


Article original : How to Build a Docker Engine-like Custom Container without Any Software
Cet article discutera de tous les aspects des conteneurs, y compris leur fonctionnement en arrière-plan et leurs différents éléments composants. Nous découvrirons également pourquoi Docker est si rapide.
À la fin, vous serez en mesure de créer votre propre conteneur personnalisé. Nous examinerons également pourquoi Kubernetes a déprécié Docker et adopté CRI-O, ainsi que comment configurer un cluster Kubernetes multi-nœuds en utilisant CRI-O.
Enfin, nous examinerons la liste des runtimes de conteneurs disponibles.

Table des matières
- Qu'est-ce que les conteneurs ?
- Pourquoi avons-nous besoin de conteneurs ?
- Quelle est la différence entre les conteneurs et la virtualisation ?
- Existe-t-il un format standard pour les conteneurs ?
- Types de plateformes de conteneurs
- Comment lancer un conteneur
- Pourquoi Kubernetes a-t-il déprécié Docker ?
- Défis de l'utilisation de Docker
- Qu'est-ce qu'une CRI (Container Runtime Interface) ?
- Comment construire un cluster multi-nœuds en utilisant CRI-O
Très bien, plongeons-nous dans le sujet.
Qu'est-ce que les conteneurs ?
Les conteneurs vous permettent de déplacer de manière fiable des logiciels d'un environnement informatique à un autre.
La technologie derrière les conteneurs est presque aussi ancienne que celle derrière les machines virtuelles. Mais l'industrie des technologies de l'information n'a commencé à utiliser les conteneurs qu'autour de 2013-14, lorsque Docker, Kubernetes et d'autres innovations qui ont perturbé le secteur sont devenus populaires.
Les conteneurs sont devenus un outil critique dans le processus de développement de logiciels. Ils peuvent servir soit de remplacement pour les machines virtuelles, soit de complément à celles-ci.
La conteneurisation aide les développeurs à construire des applications plus rapidement et en toute sécurité tout en les déployant plus facilement.
Pourquoi avons-nous besoin de conteneurs ?
Comme nous l'avons appris ci-dessus, les conteneurs fournissent une solution au problème de transport de logiciels d'un environnement informatique à un autre de manière fiable. Cela peut être simplement d'une station de travail de développeur à un environnement de test, d'un environnement de pré-production à la production, ou même d'un système réel dans un centre de données à une machine virtuelle de cloud privé ou public.
La conteneurisation rend possibles toutes ces transformations. Et ce ne sont là que quelques-unes des altérations de point de vue qui peuvent se produire.
Cette citation donne un peu de perspective sur pourquoi les conteneurs sont utiles :
"Vous allez tester en utilisant Python 2.7, et ensuite cela va s'exécuter sur Python 3 en production et quelque chose de bizarre va se produire.
Ou vous allez vous appuyer sur le comportement d'une certaine version d'une bibliothèque SSL et une autre sera installée.
Vous allez exécuter vos tests sur Debian et la production est sur Red Hat et toutes sortes de choses bizarres se produisent.
La topologie du réseau peut être différente, ou les politiques de sécurité et le stockage peuvent être différents mais le logiciel doit s'exécuter dessus." – Solomon Hykes
Comment les conteneurs résolvent-ils ce problème ?
Une interprétation plus simple est qu'un conteneur est un environnement d'exécution tout compris.
Cela signifie qu'un morceau de logiciel, avec toutes ses dépendances, bibliothèques, autres binaires et fichiers de configuration, est emballé et distribué aux clients en tant que package unique.
La plateforme d'application et ses dépendances peuvent être protégées des conséquences des changements dans la distribution du système d'exploitation et l'infrastructure sous-jacente si elles sont regroupées dans des conteneurs.
Quelle est la différence entre les conteneurs et la virtualisation ?
Une machine virtuelle est un package qui peut être partagé lors de l'utilisation de la technologie de virtualisation. Ce package comprend à la fois le programme et le système d'exploitation utilisé.
Sur un serveur physique exécutant trois machines virtuelles, vous auriez une installation d'un hyperviseur, ainsi que trois systèmes d'exploitation distincts.
D'un autre côté, un serveur Docker qui héberge trois programmes conteneurisés n'a besoin d'exécuter qu'un seul système d'exploitation car tous les conteneurs partagent le même noyau. Les composants standard du système d'exploitation ne peuvent être que lus, mais chaque conteneur a son propre point de montage ou mécanisme d'accès, ce qui lui permet de stocker et de récupérer des données.
Cela suggère que les conteneurs sont beaucoup plus légers que les machines virtuelles et utilisent considérablement moins de ressources.
Existe-t-il un format standard pour les conteneurs ?
Lorsque CoreOS a publié sa propre spécification App Container Image (ACI) en 2015, certaines personnes craignaient que le mouvement des conteneurs en rapide croissance ne se fragmente en différents formats de conteneurs Linux. C'est parce que ACI signifiait "App Container Image".
En revanche, le projet Open Container, qui deviendrait par la suite l'Open Container Initiative (OCI), n'a pas été rendu public avant la seconde moitié de la même année.
L'Open Container Initiative, dirigée par la Linux Foundation, vise à établir une norme industrielle pour les formats de conteneurs ainsi que pour les logiciels de runtime de conteneurs compatibles avec tous les systèmes d'exploitation (OCI).
La technologie Docker a été utilisée pour développer les directives du projet Open Container (OCP), et Docker a donné environ 5 pour cent de leur logiciel pour aider à lancer l'effort.
Qu'est-ce que l'Open Container Initiative ?
L'Open Container Initiative (OCI) est une organisation dont la mission est de garantir que les aspects fondamentaux de la technologie des conteneurs, tels que le format des conteneurs, soient standardisés afin que chacun puisse les utiliser.
En conséquence, les entreprises peuvent concentrer leurs efforts sur le développement du logiciel complémentaire dont elles ont besoin afin d'utiliser des conteneurs standardisés dans un environnement d'entreprise ou de cloud (au lieu de développer des technologies concurrentes pour les conteneurs).
Les composants logiciels appelés solutions d'orchestration et de gestion de conteneurs, ainsi que les systèmes de sécurité de conteneurs, sont des composants essentiels.
Types de plateformes de conteneurs
En raison du développement et de l'expansion de la technologie des conteneurs, un certain nombre de choix différents sont actuellement disponibles.
Docker est, sans aucun doute, la plateforme de conteneurs la plus courante et la plus largement utilisée disponible.
D'un autre côté, le paysage des technologies de conteneurs comprend d'autres technologies, chacune ayant ses propres cas d'utilisation et avantages.
Nous examinerons les deux plus célèbres, c'est-à-dire Docker et Podman.
Docker
Docker est la plateforme de conteneurs actuellement la plus populaire et la plus largement utilisée. Elle vous permet de développer et d'utiliser des conteneurs Linux.
Docker est un logiciel qui, en utilisant des conteneurs, simplifie les processus de création, de déploiement et d'exploitation d'applications logicielles. Il le fait en minimisant le nombre d'étapes dans chaque processus.
Docker a obtenu le soutien non seulement des principales distributions Linux, telles que Red Hat et Canonical, mais aussi de grandes organisations, telles que Microsoft, Amazon et Oracle.
Pratiquement toutes les entreprises concernées par les technologies de l'information et le cloud computing utilisent Docker.
Architecture et composants de Docker
Docker est construit sur une architecture client-serveur. Le démon Docker permet la création, l'exploitation et la distribution de conteneurs Docker.
Le client Docker et le démon Docker peuvent interagir via une interface de programmation d'applications (API) REST, des sockets UNIX ou une interface réseau.
 Source : docs.docker.com
Source : docs.docker.com
L'architecture de Docker est composée des cinq principaux composants suivants :
- Docker Daemon gère les objets Docker tels que les images, les conteneurs, les réseaux et les volumes. Il répond également aux requêtes de l'API Docker.
- Docker Clients permet aux utilisateurs d'interagir avec Docker en permettant à l'utilisateur de se connecter avec Docker. Le client Docker fournit une interface CLI qui permet aux utilisateurs d'envoyer des commandes d'application à un démon Docker et de démarrer et arrêter de telles opérations.
- Docker Host fournit un environnement complet d'exécution et d'exploitation de programmes logiciels. Ce système comprend le démon Docker, les images, les conteneurs, les réseaux et les composants de stockage.
- Docker Registry maintient les images Docker. Docker Hub est un registre public, et par défaut, Docker est configuré pour utiliser les images enregistrées sur Docker Hub. Vous pouvez l'utiliser pour administrer votre propre registre.
- Docker Images sont des modèles qui ne peuvent être que lus et produits en suivant un ensemble d'instructions d'un Dockerfile. Les images spécifient l'apparence que nous voulons pour notre programme emballé, ses dépendances et les processus qui doivent s'exécuter lorsque l'application est lancée.
Composants d'isolation des ressources dans Docker
Namespaces :
- Namespace PID pour l'isolation des processus.
- Namespace NET pour la gestion des interfaces réseau.
- Namespace IPC pour la gestion de l'accès aux ressources IPC.
- Namespace MNT pour la gestion des points de montage du système de fichiers.
- Namespace UTS pour l'isolation des identifiants du noyau et de la version.
Groupes de contrôle
- Groupe de contrôle de la mémoire qui supervise la comptabilité ainsi que les restrictions et les alertes
- HugeTBL est un groupe de contrôle qui suit l'utilisation des pages énormes par chaque groupe de processus.
- Groupe CPU responsable de la régulation du temps que les utilisateurs et le système passent à utiliser le CPU.
- Le groupe de contrôle CPUSet permet d'associer un groupe à un certain CPU. Utilisé pour les charges de travail en temps réel et les systèmes NUMA avec une mémoire localisée pour chaque CPU.
- Groupe de contrôle BlkIO pour mesurer et limiter la quantité de BlkIO que chaque groupe produit.
- Les groupes de contrôle net cls et net prio sont utilisés pour l'étiquetage du contrôle du trafic.
- Groupe de contrôle des appareils pour accéder aux appareils qui peuvent lire et écrire des données.
- Groupe de contrôle pour la congélation d'un groupe appelé le congélateur. Il est utile pour la planification des lots de clusters, le déplacement de processus et le dépannage.
Système de fichiers Union
- Les images Docker sont composées de systèmes de fichiers en couches, ce qui leur permet d'être extrêmement légères et rapides. Les systèmes de fichiers Union sont des systèmes de fichiers basés sur des couches.
- Le moteur Docker a la capacité d'utiliser plusieurs versions différentes de UnionFS, telles que AUFS, btrfs, vfs et devicemapper.
- Pour exécuter cinq conteneurs d'images de 250 Mo, nous aurions besoin de 1,25 Go d'espace disque si nous n'avions pas UnionFS.
L'interface Docker peut sembler être une boîte noire mystérieuse contenant une variété de technologies inconnues lorsqu'elle est vue de l'extérieur. Malgré leur obscurité relative, ces technologies sont à la fois très intéressantes et utiles.
Bien que nous n'ayons pas besoin de comprendre ces technologies pour utiliser Docker efficacement, il est toujours bénéfique d'apprendre et d'avoir une connaissance de ces technologies.
Si nous avons une compréhension plus profonde de l'instrument, il sera beaucoup plus facile pour nous de prendre les bonnes décisions, telles que celles concernant l'optimisation des performances ou les implications de sécurité.
De plus, cela facilite la découverte de nouvelles technologies innovantes, qui peuvent avoir beaucoup plus d'utilisations pour l'organisation que prévu initialement.
Juste une note :
Docker n'a pas besoin de cgroupfs comme pilote de groupe de contrôle. Le cgroup peut être changé en systemd.
Le propre gestionnaire de groupe de contrôle de Docker est cgroupfs. Néanmoins, pour la plupart des distributions Linux, systemd est le système d'initialisation par défaut, et systemd a une interaction étroite avec les groupes de contrôle Linux.
Pour Kubernetes, il est recommandé d'utiliser systemd, car l'utilisation de cgroupfs en conjonction avec systemd semble être sous-optimale.
Ainsi, systemd est préférable pour la gestion des cgroups. kubelet est configuré pour utiliser systemd par défaut. Par conséquent, Docker doit être modifié pour utiliser le pilote systemd.
Docker Engine a déclenché le mouvement de conteneurisation
Le moteur Docker est le runtime de conteneur de facto pour les plateformes Linux et Windows Server.
Docker développe des outils simples et une stratégie d'emballage uniforme qui encapsule toutes les exigences de l'application dans un conteneur, qui est ensuite exécuté par le moteur Docker.
Le moteur Docker permet aux applications conteneurisées de fonctionner de manière fiable n'importe où sur n'importe quelle infrastructure, résolvant le "dependency hell" pour les développeurs et les équipes d'exploitation et supprimant le problème "ça marche sur mon portable !".
Podman
Podman est le produit de RedHat. Docker et Podman sont assez comparables l'un à l'autre à bien des égards.
Podman fournit une interface de ligne de commande compatible avec Docker que vous pouvez aliaser à l'interface de ligne de commande Docker avec la commande $ alias docker = podman. De plus, Podman fournit un service d'API REST activé par socket qui permet aux applications distantes de lancer des conteneurs chaque fois qu'elles le souhaitent.
Les utilisateurs de docker-py et docker-compose sont en mesure de se connecter avec Podman en tant que service car cette API REST prend également en charge l'API Docker.
En utilisant la bibliothèque libpod, Podman est en mesure de gérer l'ensemble de l'écosystème des conteneurs, qui comprend les pods, les conteneurs, les images de conteneurs et les volumes de conteneurs.
Podman se distingue de Docker en ce qu'il ne nécessite pas de serveur et a une conception légère et sans démon. Cela signifie qu'il établit un contact direct avec runC pour démarrer les conteneurs, ce qui élimine le besoin d'un serveur de surcharge.
Les conteneurs gérés par Podman peuvent être exploités soit par l'utilisateur root, soit par un utilisateur ayant moins de privilèges que root.
Lors de l'utilisation de Docker, l'interface de ligne de commande Docker est la manière dont nous interagissons avec le démon que Docker exécute en arrière-plan. Le démon, qui fonctionne sur les conteneurs et produit des images, est l'endroit où se trouve la majorité des fonctionnalités du programme.
Ce démon s'exécute avec les permissions de l'utilisateur root. Cela suggère également qu'un conteneur Docker peut avoir accès au système de fichiers de l'ordinateur hôte si la configuration n'est pas faite de manière appropriée.
En revanche, l'architecture de Podman nous permet de collaborer avec l'utilisateur responsable de l'exécution du conteneur, et cet utilisateur n'a pas besoin d'avoir un accès root pour exécuter l'application.
Comparés aux conteneurs qui s'exécutent avec des capacités root, les conteneurs non privilégiés offrent un avantage substantiel. En effet, si un intrus pénètre dans un conteneur non privilégié et s'échappe, l'intrus sera toujours un utilisateur hôte non privilégié. L'utilisation de cette approche fournit une sauvegarde supplémentaire pour nos données.
Il suffit de remplacer Docker par Podman dans les instructions pour l'utiliser. Il a les mêmes commandes que Docker.
$ alias docker=podman
Quels autres avantages Podman offre-t-il ?
- Le support intégré pour systemd permet d'exécuter des processus de conteneur en arrière-plan sans avoir besoin d'un processus démon séparé.
- Nous offre la possibilité de construire et de gérer des Podami, une collection composée d'un ou plusieurs conteneurs fonctionnels. Grâce à cela, la migration future des charges de travail vers Kubernetes et l'orchestration des conteneurs Podman est désormais possible.
- Il est possible de mettre en œuvre une séparation UID en utilisant des namespaces, offrant une couche supplémentaire d'isolation de sécurité pendant l'exécution des conteneurs.
- Peut créer un fichier YAML pour Kubernetes à partir d'un conteneur actuellement en cours d'exécution (avec la commande
$ podman generate kube).
Comment lancer un conteneur
Pour lancer un conteneur, nous avons besoin de deux choses : une image et un runtime.
Les moteurs de conteneurs tels que Docker et Podman ne sont qu'une couche logicielle supplémentaire qui repose sur les runtimes. Ils ne sont pas responsables du lancement effectif des conteneurs eux-mêmes.
Ils initient également l'interaction avec les runtimes en arrière-plan pour démarrer les processus des conteneurs.
Un runtime de conteneur est un logiciel qui exécute et gère les composants nécessaires pour exécuter des conteneurs.
Le runtime est en fait un programme/logiciel qui lance, supprime et retire des conteneurs.
runC est un runtime très célèbre, mais nous avons de nombreux autres runtimes comme gvisor et kata.
Docker se connecte à ce runtime en arrière-plan.
Le fichier de spécification du runtime est un fichier de configuration où nous donnons toutes les choses importantes pour que le conteneur soit lancé comme CMD, dossier, réseau, etc. C'est le fichier que le runtime du conteneur utilise pour lancer le conteneur.
Nous pouvons vérifier que Docker utilise runC comme son moteur de runtime par défaut comme ceci :
$ docker info

Comment utiliser runC – le runtime de conteneur universel

Parce que les "conteneurs" sont une collection d'éléments système complexes et parfois obscurs, ils sont combinés en un seul composant de bas niveau. C'est runC.
En tant qu'outil autonome, les plombiers d'infrastructure du monde entier utilisent runC comme plombage.
runC est un runtime léger et portable pour les conteneurs. C'est un outil de ligne de commande pour créer et exécuter des conteneurs selon la spécification Open Container Initiative (OCI). Il dispose de libcontainer, qui est l'interface de bibliothèque de couche inférieure originale que le moteur Docker utilisait pour configurer ce que nous appelons un conteneur de système d'exploitation.
runC est conçu avec les principes de sécurité, d'utilisabilité à grande échelle et sans dépendance à Docker à l'esprit.
Chaque fois que nous lançons un conteneur, il démarre en une seconde. Il semble qu'un nouveau système d'exploitation ait été lancé car il possède toutes les choses qu'un système d'exploitation aurait (comme toutes les commandes, la carte réseau, et plus encore). Il semble être un système d'exploitation indépendant.
Comment un conteneur peut-il être lancé en une seconde ?
Comme vous le savez peut-être, lorsque vous exécutez un programme, il devient un processus. Donc même ici, chaque conteneur en cours d'exécution est un processus dans le système hôte. Donc chaque fois que nous lançons un conteneur, cela signifie que nous avons démarré un processus.
Il semble que ce conteneur soit un système d'exploitation différent avec son propre système de fichiers, réseau, etc., comme je l'ai mentionné ci-dessus. Mais le noyau exécute toute cette configuration à l'intérieur d'un processus en utilisant le concept de namespaces. Nous discuterons des namespaces plus en détail dans une minute.
Ainsi, comme le conteneur est un processus, il se lance rapidement.
Un conteneur est simplement un processus s'exécutant dans la RAM. Ce processus semble exécuter un système d'exploitation complet à l'intérieur d'un système d'exploitation. Typiquement, le processus (conteneur) exécute la commande bash, qui a une durée de vie infinie jusqu'à ce que quelqu'un donne une commande de sortie.
Si nous inspectons le conteneur, nous pouvons trouver le PID de la commande /bin/bash s'exécutant dans le système d'exploitation de base. Maintenant, si nous tuons le processus de /bin/bash, le conteneur sera également terminé.

Qu'est-ce qu'un namespace ?
Encore une fois, l'exécution d'un conteneur est également un processus. Mais avec Docker, un conteneur est fourni avec son propre utilisateur principal, sa configuration réseau, ses dossiers de montage, son système de fichiers, etc., qu'ils obtiennent comme composant commun du système d'exploitation de base. Par conséquent, le conteneur dispose maintenant de son propre environnement isolé, appelé namespace.
$ lsns
# Pour lister tous les namespaces dans le système d'exploitation de base
Pour lancer un conteneur, Docker crée un fichier de spécification de runtime pour runC, puis runC utilise celui-ci pour lancer le conteneur. runC crée des namespaces pour le processus du conteneur.
L'image fonctionne comme un disque dur, c'est-à-dire qu'elle contient l'ensemble du système de fichiers pour le conteneur. Une image de conteneur regroupe toutes les données qui sont montées sur un namespace de stockage (c'est-à-dire un namespace de montage).
L'image crée l'ensemble du bundle dans le répertoire "/" des conteneurs. Nous devons le décompresser en le décompressant.
Notez que runC ne téléchargera pas, ne décompressera pas ou ne décompressera pas les images pour nous. Il peut lancer le conteneur et monter les fichiers pour nous dans le conteneur. Pour les images, nous avons besoin de certains outils de gestion d'images.
De plus, runC ne nous fournit qu'un namespace réseau, mais Docker doit gérer le réseau (c'est-à-dire spécifier la plage d'IP, fournir des IP, etc.).
Docker peut télécharger, décompresser ou décompresser les images. Il peut également effectuer la configuration réseau requise. Il peut également se connecter au stockage pour nous, et de nombreuses autres fonctionnalités sont fournies par Docker. Typiquement, Docker peut faire presque tout ce que Kubernetes fournit via ses commandes.
Dans Docker, nous avons une architecture client-serveur dans laquelle nous avons Docker CLI fonctionnant comme le programme client et le conteneur comme le serveur. Le serveur se connectera maintenant au runtime et lancera le conteneur pour nous.
Si nous voulons lancer le conteneur directement, nous pouvons le faire avec l'aide de runC.
Tout d'abord, nous devons installer runC en utilisant yum.
$ runc list
# Cela listera les conteneurs disponibles.
$ runc spec
# Pour créer un fichier de spécification de runtime dans le répertoire courant.
runC est écrit en langage Go. Donc, généralement, il supporte les programmes Go (les images sont également écrites en langage Go).
$ go build -o name est la commande pour compiler un programme Go.
Commandes runC :
$ runc create <cont_name>
# Pour lancer un conteneur (Cela prendra le fichier de configuration du répertoire courant).
$ runc start <cont_name>
# Cette commande exécutera et donnera la sortie du programme que nous avons spécifié dans le conteneur.
Dans l'espace de travail, nous utilisons ce qui suit :
$ runc spec
# Cela créera un fichier config.json pour la configuration runC.
Dans le fichier congif.json, nous devons changer les valeurs des paramètres selon nos besoins.
Par exemple, si nous ne voulons pas le terminal, nous devons le mettre à false. Pour cela, nous pouvons donner la commande à exécuter dans l'arg, nous pouvons définir le nom d'hôte, etc.
Nous pouvons nous connecter à ce namespace de conteneur en faisant ce qui suit :
$ nsenter -u -t -n <pid_of_container>
# Pour entrer dans le namespace utilisateur et réseau d'un ID de processus spécifique.
Pour créer un conteneur en utilisant uniquement runC :
- Installez runC.
- Créez config.json en exécutant la commande runC spec.
- Mentionnez toutes les choses importantes dans le fichier ci-dessus. Nous devons également donner le processus en écrivant son code en langage Go.
- Créez un dossier rootfs dans l'espace de travail actuel et déplacez le code Go compilé dans ce dossier.
- Maintenant, pour lancer le conteneur :
$ start runc create <container_name>
Pour démarrer le conteneur et imprimer sur la console tout ce qui se trouve dans le fichier go, exécutez cette commande :
$ runc start <container_name>
Comment générer une spécification d'exemple avec runC :
> runc spec
> cat config.json
{
"ociVersion": "1.0.0",
"process": {
"terminal": true,
"user": { "uid": 0, "gid": 0 },
"args": ["sh"],
"env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"TERM=xterm"
],
"cwd": "/",
"capabilities": {
"bounding": ["CAP_AUDIT_WRITE", "CAP_KILL", "CAP_NET_BIND_SERVICE"],
[...]
},
"rlimits": [ { "type": "RLIMIT_NOFILE", "hard": 1024, "soft": 1024 } ],
"noNewPrivileges": true
},
"root": { "path": "rootfs", "readonly": true },
"hostname": "runc",
"mounts": [
{
"destination": "/proc",
"type": "proc",
"source": "proc"
},
[...]
],
"linux": {
"resources": { "devices": [ { "allow": false, "access": "rwm" } ] },
"namespaces": [
{ "type": "pid" },
{ "type": "network" },
{ "type": "ipc" },
{ "type": "uts" },
{ "type": "mount" }
],
"maskedPaths": [
"/proc/kcore",
[...]
],
"readonlyPaths": [
"/proc/asound",
[...]
]
}
}
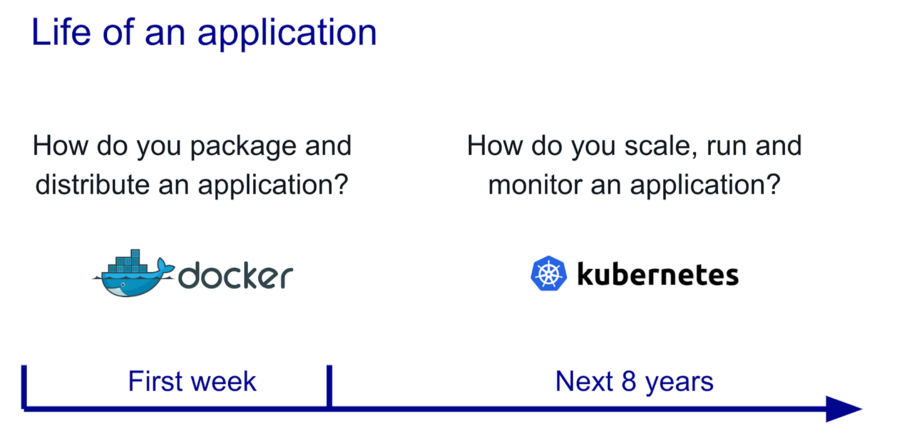
Pourquoi Kubernetes a-t-il déprécié Docker ?
Docker est souvent le premier choix lorsqu'il s'agit de gérer et de créer des conteneurs et des images. Il est extrêmement rapide – vous vous demandez peut-être pourquoi Kubernetes a abandonné Docker et est passé à l'utilisation du moteur de conteneur CRI-O ? Explorons cela.
 Source : https://www.sumologic.com/blog/kubernetes-vs-docker/
Source : https://www.sumologic.com/blog/kubernetes-vs-docker/
Nous pouvons vérifier le moteur de conteneur Docker comme ceci :
$ systemctl status docker

Ici, il montre Docker Application Container Engine mais containerD est le moteur réel en cours d'exécution.
Dans Docker, lorsque kubelet doit se connecter à containerD, il doit passer par une API Docker shim pour contacter runC. Cela agit comme une interface entre Docker et Kubernetes. Cela rend l'ensemble du processus assez complexe.
 Source : Tutorial Works
Source : Tutorial Works
Qu'est-ce que containerD ?
ContainerD est un runtime de conteneur standard de l'industrie qui met l'accent sur la simplicité, la durabilité et la portabilité.
Vous pouvez trouver une implémentation basée sur démon de containerD sur Linux et Windows. Il est responsable de la gestion de l'ensemble du cycle de vie des conteneurs du système sur lequel il est hébergé, ce qui inclut le transfert et le stockage des images, l'exécution et la surveillance des conteneurs, le stockage de bas niveau et les attaches réseau.
Fonctionnalités de containerD :
- Prise en charge de la spécification OCI Image
- Prise en charge de la poussée et de la traction des images
- Primitives réseau pour la création, la modification et la suppression d'interfaces
- Multi-locataire pris en charge avec stockage CAS pour les images globales
- Prise en charge de la spécification OCI Runtime (aka runC)
- Prise en charge du runtime et du cycle de vie des conteneurs
- Gestion des namespaces réseau des conteneurs pour rejoindre les namespaces existants

Qu'est-ce que dockerd ?
Le démon de Docker peut être lancé avec l'aide de dockerd (afin que vous puissiez commander au démon de gérer les images, les conteneurs, etc.). Dockerd est un serveur qui s'exécute en arrière-plan en tant que démon.
Pour exécuter le démon Docker, nous pouvons spécifier dockerd. Après le mot-clé dockerd, vous devez fournir les paramètres du démon que vous souhaitez utiliser.
dockerd (Docker Daemon) peut écouter les requêtes de l'API Docker Engine via trois types différents de Sockets : unix, tcp et fd.
Défis de l'utilisation de Docker
Surcharge
Docker est une plateforme assez développée sur le marché des conteneurs. En plus de la gestion des conteneurs, il offre de nombreuses autres capacités comme le stockage, la sécurité et l'infrastructure réseau, entre autres.
Comparé à Cri-O et Podman, les performances de Docker souffrent directement de la surcharge causée par ces fonctionnalités supplémentaires.
Mais Kubernetes et OpenShift sont équipés de toutes ces fonctions. Par conséquent, ils ne veulent qu'une seule chose du moteur de conteneur : la capacité de lancer et de gérer les conteneurs. En d'autres termes, ils n'ont pas besoin d'autres fonctions.
Dockershim
Dans Kubernetes, le processus de lancement des conteneurs commence lorsque kubelet communique avec containerD, qui contacte ensuite runC.
Parce que des entreprises séparées sont responsables de la production de containerD et de kubelet, kubelet doit avoir une couche supplémentaire afin de contacter containerD (une couche de type API). Et dans l'écosystème Docker, cette couche est appelée Dockershim.
Kubernetes a déprécié dockershim en raison des complexités et du fardeau créés par les mises à jour de Docker.
Quel est le problème avec dockershim ?
Kubernetes a suggéré une solution temporaire pour inclure le support de Docker afin qu'il puisse servir de runtime de conteneur. La dépréciation de Dockershim signifie simplement que le code de Dockershim ne sera plus maintenu dans le dépôt source de Kubernetes.
Dockershim est devenu un problème majeur pour les développeurs de Kubernetes. Suite à ce changement, la communauté Kubernetes ne sera autorisée à maintenir que l'interface Kubernetes Container Runtime Interface (CRI).
Kubernetes prend en charge tous les runtimes conformes à la CRI, tels que containerD et CRI-O.
Kubernetes a développé CRI-O comme son interface pour contacter runC. Kubelet contactera désormais CRI-O. Ensuite, il contactera runC, et le conteneur sera lancé.
Cependant, comme CRI-O et Docker, il existe de nombreux moteurs de conteneurs. Ainsi, la communauté Kubernetes a décidé de créer une couche d'abstraction au-dessus de tous les moteurs de conteneurs. Ainsi, un client peut utiliser n'importe quel moteur de conteneur selon ses besoins.
Cette couche d'abstraction est appelée CRI (container runtime interface).
 Kubernetes utilisant Docker vs Kubernetes utilisant CRI-O
Kubernetes utilisant Docker vs Kubernetes utilisant CRI-O
Qu'est-ce qu'une CRI (Container Runtime Interface) ?
Le programme Kubelet abstrait les moteurs de conteneurs sous-jacents. L'interface de runtime de conteneur (CRI) est une interface de plugin qui permet à kubelet d'utiliser plusieurs runtimes de conteneurs sans recompilation.
En plus des buffers de protocole, de l'API gRPC et des bibliothèques, d'autres spécifications et outils sont en développement actif pour la CRI.
Kubelet établit une connexion avec la CRI via le protocole gRPC.
Qu'est-ce que CRI-O ?
CRI-OCI est une abréviation qui signifie Container Runtime Interface et OCI, qui signifie Open Container Initiative.
Le terme CRI-O a été choisi après avoir pris en compte les références faites par les membres des communautés CRI et CIO.
CRI-O est un autre moteur de conteneur, mais il est plus léger que Docker puisqu'il n'inclut pas les capacités supplémentaires que Docker possède, telles que le réseau, le stockage, etc.
CRI-O fournit une base plus sécurisée, stable et performante pour l'exécution de runtimes compatibles avec l'Open Container Initiative (OCI). Les runtimes conformes à l'OCI peuvent être utilisés en conjonction avec le moteur de conteneur CRI-O pour lancer des conteneurs et des pods.
Des exemples de tels runtimes incluent runC, qui est le runtime OCI par défaut, et Kata Containers. Mais vous pouvez utiliser n'importe quel runtime conforme à l'OCI à sa place.
L'objectif du projet CRI-O est de remplacer Docker en tant que moteur de conteneur qui implémente l'interface Kubernetes Container Runtime Interface (CRI) pour OpenShift Container Platform et Kubernetes.
La stabilité de CRI-O peut être attribuée au fait qu'il est développé, testé et distribué en tandem avec les versions majeures et mineures de Kubernetes et qu'il est conforme aux normes OCI.
Les O dans la portée de CRI sont dépendants de l'interface Container Runtime Interface (CRI). Les spécifications réelles du moteur de conteneur d'un service Kubernetes (kubelet) ont été compilées et spécifiées par CRI.
Compte tenu du fait que plusieurs moteurs de conteneurs étaient en cours de développement, l'équipe CRI a décidé de prendre cette mesure afin de répondre aux exigences de Kubernetes en matière de moteurs de conteneurs.
Selon les documents OpenShift, les outils qui aident à remplacer et à étendre ce que la commande et le service Docker fournissaient sont :
- crictl : Pour travailler directement avec les moteurs de conteneurs CRI-O et le dépannage
- runc : Pour exécuter des images de conteneurs
- podman : Pour gérer les pods et les images de conteneurs (exécuter, arrêter, démarrer, ps, attacher, exec, etc.) en dehors du moteur de conteneur
- buildah : Pour construire, pousser et signer des images de conteneurs
- skopeo : Pour copier, inspecter, supprimer et signer des images
Architecture de CRI-O
 Source : cri-o.io
Source : cri-o.io
Comment construire un cluster multi-nœuds en utilisant CRI-O
Voici les commandes que vous utiliseriez pour créer un cluster Kubernetes multi-nœuds en utilisant CRI-O dans Ubuntu 20.04.
Voici le dépôt qui contient l'ensemble des commandes :
OS=xUbuntu_20.04
VERSION=1.20
cat >>/etc/apt/sources.list.d/devel:kubic:libcontainers:stable.list<<EOF
deb https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/ /
EOF
cat >>/etc/apt/sources.list.d/devel:kubic:libcontainers:stable:cri-o:$VERSION.list<<EOF
deb http://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable:/cri-o:/$VERSION/$OS/ /
EOF
curl -L https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/stable/$OS/Release.key | apt-key --keyring /etc/apt/trusted.gpg.d/libcontainers.gpg add -
curl -L https://download.opensuse.org/repositories/devel:kubic:libcontainers:stable:cri-o:$VERSION/$OS/Release.key | apt-key --keyring /etc/apt/trusted.gpg.d/libcontainers-cri-o.gpg add -
apt update
apt install -qq -y cri-o cri-o-runc cri-tools
systemctl daemon-reload
systemctl enable --now crio
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
apt-add-repository "deb http://apt.kubernetes.io/ kubernetes-xenial main"
apt install -qq -y kubeadm=1.20.5-00 kubelet=1.20.5-00 kubectl=1.20.5-00
cat >>/etc/modules-load.d/crio.conf<<EOF
overlay
br_netfilter
EOF
modprobe overlay
modprobe br_netfilter
cat >>/etc/sysctl.d/kubernetes.conf<<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system
cat >>/etc/crio/crio.conf.d/02-cgroup-manager.conf<<EOF
[crio.runtime]
conmon_cgroup = "pod"
cgroup_manager = "cgroupfs"
EOF
systemctl daemon-reload
systemctl enable --now crio
systemctl restart crio
sed -i '/swap/d' /etc/fstab
swapoff -a
systemctl disable --now ufw
kubeadm init --apiserver-advertise-address=172.16.16.100 --pod-network-cidr=192.168.0.0/16
kubectl --kubeconfig=/etc/kubernetes/admin.conf create -f https://docs.projectcalico.org/v3.18/manifests/calico.yaml
kubeadm token create --print-join-command
Nous pouvons utiliser la commande de jointure pour connecter les nœuds au cluster et nous sommes prêts avec un cluster multi-nœuds de Kubernetes.
Voici une illustration de la manière dont Docker, Kubernetes, CRI-O, containerD et runC fonctionnent ensemble

Runtimes de conteneurs
Nous avons vu beaucoup de détails sur le fonctionnement des conteneurs, nous avons défini les runtimes de conteneurs et comment nous pouvons construire notre conteneur personnalisé en utilisant runC. Maintenant, y a-t-il d'autres outils à notre disposition comme runC ?
Ici, nous examinerons le paysage de tous les runtimes de conteneurs disponibles.
Généralement, ils se divisent en deux catégories principales :
- Runtimes Open Container Initiative (OCI)
Les runtimes OCI sont également classés en deux catégories plus larges : Runtimes Natifs et Runtimes Sandboxés et Virtualisés
- Interface de Runtime de Conteneur (CRI)
La CRI se compose de containerD et CRI-O.
 1. Runtimes Open Container Initiative (OCI)
1. Runtimes Open Container Initiative (OCI)
 2. Interface de Runtime de Conteneur (CRI)
2. Interface de Runtime de Conteneur (CRI)
Conclusion
Ici, nous avons vu comment nous pouvons construire nos propres images personnalisées et les divers outils disponibles à notre disposition. C'était un long article, mais j'espère que vous l'avez apprécié et que vous avez appris quelque chose de nouveau.
Je suis toujours ouvert aux suggestions et aux discussions sur LinkedIn. Envoyez-moi des messages directs.
Si vous avez apprécié mon écriture et que vous souhaitez me garder motivé, envisagez de laisser des étoiles sur GitHub et de m'endosser pour des compétences pertinentes sur LinkedIn.
Jusqu'à la prochaine fois, restez en sécurité et continuez à apprendre.