

Article original : How to Build a Stress Tester Tool for Debugging Your Code
Par Alberto Gonzalez Rosales
J'ai récemment écrit sur comment les programmeurs compétitifs déboguent leurs solutions pendant les compétitions. Nous tirons parti de la randomisation et de la puissance de calcul des appareils que nous utilisons quotidiennement.
Cet article a été sélectionné comme l'un des gagnants du DebuggingFeb Writeathon et a reçu beaucoup de visibilité de la part de la communauté Hashnode.
Les retours que j'ai reçus de certains des lecteurs ont été la meilleure chose qui est venue avec toute cette visibilité. Ces lecteurs sont ce que j'aime appeler Actifs – ceux qui ne s'arrêtent pas à la fin de l'article mais continuent à poser des questions et à suggérer des améliorations.
L'une des demandes les plus fréquentes que j'ai reçues était de savoir si je pouvais essayer de rendre ce mécanisme de débogage plus similaire à un outil que les développeurs pourraient utiliser facilement dans leurs tâches de codage quotidiennes.
Cet article est ma proposition pour ceux d'entre vous qui continuent à repousser les limites de la connaissance en posant les bonnes questions et en donnant les suggestions appropriées.
Si vous n'avez pas encore lu l'article qui a motivé celui-ci, vous pouvez le faire ici. Une fois que vous êtes familier avec le sujet principal que nous allons discuter, vous pouvez plonger dans la section suivante et lire l'article entier.
C'est parti !
Qu'est-ce que le Stress Testing ?
Bien que je n'aie pas donné de nom à cette technique dans le premier article, elle a un nom propre dans la communauté des développeurs de logiciels. Ce nom est Stress Testing.
Nous pouvons définir le stress testing comme suit :
Le stress testing est une activité de test de logiciels qui détermine la robustesse du logiciel en testant au-delà des limites du fonctionnement normal. Le stress testing est particulièrement important pour les logiciels "mission critical", mais il est utilisé pour tous les types de logiciels.
Les tests de stress mettent généralement plus l'accent sur la robustesse, la disponibilité et la gestion des erreurs sous une charge lourde, que sur ce qui serait considéré comme un comportement correct dans des circonstances normales.
Bien que cette définition soit plus adaptée aux situations réelles de développement de logiciels, nous pouvons l'extrapoler à notre cas d'utilisation. Surtout à cause de la partie "sous une charge lourde".
L'avantage principal de cette approche pour tester les solutions est la capacité à générer des milliers de cas de test et à les exécuter en quelques secondes. Si ce n'est pas une charge lourde, alors qu'est-ce que c'est ?
L'approche consistant à générer des milliers de petits cas d'échantillon pour tester une solution n'est pas seulement utilisée par les programmeurs compétitifs lorsqu'ils essaient de trouver des bugs pendant les compétitions. Les poseurs de problèmes l'utilisent également lorsqu'ils veulent déterminer si une solution proposée pour un problème est effectivement correcte.
J'ai été des deux côtés, et je peux vous dire que les avantages sont remarquables. La vitesse à laquelle vous pouvez trouver des contre-tests pour vos solutions augmente d'au moins un facteur de 10. Cela vous permet de passer moins de temps à déboguer les propositions de solution et plus de temps sur des choses importantes.
Le Problème d'Exemple
Rappelons le problème que nous avons résolu la dernière fois. L'énoncé était le suivant :
"Étant donné un tableau trié d'entiers et un entier
x, trouver le premier indice du tableau contenant le nombrexou retourner-1si le nombre n'apparaît pas dans le tableau".
Nous pouvons résoudre ce problème avec une solution naïve qui parcourt la liste de gauche à droite et s'arrête dès qu'elle trouve un élément égal à x. Si elle atteint la fin de la liste sans trouver l'élément que nous cherchons, elle retourne la valeur -1.
Une implémentation possible en Python est la suivante :
# solutions/naive.py
def naive(a, x):
return next((i for i in range(len(a)) if a[i] == x), -1)
if __name__ == "__main__":
num_list = list(map(int, input().split()))
x = int(input())
print(naive(num_list, x))
Cette solution, bien qu'elle soit correcte, n'est pas assez rapide. Elle effectue une recherche linéaire dans toute la liste, ce qui entraîne une complexité temporelle de O(n), ce qui est suffisamment bon, mais nous pouvons faire mieux.
Pour améliorer notre solution, nous devrions remarquer que nous ne tirons pas parti du fait que notre liste d'entrée est triée. Cela signifie que nous pouvons utiliser l'algorithme de recherche binaire pour rechercher le nombre x.
Notre solution améliorée serait quelque chose comme ceci :
# solutions/solution.py
def solution(a, x):
l = 0
r = len(a) - 1
while l <= r:
m = (l + r) // 2
if a[m] == x:
return m
if a[m] < x:
l = m + 1
else:
r = m - 1
return -1
if __name__ == "__main__":
num_list = list(map(int, input().split()))
x = int(input())
print(solution(num_list, x))
En utilisant la recherche binaire, nous avons réduit la complexité temporelle de notre solution à O(n log n). Mais malheureusement, cette solution contient un bug.
Comment le trouver, alors ? Nous pourrions passer des heures à essayer de générer des cas de test manuels pour vérifier où notre solution échoue.
Eh bien, voici où nous bénéficions de la génération de cas aléatoires. Et voici ma nouvelle proposition pour le faire.
Comment Construire un Outil de Test de Stress
Créons un nouveau projet avec la structure suivante :
stress_tester
|-- generators
|---|-- random_generator.py
|-- solutions
|---|-- naive.py
|---|-- solution.py
|-- test_cases
Comme vous pouvez le voir, il contient un dossier "generators" avec les fichiers de générateur. Dans notre cas, nous utiliserons simplement un générateur aléatoire, mais parfois des générateurs plus spécifiques sont nécessaires.
Il contient également un dossier "solutions" qui stockera notre solution naïve pour le problème et la solution que nous voulons tester.
Enfin, nous avons créé un dossier "test_cases" qui stockera tous les cas de test que nous générons pour les inspecter chaque fois que nous trouvons une différence dans la sortie de nos solutions.
Le générateur que nous allons utiliser pour cet exemple est le suivant :
# generators/random_generator.py
import random
def generate_input():
n = random.randint(1, 10)
a = [random.randint(1, 10) for _ in range(n)]
a.sort()
x = a[random.randint(0, n - 1)]
return a, x
if __name__ == "__main__":
a, x = generate_input()
print(" ".join([str(elem) for elem in a]))
print(x)
Idéalement, ce que nous voulons, c'est générer des cas de test aléatoires, les fournir (un à la fois) à nos deux solutions, et nous arrêter lorsque les sorties retournées pour une entrée donnée sont différentes. Ensuite, nous pouvons examiner le cas de test qui fait échouer notre solution et commencer à corriger nos bugs.
Automatisons ce processus.
Automatisation avec un script shell
Le scripting shell semble être l'option privilégiée ici. Cela est largement utilisé dans les tâches liées à l'automatisation dans des domaines tels que les systèmes d'exploitation et les réseaux. Dans notre cas, nous l'utiliserons pour lier des programmes existants ensemble.
Le fait est que la sortie générée par notre programme random_generator doit être fournie en entrée à nos programmes naïf et solution. Une fois de plus, les sorties de ces deux programmes doivent être fournies en entrée à un autre programme qui indique s'ils sont différents ou non.
La bonne chose est qu'un simple script shell peut nous aider à réaliser tout cela sans trop d'effort.
Créons un fichier à la racine du projet et appelons-le check.sh. Le contenu du fichier doit être le suivant :
# check.sh
# Nombre de cas de test
TEST_CASES=100
# Commandes pour exécuter les scripts Python
RUN_GENERATOR="python3 ./generators/random_generator.py"
RUN_SOLUTION="python3 ./solutions/solution.py"
RUN_NAIVE="python3 ./solutions/naive.py"
# Répertoire de test
TEST_CASES_DIRECTORY="./test_cases"
# Couleurs de la console
RESET_COLOR="\x1b[0m"
OK_COLOR="\x1b[32m"
WA_COLOR="\x1b[31m"
echo "Démarrage du stress testing avec $TEST_CASES cas de test(s)..."
mkdir -p "$TEST_CASES_DIRECTORY" # Créer un répertoire pour stocker les cas de test
for i in `seq -f "%0${#TEST_CASES}g" 1 $TEST_CASES`
do
INPUT="$TEST_CASES_DIRECTORY/input-$i.in"
eval "$RUN_GENERATOR" > "$INPUT" # Générer un cas de test
DIFF=$(diff -w <(eval "$RUN_SOLUTION" < "$INPUT") <(eval "$RUN_NAIVE" < "$INPUT")) # Évaluer le cas de test dans les deux solutions et obtenir leurs différences de sortie
if [ "$DIFF" == "" ] ; then # Même sortie
echo -e " • Cas de test $i: ${OK_COLOR}OK!${RESET_COLOR}"
else # Sortie différente
echo -e " • Cas de test $i: ${WA_COLOR}Wrong Answer!${RESET_COLOR}"
break
fi
done
Expliquons ce qui se passe dans ce code :
- Nous définissons les variables nécessaires telles que le nombre de cas de test que nous allons exécuter, les commandes pour exécuter nos scripts Python de générateur et de solution, et les couleurs à afficher dans la console.
- Nous itérons de
1au nombre de cas que nous avons défini. Chaque fois, nous appelons le script de générateur et redirigeons la sortie vers un fichier en utilisant l'opérateur>. - Ensuite, nous fournissons ce fichier en entrée aux deux solutions en utilisant l'opérateur
<et vérifions les différences en utilisant la commandediff. - Si aucune différence n'est trouvée, nous imprimons
OK!dans la console et passons au cas de test suivant. Sinon, nous imprimonsWrong Answer!et arrêtons le script.
Pour exécuter ce script, nous devons taper la commande suivante dans notre console lorsque nous sommes à la racine de notre projet :
./check.sh
Une sortie similaire à celle-ci devrait apparaître sur votre console après avoir exécuté la commande :
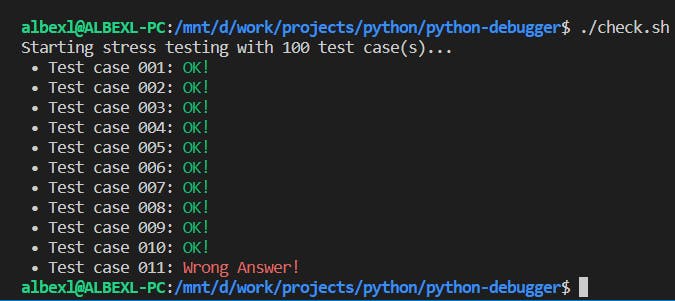
Dans mon cas, il a détecté une différence dans les sorties sur le cas numéro 11. Maintenant, je dois aller analyser ce cas et essayer de corriger les bugs dans mon code. Cela sera beaucoup plus facile maintenant que je connais un cas où ma solution échoue.
Lorsque nous avons fini de corriger notre solution boguée, nous pouvons relancer le script pour vérifier si elle passe tous les cas de test. Espérons que vous obtiendrez un résultat similaire à celui-ci :
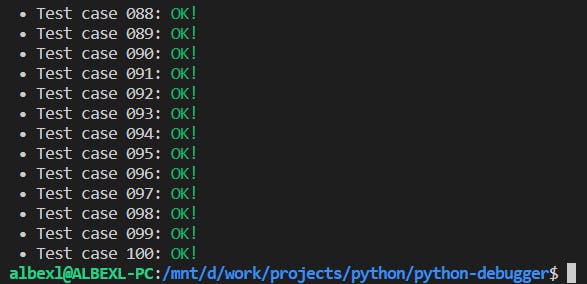
Sinon, corrigez votre solution à nouveau jusqu'à ce que vous y arriviez. Maintenant, vous aurez un nouveau cas de test à analyser.
Automatisation avec un script Python
Bien que nous ayons une solution qui utilise un script shell pour automatiser le processus de vérification, il contient encore quelques détails d'implémentation qui ne me plaisent pas. Le plus important pour moi est que les variables que nous utilisons sont fixes dans le code.
Disons, par exemple, que nous voulons changer le répertoire où se trouvent nos solutions ou où nous stockons les cas de test. Nous devrions aller dans le script et changer la valeur de ces variables à la main.
En cherchant une meilleure solution, j'ai pensé qu'il serait préférable que les valeurs des variables dont nous avons besoin pour faire fonctionner notre script puissent être passées en arguments via la CLI. Comme je ne connais pas beaucoup le langage de script shell, j'ai décidé de créer une alternative en utilisant Python.
Nous allons créer un fichier check.py à la racine de notre projet. Ce fichier contiendra une logique similaire à celle de notre script shell, mais il inclura également l'analyse des arguments de la CLI.
Pour analyser les arguments de la CLI en Python, je me tourne généralement vers la bibliothèque argparse. Elle est suffisamment simple, et la documentation est excellente. Elle vous aidera à créer des applications qui reçoivent des arguments de la console instantanément.
Voyons un exemple de la façon dont une fonction qui analyse les arguments dont nous avons besoin pourrait ressembler :
# check.py
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--test-cases", type=int, required=True)
parser.add_argument("--generator-path", required=True)
parser.add_argument("--solution-path", required=True)
parser.add_argument("--naive-path", required=True)
parser.add_argument("--tests-path", required=True)
return parser.parse_args()
Comme vous pouvez le voir, pour que notre script fonctionne, nous devons spécifier les valeurs des variables suivantes :
test-cases: Le nombre de cas de test à exécuter.generator-path: Le chemin vers le fichier générateur.solution-path: Le chemin vers le fichier solution.naive-path: Le chemin vers le fichier de solution naïve.tests-path: Répertoire pour stocker les cas de test.
Après que toutes nos variables ont été analysées, nous devons appeler la fonction qui exécutera le même flux de travail que le script shell.
Pour obtenir ce comportement à partir d'un script Python, j'ai utilisé la bibliothèque subprocess, qui permet l'exécution de commandes dans la console et redirige les entrées et les sorties. Pour les couleurs, j'ai utilisé la bibliothèque colorama.
Voici un exemple de la façon dont cette fonction pourrait ressembler :
# check.py
def check(
test_cases: int,
generator_path: str,
solution_path: str,
naive_path: str,
tests_path: str,
) -> bool:
print(f"Démarrage du stress testing avec {test_cases} cas de test(s)...")
for i in range(1, test_cases + 1):
# Générer un cas de test aléatoire
with open(f"{tests_path}/input-{i}.in", "w", encoding="utf-8") as test_case:
subprocess.run(["python3", generator_path], stdout=test_case)
# Ouvrir le fichier d'entrée du cas de test
with open(f"{tests_path}/input-{i}.in", "r", encoding="utf-8") as test_case:
# Exécuter la solution et stocker la sortie dans un fichier
with open(f"{tests_path}/solution-{i}.out", "w", encoding="utf-8") as solution_file:
test_case.seek(0)
subprocess.run(["python3", solution_path], stdin=test_case, stdout=solution_file)
# Exécuter la solution naïve et stocker la sortie dans un fichier
with open(f"{tests_path}/naive-{i}.out", "w", encoding="utf-8") as naive_file:
test_case.seek(0)
subprocess.run(["python3", naive_path], stdin=test_case, stdout=naive_file)
# Vérifier les différences dans les deux fichiers de sortie
output = subprocess.run(
["diff", f"{tests_path}/solution-{i}.out", f"{tests_path}/naive-{i}.out"], stdout=subprocess.PIPE
)
# Code de retour différent de 0 signifie que les sorties diffèrent
if output.returncode == 0:
print(f" • Cas de test {i}: {Fore.GREEN}OK!{Fore.WHITE}")
else:
print(f" • Cas de test {i}: {Fore.RED}Wrong Answer!{Fore.WHITE}")
return False
return True
Et notre fonction principale ressemblerait à ceci :
# check.py
def _main():
args = parse_args()
check(
args.test_cases,
args.generator_path,
args.solution_path,
args.naive_path,
args.tests_path,
)
if __name__ == "__main__":
_main()
Pour exécuter ce script, il est nécessaire de lancer la commande suivante à la racine du projet :
python3 check.py --test-cases 100 --generator-path ./generators/random_generator.py --solution-path ./solutions/solution.py --naive-path ./solutions/naive.py --tests-path ./test_cases
Comme vous pouvez le voir, il est maintenant possible de modifier les valeurs des paramètres à partir de la CLI sans avoir à affecter le code. Par exemple, nous pourrions augmenter le nombre de cas de test que nous voulons exécuter à 1000.
Après avoir exécuté cette commande, nous obtenons la sortie suivante dans notre console :
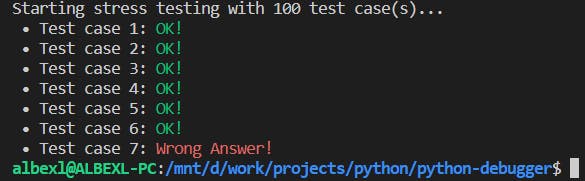
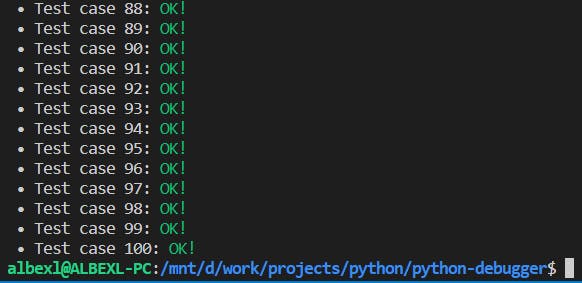
Maintenant, il a échoué au cas de test numéro 7. Après avoir inspecté le cas de test et corrigé notre solution, nous devrions obtenir quelque chose comme ceci :
Conclusions
Dans cet article, nous avons appris comment créer un outil automatisé pour tester nos solutions contre des cas de test générés aléatoirement. Nous avons automatisé le processus en utilisant un script shell puis nous avons fait une version Python, en utilisant des bibliothèques telles que argparse et subprocess.
Pouvoir trouver des contre-tests pour vos solutions est un aspect crucial du développement de logiciels. Bien que ce soit un exemple éducatif et simple, il présente de multiples similitudes avec des cas réels. Essayez cela et faites-moi savoir vos réflexions à ce sujet !
De plus, j'aimerais continuer à améliorer cet outil un peu, mais je n'ai pas beaucoup de temps pour le faire seul. Il serait formidable d'avoir quelques contributeurs sur le dépôt GitHub où je garde le code utilisé dans cet article. J'ai commencé à écrire quelques améliorations possibles. Contactez-moi si vous voulez collaborer à cela.
À bientôt !
Sources
- Les exemples de code utilisés dans cet article peuvent être trouvés ici.
- Stress Testing : Article de Wikipedia sur le stress testing dans les logiciels.
- How to test your solution in Competitive Programming par Kamil Debowski : Vidéo YouTube expliquant certains des sujets discutés, avec des exemples de code en C++.
👋 Bonjour, je suis Alberto, Développeur de Logiciels chez doWhile, Programmeur Compétitif, Enseignant et Passionné de Fitness.
🏆 Si vous avez aimé cet article, envisagez de le partager.
🔗 Tous les liens | Twitter | LinkedIn