
Article original : How to build a recommendation engine using Apache’s Prediction IO Machine Learning Server
Par Vaghawan Ojha
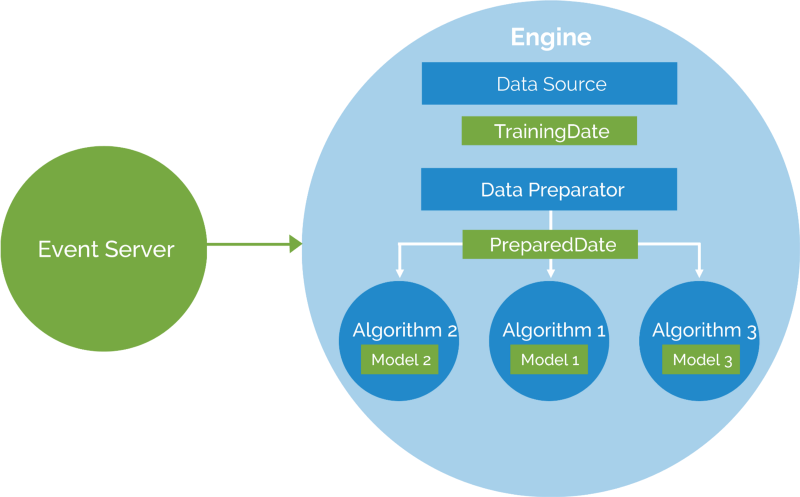
Cet article vous guidera à travers l'installation du serveur d'apprentissage automatique Apache Prediction IO. Nous utiliserons l'un de ses modèles appelé Recommendation pour construire un moteur de recommandation fonctionnel. Le produit fini sera capable de recommander des produits personnalisés en fonction du comportement d'achat d'un utilisateur donné.
Le Problème
Vous avez une quantité de données et vous devez prédire quelque chose avec précision afin d'aider votre entreprise à augmenter ses ventes, ses clients, ses profits, ses conversions, ou tout autre besoin commercial.
Les systèmes de recommandation sont probablement la première étape que tout le monde franchit pour appliquer la science des données et l'apprentissage automatique. Les moteurs de recommandation utilisent les données comme entrée et exécutent leurs algorithmes sur celles-ci. Ensuite, ils génèrent des modèles à partir desquels nous pouvons faire des prédictions sur ce qu'un utilisateur va vraiment acheter, ou ce qu'un utilisateur peut aimer ou ne pas aimer.
Présentation de Prediction IO
« Apache PredictionIO (en incubation) est un serveur d'apprentissage automatique open source construit sur une pile open source de pointe pour permettre aux développeurs et aux scientifiques des données de créer des moteurs prédictifs pour toute tâche d'apprentissage automatique. » — Documentation Apache Prediction IO
Le premier coup d'œil à la documentation me donne une bonne impression car il me donne accès à une pile technologique puissante pour résoudre les problèmes d'apprentissage automatique. Ce qui est encore plus intéressant, c'est que Prediction IO donne accès à de nombreux modèles, qui sont utiles pour résoudre des problèmes réels.
La galerie de modèles contient de nombreux modèles pour la recommandation, la classification, la régression, le traitement du langage naturel, et bien plus encore. Elle utilise des technologies comme Apache Hadoop, Apache Spark, ElasticSearch et Apache HBase pour rendre le serveur d'apprentissage automatique scalable et efficace. Je ne vais pas parler beaucoup de Prediction IO lui-même, car vous pouvez le faire vous-même ici.
Revenons donc au problème : j'ai une quantité de données provenant des historiques d'achats des utilisateurs, qui contiennent user_id, product_id et purchased_date. En utilisant ces données, je dois faire une prédiction/recommandation personnalisée à l'utilisateur. Considérant ce problème, nous utiliserons un modèle de recommandation avec le serveur d'apprentissage automatique Prediction IO. Nous utiliserons également le serveur d'événements Prediction IO ainsi que l'importation de données en masse.
Alors, avançons. (Note : Ce guide suppose que vous utilisez un système Ubuntu pour l'installation)
Étape #1 : Télécharger Apache Prediction IO
Allez dans le répertoire personnel de votre utilisateur actuel et téléchargez la dernière version 0.10.0 de Prediction IO apache incubator. Je suppose que vous êtes dans le répertoire suivant _(/home/you/)_
git clone git@github.com:apache/incubator-predictionio.git
Maintenant, allez dans le répertoire _incubator-predictionio_ où nous avons cloné le dépôt Prediction IO. Si vous l'avez cloné dans un répertoire différent, assurez-vous d'être dans ce répertoire dans votre terminal.
Maintenant, passons à la version stable actuelle de Prediction IO qui est la 0.10.0
cd incubator-predictionio # ou tout autre répertoire où vous avez cloné pio.git checkout release/0.10.0
Étape #2 : Créer une distribution de Prediction IO
./make-distribution.sh
Si tout s'est bien passé, vous obtiendrez un message comme celui-ci dans votre console :
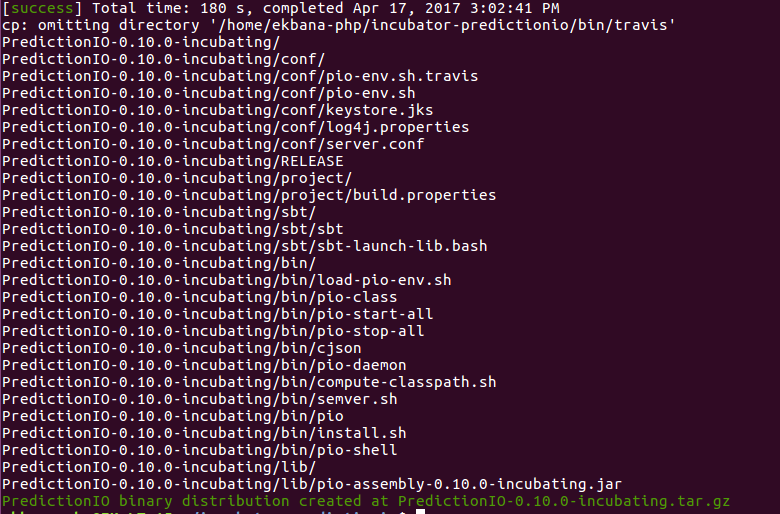
Cependant, si vous rencontrez quelque chose comme ceci :

alors vous devrez supprimer le répertoire _.ivy2_ dans votre répertoire personnel, par défaut ce dossier est caché. Vous devez le supprimer complètement puis relancer la commande _./make-distribution.sh_ pour que le build génère avec succès un fichier de distribution.
Personnellement, j'ai rencontré ce problème à plusieurs reprises, mais je ne suis pas sûr que ce soit la méthode valide pour résoudre ce problème. Mais supprimer le dossier _.ivy2_ et relancer la commande make-distribution fonctionne.
Étape #3 : Extraire le fichier de distribution
Après le build réussi, nous aurons un fichier nommé PredictionIO-0.10.0-incubating.tar.gz dans le répertoire où nous avons construit notre Prediction IO. Maintenant, extrayons-le dans un répertoire appelé pio.
mkdir ~/piotar zxvf PredictionIO-0.10.0-incubating.tar.gz -C ~/pio
Assurez-vous que le nom du fichier tar.gz correspond au fichier de distribution que vous avez dans le répertoire original predictionIo. Si vous avez oublié de vérifier la version 0.10.0 de Prediction IO, vous êtes sûr d'obtenir un nom de fichier différent, car par défaut la version serait la dernière.
Étape #4 : Préparer le téléchargement des dépendances
cd ~/pio
#Créons un dossier vendors dans ~/pio/PredictionIO-0.10.0-incubating où nous sauvegarderons hadoop, elasticsearch et hbase.
mkdir ~/pio/PredictionIO-0.10.0-incubating/vendors
Étape #5 : Télécharger et configurer Spark
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.5.1-bin-hadoop2.6.tgz
Si votre répertoire actuel est ~/pio, la commande téléchargera spark dans le répertoire pio. Maintenant, extrayons-le. Selon l'endroit où vous l'avez téléchargé, vous pourriez vouloir changer la commande ci-dessous.
tar zxvfC spark-1.5.1-bin-hadoop2.6.tgz PredictionIO-0.10.0-incubating/vendors
# Cela extraira la configuration spark que nous avons téléchargée et la placera dans le dossier vendors de notre nouvelle installation pio.
Assurez-vous d'avoir fait _mkdir PredictionIO-0.10.0-incubating/vendors_ plus tôt.
Étape #6 : Télécharger et configurer ElasticSearch
wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.4.tar.gz
#Extrayons elastic search dans le dossier vendors.
tar zxvfC elasticsearch-1.4.4.tar.gz PredictionIO-0.10.0-incubating/vendors
Étape #7 : Télécharger et configurer Hbase
wget http://archive.apache.org/dist/hbase/hbase-1.0.0/hbase-1.0.0-bin.tar.gz
#Extrayons-le.
tar zxvfC hbase-1.0.0-bin.tar.gz PredictionIO-0.10.0-incubating/vendors
Maintenant, éditons le fichier _hbase-site.xml_ pour pointer la configuration hbase vers le bon répertoire. En supposant que vous êtes dans le répertoire _~/pio_, vous pouvez exécuter cette commande et éditer la configuration hbase.
nano PredictionIO-0.10.0-incubating/vendors/hbase-1.0.0/conf/hbase-site.xml
Remplacez le bloc de configuration par la configuration suivante.
<configuration> <property> <name>hbase.rootdir</name> <value>file:///home/you/pio/PredictionIO-0.10.0-incubating/vendors/hbase-1.0.0/data</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/you/pio/PredictionIO-0.10.0-incubating/vendors/hbase-1.0.0/zookeeper</value> </property></configuration>
Ici, « you » signifie votre répertoire utilisateur, par exemple si vous faites tout cela en tant qu'utilisateur « tom », ce serait quelque chose comme file::///home/tom/…
Assurez-vous que les bons fichiers sont présents.
Maintenant, configurons JAVA_HOME dans hbase-env.sh.
nano PredictionIO-0.10.0-incubating/vendors/hbase-1.0.0/conf/hbase-env.sh
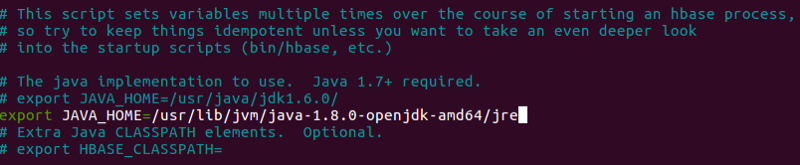
Si vous n'êtes pas sûr de la version de JDK que vous utilisez actuellement, suivez ces étapes et apportez les modifications nécessaires si nécessaire.
Nous avons besoin de Java SE Development Kit 7 ou supérieur pour que Prediction IO fonctionne. Maintenant, assurons-nous que nous utilisons la bonne version en exécutant :
sudo update-alternatives --config java
Par défaut, j'utilise :
java -version
openjdk version "1.8.0_121"
OpenJDK Runtime Environment (build 1.8.0_121–8u121-b13–0ubuntu1.16.04.2-b13)
OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode)
Si vous utilisez une version inférieure à 1.7, vous devez changer la configuration java pour utiliser une version de java égale ou supérieure à 1.7. Vous pouvez changer cela avec la commande update-alternatives comme indiqué ci-dessus. Dans mon cas, la commande sudo update-alternatives -config java produit quelque chose comme ceci :

Si vous avez des problèmes pour configurer cela, vous pouvez suivre ce lien.
Maintenant, exportons le chemin JAVA_HOME dans le fichier .bashrc à l'intérieur de /home/you/pio.
En supposant que vous êtes dans le répertoire ~/pio, vous pouvez faire ceci : nano .bashrc
N'oubliez pas de faire source .bashrc après avoir configuré le chemin java dans le .bashrc.
Étape #8 : Configurer l'environnement Prediction IO
Maintenant, configurons pio.env.sh pour donner une touche finale à notre installation du serveur d'apprentissage automatique Prediction IO.
nano PredictionIO-0.10.0-incubating/conf/pio-env.sh
Nous n'utilisons pas ProsgesSQl ou MySql pour notre serveur d'événements, alors commentons cette section et avons un pio-env.sh comme ceci :
#!/usr/bin/env bash## Copiez ce fichier en tant que pio-env.sh et éditez-le pour la configuration de votre site.## Licencié à la Apache Software Foundation (ASF) sous une ou plusieurs# licences de contributeur. Voir le fichier NOTICE distribué avec# ce travail pour des informations supplémentaires concernant la propriété des droits d'auteur.# L'ASF vous licence ce fichier sous la Licence Apache, Version 2.0# (la "Licence") ; vous ne pouvez pas utiliser ce fichier sauf en conformité avec# la Licence. Vous pouvez obtenir une copie de la Licence à## http://www.apache.org/licenses/LICENSE-2.0## Sauf si requis par la loi applicable ou convenu par écrit, le logiciel# distribué sous la Licence est distribué "TEL QUEL",# SANS GARANTIES OU CONDITIONS DE QUELQUE NATURE QUE CE SOIT, expresses ou implicites.# Voir la Licence pour le langage spécifique régissant les permissions et# les limitations sous la Licence.#
# Configuration principale de PredictionIO## Cette section contrôle le comportement principal de PredictionIO. Il est très probable que# vous deviez changer ces paramètres pour les adapter à votre site.
# SPARK_HOME : Apache Spark est une dépendance obligatoire et doit être configuré.SPARK_HOME=$PIO_HOME/vendors/spark-1.5.1-bin-hadoop2.6
POSTGRES_JDBC_DRIVER=$PIO_HOME/lib/postgresql-9.4-1204.jdbc41.jarMYSQL_JDBC_DRIVER=$PIO_HOME/lib/mysql-connector-java-5.1.37.jar
# ES_CONF_DIR : Vous devez configurer ceci si vous avez une configuration avancée pour# votre installation Elasticsearch. ES_CONF_DIR=$PIO_HOME/vendors/elasticsearch-1.4.4/conf
# HADOOP_CONF_DIR : Vous devez configurer ceci si vous avez l'intention d'exécuter PredictionIO# avec Hadoop 2. HADOOP_CONF_DIR=$PIO_HOME/vendors/spark-1.5.1-bin-hadoop2.6/conf
# HBASE_CONF_DIR : Vous devez configurer ceci si vous avez l'intention d'exécuter PredictionIO# avec HBase sur un cluster distant. HBASE_CONF_DIR=$PIO_HOME/vendors/hbase-1.0.0/conf
# Chemins du système de fichiers où PredictionIO utilise le stockage par blocs.PIO_FS_BASEDIR=$HOME/.pio_storePIO_FS_ENGINESDIR=$PIO_FS_BASEDIR/enginesPIO_FS_TMPDIR=$PIO_FS_BASEDIR/tmp
# Configuration du stockage PredictionIO## Cette section contrôle les programmes qui utilisent les# installations de stockage intégrées de PredictionIO. Les valeurs par défaut sont affichées ci-dessous.## Pour plus d'informations sur la configuration du stockage, veuillez vous référer à# http://predictionio.incubator.apache.org/system/anotherdatastore/
# Référentiels de stockage
# Par défaut, utilise PostgreSQLPIO_STORAGE_REPOSITORIES_METADATA_NAME=pio_metaPIO_STORAGE_REPOSITORIES_METADATA_SOURCE=ELASTICSEARCH
PIO_STORAGE_REPOSITORIES_EVENTDATA_NAME=pio_eventPIO_STORAGE_REPOSITORIES_EVENTDATA_SOURCE=HBASE
PIO_STORAGE_REPOSITORIES_MODELDATA_NAME=pio_modelPIO_STORAGE_REPOSITORIES_MODELDATA_SOURCE=LOCALFS
# Sources de données de stockage
# Paramètres par défaut de PostgreSQL# Veuillez changer "pio" par le nom de votre base de données dans PIO_STORAGE_SOURCES_PGSQL_URL# Veuillez changer PIO_STORAGE_SOURCES_PGSQL_USERNAME et# PIO_STORAGE_SOURCES_PGSQL_PASSWORD en conséquence# PIO_STORAGE_SOURCES_PGSQL_TYPE=jdbc# PIO_STORAGE_SOURCES_PGSQL_URL=jdbc:postgresql://localhost/pio# PIO_STORAGE_SOURCES_PGSQL_USERNAME=pio# PIO_STORAGE_SOURCES_PGSQL_PASSWORD=root
# Exemple MySQL# PIO_STORAGE_SOURCES_MYSQL_TYPE=jdbc# PIO_STORAGE_SOURCES_MYSQL_URL=jdbc:mysql://localhost/pio# PIO_STORAGE_SOURCES_MYSQL_USERNAME=root# PIO_STORAGE_SOURCES_MYSQL_PASSWORD=root
# Exemple Elasticsearch PIO_STORAGE_SOURCES_ELASTICSEARCH_TYPE=elasticsearch PIO_STORAGE_SOURCES_ELASTICSEARCH_CLUSTERNAME=firstcluster PIO_STORAGE_SOURCES_ELASTICSEARCH_HOSTS=localhost PIO_STORAGE_SOURCES_ELASTICSEARCH_PORTS=9300 PIO_STORAGE_SOURCES_ELASTICSEARCH_HOME=$PIO_HOME/vendors/elasticsearch-1.4.4
# Exemple de système de fichiers localPIO_STORAGE_SOURCES_LOCALFS_TYPE=localfsPIO_STORAGE_SOURCES_LOCALFS_PATH=$PIO_FS_BASEDIR/models
# Exemple HBasePIO_STORAGE_SOURCES_HBASE_TYPE=hbasePIO_STORAGE_SOURCES_HBASE_HOME=$PIO_HOME/vendors/hbase-1.0.0
Étape #9 : Configurer le nom du cluster dans la configuration ElasticSearch
Puisque cette ligne PIO_STORAGE_SOURCES_ELASTICSEARCH_CLUSTERNAME=firstcluster pointe vers le nom de notre cluster dans la configuration ElasticSearch, remplaçons le nom du cluster par défaut dans la configuration ElasticSearch.
nano PredictionIO-0.10.0-incubating/vendors/elasticsearch-1.4.4/config/elasticsearch.yml
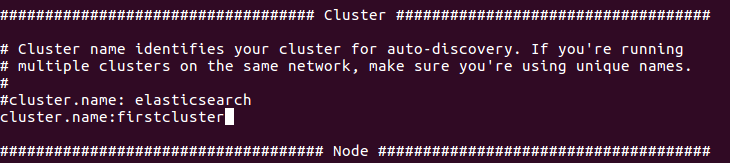
Étape #10 : Exporter le chemin Prediction IO
Exportons maintenant le chemin Prediction IO afin de pouvoir utiliser librement la commande pio sans pointer vers son bin à chaque fois. Exécutez la commande suivante dans votre terminal :
PATH=$PATH:/home/you/pio/PredictionIO-0.10.0-incubating/bin; export PATH
Étape #11 : Donner la permission à l'installation de Prediction IO
sudo chmod -R 775 ~/pio
Cela est vital car si nous n'avons pas donné la permission au dossier pio, le processus Prediction IO ne pourra pas écrire les fichiers de journalisation.
Étape #12 : Démarrer le serveur Prediction IO
Maintenant, nous sommes prêts à démarrer notre serveur Prediction IO. Avant d'exécuter cette commande, assurez-vous d'avoir exporté le chemin pio décrit ci-dessus.
pio-start-all
#if vous avez oublié d'exporter le chemin pio, cela ne fonctionnera pas et vous devrez pointer manuellement le chemin bin de pio.
Si tout est correct à ce stade, vous devriez voir une sortie comme ceci.

Note : Si vous oubliez de donner la permission, il y aura des problèmes d'écriture des logs et si votre chemin JAVA_HOME est incorrect, HBASE ne démarrera pas correctement et vous donnera une erreur.
Étape #13 : Vérifier le processus
Maintenant, vérifions notre installation avec pio status, si tout est correct, vous obtiendrez une sortie comme ceci :
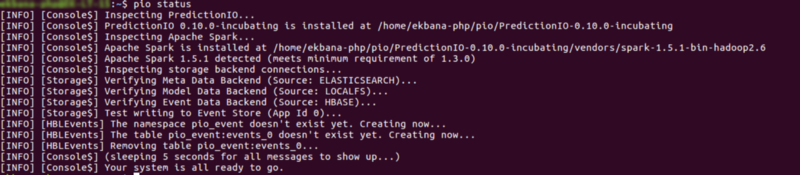
Si vous rencontrez une erreur dans Hbase ou tout autre stockage backend, assurez-vous que tout a été démarré correctement.
Notre serveur Prediction IO est prêt à implémenter le modèle maintenant.
Implémentation du Moteur de Recommandation
Un modèle de moteur de recommandation est un modèle de moteur Prediction IO qui utilise le filtrage collaboratif pour faire des recommandations personnalisées à l'utilisateur. Il peut être utilisé sur un site de commerce électronique, un site d'actualités, ou toute application qui collecte les historiques d'événements des utilisateurs pour offrir une expérience personnalisée à l'utilisateur.
Nous allons implémenter ce modèle dans Prediction IO avec quelques données d'utilisateurs de commerce électronique, juste pour faire une expérience d'échantillon avec le serveur d'apprentissage automatique Prediction IO.
Maintenant, retournons à notre répertoire personnel cd ~
Étape #14 : Télécharger le modèle de recommandation
pio template get apache/incubator-predictionio-template-recommender MyRecommendation
Il vous demandera le nom de la société et le nom de l'auteur, entrez-les successivement, maintenant nous avons un modèle MyRecommendation dans notre répertoire personnel. Juste un rappel : vous pouvez mettre le modèle où vous voulez.
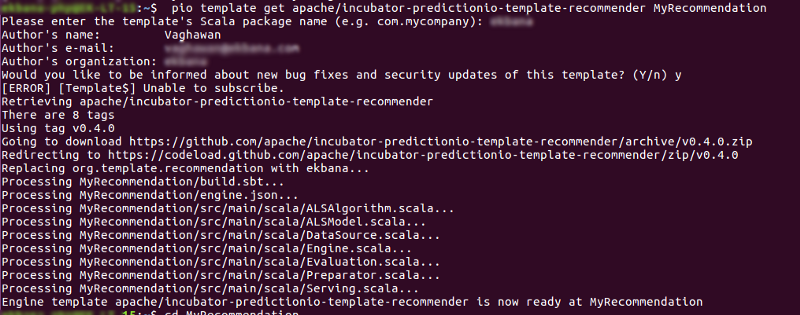
#15. Créer notre première application Prediction IO
Maintenant, allons dans le répertoire MyRecommendation cd MyRecommendation
Après être entré dans le répertoire du modèle, créons notre première application Prediction IO appelée ourrecommendation.
Vous obtiendrez une sortie comme celle-ci. Veuillez noter que vous pouvez donner n'importe quel nom à votre application, mais pour cet exemple, j'utiliserai le nom d'application ourrecommendation.
pio app new ourrecommendation
Cette commande produira quelque chose comme ceci :

Vérifions que notre nouvelle application est présente avec cette commande :
pio app list
Maintenant, notre application devrait être listée dans la liste.
Étape #16 : Importer quelques données d'exemple
Téléchargeons les données d'exemple depuis gist, et plaçons-les dans le dossier importdata à l'intérieur du dossier MyRecommendation.
mkdir importdata
Copiez le fichier sample-data.json que vous venez de créer dans le dossier importdata.
Enfin, importons les données dans notre application ourrecommendation. En supposant que vous êtes dans le répertoire MyRecommendation, vous pouvez faire ceci pour importer les événements par lots.
pio import -- appid 1 -- input importdata/data-sample.json
(Note : assurez-vous que l'appid de ourrecommendation est le même que celui de votre appid que vous venez de fournir)
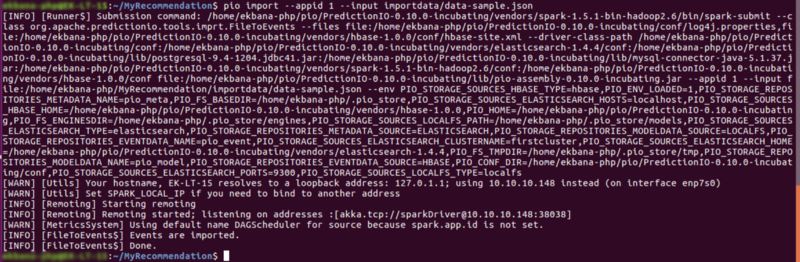
Étape #17 : Construire l'application
Avant de construire l'application, éditons le fichier engine.json à l'intérieur du répertoire MyRecommendation pour répliquer le nom de notre application à l'intérieur. Il devrait ressembler à quelque chose comme ceci :
Note : Ne copiez pas ceci, changez simplement le « appName » dans votre engine.json.
{ "id": "default", "description": "Paramètres par défaut", "engineFactory": "orgname.RecommendationEngine", "datasource": { "params" : { "appName": "ourrecommendation" } }, "algorithms": [ { "name": "als", "params": { "rank": 10, "numIterations": 5, "lambda": 0.01, "seed": 3 } } ]}
Note : le « engineFactory » sera généré automatiquement lorsque vous téléchargez le modèle dans notre étape 14, donc vous n'avez pas à le changer. Dans mon cas, c'est mon orgname, que j'ai mis dans l'invite du terminal lors de l'installation du modèle. Dans votre engine.json, vous devez simplement modifier le appName, veuillez ne pas changer autre chose.
Dans le même répertoire où se trouve notre modèle de moteur MyRecommendation, exécutons cette commande pio pour construire notre application.
pio build
(Note : si vous voulez voir tous les messages pendant le processus de construction, vous pouvez exécuter ceci pio build -- verbose)
Cela peut prendre un certain temps pour construire notre application, puisque c'est la première fois. À partir de la prochaine fois, cela prendra moins de temps. Vous devriez obtenir une sortie comme ceci :

Notre moteur est maintenant prêt à entraîner nos données.
Étape #18 : Entraîner le jeu de données
pio train
Si vous obtenez une erreur comme celle ci-dessous au milieu de l'entraînement, alors vous devrez peut-être changer le nombre d'itérations dans votre engine.json et reconstruire l'application.

Changeons le numItirations dans engine.json qui est par défaut 20 à 5 :
"numIterations": 5,
Maintenant, construisons l'application avec pio build, puis faisons pio train. L'entraînement devrait être terminé avec succès. Après avoir terminé l'entraînement, vous obtiendrez le message comme ceci :

Veuillez noter que cet entraînement fonctionne uniquement pour les petites données, si vous souhaitez essayer avec un grand ensemble de données, nous devrions configurer un worker spark autonome pour accomplir l'entraînement. (J'écrirai à ce sujet dans un futur article.)
Étape #19 : Déployer et servir la prédiction
pio deploy#par défaut, il prendra le port 8000.
Nous aurons maintenant notre serveur de prédiction io en cours d'exécution.
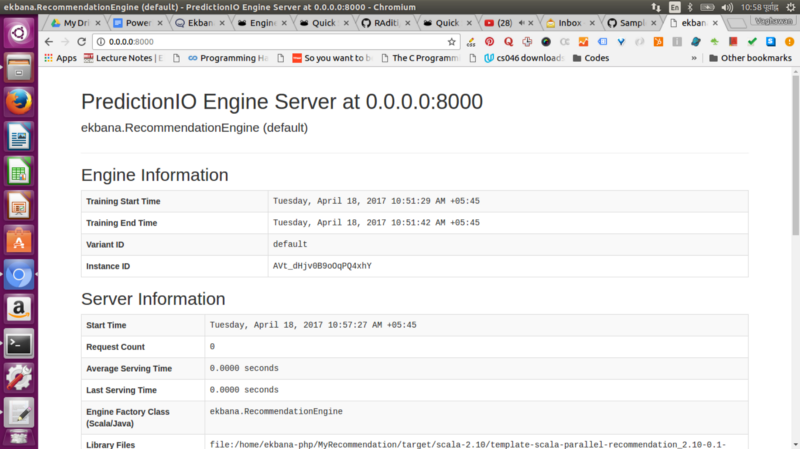
Note : pour garder cela simple, je ne discute pas du serveur d'événements dans cet article, car cela pourrait être encore plus long, nous nous concentrons donc sur un cas d'utilisation simple de Prediction IO.
Maintenant, obtenons la prédiction en utilisant curl.
Ouvrez un nouveau terminal et tapez :
curl -H "Content-Type: application/json" \-d '{"user":"user1","num":4}' http://localhost:8000/queries.json
Dans la requête ci-dessus, l'utilisateur signifie l'user_id dans nos données d'événement, et le num signifie combien de recommandations nous voulons obtenir.
Maintenant, vous obtiendrez le résultat comme ceci :
{"itemScores":[{"item":"product5","score":3.9993937903501093},{"item":"product101","score":3.9989989282500904},{"item":"product30","score":3.994934059438341},{"item":"product98","score":3.1035806376677866}]}
C'est tout ! Bon travail. Nous avons terminé. Mais attendez, qu'est-ce qui suit ?
- Ensuite, nous utiliserons un cluster spark autonome pour entraîner un grand jeu de données (croyez-moi, c'est facile, si vous voulez le faire maintenant, vous pouvez suivre la documentation dans Prediction IO)
- Nous utiliserons Universal Recommender from Action ML pour construire un moteur de recommandation.
Notes importantes :
- Le modèle que nous avons utilisé utilise l'algorithme ALS avec un retour explicite, cependant, vous pouvez facilement passer à un retour implicite en fonction de vos besoins.
- Si vous êtes curieux à propos de Prediction IO et que vous souhaitez en savoir plus, vous pouvez le faire sur le site officiel de Prediction IO.
- Si votre version de Java n'est pas adaptée à la spécification de Prediction IO, vous êtes sûr de rencontrer des problèmes. Assurez-vous donc de configurer cela en premier.
- N'exécutez aucune des commandes décrites ci-dessus avec
sudosauf pour donner des permissions. Sinon, vous rencontrerez des problèmes. - Assurez-vous que votre chemin java est correct, et assurez-vous d'exporter le chemin Prediction IO. Vous pourriez vouloir ajouter le chemin Prediction IO à votre .bashrc ou profil également en fonction de vos besoins.
Mise à jour 2017/07/14 : Utilisation de Spark pour entraîner des ensembles de données réels
Nous avons installé spark dans nos dossiers vendors, avec notre installation actuelle, notre bin spark se trouve dans le répertoire suivant.
~/pio/PredictionIO-0.10.0-incubating/vendors/spark-1.5.1-bin-hadoop2.6/sbin
À partir de là, nous devons configurer un primaire spark et une réplique pour exécuter l'entraînement de notre modèle afin de l'accomplir plus rapidement. Si votre entraînement semble bloqué, nous pouvons utiliser les options spark pour accomplir les tâches d'entraînement.
#Démarrer le primaire Spark
~/pio/PredictionIO-0.10.0-incubating/vendors/spark-1.5.1-bin-hadoop2.6/sbin/start-master.sh
Cela démarrera le primaire spark. Maintenant, parcourons l'interface web du primaire spark en allant sur http://localhost:8080/ dans le navigateur.
Maintenant, copions l'URL primaire pour démarrer le worker réplique. Dans notre cas, l'URL spark primaire est quelque chose comme ceci :
spark://your-machine:7077 (votre machine signifie le nom de votre machine)
~/pio/PredictionIO-0.10.0-incubating/vendors/spark-1.5.1-bin-hadoop2.6/sbin/start-slave.sh spark://your-machine:7077
Le worker démarrera. Actualisez l'interface web, vous verrez le worker enregistré cette fois. Maintenant, exécutons à nouveau l'entraînement.
pio train -- --master spark://localhost:7077 --driver-memory 4G --executor-memory 6G
Génial !
Remerciements spéciaux : Pat Ferrel de Action ML & Marius Rabenarivo