


Article original : How to Build a Serverless CRUD REST API with the Serverless Framework, Node.js, and GitHub Actions
L'informatique serverless est apparue comme une réponse aux défis des architectures traditionnelles basées sur des serveurs. Avec le serverless, les développeurs n'ont plus besoin de gérer ou de mettre à l'échelle les serveurs manuellement. Au lieu de cela, les fournisseurs de cloud gèrent l'infrastructure, permettant aux équipes de se concentrer uniquement sur l'écriture et le déploiement du code.
Les solutions serverless s'adaptent automatiquement en fonction de la demande et proposent un modèle de paiement à l'usage. Cela signifie que vous ne payez que pour les ressources que votre application utilise réellement. Cette approche réduit considérablement les frais opérationnels, augmente la flexibilité et accélère les cycles de développement, ce qui en fait une option attrayante pour le développement d'applications modernes.
En faisant abstraction de la gestion des serveurs, les plateformes Serverless vous permettent de vous concentrer sur la logique métier et les fonctionnalités de l'application. Cela conduit à des déploiements plus rapides et à plus d'innovation. Les architectures serverless sont également pilotées par les événements, ce qui signifie qu'elles peuvent répondre automatiquement aux événements en temps réel et s'adapter pour répondre aux demandes des utilisateurs sans intervention manuelle.
Table des matières
Étape 3 : Développer les fonctions Lambda pour les opérations CRUD
Étape 6 : Tester et valider les API Prod et Dev à l'aide de Postman
Avant de plonger dans les détails techniques, nous allons passer en revue quelques concepts de base clés.
Concepts importants à comprendre
Interface de Programmation d'Application (API)
Une Interface de Programmation d'Application (API) permet à différentes applications logicielles de communiquer et d'interagir entre elles. Elle définit les méthodes et les formats de données que les applications peuvent utiliser pour demander et échanger des informations pour l'intégration et le partage de données entre divers systèmes.
Méthodes HTTP
Les méthodes HTTP ou méthodes de requête sont un composant critique des services web et des API. Elles indiquent l'action souhaitée à effectuer sur une ressource dans une URL de requête donnée.
Les méthodes les plus couramment utilisées dans les API RESTful sont :
GET : utilisée pour récupérer des données d'un serveur
POST : envoie des données, incluses dans le corps de la requête, pour créer ou mettre à jour une ressource
PUT : met à jour ou remplace une ressource existante ou crée une nouvelle ressource si elle n'existe pas
DELETE : supprime les données spécifiées du serveur.
Amazon API Gateway
Amazon API Gateway est un service entièrement géré qui permet aux développeurs de créer, publier, maintenir, surveiller et sécuriser facilement des API à n'importe quelle échelle. Il agit comme un point d'entrée pour plusieurs API, gérant et contrôlant les interactions entre les clients (tels que les applications web ou mobiles) et les services backend.
Il fournit également diverses fonctions, notamment le routage des requêtes, la sécurité, l'authentification, la mise en cache et la limitation du débit qui aident à simplifier la gestion et le déploiement des API.
Amazon DynamoDB
DynamoDB est un service de base de données NoSQL entièrement géré conçu pour une évolutivité élevée, une faible latence et la réplication des données sur plusieurs régions.
DynamoDB stocke les données dans un format sans schéma, permettant un stockage et une récupération flexibles et rapides de données structurées et semi-structurées. Il est couramment utilisé pour créer des applications évolutives et réactives dans des environnements basés sur le cloud.
Application CRUD Serverless
Une application CRUD serverless fait référence à la capacité de Créer, Lire (Read), Mettre à jour (Update) et Supprimer (Delete) des données. Mais l'architecture et les composants impliqués diffèrent des applications traditionnelles basées sur des serveurs.
Créer implique l'ajout de nouvelles entrées dans une table DynamoDB. L'opération Lire récupère les données d'une table DynamoDB. Mettre à jour actualise les données existantes dans DynamoDB. Et l'opération Supprimer efface les données de DynamoDB.
Le Serverless Framework
Le Serverless Framework est un outil open-source qui simplifie le déploiement et la gestion des applications serverless sur plusieurs fournisseurs de cloud, y compris AWS. Il fait abstraction de la complexité du provisionnement et de la gestion de l'infrastructure en permettant aux développeurs de définir leur infrastructure en tant que code à l'aide d'un fichier YAML.
Le framework gère le déploiement, la mise à l'échelle et la mise à jour des fonctions serverless, des API et d'autres ressources.
GitHub Actions
GitHub Actions est un puissant outil d'automatisation CI/CD qui permet aux développeurs d'automatiser leurs flux de travail logiciels directement depuis leur dépôt GitHub.
Avec GitHub Actions, vous pouvez créer des pipelines personnalisés déclenchés par des événements tels que des poussées de code (push), des demandes de tirage (pull requests) ou des fusions de branches. Ces flux de travail sont définis dans des fichiers YAML au sein du dépôt et peuvent effectuer des tâches telles que les tests, la construction et le déploiement d'applications dans divers environnements.
Postman
Postman est une plateforme de collaboration populaire qui simplifie le processus de conception, de test et de documentation des API. Il offre une interface conviviale pour que les développeurs puissent créer et envoyer des requêtes HTTP, tester les points de terminaison d'API et automatiser les flux de travail de test.
Très bien, maintenant que vous êtes familiarisé avec les outils et les technologies que nous allons utiliser ici, plongeons dans le vif du sujet.
Prérequis
Node.js et npm installés
AWS CLI configuré avec accès à votre compte AWS
Un compte Serverless Framework
Serverless Framework installé globalement dans votre CLI locale
Notre cas d'utilisation
Voici Alyx, une entrepreneuse qui a récemment découvert l'architecture serverless. Elle a lu comment c'est un moyen puissant et efficace de construire des backends pour les applications web, offrant une approche plus moderne du développement d'applications web.
Elle veut appliquer ce qu'elle a appris jusqu'à présent sur les fondamentaux de l'informatique serverless AWS. Elle sait que serverless ne signifie pas qu'il n'y a pas de serveurs impliqués – cela signifie plutôt que la gestion et le provisionnement des serveurs sont masqués. Et maintenant, elle veut se concentrer uniquement sur l'écriture de code et l'implémentation de la logique métier.
Voyons comment Alyx, propriétaire d'un café prospère, commence à exploiter l'architecture serverless pour le backend de son application web.
Le "Coffee Haven" d'Alyx, un café en ligne, propose une gamme de mélanges de café et de friandises à la vente. Au départ, Alyx gérait les commandes et l'inventaire de la boutique avec des services d'hébergement web et des opérations traditionnels, où elle gérait plusieurs serveurs et ressources. Mais au fur et à mesure que son café gagnait en popularité, elle a commencé à faire face à un nombre croissant de commandes, surtout pendant les heures de pointe et les promotions saisonnières.
Gérer les serveurs et s'assurer que l'application pouvait supporter l'augmentation du trafic est devenu un défi pour Alyx. Elle se retrouvait constamment à s'inquiéter de la capacité des serveurs, de l'évolutivité et du coût de maintenance de l'infrastructure.
Elle souhaitait également introduire de nouvelles fonctionnalités telles que des recommandations personnalisées et des programmes de fidélité, mais cela devenait une tâche ardue compte tenu des limites de sa configuration traditionnelle.
C'est alors qu'Alyx a entendu parler du concept de serverless. Elle a comparé un backend serverless à un barista qui prépare automatiquement le café en temps réel, sans qu'elle ait à se soucier des détails complexes du processus de fabrication du café.
Enthousiasmée par cette idée, Alyx a décidé de migrer le backend de son café vers une plateforme serverless utilisant AWS Lambda, AWS API Gateway et Amazon DynamoDB. Cette configuration lui permettra de se concentrer davantage sur la création de mélanges de café et de friandises parfaits pour ses clients.
Avec le serverless, chaque commande client devient un événement qui déclenche une série de fonctions serverless. Des fonctions AWS Lambda distinctes traitent les commandes et gèrent toute la logique métier en coulisses. Par exemple, elles créent la commande d'un client et sont capables de récupérer cette commande. Elles peuvent également supprimer la commande de quelqu'un ou mettre à jour le statut d'une commande.
Alyx n'a plus besoin de s'inquiéter de la gestion des serveurs, car la plateforme serverless monte et descend automatiquement en charge en fonction des demandes de commandes entrantes. De plus, l'efficacité des coûts du serverless est énorme pour Alyx. Avec un modèle de paiement à l'usage, elle ne paie que pour le temps de calcul réel que ses fonctions consomment, ce qui lui offre une solution plus rentable pour son entreprise en pleine croissance.
Mais elle ne s'arrête pas là ! Elle veut également tout automatiser, du déploiement de l'infrastructure à la mise à jour de son application à chaque changement. En utilisant l'Infrastructure as Code (IaC) avec le Serverless Framework, elle peut définir toute son infrastructure dans le code et la gérer facilement.
En plus de cela, elle configure GitHub Actions pour l'intégration et la livraison continues (CI/CD), de sorte que chaque changement qu'elle effectue soit automatiquement déployé via un pipeline, qu'il s'agisse d'une nouvelle fonctionnalité en développement ou d'un correctif urgent pour la production.
Objectifs du tutoriel
Configurer l'environnement Serverless Framework
Définir une API dans le fichier YAML
Développer des fonctions AWS Lambda pour traiter les opérations CRUD
Configurer des déploiements multi-étapes pour Dev et Prod
Tester les pipelines Dev et Prod
Tester et valider les API Dev et Prod à l'aide de Postman
Comment commencer : Cloner le dépôt Git
Pour améliorer votre compréhension et pour que vous puissiez suivre ce tutoriel plus efficacement, n'hésitez pas à cloner le dépôt du projet depuis mon GitHub. Vous pouvez le faire en allant ici. Au fur et à mesure que nous progressons, n'hésitez pas à modifier les fichiers comme bon vous semble.
Après avoir cloné le dépôt, vous remarquerez la présence de plusieurs fichiers dans votre dossier, comme vous pouvez le voir dans l'image ci-dessous. Nous utiliserons tous ces fichiers pour construire notre API serverless de café.
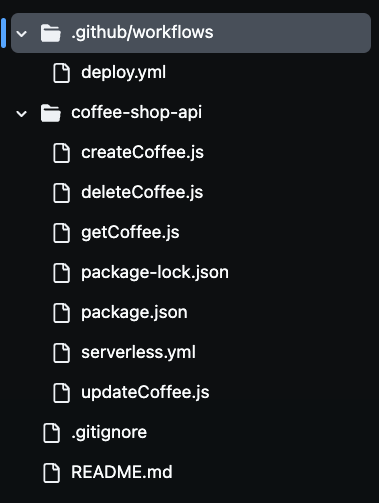
Étape 1 : Configurer l'environnement Serverless Framework
Pour configurer l'environnement Serverless Framework pour les déploiements automatisés, vous devrez authentifier votre compte Serverless Framework via la CLI.
Cela nécessite la création d'une clé d'accès qui active le pipeline CI/CD et utilise le Serverless Framework pour s'authentifier de manière sécurisée sur votre compte sans exposer vos identifiants. En vous connectant à votre compte Serverless et en générant une clé d'accès, le pipeline peut déployer votre application serverless automatiquement à partir du fichier de configuration de build.
Pour ce faire, rendez-vous sur votre compte Serverless et naviguez vers la section Access Keys. Cliquez sur « +add », nommez-la SERVERLESS_ACCESS_KEY, puis créez la clé.
Une fois que vous avez créé votre clé d'accès, assurez-vous de la copier et de la stocker en toute sécurité. Vous utiliserez cette clé comme variable secrète (secret) dans votre dépôt GitHub pour authentifier et autoriser votre pipeline CI/CD.
Elle fournira l'accès à votre compte Serverless Framework pendant le processus de déploiement. Vous ajouterez cette clé aux secrets de votre dépôt GitHub plus tard, afin que votre pipeline puisse l'utiliser en toute sécurité pour déployer les ressources serverless sans exposer d'informations sensibles dans votre codebase.
Maintenant, définissons les ressources AWS en tant que code dans le fichier serverless.yaml.
Étape 2 : Définir l'API dans le fichier YAML Serverless
Dans ce fichier, vous définirez l'infrastructure de base et les fonctionnalités de l'API Coffee Shop en utilisant la configuration YAML du Serverless Framework.
Ce fichier définit les services AWS utilisés, notamment API Gateway, les fonctions Lambda pour les opérations CRUD et DynamoDB pour le stockage des données.
Vous configurerez également un rôle IAM afin que les fonctions Lambda disposent des autorisations nécessaires pour interagir avec le service DynamoDB.
L'API Gateway est configuré avec les méthodes HTTP appropriées (POST, GET, PUT et DELETE) pour gérer les requêtes entrantes et déclencher les fonctions Lambda correspondantes.
Voyons le code :
service: coffee-shop-api
frameworkVersion: '4'
provider:
name: aws
runtime: nodejs20.x
region: us-east-1
stage: ${opt:stage}
iam:
role:
statements:
- Effect: Allow
Action:
- dynamodb:PutItem
- dynamodb:GetItem
- dynamodb:Scan
- dynamodb:UpdateItem
- dynamodb:DeleteItem
Resource: arn:aws:dynamodb:${self:provider.region}:*:table/CoffeeOrders-${self:provider.stage}
functions:
createCoffee:
handler: createCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: post
getCoffee:
handler: getCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: get
updateCoffee:
handler: updateCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: put
deleteCoffee:
handler: deleteCoffee.handler
environment:
COFFEE_ORDERS_TABLE: CoffeeOrders-${self:provider.stage}
events:
- http:
path: coffee
method: delete
resources:
Resources:
CoffeeTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: CoffeeOrders-${self:provider.stage}
AttributeDefinitions:
- AttributeName: OrderId
AttributeType: S
- AttributeName: CustomerName
AttributeType: S
KeySchema:
- AttributeName: OrderId
KeyType: HASH
- AttributeName: CustomerName
KeyType: RANGE
BillingMode: PAY_PER_REQUEST
La configuration serverless.yml définit comment l'API Coffee Shop d'Alyx s'exécutera dans un environnement serverless sur AWS. La section provider spécifie que l'application utilisera AWS comme fournisseur de cloud, avec Node.js comme environnement d'exécution.
La région est définie sur us-east-1 et la variable stage permet un déploiement dynamique sur différents environnements, comme dev et prod. Cela signifie que le même code peut être déployé dans différents environnements, les ressources étant nommées en conséquence pour éviter les conflits.
Dans la section iam, des autorisations sont accordées aux fonctions Lambda pour interagir avec la table DynamoDB. La syntaxe ${self:provider.stage} nomme dynamiquement la table DynamoDB, de sorte que chaque environnement ait ses propres ressources distinctes, comme CoffeeOrders-dev pour l'environnement de développement et CoffeeOrders-prod pour la production. Ce nommage dynamique aide à gérer plusieurs environnements sans configurer manuellement des tables séparées pour chacun.
La section functions définit les quatre fonctions Lambda de base, createCoffee, getCoffee, updateCoffee et deleteCoffee. Celles-ci gèrent les opérations CRUD pour l'API Coffee Shop.
Chaque fonction est connectée à une méthode HTTP spécifique dans l'API Gateway, telle que POST, GET, PUT et DELETE. Ces fonctions interagissent avec la table DynamoDB qui est nommée dynamiquement en fonction de l'étape (stage) actuelle.
La dernière section resources définit la table DynamoDB elle-même. Elle configure la table avec les attributs OrderId et CustomerName, qui sont utilisés comme clé primaire. La table est configurée pour utiliser un mode de facturation au paiement par requête, ce qui la rend rentable pour l'entreprise en croissance d'Alyx.
En automatisant le déploiement de ces ressources à l'aide du Serverless Framework, Alyx peut facilement gérer son infrastructure, se libérant ainsi du fardeau du provisionnement et de la mise à l'échelle manuels des ressources.
Étape 3 : Développer les fonctions Lambda pour les opérations CRUD
Dans cette étape, nous implémentons la logique de base de l'API Coffee Shop d'Alyx en créant des fonctions Lambda avec JavaScript qui effectuent les opérations CRUD essentielles : createCoffee, getCoffee, updateCoffee et deleteCoffee.
Ces fonctions utilisent le SDK AWS pour interagir avec les services AWS, en particulier DynamoDB. Chaque fonction sera responsable de la gestion de requêtes API spécifiques telles que la création d'une commande, la récupération de commandes, la mise à jour des statuts de commande et la suppression de commandes.
Créer la fonction Lambda Coffee
Cette fonction crée une commande :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
const { v4: uuidv4 } = require('uuid');
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const customerName = requestBody.customer_name;
const coffeeBlend = requestBody.coffee_blend;
const orderId = uuidv4();
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Item: {
OrderId: orderId,
CustomerName: customerName,
CoffeeBlend: coffeeBlend,
OrderStatus: 'Pending'
}
};
try {
await dynamoDb.put(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Commande créée avec succès !', OrderId: orderId })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Impossible de créer la commande : ${error.message}` })
};
}
};
Cette fonction Lambda gère la création d'une nouvelle commande de café dans la table DynamoDB. Tout d'abord, nous importons le SDK AWS et initialisons un DynamoDB.DocumentClient pour interagir avec DynamoDB. La bibliothèque uuid est également importée pour générer des identifiants de commande uniques.
À l'intérieur de la fonction handler, nous analysons le corps de la requête entrante pour extraire les informations du client, telles que son nom et son mélange de café préféré. Un orderId unique est généré à l'aide de uuidv4() et ces données sont préparées pour être insérées dans DynamoDB.
L'objet params définit la table où les données seront stockées, avec TableName défini dynamiquement sur la valeur de la variable d'environnement COFFEE_ORDERS_TABLE. La nouvelle commande comprend des champs tels que OrderId, CustomerName, CoffeeBlend et un statut initial de Pending.
Dans le bloc try, le code tente d'ajouter la commande à la table DynamoDB à l'aide de la méthode put(). En cas de succès, la fonction renvoie un code d'état 200 avec un message de succès et l'OrderId. S'il y a une erreur, le code la capture et renvoie un code d'état 500 avec un message d'erreur.
Obtenir la fonction Lambda Coffee
Cette fonction récupère tous les articles de café :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async () => {
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE
};
try {
const result = await dynamoDb.scan(params).promise();
return {
statusCode: 200,
body: JSON.stringify(result.Items)
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Impossible de récupérer les commandes : ${error.message}` })
};
}
};
Cette fonction Lambda est responsable de la récupération de toutes les commandes de café d'une table DynamoDB et illustre une approche serverless pour récupérer des données de DynamoDB de manière évolutive.
Nous utilisons à nouveau le SDK AWS pour initialiser une instance DynamoDB.DocumentClient pour interagir avec DynamoDB. La fonction handler construit l'objet params, spécifiant le TableName, qui est défini dynamiquement à l'aide de la variable d'environnement COFFEE_ORDERS_TABLE.
La méthode scan() récupère tous les éléments de la table. Encore une fois, si l'opération réussit, la fonction renvoie un code d'état 200 ainsi que les éléments récupérés au format JSON. En cas d'erreur, un code d'état 500 et un message d'erreur sont renvoyés.
Mettre à jour la fonction Lambda Coffee
Cette fonction met à jour un article de café par son identifiant :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, new_status, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
},
UpdateExpression: 'SET OrderStatus = :status',
ExpressionAttributeValues: {
':status': new_status
}
};
try {
await dynamoDb.update(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Statut de la commande mis à jour avec succès !', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Impossible de mettre à jour la commande : ${error.message}` })
};
}
};
Cette fonction Lambda gère la mise à jour du statut d'une commande de café spécifique dans la table DynamoDB.
La fonction handler extrait l'order_id, le new_status et le customer_name du corps de la requête. Elle construit ensuite l'objet params pour spécifier le nom de la table et la clé primaire de la commande (en utilisant OrderId et CustomerName). L'UpdateExpression définit le nouveau statut de la commande.
Dans le bloc try, le code tente de mettre à jour la commande dans DynamoDB à l'aide de la méthode update(). Une fois de plus, bien sûr, en cas de succès, la fonction renvoie un code d'état 200 avec un message de succès. Si une erreur survient, elle capture l'erreur et renvoie un code d'état 500 accompagné d'un message d'erreur.
Supprimer la fonction Lambda Coffee
Cette fonction supprime un article de café par son identifiant :
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports.handler = async (event) => {
const requestBody = JSON.parse(event.body);
const { order_id, customer_name } = requestBody;
const params = {
TableName: process.env.COFFEE_ORDERS_TABLE,
Key: {
OrderId: order_id,
CustomerName: customer_name
}
};
try {
await dynamoDb.delete(params).promise();
return {
statusCode: 200,
body: JSON.stringify({ message: 'Commande supprimée avec succès !', OrderId: order_id })
};
} catch (error) {
return {
statusCode: 500,
body: JSON.stringify({ error: `Impossible de supprimer la commande : ${error.message}` })
};
}
};
La fonction Lambda supprime une commande de café spécifique de la table DynamoDB. Dans la fonction handler, le code analyse le corps de la requête pour extraire l'order_id et le customer_name. Ces valeurs sont utilisées comme clé primaire pour identifier l'élément à supprimer de la table. L'objet params spécifie le nom de la table et la clé de l'élément à supprimer.
Dans le bloc try, le code tente de supprimer la commande de DynamoDB à l'aide de la méthode delete(). En cas de succès, il renvoie à nouveau un code d'état 200 avec un message de succès, indiquant que la commande a été supprimée. Si une erreur survient, le code la capture et renvoie un code d'état 500 avec un message d'erreur.
Maintenant que nous avons expliqué chaque fonction Lambda, mettons en place un pipeline CI/CD multi-étapes.
Étape 4 : Configurer le pipeline CI/CD pour des déploiements multi-étapes dans les environnements Dev et Prod
Pour configurer les secrets AWS dans votre dépôt GitHub, commencez par naviguer dans les paramètres du dépôt. Sélectionnez Settings en haut à droite, puis allez en bas à gauche et sélectionnez Secrets and variables.

Ensuite, cliquez sur Actions comme on le voit dans l'image ci-dessous :
De là, sélectionnez New repository secret pour créer des secrets.
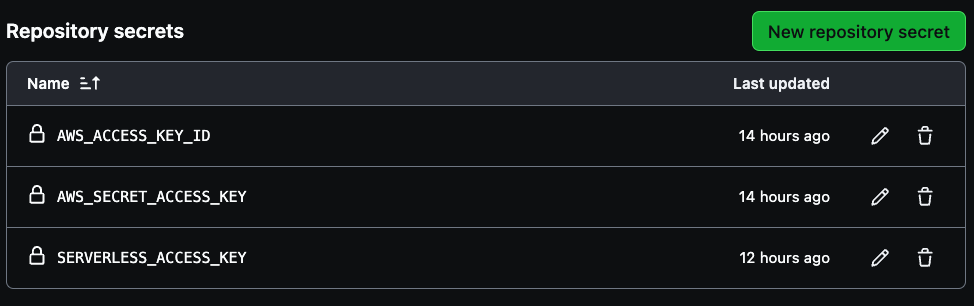
Trois secrets doivent être créés pour votre pipeline : AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY et SERVERLESS_ACCESS_KEY.
Utilisez les identifiants de clé d'accès de votre compte AWS pour les deux premières variables, puis la clé d'accès serverless précédemment enregistrée pour créer la SERVERLESS_ACCESS_KEY. Ces secrets authentifieront de manière sécurisée votre pipeline CI/CD, comme illustré dans l'image ci-dessous.
Assurez-vous que votre branche principale s'appelle « main », car elle servira de branche de production. Ensuite, créez une nouvelle branche appelée « dev » pour le travail de développement.
Vous pouvez également créer des branches spécifiques à des fonctionnalités, telles que « dev/feature », pour un développement plus granulaire. GitHub Actions utilisera ces branches pour déployer automatiquement les modifications, dev représentant l'environnement de développement et main représentant la production.
Cette stratégie de branches vous permet de gérer efficacement le pipeline CI/CD, en déployant de nouveaux changements de code chaque fois qu'il y a une fusion dans les environnements dev ou prod.
Comment utiliser GitHub Actions pour déployer le fichier YAML
Pour automatiser le processus de déploiement de l'API Coffee Shop, vous utiliserez GitHub Actions, qui s'intègre à votre dépôt GitHub.
Ce pipeline de déploiement est déclenché chaque fois que du code est poussé vers les branches main ou dev. En configurant des déploiements spécifiques à l'environnement, vous vous assurerez que les mises à jour de la branche dev sont déployées dans l'environnement de développement, tandis que les modifications de la branche main déclenchent des déploiements en production.
Maintenant, passons en revue le code :
name: deploy-coffee-shop-api
on:
push:
branches:
- main
- dev
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Setup Node.js
uses: actions/setup-node@v3
with:
node-version: '20.x'
- name: Install dependencies
run: |
cd coffee-shop-api
npm install
- name: Install Serverless Framework
run: npm install -g serverless
- name: Deploy to AWS (Dev)
if: github.ref == 'refs/heads/dev'
run: |
cd coffee-shop-api
npx serverless deploy --stage dev
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
- name: Deploy to AWS (Prod)
if: github.ref == 'refs/heads/main'
run: |
cd coffee-shop-api
npx serverless deploy --stage prod
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
SERVERLESS_ACCESS_KEY: ${{secrets.SERVERLESS_ACCESS_KEY}}
La configuration YAML de GitHub Actions est ce qui automatise le processus de déploiement de l'API Coffee Shop sur AWS à l'aide du Serverless Framework. Le workflow se déclenche dès que des modifications sont poussées vers les branches main ou dev.
Il commence par extraire le code du dépôt, puis configure Node.js avec la version 20.x pour correspondre à l'environnement d'exécution utilisé par les fonctions Lambda. Ensuite, il installe les dépendances du projet en naviguant dans le répertoire coffee-shop-api et en exécutant npm install.
Le workflow installe également le Serverless Framework globalement, permettant d'utiliser la CLI serverless pour les déploiements. Selon la branche mise à jour, le workflow déploie conditionnellement dans l'environnement approprié.
Si les modifications sont poussées vers la branche dev, il déploie vers l'étape dev. Si elles sont poussées vers la branche main, il déploie vers l'étape prod. Les commandes de déploiement, npx serverless deploy --stage dev ou npx serverless deploy --stage prod, sont exécutées dans le répertoire coffee-shop-api.
Pour un déploiement sécurisé, le workflow accède aux identifiants AWS et à la clé d'accès Serverless via des variables d'environnement stockées dans les GitHub Secrets. Cela permet au pipeline CI/CD de s'authentifier auprès d'AWS et du Serverless Framework sans exposer d'informations sensibles dans le dépôt.
Maintenant, nous pouvons procéder au test du pipeline.
Étape 5 : Tester les pipelines Dev et Prod
Tout d'abord, vous devrez vérifier que la branche principale (prod) s'appelle « main ». Ensuite, créez une branche de développement appelée « dev ». Une fois que vous avez effectué des modifications valides sur la branche dev, committez-les pour déclencher le pipeline GitHub Actions. Cela déploiera automatiquement les ressources mises à jour dans l'environnement de développement. Après avoir tout vérifié en dev, vous pouvez alors fusionner la branche dev dans la branche main.
La fusion des modifications dans la branche main déclenche également automatiquement le pipeline de déploiement pour l'environnement de production. De cette façon, toutes les mises à jour nécessaires sont appliquées et les ressources de production sont déployées de manière transparente.
Vous pouvez surveiller le processus de déploiement et consulter les journaux détaillés de chaque exécution de GitHub Actions en naviguant vers l'onglet Actions de votre dépôt GitHub.
Les journaux offrent une visibilité sur chaque étape du pipeline, vous aidant à vérifier que tout fonctionne comme prévu.
Vous pouvez sélectionner n'importe quelle exécution de build pour consulter les journaux détaillés des déploiements des environnements de développement et de production afin de suivre la progression et de vous assurer que tout se passe bien.
Naviguez vers l'exécution de build spécifique dans GitHub Actions, comme illustré dans l'image ci-dessous. Là, vous pouvez visualiser les détails de l'exécution et les résultats pour les pipelines de développement ou de production.
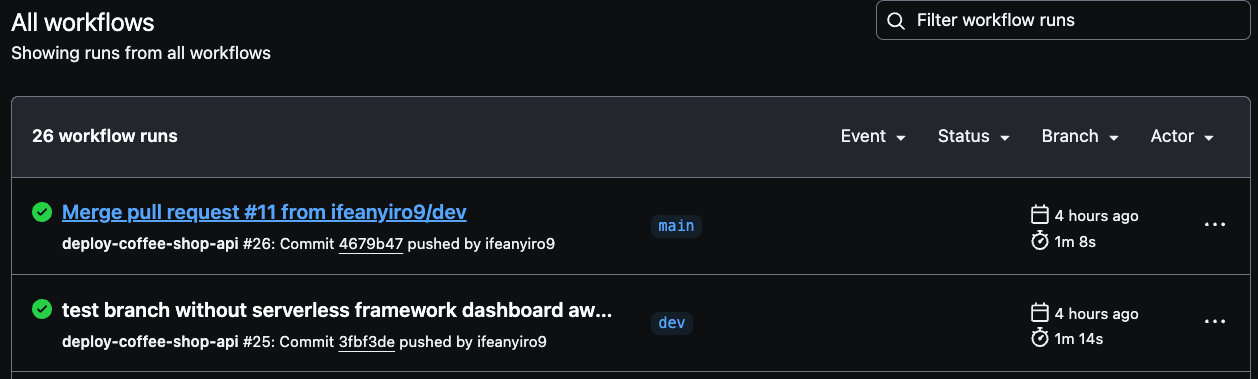
Assurez-vous de tester minutieusement les environnements de développement et de production pour confirmer le succès de l'exécution du pipeline.
Étape 6 : Tester et valider les API Prod et Dev à l'aide de Postman
Maintenant que les API et les ressources sont déployées et configurées, nous devons localiser les points de terminaison (URL) d'API uniques générés par AWS pour commencer à effectuer des requêtes afin de tester les fonctionnalités.
Ces URL peuvent tester les fonctionnalités de l'API en les collant simplement dans un navigateur web. Les URL de l'API se trouvent dans les résultats de sortie de votre build CI/CD.
Pour les récupérer, accédez aux journaux GitHub Actions, sélectionnez la construction réussie de l'environnement le plus récent et cliquez sur deploy pour vérifier les détails du déploiement pour les points de terminaison d'API générés.
Cliquez sur l'étape Deploy to AWS pour l'environnement sélectionné (Prod ou Dev) dans vos journaux GitHub Actions. Une fois là-bas, vous trouverez l'URL de l'API générée.
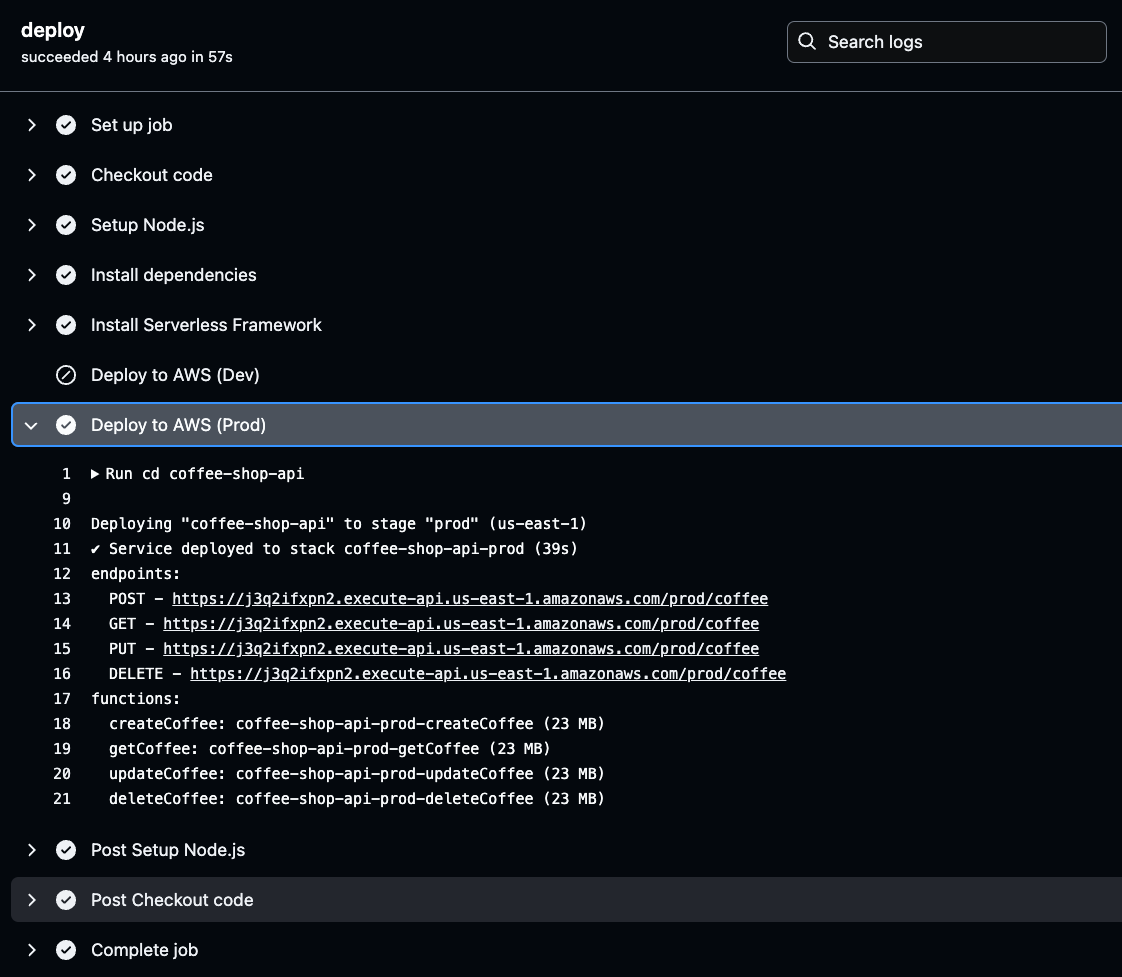
Copiez et enregistrez cette URL, car elle sera nécessaire lors du test des fonctionnalités de votre API. Cette URL est votre passerelle pour vérifier que l'API déployée fonctionne comme prévu.
Maintenant, copiez l'une des URL d'API générées et collez-la dans votre navigateur. Vous verrez un tableau vide ou une liste affichée dans la réponse. Cela confirme en fait que l'API fonctionne correctement et que vous parvenez à récupérer des données de la table DynamoDB.
Même si la liste est vide, cela indique que l'API peut se connecter à la base de données et renvoyer des informations.
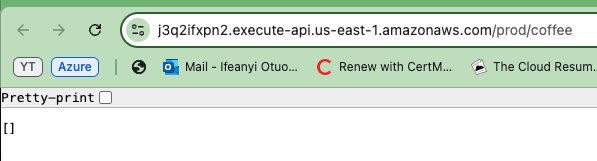
Pour vérifier que votre API fonctionne sur les deux environnements, répétez les étapes pour l'autre environnement d'API (Prod et Dev).
Pour des tests plus complets, nous utiliserons Postman pour tester toutes les méthodes de l'API, Créer, Lire, Mettre à jour et Supprimer, et effectuerons ces tests pour les environnements de développement et de production.
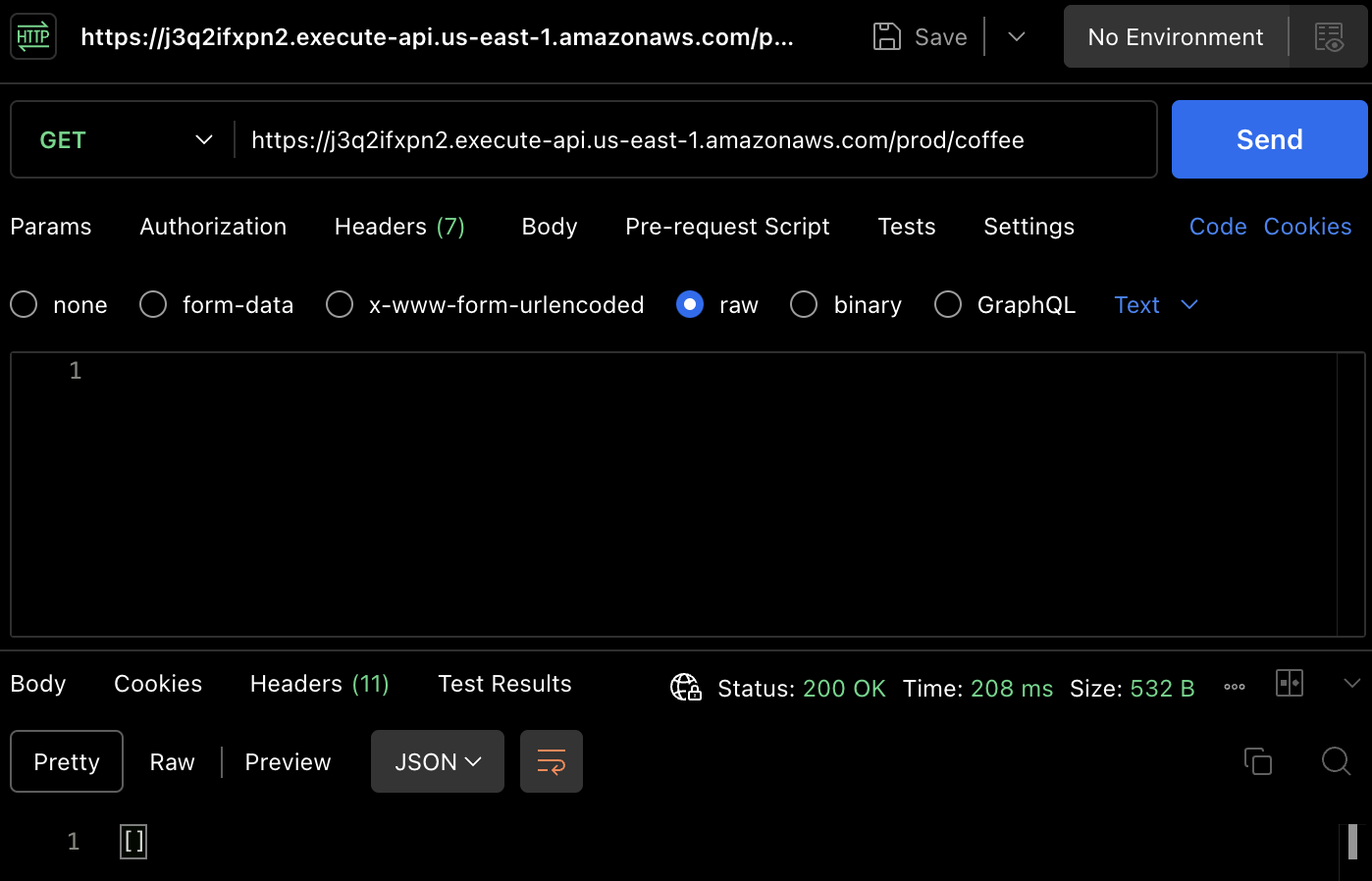
Pour tester la méthode GET, utilisez Postman pour envoyer une requête GET au point de terminaison de l'API à l'aide de l'URL. Vous recevrez la même réponse, une liste vide de commandes de café comme on le voit en bas de l'image ci-dessous. Cela confirme la capacité de l'API à récupérer des données avec succès, comme illustré dans l'image ci-dessous.
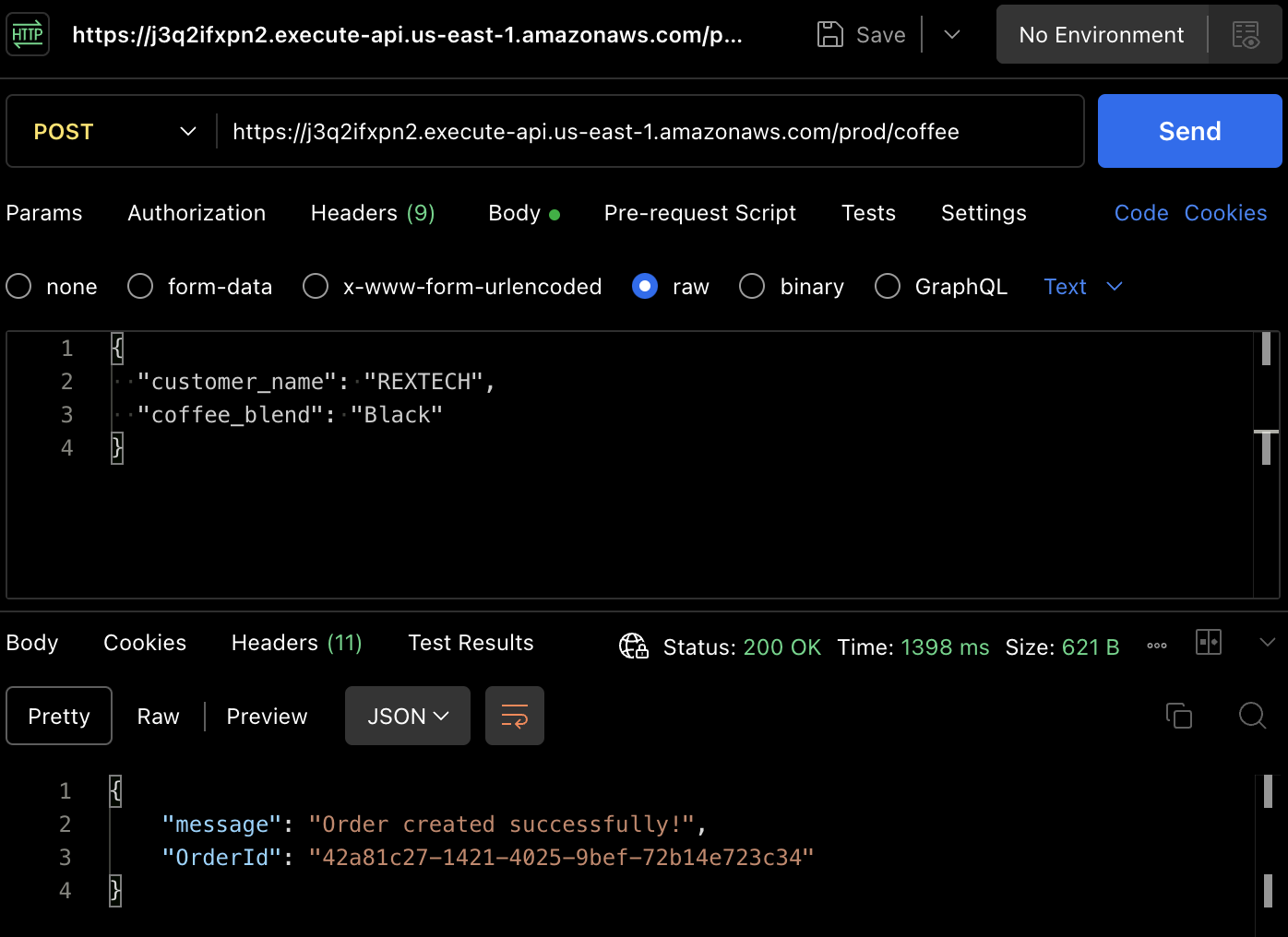
Pour créer réellement une commande, testons la méthode POST. Utilisez à nouveau Postman pour effectuer une requête POST vers le point de terminaison de l'API, en fournissant le nom du client et le mélange de café dans le corps de la requête, comme indiqué ci-dessous :
{
"customer_name": "REXTECH",
"coffee_blend": "Black"
}
La réponse sera un message de succès avec un OrderId unique pour la commande passée.
Vérifiez que la nouvelle commande a été enregistrée dans la table DynamoDB en examinant les éléments dans la table spécifique à l'environnement :

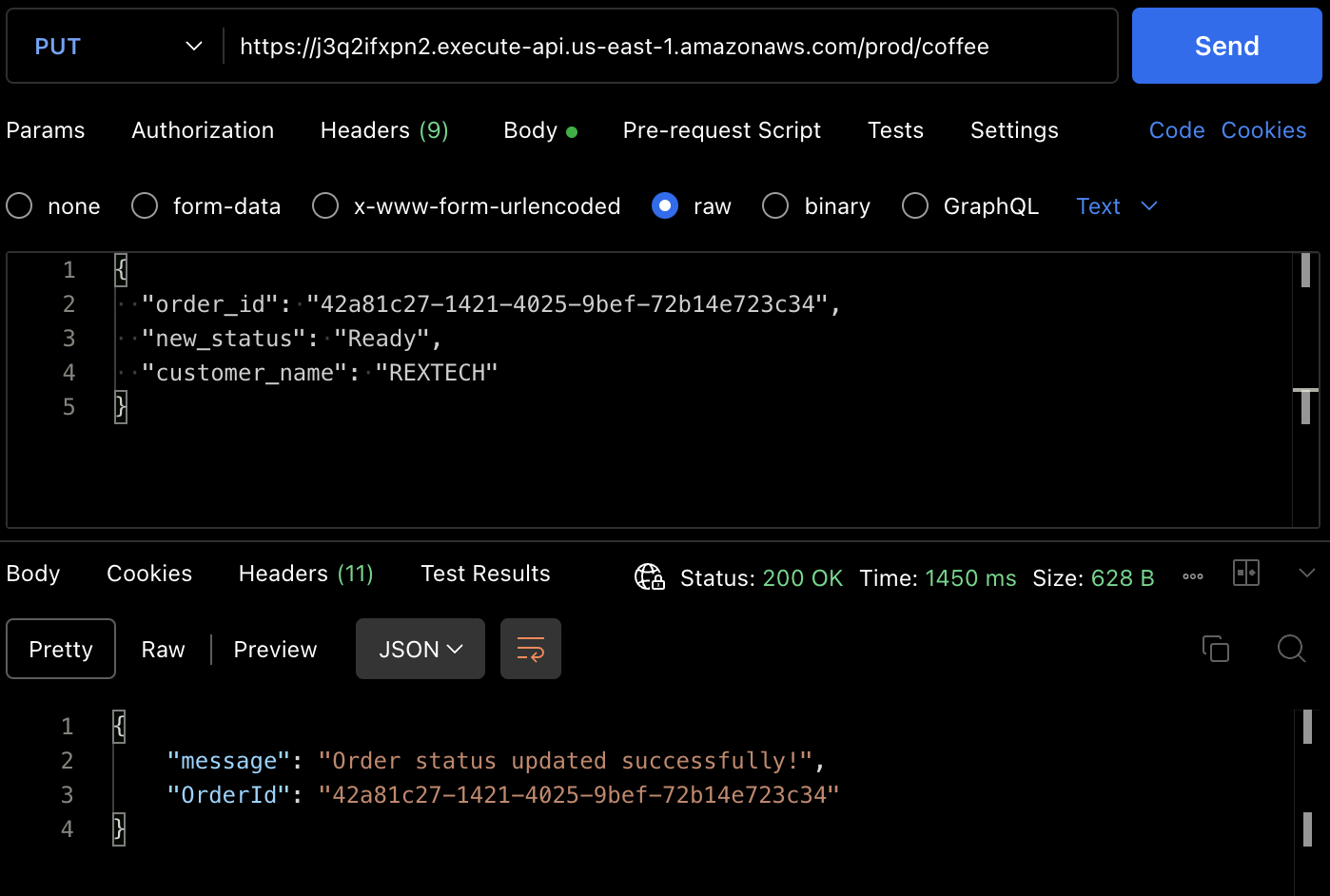
Pour tester la méthode PUT, effectuez une requête PUT vers le point de terminaison de l'API en fournissant l'identifiant de commande précédent et un nouveau statut de commande dans le corps de la requête comme indiqué ci-dessous :
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"new_status": "Ready",
"customer_name": "REXTECH"
}
La réponse sera un message de mise à jour de commande réussie avec l'OrderId de la commande passée.
Vous pouvez également vérifier que le statut de la commande a été mis à jour à partir de l'élément de la table DynamoDB.

Pour tester la méthode DELETE, à l'aide de Postman, effectuez une requête DELETE en fournissant l'identifiant de commande précédent et le nom du client dans le corps de la requête comme indiqué ci-dessous :
{
"order_id": "42a81c27-1421-4025-9bef-72b14e723c34",
"customer_name": "REXTECH"
}
La réponse sera un message de commande supprimée avec succès avec l'identifiant de commande de la commande passée.
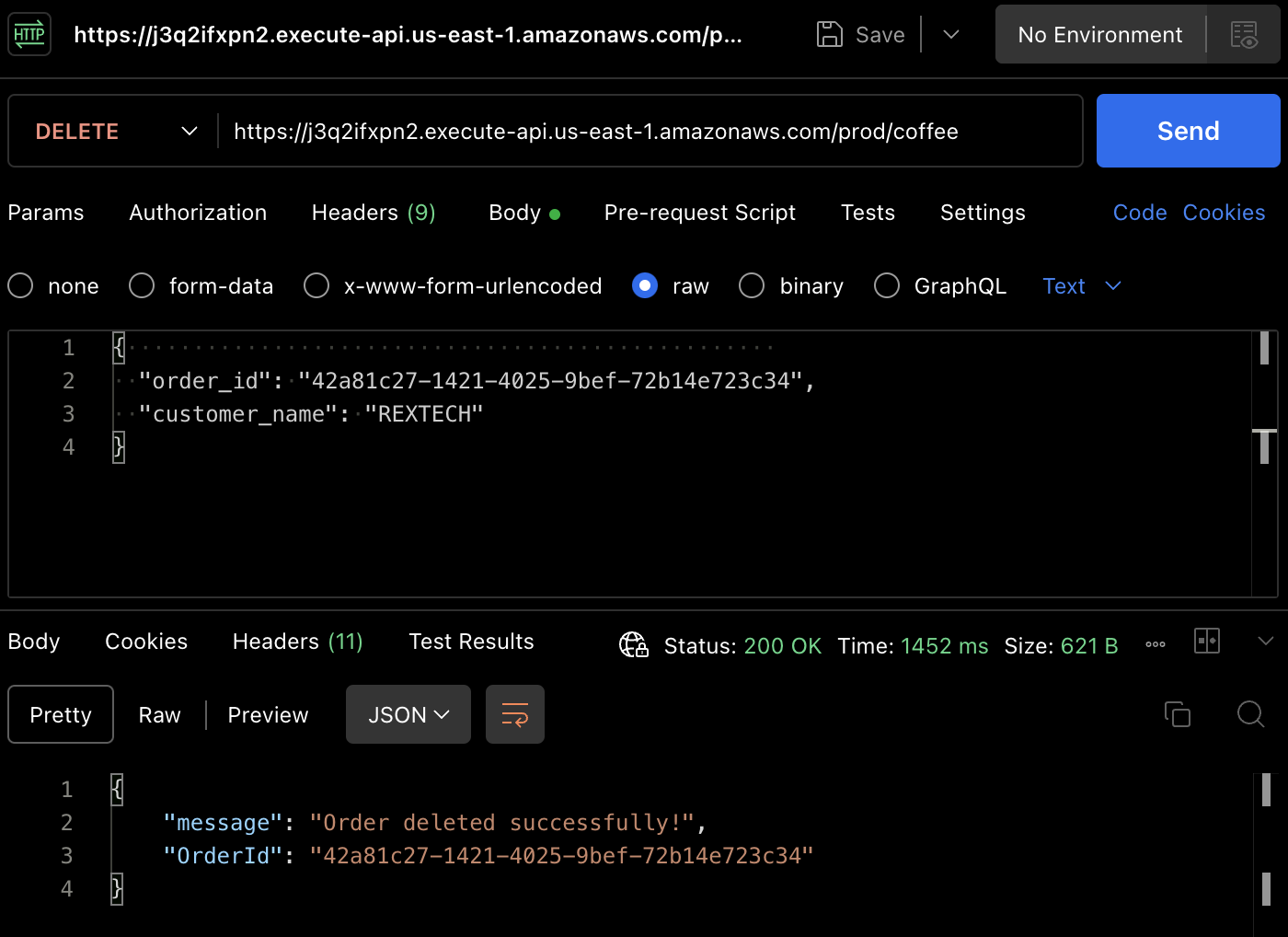
À nouveau, vous pouvez vérifier que la commande a été supprimée dans la table DynamoDB.

Conclusion
C'est tout – félicitations ! Vous avez terminé avec succès toutes les étapes. Nous avons construit une API REST serverless qui prend en charge les fonctionnalités CRUD (Créer, Lire, Mettre à jour, Supprimer) avec API Gateway, Lambda, DynamoDB, Serverless Framework et Node.js, en automatisant le déploiement des modifications de code approuvées avec GitHub Actions.
Si vous êtes arrivé jusqu'ici, merci de m'avoir lu ! J'espère que cela vous a été utile.
Ifeanyi Otuonye est un ingénieur cloud certifié AWS (6X) spécialisé en DevOps, en rédaction technique et en enseignement technique en tant qu'instructeur. Il est motivé par son désir d'apprendre et de se développer et s'épanouit dans des environnements collaboratifs. Avant de passer au Cloud, il a passé six ans en tant qu'athlète professionnel d'athlétisme.
Début 2022, il s'est stratégiquement lancé dans une mission pour devenir ingénieur Cloud/DevOps par l'auto-apprentissage et en rejoignant un programme Cloud accéléré de 6 mois.
En mai 2023, il a accompli cet objectif et a décroché son premier poste d'ingénieur Cloud et s'est maintenant fixé une autre mission personnelle : accompagner d'autres personnes dans leur voyage vers le Cloud.