

Article original : How to Build a Speech to Emotion Converter with the Web Speech API and Node.js
Par Diogo Spínola
Vous êtes-vous déjà demandé - pouvons-nous faire en sorte que Node.js vérifie si ce que nous disons est positif ou négatif ?
J'ai reçu une newsletter qui discutait de la détection de ton. Le programme peut vérifier ce que nous écrivons et nous dire si cela peut être perçu comme agressif, confiant, ou une variété d'autres sentiments.
Cela m'a fait réfléchir à la façon dont je pourrais construire une version simplifiée en utilisant le navigateur et Node.js qui serait initiée par la parole.
En résultat, j'ai terminé avec un petit projet qui détecte si ce qui a été dit a une valence positive, neutre ou négative.
Voici comment je l'ai fait.
Le plan
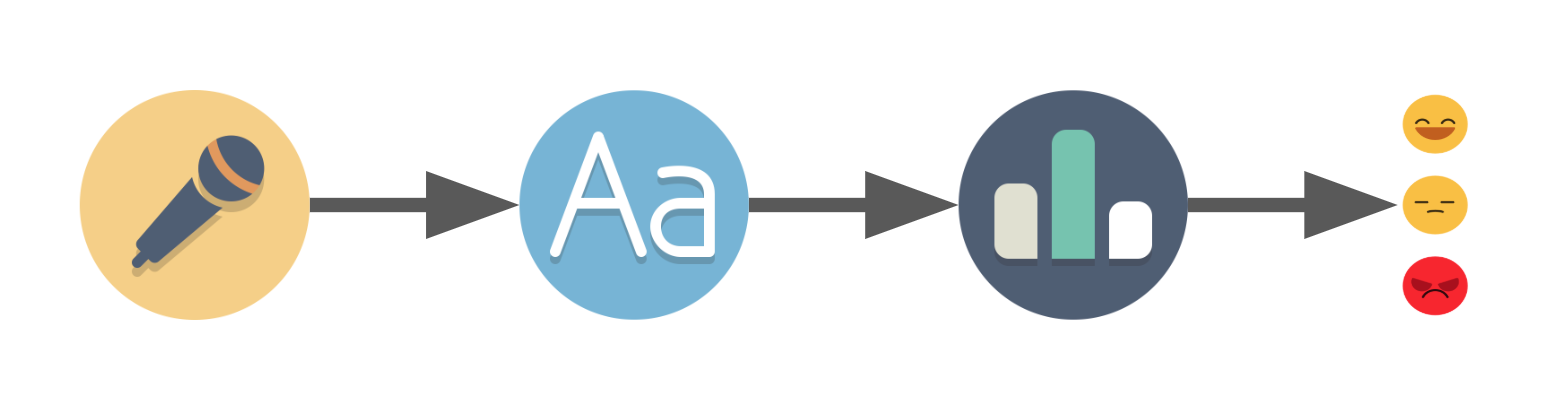 Détection vocale → Voix en texte → Notation du texte → Résultat
Détection vocale → Voix en texte → Notation du texte → Résultat
Lorsque vous commencez un projet, vous devriez esquisser - au moins vaguement - votre objectif et comment l'atteindre. Avant de commencer ma recherche, j'ai noté que j'avais besoin de :
- Enregistrement vocal
- Un moyen de traduire l'enregistrement en texte
- Un moyen de donner une note au texte
- Un moyen de montrer le résultat à l'utilisateur qui vient de parler
Après avoir fait des recherches pendant un moment, j'ai découvert que les parties d'enregistrement vocal et de traduction en texte étaient déjà faites par l'API Web Speech qui est disponible dans Google Chrome. Elle a exactement ce dont nous avons besoin dans l'interface SpeechRecognition.
En ce qui concerne la notation du texte, j'ai trouvé AFINN qui est une liste de mots déjà notés. Elle a un champ d'application limité avec "seulement" 2477 mots, mais c'est plus que suffisant pour notre projet.
Puisque nous utilisons déjà le navigateur, nous pouvons montrer un emoji différent avec HTML, JavaScript et CSS en fonction du résultat. Donc cela gère notre dernière étape.
Maintenant que nous savons ce que nous allons utiliser, nous pouvons le résumer :
- Le navigateur écoute l'utilisateur et retourne du texte en utilisant l'API Web Speech
- Il fait une requête à notre serveur Node.js avec le texte
- Le serveur évalue le texte en utilisant la liste d'AFINN et retourne la note
- Le navigateur montre un emoji différent en fonction de la note
Note : Si vous êtes familier avec la configuration de projet, vous pouvez sauter la section "fichiers et configuration du projet" ci-dessous.
Fichiers et configuration du projet
Notre dossier de projet et la structure des fichiers seront les suivants :
src/
|-public // dossier avec le contenu que nous allons fournir au navigateur
|-style // dossier pour notre css et emojis
|-css // dossier optionnel, nous n'avons qu'un seul fichier évident
|-emojis.css
|-images // dossier pour les emojis
|-index.html
|-recognition.js
package.json
server.js // notre serveur Node.js
Du côté front-end, notre fichier index.html inclura le JS et le CSS :
<html>
<head>
<title>
Parole en émotion
</title>
<link rel="stylesheet" href="style/css/emojis.css">
</head>
<body>
rien pour l'instant
<script src="recognition.js"></script>
</body>
</html>
Le fichier recognition.js sera enveloppé dans l'événement DOMContentLoaded pour nous assurer que la page est chargée avant d'exécuter notre JS :
document.addEventListener('DOMContentLoaded', speechToEmotion, false);
function speechToEmotion() {
// Le code de la section de l'API Web Speech sera ajouté ici
}
Nous laissons notre fichier emojis.css vide pour l'instant.
Dans notre dossier, nous allons exécuter npm run init qui créera package.json.
Pour l'instant, nous allons avoir besoin d'installer deux packages pour faciliter notre travail. Donc, installez simplement les deux avec npm install :
- expressjs - pour avoir un serveur HTTP rapidement opérationnel
- nodemon - pour ne pas avoir à taper constamment node server.js chaque fois que nous faisons une modification dans notre fichier server.js.
package.json ressemblera à quelque chose comme ceci :
{
"name": "speech-to-emotion",
"version": "1.0.0",
"description": "Nous parlons et il nous ressent :o",
"main": "index.js",
"scripts": {
"server": "node server.js",
"server-debug": "nodemon --inspect server.js"
},
"author": "daspinola",
"license": "MIT",
"dependencies": {
"express": "^4.17.1"
},
"devDependencies": {
"nodemon": "^2.0.2"
}
}
server.js commence comme ceci :
const express = require('express')
const path = require('path')
const port = 3000
const app = express()
app.use(express.static(path.join(__dirname, 'public')))
app.get('/', function(req, res) {
res.sendFile(path.join(__dirname, 'index.html'))
})
app.get('/emotion', function(req, res) {
// Le code de la section de la valence de l'émotion sera ici pour l'instant il ne retourne rien
res.send({})
})
app.listen(port, function () {
console.log(`Écoute sur le port ${port}!`)
})
Et avec cela, nous pouvons exécuter npm run server-debug dans la ligne de commande et ouvrir le navigateur sur localhost:3000. Ensuite, nous verrons notre message "rien pour l'instant" qui est dans le fichier HTML.
API Web Speech
Cette API est disponible par défaut dans Chrome et contient SpeechRecognition. C'est ce qui nous permettra d'activer le microphone, de parler et d'obtenir le résultat sous forme de texte.
Elle fonctionne avec des événements qui peuvent détecter, par exemple, quand l'audio est capturé pour la première et la dernière fois.
Pour l'instant, nous aurons besoin des événements onresult et onend pour vérifier ce que le microphone a capturé et quand il cesse de fonctionner, respectivement.
Pour faire notre première capture de son en texte, nous avons juste besoin d'une douzaine de lignes de code dans notre fichier recognition.js.
const recognition = new webkitSpeechRecognition()
recognition.lang = 'en-US'
recognition.onresult = function(event) {
const results = event.results;
const transcript = results[0][0].transcript
console.log('texte ->', transcript)
}
recognition.onend = function() {
console.log('déconnecté')
}
recognition.start()
Nous pouvons trouver une liste des langues disponibles dans la documentation Google ici.
Si nous voulons qu'il reste connecté pendant plus de quelques secondes (ou pour quand nous parlons plus d'une fois), il y a une propriété appelée continuous. Elle peut être changée de la même manière que la propriété lang en lui assignant simplement true. Cela fera en sorte que le microphone écoute l'audio indéfiniment.
const recognition = new webkitSpeechRecognition()
recognition.lang = 'en-US'
recognition.continuous = true
recognition.onresult = function(event) {
const results = event.results;
const transcript = results[results.length-1][0].transcript
console.log('texte ->', transcript)
}
recognition.onend = function() {
console.log('déconnecté')
}
recognition.start()
Si nous actualisons notre page, au début, il devrait demander si nous voulons autoriser l'utilisation du microphone. Après avoir répondu oui, nous pouvons parler et vérifier dans la console des outils de développement de Chrome le résultat de notre parole.
Les jurons sont affichés censurés et il ne semble pas y avoir de moyen de supprimer la censure. Cela signifie que nous ne pouvons pas nous fier aux jurons pour le scoring, même si AFINN n'est pas censuré.
Note : Au moment de l'écriture, cette API ne peut être trouvée que dans Chrome et Android avec un support prévu pour Edge dans un avenir proche. Il existe probablement des polyfills ou d'autres outils qui offrent une meilleure compatibilité avec les navigateurs, mais je ne les ai pas testés. Vous pouvez vérifier la compatibilité sur Can I use.
Faire la requête
Pour la requête, un simple fetch suffit. Nous envoyons la transcription en tant que paramètre de requête que nous appellerons text.
Notre fonction onresult devrait maintenant ressembler à ceci :
recognition.onresult = function(event) {
const results = event.results;
const transcript = results[results.length-1][0].transcript
// faire une requête à notre endpoint /emotion que nous avons défini dans la section de démarrage et de configuration du projet
fetch(`/emotion?text=${transcript}`)
.then((response) => response.json())
.then((result) => {
console.log('résultat ->', result) // devrait être indéfini
})
.catch((e) => {
console.error('Erreur de requête -> ', e)
})
}
Valence de l'émotion
La valence peut être vue comme un moyen de mesurer si nos émotions sont positives ou négatives et si elles créent une faible ou une forte excitation.
Pour ce projet, nous utiliserons deux émotions : happy du côté positif pour tout score supérieur à zéro, et upset du côté négatif pour les scores inférieurs à zéro. Les scores de zéro seront considérés comme indifférents. Tout score de 0 sera traité comme "quoi ?!".
La liste AFINN est notée de -5 à 5 et le fichier contient des mots organisés comme suit :
hope 2
hopeful 2
hopefully 2
hopeless -2
hopelessness -2
hopes 2
hoping 2
horrendous -3
horrible -3
horrific -3
Par exemple, supposons que nous avons parlé au microphone et dit "J'espère que ce n'est pas horrible". Cela donnerait 2 points pour "hope" et -3 points pour "horrendous", ce qui rendrait notre phrase négative avec -1 point. Tous les autres mots qui ne sont pas dans la liste seraient ignorés pour le scoring.
Nous pourrions analyser le fichier et le convertir en un fichier JSON qui ressemble à ceci :
{
<word>: <score>,
<word1>: <score1>,
..
}
Ensuite, nous pourrions vérifier chaque mot dans le texte et additionner les scores. Mais c'est quelque chose que Andrew Sliwinski a déjà fait avec sentiment. Donc nous allons utiliser cela au lieu de tout coder à partir de zéro.
Pour installer, nous utilisons npm install sentiment et ouvrons server.js afin de pouvoir importer la bibliothèque avec :
const Sentiment = require('sentiment');
Suivi par la modification de la route "/emotion" en :
app.get('/emotion', function(req, res) {
const sentiment = new Sentiment()
const text = req.query.text // cela retourne notre requête de paramètre "text"
const score = sentiment.analyze(text);
res.send(score)
})
_sentiment.analyze()_ effectue les étapes décrites précédemment : il vérifie chaque mot de notre texte par rapport à la liste d'AFINN et nous donne un score à la fin.
La variable score contiendra un objet similaire à ceci :
{
score: 7,
comparative: 2.3333333333333335,
calculation: [ { awesome: 4 }, { good: 3 } ],
tokens: [ 'good', 'awesome', 'film' ],
words: [ 'awesome', 'good' ],
positive: [ 'awesome', 'good' ],
negative: []
}
Maintenant que nous avons le score retourné, nous devons simplement le faire apparaître dans notre navigateur.
Note : AFINN est en anglais. Bien que nous puissions sélectionner d'autres langues dans l'API Web Speech, nous devrions trouver une liste notée similaire à AFINN dans la langue souhaitée pour que la correspondance fonctionne.
Faire sourire
Pour notre dernière étape, nous allons mettre à jour notre index.html pour afficher une zone où nous pouvons montrer l'emoji. Nous le modifions donc comme suit :
<html>
<head>
<title>
Parole en émotion
</title>
<link rel="stylesheet" href="style/css/emojis.css">
</head>
<body>
<!-- Nous remplaçons le "rien pour l'instant" -->
<div class="emoji">
<img class="idle">
</div>
<!-- Et laissons le reste tel quel -->
<script src="recognition.js"></script>
</body>
</html>
Les emojis utilisés dans ce projet sont gratuits pour un usage commercial et peuvent être trouvés ici. Bravo à l'artiste.
Nous téléchargeons les icônes que nous aimons et les ajoutons au dossier images. Nous aurons besoin d'emojis pour :
- error - Quand une erreur se produit
- idle - Quand le microphone n'est pas actif
- listening - Quand le microphone est connecté et attend une entrée
- negative - Pour les scores positifs
- neutral - Quand le score est zéro
- positive - Pour les scores négatifs
- searching - Quand notre requête serveur est en cours
Et dans notre fichier emojis.css, nous ajoutons simplement :
.emoji img {
width: 100px;
width: 100px;
}
.emoji .error {
content:url("../images/error.png");
}
.emoji .idle {
content:url("../images/idle.png");
}
.emoji .listening {
content:url("../images/listening.png");
}
.emoji .negative {
content:url("../images/negative.png");
}
.emoji .neutral {
content:url("../images/neutral.png");
}
.emoji .positive {
content:url("../images/positive.png");
}
.emoji .searching {
content:url("../images/searching.png");
}
Lorsque nous rechargeons la page après ces modifications, elle affichera l'emoji idle. Il ne change jamais, cependant, puisque nous n'avons pas remplacé notre classe idle dans l'élément en fonction du scénario.
Pour corriger cela, nous allons une dernière fois dans notre fichier recognition.js. Là, nous allons ajouter une fonction pour changer l'emoji :
/**
* @param {string} type - pourrait être l'un des suivants :
* error|idle|listening|negative|positive|searching
*/
function setEmoji(type) {
const emojiElem = document.querySelector('.emoji img')
emojiElem.classList = type
}
Dans la réponse de notre requête serveur, nous ajoutons la vérification pour un score positif, négatif ou neutre et appelons notre fonction setEmoji en conséquence :
console.log(transcript) // Pour savoir ce qu'il a compris quand nous avons parlé
setEmoji('searching')
fetch(`/emotion?text=${transcript}`)
.then((response) => response.json())
.then((result) => {
if (result.score > 0) {
setEmoji('positive')
} else if (result.score < 0) {
setEmoji('negative')
} else {
setEmoji('listening')
}
})
.catch((e) => {
console.error('Erreur de requête -> ', e)
recognition.abort()
})
Enfin, nous ajoutons les événements onerror et onaudiostart et modifions l'événement onend pour qu'ils soient définis avec l'emoji approprié.
recognition.onerror = function(event) {
console.error('Erreur de reconnaissance -> ', event.error)
setEmoji('error')
}
recognition.onaudiostart = function() {
setEmoji('listening')
}
recognition.onend = function() {
setEmoji('idle')
}
Notre fichier final recognition.js devrait ressembler à ceci :
document.addEventListener('DOMContentLoaded', speechToEmotion, false);
function speechToEmotion() {
const recognition = new webkitSpeechRecognition()
recognition.lang = 'en-US'
recognition.continuous = true
recognition.onresult = function(event) {
const results = event.results;
const transcript = results[results.length-1][0].transcript
console.log(transcript)
setEmoji('searching')
fetch(`/emotion?text=${transcript}`)
.then((response) => response.json())
.then((result) => {
if (result.score > 0) {
setEmoji('positive')
} else if (result.score < 0) {
setEmoji('negative')
} else {
setEmoji('listening')
}
})
.catch((e) => {
console.error('Erreur de requête -> ', e)
recognition.abort()
})
}
recognition.onerror = function(event) {
console.error('Erreur de reconnaissance -> ', event.error)
setEmoji('error')
}
recognition.onaudiostart = function() {
setEmoji('listening')
}
recognition.onend = function() {
setEmoji('idle')
}
recognition.start();
/**
* @param {string} type - pourrait être l'un des suivants :
* error|idle|listening|negative|positive|searching
*/
function setEmoji(type) {
const emojiElem = document.querySelector('.emoji img')
emojiElem.classList = type
}
}
Et en testant notre projet, nous pouvons maintenant voir les résultats finaux :
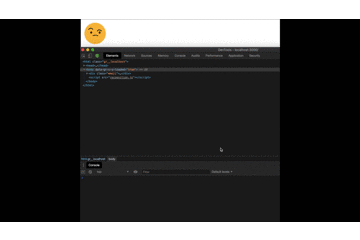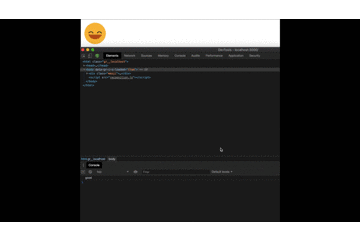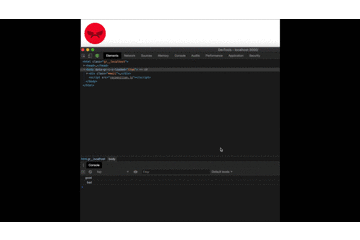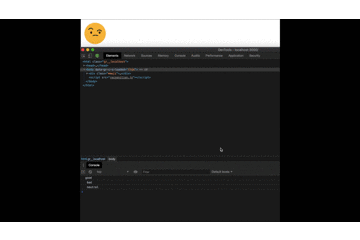
Note : Au lieu d'un console.log pour vérifier ce que la reconnaissance a compris, nous pouvons ajouter un élément à notre html et remplacer le console.log. De cette façon, nous avons toujours accès à ce qu'il a compris.
Remarques finales
Il y a certains domaines où ce projet peut être grandement amélioré :
- il ne peut pas détecter le sarcasme
- il n'y a aucun moyen de vérifier si vous êtes enragé en raison de la censure de l'API de reconnaissance vocale
- il y a probablement un moyen de le faire avec juste la voix sans conversion en texte.
D'après ce que j'ai vu en recherchant ce projet, il existe des implémentations qui vérifient si votre ton et votre humeur mèneront à une vente dans un centre d'appels. Et la newsletter que j'ai reçue provenait de Grammarly, qui l'utilise pour vérifier le ton de ce que vous écrivez. Donc, comme vous pouvez le voir, il y a des applications intéressantes.
Espérons que ce contenu a aidé d'une manière ou d'une autre. Si quelqu'un construit quelque chose en utilisant cette pile, faites-le moi savoir – c'est toujours amusant de voir ce que les gens construisent.
Le code peut être trouvé dans mon github ici.
À la prochaine, en attendant, allez coder quelque chose !