


Article original : How to Build End-to-End Machine Learning Lineage
Le lignage d'apprentissage automatique (ML lineage) est essentiel dans tout système ML robuste. Il vous permet de suivre les versions des données et des modèles, garantissant ainsi la reproductibilité, l'auditabilité et la conformité.
Bien qu'il existe de nombreux services pour suivre le lignage ML, la création d'un lignage complet et gérable s'avère souvent complexe.
Dans cet article, je vais vous guider à travers l'intégration d'une solution complète de lignage ML pour une application ML déployée sur AWS Lambda serverless, couvrant les étapes du pipeline de bout en bout :
Pipeline ETL
Détection de la dérive des données (Data drift)
Prétraitement
Réglage du modèle (Model tuning)
Évaluation des risques et de l'équité.
Table des matières
Prérequis :
Connaissance des concepts clés du Machine Learning / Deep Learning, y compris le cycle de vie complet : gestion des données, entraînement du modèle, réglage et validation.
Maîtrise de Python, avec une expérience dans l'utilisation des principales bibliothèques ML.
Compréhension de base des principes DevOps.
Outils que nous utiliserons :
Voici un résumé des outils que nous allons utiliser pour suivre le lignage ML :
DVC : Un système de versionnage open-source pour les données. Utilisé pour suivre le lignage ML.
AWS S3 : Un service de stockage d'objets sécurisé d'AWS. Utilisé comme stockage distant.
Evently AI : Un Framework d'observabilité ML et LLM open-source. Utilisé pour détecter la dérive des données.
Prefect : Un moteur d'orchestration de flux de travail. Utilisé pour gérer l'exécution planifiée du lignage.
Qu'est-ce que le lignage d'apprentissage automatique ?
Le lignage d'apprentissage automatique (ML lineage) est un Framework permettant de suivre et de comprendre le cycle de vie complet d'un modèle d'apprentissage automatique.
Il contient des informations à différents niveaux tels que :
Code : Les scripts, bibliothèques et configurations pour l'entraînement du modèle.
Données : Les données originales, les transformations et les caractéristiques (features).
Expériences : Les cycles d'entraînement, les résultats du réglage des hyperparamètres.
Modèles : Les modèles entraînés et leurs versions.
Prédictions : Les sorties des modèles déployés.
Le lignage ML est essentiel pour plusieurs raisons :
Reproductibilité : Recréer le même modèle et la même prédiction pour validation.
Analyse des causes racines : Remonter jusqu'aux données, au code ou au changement de configuration lorsqu'un modèle échoue en production.
Conformité : Certaines industries réglementées exigent des preuves de l'entraînement du modèle pour garantir l'équité, la transparence et le respect des lois comme le RGPD et l'IA Act de l'UE.
Ce que nous allons construire
Dans ce projet, j'intégrerai un lignage ML dans ce système de prédiction de prix construit sur l'architecture AWS Lambda en utilisant DVC, un système de contrôle de version open-source pour les applications ML.
Le diagramme ci-dessous illustre l'architecture du système et le lignage ML que nous allons intégrer :

Figure A : Un lignage ML complet pour une application ML sur Lambda serverless (Créé par Kuriko IWAI)
L'architecture du système : Tarification IA pour les détaillants
Le système fonctionne comme un microservice serverless conteneurisé conçu pour fournir des recommandations de prix optimales afin de maximiser les ventes des détaillants.
Son intelligence centrale provient de modèles d'IA entraînés sur des données d'achat historiques pour prédire la quantité de produit vendue à différents prix, permettant aux vendeurs de déterminer le meilleur prix.
Pour un déploiement cohérent, la logique de prédiction et ses dépendances sont empaquetées dans une image de conteneur Docker et stockées dans AWS ECR (Elastic Container Registry).
La prédiction est ensuite servie par une fonction AWS Lambda, qui récupère et exécute le conteneur depuis ECR et expose le résultat via AWS API Gateway pour que l'application Flask puisse le consommer.
Si vous voulez voir comment construire cela de zéro, vous pouvez suivre mon tutoriel Comment construire un système de Machine Learning sur une architecture Serverless.
Le lignage ML
Dans le système, GitHub gère le lignage du code, tandis que DVC capture le lignage de :
Données (boîtes bleues) : ETL et prétraitement.
Expériences (orange clair) : Réglage des hyperparamètres et validation.
Modèles et Prédiction (orange foncé) : Artefacts finaux du modèle et résultats de prédiction.
DVC suit le lignage à travers des étapes distinctes, de l'extraction des données aux tests d'équité (lignes jaunes dans la Figure A).
Pour chaque étape, DVC utilise un hash MD5 ou SHA256 pour suivre et pousser les métadonnées telles que les artefacts, les métriques et les rapports vers son stockage distant sur AWS S3.
Le pipeline intègre Evently AI pour gérer les tests de dérive des données, qui sont essentiels pour identifier les changements dans les distributions de données qui pourraient compromettre les capacités de généralisation du modèle en production.
Seuls les modèles qui réussissent à la fois les tests de dérive des données et d'équité peuvent servir des prédictions via la passerelle API AWS (boîte rouge dans la Figure A).
Enfin, l'ensemble de ce processus de lignage est déclenché chaque semaine par l'ordonnanceur de flux de travail open-source, Prefect.
Prefect invite DVC à vérifier les mises à jour des données et des scripts, et exécute le processus de lignage complet si des changements sont détectés.
Flux de travail en action
Le processus de construction comprend cinq étapes principales :
Initialiser un projet DVC
Définir les étapes du lignage avec le script DVC
dvc.yamlet le script Python correspondantDéployer le projet DVC
Configurer l'exécution planifiée avec Prefect
Déployer l'application
Parcourons chaque étape ensemble.
Étape 1 : Initialisation d'un projet DVC
La première étape consiste à initialiser un projet DVC :
$dvc init
Cette commande crée automatiquement un répertoire .dvc à la racine du dossier du projet :
.
.dvc/
│
└── cache/ # [.gitignore] stocke les caches dvc (fichiers de données réels mis en cache)
└── tmp/ # [.gitignore]
└── .gitignore # ignore le cache, tmp et config.local
└── config # config dvc pour la production
└── config.local # [.gitignore] config dvc pour le local
DVC maintient un dépôt Git rapide et léger en séparant les données originales volumineuses du dépôt.
Le processus consiste à mettre en cache les données originales dans le répertoire local .dvc/cache, à créer un petit fichier de métadonnées .dvc qui contient un hash MD5 et un lien vers le chemin du fichier de données original, à pousser uniquement les petits fichiers de métadonnées vers Git, et à pousser les données originales vers le stockage distant DVC.
Étape 2 : Le lignage ML
Ensuite, nous allons configurer le lignage ML avec les étapes suivantes :
etl_pipeline: Extraire, nettoyer, imputer les données originales et effectuer l'ingénierie des caractéristiques.data_drift_check: Exécuter des tests de dérive des données. S'ils échouent, le système s'arrête.preprocess: Créer des jeux de données d'entraînement, de validation et de test.tune_primary_model: Régler les hyperparamètres et entraîner le modèle.inference_primary_model: Effectuer l'inférence sur le jeu de données de test.assess_model_risk: Exécuter des tests de risque et d'équité.
Chaque étape nécessite de définir la commande DVC et son script Python correspondant.
Commençons.
Étape 1 : Le pipeline ETL
La première étape consiste à extraire, nettoyer, imputer les données originales et effectuer l'ingénierie des caractéristiques.
Configuration DVC
Nous allons créer le fichier dvc.yaml à la racine du répertoire du projet et ajouter l'étape etl_pipeline :
dvc.yaml
stages:
etl_pipeline:
# la commande principale que dvc exécutera dans cette étape
cmd: python src/data_handling/etl_pipeline.py
# dépendances nécessaires pour exécuter la commande principale
deps:
- src/data_handling/etl_pipeline.py
- src/data_handling/
- src/_utils/
# chemins de sortie à suivre par dvc
outs:
- data/original_df.parquet
- data/processed_df.parquet
Le fichier dvc.yaml définit une séquence d'étapes (stages) en utilisant des sections telles que :
cmd: La commande shell à exécuter pour cette étapedeps: Dépendances nécessaires pour exécuter lacmdprams: Paramètres par défaut pour lacmddéfinis dans le fichierparams.yamlmetrics: Les fichiers de métriques à suivrereports: Les fichiers de rapport à suivreplots: Les fichiers de graphiques DVC pour la visualisationouts: Les fichiers de sortie produits par lacmd, que DVC suivra
La configuration aide DVC à garantir la reproductibilité en listant explicitement les dépendances, les sorties et les commandes de chaque étape. Elle l'aide également à gérer le lignage en établissant un Graphe Acyclique Dirigé (DAG) du flux de travail, reliant chaque étape à la suivante.
Scripts Python
Ensuite, ajoutons les scripts Python, en veillant à ce que les données soient stockées en utilisant les chemins de fichiers spécifiés dans la section outs du fichier dvc.yaml :
src/data_handling/etl_pipeline.py :
import os
import argparse
import src.data_handling.scripts as scripts
from src._utils import main_logger
def etl_pipeline():
# extraire l'intégralité des données
df = scripts.extract_original_dataframe()
# charger le fichier parquet
ORIGINAL_DF_PATH = os.path.join('data', 'original_df.parquet')
df.to_parquet(ORIGINAL_DF_PATH, index=False) # suivi par dvc
# transformer
df = scripts.structure_missing_values(df=df)
df = scripts.handle_feature_engineering(df=df)
PROCESSED_DF_PATH = os.path.join('data', 'processed_df.parquet')
df.to_parquet(PROCESSED_DF_PATH, index=False) # suivi par dvc
return df
# pour l'exécution dvc
if __name__ == '__main__':
parser = argparse.ArgumentParser(description="run etl pipeline")
parser.add_argument('--stockcode', type=str, default='', help="specific stockcode to process. empty runs full pipeline.")
parser.add_argument('--impute', action='store_true', help="flag to create imputation values")
args = parser.parse_args()
etl_pipeline(stockcode=args.stockcode, impute_stockcode=args.impute)
Sorties
Les données originales et structurées dans les DataFrames Pandas sont stockées dans le cache DVC :
data/original_df.parquetdata/processed_df.parquet
Étape 2 : La vérification de la dérive des données
Avant de passer au prétraitement, nous allons exécuter des tests de dérive des données pour nous assurer qu'aucune dérive notable n'est présente dans les données. Pour ce faire, nous utiliserons EventlyAI, un Framework d'observabilité ML et LLM open-source.
Qu'est-ce que la dérive des données (Data Drift) ?
La dérive des données fait référence à tout changement dans les propriétés statistiques comme la moyenne, la variance ou la distribution des données sur lesquelles le modèle est entraîné.
Il existe trois types principaux de dérive des données :
Dérive des covariables (Feature Drift) : Un changement dans la distribution des caractéristiques d'entrée.
Dérive de probabilité a priori (Label Drift) : Un changement dans la distribution de la variable cible.
Dérive de concept (Concept Drift) : Un changement dans la relation entre les données d'entrée et la variable cible.
La dérive des données compromet les capacités de généralisation du modèle au fil du temps, ce qui rend sa détection après le déploiement cruciale.
Configuration DVC
Nous ajouterons l'étape data_drift_check juste après l'étape etl_pipeline :
dvc.yaml :
stages:
etl_pipeline:
###
data_drift_check:
# la commande principale que dvc exécutera dans cette étape
cmd: >
python src/data_handling/report_data_drift.py
data/processed/processed_df.csv
data/processed_df_${params.stockcode}.parquet
reports/data_drift_report_${params.stockcode}.html
metrics/data_drift_${params.stockcode}.json
${params.stockcode}
# valeurs par défaut des paramètres (définies dans le fichier param.yaml)
params:
- params.stockcode
# dépendances nécessaires pour exécuter la commande principale
deps:
- src/data_handling/report_data_drift.py
- src/
# chemins des fichiers de sortie à suivre par dvc
plots:
- reports/data_drift_report_${params.stockcode}.html:
metrics:
- metrics/data_drift_${params.stockcode}.json:
type: json
Ensuite, ajoutez les valeurs par défaut aux paramètres passés à la commande DVC :
params.yaml :
params:
stockcode: <STOCKCODE DE VOTRE CHOIX>
Scripts Python
Après avoir généré un jeton API depuis l'espace de travail EventlyAI, nous ajouterons un script Python pour détecter la dérive des données et stocker les résultats dans la variable metrics :
src/data_handling/report_data_drift.py :
import os
import sys
import json
import pandas as pd
import datetime
from dotenv import load_dotenv
from evidently import Dataset, DataDefinition, Report
from evidently.presets import DataDriftPreset
from evidently.ui.workspace import CloudWorkspace
import src.data_handling.scripts as scripts
from src._utils import main_logger
if __name__ == '__main__':
# initialiser l'espace de travail cloud evently
load_dotenv(override=True)
ws = CloudWorkspace(token=os.getenv('EVENTLY_API_TOKEN'), url='https://app.evidently.cloud')
# récupérer le projet evently
project = ws.get_project('EVENTLY AI PROJECT ID')
# récupérer les chemins depuis les arguments de la ligne de commande
REFERENCE_DATA_PATH = sys.argv[1]
CURRENT_DATA_PATH = sys.argv[2]
REPORT_OUTPUT_PATH = sys.argv[3]
METRICS_OUTPUT_PATH = sys.argv[4]
STOCKCODE = sys.argv[5]
# créer les dossiers s'ils n'existent pas
os.makedirs(os.path.dirname(REPORT_OUTPUT_PATH), exist_ok=True)
os.makedirs(os.path.dirname(METRICS_OUTPUT_PATH), exist_ok=True)
# extraire les jeux de données
reference_data_full = pd.read_csv(REFERENCE_DATA_PATH)
reference_data_stockcode = reference_data_full[reference_data_full['stockcode'] == STOCKCODE]
current_data_stockcode = pd.read_parquet(CURRENT_DATA_PATH)
# définir le schéma des données
nums, cats = scripts.categorize_num_cat_cols(df=reference_data_stockcode)
for col in nums: current_data_stockcode[col] = pd.to_numeric(current_data_stockcode[col], errors='coerce')
schema = DataDefinition(numerical_columns=nums, categorical_columns=cats)
# définir le jeu de données evently avec le schéma de données
eval_data_1 = Dataset.from_pandas(reference_data_stockcode, data_definition=schema)
eval_data_2 = Dataset.from_pandas(current_data_stockcode, data_definition=schema)
# exécuter la détection de dérive
report = Report(metrics=[DataDriftPreset()])
data_eval = report.run(reference_data=eval_data_1, current_data=eval_data_2)
data_eval.save_html(REPORT_OUTPUT_PATH)
# créer des métriques pour le suivi dvc
report_dict = json.loads(data_eval.json())
num_drifts = report_dict['metrics'][0]['value']['count']
shared_drifts = report_dict['metrics'][0]['value']['share']
metrics = dict(
drift_detected=bool(num_drifts > 0.0), num_drifts=num_drifts, shared_drifts=shared_drifts,
num_cols=nums,
cat_cols=cats,
stockcode=STOCKCODE,
timestamp=datetime.datetime.now().isoformat(),
)
# charger le fichier de métriques
with open(METRICS_OUTPUT_PATH, 'w') as f:
json.dump(metrics, f, indent=4)
main_logger.info(f'... drift metrics saved to {METRICS_OUTPUT_PATH}... ')
# arrêter le système si une dérive des données est trouvée
if num_drifts > 0.0: sys.exit('❌ FATAL: data drift detected. stopping pipeline')
Si une dérive des données est détectée, le script s'arrête immédiatement en utilisant la commande finale sys.exit.
Sorties
Le script génère deux fichiers que DVC suivra :
reports/data_drift_report.html: Le rapport de dérive des données dans un fichier HTML.metrics/data_drift.json: Les métriques de dérive des données dans un fichier JSON incluant les résultats de la dérive ainsi que les colonnes de caractéristiques et un horodatage :
metrics/data_drift.json :
{
"drift_detected": false,
"num_drifts": 0.0,
"shared_drifts": 0.0,
"num_cols": [
"invoiceno",
"invoicedate",
"unitprice",
"product_avg_quantity_last_month",
"product_max_price_all_time",
"unitprice_vs_max",
"unitprice_to_avg",
"unitprice_squared",
"unitprice_log"
],
"cat_cols": [
"stockcode",
"customerid",
"country",
"year",
"year_month",
"day_of_week",
"is_registered"
],
"timestamp": "2025-10-07T00:24:29.899495"
}
Les résultats des tests de dérive sont également disponibles sur le tableau de bord de l'espace de travail Evently pour une analyse plus approfondie :

Figure B. Capture d'écran du tableau de bord de l'espace de travail Evently
Étape 3 : Prétraitement
Si aucune dérive des données n'est détectée, le lignage passe à l'étape de prétraitement.
Configuration DVC
Nous ajouterons l'étape preprocess juste après l'étape data_drift_check :
dvc.yaml :
stages:
etl_pipeline:
###
data_drift_check:
###
preprocess:
cmd: >
python src/data_handling/preprocess.py --target_col ${params.target_col} --should_scale ${params.should_scale} --verbose ${params.verbose}
deps:
- src/data_handling/preprocess.py
- src/data_handling/
- src/_utils
# paramètres de params.yaml
params:
- params.target_col
- params.should_scale
- params.verbose
outs:
# jeux de données train, val, test
- data/x_train_df.parquet
- data/x_val_df.parquet
- data/x_test_df.parquet
- data/y_train_df.parquet
- data/y_val_df.parquet
- data/y_test_df.parquet
# jeux de données d'entrée prétraités
- data/x_train_processed.parquet
- data/x_val_processed.parquet
- data/x_test_processed.parquet
# préprocesseur entraîné et noms de caractéristiques lisibles par l'homme pour l'analyse shap
- preprocessors/column_transformer.pkl
- preprocessors/feature_names.json
Et ensuite, ajoutez les valeurs par défaut des paramètres utilisés dans la cmd :
params.yaml :
params:
target_col: "quantity"
should_scale: True
verbose: False
Scripts Python
Ensuite, nous ajouterons un script Python pour créer les jeux de données d'entraînement, de validation et de test et prétraiter les données d'entrée :
import os
import argparse
import json
import joblib
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import src.data_handling.scripts as scripts
from src._utils import main_logger
def preprocess(stockcode: str = '', target_col: str = 'quantity', should_scale: bool = True, verbose: bool = False):
# initialiser les métriques à suivre (dvc)
DATA_DRIFT_METRICS_PATH = os.path.join('metrics', f'data_drift_{args.stockcode}.json')
if os.path.exists(DATA_DRIFT_METRICS_PATH):
with open(DATA_DRIFT_METRICS_PATH, 'r') as f:
metrics = json.load(f)
else: metrics = dict()
# charger le df traité depuis le cache dvc
PROCESSED_DF_PATH = os.path.join('data', 'processed_df.parquet')
df = pd.read_parquet(PROCESSED_DF_PATH)
# catégoriser les colonnes num et cat
num_cols, cat_cols = scripts.categorize_num_cat_cols(df=df, target_col=target_col)
if verbose: main_logger.info(f'num_cols: {num_cols} \ncat_cols: {cat_cols}')
# structurer les colonnes cat
if cat_cols:
for col in cat_cols: df[col] = df[col].astype('string')
# initialiser le préprocesseur (soit charger depuis le cache dvc, soit créer de zéro)
PREPROCESSOR_PATH = os.path.join('preprocessors', 'column_transformer.pkl')
try:
preprocessor = joblib.load(PREPROCESSOR_PATH)
except:
preprocessor = scripts.create_preprocessor(num_cols=num_cols if should_scale else [], cat_cols=cat_cols)
# crée les jeux de données train, val, test
y = df[target_col]
X = df.copy().drop(target_col, axis='columns')
# split
test_size, random_state = 50000, 42
X_tv, X_test, y_tv, y_test = train_test_split(X, y, test_size=test_size, random_state=random_state, shuffle=False)
X_train, X_val, y_train, y_val = train_test_split(X_tv, y_tv, test_size=test_size, random_state=random_state, shuffle=False)
# stocker les jeux de données train, val, test (suivi dvc)
X_train.to_parquet('data/x_train_df.parquet', index=False)
X_val.to_parquet('data/x_val_df.parquet', index=False)
X_test.to_parquet('data/x_test_df.parquet', index=False)
y_train.to_frame(name=target_col).to_parquet('data/y_train_df.parquet', index=False)
y_val.to_frame(name=target_col).to_parquet('data/y_val_df.parquet', index=False)
y_test.to_frame(name=target_col).to_parquet('data/y_test_df.parquet', index=False)
# prétraitement
X_train = preprocessor.fit_transform(X_train)
X_val = preprocessor.transform(X_val)
X_test = preprocessor.transform(X_test)
# stocker les données d'entrée prétraitées (suivi dvc)
pd.DataFrame(X_train).to_parquet(f'data/x_train_processed.parquet', index=False)
pd.DataFrame(X_val).to_parquet(f'data/x_val_processed.parquet', index=False)
pd.DataFrame(X_test).to_parquet(f'data/x_test_processed.parquet', index=False)
# sauvegarder les noms de caractéristiques (suivi dvc) pour shap
with open('preprocessors/feature_names.json', 'w') as f:
feature_names = preprocessor.get_feature_names_out()
json.dump(feature_names.tolist(), f)
return X_train, X_val, X_test, y_train, y_val, y_test, preprocessor
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='run data preprocessing')
parser.add_argument('--stockcode', type=str, default='', help='specific stockcode')
parser.add_argument('--target_col', type=str, default='quantity', help='the target column name')
parser.add_argument('--should_scale', type=bool, default=True, help='flag to scale numerical features')
parser.add_argument('--verbose', type=bool, default=False, help='flag for verbose logging')
args = parser.parse_args()
X_train, X_val, X_test, y_train, y_val, y_test, preprocessor = preprocess(
target_col=args.target_col,
should_scale=args.should_scale,
verbose=args.verbose,
stockcode=args.stockcode,
)
Sorties
Cette étape génère les jeux de données nécessaires à la fois pour l'entraînement du modèle et pour l'inférence :
Caractéristiques d'entrée :
data/x_train_df.parquetdata/x_val_df.parquetdata/x_test_df.parquet
Caractéristiques d'entrée prétraitées :
data/x_train_processed_df.parquetdata/x_val_processed_df.parquetdata/x_test_processed_df.parquet
Variables cibles :
data/y_train_df.parquetdata/y_val_df.parquetdata/y_test_df.parquet
Le préprocesseur et les noms de caractéristiques lisibles par l'homme sont également stockés dans le cache pour l'inférence et l'analyse d'impact des caractéristiques SHAP ultérieure :
preprocessors/column_transformer.pkpreprocessors/feature_names.json
Enfin, DVC ajoute le preprocess_status, x_train_processed_path et preprocessor_path au fichier de métriques de résumé des données data.json créé à l'étape 2 pour suivre le processus de bout en bout des étapes 2 et 3 :
metrics/data.json :
{
"drift_detected": false,
"num_drifts": 0.0,
"shared_drifts": 0.0,
"num_cols": [
"invoiceno",
"invoicedate",
"unitprice",
"product_avg_quantity_last_month",
"product_max_price_all_time",
"unitprice_vs_max",
"unitprice_to_avg",
"unitprice_squared",
"unitprice_log"
],
"cat_cols": [
"stockcode",
"customerid",
"country",
"year",
"year_month",
"day_of_week",
"is_registered"
],
"timestamp": "2025-10-07T00:24:29.899495",
# mises à jour
"preprocess_status": "completed",
"x_train_processed_path": "data/x_train_processed_85123A.parquet",
"preprocessor_path": "preprocessors/column_transformer.pkl"
}
Ensuite, passons au lignage du modèle/de l'expérience.
Étape 4 : Réglage du modèle
Maintenant que nous avons créé les jeux de données, nous allons régler et entraîner le modèle principal. Il s'agit d'un réseau feedforward multicouche sur PyTorch, utilisant les jeux de données d'entraînement et de validation créés lors de l'étape preprocess.
Configuration DVC
Tout d'abord, nous ajouterons l'étape tuning_primary_model juste après l'étape preprocess :
dvc.yaml :
stages:
etl_pipeline:
###
data_drift_check:
###
preprocess:
###
tune_primary_model:
cmd: >
python src/model/torch_model/main.py
data/x_train_processed_${params.stockcode}.parquet
data/x_val_processed_${params.stockcode}.parquet
data/y_train_df_${params.stockcode}.parquet
data/y_val_df_${params.stockcode}.parquet
${tuning.should_local_save}
${tuning.grid}
${tuning.n_trials}
${tuning.num_epochs}
${params.stockcode}
deps:
- src/model/torch_model/main.py
- src/data_handling/
- src/model/
- src/_utils/
params:
- params.stockcode
- tuning.n_trials
- tuning.grid
- tuning.should_local_save
outs:
- models/production/dfn_best_${params.stockcode}.pth # suivi dvc
metrics:
- metrics/dfn_val_${params.stockcode}.json: # suivi dvc
Ensuite, nous ajouterons les valeurs par défaut aux paramètres :
params.yaml :
params:
target_col: "quantity"
should_scale: True
verbose: False
tuning:
n_trials: 100
num_epochs: 3000
should_local_save: False
grid: False
Scripts Python
Ensuite, nous ajouterons les scripts Python pour régler le modèle en utilisant l'optimisation bayésienne, puis entraîner le modèle optimal sur les jeux de données complets X_train et y_train créés lors de l'étape preprocess.
src/model/torch_model/main.py :
import os
import sys
import json
import datetime
import pandas as pd
import torch
import torch.nn as nn
import src.model.torch_model.scripts as scripts
def tune_and_train(
X_train, X_val, y_train, y_val,
stockcode: str = '',
should_local_save: bool = True,
grid: bool = False,
n_trials: int = 50,
num_epochs: int = 3000
) -> tuple[nn.Module, dict]:
# effectuer l'optimisation bayésienne
best_dfn, best_optimizer, best_batch_size, best_checkpoint = scripts.bayesian_optimization(
X_train, X_val, y_train, y_val, n_trials=n_trials, num_epochs=num_epochs
)
# sauvegarder l'artefact du modèle (suivi dvc)
DFN_FILE_PATH = os.path.join('models', 'production', f'dfn_best_{stockcode}.pth' if stockcode else 'dfn_best.pth')
os.makedirs(os.path.dirname(DFN_FILE_PATH), exist_ok=True)
torch.save(best_checkpoint, DFN_FILE_PATH)
return best_dfn, best_checkpoint
def track_metrics_by_stockcode(X_val, y_val, best_model, checkpoint: dict, stockcode: str):
MODEL_VAL_METRICS_PATH = os.path.join('metrics', f'dfn_val_{stockcode}.json')
os.makedirs(os.path.dirname(MODEL_VAL_METRICS_PATH), exist_ok=True)
# valider le modèle réglé
_, mse, exp_mae, rmsle = scripts.perform_inference(model=best_model, X=X_val, y=y_val)
model_version = f"dfn_{stockcode}_{os.getpid()}"
metrics = dict(
stockcode=stockcode,
mse_val=mse,
mae_val=exp_mae,
rmsle_val=rmsle,
model_version=model_version,
hparams=checkpoint['hparams'],
optimizer=checkpoint['optimizer_name'],
batch_size=checkpoint['batch_size'],
lr=checkpoint['lr'],
timestamp=datetime.datetime.now().isoformat()
)
# stocker les résultats de validation (suivi dvc)
with open(MODEL_VAL_METRICS_PATH, 'w') as f:
json.dump(metrics, f, indent=4)
main_logger.info(f'... validation metrics saved to {MODEL_VAL_METRICS_PATH} ...')
if __name__ == '__main__':
# récupérer les valeurs des arguments de commande
X_TRAIN_PATH = sys.argv[1]
X_VAL_PATH = sys.argv[2]
Y_TRAIN_PATH = sys.argv[3]
Y_VAL_PATH = sys.argv[4]
SHOULD_LOCAL_SAVE = sys.argv[5] == 'True'
GRID = sys.argv[6] == 'True'
N_TRIALS = int(sys.argv[7])
NUM_EPOCHS = int(sys.argv[8])
STOCKCODE = str(sys.argv[9])
# extraire les jeux de données d'entraînement et de validation du cache dvc
X_train, X_val = pd.read_parquet(X_TRAIN_PATH), pd.read_parquet(X_VAL_PATH)
y_train, y_val = pd.read_parquet(Y_TRAIN_PATH), pd.read_parquet(Y_VAL_PATH)
# réglage
best_model, checkpoint = tune_and_train(
X_train, X_val, y_train, y_val,
stockcode=STOCKCODE, should_local_save=SHOULD_LOCAL_SAVE, grid=GRID, n_trials=N_TRIALS, num_epochs=NUM_EPOCHS
)
# suivi des métriques
track_metrics_by_stockcode(X_val, y_val, best_model=best_model, checkpoint=checkpoint, stockcode=STOCKCODE)
Sorties
L'étape génère deux fichiers :
models/production/dfn_best.pth: Comprend les artefacts du modèle et le point de contrôle (checkpoint) comme l'ensemble optimal d'hyperparamètres.metrics/dfn_val.json: Contient les résultats du réglage, la version du modèle, l'horodatage et les résultats de validation pour MSE, MAE et RMSLE :
metrics/dfn_val.json :
{
"stockcode": "85123A",
"mse_val": 0.6137686967849731,
"mae_val": 9.092489242553711,
"rmsle_val": 0.6953299045562744,
"model_version": "dfn_85123A_35604",
"hparams": {
"num_layers": 4,
"batch_norm": false,
"dropout_rate_layer_0": 0.13765888061300502,
"n_units_layer_0": 184,
"dropout_rate_layer_1": 0.5509872409359128,
"n_units_layer_1": 122,
"dropout_rate_layer_2": 0.2408753527744403,
"n_units_layer_2": 35,
"dropout_rate_layer_3": 0.03451842588822594,
"n_units_layer_3": 224,
"learning_rate": 0.026240673135104406,
"optimizer": "adamax",
"batch_size": 64
},
"optimizer": "adamax",
"batch_size": 64,
"lr": 0.026240673135104406,
"timestamp": "2025-10-07T00:31:08.700294"
}
Étape 5 : Exécution de l'inférence
Une fois la phase de réglage du modèle terminée, nous allons configurer l'inférence de test pour une évaluation finale.
L'évaluation finale utilise les métriques MSE, MAE et RMSLE, ainsi que SHAP pour l'analyse de l'impact des caractéristiques et de l'interprétabilité.
SHAP (SHapley Additive exPlanations) est un Framework permettant de quantifier la contribution de chaque caractéristique à la prédiction d'un modèle en utilisant le concept des valeurs de Shapley issues de la théorie des jeux.
Les valeurs SHAP sont exploitées pour les futures analyses exploratoires de données (EDA) et l'ingénierie des caractéristiques.
Configuration DVC
Tout d'abord, nous ajouterons l'étape inference_primary_model à la configuration DVC.
Cette étape comporte la section plots où DVC suivra et versionnera les fichiers de visualisation générés sur les valeurs SHAP.
dvc.yaml :
stages:
etl_pipeline:
###
data_drift_check:
###
preprocess:
###
tune_primary_model:
###
inference_primary_model:
cmd: >
python src/model/torch_model/inference.py
data/x_test_processed_${params.stockcode}.parquet
data/y_test_df_${params.stockcode}.parquet
models/production/dfn_best_${params.stockcode}.pth
${params.stockcode}
${tracking.sensitive_feature_col}
${tracking.privileged_group}
deps:
- src/model/torch_model/inference.py
- models/production/
- src/
params:
- params.stockcode
- tracking.sensitive_feature_col
- tracking.privileged_group
metrics:
- metrics/dfn_inf_${params.stockcode}.json: # suivi dvc
type: json
plots:
# graphique shap summary / beeswarm pour l'interprétabilité globale
- reports/dfn_shap_summary_${params.stockcode}.json:
template: simple
x: shap_value
y: feature_name
title: SHAP Beeswarm Plot
# valeurs shap moyennes absolues - graphique à barres d'importance des caractéristiques
- reports/dfn_shap_mean_abs_${params.stockcode}.json:
template: bar
x: mean_abs_shap
y: feature_name
title: Mean Absolute SHAP Importance
outs:
- data/dfn_inference_results_${params.stockcode}.parquet
- reports/dfn_raw_shap_values_${params.stockcode}.parquet # sauvegarde des valeurs shap brutes pour analyse détaillée ultérieure
Scripts Python
Ensuite, nous ajouterons des scripts où le modèle entraîné effectue l'inférence :
src/model/torch_model/inference.py :
import os
import sys
import json
import datetime
import numpy as np
import pandas as pd
import torch
import shap
import src.model.torch_model.scripts as scripts
from src._utils import main_logger
if __name__ == '__main__':
# charger le jeu de données de test
X_TEST_PATH = sys.argv[1]
Y_TEST_PATH = sys.argv[2]
X_test, y_test = pd.read_parquet(X_TEST_PATH), pd.read_parquet(Y_TEST_PATH)
# créer X_test avec les noms de colonnes pour l'analyse shap et le suivi des caractéristiques sensibles
X_test_with_col_names = X_test.copy()
FEATURE_NAMES_PATH = os.path.join('preprocessors', 'feature_names.json')
try:
with open(FEATURE_NAMES_PATH, 'r') as f: feature_names = json.load(f)
except FileNotFoundError: feature_names = X_test.columns.tolist()
if len(X_test_with_col_names.columns) == len(feature_names): X_test_with_col_names.columns = feature_names
# reconstruire le modèle optimal réglé à l'étape précédente
MODEL_PATH = sys.argv[3]
checkpoint = torch.load(MODEL_PATH)
model = scripts.load_model(checkpoint=checkpoint)
# effectuer l'inférence
y_pred, mse, exp_mae, rmsle = scripts.perform_inference(model=model, X=X_test, y=y_test, batch_size=checkpoint['batch_size'])
# créer le df de résultat avec y_pred, y_true et les caractéristiques sensibles
STOCKCODE = sys.argv[4]
SENSITIVE_FEATURE = sys.argv[5]
PRIVILEGED_GROUP = sys.argv[6]
inference_df = pd.DataFrame(y_pred.cpu().numpy().flatten(), columns=['y_pred'])
inference_df['y_true'] = y_test
inference_df[SENSITIVE_FEATURE] = X_test_with_col_names[f'cat__{SENSITIVE_FEATURE}_{str(PRIVILEGED_GROUP)}'].astype(bool)
inference_df.to_parquet(path=os.path.join('data', f'dfn_inference_results_{STOCKCODE}.parquet'))
# enregistrer les métriques d'inférence
MODEL_INF_METRICS_PATH = os.path.join('metrics', f'dfn_inf_{STOCKCODE}.json')
os.makedirs(os.path.dirname(MODEL_INF_METRICS_PATH), exist_ok=True)
model_version = f"dfn_{STOCKCODE}_{os.getpid()}"
inf_metrics = dict(
stockcode=STOCKCODE,
mse_inf=mse,
mae_inf=exp_mae,
rmsle_inf=rmsle,
model_version=model_version,
hparams=checkpoint['hparams'],
optimizer=checkpoint['optimizer_name'],
batch_size=checkpoint['batch_size'],
lr=checkpoint['lr'],
timestamp=datetime.datetime.now().isoformat()
)
with open(MODEL_INF_METRICS_PATH, 'w') as f: # suivi dvc
json.dump(inf_metrics, f, indent=4)
main_logger.info(f'... inference metrics saved to {MODEL_INF_METRICS_PATH} ...')
## analyse shap
# calculer les valeurs shap
model.eval()
# préparer les données d'arrière-plan
X_test_tensor = torch.from_numpy(X_test.values.astype(np.float32)).to(device_type)
# prendre de petits échantillons de x_test comme arrière-plan
background = X_test_tensor[np.random.choice(X_test_tensor.shape[0], 100, replace=False)].to(device_type)
# définir deepexplainer
explainer = shap.DeepExplainer(model, background)
# calculer les valeurs shap
shap_values = explainer.shap_values(X_test_tensor) # sorties = tableau numpy ou tenseur
# convertir le tableau shap en df pandas
if isinstance(shap_values, list): shap_values = shap_values[0]
if isinstance(shap_values, torch.Tensor): shap_values = shap_values.cpu().numpy()
shap_values = shap_values.squeeze(axis=-1) # type: ignore
shap_df = pd.DataFrame(shap_values, columns=feature_names)
# données brutes shap (suivi dvc)
RAW_SHAP_OUT_PATH = os.path.join('reports', f'dfn_raw_shap_values_{STOCKCODE}.parquet')
os.makedirs(os.path.dirname(RAW_SHAP_OUT_PATH), exist_ok=True)
shap_df.to_parquet(RAW_SHAP_OUT_PATH, index=False)
main_logger.info(f'... shap values saved to {RAW_SHAP_OUT_PATH} ...')
# graphique à barres des valeurs shap moyennes absolues (rapport dvc)
mean_abs_shap = shap_df.abs().mean().sort_values(ascending=False)
shap_mean_abs_df = pd.DataFrame({'feature_name': feature_names, 'mean_abs_shap': mean_abs_shap.values })
MEAN_ABS_SHAP_PATH = os.path.join('reports', f'dfn_shap_mean_abs_{STOCKCODE}.json')
shap_mean_abs_df.to_json(MEAN_ABS_SHAP_PATH, orient='records', indent=4)
Sorties
Cette étape génère cinq fichiers de sortie :
data/dfn_inference_result_${params_stockcode}.parquet: Stocke les résultats de prédiction, les cibles étiquetées et toutes les colonnes avec des caractéristiques sensibles comme le sexe, l'âge, le revenu, etc. J'utiliserai ce fichier pour le test d'équité lors de la dernière étape.metrics/dfn_inf.json: Stocke les métriques d'évaluation et les résultats du réglage :
{
"stockcode": "85123A",
"mse_inf": 0.6841545701026917,
"mae_inf": 11.5866117477417,
"rmsle_inf": 0.7423332333564758,
"model_version": "dfn_85123A_35834",
"hparams": {
"num_layers": 4,
"batch_norm": false,
"dropout_rate_layer_0": 0.13765888061300502,
"n_units_layer_0": 184,
"dropout_rate_layer_1": 0.5509872409359128,
"n_units_layer_1": 122,
"dropout_rate_layer_2": 0.2408753527744403,
"n_units_layer_2": 35,
"dropout_rate_layer_3": 0.03451842588822594,
"n_units_layer_3": 224,
"learning_rate": 0.026240673135104406,
"optimizer": "adamax",
"batch_size": 64
},
"optimizer": "adamax",
"batch_size": 64,
"lr": 0.026240673135104406,
"timestamp": "2025-10-07T00:31:12.946405"
}
reports/dfn_shap_mean_abs.json: Stocke les valeurs SHAP moyennes :
[
{
"feature_name":"num__invoicedate",
"mean_abs_shap":0.219255722
},
{
"feature_name":"num__unitprice",
"mean_abs_shap":0.1069829418
},
{
"feature_name":"num__product_avg_quantity_last_month",
"mean_abs_shap":0.1021453096
},
{
"feature_name":"num__product_max_price_all_time",
"mean_abs_shap":0.0855356899
},
...
]
reports/dfn_shap_summary.json: Contient les points de données nécessaires pour dessiner les graphiques beeswarm/barres.reports/dfn_raw_shap_values.parquet: Stocke les valeurs SHAP brutes.
Étape 6 : Évaluation des risques et de l'équité du modèle
La dernière étape consiste à évaluer le risque et l'équité des résultats d'inférence finaux.
Le test d'équité
Le test d'équité en ML est le processus d'évaluation systématique des prédictions d'un modèle pour s'assurer qu'elles ne sont pas injustement biaisées envers des groupes spécifiques définis par des attributs sensibles comme la race et le sexe.
Dans ce projet, nous utiliserons la colonne de statut d'enregistrement is_registered comme caractéristique sensible et nous nous assurerons que la Différence de Résultat Moyen (MOD - Mean Outcome Difference) se situe dans le seuil spécifié de 0.1.
La MOD est calculée comme la différence absolue entre les valeurs de prédiction moyennes des groupes privilégiés (enregistrés) et non privilégiés (non enregistrés).
Configuration DVC
Tout d'abord, nous ajouterons l'étape assess_model_risk juste après l'étape inference_primary_model :
dvc.yaml :
stages:
etl_pipeline:
###
data_drift_check:
###
preprocess:
###
tune_primary_model:
###
inference_primary_model:
###
assess_model_risk:
cmd: >
python src/model/torch_model/assess_risk_and_fairness.py
data/dfn_inference_results_${params.stockcode}.parquet
metrics/dfn_risk_fairness_${params.stockcode}.json
${tracking.sensitive_feature_col}
${params.stockcode}
${tracking.privileged_group}
${tracking.mod_threshold}
deps:
- src/model/torch_model/assess_risk_and_fairness.py
- src/_utils/
- data/dfn_inference_results_${params.stockcode}.parquet # s'assurer que le df de résultat est une dépendance
params:
- params.stockcode
- tracking.sensitive_feature_col
- tracking.privileged_group
- tracking.mod_threshold
metrics:
- metrics/dfn_risk_fairness_${params.stockcode}.json:
type: json
Ensuite, nous ajouterons les valeurs par défaut aux paramètres :
param.yaml :
params:
target_col: "quantity"
should_scale: True
verbose: False
tuning:
n_trials: 100
num_epochs: 3000
should_local_save: False
grid: False
# ajout de valeurs par défaut aux métriques de suivi
tracking:
sensitive_feature_col: "is_registered"
privileged_group: 1 # membre
mod_threshold: 0.1
Script Python
Le script Python correspondant contient la fonction calculate_fairness_metrics qui effectue l'évaluation des risques et de l'équité :
src/model/torch_model/assess_risk_and_fairness.py :
import os
import json
import datetime
import argparse
import pandas as pd
from sklearn.metrics import mean_absolute_error, mean_squared_error, root_mean_squared_log_error
from src._utils import main_logger
def calculate_fairness_metrics(
df: pd.DataFrame,
sensitive_feature_col: str,
label_col: str = 'y_true',
prediction_col: str = 'y_pred',
privileged_group: int = 1,
mod_threshold: float = 0.1,
) -> dict:
metrics = dict()
unprivileged_group = 0 if privileged_group == 1 else 1
## 1. évaluation des risques - métriques de performance prédictive par groupe
for group, name in zip([unprivileged_group, privileged_group], ['unprivileged', 'privileged']):
subset = df[df[sensitive_feature_col] == group]
if len(subset) == 0: continue
y_true = subset[label_col].values
y_pred = subset[prediction_col].values
metrics[f'mse_{name}'] = float(mean_squared_error(y_true, y_pred)) # type: ignore
metrics[f'mae_{name}'] = float(mean_absolute_error(y_true, y_pred)) # type: ignore
metrics[f'rmsle_{name}'] = float(root_mean_squared_log_error(y_true, y_pred)) # type: ignore
# prédiction moyenne (composante de disparité de résultat)
metrics[f'mean_prediction_{name}'] = float(y_pred.mean()) # type: ignore
## 2. évaluation du biais - métriques d'équité
# différence d'erreur absolue moyenne
mae_diff = metrics.get('mae_unprivileged', 0) - metrics.get('mae_privileged', 0)
metrics['mae_diff'] = float(mae_diff)
# différence de résultat moyen (MOD)
mod = metrics.get('mean_prediction_unprivileged', 0) - metrics.get('mean_prediction_privileged', 0)
metrics['mean_outcome_difference'] = float(mod)
metrics['is_mod_acceptable'] = 1 if abs(mod) <= mod_threshold else 0
return metrics
def main():
parser = argparse.ArgumentParser(description='assess bias and fairness metrics on model inference results.')
parser.add_argument('inference_file_path', type=str, help='parquet file path to the inference results w/ y_true, y_pred, and sensitive feature cols.')
parser.add_argument('metrics_output_path', type=str, help='json file path to save the metrics output.')
parser.add_argument('sensitive_feature_col', type=str, help='column name of sensitive features')
parser.add_argument('stockcode', type=str)
parser.add_argument('privileged_group', type=int, default=1)
parser.add_argument('mod_threshold', type=float, default=.1)
args = parser.parse_args()
try:
# charger le df d'inférence
df_inference = pd.read_parquet(args.inference_file_path)
LABEL_COL = 'y_true'
PREDICTION_COL = 'y_pred'
SENSITIVE_COL = args.sensitive_feature_col
# calculer les métriques d'équité
metrics = calculate_fairness_metrics(
df=df_inference,
sensitive_feature_col=SENSITIVE_COL,
label_col=LABEL_COL,
prediction_col=PREDICTION_COL,
privileged_group=args.privileged_group,
mod_threshold=args.mod_threshold,
)
# ajouter des éléments aux métriques
metrics['model_version'] = f'dfn_{args.stockcode}_{os.getpid()}'
metrics['sensitive_feature'] = args.sensitive_feature_col
metrics['privileged_group'] = args.privileged_group
metrics['mod_threshold'] = args.mod_threshold
metrics['stockcode'] = args.stockcode
metrics['timestamp'] = datetime.datetime.now().isoformat()
# charger les métriques (suivi dvc)
with open(args.metrics_output_path, 'w') as f:
json_metrics = { k: (v if pd.notna(v) else None) for k, v in metrics.items() }
json.dump(json_metrics, f, indent=4)
except Exception as e:
main_logger.error(f'... an error occurred during risk and fairness assessment: {e} ...')
exit(1)
if __name__ == '__main__':
main()
Sorties
L'étape finale génère un fichier de métriques qui contient les résultats des tests et la version du modèle :
metrics/dfn_risk_fairness.json :
{
"mse_unprivileged": 3.5370739412593575,
"mae_unprivileged": 1.48263614013523,
"rmsle_unprivileged": 0.6080000224747837,
"mean_prediction_unprivileged": 1.8507767915725708,
"mae_diff": 1.48263614013523,
"mean_outcome_difference": 1.8507767915725708,
"is_mod_acceptable": 1,
"model_version": "dfn_85123A_35971",
"sensitive_feature": "is_registered",
"privileged_group": 1,
"mod_threshold": 0.1,
"timestamp": "2025-10-07T00:31:15.998590"
}
C'est tout pour la configuration du lignage. Maintenant, nous allons le tester en local.
Test en local
Nous allons exécuter l'intégralité du lignage ML avec cette commande :
$dvc repro -f
-f force DVC à réexécuter toutes les étapes avec ou sans mises à jour.
La commande créera automatiquement le fichier dvc.lock à la racine du répertoire du projet :
schema: '2.0'
stages:
etl_pipeline_full:
cmd: python src/data_handling/etl_pipeline.py
deps:
- path: src/_utils/
hash: md5
md5: ae41392532188d290395495f6827ed00.dir
size: 15870
nfiles: 10
- path: src/data_handling/
hash: md5
md5: a8a61a4b270581a7c387d51e416f4e86.dir
size: 95715
...
Le fichier dvc.lock doit être publié dans Git pour s'assurer que DVC chargera les derniers fichiers :
$git add dvc.lock .dvc dvc.yaml params.yaml
$git commit -m'updated dvc config'
$git push
Étape 3 : Déploiement du projet DVC
Ensuite, nous allons déployer le projet DVC pour nous assurer que la fonction AWS Lambda peut accéder aux fichiers mis en cache en production.
Nous commencerons par configurer le stockage distant DVC (remote) où les fichiers mis en cache sont stockés.
DVC propose différents types de stockage comme AWS S3 et Google Cloud. Nous utiliserons AWS S3 pour ce projet, mais votre choix dépend de l'écosystème du projet, de votre familiarité avec l'outil et des éventuelles contraintes de ressources.
Tout d'abord, nous allons créer un nouveau bucket S3 dans la région AWS sélectionnée :
$aws s3 mb s3://<NOM DU PROJET>/<NOM DU BUCKET> --region <RÉGION AWS>
Assurez-vous que le rôle IAM dispose des permissions suivantes : s3:ListBucket, s3:GetObject, s3:PutObject et s3:DeleteObject.
Ensuite, ajoutez l'URI du bucket S3 au stockage distant DVC :
$dvc remote add -d <NOM DU REMOTE DVC> ss3://<NOM DU PROJET>/<NOM DU BUCKET>
Ensuite, poussez les fichiers de cache vers le stockage distant DVC :
$dvc push
Maintenant, tous les fichiers de cache sont stockés dans le bucket S3 :

Figure C. Capture d'écran du stockage distant DVC dans le bucket AWS S3
Comme le montre la Figure A, cette étape de déploiement est nécessaire pour que la fonction AWS Lambda accède au cache DVC en production.
Étape 4 : Configuration de l'exécution planifiée avec Prefect
L'étape suivante consiste à configurer l'exécution planifiée de l'intégralité du lignage avec Prefect.
Prefect est un outil d'orchestration de flux de travail open-source pour la construction, la planification et la surveillance des pipelines. Il utilise un concept appelé "work pool" pour découpler efficacement la logique d'orchestration de l'infrastructure d'exécution.
Ensuite, le work pool sert de configuration de base standardisée en exécutant une image de conteneur Docker pour garantir un environnement d'exécution cohérent pour tous les flux.
Configuration du registre d'images Docker
La première étape consiste à configurer le registre d'images Docker pour le work pool Prefect :
Pour le déploiement local : Un registre de conteneurs dans Docker Hub.
Pour le déploiement en production : AWS ECR.
Pour le déploiement local, nous allons d'abord authentifier le client Docker :
$docker login
Et accorder à un utilisateur la permission d'exécuter des commandes Docker sans sudo :
$sudo dscl . -append /Groups/docker GroupMembership $USER
Pour le déploiement en production, nous allons créer un nouvel ECR :
$aws ecr create-repository --repository-name <NOM DU REGISTRE> --region <RÉGION AWS>
(Assurez-vous que le rôle IAM a accès à cet URI ECR.)
Configuration des tâches et des flux Prefect
Ensuite, nous allons configurer la task et le flow Prefect dans le projet :
La
taskPrefect exécute les commandesdvc reproetdvc push.Le
flowPrefect exécute chaque semaine lataskPrefect.
src/prefect_flows.py :
import os
import sys
import subprocess
from datetime import timedelta, datetime
from dotenv import load_dotenv
from prefect import flow, task
from prefect.schedules import Schedule
from prefect_aws import AwsCredentials
from src._utils import main_logger
# ajouter la racine du projet au chemin python - permettant à prefect de trouver le script
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
# définir la tâche prefect
@task(retries=3, retry_delay_seconds=30)
def run_dvc_pipeline():
# exécuter le pipeline dvc
result = subprocess.run(["dvc", "repro"], capture_output=True, text=True, check=True)
# pousser les données mises à jour
subprocess.run(["dvc", "push"], check=True)
# définir le flux prefect
@flow(name="Weekly Data Pipeline")
def weekly_data_flow():
run_dvc_pipeline()
if __name__ == '__main__':
# registre d'images docker (soit docker hub, soit aws ecr)
load_dotenv(override=True)
ENV = os.getenv('ENV', 'production')
DOCKER_HUB_REPO = os.getenv('DOCKER_HUB_REPO')
ECR_FOR_PREFECT_PATH = os.getenv('S3_BUCKET_FOR_PREFECT_PATH')
image_repo = f'{DOCKER_HUB_REPO}:ml-sales-pred-data-latest' if ENV == 'local' else f'{ECR_FOR_PREFECT_PATH}:latest'
# définir le calendrier hebdomadaire
weekly_schedule = Schedule(
interval=timedelta(weeks=1),
anchor_date=datetime(2025, 9, 29, 9, 0, 0),
active=True,
)
# identifiants aws pour accéder à ecr
AwsCredentials(
aws_access_key_id=os.getenv('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.getenv('AWS_SECRET_ACCESS_KEY'),
region_name=os.getenv('AWS_REGION_NAME'),
).save('aws', overwrite=True)
# déployer le flux prefect
weekly_data_flow.deploy(
name='weekly-data-flow',
schedule=weekly_schedule, # calendrier
work_pool_name="wp-ml-sales-pred", # work pool où l'image docker (flux) s'exécute
image=image_repo, # créer une image docker sur docker hub (local) ou ecr (production)
concurrency_limit=3,
push=True # pousser l'image docker vers l'image_repo
)
Test en local
Ensuite, nous allons tester le flux de travail localement avec le serveur Prefect :
$uv run prefect server start
$export PREFECT_API_URL="http://127.0.0.1:4200/api"
Exécutez le script prefect_flows.py :
$uv run src/prefect_flows.py
Une fois l'exécution réussie, le tableau de bord Prefect indique que le flux de travail est planifié :
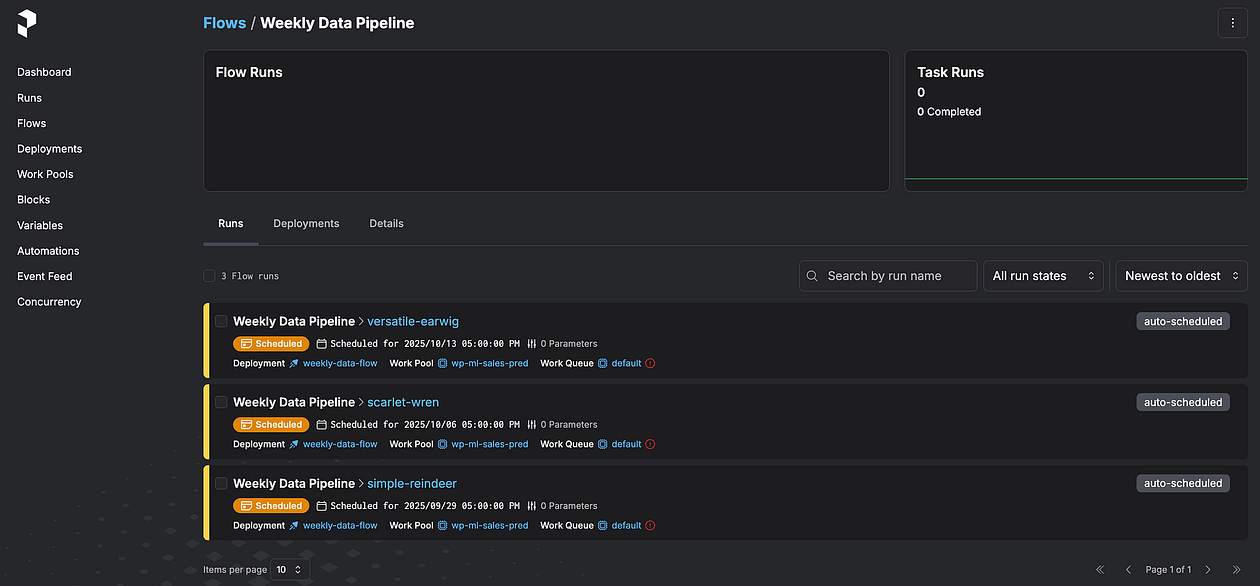
Figure D. Capture d'écran du tableau de bord Prefect
Étape 5 : Déploiement de l'application
La dernière étape consiste à déployer l'intégralité de l'application sous forme de Lambda conteneurisée en configurant le Dockerfile et les scripts de l'application Flask.
Le processus spécifique de cette étape finale de déploiement dépend de l'infrastructure.
Mais le point commun est que DVC élimine le besoin de stocker les fichiers Parquet ou CSV volumineux directement dans le magasin de caractéristiques (feature store) ou le magasin de modèles (model store) car il les met en cache sous forme de fichiers hachés légers.
Ainsi, tout d'abord, nous allons simplifier la logique de chargement du script de l'application Flask en utilisant le Framework dvc.api :
app.py :
### ... les autres composants restent les mêmes ...
import dvc.api
DVC_REMOTE_NAME=<NOM DU REMOTE DANS LE FICHIER .dvc/config>
def configure_dvc_for_lambda():
# définir les répertoires dvc dans /tmp
os.environ.update({
'DVC_CACHE_DIR': '/tmp/dvc-cache',
'DVC_DATA_DIR': '/tmp/dvc-data',
'DVC_CONFIG_DIR': '/tmp/dvc-config',
'DVC_GLOBAL_CONFIG_DIR': '/tmp/dvc-global-config',
'DVC_SITE_CACHE_DIR': '/tmp/dvc-site-cache'
})
for dir_path in ['/tmp/dvc-cache', '/tmp/dvc-data', '/tmp/dvc-config']:
os.makedirs(dir_path, exist_ok=True)
def load_x_test():
global X_test
if not os.environ.get('PYTEST_RUN', False):
main_logger.info("... loading x_test ...")
# configurer les répertoires dvc
configure_dvc_for_lambda()
try:
with dvc.api.open(X_TEST_PATH, remote=DVC_REMOTE_NAME, mode='rb') as fd:
X_test = pd.read_parquet(fd)
main_logger.info('✅ successfully loaded x_test via dvc api')
except Exception as e:
main_logger.error(f'❌ general loading error: {e}', exc_info=True)
def load_preprocessor():
global preprocessor
if not os.environ.get('PYTEST_RUN', False):
main_logger.info("... loading preprocessor ...")
configure_dvc_for_lambda()
try:
with dvc.api.open(PREPROCESSOR_PATH, remote=DVC_REMOTE_NAME, mode='rb') as fd:
preprocessor = joblib.load(fd)
main_logger.info('✅ successfully loaded preprocessor via dvc api')
except Exception as e:
main_logger.error(f'❌ general loading error: {e}', exc_info=True)
### ... les autres composants restent les mêmes ...
Ensuite, mettez à jour le Dockerfile pour permettre à Docker de référencer correctement les composants DVC :
Dockerfile.lambda.production :
# utiliser un runtime python officiel
FROM public.ecr.aws/lambda/python:3.12
# définir les variables d'environnement (ajout des variables d'env liées à dvc)
ENV JOBLIB_MULTIPROCESSING=0
ENV DVC_HOME="/tmp/.dvc"
ENV DVC_CACHE_DIR="/tmp/.dvc/cache"
ENV DVC_REMOTE_NAME="storage"
ENV DVC_GLOBAL_SITE_CACHE_DIR="/tmp/dvc_global"
# copier le fichier requirements et installer les dépendances
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN python -m pip install --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
RUN pip install --no-cache-dir dvc dvc-s3
# configurer dvc
RUN dvc init --no-scm
RUN dvc config core.no_scm true
# copier le code vers la racine de la tâche lambda
COPY . ${LAMBDA_TASK_ROOT}
CMD [ "app.handler" ]
Enfin, assurez-vous que les fichiers volumineux sont ignorés de l'image du conteneur Docker :
.dockerignore :
### ... les autres composants restent les mêmes ...
# le cache dvc contient des fichiers volumineux
.dvc/cache
.dvcignore
# ajouter tous les dossiers que DVC suivra
data/
preprocessors/
models/
reports/
metrics/
Test en local
Enfin, nous allons construire et tester l'image Docker :
$docker build -t my-app -f Dockerfile.lambda.local .
$docker run -p 5002:5002 -e ENV=local my-app app.py
Une fois la configuration réussie, le serveur waitress exécutera l'application Flask.
Après avoir confirmé les changements, poussez le code vers Git :
$git add .
$git commit -m'updated dockerfiles and flask app scripts'
$git push
Cette commande push déclenche le pipeline CI/CD via GitHub Actions, qui génère une image de conteneur Docker et la pousse vers AWS ECR.
Ensuite, après un flux de pipeline réussi et une vérification, nous pouvons exécuter manuellement le flux de travail de déploiement en utilisant GitHub Actions.
Et voilà !
Vous pouvez en apprendre plus ici : Intégration du pipeline CI/CD de l'infrastructure à une application ML
Tout le code est disponible dans mon dépôt GitHub.
L'application fictive est disponible ici.
Conclusion
La construction d'applications ML robustes nécessite un lignage ML complet pour garantir la fiabilité et la traçabilité.
Dans cet article, vous avez appris à construire un lignage ML en intégrant des services open-source comme DVC et Prefect.
En pratique, la planification initiale est importante. Plus précisément, définir comment les métriques sont suivies et à quelles étapes mène directement à une structure de code plus propre et plus maintenable, ainsi qu'à une extensibilité future.
À l'avenir, nous pourrons envisager d'ajouter plus d'étapes au lignage et d'intégrer une logique avancée pour la détection de la dérive des données ou les tests d'équité.
Cela garantira davantage la performance continue du modèle et l'intégrité des données dans l'environnement de production.
Vous pouvez consulter mon Portfolio / Github.
Toutes les images, sauf indication contraire, sont de l'auteur.