

Article original : How to build a movie bot with SAP Conversational AI and NodeJS
Par Paul Pinard
Obtenez des recommandations de films de The Movie Database en demandant à votre propre chatbot sur Facebook Messenger.

À la fin de ce tutoriel, vous serez en mesure de construire un bot de films entièrement fonctionnel, capable de faire des recommandations de films basées sur plusieurs critères. Nous utilisons la plateforme de construction de bots SAP Conversational AI (inscrivez-vous ici gratuitement) et The Movie Database pour obtenir des informations sur les films.
Voici une démonstration de chat avec Movie Bot :
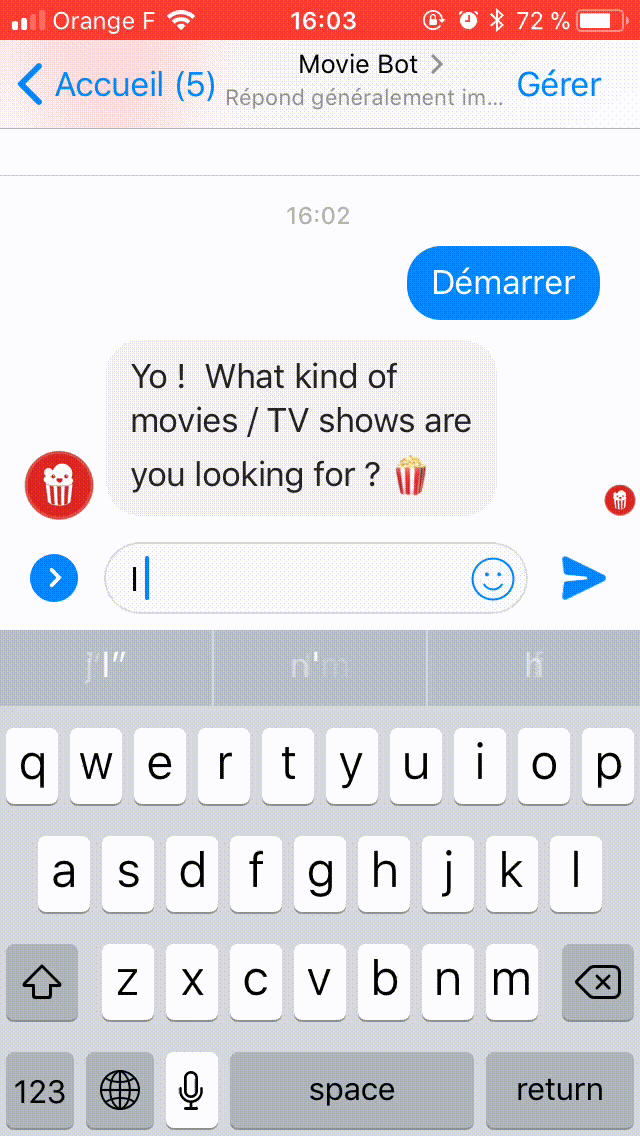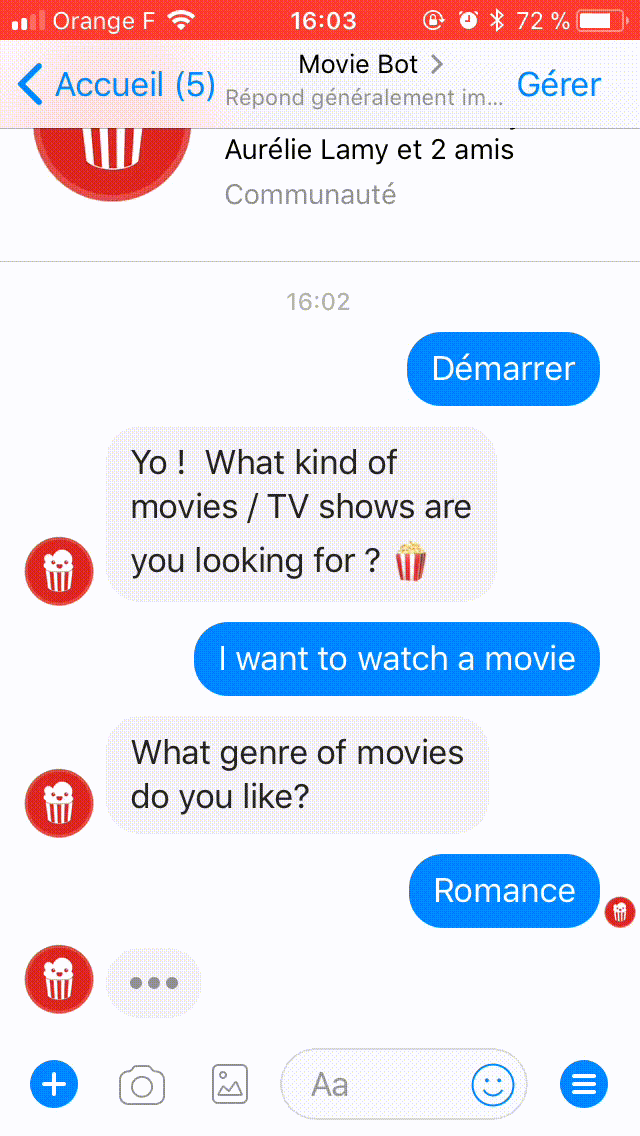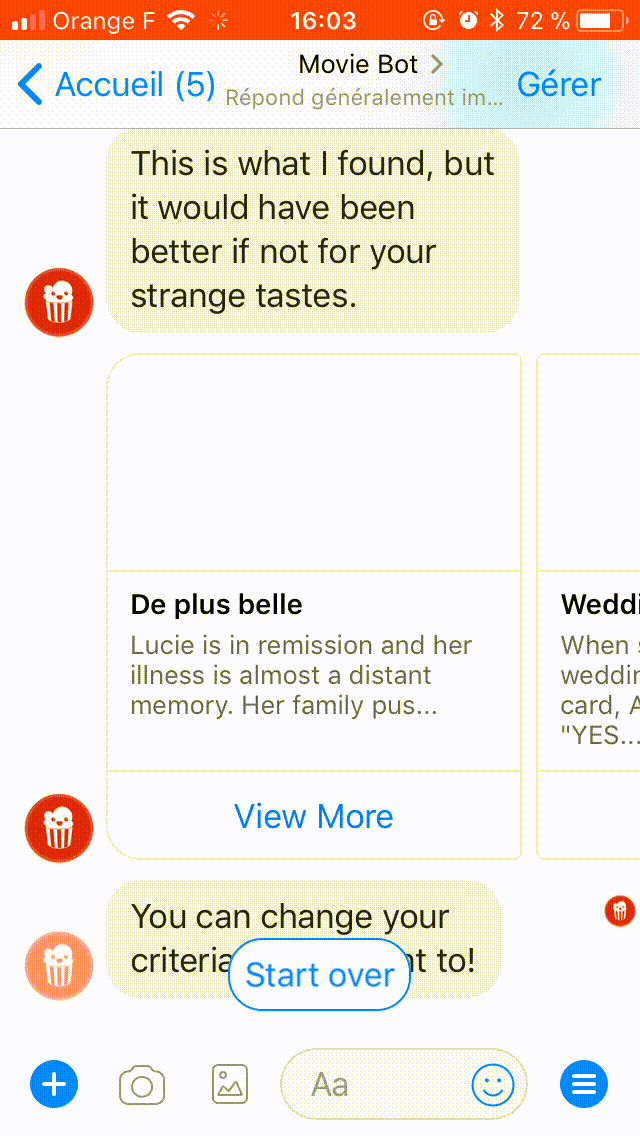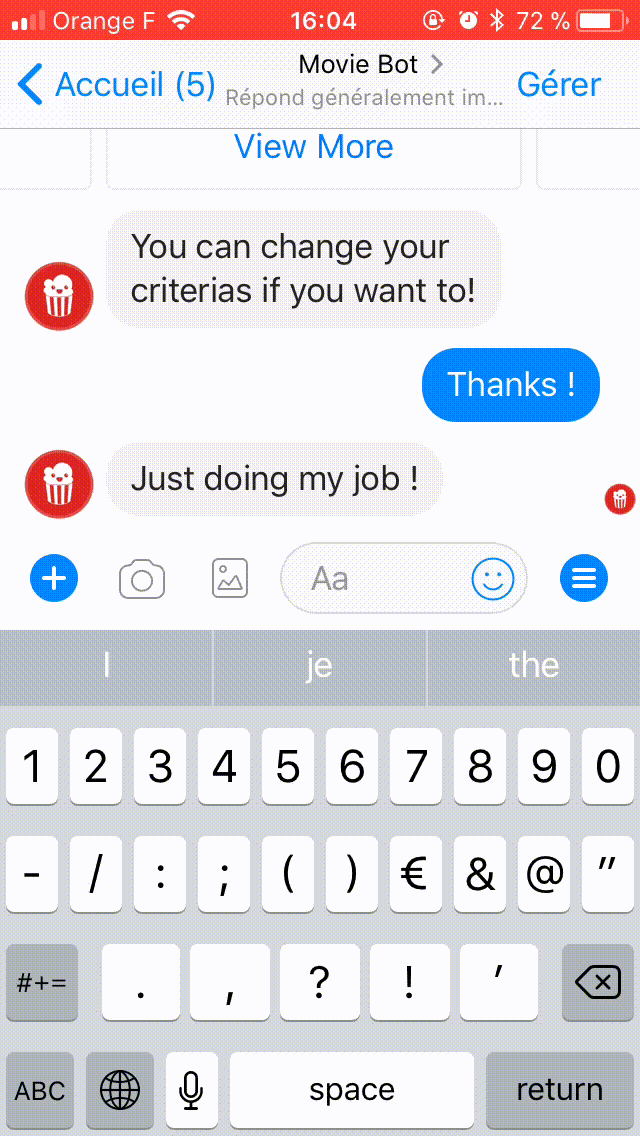
Que construisons-nous aujourd'hui ?
Interagir avec des API tierces permet des cas d'utilisation beaucoup plus intéressants que de simples chatbots de questions/réponses. Avec les compétences de bot, nous avons ajouté l'option d'appeler des webhooks directement depuis le constructeur, ce qui rend cela encore plus facile.
Le bot d'aujourd'hui nécessite plusieurs étapes :
- Extraire des informations clés dans une phrase
- Construire le flux du bot (déclencheurs, exigences, actions)
- Créer et connecter une API de bot capable de récupérer des données de The Movie Database
Vous aurez besoin d'un compte SAP Conversational AI, Node.JS et potentiellement Ngrok pour les tests.
Avant de commencer, veuillez consulter ce guide à la place si vous cherchez un guide détaillant la création de votre premier bot.
Commençons !
Étape 1 : Extraire des informations clés d'une phrase
Les intentions sont utiles pour déterminer le sens général d'une phrase. Pour notre cas d'utilisation, savoir que l'utilisateur veut regarder quelque chose n'est pas suffisant.
Nous devons savoir quoi les utilisateurs veulent regarder.
Les entités sont conçues pour résoudre ce problème : elles extraient des informations clés dans une phrase.
Les intentions vous aident à comprendre que vous devez faire quelque chose. Les entités vous aident à le faire réellement.
Imaginons que vous êtes une entreprise de télécommunications fournissant un accès téléphonique et internet. Votre bot a une intention qui comprend lorsque les gens se plaignent d'une panne :

Les entités extraites aideront à comprendre quoi ne va pas, où et depuis quand.
Pour notre bot de films, nous allons essayer d'extraire 3 informations clés :
- Ce que l'utilisateur veut regarder (un film ou une série TV)
- Le genre qu'il recherche
- Dans quelle langue
Utilisation des entités gold
Pour vous aider à accélérer votre développement, SAP Conversational AI extrait plusieurs entités par défaut : dates, lieux, numéros de téléphone...
Une liste exhaustive est disponible ici.
L'entité Language sera utile :
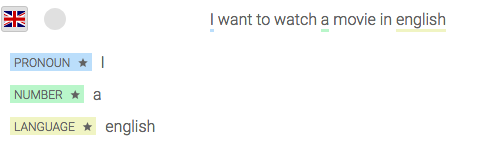
Voyez-vous la petite étoile à côté du nom de l'entité ? Elle différencie une entité gold d'une entité personnalisée.
Nous allons l'utiliser pour remplir notre troisième exigence : la langue du film.
Création d'entités personnalisées
Nous allons créer des entités personnalisées pour extraire les informations dont nous avons besoin. Comme pour les intentions, l'entraînement est très important : plus vous ajoutez d'exemples à votre bot, plus il devient précis.
L'entraînement de vos entités peut se faire à travers plusieurs intentions. Les entités sont indépendantes des intentions.
Pour notre bot de films, nous n'avons besoin que d'une seule intention, discover, et de 2 entités :
recordingpour identifier que l'utilisateur veut regarder un film ou une série TVgenre
Ouvrez l'intention discover et ajoutez des expressions. Assurez-vous de couvrir toutes les possibilités, cela signifie un mélange sain d'expressions avec :
- Aucune entité : « Mon petit ami veut regarder quelque chose ce soir »
- Une entité : « Je veux regarder un film »
- Plusieurs entités : « Peut-tu me recommander des séries TV dramatiques françaises ? »
Pour taguer vos expressions, sélectionnez le texte que vous souhaitez taguer et tapez le nom de votre entité :
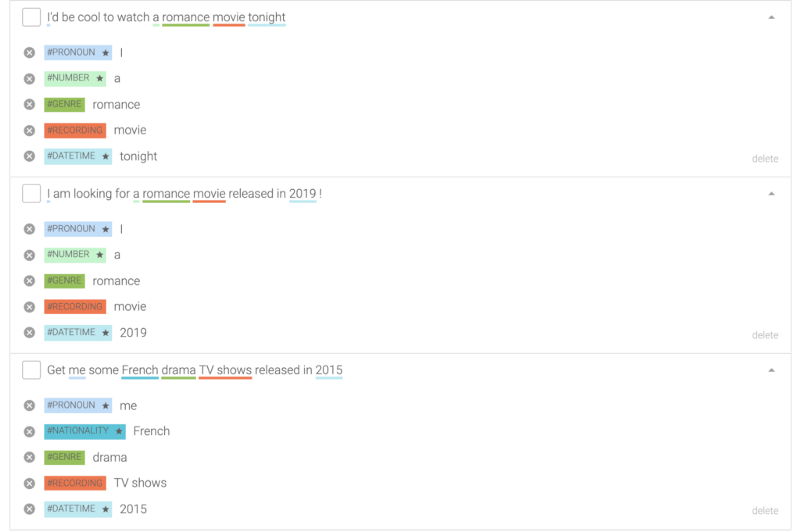
Vous devriez ajouter beaucoup plus d'exemples : 15 seraient bien, mais un bot prêt pour la production nécessiterait au moins 50 exemples pour bien performer. Pour accélérer le processus, vous pouvez fork les entités construites dans ce bot [entité recording, entité genre] puis fork l'intention discover de ce bot.
Vous pouvez voir ici que « French » a été détecté comme une nationalité, et non une langue, car c'est ce qu'il est dans ce contexte. Lors de la construction du flux du bot, nous veillerons à vérifier ces deux entités.
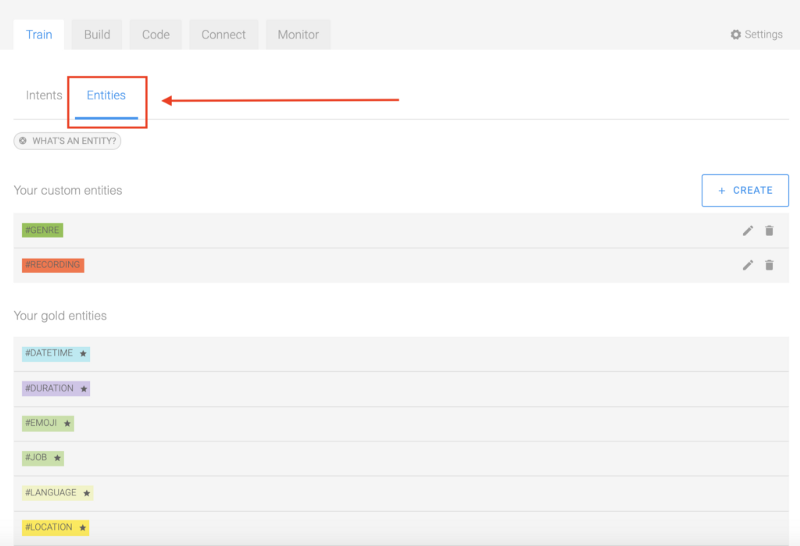
Ajout d'enrichissements personnalisés
Maintenant que nous avons étiqueté nos entités, nous allons les enrichir ! Ouvrez le panneau des entités de votre bot sous l'onglet d'entraînement comme montré ci-dessous :
Ouvrons maintenant l'entité genre. Si vous regardez en haut à droite du panneau, vous devriez voir un toggle disant free - restricted et settings. Ouvrez-le afin que nous puissions expliquer en détail les différentes options auxquelles vous avez accès :
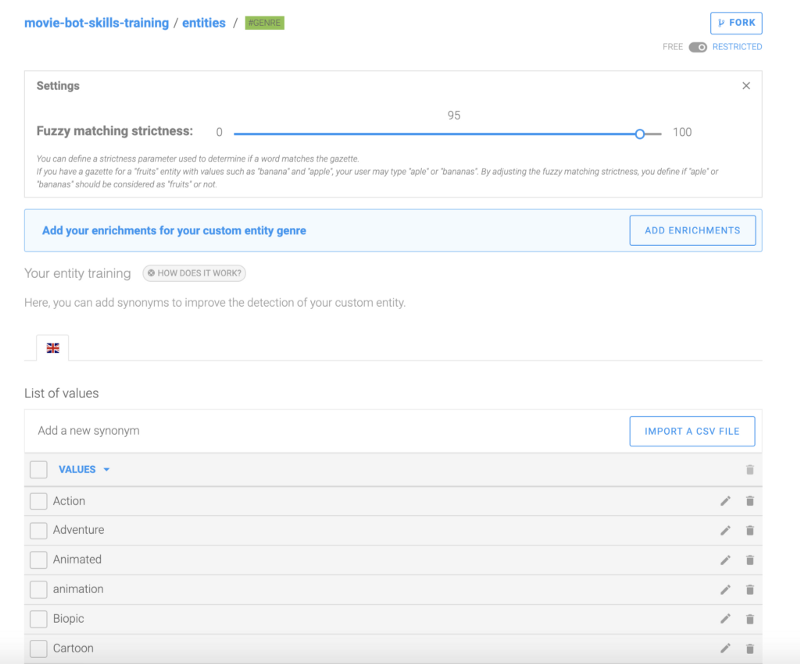
Dans le panneau d'entité, vous avez accès à différentes options pour votre entité :
- Libre vs Restreint — Une entité personnalisée libre est utilisée lorsque vous n'avez pas une liste stricte de valeurs et que vous voulez que le machine learning détecte toutes les valeurs possibles. Alors qu'une entité personnalisée restreinte est utilisée si vous avez une liste stricte de mots à détecter et que vous n'avez pas besoin de détection automatique de l'entité.
- Correspondance floue — La correspondance floue est un indice entre 0 et 1 pour indiquer à quel point un mot peut être proche de celui dans votre liste de valeurs d'entité. Si le mot est au-dessus de cet indice, alors la plateforme le taguera comme la valeur la plus proche dans votre liste.
- Liste de valeurs — C'est ici que vous pouvez ajouter toutes les valeurs de votre entité qui peuvent être différentes valeurs ou synonymes
Pour plus d'informations détaillées sur les entités, vous pouvez lire notre documentation détaillée.
Dans notre cas, notre entité genre sera restreinte car l'API The Movie Database ne gère qu'une liste spécifique de genres. Voici la liste ci-dessous :
[ { id: 28, name: 'Action' }, { id: 12, name: 'Aventure' }, { id: 16, name: 'Animation' }, { id: 35, name: 'Comédie' }, { id: 80, name: 'Crime' }, { id: 99, name: 'Documentaire' }, { id: 18, name: 'Drame' }, { id: 10751, name: 'Famille' }, { id: 14, name: 'Fantaisie' }, { id: 36, name: 'Histoire' }, { id: 27, name: 'Horreur' }, { id: 10402, name: 'Musique' }, { id: 9648, name: 'Mystère' }, { id: 10749, name: 'Romance' }, { id: 878, name: 'Science Fiction' }, { id: 53, name: 'Thriller' }, { id: 10752, name: 'Guerre' }, { id: 37, name: 'Western' } ]
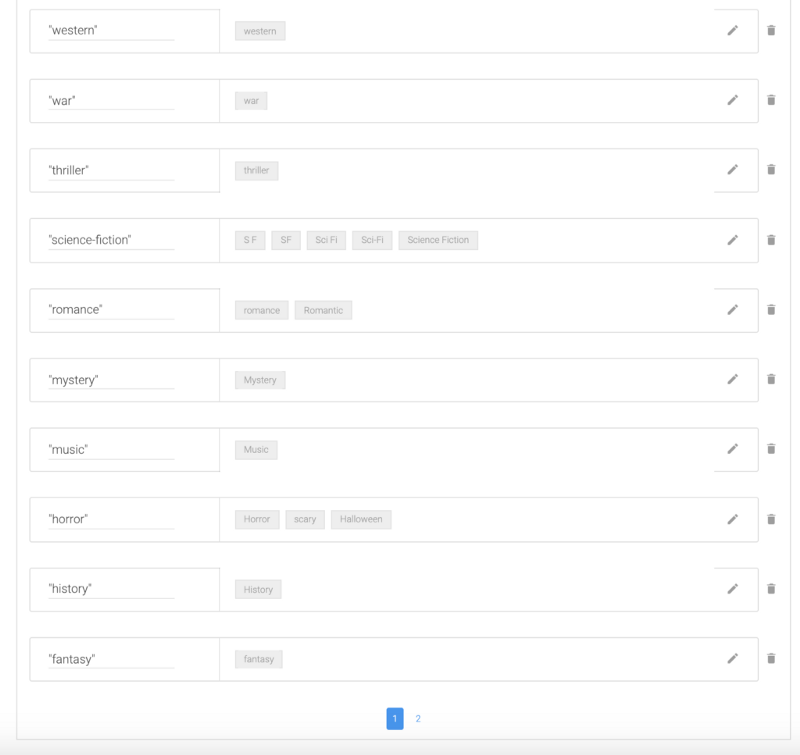
Ajoutez tous les différents genres à notre liste de valeurs. N'oubliez pas d'ajouter également des synonymes tels que SF, Sci-Fi pour Science Fiction, Romantique pour Romance ou Animé, Dessin animé pour Animation. Vous pouvez récupérer la liste des valeurs ici.
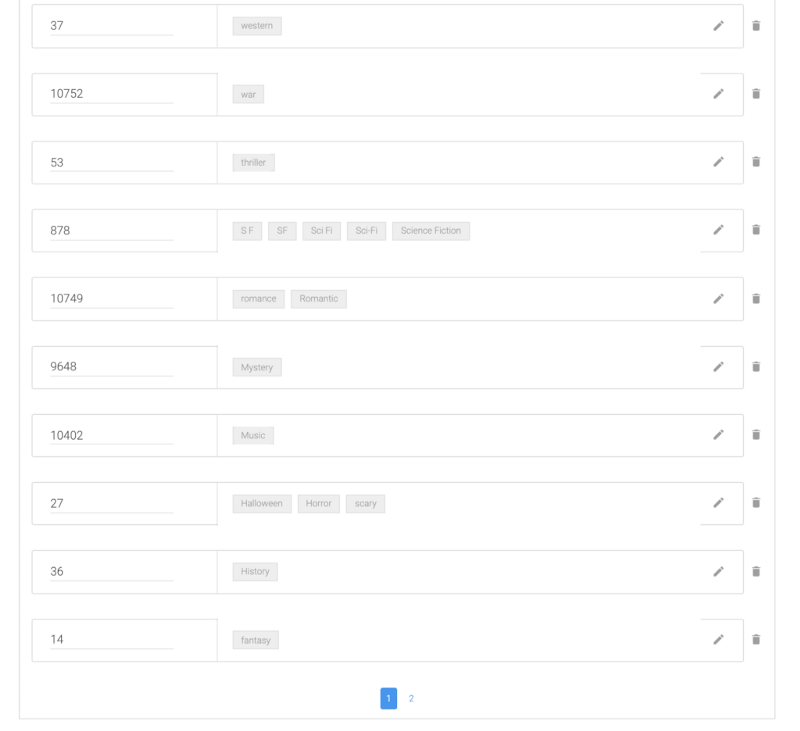
Comme vous pouvez le voir dans le JSON ci-dessus, il y a des ID associés aux genres. La raison est que The Movie Database ne peut pas rechercher un genre spécifique basé sur son nom anglais, mais plutôt sur un numéro personnalisé. Nous pouvons associer pour chacun des genres une valeur d'ID spécifique qui sera retournée dans le JSON de l'API NLP. Nous pouvons la transmettre à l'API The Movie Database. C'est le but des enrichissements personnalisés. Chaque fois qu'une entité est détectée, le JSON retourné par l'API NLP est enrichi avec des informations supplémentaires sur l'entité.
Dans le panneau d'enrichissement personnalisé, nous devons créer 3 clés :
name— pour mapper les synonymes sous la même valeurid— pour enrichir avec l'ID de The Movie Databasearticle— pour ajouter l'article du genre (nous l'utiliserons plus tard)
Pour ajouter un enrichissement personnalisé, cliquez sur add new key et ajoutez les trois clés listées ci-dessus. Pour l'article, définissez la valeur de la clé par défaut sur 'un' car la plupart des genres seraient avec 'un'. Dans le nom, vous pouvez commencer à ajouter l'enrichissement spécifique et le mapper à toutes les différentes valeurs pour votre article, id et name comme ci-dessous :
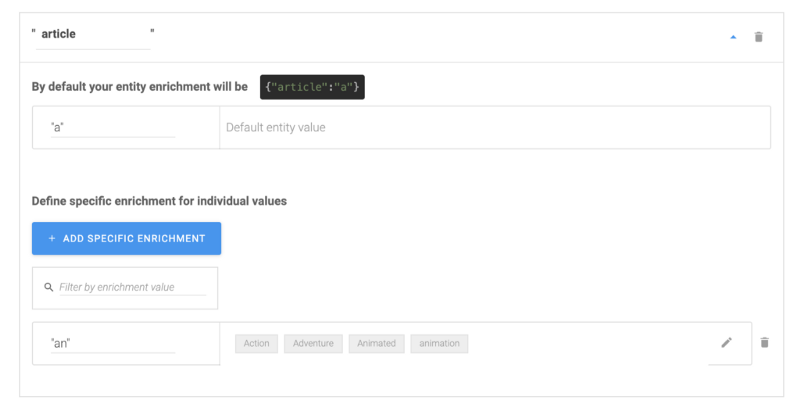
Vous pouvez fork l'entité complète à partir de cette page qui inclura l'enrichissement. Maintenant que cela est fait, testons-le dans la console de test. Si vous envoyez la phrase « Je veux regarder un film d'animation », vous devriez maintenant voir l'enrichissement personnalisé suivant :
"genre": [ { "value": "animated", "raw": "animated", "confidence": 0.99, "name": "animation", "id": 16, "article": "an" }
Super, maintenant notre enrichissement nous donne le nom générique, l'ID et l'article ! Faisons la même chose pour l'entité recording. Retournez au panneau des entités et cliquez sur recording. Ensuite, rendez-le restreint et ajoutez toutes les valeurs et synonymes possibles pour les séries TV et les films (comme séries TV, émissions, film, films, etc.). Voir la liste complète ici. Allez maintenant aux enrichissements personnalisés et ajoutez la clé type et ajoutez 2 valeurs spécifiques :
movie— pour tous les synonymes de filmstv— pour tous les synonymes de séries TV
Cela devrait ressembler à ceci :
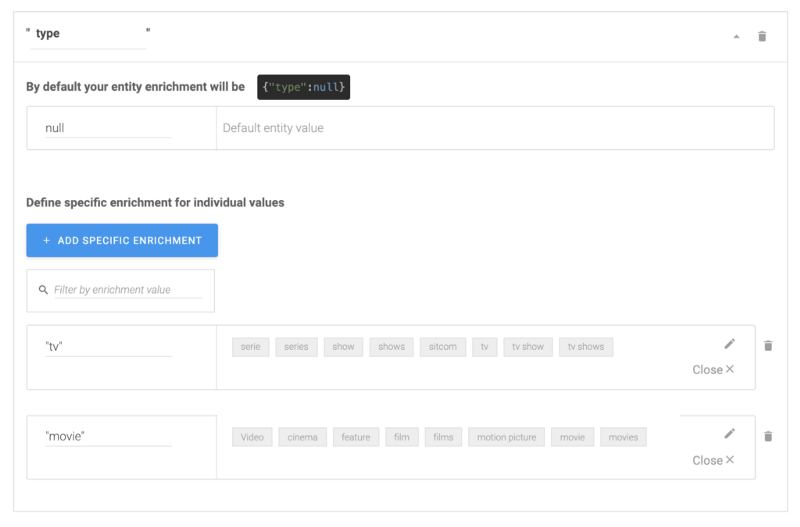
En renvoyant notre phrase « Je veux regarder un film d'animation », nous avons maintenant également l'enrichissement pour recording :
"recording": [ { "value": "movie", "raw": "movie", "confidence": 0.99, "type": "movie" } ]
Étape 2 : Construire le flux de votre bot
Puisque nous devons simplement nous assurer que tous nos critères sont remplis avant d'appeler une API Node.JS, la partie construction sera plutôt simple.
Nous aurons simplement besoin d'une compétence, appelons-la discover.
Vous pouvez trouver un exemple de compétence configurée ici.
Déclencheurs
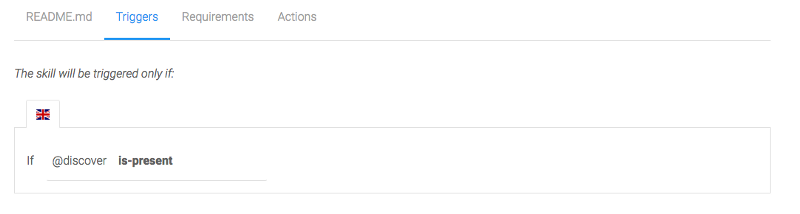
Nous voulons déclencher cette compétence si l'intention @discover est présente :
Cet onglet vous aide à collecter des données avant de passer aux Actions. Nous voulons nous assurer que l'utilisateur spécifie un enregistrement, un genre, une langue et une intention oui ou non avant de continuer :
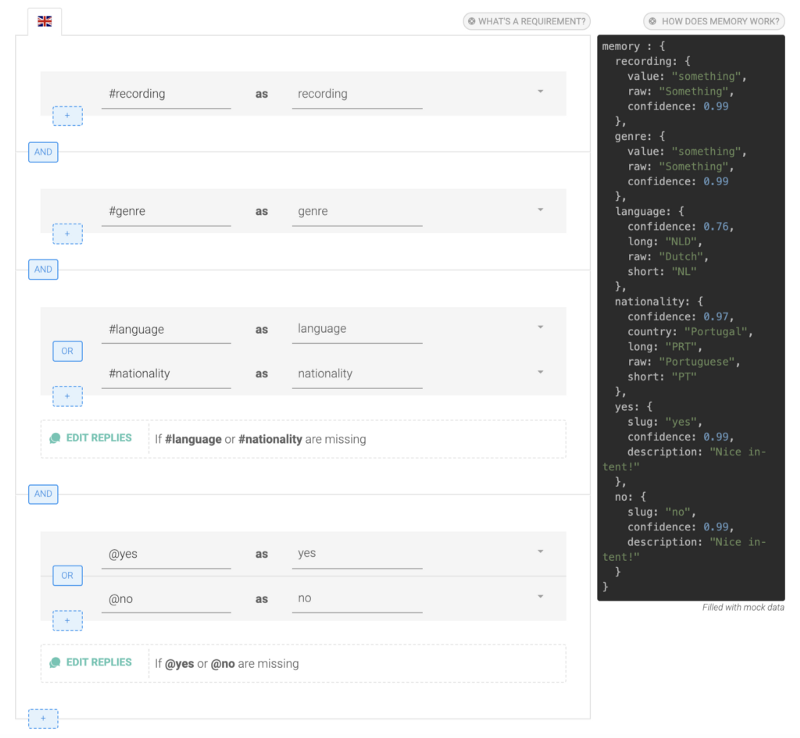
Les exigences seront vérifiées une par une. Elles peuvent toutes être remplies dans le premier message. Par exemple, si l'utilisateur dit Je veux regarder un film policier en anglais, alors les Actions seront déclenchées immédiatement.
Pour chaque exigence, vous pouvez choisir d'envoyer un message si elle est complète ou si elle est manquante.
Envoyer des messages lorsqu'une exigence est complète peut rendre votre bot plus vivant : Un film policier ? J'adore ça aussi !, mais ils sont presque obligatoires lorsque l'exigence est manquante : vous devez demander à vos utilisateurs de remplir ce que vous devez savoir.
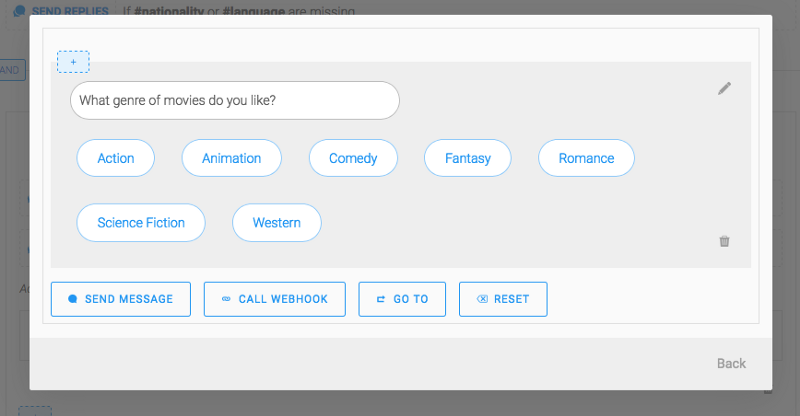
Par exemple, j'envoie des réponses rapides avec des genres suggérés si #genre est manquant :
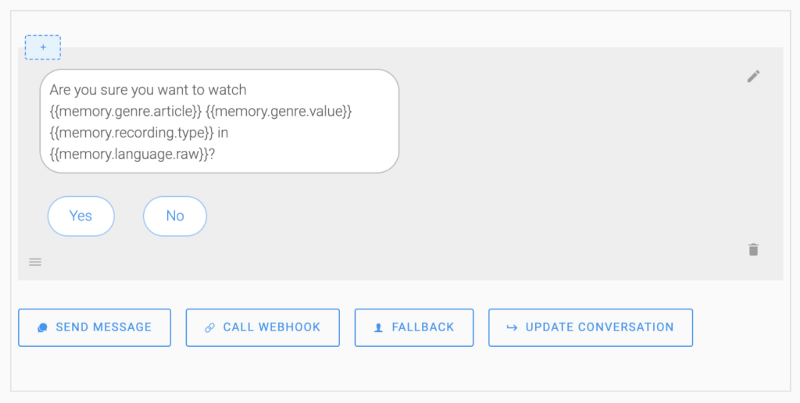
Pour la confirmation, nous utilisons la mémoire pour afficher un message dynamique afin de valider le choix de l'utilisateur en utilisant les intentions @yes et @no :
Une fois que vous avez configuré des questions pour les 4 groupes d'entités, allez à l'onglet Actions.
Actions
Une fois les exigences remplies, nous voulons appeler notre API pour effectuer la recherche si l'utilisateur a dit oui. Sinon, nous réinitialisons la mémoire et demandons à nouveau ce que l'utilisateur veut regarder.
Si _memory.no est présent — réinitialisez toute la mémoire et envoyez un message tel que « Recommençons, que voulez-vous regarder ? »
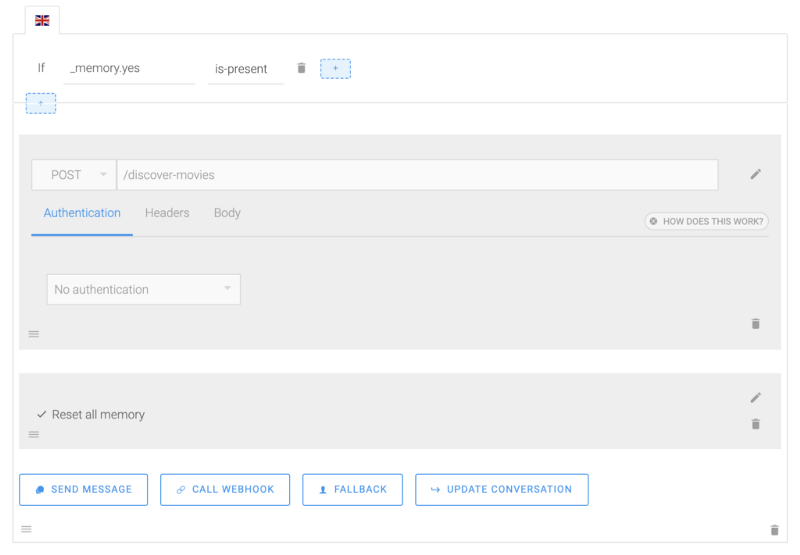
Si _memory.yes est présent, créez une action CALL WEHBOOK. Vous pouvez soit taper une URL complète (par exemple : https://mydomainname.com/discover-movies), soit une URL relative (/discover-movies). SAP Conversational AI utilisera le paramètre Bot base URL dans les paramètres de votre bot lorsque vous tapez une URL relative.
Ensuite, ajoutez une action UPDATE CONVERSATION > EDIT MEMORY > RESET ALL MEMORY pour vider la mémoire une fois l'appel effectué.
Si vous n'avez pas de serveur public, ou si vous souhaitez tester votre bot pendant le développement, ngrok est un outil très pratique. Il crée une URL publique pour vous et transfère les requêtes à votre ordinateur.
Une fois que vous l'avez installé, exécutez
ngrok http 5000
Et copiez l'URL Forwarding en HTTPS (https://XXX.ngrok.io) dans les paramètres de votre bot (champ « Bot webhook base URL »). Toutes les requêtes faites à cette URL seront transférées au port 5000 de votre ordinateur.
Tout ce dont votre bot a besoin maintenant, c'est de son API pour obtenir vos films !
Étape 3 : Créer l'API du bot de films
La partie NodeJS de ce bot est assez simple : elle se comportera comme un proxy HTTP entre SAP Conversational AI et The Movie Database.
Lorsque votre application reçoit une requête de SAP Conversational AI, elle envoie une requête de recherche à The Movie Database avec les critères de votre utilisateur et formate la réponse JSON au format de message de SAP Conversational AI.

Option 1 : la méthode automatique
Vous pouvez cloner l'ensemble du projet directement depuis notre dépôt Git : https://github.com/plieb/movie-bot-skills-training
Option 2 : la méthode manuelle
Étape 1 — structuration de votre projet
mkdir movie-bot && cd movie-botnpm initnpm install --save express body-parser axiostouch index.js config.jsmkdir discover-movies && cd discover-moviestouch index.js movieApi.jscd..
Étape 2 — obtenir un jeton d'API TMDb
Vous aurez besoin d'un jeton pour utiliser l'API The Movie Database, allez ici pour en générer un, et éditez votre fichier config.js :
module.exports = { MOVIEDB_TOKEN: process.env.MOVIEDB_TOKEN || 'PURYOURTOKENHERE', PORT: process.env.PORT || 5000, };
Étape 3 — remplir votre index.js avec une application Express
Créons une application Express pour gérer les requêtes de SAP Conversational AI. Pour mieux organiser notre projet, comme vu dans l'Étape 1, nous avons un dossier /discover-movies/ qui contient le cœur de notre code de bot (au lieu de mettre tous nos fichiers dans le même dossier), et nous l'appelons via loadMovieRoute.
const express = require('express');const bodyParser = require('body-parser');const config = require('./config');const loadMovieRoute = require('./discover-movies');const app = express();app.use(bodyParser.json());loadMovieRoute(app);app.post('/errors', function(req, res) { console.log(req.body); res.sendStatus(200);});const port = config.PORT;app.listen(port, function() { console.log(`App is listening on port ${port}`);});
Étape 4 — remplir discover-movies/index.js
Nous demandons à SAP Conversational AI d'envoyer une requête POST à /discover-movies lorsqu'un utilisateur a rempli ses critères de recherche.
Le principal objectif de notre contrôleur est de sélectionner et formater les préférences de la mémoire pour les envoyer à l'API de The Movie Database :
const config = require('../config'); const { discoverMovie } = require('./movieApi'); function loadMovieRoute(app) { app.post('/discover-movies', function(req, res) { console.log('[GET] /discover-movies'); const kind = req.body.conversation.memory['recording'].type; const genre = req.body.conversation.memory['genre'].id; const language = req.body.conversation.memory['language']; const nationality = req.body.conversation.memory['nationality']; const isoCode = language ? language.short.toLowerCase() : nationality.short.toLowerCase(); return discoverMovie(kind, genreId, isoCode) .then(function(carouselle) { res.json({ replies: carouselle, conversation: { } }); }) .catch(function(err) { console.error('movieApi::discoverMovie error: ', err); }); }); } module.exports = loadMovieRoute;
Étape 5 — remplir discover-movies/movieApi.js
Maintenant que nous avons extrait et formaté tous les filtres de la requête, nous devons envoyer la requête à The Movie Database et formater la réponse :
const axios = require('axios');const config = require('../config');function discoverMovie(kind, genreId, language) { return moviedbApiCall(kind, genreId, language).then(response => apiResultToCarousselle(response.data.results) );}function moviedbApiCall(kind, genreId, language) { return axios.get(`https://api.themoviedb.org/3/discover/${kind}`, { params: { api_key: config.MOVIEDB_TOKEN, sort_by: 'popularity.desc', include_adult: false, with_genres: genreId, with_original_language: language, }, });}function apiResultToCarousselle(results) { if (results.length === 0) { return [ { type: 'quickReplies', content: { title: 'Désolé, mais je n\'ai pas trouvé de résultats pour votre demande :(', buttons: [{ title: 'Recommencer', value: 'Recommencer' }], }, }, ]; } const cards = results.slice(0, 10).map(e => ({ title: e.title || e.name, subtitle: e.overview, imageUrl: `https://image.tmdb.org/t/p/w600_and_h900_bestv2${e.poster_path}`, buttons: [ { type: 'web_url', value: `https://www.themoviedb.org/movie/${e.id}`, title: 'Voir plus', }, ], })); return [ { type: 'text', content: "Voici ce que j'ai trouvé pour vous !", }, { type: 'carousel', content: cards }, ];}module.exports = { discoverMovie,};
Étape 6 — Démarrez le moteur !
C'est tout ! Vous êtes prêt à tester votre bot.
Démarrez votre application en exécutant : node index.js
Si tout se passe bien, vous devriez voir : App started on port 5000
Recommandations de films, météo, santé, trafic... Avec les API tierces, tout est possible ! Maintenant que vous êtes familiarisé avec le flux de travail, nous avons hâte de savoir ce que vous construisez ! Et n'oubliez pas, vous êtes très bienvenu pour nous contacter si vous avez besoin d'aide, via la section des commentaires ci-dessous ou via Slack.
*Publié à l'origine sur le blog SAP Conversational AI.