
Article original : How to Build a Scalable Data Analytics Pipeline
Par Priyanka Vergadia
Chaque application génère des données, mais que signifient ces données ? C'est une question à laquelle tous les scientifiques des données sont embauchés pour répondre.
Il ne fait aucun doute que ces informations sont la marchandise la plus précieuse pour une entreprise. Mais donner un sens aux données, créer des insights et les transformer en décisions est encore plus important.
À mesure que les données continuent de croître en volume, les pipelines d'analyse de données doivent être évolutifs pour s'adapter au rythme du changement. Et pour cette raison, choisir de configurer le pipeline dans le cloud a parfaitement du sens (puisque le cloud offre une évolutivité et une flexibilité à la demande).
Dans cet article, je vais démystifier comment construire un pipeline de traitement de données évolutif et adaptable dans Google Cloud. Et ne vous inquiétez pas – ces concepts sont applicables dans tout autre cloud ou pipeline de données sur site.
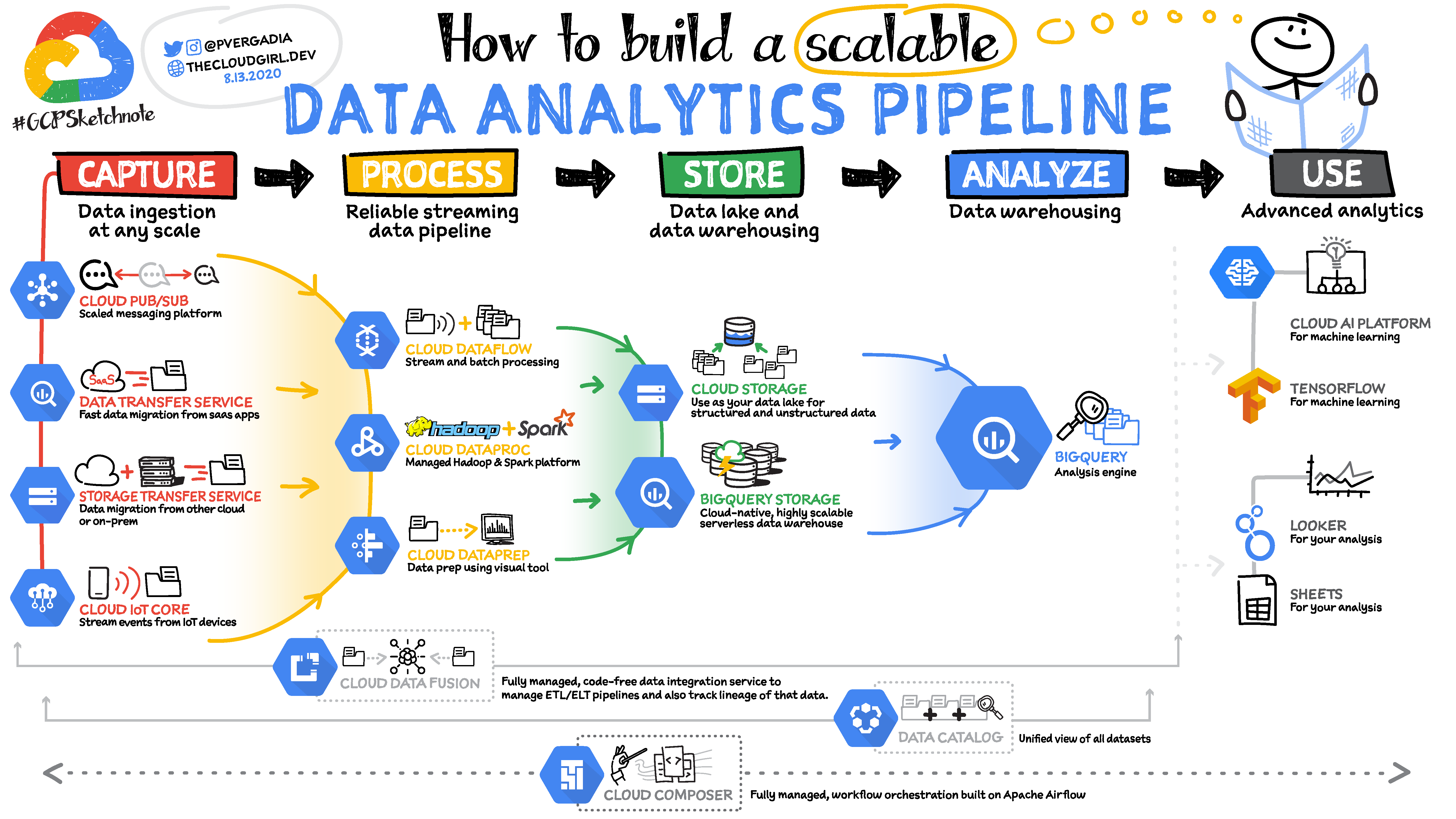
5 étapes pour créer un pipeline d'analyse de données :
 5 étapes dans un pipeline d'analyse de données
5 étapes dans un pipeline d'analyse de données
- Tout d'abord, vous ingérez les données à partir de la source de données
- Ensuite, vous traitez et enrichissez les données afin que votre système en aval puisse les utiliser dans le format qu'il comprend le mieux.
- Ensuite, vous stockez les données dans un lac de données ou un entrepôt de données pour soit une archivage à long terme, soit pour des rapports et des analyses.
- Vous pouvez ensuite analyser les données en les alimentant dans des outils d'analyse.
- Appliquez le machine learning pour des prédictions ou créez des rapports à partager avec vos équipes.
Examinons chacune de ces étapes plus en détail.
Comment capturer les données
Selon l'origine de vos données, vous pouvez avoir plusieurs options pour les ingérer.
- Utilisez des outils de migration de données pour migrer des données depuis des systèmes sur site ou d'un cloud à un autre. Google Cloud offre un service de transfert de stockage à cette fin.
- Pour ingérer des données depuis vos services SaaS tiers, utilisez des API et envoyez les données à l'entrepôt de données. Dans Google Cloud BigQuery, l'entrepôt de données serverless fournit un service de transfert de données qui vous permet d'importer des données depuis des applications SaaS telles que YouTube, Google Ads, Amazon S3, Teradata, ResShift et plus encore.
- Vous pouvez également diffuser des données en temps réel depuis vos applications avec le service Pub/Sub. Vous configurez une source de données pour pousser des messages d'événements dans Pub/Sub, d'où un abonné récupère le message et prend les mesures appropriées.
- Si vous avez des appareils IoT, ils peuvent diffuser des données en temps réel en utilisant Cloud IoT Core qui prend en charge le protocole MQTT pour les appareils IoT. Vous pouvez également envoyer des données IoT à Pub/Sub.
Comment traiter les données
Une fois les données ingérées, elles doivent être traitées ou enrichies afin de les rendre utiles pour les systèmes en aval.
Il existe trois outils principaux qui vous aident à le faire dans Google Cloud :
- Dataproc est essentiellement Hadoop géré. Si vous utilisez l'écosystème Hadoop, vous savez qu'il peut être compliqué à configurer, impliquant des heures, voire des jours. Dataproc peut démarrer un cluster en 90 secondes afin que vous puissiez commencer à analyser les données rapidement.
- Dataprep est un outil intelligent à interface graphique qui aide les analystes de données à traiter les données rapidement sans avoir à écrire de code.
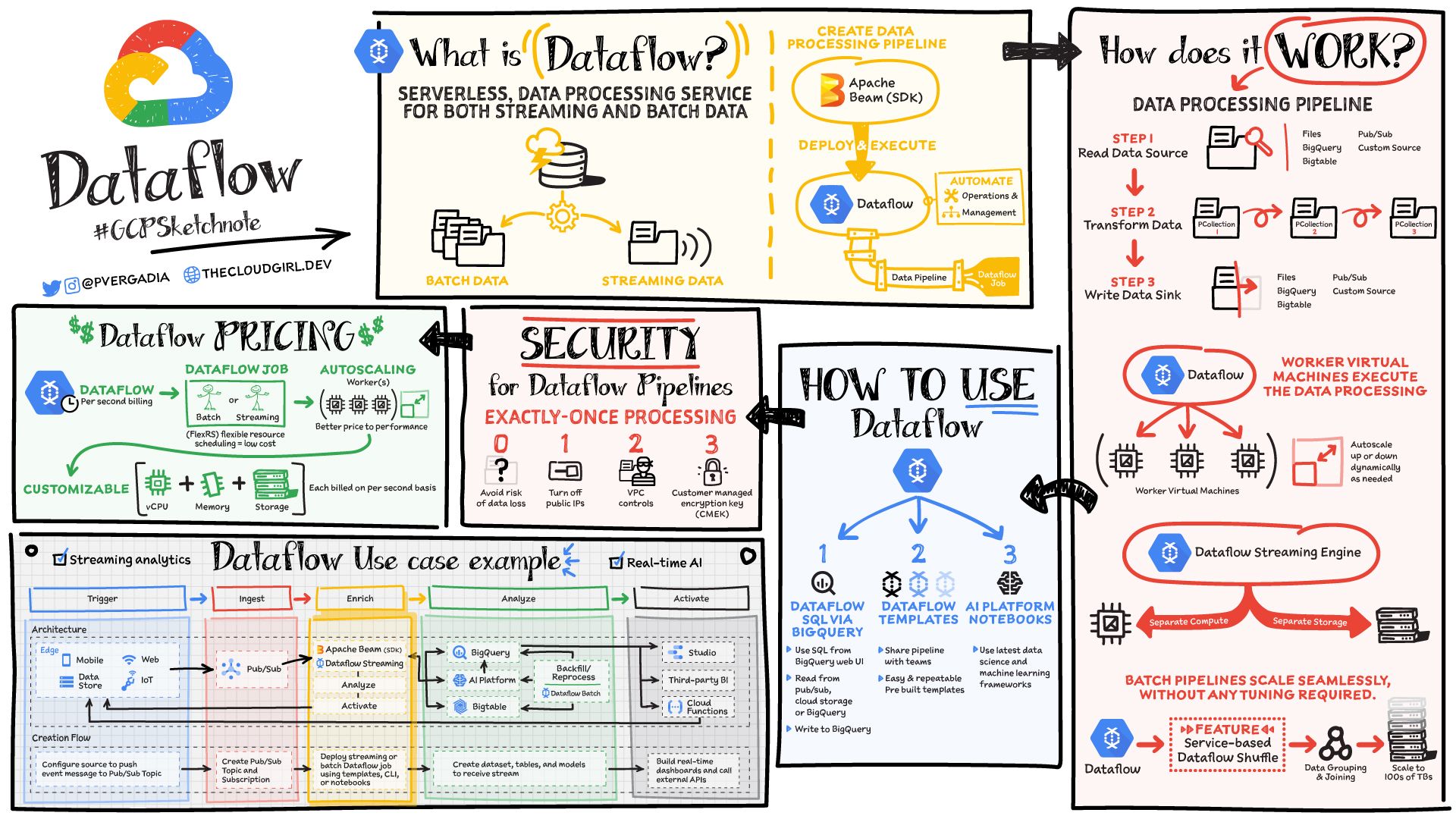
- Dataflow est un service de traitement de données serverless pour les données en streaming et par lots. Il est basé sur le SDK open source Apache Beam, rendant vos pipelines portables. Le service sépare le stockage du calcul, ce qui lui permet de s'adapter de manière transparente. Pour plus de détails, consultez le GCPSketchnote ci-dessous.
Comment stocker les données
Une fois traitées, vous devez stocker les données dans un lac de données ou un entrepôt de données pour soit une archivage à long terme, soit pour des rapports et des analyses.
Il existe deux outils principaux qui vous aident à le faire dans Google Cloud :
Google Cloud Storage est un stockage d'objets pour les images, vidéos, fichiers, etc., qui se décline en 4 types :
- Standard Storage : Idéal pour les données "chaudes" qui sont fréquemment accessibles, y compris les sites web, les vidéos en streaming et les applications mobiles.
- Nearline Storage : Coût faible. Idéal pour les données qui peuvent être stockées pendant au moins 30 jours, y compris les sauvegardes de données et le contenu multimédia de longue traîne.
- Coldline Storage : Coût très faible. Idéal pour les données qui peuvent être stockées pendant au moins 90 jours, y compris la récupération après sinistre.
- Archive Storage : Coût le plus faible. Idéal pour les données qui peuvent être stockées pendant au moins 365 jours, y compris les archives réglementaires.
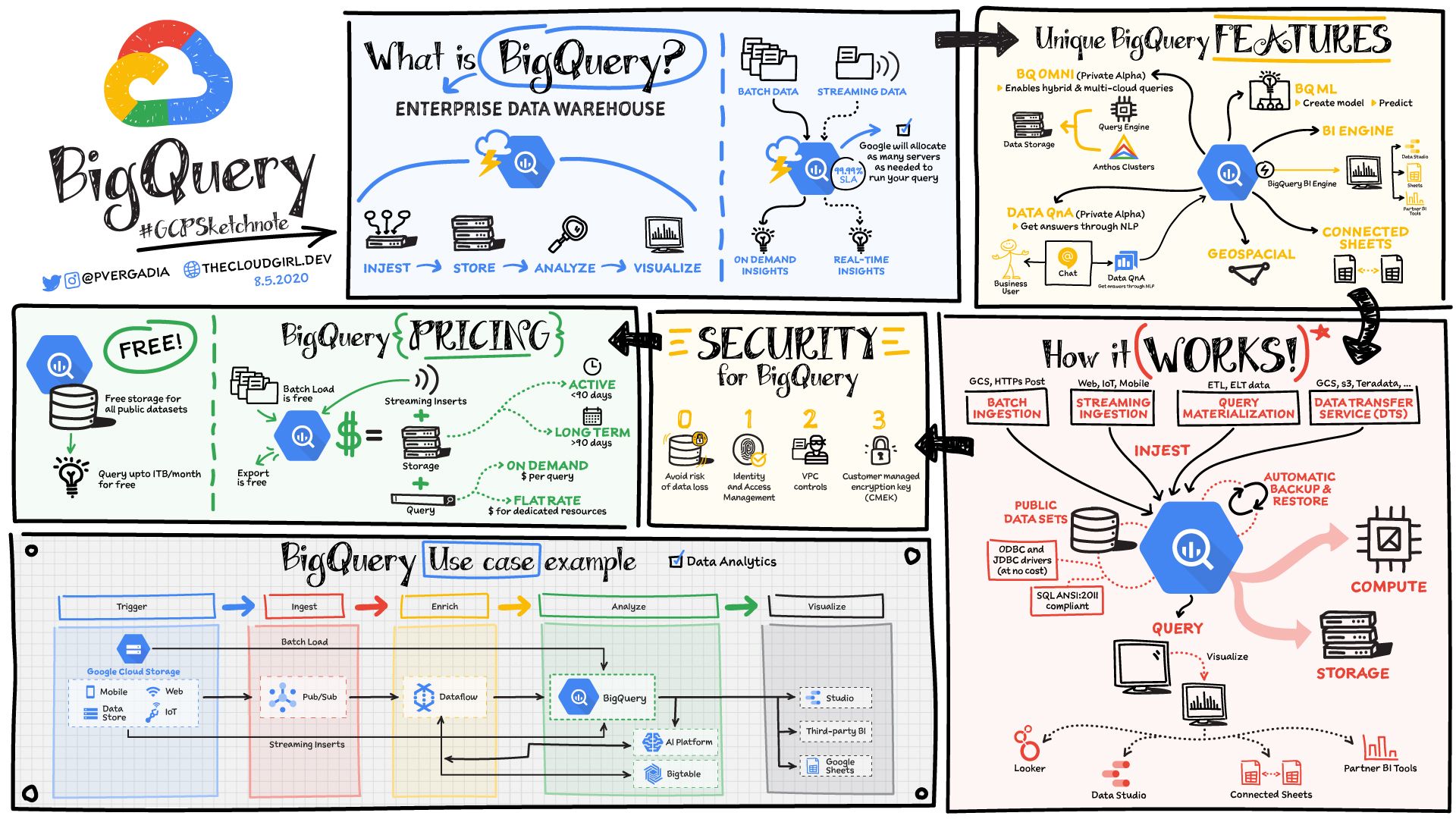
BigQuery est un entrepôt de données serverless qui s'adapte de manière transparente à des pétaoctets de données sans avoir à gérer ou maintenir de serveur.
Vous pouvez stocker et interroger des données dans BigQuery en utilisant SQL. Ensuite, vous pouvez facilement partager les données et les requêtes avec d'autres membres de votre équipe.
Il héberge également des centaines de jeux de données publics gratuits que vous pouvez utiliser dans vos analyses. Et il fournit des connecteurs intégrés à d'autres services afin que les données puissent être facilement ingérées et extraites pour la visualisation ou un traitement/analyse supplémentaire.
Comment analyser les données
Une fois les données traitées et stockées dans un lac de données ou un entrepôt de données, elles sont prêtes à être analysées.
Si vous utilisez BigQuery pour stocker les données, vous pouvez directement analyser ces données dans BigQuery en utilisant SQL.
Si vous utilisez Google Cloud Storage, vous pouvez facilement déplacer les données dans BigQuery.
BigQuery offre également des fonctionnalités de Machine Learning avec BigQueryML. Vous pouvez ainsi créer des modèles et faire des prédictions directement depuis l'interface utilisateur de BigQuery en utilisant le SQL peut-être plus familier.
Comment utiliser et visualiser les données
Utilisation des données
Une fois les données dans l'entrepôt de données, vous pouvez les utiliser pour obtenir des insights et faire des prédictions en utilisant le machine learning.
Pour un traitement et des prédictions supplémentaires, vous pouvez utiliser le framework Tensorflow et AI Platform en fonction de vos besoins.
Tensorflow est une plateforme de machine learning open source de bout en bout avec des outils, des bibliothèques et des ressources communautaires.
AI Platform facilite la tâche des développeurs, des scientifiques des données et des ingénieurs de données pour rationaliser leurs workflows ML. Il inclut des outils pour chaque étape du cycle de vie du ML, de la préparation à la construction, en passant par la validation et le déploiement.
Visualisation des données
Il existe de nombreux outils différents pour la visualisation des données, et la plupart d'entre eux ont un connecteur à BigQuery pour créer facilement des graphiques dans l'outil de votre choix.
Google Cloud fournit quelques outils que vous pourriez trouver utiles.
- Data Studio est gratuit et se connecte non seulement à BigQuery mais aussi à de nombreux autres services pour une visualisation facile des données. Si vous avez utilisé Google Drive, le partage de graphiques et de tableaux de bord est exactement comme cela – extrêmement facile.
- De plus, Looker est une plateforme d'entreprise pour l'intelligence d'affaires, les applications de données et l'analyse intégrée.
Conclusion
Il se passe beaucoup de choses dans un pipeline d'analyse de données. Quels que soient les outils que vous choisissez d'utiliser, assurez-vous qu'ils peuvent évoluer à mesure que vos données grandissent à l'avenir.
Pour plus de contenu similaire, vous pouvez me suivre sur Twitter, @pvergadia et visiter mon site web, thecloudgirl.dev.