrons dans cet article comment Ruby peut utiliser la bibliothèque ggplot2 de R de manière transparente, apportant à Ruby la puissance de la visualisation scientifique de haute qualité. Nous montrons également que la migration de R vers Ruby avec Galaaz est une question de petits changements syntaxiques. En utilisant Ruby, le développeur R peut utiliser toutes les fonctionnalités puissantes orientées objet de Ruby. De plus, avec Ruby, il devient beaucoup plus facile de passer du code de la phase d'analyse à la phase de production.
Dans cet article, nous allons explorer le jeu de données R ToothGrowth. Pour illustrer, nous allons créer quelques boxplots. Un guide sur les boxplots est disponible dans cet article.
Nous allons également créer un modèle d'entreprise pour garantir que les graphiques auront une visualisation cohérente. Ce modèle est construit en utilisant un module Ruby. Il existe un moyen de construire des thèmes ggplot qui fonctionneront de la même manière que le module Ruby. Pourtant, l'écriture d'un nouveau thème nécessite des connaissances spécifiques sur l'écriture de thèmes. Les modules Ruby sont standard pour le langage et n'ont pas besoin de connaissances spéciales.
Ici, nous montrons un nuage de points en Ruby également avec Galaaz.
gKnit
Knitr est une application qui convertit du texte écrit en rmarkdown vers de nombreux formats de sortie différents. Par exemple, un rédacteur peut convertir un document rmarkdown en HTML, LaTex, docx et de nombreux autres formats.
Les documents Rmarkdown peuvent contenir du texte et des blocs de code. Knitr formate les blocs de code dans une boîte grisée dans le document de sortie. Il exécute également les blocs de code et formate la sortie dans une boîte blanche. Chaque ligne de sortie de l'exécution du code est précédée par '##'.
Knitr permet aux blocs de code d'être en R, Python, Ruby et des dizaines d'autres langages. Pourtant, tandis que les blocs R et Python peuvent partager des données, dans d'autres langages, les blocs sont indépendants. Cela signifie qu'une variable définie dans un bloc ne peut pas être utilisée dans un autre bloc.
Avec gKnit, les blocs de code Ruby peuvent partager des données. Dans gKnit, chaque bloc Ruby s'exécute dans son propre scope et ainsi, les variables locales définies dans un bloc ne sont pas accessibles par d'autres blocs. Pourtant, tous les blocs s'exécutent dans le scope d'une classe 'chunk' et les variables d'instance ('@'), sont disponibles dans tous les blocs.
Exploration du jeu de données
Commençons par explorer notre jeu de données sélectionné. Un jeu de données est comme une simple feuille de calcul Excel, dans laquelle chaque colonne ne contient qu'un seul type de données. Par exemple, une colonne peut contenir des floats, une autre des entiers, et une troisième des chaînes de caractères.
Le jeu de données R ToothGrowth analyse la longueur des odontoblastes (cellules responsables de la croissance des dents) chez 60 cobayes, où chaque animal a reçu l'un des trois niveaux de dose de vitamine C (0,5, 1 et 2 mg/jour) par l'une des deux méthodes d'administration, jus d'orange (OJ) ou acide ascorbique (une forme de vitamine C et codé comme VC).
Le jeu de données ToothGrowth contient trois colonnes : 'len', 'supp' et 'dose'. Jetons un coup d'œil à quelques lignes de ce jeu de données.
Dans Galaaz, les variables R sont accessibles en utilisant le symbole Ruby correspondant précédé de la fonction tilde ('~'). Notez dans le bloc suivant que 'ToothGrowth' est la variable R et que '@tooth_growth' de Ruby est assigné la valeur de '~:ToothGrowth'.
# Lire la variable R ToothGrowth et l'assigner à la# variable d'instance Ruby @tooth_growth qui sera # disponible pour tous les blocs Ruby dans ce document.@tooth_growth = ~:ToothGrowth
# imprimer les premiers éléments du jeu de donnéesputs @tooth_growth.head
## len supp dose## 1 4.2 VC 0.5## 2 11.5 VC 0.5## 3 7.3 VC 0.5## 4 5.8 VC 0.5## 5 6.4 VC 0.5## 6 10.0 VC 0.5
Super ! Nous avons réussi à lire le jeu de données ToothGrowth et à jeter un coup d'œil à ses éléments. Nous voyons ici les six premières lignes du jeu de données. Pour accéder à une colonne, suivez le nom du jeu de données avec un point ('.') et le nom de la colonne. Utilisez également la notation par points pour enchaîner les méthodes dans le style Ruby habituel.
# Accéder à la colonne 'len' de tooth_growth et imprimer les premiers éléments# de cette colonne avec la méthode 'head'.puts @tooth_growth.len.head
## [1] 4.2 11.5 7.3 5.8 6.4 10.0
La colonne 'dose' contient une valeur numérique avec soit 0,5, 1 ou 2, bien que les six premières lignes comme vu ci-dessus ne contiennent que les valeurs 0,5. Même si ce sont des nombres, ils sont mieux interprétés comme un facteur ou catégorie. Donc, convertissons notre colonne 'dose' de numérique en 'facteur'.
En R, la fonction 'as.factor' est utilisée pour convertir les données d'un vecteur en facteurs. Pour utiliser cette fonction à partir de Galaaz, le point ('.') dans le nom de la fonction est remplacé par '' (double soulignement). La fonction 'as.factor' devient 'R.asfactor' ou simplement 'as__factor' lors de l'enchaînement.
# convertir la dose en un facteur@tooth_growth.dose = @tooth_growth.dose.as__factor
Explorons quelques détails supplémentaires de ce jeu de données. En particulier, regardons ses dimensions, sa structure et ses statistiques récapitulatives.
puts @tooth_growth.dim
## [1] 60 3
Ce jeu de données contient 60 lignes, une pour chaque sujet, et 3 colonnes, comme nous l'avons déjà vu.
Notez que nous n'avons pas besoin d'appeler 'puts' lorsque nous utilisons la fonction 'str'. Cette fonction ne retourne rien et imprime la structure du jeu de données comme effet secondaire.
@tooth_growth.str
## 'data.frame': 60 obs. of 3 variables:## $ len : num 4.2 11.5 7.3 5.8 6.4 10 11.2 11.2 5.2 7 ...## $ supp: Factor w/ 2 levels "OJ","VC": 2 2 2 2 2 2 2 2 2 2 ...## $ dose: Factor w/ 3 levels "0.5","1","2": 1 1 1 1 1 1 1 1 1 1 ...
Observez que les deux variables 'supp' et 'dose' sont des facteurs. Le système a automatiquement fait de la variable 'supp' un facteur, puisqu'elle contient deux chaînes de caractères OJ et VC.
Enfin, en utilisant la méthode summary, nous obtenons le résumé statistique pour le jeu de données
puts @tooth_growth.summary
## len supp dose ## Min. : 4.20 OJ:30 0.5:20 ## 1st Qu.:13.07 VC:30 1 :20 ## Median :19.25 2 :20 ## Mean :18.81 ## 3rd Qu.:25.27 ## Max. :33.90
Réalisation de l'analyse des données
Tracé rapide pour visualiser les données
Créons maintenant notre premier tracé avec les données données en accédant à ggplot2 depuis Ruby. Pour les Rubyistes qui n'ont jamais vu ou utilisé ggplot2, voici la description de ggplot trouvée sur sa page d'accueil :
« ggplot2 est un système pour créer des graphiques de manière déclarative, basé sur The Grammar of Graphics. Vous fournissez les données, dites à ggplot2 comment mapper les variables aux esthétiques, quelles primitives graphiques utiliser, et il s'occupe des détails. »
Cette description peut sembler un peu cryptique et il est préférable de la voir en action pour la comprendre. En substance, dans la grammaire des graphiques, les développeurs ajoutent des couches de composants tels que la grille, les axes, les données, le titre, le sous-titre et également des primitives graphiques telles que bar plot, box plot, pour former les graphiques finaux.
Les lecteurs intéressés peuvent consulter les articles suivants sur la grammaire des graphiques sur medium : A Comprehensive Guide to the Grammar of Graphics for Effective Visualization of Multi-dimensional Data et What are the Ingredients of a Terrible Data Story?.
Pour créer un graphique, nous utilisons la fonction 'ggplot' sur le jeu de données. En R, cela s'écrirait ggplot(<dataset>, ...). Galaaz vous offre la flexibilité d'utiliser soit R.ggplot(<dataset>, ...) soit <dataset>.ggplot(...). Dans la spécification du graphique ci-dessous, nous utilisons la deuxième notation qui ressemble davantage à Ruby. Ggplot utilise la méthode 'aes' pour spécifier les axes x et y ; dans ce cas, la 'dose' sur l'axe x et la 'longueur' sur l'axe y : 'E.aes(x: :dose, y: :len)'. Pour spécifier le type de graphique, ajoutez un geom au graphique. Pour un boxplot, le geom est R.geom_boxplot.
Notez également que nous avons un appel à 'R.png' avant le traçage et 'R.devoff' après l'instruction print. 'R.png' ouvre un 'périphérique png' pour la sortie du graphique. Si nous ne passons pas de nom à la fonction 'png', l'image reçoit un nom par défaut de 'Rplot' où est le numéro du graphique. 'R.devoff' ferme le périphérique et crée le fichier 'png'. Nous pouvons ensuite inclure le fichier 'png' généré dans le document en ajoutant une directive rmarkdown.
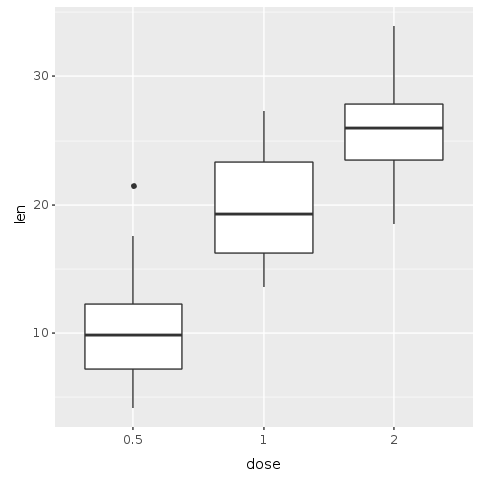
Super ! Nous venons de réussir à créer et sauvegarder notre premier graphique en Ruby avec seulement quatre lignes de code. Nous pouvons maintenant facilement voir avec ce graphique une tendance claire : à mesure que la dose du supplément augmente, la longueur des dents augmente également.
Facettage du graphique
Ce premier graphique montre une tendance, mais nos données contiennent des informations sur deux méthodes d'administration différentes, soit par jus d'orange (OJ) soit par vitamine C (VC). Essayons donc de créer un graphique qui nous aide à discerner l'effet de chaque méthode d'administration.
Le graphique suivant est un graphique facetté où chaque méthode d'administration obtient son propre graphique. Sur le côté gauche, le graphique montre la méthode d'administration OJ. Sur le côté droit, nous voyons la méthode d'administration VC. Pour obtenir ce graphique, nous utilisons la fonction 'R.facet_grid' qui crée automatiquement les facettes en fonction des facteurs de la méthode d'administration. Le paramètre de la méthode 'facet_grid' est une formule.
Dans Galaaz, nous donnons aux programmeurs la flexibilité d'utiliser deux méthodes différentes pour écrire des formules. Dans la première méthode, les changements suivants sont nécessaires pour écrire des formules (par exemple 'x ~ y') en R :
- Les symboles R sont représentés par le même symbole Ruby précédé de la méthode '+'. Le symbole
xen R devient+:xen Ruby ; - L'opérateur '~' en R devient '=~' en Ruby. La formule
x ~ yen R s'écrit+:x =~ +:yen Ruby ; - Le symbole '.' en R devient
+:all
Une autre façon d'écrire une formule est d'utiliser la fonction 'formula' avec la formule réelle sous forme de chaîne. La formule x ~ y en R peut s'écrire R.formula("x ~ y"). Pour les formules plus complexes, l'utilisation de la fonction 'formula' est préférée.
La formule +:all =~ +:supp indique à la fonction 'facet_grid' qu'elle doit facetter le graphique en fonction de la variable supp et diviser le graphique verticalement. En changeant la formule en +:supp =~ +:all, le graphique serait divisé horizontalement.
R.png("figures/facet_by_delivery.png")@base_tooth = @tooth_growth.ggplot(E.aes(x: :dose, y: :len, group: :dose))@bp = @base_tooth + R.geom_boxplot + # Diviser en direction verticale R.facet_grid(+:all =~ +:supp) puts @bpR.dev__off
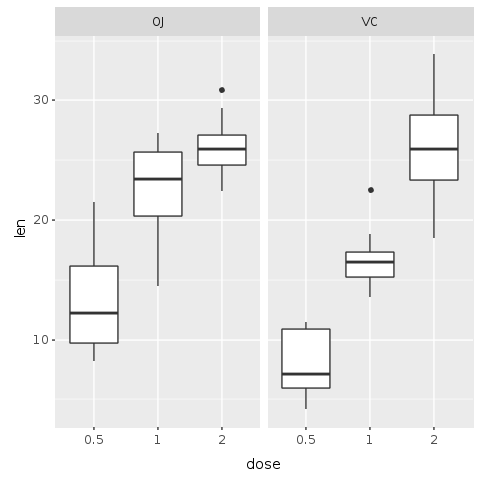
Il devient maintenant clair que, bien que les deux méthodes d'administration aient un impact direct sur la croissance des dents, la méthode OJ est non linéaire, ayant un impact plus élevé avec des doses plus faibles d'acide ascorbique et réduisant son impact à mesure que la dose augmente. Avec l'approche VC, l'impact semble être plus linéaire.
Ajout de couleur
Si nous écrivions sur l'analyse des données, nous ferions une meilleure analyse des tendances et améliorerions l'analyse statistique. Mais ici, nous nous intéressons à travailler avec ggplot en Ruby. Ajoutons donc quelques couleurs à ce graphique pour rendre la tendance et la comparaison plus visibles.
Dans le graphique suivant, les boîtes sont codées par couleur en fonction de la dose. Pour ajouter de la couleur, il suffit d'ajouter fill: :dose à l'esthétique du boxplot. Avec cette commande, chaque facteur 'dose' obtient sa propre couleur.
R.png("figures/facets_by_delivery_color.png")
@bp = @bp + R.geom_boxplot(E.aes(fill: :dose))puts @bp
R.dev__off
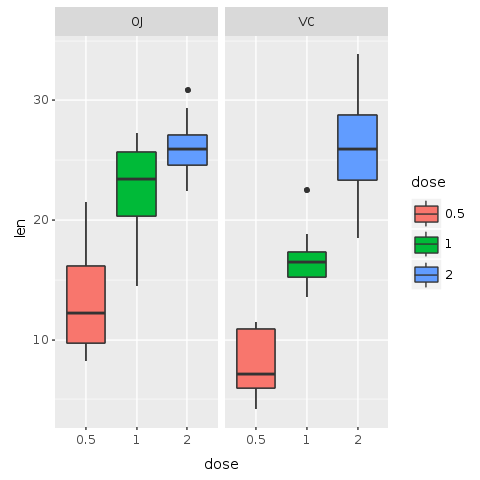
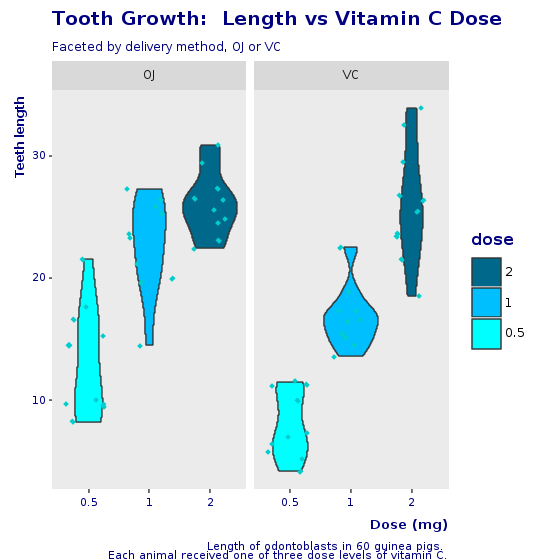
Le facettage nous aide à comparer les tendances générales pour chaque méthode d'administration. L'ajout de couleur nous permet de comparer spécifiquement comment chaque dosage impacte la croissance des dents. Il est possible d'observer qu'avec des doses plus faibles, jusqu'à 1 mg, OJ performe mieux que VC (couleur rouge). Pour 2 mg, OJ et VC ont la même médiane, mais OJ est moins dispersé (couleur bleue). Pour 1 mg (couleur verte), OJ est significativement meilleur que VC. Par cette analyse visuelle très rapide, il semble que OJ soit une meilleure méthode d'administration que VC.
Clarification des données
Les boxplots nous donnent une bonne idée de la distribution des données, mais en regardant ces graphiques avec de grandes boîtes colorées, nous nous demandons ce qui se passe d'autre. Selon Edward Tufte dans Envisioning Information :
Les données minces suscitent à juste titre des soupçons : « Que laissent-ils de côté ? Est-ce vraiment tout ce qu'ils savent ? Que cachent-ils ? Est-ce tout ce qu'ils ont fait ? » De temps en temps, il est affirmé que l'espace vide est « amical » (anthropomorphisant une idée intrinsèquement trouble), mais ce n'est pas la quantité d'espace vide qui compte, mais plutôt comment il est utilisé. Ce n'est pas la quantité d'informations qui compte, mais plutôt comment elles sont organisées de manière efficace.
Et il déclare :
Une stratégie de conception très unconventionnelle est révélée : pour clarifier, ajoutez des détails.
Utilisons cette sagesse et ajoutons une autre couche de données à notre graphique, afin de le clarifier avec des détails et de ne pas laisser de grandes boîtes vides. Dans le graphique suivant, nous ajoutons des points de données pour chacun des 60 cochons d'Inde de l'expérience. Pour cela, ajoutez la fonction 'R.geom_point' au graphique.
R.png("figures/facets_with_points.png")
# Ajouter un point pour chaque sujet@bp = @bp + R.geom_point
puts @bp
R.dev__off
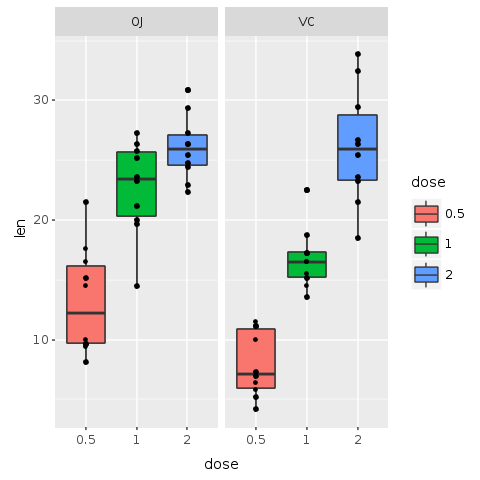
Nous pouvons maintenant voir la distribution réelle de tous les 60 sujets. En fait, ce n'est pas totalement vrai. Nous avons du mal à voir tous les 60 sujets. Il semble que certains points puissent être placés les uns sur les autres, masquant des informations utiles.
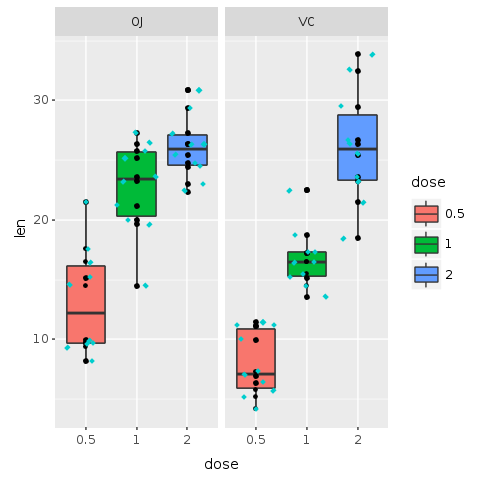
Mais ne vous inquiétez pas ! Une autre couche pourrait résoudre le problème. Dans le graphique suivant, une nouvelle couche appelée 'geom_jitter' est ajoutée au graphique. Jitter ajoute une petite quantité de variation aléatoire à l'emplacement de chaque point, et est un moyen utile de gérer le sur-tracé causé par la discrétion dans les petits jeux de données. Cela facilite la visualisation de tous les points et empêche le masquage des données. Nous ajoutons également de la couleur et changeons la forme des points, les rendant encore plus faciles à voir.
R.png("figures/facets_with_jitter.png")
# Utiliser de petits diamants de couleur bleu clair (cyan3) # pour tracer les sujets de l'expérienceputs @bp + R.geom_jitter(shape: 23, color: "cyan3", size: 1)
R.dev__off
Préparation du graphique pour la présentation
Nous avons parcouru un long chemin depuis notre premier graphique. Comme nous l'avons déjà dit, cet article n'est pas sur l'analyse des données et se concentre sur l'intégration de Ruby et ggplot. Donc, supposons que l'analyse est maintenant terminée. Pourtant, la fin de l'analyse ne signifie pas que le travail est terminé. Au contraire, la partie la plus difficile est encore à venir !
Après l'analyse, il est nécessaire de la communiquer en créant un graphique final pour la présentation. Le dernier graphique contient toutes les informations que nous voulons partager, mais il n'est pas très agréable à l'œil.
Amélioration des couleurs
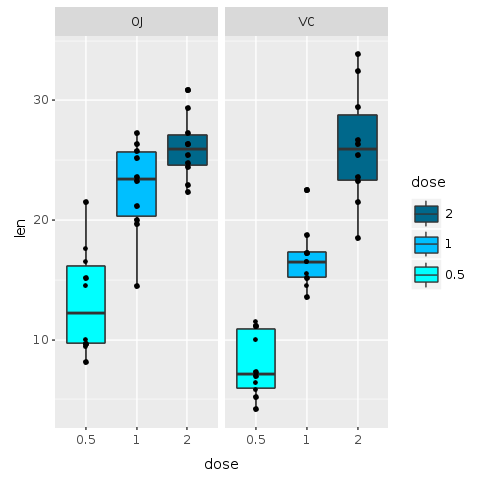
Commençons par essayer d'améliorer les couleurs. Pour l'instant, nous n'utiliserons pas la couche de jitter. Le graphique précédent utilise trois couleurs vives. Y a-t-il une interprétation évidente, ou non évidente d'ailleurs, pour les couleurs ? Clairement, ce sont simplement des couleurs aléatoires sélectionnées automatiquement par notre logiciel. Bien que ces couleurs nous aient aidés à comprendre les données, pour une présentation finale, des couleurs aléatoires peuvent distraire le spectateur.
Dans le graphique suivant, nous utilisons la fonction 'scale_fill_manual' pour changer les couleurs des boîtes et l'ordre des étiquettes. Pour les couleurs, nous utilisons des nuances de bleu pour chaque dosage, avec du bleu clair ('cyan') représentant la dose la plus faible et du bleu profond ('deepskyblue4') la dose la plus élevée.
De plus, la légende pourrait être améliorée : nous utilisons le paramètre 'breaks' pour placer la valeur la plus petite (0,5) en bas des étiquettes et la plus grande (2) en haut. Cet ordre semble plus naturel et correspond à l'ordre réel des couleurs dans le graphique.
R.png("figures/facets_by_delivery_color2.png")
@bp = @bp + R.scale_fill_manual(values: R.c("cyan", "deepskyblue", "deepskyblue4"), breaks: R.c("2","1","0.5"))
puts @bp
R.dev__off
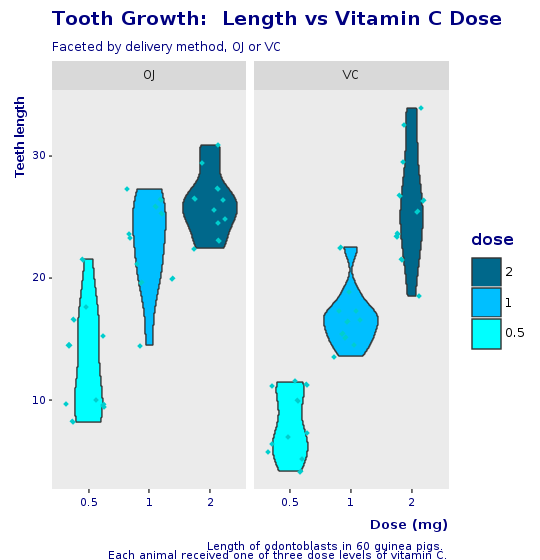
Graphique en violon et jitter
Le boxplot avec jitter semblait un peu écrasant. Le graphique suivant utilise une variation d'un boxplot connue sous le nom de violin plot avec des données en jitter.
Un graphique en violon est une méthode de traçage de données numériques. Il est similaire à un box plot avec un tracé de densité de noyau tourné sur chaque côté.
Un graphique en violon a quatre couches. La forme extérieure représente tous les résultats possibles, avec une épaisseur indiquant la fréquence. (Ainsi, la section la plus épaisse représente la moyenne du mode.) La couche suivante à l'intérieur représente les valeurs qui se produisent 95 % du temps. La couche suivante (si elle existe) à l'intérieur représente les valeurs qui se produisent 50 % du temps. Le point central représente la valeur moyenne médiane.
R.png("figures/violin_with_jitter.png")@violin = @base_tooth + R.geom_violin(E.aes(fill: :dose)) + R.facet_grid(+:all =~ +:supp) + R.geom_jitter(shape: 23, color: "cyan3", size: 1) + R.scale_fill_manual(values: R.c("cyan", "deepskyblue", "deepskyblue4"), breaks: R.c("2","1","0.5"))puts @violinR.dev__off
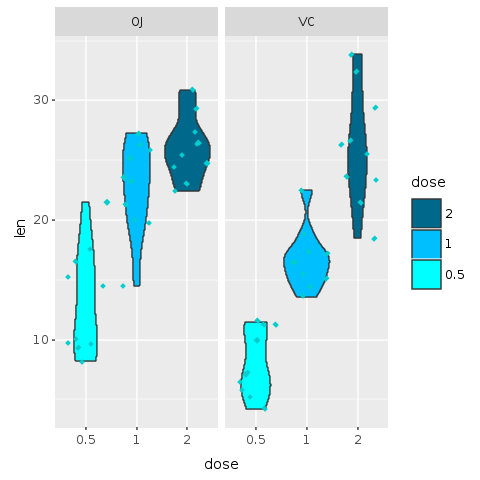
Ce graphique est une alternative au boxplot original. Pour la présentation finale, il est important de réfléchir aux graphiques qui seront les mieux compris par notre public. Un graphique en violon est un graphique moins connu et pourrait ajouter une surcharge mentale, mais, à mon avis, il semble un peu mieux que le boxplot et fournit encore plus d'informations que le boxplot avec jitter.
Ajout de décoration
Notre graphique final commence à prendre forme, mais un graphique de présentation devrait avoir au moins un titre, des étiquettes sur les axes et peut-être quelques autres décorations. Commençons à ajouter celles-ci. Comme la décoration nécessite plus d'espace graphique, ce nouveau graphique a une spécification de 'largeur' et de 'hauteur'. Lorsqu'il n'y a pas de spécification, les valeurs par défaut de R pour la largeur et la hauteur sont de 480 pixels.
La fonction 'labs' ajoute la décoration requise. Dans cet exemple, nous utilisons 'title', 'subtitle', 'x' pour l'étiquette de l'axe x et 'y', pour l'étiquette de l'axe y, et 'caption' pour les informations sur le graphique (pour plus de clarté, nous avons défini une variable de légende en utilisant le style Here Doc de Ruby).
R.png("figures/facets_with_decorations.png", width: 540, height: 560)
caption = <<-EOTLongueur des odontoblastes chez 60 cobayes. Chaque animal a reçu l'un des trois niveaux de dose de vitamine C.EOT
@decorations = R.labs(title: "Croissance des dents : Longueur vs Dose de vitamine C", subtitle: "Facetté par méthode d'administration, OJ ou VC", x: "Dose (mg)", y: "Longueur des dents", caption: caption)
puts @bp + @decorations
R.dev__off
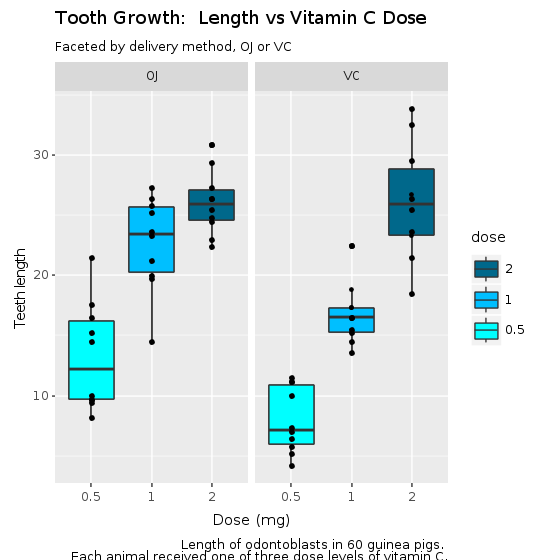
Le thème de l'entreprise
Nous avons presque terminé. Mais la configuration par défaut du graphique n'est pas encore agréable à l'œil. Nous sommes toujours distraits par de nombreux aspects du graphique. Tout d'abord, la couleur de police noire ne semble pas bonne. Ensuite, l'arrière-plan du graphique, les bordures, les grilles ajoutent tous du désordre au graphique.
Nous allons maintenant définir notre thème d'entreprise dans un module qui peut être utilisé/chargé pour tous les graphiques, similaire à CSS ou à toute autre définition de style.
Dans ce thème, nous supprimons les bordures et les grilles. L'arrière-plan est laissé pour les graphiques facettés mais supprimé pour les graphiques non facettés. Les couleurs de police sont une nuance de bleu (couleur : '#00080'). Les étiquettes des axes sont déplacées près de l'extrémité de l'axe et écrites en 'gras'.
module CorpTheme
R.install_and_loads 'RColorBrewer' #----------------------------------------------------------------# face peut être (1=plain, 2=bold, 3=italic, 4=bold-italic)#---------------------------------------------------------------- def self.text_element(size, face: "plain", hjust: nil) E.element_text(color: "#000080", face: face, size: size, hjust: hjust) end #----------------------------------------------------------------# Définit le thème du graphique (visualisation). Dans ce thème, nous # supprimons les grilles majeures et mineures, les bordures et l'arrière-plan. Nous # désactivons également la notation scientifique.#---------------------------------------------------------------- def self.global_theme(faceted = false) # désactiver la notation scientifique comme 1e+48 R.options(scipen: 999) # supprimer les grilles majeures gb = R.theme(panel__grid__major: E.element_blank()) # supprimer les grilles mineures gb = gb + R.theme(panel__grid__minor: E.element_blank) # supprimer la bordure gb = gb + R.theme(panel__border: E.element_blank) # supprimer l'arrière-plan. Lors de la création de graphiques facettés, # l'arrière-plan facilite la visualisation de chaque facette, donc # le laisser gb = gb + R.theme(panel__background: E.element_blank) if !faceted # Changer la police de l'axe gb = gb + R.theme(axis__text: text_element(8)) # changer la police du titre de l'axe gb = gb + R.theme(axis__title: text_element(10, face: "bold", hjust: 1)) # changer la police du titre gb = gb + R.theme(title: text_element(12, face: "bold")) # changer la police du sous-titre gb = gb + R.theme(plot__subtitle: text_element(9)) # changer la police des légendes gb = gb + R.theme(plot__caption: text_element(8))
end end
Box Plot final
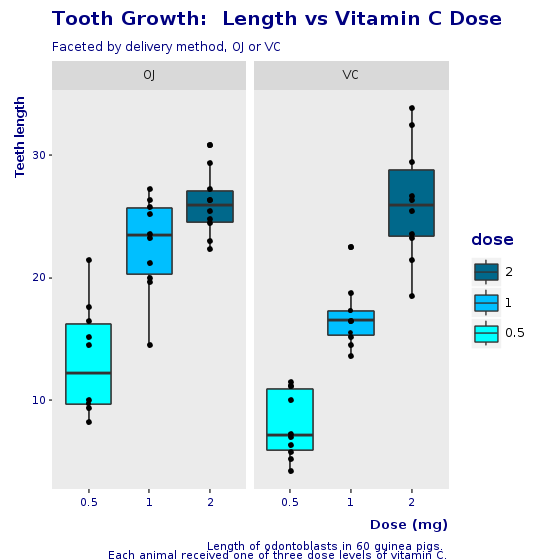
Nous pouvons maintenant facilement créer notre boxplot final et notre graphique en violon. Toutes les couches pour le graphique ont été ajoutées afin d'exposer notre compréhension des données et la nécessité de présenter le résultat à notre public.
La spécification finale est simplement l'addition de toutes les couches construites jusqu'à ce point (@bp), plus les décorations (@decorations), plus le thème de l'entreprise.
Voici notre boxplot final, sans jitter.
R.png("figures/final_box_plot.png", width: 540, height: 560)
puts @bp + @decorations + CorpTheme.global_theme(faceted: true)
R.dev__off
Et voici le graphique en violon final, avec jitter et le même look et feel que le boxplot de l'entreprise.
R.png("figures/final_violin_plot.png", width: 540, height: 560)
puts @violin + @decorations + CorpTheme.global_theme(faceted: true)
R.dev__off
Une autre vue
Nous créons maintenant un autre graphique, avec le même look et feel qu'auparavant mais facetté par dose et non par supplément. Cela montre à quel point il est facile de créer de nouveaux graphiques en changeant simplement de petites déclarations sur la grammaire des graphiques.
R.png("figures/facet_by_dose.png", width: 540, height: 560)
caption = <<-EOTLongueur des odontoblastes chez 60 cobayes. Chaque animal a reçu l'un des trois niveaux de dose de vitamine C.EOT
@bp = @tooth_growth.ggplot(E.aes(x: :supp, y: :len, group: :supp)) + R.geom_boxplot(E.aes(fill: :supp)) + R.facet_grid(+:all =~ +:dose) + R.scale_fill_manual(values: R.c("cyan", "deepskyblue4")) + R.labs(title: "Croissance des dents : Longueur par dose", subtitle: "Facetté par dose", x: "Méthode d'administration", y: "Longueur des dents", caption: caption) + CorpTheme.global_theme(faceted: true)
puts @bp
R.dev__off
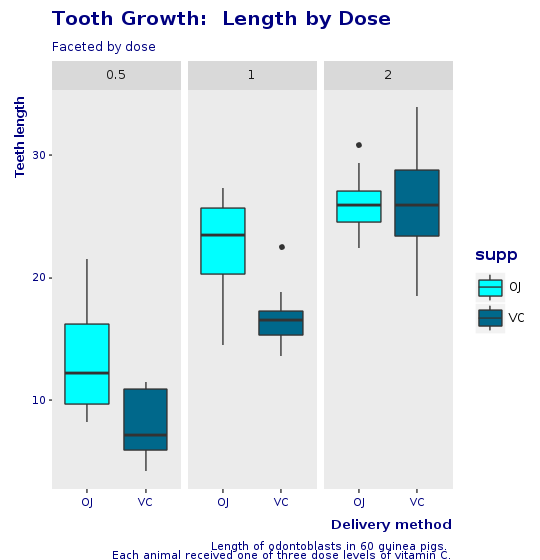
Conclusion
Dans cet article, nous présentons Galaaz et montrons comment coupler étroitement Ruby et R de manière à ce que les développeurs Ruby n'aient pas besoin d'être conscients du moteur R en cours d'exécution. Pour le développeur Ruby, l'existence de R n'a aucune conséquence, il code simplement en Ruby. D'autre part, pour le développeur R, la migration vers Ruby est une question de petits changements syntaxiques avec une courbe d'apprentissage très douce. À mesure que le développeur R devient plus compétent en Ruby, il peut commencer à utiliser des 'classes', des 'modules', des 'procs', des 'lambdas'.
Essayer d'apporter à Ruby la puissance de R en partant de zéro est une entreprise énorme et ne serait probablement jamais accomplie. Les scientifiques des données d'aujourd'hui resteraient certainement avec Python ou R. Maintenant, les communautés Ruby et R peuvent toutes deux bénéficier de ce mariage, fourni par Galaaz sur GraalVM et l'environnement polyglotte de Truffle.
Nous avons développé le couplage de Ruby et R, mais le processus que nous avons utilisé peut également être fait pour coupler Ruby et JavaScript ou Ruby et Python. Dans un monde polyglotte, nous croyons qu'une bibliothèque uniglot pourrait être extrêmement pertinente.
Du point de vue des performances, GraalVM et Truffle promettent des améliorations qui pourraient atteindre plus de 10 fois, à la fois pour FastR et pour TruffleRuby.
Cet article a montré comment améliorer un graphique étape par étape. En partant d'un boxplot très simple avec toutes les configurations par défaut, nous avons progressivement évolué vers notre graphique final. Le point important ici n'est pas de savoir si le graphique final est réellement beau (car la beauté est dans l'œil de celui qui regarde), mais qu'il existe un processus d'améliorations par petites étapes qui peut être suivi pour obtenir un graphique final prêt pour la présentation.
Enfin, cet article entier a été écrit en rmarkdown et compilé en HTML par gknit, une application qui enveloppe knitr et permet de documenter le code Ruby. Cette application peut être d'une grande aide pour tout Rubyiste essayant d'écrire des articles, des blogs ou de la documentation pour Ruby.
Installation de Galaaz
Prérequis
- GraalVM (>= rc8): https://github.com/oracle/graal/releases
- TruffleRuby
- FastR
Les packages R suivants seront installés automatiquement si nécessaire, mais pourraient être installés avant d'utiliser gKnit si souhaité :
- ggplot2
- gridExtra
- knitr
L'installation des packages R nécessite un environnement de développement et peut prendre du temps. Sous Linux, le compilateur gnu et les outils devraient suffire. Je ne suis pas sûr de ce qui est nécessaire sur Mac.
Pour exécuter les 'specs', le package Ruby suivant est nécessaire :
- gem install rspec
Préparation
- gem install galaaz
Utilisation
- gknit
- Dans un script, ajoutez : require 'galaaz'
Exécution des démonstrations
Après l'installation, de nombreuses démonstrations de galaaz sont disponibles en faisant :
> galaaz -T
affichera une liste avec toutes les démonstrations disponibles. Pour exécuter l'une des démonstrations de la liste, remplacez l'appel à 'rake' par 'galaaz'. Par exemple, l'un des exemples de la liste est 'rake sthda:bar'. Pour exécuter cet exemple, faites simplement 'galaaz sthda:bar'. Faire 'galaaz sthda:all' exécutera toutes les démonstrations de la catégorie sthda, dans ce cas, un diaporama avec plus de 80 graphiques ggplot écrits en Ruby.
Certains des exemples nécessitent que 'rspec' soit disponible. Pour installer 'rspec', faites simplement 'gem install rspec'.