

Article original : How to Build a Neural Network from Scratch with PyTorch
Par Bipin Krishnan P
Dans cet article, nous allons plonger sous le capot des réseaux de neurones pour apprendre à en construire un à partir de zéro.
Ce qui m'excite le plus dans le deep learning, c'est de bidouiller du code pour construire quelque chose à partir de rien. Ce n'est pas une tâche facile, et enseigner à quelqu'un d'autre comment le faire est encore plus difficile.
J'ai suivi le cours Fast.ai et ce blog est grandement inspiré de mon expérience.
Sans plus tarder, commençons notre merveilleux voyage de démystification des réseaux de neurones.
Comment fonctionne un réseau de neurones ?
Commençons par comprendre le fonctionnement de haut niveau des réseaux de neurones.
Un réseau de neurones prend un ensemble de données et produit une prédiction. C'est aussi simple que cela.
 Fonctionnement d'un réseau de neurones
Fonctionnement d'un réseau de neurones
Permettez-moi de vous donner un exemple.
Supposons qu'un de vos amis (qui n'est pas un grand fan de football) pointe une vieille photo d'un célèbre footballeur – disons Lionel Messi – et vous demande qui c'est.
Vous serez capable d'identifier le footballeur en une seconde. La raison est que vous avez vu ses photos des milliers de fois auparavant. Donc vous pouvez l'identifier même si la photo est vieille ou a été prise dans une lumière tamisée.
Mais que se passe-t-il si je vous montre une photo d'un célèbre joueur de baseball (et que vous n'avez jamais vu un seul match de baseball auparavant) ? Vous ne serez pas capable de reconnaître ce joueur. Dans ce cas, même si la photo est claire et lumineuse, vous ne saurez pas qui c'est.
C'est le même principe utilisé pour les réseaux de neurones. Si notre objectif est de construire un réseau de neurones pour reconnaître des chats et des chiens, nous montrons simplement au réseau de neurones un tas de photos de chiens et de chats.
Plus spécifiquement, nous montrons au réseau de neurones des photos de chiens et lui disons que ce sont des chiens. Puis nous lui montrons des photos de chats, et les identifions comme des chats.
Une fois que nous avons entraîné notre réseau de neurones avec des images de chats et de chiens, il peut facilement classer si une image contient un chat ou un chien. En bref, il peut reconnaître un chat d'un chien.
Mais si vous montrez à notre réseau de neurones une photo d'un cheval ou d'un aigle, il ne l'identifiera jamais comme un cheval ou un aigle. Cela est dû au fait qu'il n'a jamais vu une photo d'un cheval ou d'un aigle auparavant parce que nous ne lui avons jamais montré ces animaux.
Si vous souhaitez améliorer la capacité du réseau de neurones, alors tout ce que vous avez à faire est de lui montrer des photos de tous les animaux que vous voulez que le réseau de neurones classe. Pour l'instant, tout ce qu'il connaît, ce sont les chats et les chiens et rien d'autre.
L'ensemble de données que nous utilisons pour notre entraînement dépend fortement du problème que nous avons entre les mains. Si vous souhaitez classer si un tweet a un sentiment positif ou négatif, alors probablement, vous voudrez un ensemble de données contenant beaucoup de tweets avec leur étiquette correspondante comme positive ou négative.
Maintenant que vous avez une vue d'ensemble de haut niveau des ensembles de données et de la manière dont un réseau de neurones apprend à partir de ces données, plongeons plus profondément dans le fonctionnement des réseaux de neurones.
Comprendre les réseaux de neurones
Nous allons construire un réseau de neurones pour classer les chiffres trois et sept à partir d'une image.
Mais avant de construire notre réseau de neurones, nous devons approfondir pour comprendre comment ils fonctionnent.
Chaque image que nous passons à notre réseau de neurones n'est qu'un ensemble de nombres. C'est-à-dire que chacune de nos images a une taille de 28×28, ce qui signifie qu'elle a 28 lignes et 28 colonnes, tout comme une matrice.
Nous voyons chacun des chiffres comme une image complète, mais pour un réseau de neurones, ce n'est qu'un ensemble de nombres allant de 0 à 255.
Voici une représentation en pixels du chiffre cinq :
 Valeurs des pixels avec les nuances
Valeurs des pixels avec les nuances
Comme vous pouvez le voir ci-dessus, nous avons 28 lignes et 28 colonnes (l'index commence à 0 et se termine à 27), tout comme une matrice. Les réseaux de neurones ne voient que ces matrices 28×28.
Pour montrer quelques détails supplémentaires, j'ai simplement affiché la nuance avec les valeurs des pixels. Si vous regardez de plus près l'image, vous pouvez voir que les valeurs des pixels proches de 255 sont plus sombres, tandis que les valeurs plus proches de 0 sont plus claires.
Dans PyTorch, nous n'utilisons pas le terme matrice. Au lieu de cela, nous utilisons le terme tenseur. Chaque nombre dans PyTorch est représenté comme un tenseur. Donc, à partir de maintenant, nous utiliserons le terme tenseur au lieu de matrice.
Visualiser un réseau de neurones
Un réseau de neurones peut avoir n'importe quel nombre de neurones et de couches.
Voici à quoi ressemble un réseau de neurones :
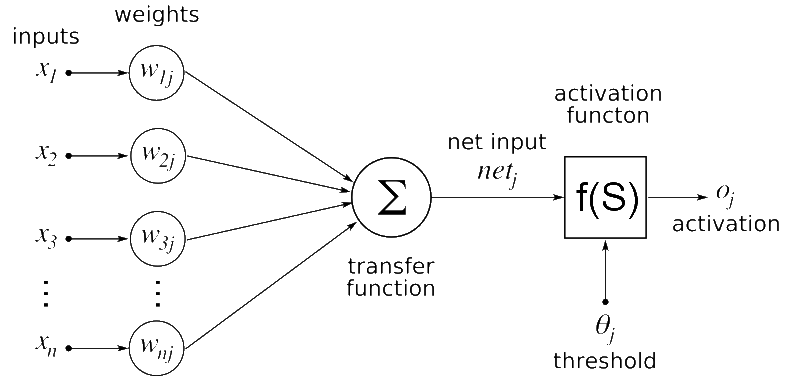 Réseau de neurones artificiel
Réseau de neurones artificiel
Ne vous laissez pas confondre par les lettres grecques dans l'image. Je vais vous l'expliquer :
Prenons le cas de la prédiction de la survie d'un patient ou non, sur la base d'un ensemble de données contenant le nom du patient, la température, la pression artérielle, l'état cardiaque, le salaire mensuel et l'âge.
Dans notre ensemble de données, seule la température, la pression artérielle, l'état cardiaque et l'âge ont une importance significative pour prédire si le patient survivra ou non. Nous allons donc attribuer une valeur de poids plus élevée à ces valeurs afin de montrer une importance plus grande.
Mais des caractéristiques comme le nom du patient et le salaire mensuel ont peu ou pas d'influence sur le taux de survie du patient. Nous attribuons donc des valeurs de poids plus petites à ces caractéristiques pour montrer une importance moindre.
Dans la figure ci-dessus, x1, x2, x3...xn sont les caractéristiques de notre ensemble de données qui peuvent être des valeurs de pixels dans le cas de données d'image ou des caractéristiques comme la pression artérielle ou l'état cardiaque comme dans l'exemple ci-dessus.
Les valeurs des caractéristiques sont multipliées par les valeurs de poids correspondantes, appelées w1j, w2j, w3j...wnj. Les valeurs multipliées sont additionnées et transmises à la couche suivante.
Les valeurs de poids optimales sont apprises lors de l'entraînement du réseau de neurones. Les valeurs de poids sont mises à jour en continu de manière à maximiser le nombre de prédictions correctes.
La fonction d'activation n'est rien d'autre que la fonction sigmoïde dans notre cas. Toute valeur que nous passons à la sigmoïde est convertie en une valeur comprise entre 0 et 1. Nous plaçons simplement la fonction sigmoïde au-dessus de notre prédiction de réseau de neurones pour obtenir une valeur entre 0 et 1.
Vous comprendrez l'importance de la couche sigmoïde une fois que nous commencerons à construire notre modèle de réseau de neurones.
Il existe de nombreuses autres fonctions d'activation qui sont encore plus simples à apprendre que la sigmoïde.
Voici l'équation pour une fonction sigmoïde :
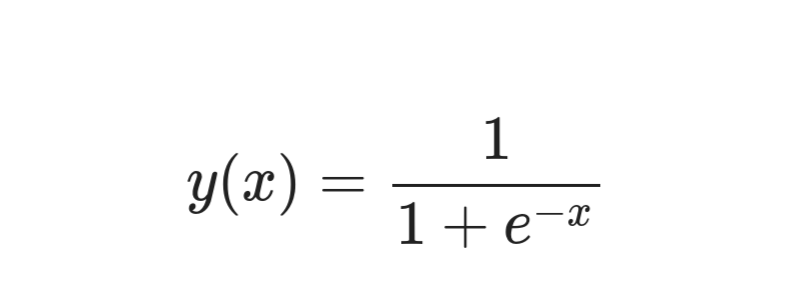 Fonction sigmoïde
Fonction sigmoïde
Les nœuds en forme de cercle dans le diagramme sont appelés neurones. À chaque couche du réseau de neurones, les poids sont multipliés par les données d'entrée.
Nous pouvons augmenter la profondeur du réseau de neurones en augmentant le nombre de couches. Nous pouvons améliorer la capacité d'une couche en augmentant le nombre de neurones dans cette couche.
Comprendre notre ensemble de données
La première chose dont nous avons besoin pour entraîner notre réseau de neurones est l'ensemble de données.
Puisque l'objectif de notre réseau de neurones est de classer si une image contient le chiffre trois ou sept, nous devons entraîner notre réseau de neurones avec des images de trois et de sept. Donc, construisons notre ensemble de données.
Heureusement, nous n'avons pas à créer l'ensemble de données à partir de zéro. Notre ensemble de données est déjà présent dans PyTorch. Tout ce que nous avons à faire est de le télécharger et d'effectuer quelques opérations de base dessus.
Nous devons télécharger un ensemble de données appelé MNIST (Modified National Institute of Standards and Technology) à partir de la bibliothèque torchvision de PyTorch.
Maintenant, plongeons plus profondément dans notre ensemble de données.
Qu'est-ce que l'ensemble de données MNIST ?
L'ensemble de données MNIST contient des chiffres manuscrits de zéro à neuf avec leurs étiquettes correspondantes comme montré ci-dessous :
 Ensemble de données MNIST
Ensemble de données MNIST
Donc, ce que nous faisons est simplement d'alimenter le réseau de neurones avec les images des chiffres et leurs étiquettes correspondantes qui indiquent au réseau de neurones que ceci est un trois ou un sept.
Comment préparer notre ensemble de données
L'ensemble de données MNIST téléchargé contient des images et leurs étiquettes correspondantes.
Nous écrivons simplement le code pour indexer uniquement les images avec une étiquette de trois ou sept. Ainsi, nous obtenons un ensemble de données de trois et de sept.
Tout d'abord, importons toutes les bibliothèques nécessaires.
import torch
from torchvision import datasets
import matplotlib.pyplot as plt
Nous importons la bibliothèque PyTorch pour construire notre réseau de neurones et la bibliothèque torchvision pour télécharger l'ensemble de données MNIST, comme discuté précédemment. La bibliothèque Matplotlib est utilisée pour afficher les images de notre ensemble de données.
Maintenant, préparons notre ensemble de données.
mnist = datasets.MNIST('./data', download=True)
threes = mnist.data[(mnist.targets == 3)]/255.0
sevens = mnist.data[(mnist.targets == 7)]/255.0
len(threes), len(sevens)
Comme nous l'avons appris ci-dessus, tout dans PyTorch est représenté sous forme de tenseurs. Donc notre ensemble de données est également sous forme de tenseurs.
Nous téléchargeons l'ensemble de données dans la première ligne. Nous indexons uniquement les images dont la valeur cible est égale à 3 ou 7 et les normalisons en divisant par 255 et les stockons séparément.
Nous pouvons vérifier si notre indexation a été effectuée correctement en exécutant le code de la dernière ligne qui donne le nombre d'images dans les tenseurs threes et sevens.
Maintenant, vérifions si nous avons préparé notre ensemble de données correctement.
def show_image(img):
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
show_image(threes[3])
show_image(sevens[8])
En utilisant la bibliothèque Matplotlib, nous créons une fonction pour afficher les images.
Faisons un rapide contrôle de cohérence en imprimant la forme de nos tenseurs.
print(threes.shape, sevens.shape)
Si tout s'est bien passé, vous obtiendrez la taille de threes et sevens comme ([6131, 28, 28]) et ([6265, 28, 28]) respectivement. Cela signifie que nous avons 6131 images de taille 28×28 pour les trois et 6265 images de taille 28×28 pour les sept.
Nous avons créé deux tenseurs avec des images de trois et de sept. Maintenant, nous devons les combiner en un seul ensemble de données pour alimenter notre réseau de neurones.
combined_data = torch.cat([threes, sevens])
combined_data.shape
Nous allons concaténer les deux tenseurs en utilisant PyTorch et vérifier la forme de l'ensemble de données combiné.
Maintenant, nous allons aplatir les images dans l'ensemble de données.
flat_imgs = combined_data.view((-1, 28*28))
flat_imgs.shape
Nous allons aplatir les images de telle sorte que chacune des images de taille 28×28 devienne une seule ligne avec 784 colonnes (28×28=784). Ainsi, la forme est convertie en ([12396, 784]).
Nous devons créer des étiquettes correspondant aux images dans l'ensemble de données combiné.
target = torch.tensor([1]*len(threes)+[2]*len(sevens))
target.shape
Nous attribuons l'étiquette 1 pour les images contenant un trois, et l'étiquette 0 pour les images contenant un sept.
Comment entraîner votre réseau de neurones
Pour entraîner votre réseau de neurones, suivez ces étapes.
Étape 1 : Construire le modèle
Ci-dessous, vous pouvez voir l'équation la plus simple qui montre comment fonctionnent les réseaux de neurones :
y = Wx + b
Ici, le terme 'y' fait référence à notre prédiction, c'est-à-dire trois ou sept. 'W' fait référence à nos valeurs de poids, 'x' fait référence à notre image d'entrée, et 'b' est le biais (qui, avec les poids, aide à faire des prédictions).
En bref, nous multiplions chaque valeur de pixel par les valeurs de poids et les ajoutons à la valeur de biais.
Les poids et la valeur de biais décident de l'importance de chaque valeur de pixel lors de la réalisation de prédictions.
Nous classons trois et sept, donc nous n'avons que deux classes à prédire.
Donc, nous pouvons prédire 1 si l'image est trois et 0 si l'image est sept. La prédiction que nous obtenons de cette étape peut être n'importe quel nombre réel, mais nous devons faire en sorte que notre modèle (réseau de neurones) prédise une valeur entre 0 et 1.
Cela nous permet de créer un seuil de 0,5. C'est-à-dire, si la valeur prédite est inférieure à 0,5, alors c'est un sept. Sinon, c'est un trois.
Nous utilisons une fonction sigmoïde pour obtenir une valeur entre 0 et 1.
Nous allons créer une fonction pour la sigmoïde en utilisant la même équation montrée précédemment. Ensuite, nous passons les valeurs du réseau de neurones dans la sigmoïde.
Nous allons créer un réseau de neurones à une seule couche.
Nous ne pouvons pas créer beaucoup de boucles pour multiplier chaque valeur de poids avec chaque pixel de l'image, car c'est très coûteux. Donc, nous pouvons utiliser un truc magique pour faire toute la multiplication en une seule fois en utilisant la multiplication de matrices.
def sigmoid(x): return 1/(1+torch.exp(-x))
def simple_nn(data, weights, bias): return sigmoid((data@weights) + bias)
Étape 2 : Définir la perte
Maintenant, nous avons besoin d'une fonction de perte pour calculer de combien notre valeur prédite est différente de celle de la vérité terrain.
Par exemple, si la valeur prédite est 0,3 mais que la vérité terrain est 1, alors notre perte est très élevée. Donc notre modèle essaiera de réduire cette perte en mettant à jour les poids et le biais afin que nos prédictions deviennent proches de la vérité terrain.
Nous allons utiliser l'erreur quadratique moyenne pour vérifier la valeur de la perte. L'erreur quadratique moyenne trouve la moyenne du carré de la différence entre la valeur prédite et la vérité terrain.
def error(pred, target): return ((pred-target)**2).mean()
Étape 3 : Initialiser les valeurs de poids
Nous initialisons simplement les poids et le biais de manière aléatoire. Plus tard, nous verrons comment ces valeurs sont mises à jour pour obtenir les meilleures prédictions.
w = torch.randn((flat_imgs.shape[1], 1), requires_grad=True)
b = torch.randn((1, 1), requires_grad=True)
La forme des valeurs de poids doit être sous la forme suivante :
(Nombre de neurones dans la couche précédente, nombre de neurones dans la couche suivante)
Nous utilisons une méthode appelée descente de gradient pour mettre à jour nos poids et biais afin de faire le maximum de prédictions correctes.
Notre objectif est d'optimiser ou de diminuer notre perte, donc la meilleure méthode est de calculer les gradients.
Nous devons prendre la dérivée de chaque poids et biais par rapport à la fonction de perte. Ensuite, nous devons soustraire cette valeur de nos poids et biais.
De cette manière, nos valeurs de poids et de biais sont mises à jour de telle sorte que notre modèle fasse une bonne prédiction.
Mettre à jour un paramètre pour optimiser une fonction n'est pas une nouvelle chose – vous pouvez optimiser n'importe quelle fonction arbitraire en utilisant des gradients.
Nous avons défini un paramètre spécial (appelé requires_grad) à vrai pour calculer le gradient des poids et du biais.
Étape 4 : Mettre à jour les poids
Si notre prédiction ne se rapproche pas de la vérité terrain, cela signifie que nous avons fait une prédiction incorrecte. Cela signifie que nos poids ne sont pas corrects. Donc nous devons mettre à jour nos poids jusqu'à ce que nous obtenions de bonnes prédictions.
À cette fin, nous mettons toutes les étapes ci-dessus à l'intérieur d'une boucle for et lui permettons de s'itérer autant de fois que nous le souhaitons.
À chaque itération, la perte est calculée et les poids et biais sont mis à jour pour obtenir une meilleure prédiction à l'itération suivante.
Ainsi, notre modèle devient meilleur après chaque itération en trouvant la valeur de poids optimale adaptée à notre tâche en cours.
Chaque tâche nécessite un ensemble différent de valeurs de poids, donc nous ne pouvons pas nous attendre à ce que notre réseau de neurones entraîné pour classer des animaux performe bien sur la classification d'instruments de musique.
Voici à quoi ressemble l'entraînement de notre modèle :
for i in range(2000):
pred = simple_nn(flat_imgs, w, b)
loss = error(pred, target.unsqueeze(1))
loss.backward()
w.data -= 0.001*w.grad.data
b.data -= 0.001*b.grad.data
w.grad.zero_()
b.grad.zero_()
print("Perte : ", loss.item())
Nous allons calculer les prédictions et les stocker dans la variable 'pred' en appelant la fonction que nous avons créée précédemment. Ensuite, nous calculons la perte d'erreur quadratique moyenne.
Ensuite, nous allons calculer tous les gradients pour nos poids et biais et mettre à jour la valeur en utilisant ces gradients.
Nous avons multiplié les gradients par 0,001, et cela s'appelle le taux d'apprentissage. Cette valeur décide du taux auquel notre modèle va apprendre, si elle est trop basse, alors le modèle va apprendre lentement, ou en d'autres termes, la perte sera réduite lentement.
Si le taux d'apprentissage est trop élevé, notre modèle ne sera pas stable, sautant entre une large gamme de valeurs de perte. Cela signifie qu'il échouera à converger.
Nous faisons les étapes ci-dessus 2000 fois, et chaque fois notre modèle essaie de réduire la perte en mettant à jour les valeurs des poids et du biais.
Nous devons remettre à zéro les gradients à la fin de chaque boucle ou époque afin qu'il n'y ait pas d'accumulation de gradients indésirables dans la mémoire qui affectera l'apprentissage de notre modèle.
Puisque notre modèle est très petit, il ne prend pas beaucoup de temps pour s'entraîner pendant 2000 époques ou itérations. Après 2000 époques, notre réseau de neurones a donné une valeur de perte de 0,6805, ce qui n'est pas mal pour un modèle aussi petit.
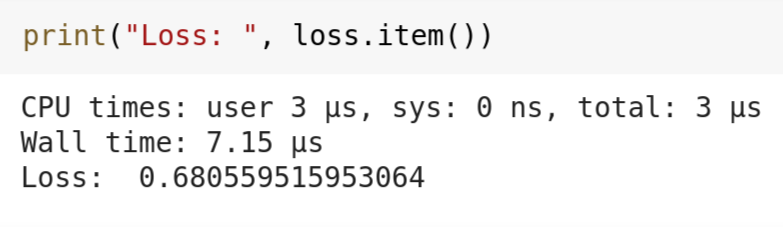 Résultat final
Résultat final
Conclusion
Il y a un énorme espace d'amélioration dans le modèle que nous venons de créer.
Ce n'est qu'un modèle simple, et vous pouvez expérimenter en augmentant le nombre de couches, le nombre de neurones dans chaque couche, ou en augmentant le nombre d'époques.
En bref, le machine learning est une grande magie utilisant les mathématiques. Apprenez toujours les concepts fondamentaux – ils peuvent être ennuyeux, mais finalement vous comprendrez que ces concepts mathématiques ennuyeux ont créé ces technologies de pointe comme les deepfakes.
Vous pouvez obtenir le code complet sur GitHub ou jouer avec le code dans Google colab.