

Article original : How to Build a Simple Image Recognition System with TensorFlow (Part 2)
Par Wolfgang Beyer
Il s'agit de la deuxième partie de mon introduction à la construction d'un système de reconnaissance d'images avec TensorFlow. Dans la première partie, nous avons construit un classificateur softmax pour étiqueter des images du jeu de données CIFAR-10. Nous avons atteint une précision d'environ 25–30 %. Puisqu'il y a 10 catégories différentes et également probables, en étiquetant les images de manière aléatoire, nous obtiendrions une précision de 10 %. Nous sommes donc déjà bien meilleurs que le hasard, mais il reste encore beaucoup de place pour l'amélioration.
Dans cet article, je vais décrire comment construire un réseau de neurones qui effectue la même tâche. Voyons de combien nous pouvons augmenter notre précision de prédiction !
Réseaux de neurones
Les réseaux de neurones sont très vaguement basés sur le fonctionnement des cerveaux biologiques. Ils se composent d'un certain nombre de neurones artificiels, chacun traitant plusieurs signaux entrants et retournant un seul signal de sortie. Le signal de sortie peut ensuite être utilisé comme signal d'entrée pour d'autres neurones.
Examinons un neurone individuel :
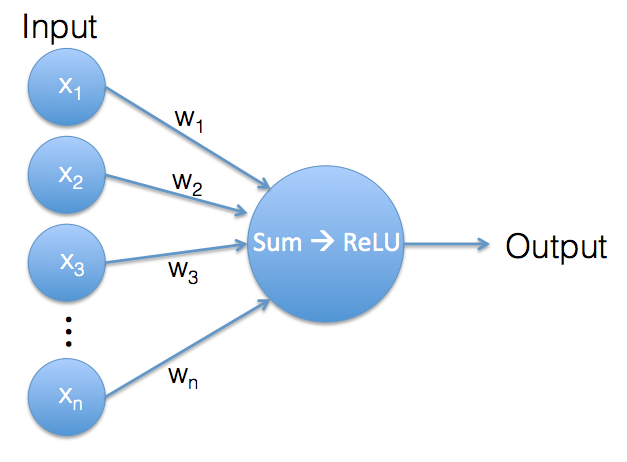 Un neurone artificiel. Sa sortie est le résultat de la fonction ReLU d'une somme pondérée de ses entrées.
Un neurone artificiel. Sa sortie est le résultat de la fonction ReLU d'une somme pondérée de ses entrées.
Ce qui se passe dans un seul neurone est très similaire à ce qui se passe dans le classificateur softmax. Nous avons à nouveau un vecteur de valeurs d'entrée et un vecteur de poids. Les poids sont les paramètres internes du neurone. Le vecteur d'entrée et le vecteur de poids contiennent le même nombre de valeurs, donc nous pouvons les utiliser pour calculer une somme pondérée.
![]()
Jusqu'à présent, nous effectuons exactement le même calcul que dans le classificateur softmax, mais voici un petit changement : tant que le résultat de la somme pondérée est une valeur positive, la sortie du neurone est cette valeur. Mais si la somme pondérée est une valeur négative, nous ignorons cette valeur négative et le neurone génère une sortie de 0 à la place. Cette opération est appelée Rectified Linear Unit (ReLU).
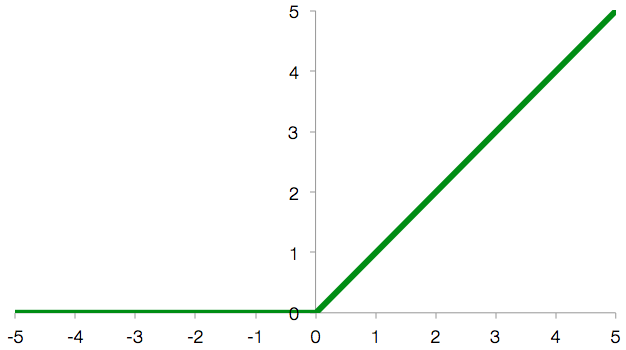 Rectified Linear Unit, qui est définie par f(x) = max(0, x)
Rectified Linear Unit, qui est définie par f(x) = max(0, x)
La raison d'utiliser une ReLU est que cela crée une non-linéarité. La sortie du neurone n'est plus strictement une combinaison linéaire (= somme pondérée) de ses entrées. Nous verrons pourquoi cela est utile lorsque nous cesserons de regarder les neurones individuels et que nous regarderons plutôt le réseau dans son ensemble.
Les neurones dans les réseaux de neurones artificiels ne sont généralement pas connectés de manière aléatoire les uns aux autres. La plupart du temps, ils sont disposés en couches :
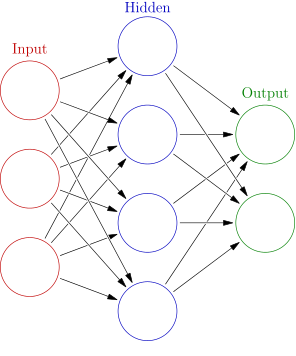 _Un réseau de neurones artificiels avec 2 couches, une couche cachée et une couche de sortie. L'entrée n'est pas considérée comme une couche, car elle alimente simplement les données (sans les transformer) à la première couche proprement dite.
_Un réseau de neurones artificiels avec 2 couches, une couche cachée et une couche de sortie. L'entrée n'est pas considérée comme une couche, car elle alimente simplement les données (sans les transformer) à la première couche proprement dite.
(L'image fait partie des [Wikimedia Commons](https://commons.wikimedia.org/wiki/Main_Page" rel="noopener" target="_blank" title=""> et a été prise de <a href="https://commons.wikimedia.org/wiki/File:Colored_neural_network.svg" rel="noopener" target="blank" title="))
Les valeurs des pixels de l'image d'entrée sont les entrées de la première couche de neurones du réseau. La sortie des neurones de la couche 1 est l'entrée des neurones de la couche 2 et ainsi de suite. C'est la raison pour laquelle avoir une non-linéarité est si important. Sans la ReLU à chaque couche, nous n'aurions qu'une séquence de sommes pondérées. Et les sommes pondérées empilées peuvent être fusionnées en une seule somme pondérée, donc les multiples couches ne nous donneraient aucune amélioration par rapport à un réseau à une seule couche. L'introduction de la non-linéarité ReLU résout ce problème car chaque couche supplémentaire ajoute vraiment quelque chose au réseau.
La sortie de la couche finale du réseau sont les valeurs qui nous intéressent, les scores pour les catégories d'images. Dans cette architecture de réseau, chaque neurone est connecté à tous les neurones de la couche précédente, donc ce type de réseau est appelé un réseau entièrement connecté. Comme nous le verrons dans la partie 3 de ce tutoriel, ce n'est pas nécessairement toujours le cas.
Et c'est déjà la fin de ma très brève partie sur la théorie des réseaux de neurones. Commençons à en construire un !
Le code
Le code complet pour cet exemple est disponible sur Github. Il nécessite TensorFlow et le jeu de données CIFAR-10 (voir Partie 1 pour savoir comment installer les prérequis).
Si vous avez suivi mon précédent article de blog, vous verrez que le code pour le classificateur de réseau de neurones est assez similaire au code pour le classificateur softmax. Mais en plus de remplacer la partie du code qui définit le modèle, j'ai ajouté quelques petites fonctionnalités pour montrer certaines des choses que TensorFlow peut faire :
- Régularisation : il s'agit d'une technique très courante pour prévenir le surapprentissage d'un modèle. Elle fonctionne en appliquant une force contraire pendant le processus d'optimisation qui vise à garder le modèle simple.
- Visualisation du modèle avec TensorBoard : TensorBoard est inclus avec TensorFlow et vous permet de générer des graphiques à partir de vos modèles et des données générées par vos modèles. Cela aide à analyser vos modèles et est particulièrement utile pour le débogage.
- Points de contrôle : cette fonctionnalité vous permet de sauvegarder l'état actuel de votre modèle pour une utilisation ultérieure. L'entraînement d'un modèle peut prendre un certain temps, il est donc essentiel de ne pas avoir à recommencer de zéro chaque fois que vous souhaitez l'utiliser.
Le code est divisé en deux fichiers cette fois : il y a two_layer_fc.py, qui définit le modèle, et run_fc_model.py, qui exécute le modèle (au cas où vous vous poseriez la question : 'fc' signifie fully connected).
Réseau de neurones entièrement connecté à 2 couches
Regardons d'abord le modèle lui-même et traitons son exécution et son entraînement plus tard. two_layer_fc.py contient les fonctions suivantes :
inference()nous permet de passer des données d'entrée aux scores de classe.loss()calcule la valeur de perte à partir des scores de classe.training()effectue une seule étape d'entraînement.evaluation()calcule la précision du réseau.
Génération des scores de classe : inference()
inference() décrit le passage avant à travers le réseau. Comment les scores de classe sont-ils calculés, à partir des images d'entrée ?
Le paramètre images est le placeholder TensorFlow contenant les données d'image réelles. Les trois paramètres suivants décrivent la forme/taille du réseau. image_pixels est le nombre de pixels par image d'entrée, classes est le nombre de différentes étiquettes de sortie et hidden_units est le nombre de neurones dans la première/couche cachée de notre réseau.
Chaque neurone prend toutes les valeurs de la couche précédente comme entrée et génère une seule valeur de sortie. Chaque neurone de la couche cachée a donc image_pixels entrées et la couche dans son ensemble génère hidden_units sorties. Celles-ci sont ensuite alimentées dans les neurones classes de la couche de sortie qui génèrent classes valeurs de sortie, un score par classe.
reg_constant est la constante de régularisation. TensorFlow nous permet d'ajouter facilement de la régularisation à notre réseau en gérant la plupart des calculs automatiquement. J'entrerai dans un peu plus de détails lorsque nous arriverons à la fonction de perte.
Puisque notre réseau de neurones a 2 couches similaires, nous allons définir une portée séparée pour chacune. Cela nous permet de réutiliser les noms de variables dans chaque portée. La variable biases est définie de la manière que nous connaissons déjà, en utilisant tf.Variable().
La définition de la variable weights est un peu plus complexe. Nous utilisons tf.get_variable(), qui nous permet d'ajouter de la régularisation. weights est une matrice avec des dimensions de image_pixels par hidden_units (taille du vecteur d'entrée x taille du vecteur de sortie). Le paramètre initializer décrit les valeurs initiales de la variable weight.
Jusqu'à présent, nous avons initialisé nos variables à 0, mais cela ne fonctionnerait pas ici. Pensez aux neurones d'une seule couche. Ils reçoivent tous exactement les mêmes valeurs d'entrée. S'ils avaient tous les mêmes paramètres internes, ils effectueraient tous le même calcul et sortiraient tous la même valeur. Pour éviter cela, nous devons randomiser leurs poids initiaux. Nous utilisons un schéma d'initialisation qui fonctionne généralement bien, les poids sont initialisés à des valeurs normalement distribuées. Nous abandonnons les valeurs qui sont à plus de 2 écarts-types de la moyenne, et l'écart-type est défini comme l'inverse de la racine carrée du nombre de pixels d'entrée. Heureusement, TensorFlow gère tous ces détails pour nous, nous devons simplement spécifier que nous voulons utiliser un truncated_normal_initializer qui fait exactement ce que nous voulons.
Le paramètre final pour la variable weights est le regularizer. À ce stade, tout ce que nous avons à faire est de dire à TensorFlow que nous voulons utiliser la régularisation L2 pour la variable weights. Je couvrirai la régularisation ici.
Pour créer la sortie de la première couche, nous multiplions la matrice images et la matrice weights l'une avec l'autre et ajoutons la variable bias. C'est exactement la même chose que dans le classificateur softmax de l'article de blog précédent. Ensuite, nous appliquons tf.nn.relu(), la fonction ReLU pour arriver à la sortie de la couche cachée.
La couche 2 est très similaire à la couche 1. Le nombre d'entrées est hidden_units, le nombre de sorties est classes. Par conséquent, les dimensions de la matrice weights sont [hidden_units, classes]. Puisque c'est la couche finale de notre réseau, il n'y a plus besoin d'une ReLU. Nous arrivons aux scores de classe (logits) en multipliant l'entrée (hidden) et weights l'un avec l'autre et en ajoutant bias.
L'opération de résumé tf.histogram_summary() nous permet d'enregistrer la valeur de la variable logits pour une analyse ultérieure avec TensorBoard. Je couvrirai cela plus tard.
Pour résumer, la fonction inference() dans son ensemble prend des images d'entrée et retourne des scores de classe. C'est tout ce qu'un classificateur entraîné doit faire, mais pour arriver à un classificateur entraîné, nous devons d'abord mesurer à quel point ces scores de classe sont bons. C'est le travail de la fonction de perte.
Calcul de la perte : loss()
Tout d'abord, nous calculons l'entropie croisée entre logits (la sortie du modèle) et labels (les étiquettes correctes du jeu de données d'entraînement). Cela a été notre fonction de perte complète pour le classificateur softmax, mais cette fois nous voulons utiliser la régularisation, donc nous devons ajouter un autre terme à notre perte.
Faisons d'abord un pas en arrière et regardons ce que nous voulons atteindre en utilisant la régularisation.
Surapprentissage et régularisation
Lorsque un modèle statistique capture le bruit aléatoire dans les données sur lesquelles il a été entraîné au lieu de la véritable relation sous-jacente, cela s'appelle le surapprentissage.
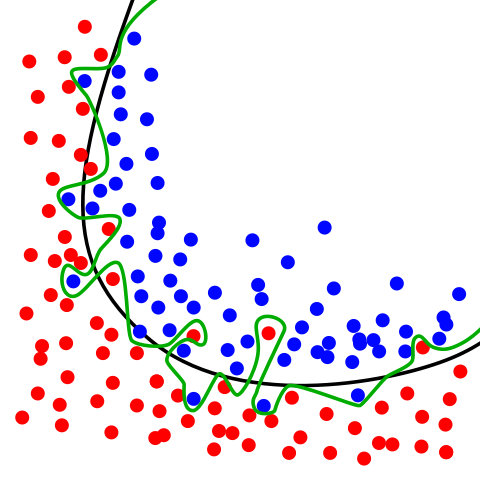 _Les cercles rouges et bleus représentent deux classes différentes. La ligne verte représente un modèle surapprenti tandis que la ligne noire représente un modèle bien ajusté.
_Les cercles rouges et bleus représentent deux classes différentes. La ligne verte représente un modèle surapprenti tandis que la ligne noire représente un modèle bien ajusté.
(L'image fait partie des [Wikimedia Commons](https://commons.wikimedia.org/wiki/Main_Page" rel="noopener" target="_blank" title=""> et a été prise de <a href="https://en.wikipedia.org/wiki/File:Overfitting.svg" rel="noopener" target="blank" title="))
Dans l'image ci-dessus, il y a deux classes différentes, représentées par les cercles bleus et rouges. La ligne verte est un classificateur surapprenti. Il suit parfaitement les données d'entraînement, mais il est également fortement dépendant de celles-ci et est susceptible de gérer les données invisibles pire que la ligne noire, qui représente un modèle régularisé.
Notre objectif pour la régularisation est donc d'arriver à un modèle simple sans complications inutiles. Il existe différentes façons d'y parvenir, et l'option que nous choisissons s'appelle la régularisation L2. La régularisation L2 ajoute la somme des carrés de tous les poids du réseau à la fonction de perte. Cela correspond à une lourde pénalité si le modèle utilise de grands poids et à une petite pénalité si le modèle utilise de petits poids.
C'est pourquoi nous avons utilisé le paramètre regularizer lors de la définition des poids et assigné un l2_regularizer à celui-ci. Cela indique à TensorFlow de garder une trace des termes de régularisation L2 (et de les pondérer par le paramètre reg_constant) pour cette variable. Tous les termes de régularisation sont ajoutés à une collection appelée tf.GraphKeys.REGULARIZATION_LOSSES, à laquelle la fonction de perte accède. Nous ajoutons ensuite la somme de toutes les pertes de régularisation à l'entropie croisée précédemment calculée pour obtenir la perte totale de notre modèle.
Optimisation des variables : training()
global_step est une variable scalaire qui garde une trace du nombre d'itérations d'entraînement déjà effectuées. Lorsque nous exécutons le modèle de manière répétée dans notre boucle d'entraînement, nous connaissons déjà cette valeur. C'est la variable d'itération de la boucle. La raison pour laquelle nous ajoutons cette valeur directement au graphe TensorFlow est que nous voulons pouvoir prendre des instantanés du modèle. Et ces instantanés doivent inclure des informations sur le nombre d'étapes d'entraînement déjà effectuées.
La définition de l'optimiseur de descente de gradient est simple. Nous fournissons le taux d'apprentissage et indiquons à l'optimiseur quelle variable il doit minimiser. En outre, l'optimiseur incrémente automatiquement le paramètre global_step à chaque itération.
Mesure de la performance : evaluation()
Le calcul de la précision du modèle est le même que dans le cas du softmax : nous comparons les prédictions du modèle avec les vraies étiquettes et calculons la fréquence à laquelle la prédiction est correcte. Nous sommes également intéressés par l'évolution de la précision au fil du temps, nous ajoutons donc une opération de résumé qui suit la valeur de accuracy. Nous couvrirons cela dans la section sur TensorBoard.
Pour résumer ce que nous avons fait jusqu'à présent, nous avons défini le comportement d'un réseau de neurones artificiels à 2 couches en utilisant 4 fonctions : inference() constitue le passage avant à travers le réseau et retourne les scores de classe. loss() compare les scores de classe prédits et réels et génère une valeur de perte. training() effectue une étape d'entraînement et optimise les paramètres internes du modèle et evaluation() mesure la performance de notre modèle.
Exécution du réseau de neurones
Maintenant que le réseau de neurones est défini, voyons comment run_fc_model.py exécute, entraîne et évalue le modèle.
Après les imports obligatoires, nous définissons les paramètres du modèle comme des drapeaux externes. TensorFlow a son propre module pour les paramètres de ligne de commande, qui est un wrapper mince autour de l'argparse de Python. Nous l'utilisons ici pour des raisons de commodité, mais vous pouvez tout aussi bien utiliser argparse directement.
Dans les premières lignes, les différents paramètres de ligne de commande sont définis. Les paramètres pour chaque drapeau sont le nom du drapeau, sa valeur par défaut et une courte description. L'exécution du fichier avec le drapeau -h affiche ces descriptions.
Le deuxième bloc de lignes appelle la fonction qui analyse réellement les paramètres de ligne de commande. Ensuite, les valeurs de tous les paramètres sont imprimées à l'écran.
Ici, nous définissons des constantes pour le nombre de pixels par image (32 x 32 x 3) et le nombre de catégories d'images différentes. Ensuite, nous commençons à mesurer le temps d'exécution en créant un minuteur.
Nous voulons enregistrer certaines informations sur le processus d'entraînement et utiliser TensorBoard pour afficher ces informations. TensorBoard nécessite que les journaux pour chaque exécution soient dans un répertoire séparé, nous ajoutons donc des informations de date et d'heure au nom du répertoire de journalisation.
load_data() charge les données CIFAR-10 et retourne un dictionnaire contenant des jeux de données d'entraînement et de test séparés.
Génération du graphe TensorFlow
Nous définissons des placeholders TensorFlow. Lors de l'exécution des calculs réels, ceux-ci seront remplis avec des données d'entraînement/test.
Le images_placeholder a des dimensions de taille de lot x pixels par image. Une taille de lot de 'None' nous permet d'exécuter le graphe avec différentes tailles de lot (la taille de lot pour l'entraînement du réseau peut être définie via un paramètre de ligne de commande, mais pour le test, nous passons l'ensemble du jeu de test en un seul lot).
Le labels_placeholder est un vecteur de valeurs entières contenant l'étiquette de classe correcte, une par image dans le lot.
Ici, nous référençons les fonctions que nous avons couvertes précédemment dans two_layer_fc.py.
inference()nous permet de passer des données d'entrée aux scores de classe.loss()calcule une valeur de perte à partir des scores de classe.training()effectue une seule étape d'entraînement.evaluation()calcule la précision du réseau.
Définir une opération de résumé pour TensorBoard (couvert ici).
Génère un objet saver pour sauvegarder l'état du modèle aux points de contrôle (couvert ici).
Nous démarrons la session TensorFlow et initialisons immédiatement toutes les variables. Ensuite, nous créons un écrivain de résumé que nous utiliserons pour sauvegarder périodiquement les informations de journalisation sur le disque.
Ces lignes sont responsables de la génération de lots de données d'entrée. Supposons que nous avons 100 images d'entraînement et une taille de lot de 10. Dans l'exemple softmax, nous avons simplement choisi 10 images aléatoires pour chaque itération. Cela signifie qu'après 10 itérations, chaque image aura été choisie une fois en moyenne (!). Mais en fait, certaines images auront été choisies plusieurs fois tandis que certaines images n'auront fait partie d'aucun lot jusqu'à présent. Tant que vous répétez cela suffisamment souvent, ce n'est pas si terrible que le hasard cause certaines images à faire partie des lots d'entraînement un peu plus souvent que d'autres.
Mais cette fois, nous voulons améliorer le processus d'échantillonnage. Ce que nous faisons, c'est que nous mélangeons d'abord les 100 images du jeu de données d'entraînement. Les 10 premières images des données mélangées sont notre premier lot, les 10 images suivantes sont notre deuxième lot et ainsi de suite. Après 10 lots, nous sommes à la fin de notre jeu de données et le processus recommence. Nous mélangeons à nouveau les données et les parcourons de l'avant vers l'arrière. Cela garantit qu'aucune image n'est choisie plus souvent qu'une autre tout en assurant que l'ordre dans lequel les images sont retournées est aléatoire.
Pour y parvenir, la fonction gen_batch() dans data_helpers() retourne un générateur Python, qui retourne le lot suivant chaque fois qu'il est évalué. Les détails de fonctionnement des générateurs sont hors du cadre de cet article (une bonne explication peut être trouvée ici). Nous utilisons la fonction intégrée zip() de Python pour générer une liste de tuples de la forme [(image1, label1), (image2, label2), ...], qui est ensuite passée à notre fonction générateur.
next(batches) retourne le lot suivant de données. Puisqu'il est encore sous la forme [(imageA, labelA), (imageB, labelB), ...], nous devons d'abord le dézipper pour séparer les images des étiquettes, avant de remplir feed_dict, le dictionnaire contenant les placeholders TensorFlow, avec un seul lot de données d'entraînement.
Toutes les 100 itérations, la précision actuelle du modèle est évaluée et imprimée à l'écran. En outre, l'opération summary est exécutée et ses résultats sont ajoutés à summary_writer qui est responsable de l'écriture des résumés sur le disque. De là, ils peuvent être lus et affichés par TensorBoard (voir cette section).
Cette ligne exécute l'opération train_step (définie précédemment pour appeler two_layer_fc.training(), qui contient les instructions réelles pour l'optimisation des variables).
Lorsque l'entraînement d'un modèle prend une période de temps plus longue, il existe un moyen facile de sauvegarder un instantané de votre progression. Cela vous permet de revenir plus tard et de restaurer le modèle dans exactement le même état. Tout ce que vous avez à faire est de créer un objet tf.train.Saver (nous l'avons fait plus tôt) et ensuite d'appeler sa méthode save() chaque fois que vous voulez prendre un instantané.
Restaurer un modèle est tout aussi facile, il suffit d'appeler la méthode restore() du sauvegardeur. Il y a un exemple de code fonctionnel montrant comment faire cela dans le fichier [restore_model.py](https://github.com/wolfib/image-classification-CIFAR10-tf/blob/master/restore_model.py) dans le dépôt github.
Après la fin de l'entraînement, le modèle final est évalué sur le jeu de test (rappelons que le jeu de test contient des données que le modèle n'a pas encore vues, ce qui nous permet de juger à quel point le modèle est capable de généraliser à de nouvelles données).
Résultats
Exécutons le modèle avec les paramètres par défaut via « python run_fc_model.py ». Ma sortie ressemble à ceci :
Paramètres : batch_size = 400 hidden1 = 120 learning_rate = 0.001 max_steps = 2000 reg_constant = 0.1 train_dir = tf_logs
Étape 0, précision d'entraînement 0.09 Étape 100, précision d'entraînement 0.2675 Étape 200, précision d'entraînement 0.3925 Étape 300, précision d'entraînement 0.41 Étape 400, précision d'entraînement 0.4075 Étape 500, précision d'entraînement 0.44 Étape 600, précision d'entraînement 0.455 Étape 700, précision d'entraînement 0.44 Étape 800, précision d'entraînement 0.48 Étape 900, précision d'entraînement 0.51 Point de contrôle sauvegardé Étape 1000, précision d'entraînement 0.4425 Étape 1100, précision d'entraînement 0.5075 Étape 1200, précision d'entraînement 0.4925 Étape 1300, précision d'entraînement 0.5025 Étape 1400, précision d'entraînement 0.5775 Étape 1500, précision d'entraînement 0.515 Étape 1600, précision d'entraînement 0.4925 Étape 1700, précision d'entraînement 0.56 Étape 1800, précision d'entraînement 0.5375 Étape 1900, précision d'entraînement 0.51 Point de contrôle sauvegardé Précision de test 0.4633 Temps total : 97.54s
Nous pouvons voir que la précision d'entraînement commence à un niveau que nous attendrions d'une devinette aléatoire (10 classes -> 10 % de chances de choisir la bonne). Au cours des 1000 premières itérations environ, la précision augmente jusqu'à environ 50 % et fluctue autour de cette valeur pour les 1000 itérations suivantes. La précision de test de 46 % n'est pas beaucoup plus faible que la précision d'entraînement. Cela indique que notre modèle n'est pas significativement surapprenti. La performance du classificateur softmax était d'environ 30 %, donc 46 % est une amélioration d'environ 50 %. Pas mal !
Visualisation avec TensorBoard
TensorBoard vous permet de visualiser différents aspects de vos graphes TensorFlow et est très utile pour le débogage et l'amélioration de vos réseaux. Regardons les lignes de code liées à TensorBoard réparties dans la base de code.
Dans two_layer_fc.py, nous trouvons ce qui suit :
Chacune de ces trois lignes crée une opération de résumé. En définissant une opération de résumé, vous indiquez à TensorFlow que vous êtes intéressé à collecter des informations de résumé à partir de certains tenseurs (logits, loss et accuracy dans notre cas). L'autre paramètre pour l'opération de résumé est simplement une étiquette que vous souhaitez attacher au résumé.
Il existe différents types d'opérations de résumé. Nous utilisons scalar_summary pour enregistrer des informations sur les valeurs scalaires (non vectorielles) et histogram_summary pour collecter des informations sur une distribution de plusieurs valeurs (plus d'informations sur les différentes opérations de résumé peuvent être trouvées dans la documentation TensorFlow).
Dans run_fc_model.py, les lignes suivantes sont pertinentes pour la visualisation TensorBoard :
Une opération dans TensorFlow ne s'exécute pas toute seule, vous devez soit l'appeler directement, soit appeler une autre opération qui en dépend. Puisque nous ne voulons pas appeler chaque opération de résumé individuellement chaque fois que nous voulons collecter des informations de résumé, nous utilisons tf.merge_all_summaries pour créer une seule opération qui exécute tous nos résumés.
Lors de l'initialisation de la session TensorFlow, nous créons un écrivain de résumé. L'écrivain de résumé est responsable de l'écriture réelle des données de résumé sur le disque. Dans son constructeur, nous fournissons logdir, le répertoire où nous voulons que les journaux soient écrits. L'argument de graphe optionnel indique à TensorBoard de rendre une affichage de l'ensemble du graphe TensorFlow.
Toutes les 100 itérations, nous exécutons l'opération de résumé fusionnée et alimentons les résultats à l'écrivain de résumé qui les écrit sur le disque.
Pour visualiser les résultats, nous exécutons TensorBoard via « tensorboard --logdir=tf_logs » et ouvrons localhost:6006 dans un navigateur web. Dans l'onglet « Events », nous pouvons voir comment la perte du réseau diminue et comment sa précision augmente au fil du temps.
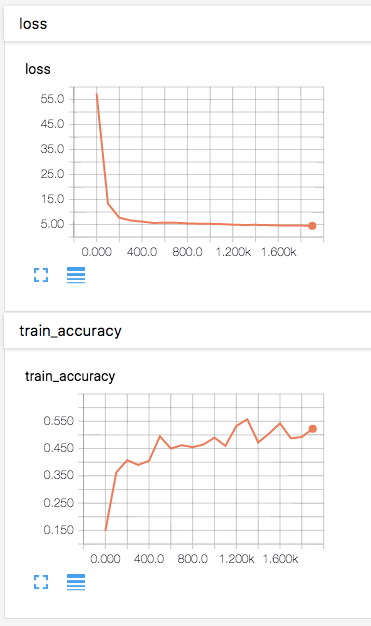 Graphiques TensorBoard affichant la perte et la précision du modèle au cours d'une exécution d'entraînement.
Graphiques TensorBoard affichant la perte et la précision du modèle au cours d'une exécution d'entraînement.
L'onglet « Graphs » montre une visualisation du graphe TensorFlow que nous avons défini. Vous pouvez le réorganiser de manière interactive jusqu'à ce que vous soyez satisfait de son apparence. Je pense que l'image suivante montre bien la structure de notre réseau.
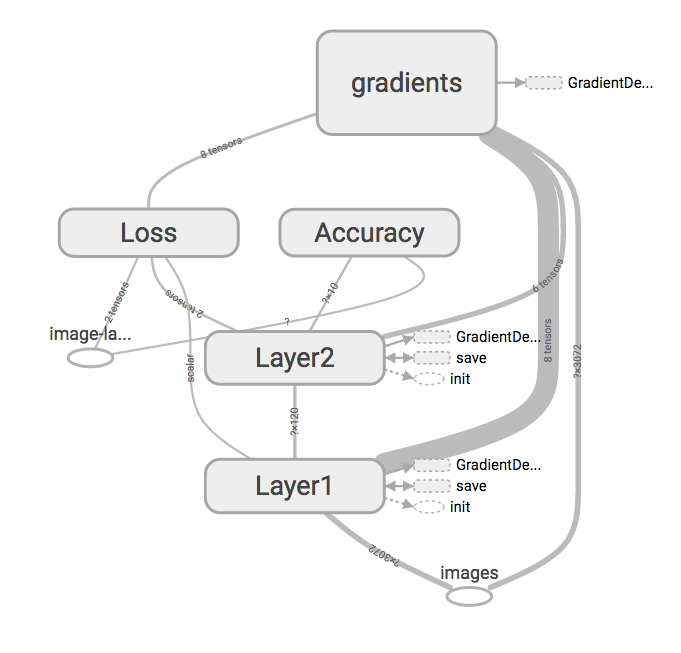 TensorBoard affiche le graphe TensorBoard dans une visualisation interactive.
TensorBoard affiche le graphe TensorBoard dans une visualisation interactive.
Dans les onglets « Distribution » et « Histograms », vous pouvez explorer les résultats de l'opération tf.histogram_summary que nous avons attachée à logits, mais je n'entrerai pas dans plus de détails ici. Plus d'informations peuvent être trouvées dans la section pertinente de la documentation officielle de TensorFlow.
Améliorations supplémentaires
Peut-être pensez-vous que l'entraînement du classificateur softmax a pris beaucoup moins de temps de calcul que l'entraînement du réseau de neurones. Bien que ce soit vrai, même si nous continuions à entraîner le classificateur softmax aussi longtemps qu'il a fallu pour entraîner le réseau de neurones, il n'atteindrait pas la même performance. Plus vous entraînez un modèle longtemps, plus les gains supplémentaires sont petits et après un certain point, l'amélioration de la performance est minime. Nous avons atteint ce point avec le réseau de neurones également. Un temps d'entraînement supplémentaire n'améliorerait plus significativement la précision. Il y a autre chose que nous pourrions faire cependant :
Les valeurs des paramètres par défaut sont choisies pour être assez bonnes, mais il reste encore de la place pour l'amélioration. En faisant varier des paramètres tels que le nombre de neurones dans la couche cachée ou le taux d'apprentissage, nous devrions pouvoir améliorer davantage la précision du modèle. Une précision de test supérieure à 50 % devrait définitivement être possible avec ce modèle avec une optimisation supplémentaire. Bien que je serais très surpris si ce modèle pouvait être ajusté pour atteindre 65 % ou plus. Mais il existe un autre type d'architecture de réseau pour lequel une telle précision est facilement réalisable : les réseaux de neurones convolutifs. Ce sont une classe de réseaux de neurones qui ne sont pas entièrement connectés. Au lieu de cela, ils essaient de donner un sens aux caractéristiques locales de leur entrée, ce qui est très utile pour analyser des images. Il est intuitivement logique de prendre en compte les informations spatiales lors de l'examen des images. Dans la partie 3 de cette série, nous verrons les principes de fonctionnement des réseaux de neurones convolutifs et en construirons un nous-mêmes.
Restez à l'écoute pour la partie 3 sur les réseaux de neurones convolutifs et merci beaucoup pour votre lecture ! Je suis heureux de recevoir tout retour que vous pourriez avoir !
Vous pouvez également consulter d'autres articles que j'ai écrits sur mon blog.