


Article original : How to Build a RAG Pipeline with LlamaIndex
Les grands modèles de langage (LLM) sont partout de nos jours – pensez à ChatGPT – mais ils ont leur lot de défis.
L'un des plus grands défis auxquels sont confrontés les LLM est l'hallucination. Cela se produit lorsque le modèle génère un texte factuellement incorrect ou trompeur, souvent basé sur des modèles qu'il a appris de ses données d'entraînement. Alors, comment la génération augmentée de récupération, ou RAG (Retrieval-Augmented Generation), peut-elle aider à atténuer ce problème ?
En récupérant des informations pertinentes à partir d'une base de connaissances plus vaste et plus large, le RAG garantit que les réponses du LLM sont ancrées dans des faits réels. Cela réduit considérablement la probabilité d'hallucinations et améliore la précision et la fiabilité globales du contenu généré.
Table des matières :
Qu'est-ce que la génération augmentée de récupération (RAG) ?
Le RAG est une technique qui combine la récupération d'informations et la génération de langage. Considérez cela comme un processus en deux étapes :
Récupération (Retrieval) : Le modèle récupère d'abord les informations pertinentes à partir d'un vaste corpus de documents en fonction de la requête de l'utilisateur.
Génération : En utilisant ces informations récupérées, le modèle génère ensuite une réponse complète et informative.
Pourquoi utiliser LlamaIndex pour le RAG ?
LlamaIndex est un Framework puissant qui simplifie le processus de construction de pipelines RAG. Il offre un moyen flexible et efficace de connecter les composants de récupération (comme les bases de données vectorielles et les modèles d'embedding) aux composants de génération (comme les LLM).
Certains des avantages clés de l'utilisation de LlamaIndex incluent :
Modularité : Il vous permet de personnaliser et d'expérimenter facilement différents composants.
Scalabilité : Il peut gérer de grands ensembles de données et des requêtes complexes.
Facilité d'utilisation : Il fournit une API de haut niveau qui abstrait une grande partie de la complexité sous-jacente.
Ce que vous allez apprendre ici :
Dans cet article, nous approfondirons les composants d'un pipeline RAG et explorerons comment vous pouvez utiliser LlamaIndex pour construire ces systèmes.
Nous aborderons des sujets tels que les bases de données vectorielles, les modèles d'embedding, les modèles de langage et le rôle de LlamaIndex dans la connexion de ces composants.
Comprendre les composants d'un pipeline RAG
Voici un schéma qui vous aidera à vous familiariser avec les bases de l'architecture RAG :
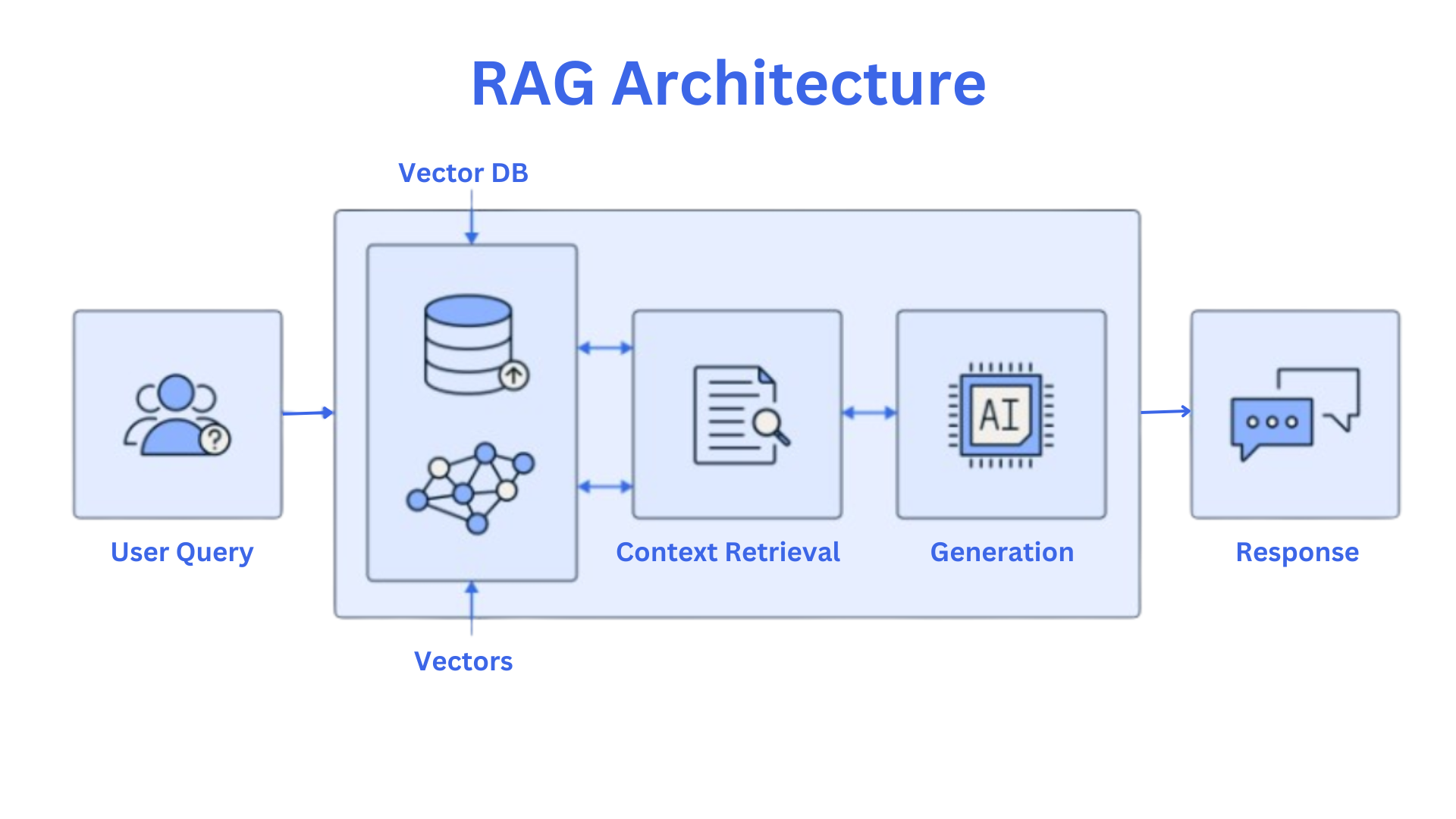
Ce schéma est inspiré par cet article. Passons en revue les éléments clés.
Composants du RAG
Composant de récupération :
Bases de données vectorielles : Ces bases de données sont optimisées pour stocker et rechercher des vecteurs de haute dimension. Elles sont cruciales pour trouver efficacement des informations pertinentes dans un vaste corpus de documents.
Modèles d'embedding : Ces modèles convertissent le texte en représentations numériques ou embeddings. Ces embeddings capturent la signification sémantique du texte, permettant une comparaison et une récupération efficaces dans les bases de données vectorielles.
Un vecteur est un objet mathématique qui représente une quantité ayant à la fois une magnitude (taille) et une direction. Dans le contexte du RAG, les embeddings sont des vecteurs de haute dimension qui capturent la signification sémantique du texte. Chaque dimension du vecteur représente un aspect différent de la signification du texte, permettant une comparaison et une récupération efficaces.
Composant de génération :
- Modèles de langage (LLM) : Ces modèles sont entraînés sur d'énormes quantités de données textuelles, ce qui leur permet de générer du texte de qualité humaine. Ils sont capables de comprendre et de répondre à des invites de manière cohérente et informative.
Le flux RAG
Soumission de la requête : Un utilisateur soumet une requête ou une question.
Création de l'embedding : La requête est convertie en un embedding en utilisant le même modèle d'embedding que celui utilisé pour le corpus.
Récupération : L'embedding est recherché dans la base de données vectorielle pour trouver les documents les plus pertinents.
Contextualisation : Les documents récupérés sont combinés avec la requête originale pour former un contexte.
Génération : Le modèle de langage génère une réponse basée sur le contexte fourni.
LlamaIndex
LlamaIndex joue un rôle crucial dans la connexion des composants de récupération et de génération. Il agit comme un index qui fait correspondre les requêtes aux documents pertinents. En gérant efficacement l'index, LlamaIndex garantit que le processus de récupération est rapide et précis.
Prérequis
Nous utiliserons Python et IBM watsonx via LlamaIndex dans cet article. Vous devriez avoir les éléments suivants sur votre système avant de commencer :
Python 3.9+
De la curiosité pour apprendre
C'est parti !
Dans cet article, nous allons utiliser LlamaIndex pour créer un pipeline RAG simple.
Créons un environnement virtuel pour Python en utilisant la commande suivante dans votre terminal : python -m venv venv. Cela créera un environnement virtuel (venv) pour votre projet. Si vous êtes sous Windows, vous pouvez l'activer avec .\venv\Scripts\activate, et les utilisateurs de Mac peuvent l'activer avec source venv/bin/activate.
Maintenant, installons les packages :
pip install wikipedia llama-index-llms-ibm llama-index-embeddings-huggingface
Une fois ces packages installés, vous aurez également besoin de la clé API de watsonx.ai. Cela vous aidera à utiliser les LLM via LlamaIndex.
Pour savoir comment obtenir vos clés API watsonx.ai, cliquez ici. Vous avez besoin de l'ID du projet et de la clé API pour pouvoir travailler sur l'aspect "Génération" du RAG. Les avoir vous aidera à effectuer des appels LLM via watsonx.ai.
import wikipedia
# Rechercher une page spécifique
page = wikipedia.page("Artificial Intelligence")
# Accéder au contenu
print(page.content)
Maintenant, enregistrons le contenu de la page dans un document texte. Nous faisons cela pour pouvoir y accéder plus tard. Vous pouvez le faire avec le code ci-dessous :
import os
# Créer le répertoire 'Document' s'il n'existe pas
if not os.path.exists('Document'):
os.mkdir('Document')
# Ouvrir le fichier 'AI.txt' en mode écriture avec l'encodage UTF-8
with open('Document/AI.txt', 'w', encoding='utf-8') as f:
# Écrire le contenu de l'objet 'page' dans le fichier
f.write(page.content)
Nous allons maintenant utiliser watsonx.ai via LlamaIndex. Cela nous aidera à générer des réponses basées sur la requête de l'utilisateur.
Note : Assurez-vous de remplacer les paramètres WATSONX_APIKEY et project_id par vos propres valeurs dans le code ci-dessous :
import os
from llama_index.llms.ibm import WatsonxLLM
from llama_index.core import SimpleDirectoryReader, Document
# Définir une fonction pour générer des réponses en utilisant l'instance WatsonxLLM
def generate_response(prompt):
"""
Génère une réponse à l'invite donnée en utilisant l'instance WatsonxLLM.
Args:
prompt (str): L'invite à fournir au grand modèle de langage.
Returns:
str: La réponse générée par WatsonxLLM.
"""
response = watsonx_llm.complete(prompt)
return response
# Définir la variable d'environnement WATSONX_APIKEY (remplacez par votre clé réelle)
os.environ["WATSONX_APIKEY"] = 'VOTRE_CLÉ_API_WATSONX' # Remplacer par votre clé API
# Définir les paramètres du modèle (ajuster au besoin)
temperature = 0
max_new_tokens = 1500
additional_params = {
"decoding_method": "sample",
"min_new_tokens": 1,
"top_k": 50,
"top_p": 1,
}
# Créer une instance WatsonxLLM avec le modèle, l'URL, l'ID de projet et les paramètres spécifiés
watsonx_llm = WatsonxLLM(
model_id="meta-llama/llama-3-1-70b-instruct",
url="https://us-south.ml.cloud.ibm.com",
project_id="VOTRE_ID_DE_PROJET",
temperature=temperature,
max_new_tokens=max_new_tokens,
additional_params=additional_params,
)
# Charger les documents depuis le répertoire spécifié
documents = SimpleDirectoryReader(
input_files=["Document/AI.txt"]
).load_data()
# Combiner le contenu textuel de tous les documents en un seul objet Document
combined_documents = Document(text="\n\n".join([doc.text for doc in documents]))
# Afficher le document combiné
print(combined_documents)
Voici une explication des paramètres :
temperature = 0 : Ce réglage permet au modèle de générer la séquence de texte la plus probable, ce qui conduit à un résultat plus déterministe et prévisible. C'est comme dire au modèle de s'en tenir aux mots et phrases les plus courants.
max_new_tokens = 1500 : Limite le texte généré à un maximum de 1500 nouveaux tokens (mots ou parties de mots).
additional_params :
decoding_method = "sample" : Signifie que le modèle générera du texte de manière aléatoire en fonction de la distribution de probabilité de chaque token.
min_new_tokens = 1 : Garantit qu'au moins un nouveau token est généré, empêchant le modèle de se répéter.
top_k = 50 : Limite les choix du modèle aux 50 tokens les plus probables à chaque étape, rendant le résultat plus ciblé et moins aléatoire.
top_p = 1 : Définit la probabilité d'échantillonnage nucléaire à 1, ce qui signifie que tous les tokens avec une probabilité supérieure ou égale à la valeur top_p seront considérés.
Vous pouvez ajuster ces paramètres pour expérimenter et voir comment ils affectent votre réponse. Nous allons maintenant construire et charger un index de magasin vectoriel à partir du document donné. Mais d'abord, comprenons de quoi il s'agit.
Comprendre les index de magasin vectoriel (Vector Store Indexes)
Un index de magasin vectoriel est une structure de données spécialisée conçue pour stocker et récupérer efficacement des vecteurs de haute dimension. Dans le contexte de LlamaIndex, ces vecteurs représentent les embeddings sémantiques des documents.
Caractéristiques clés des index de magasin vectoriel :
Vecteurs de haute dimension : Chaque document est représenté comme un vecteur de haute dimension, capturant sa signification sémantique.
Récupération efficace : Les index de magasin vectoriel sont optimisés pour une recherche de similitude rapide, vous permettant de trouver rapidement des documents sémantiquement similaires à une requête donnée.
Scalabilité : Ils peuvent gérer de grands ensembles de données et s'adapter efficacement à mesure que le nombre de documents augmente.
Comment LlamaIndex utilise les index de magasin vectoriel :
Embedding du document : Les documents sont d'abord convertis en vecteurs de haute dimension à l'aide d'un modèle de langage comme Llama.
Création de l'index : Les embeddings sont stockés dans un index de magasin vectoriel.
Traitement de la requête : Lorsqu'un utilisateur soumet une requête, elle est également convertie en vecteur. L'index de magasin vectoriel est ensuite utilisé pour trouver les documents les plus similaires basés sur leurs embeddings.
Génération de la réponse : Les documents récupérés sont utilisés pour générer une réponse pertinente.
Dans le code ci-dessous, vous rencontrerez le mot "chunk". Un chunk est une unité de texte plus petite et gérable extraite d'un document plus large. Il s'agit généralement d'un paragraphe ou de quelques phrases. Ils sont utilisés pour rendre la récupération et le traitement des informations plus efficaces, surtout avec de grands documents.
En décomposant les documents en chunks, les systèmes RAG peuvent se concentrer sur les parties les plus pertinentes et générer des réponses plus précises et concises.
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core import VectorStoreIndex, load_index_from_storage
from llama_index.core import Settings
from llama_index.core import StorageContext
def get_build_index(documents, embed_model="local:BAAI/bge-small-en-v1.5", save_dir="./vector_store/index"):
"""
Construit ou charge un index de magasin vectoriel à partir des documents fournis.
Args:
documents (list[Document]): Une liste d'objets Document.
embed_model (str, optional): Le modèle d'embedding à utiliser. Par défaut "local:BAAI/bge-small-en-v1.5".
save_dir (str, optional): Le répertoire pour sauvegarder ou charger l'index. Par défaut "./vector_store/index".
Returns:
VectorStoreIndex: L'index construit ou chargé.
"""
# Définir les paramètres de l'index
Settings.llm = watsonx_llm
Settings.embed_model = embed_model
Settings.node_parser = SentenceSplitter(chunk_size=1000, chunk_overlap=200)
Settings.num_output = 512
Settings.context_window = 3900
# Vérifier si le répertoire de sauvegarde existe
if not os.path.exists(save_dir):
# Créer et charger l'index
index = VectorStoreIndex.from_documents(
[documents], service_context=Settings
)
index.storage_context.persist(persist_dir=save_dir)
else:
# Charger l'index existant
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
service_context=Settings,
)
return index
# Obtenir l'index vectoriel
vector_index = get_build_index(documents=documents, embed_model="local:BAAI/bge-small-en-v1.5", save_dir="./vector_store/index")
Voici la dernière partie du RAG : nous créons un moteur de requête avec remplacement de métadonnées et reclassement par transformateur de phrases (sentence transformer reranking). Mais au fait, qu'est-ce qu'un re-ranker ?
Un re-ranker est un composant qui réordonne les documents récupérés en fonction de leur pertinence par rapport à la requête. Il utilise des informations supplémentaires, telles que la similitude sémantique ou des facteurs spécifiques au contexte, pour affiner le classement initial fourni par le système de récupération. Cela aide à garantir que les documents les plus pertinents sont présentés à l'utilisateur, menant à des réponses plus précises et informatives.
from llama_index.core.postprocessor import MetadataReplacementPostProcessor, SentenceTransformerRerank
def get_query_engine(sentence_index, similarity_top_k=6, rerank_top_n=2):
"""
Crée un moteur de requête avec remplacement de métadonnées et reclassement par transformateur de phrases.
Args:
sentence_index (VectorStoreIndex): L'index de phrases à utiliser.
similarity_top_k (int, optional): Le nombre de nœuds similaires à considérer. Par défaut 6.
rerank_top_n (int, optional): Le nombre de nœuds à reclasser. Par défaut 2.
Returns:
QueryEngine: Le moteur de requête.
"""
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
engine = sentence_index.as_query_engine(
similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank]
)
return engine
# Créer un moteur de requête avec les paramètres spécifiés
query_engine = get_query_engine(sentence_index=vector_index, similarity_top_k=8, rerank_top_n=5)
# Interroger le moteur avec une question
query = 'What is Deep learning?'
response = query_engine.query(query)
prompt = f'''Générez une réponse détaillée pour la requête posée en vous basant uniquement sur le contexte récupéré :
Requête : {query}
Contexte : {response}
Instructions :
1. Affichez la requête et votre réponse générée basée sur le contexte.
2. Votre réponse doit être détaillée et couvrir tous les aspects du contexte.
3. Soyez percutant et concis.
4. N'incluez rien d'autre dans votre réponse - pas d'en-tête/pied de page/code etc.
'''
response = generate_response(prompt)
print(response.text)
'''
SORTIE -
Requête : What is Deep learning?
Le Deep Learning est un sous-ensemble de l'intelligence artificielle qui utilise plusieurs couches de neurones entre les entrées et les sorties du réseau pour extraire progressivement des caractéristiques de plus haut niveau à partir des données d'entrée brutes.
Cette technique permet d'améliorer les performances dans divers sous-domaines de l'IA, tels que la vision par ordinateur, la reconnaissance vocale, le traitement du langage naturel et la classification d'images.
Les multiples couches des réseaux de Deep Learning sont capables d'identifier des concepts et des motifs complexes, notamment des bords, des visages, des chiffres et des lettres.
La raison du succès du Deep Learning n'est pas attribuée à une percée théorique récente, mais plutôt à l'augmentation significative de la puissance informatique, en particulier le passage à l'utilisation d'unités de traitement graphique (GPU), qui ont multiplié la vitesse par cent.
De plus, la disponibilité de vastes quantités de données d'entraînement, y compris de grands ensembles de données organisés, a également contribué au succès du Deep Learning.
Dans l'ensemble, la capacité du Deep Learning à analyser et à extraire des informations à partir de données brutes a conduit à son application généralisée dans divers domaines, et ses performances continuent de s'améliorer avec les progrès technologiques et la disponibilité des données. '''
Comment affiner le pipeline
Une fois que vous avez construit un pipeline RAG de base, l'étape suivante consiste à l'affiner pour des performances optimales. Cela implique d'ajuster de manière itérative divers composants et paramètres pour améliorer la qualité des réponses générées.
Comment évaluer les performances du pipeline
Pour évaluer l'efficacité du pipeline, vous pouvez utiliser des métriques telles que :
Précision (Accuracy) : À quelle fréquence le pipeline génère-t-il des réponses correctes et pertinentes ?
Pertinence : Dans quelle mesure les documents récupérés correspondent-ils à la requête ?
Cohérence : Le texte généré est-il bien structuré et facile à comprendre ?
Factualité : Les réponses générées sont-elles exactes et cohérentes avec les faits connus ?
Itérer sur la structure de l'index, le modèle d'embedding et le modèle de langage
Vous pouvez expérimenter différentes structures d'index (par exemple, index plat, index hiérarchique) pour trouver celle qui convient le mieux à vos données et à vos modèles de requêtes. Envisagez d'utiliser différents modèles d'embedding pour capturer différentes nuances sémantiques. Affiner le modèle de langage peut également améliorer sa capacité à générer des réponses de haute qualité.
Expérimenter avec différents hyperparamètres
Les hyperparamètres sont des réglages qui contrôlent le comportement des composants du pipeline. En expérimentant avec différentes valeurs, vous pouvez optimiser les performances du pipeline. Voici quelques exemples d'hyperparamètres :
Dimension de l'embedding : La taille des vecteurs d'embedding
Taille de l'index : Le nombre maximum de documents à stocker dans l'index
Seuil de récupération : Le score de similitude minimum pour qu'un document soit considéré comme pertinent
Real-World Applications of RAG
Les pipelines RAG ont un large éventail d'applications, notamment :
Chatbots de support client : Fournir des réponses informatives et utiles aux demandes des clients.
Recherche dans une base de connaissances : Récupérer efficacement des informations pertinentes dans de grandes collections de documents.
Résumé de documents volumineux : Condenser de longs documents en résumés concis.
Systèmes de questions-réponses : Répondre à des questions complexes basées sur un corpus de connaissances donné.
Bonnes pratiques et considérations RAG
Pour construire des pipelines RAG efficaces, considérez ces bonnes pratiques :
Qualité des données et prétraitement : Assurez-vous que vos données sont propres, cohérentes et pertinentes pour votre cas d'utilisation. Prétraitez les données pour éliminer le bruit et améliorer leur qualité.
Sélection du modèle d'embedding : Choisissez un modèle d'embedding approprié pour votre domaine et votre tâche spécifiques. Considérez des facteurs tels que la précision, l'efficacité de calcul et l'interprétabilité.
Optimisation de l'index : Optimisez la structure et les paramètres de l'index pour améliorer l'efficacité et la précision de la récupération.
Considérations éthiques et biais : Soyez conscient des biais potentiels dans vos données et vos modèles. Prenez des mesures pour atténuer les biais et garantir l'équité dans votre pipeline RAG.
Conclusion
Les pipelines RAG offrent une approche puissante pour tirer parti des grands modèles de langage pour une variété de tâches. En sélectionnant et en affinant soigneusement les composants d'un pipeline RAG, vous pouvez construire des systèmes qui fournissent des réponses informatives, précises et pertinentes.
Points clés à retenir :
Le RAG combine la récupération d'informations et la génération de langage.
LlamaIndex simplifie le processus de construction de pipelines RAG.
L'affinage est essentiel pour optimiser les performances du pipeline.
Le RAG a un large éventail d'applications concrètes.
Les considérations éthiques sont cruciales pour construire des systèmes RAG responsables.
À mesure que la technologie RAG continue d'évoluer, nous pouvons nous attendre à voir des applications encore plus innovantes et puissantes à l'avenir. D'ici là, attendons que l'avenir se dévoile !