

Article original : How to build and deploy a multifunctional Twitter bot
Par Scott Spence
MISE À JOUR 20190507: Ce tutoriel n'est probablement plus pertinent car Twitter a déprécié certaines parties de l'API, ce qui le rendra de moins en moins pertinent. Je ne le mettrai pas à jour à l'avenir. ?
MISE À JOUR 20171105: Pour faciliter la navigation, j'ai compilé toute cette histoire dans un GitBook qui est une représentation presque exacte de cette histoire mais sera maintenu à jour avec les changements apportés au dépôt GitHub. Merci.
J'ai été occupé à construire des bots Twitter à nouveau !
Si vous regardez mon profil GitHub, vous verrez que j'ai plusieurs dépôts liés aux bots Twitter.
Mon dernier projet a commencé avec la décision de réutiliser l'un de mes dépôts de test comme documentation sur l'utilisation du package npm twit. Mais alors que j'ajoutais de nouveaux exemples, il s'est rapidement transformé en un autre bot Twitter.
Ce bot est assemblé à partir de trois exemples que nous allons passer en revue ici. Je vais également détailler comment j'ai utilisé la plateforme now de Zeit pour déployer le bot sur un serveur.
Un grand merci à Tim pour m'avoir aidé avec le déploiement now. Et à Hannah Davis pour le matériel de cours egghead.io. Il contient des exemples assez intéressants, que j'ai liés dans les sections pertinentes.
Commencer
Cet article est destiné à servir de référence pour moi et toute autre personne intéressée par les bots Twitter en JavaScript utilisant Node.js. Notez que tous les exemples ici utilisent le package npm twit.
Exemple de bot 1 : tweeter des médias avec l'image NASA du jour
Ganymede: The Largest Moon pic.twitter.com/6ir3tp1lRM
— Botland Mc Bot ? ?? (@DroidScott) 14 mai 2017
Exemple de bot 2 : utiliser RiTa pour créer un bot Markov qui utilisera votre archive Twitter pour publier des statuts basés sur votre historique de tweets.
I had the best turkey pie and mash made by my sister in law # nomnomnom the pants still not turned up?
— Botland Mc Bot ? ?? (@DroidScott) 14 mai 2017
Exemple de bot 3 : publier des liens (ou d'autres données) à partir d'une feuille de calcul.
https://t.co/9M9K7Gmtoa un lien depuis une feuille de calcul Google
— Botland Mc Bot ? ?? (@DroidScott) 15 mai 2017
Nous allons passer par la configuration d'un bot simple, que nous utiliserons pour exécuter chacun de ces exemples.
Je vais supposer que vous avez Node.js installé ainsi que npm et que vous êtes à l'aise avec le terminal.
Si vous n'êtes pas familier avec Node.js ou si vous n'avez pas configuré votre environnement pour l'utiliser, consultez le README.md sur mon dépôt Twitter bot bootstrap. Il donne des détails sur la configuration d'une application Twitter et d'un environnement de développement avec c9.
Une excellente ressource est le dépôt Awesome Twitter bots d'Aman Mittal qui contient des ressources et des exemples de bots.
Beaucoup de ces informations sont déjà disponibles, mais j'espère que cela contient toutes les informations dont quelqu'un aura besoin pour commencer avec son propre bot Twitter. Je fais cela pour mon propre apprentissage et j'espère que d'autres personnes en tireront également quelque chose.
Configurer le bot
Avant de toucher au terminal ou d'écrire du code, nous devons créer une application Twitter pour obtenir nos clés API (nous en aurons besoin de toutes) :
Clé du consommateur (Clé API)
Secret du consommateur (Secret API)
Jeton d'accès
Secret du jeton d'accès
Gardez les clés dans un endroit sûr afin de pouvoir les réutiliser lorsque vous en aurez besoin. Nous allons les utiliser dans un fichier [.env](https://www.npmjs.com/package/dotenv) que nous allons créer.
Nous utilisons [dotenv](https://www.npmjs.com/package/dotenv) afin que si à un moment donné dans le futur nous voulons ajouter notre bot à GitHub, les clés API de Twitter ne soient pas ajoutées à GitHub pour que tout le monde puisse les voir.
En partant de zéro, créez un nouveau dossier via le terminal et initialisez le package.json via npm ou yarn. Nous aurons besoin de twit et dotenv pour tous ces exemples.
J'utiliserai yarn pour tous ces exemples, vous pouvez utiliser npm si vous préférez.
Commandes du terminal :
mkdir tweebot-play
cd tweebot-play
yarn init -y
yarn add twit dotenv
touch .env .gitignore index.js
Si vous regardez le package.json qui a été créé, il devrait ressembler à ceci :
{
"name": "tweebot-play",
"version": "1.0.0",
"main": "index.js",
"author": "Scott Spence <spences10apps@gmail.com> (https://spences10.github.io/)",
"license": "MIT",
"dependencies": {
"dotenv": "^4.0.0",
"twit": "^2.2.5"
}
}
Ajoutez un script npm au package.json pour lancer le bot lorsque nous testons et recherchons une sortie :
"scripts": {
"start": "node index.js"
},
Il devrait maintenant ressembler à ceci :
{
"name": "tweebot-play",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"start": "node index.js"
},
"author": "Scott Spence <spences10apps@gmail.com> (https://spences10.github.io/)",
"license": "MIT",
"dependencies": {
"dotenv": "^4.0.0",
"twit": "^2.2.5"
}
}
Maintenant, nous pouvons ajouter le pointeur suivant vers le bot dans index.js, comme ceci :
require('./src/bot')
Ainsi, lorsque nous utilisons yarn start pour exécuter le bot, il appelle le fichier index.js qui exécute le fichier bot.js à partir du dossier src que nous allons créer.
Maintenant, ajoutons nos clés API au fichier .env, il devrait ressembler à ceci :
CONSUMER_KEY=AmMSbxxxxxxxxxxNh4BcdMhxg
CONSUMER_SECRET=eQUfMrHbtlxxxxxxxxxxkFNNj1H107xxxxxxxxxx6CZH0fjymV
ACCESS_TOKEN=7xxxxx492-uEcacdl7HJxxxxxxxxxxecKpi90bFhdsGG2N7iII
ACCESS_TOKEN_SECRET=77vGPTt20xxxxxxxxxxxZAU8wxxxxxxxxxx0PhOo43cGO
Dans le fichier .gitignore, nous devons ajouter .env et node_modules
# Répertoires de dépendances
node_modules
# Fichiers env
.env
Puis initialisez git :
git init
D'accord, maintenant nous pouvons commencer à configurer le bot, nous aurons besoin d'un dossier src, d'un fichier bot.js et d'un fichier config.js.
Terminal :
mkdir src
cd src
touch config.js bot.js
Ensuite, nous pouvons configurer le bot, ouvrez le fichier config.js et ajoutez ce qui suit :
require('dotenv').config()
module.exports = {
consumer_key: process.env.CONSUMER_KEY,
consumer_secret: process.env.CONSUMER_SECRET,
access_token: process.env.ACCESS_TOKEN,
access_token_secret: process.env.ACCESS_TOKEN_SECRET,
}
D'accord, avec la configuration du bot terminée, nous pouvons maintenant configurer le bot. Chacun des exemples détaillés ici aura les trois mêmes lignes de code :
const Twit = require('twit')
const config = require('./config')
const bot = new Twit(config)
Faites un test avec yarn start depuis le terminal, nous devrions obtenir ceci comme sortie :
yarn start
yarn start v0.23.4
$ node index.js
Terminé en 0.64s.
Notre bot est maintenant configuré et prêt à partir !
Publier des statuts
Pour publier un statut, utilisez .post('statuses/update'.... Cet exemple fait publier au bot un statut "hello world !".
bot.post('statuses/update', {
status: 'hello world!'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(`${data.text} tweeté !`)
}
})
Travailler avec les utilisateurs
Pour obtenir une liste des IDs des followers, utilisez .get('followers/ids'... et incluez le compte dont vous souhaitez les followers. Dans cet exemple, nous utilisons [@DroidScott](https://twitter.com/DroidScott), mais vous pouvez utiliser n'importe quel compte que vous aimez. Nous pouvons ensuite les enregistrer dans la console.
bot.get('followers/ids', {
screen_name: 'DroidScott',
count: 5
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data)
}
})
Vous pouvez utiliser le paramètre count pour spécifier le nombre de résultats que vous obtenez, jusqu'à 100 à la fois.
Ou pour obtenir une liste détaillée, vous pouvez utiliser .get('followers/list'...
Ici, nous imprimons une liste de user.screen_name jusqu'à 200 par appel.
bot.get('followers/list', {
screen_name: 'DroidScott',
count:200
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
data.users.forEach(user => {
console.log(user.screen_name)
})
}
})
Pour suivre un follower, nous pouvons utiliser .post('friendships/create'... ici le bot suit l'utilisateur MarcGuberti
Un bot ne doit suivre que les utilisateurs qui suivent le bot.
bot.post('friendships/create', {
screen_name: 'MarcGuberti'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data)
}
})
Comme nous l'avons fait avec les followers, vous pouvez obtenir une liste des comptes que votre bot suit.
bot.get('friends/ids', {
screen_name: 'DroidScott'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data)
}
})
Et aussi une liste détaillée.
bot.get('friends/list', {
screen_name: 'DroidScott'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data)
}
})
Vous pouvez obtenir les statuts des relations. Cela est utile pour suivre les nouveaux followers et nous donne la relation d'un utilisateur spécifique. Vous pouvez parcourir votre liste de followers et suivre les utilisateurs qui n'ont pas la connexion following.
Regardons la relation entre notre bot et [@ScottDevTweets](https://twitter.com/ScottDevTweets)
bot.get('friendships/lookup', {
screen_name: 'ScottDevTweets'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data)
}
})
Si l'utilisateur suit le bot, alors la relation sera :
[ { name: 'Scott Spence ???
',
screen_name: 'ScottDevTweets',
id: 4897735439,
id_str: '4897735439',
connections: [ 'followed_by' ] } ]
Si l'utilisateur et le bot se suivent mutuellement, la relation sera :
[ { name: 'Scott Spence ???
',
screen_name: 'ScottDevTweets',
id: 4897735439,
id_str: '4897735439',
connections: [ 'following', 'followed_by' ] } ]
Et s'il n'y a pas de relation, alors :
[ { name: 'Scott Spence ???
',
screen_name: 'ScottDevTweets',
id: 4897735439,
id_str: '4897735439',
connections: [ 'none' ] } ]
Envoyer un message direct à un utilisateur avec bot.post('direct_messages/new'...
Un bot ne doit envoyer un DM qu'à un utilisateur qui suit le compte du bot
bot.post('direct_messages/new', {
screen_name: 'ScottDevTweets',
text: 'Bonjour du bot !'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data)
}
})
Interagir avec les tweets
Pour obtenir une liste de tweets dans la timeline du bot, utilisez .get(statuses/home_timeline'...
bot.get('statuses/home_timeline', {
count: 1
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data)
}
})
Pour être plus précis, vous pouvez extraire des informations spécifiques sur chaque tweet.
bot.get('statuses/home_timeline', {
count: 5
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
data.forEach(t => {
console.log(t.text)
console.log(t.user.screen_name)
console.log(t.id_str)
console.log('\n')
})
}
})
Pour retweeter, utilisez .post('statuses/retweet/:id'... et passez un ID de tweet à retweeter.
bot.post('statuses/retweet/:id', {
id: '860828247944253440'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(`${data.text} retweet réussi !`)
}
})
Pour annuler un retweet, utilisez simplement .post('statuses/unretweet/:id'...
bot.post('statuses/unretweet/:id', {
id: '860828247944253440'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(`${data.text} annulation de retweet réussie !`)
}
})
Pour aimer un tweet, utilisez .post('favorites/create'...
bot.post('favorites/create', {
id: '860897020726435840'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(`${data.text} tweet aimé !`)
}
})
Pour ne plus aimer un tweet, utilisez .post('favorites/destroy'...
bot.post('favorites/destroy', {
id: '860897020726435840'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(`${data.text} tweet non aimé !`)
}
})
Pour répondre à un tweet, c'est presque la même chose que de publier un tweet, mais vous devez inclure le paramètre in_reply_to_status_id. De plus, vous devrez mettre le nom d'écran de la personne à qui vous répondez.
bot.post('statuses/update', {
status: '@ScottDevTweets Je te réponds oui !',
in_reply_to_status_id: '860900406381211649'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(`${data.text} tweeté !`)
}
})
Enfin, si vous voulez supprimer un tweet, utilisez .post('statuses/destroy/:id'... en passant l'ID du tweet que vous voulez supprimer.
bot.post('statuses/destroy/:id', {
id: '860900437993676801'
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(`${data.text} tweet supprimé !`)
}
})
Utiliser la recherche Twitter
Pour utiliser la recherche, utilisez .get('search/tweets',.... Il existe plusieurs paramètres de recherche.
La structure est q: '' où q est pour la requête. Vous utiliseriez q: 'mango' pour rechercher mango. Nous pouvons également limiter les résultats retournés avec count: n, alors limitons le compte à 5 dans l'exemple.
bot.get('search/tweets', {
q: 'mango',
count: 5
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log(data.statuses)
}
})
Comme nous l'avons fait avec la timeline, nous allons extraire des éléments spécifiques des data.statuses retournés, comme ceci :
bot.get('search/tweets', {
q: 'mango',
count: 5
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
data.statuses.forEach(s => {
console.log(s.text)
console.log(s.user.screen_name)
console.log('\n')
})
}
})
L'API de recherche retourne des résultats par pertinence et non par exhaustivité. Si vous souhaitez rechercher une phrase exacte, vous devrez envelopper la requête dans des guillemets "purple pancakes". Si vous souhaitez rechercher l'un des deux mots, utilisez OR comme 'tabs OR spaces'. Et si vous souhaitez rechercher les deux, utilisez AND comme 'tabs AND spaces'.
Si vous souhaitez rechercher un tweet sans un autre mot, utilisez - comme donald -trump. Vous pouvez l'utiliser plusieurs fois également, comme donald -trump -duck
Vous pouvez rechercher des tweets avec des émoticônes, comme q: 'sad :(' essayez-le !
Bien sûr, vous pouvez rechercher des hashtags q: '#towie'. Recherchez des tweets à un utilisateur q: 'to:@stephenfry' ou d'un utilisateur q: 'from:@stephenfry'
Vous pouvez filtrer les tweets indécents avec le paramètre filter:safe. Vous pouvez également l'utiliser pour filtrer les tweets media qui retourneront des tweets contenant des vidéos. Vous pouvez spécifier images pour voir des tweets avec des images et vous pouvez spécifier links pour des tweets avec des liens.
Si vous voulez des tweets d'un certain site web, vous pouvez spécifier avec le paramètre url comme url:asda
bot.get('search/tweets', {
q: 'from:@dan_abramov url:facebook filter:images since:2017-01-01',
count: 5
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
data.statuses.forEach(s => {
console.log(s.text)
console.log(s.user.screen_name)
console.log('\n')
})
}
})
Les derniers maintenant, il y a le paramètre result_type qui retournera des résultats recent, popular, ou mixed.
Le paramètre geocode prend le format latitude longitude puis rayon en miles '51.5033640,-0.1276250,1mi' exemple :
bot.get('search/tweets', {
q: 'bacon',
geocode: '51.5033640,-0.1276250,1mi',
count: 5
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
data.statuses.forEach(s => {
console.log(s.text)
console.log(s.user.screen_name)
console.log('\n')
})
}
})
Utiliser l'API de streaming Twitter
Il y a deux façons d'utiliser l'API de streaming. Tout d'abord, il y a .stream('statuses/sample').
const stream = bot.stream('statuses/sample');
stream.on('tweet', t => {
console.log(`${t.text}\n`)
})
Cela vous donnera un échantillon aléatoire de tweets.
Pour des informations plus spécifiques, utilisez .stream('statuses/filter')... puis passez quelques paramètres, et utilisez track: pour spécifier une chaîne de recherche.
var stream = bot.stream('statuses/filter', {
track: 'bot'
})
stream.on('tweet', function (t) {
console.log(t.text + '\n')
})
Vous pouvez également utiliser plusieurs mots dans le paramètre track, cela vous donnera des résultats avec soit twitter soit bot.
const stream = bot.stream('statuses/filter', {
track: 'twitter, bot'
});
stream.on('tweet', t => {
console.log(`${t.text}\n`)
})
Si vous voulez les deux mots, alors retirez la virgule , — vous pouvez penser aux espaces comme AND et aux virgules comme OR.
Vous pouvez également utiliser le paramètre follow: qui vous permet de saisir les IDs d'utilisateurs spécifiques.
const stream = bot.stream('statuses/filter', {
follow: '4897735439'
});
stream.on('tweet', t => {
console.log(`${t.text}\n`)
})
Tweeter des fichiers multimédias
Cette vidéo egghead.io est une excellente ressource pour cette section, merci à Hannah Davis pour le contenu génial !
Cela sera une demande pour obtenir l'image NASA du jour et la tweeter.
Nous aurons besoin de références à request et fs pour travailler avec le système de fichiers.
const Twit = require('twit')
const request = require('request')
const fs = require('fs')
const config = require('./config')
const bot = new Twit(config)
La première étape consiste à obtenir la photo de l'API NASA. Nous devrons créer un objet de paramètres à l'intérieur de notre fonction getPhoto qui sera passé au client HTTP node request pour l'image.
function getPhoto() {
const parameters = {
url: 'https://api.nasa.gov/planetary/apod',
qs: {
api_key: process.env.NASA_KEY
},
encoding: 'binary'
};
}
Les parameters spécifient une api_key, donc pour cela, vous pouvez demander une clé API ou vous pouvez utiliser la DEMO_KEY. Cette clé API peut être utilisée pour explorer initialement les API avant de s'inscrire, mais elle a des limites de taux beaucoup plus basses, donc vous êtes encouragé à vous inscrire pour votre propre clé API.
Dans l'exemple, vous pouvez voir que j'ai configuré ma clé avec le reste de mes variables .env.
CONSUMER_KEY=AmMSbxxxxxxxxxxNh4BcdMhxg
CONSUMER_SECRET=eQUfMrHbtlxxxxxxxxxxkFNNj1H107xxxxxxxxxx6CZH0fjymV
ACCESS_TOKEN=7xxxxx492-uEcacdl7HJxxxxxxxxxxecKpi90bFhdsGG2N7iII
ACCESS_TOKEN_SECRET=77vGPTt20xxxxxxxxxxxZAU8wxxxxxxxxxx0PhOo43cGO
NASA_KEY=DEMO_KEY
Maintenant, pour utiliser la request pour obtenir l'image :
function getPhoto() {
const parameters = {
url: 'https://api.nasa.gov/planetary/apod',
qs: {
api_key: process.env.NASA_KEY
},
encoding: 'binary'
};
request.get(parameters, (err, respone, body) => {
body = JSON.parse(body)
saveFile(body, 'nasa.jpg')
})
}
Dans la request, nous passons nos paramètres et analysons le corps en JSON afin de pouvoir l'enregistrer avec la fonction saveFile.
function saveFile(body, fileName) {
const file = fs.createWriteStream(fileName);
request(body).pipe(file).on('close', err => {
if (err) {
console.log(err)
} else {
console.log('Media saved!')
console.log(body)
}
})
}
request(body).pipe(file).on('close'... est ce qui enregistre le fichier à partir de la variable file. Il a le nom nasa.jpg qui lui est passé à partir de la fonction getPhoto.
L'appel de getPhoto() devrait maintenant enregistrer l'image NASA du jour à la racine de votre projet.
Maintenant, nous pouvons la partager sur Twitter. Il y a deux parties à cela, la première est d'enregistrer le fichier.
function saveFile(body, fileName) {
const file = fs.createWriteStream(fileName);
request(body).pipe(file).on('close', err => {
if (err) {
console.log(err)
} else {
console.log('Media saved!')
const descriptionText = body.title;
uploadMedia(descriptionText, fileName)
}
})
}
Ensuite, uploadMedia pour télécharger le média sur Twitter avant de pouvoir le publier. Cela m'a laissé perplexe pendant un moment car j'ai mes fichiers dans un dossier src. Si vous avez vos fichiers de bot imbriqués dans des dossiers, alors vous devrez faire de même si vous avez des erreurs file does not exist.
Ajoutez un require à path puis utilisez join avec le chemin de fichier relatif pertinent.
const path = require('path')
//...
const filePath = path.join(__dirname, '../' + fileName)
Voici la fonction complète :
function uploadMedia(descriptionText, fileName) {
console.log(`uploadMedia: file PATH ${fileName}`)
bot.postMediaChunked({
file_path: fileName
}, (err, data, respone) => {
if (err) {
console.log(err)
} else {
console.log(data)
const params = {
status: descriptionText,
media_ids: data.media_id_string
}
postStatus(params)
}
})
}
Ensuite, avec les params que nous avons créés dans uploadMedia, nous pouvons publier avec un .post('statuses/update'... simple.
function postStatus(params) {
bot.post('statuses/update', params, (err, data, respone) => {
if (err) {
console.log(err)
} else {
console.log('Status posted!')
}
})
}
Appelez la fonction getPhoto() pour publier sur Twitter... super simple, non ? Je sais que ce n'était pas le cas. Voici le module complet :
const Twit = require('twit')
const request = require('request')
const fs = require('fs')
const config = require('./config')
const path = require('path')
const bot = new Twit(config)
function getPhoto() {
const parameters = {
url: 'https://api.nasa.gov/planetary/apod',
qs: {
api_key: process.env.NASA_KEY
},
encoding: 'binary'
}
request.get(parameters, (err, respone, body) => {
body = JSON.parse(body)
saveFile(body, 'nasa.jpg')
})
}
function saveFile(body, fileName) {
const file = fs.createWriteStream(fileName)
request(body).pipe(file).on('close', err => {
if (err) {
console.log(err)
} else {
console.log('Media saved!')
const descriptionText = body.title
uploadMedia(descriptionText, fileName)
}
})
}
function uploadMedia(descriptionText, fileName) {
const filePath = path.join(__dirname, `../${fileName}`)
console.log(`file PATH ${filePath}`)
bot.postMediaChunked({
file_path: filePath
}, (err, data, respone) => {
if (err) {
console.log(err)
} else {
console.log(data)
const params = {
status: descriptionText,
media_ids: data.media_id_string
}
postStatus(params)
}
})
}
function postStatus(params) {
bot.post('statuses/update', params, (err, data, respone) => {
if (err) {
console.log(err)
} else {
console.log('Status posted!')
}
})
}
getPhoto()
Créer un bot Markov
C'est assez génial, encore une fois de la série egghead.io, elle utilise le kit d'outils de langage naturel [rita](https://www.npmjs.com/package/rita). Il utilise également csv-parse car nous allons lire notre archive Twitter pour faire en sorte que le bot semble que c'est nous qui tweetons.
Tout d'abord, pour configurer l'archive Twitter, vous devrez demander vos données depuis la page des paramètres Twitter. Vous recevrez un email avec un lien pour télécharger votre archive, puis une fois que vous avez téléchargé l'archive, extrayez le fichier tweets.csv, nous allons ensuite le mettre dans son propre dossier, donc depuis la racine de votre projet :
cd src
mkdir twitter-archive
Nous allons déplacer notre tweets.csv là pour qu'il soit accessible par le bot que nous allons passer en revue maintenant.
Utilisez fs pour configurer un flux de lecture...
const filePath = path.join(__dirname, './twitter-archive/tweets.csv')
const tweetData =
fs.createReadStream(filePath)
.pipe(csvparse({
delimiter: ','
}))
.on('data', row => {
console.log(row[5])
})
Lorsque vous exécutez cela depuis la console, vous devriez obtenir la sortie de votre archive Twitter.
Maintenant, nettoyez les choses comme @ et RT pour aider au traitement du langage naturel. Nous allons configurer deux fonctions cleanText et hasNoStopWords
cleanText va tokeniser le texte en le délimitant sur l'espace ' ', filtrer les mots vides, puis .join(' ') ensemble avec un espace, et .trim() tout espace blanc qui peut être au début du texte.
function cleanText(text) {
return rita.RiTa.tokenize(text, ' ')
.filter(hasNoStopWords)
.join(' ')
.trim()
}
Le texte tokenisé peut ensuite être alimenté dans la fonction hasNoStopWords pour être assaini pour une utilisation dans tweetData
function hasNoStopWords(token) {
const stopwords = ['@', 'http', 'RT'];
return stopwords.every(sw => !token.includes(sw))
}
Maintenant que nous avons les données nettoyées, nous pouvons les tweeter. Remplacez console.log(row[5]) par inputText = inputText + ' ' + cleanText(row[5]). Ensuite, nous pouvons utiliser rita.RiMarkov(3) où le 3 est le nombre de mots à prendre en considération. Ensuite, utilisez markov.generateSentences(1) où 1 est le nombre de phrases générées. Nous utiliserons également .toString() et .substring(0, 140) pour tronquer le résultat à 140 caractères.
const tweetData =
fs.createReadStream(filePath)
.pipe(csvparse({
delimiter: ','
}))
.on('data', function (row) {
inputText = `${inputText} ${cleanText(row[5])}`
})
.on('end', function(){
const markov = new rita.RiMarkov(3)
markov.loadText(inputText)
const sentence = markov.generateSentences(1)
.toString()
.substring(0, 140)
}
Maintenant, nous pouvons tweeter cela avec le bot en utilisant .post('statuses/update'... en passant la variable sentence comme status et en enregistrant un message dans la console lorsqu'il y a un tweet.
const tweetData =
fs.createReadStream(filePath)
.pipe(csvparse({
delimiter: ','
}))
.on('data', row => {
inputText = `${inputText} ${cleanText(row[5])}`
})
.on('end', () => {
const markov = new rita.RiMarkov(3)
markov.loadText(inputText)
const sentence = markov.generateSentences(1)
.toString()
.substring(0, 140)
bot.post('statuses/update', {
status: sentence
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log('Markov status tweeted!', sentence)
}
})
})
}
Si vous voulez que vos phrases soient plus proches du texte d'entrée, vous pouvez augmenter le nombre de mots à considérer dans rita.RiMarkov(6) et si vous voulez le rendre absurde, diminuez le nombre.
Voici le module complet :
const Twit = require('twit')
const fs = require('fs')
const csvparse = require('csv-parse')
const rita = require('rita')
const config = require('./config')
const path = require('path')
let inputText = ''
const bot = new Twit(config)
const filePath = path.join(__dirname, '../twitter-archive/tweets.csv')
const tweetData =
fs.createReadStream(filePath)
.pipe(csvparse({
delimiter: ','
}))
.on('data', row => {
inputText = `${inputText} ${cleanText(row[5])}`
})
.on('end', () => {
const markov = new rita.RiMarkov(10)
markov.loadText(inputText)
const sentence = markov.generateSentences(1)
.toString()
.substring(0, 140)
bot.post('statuses/update', {
status: sentence
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log('Markov status tweeted!', sentence)
}
})
})
}
function hasNoStopWords(token) {
const stopwords = ['@', 'http', 'RT']
return stopwords.every(sw => !token.includes(sw))
}
function cleanText(text) {
return rita.RiTa.tokenize(text, ' ')
.filter(hasNoStopWords)
.join(' ')
.trim()
}
Récupérer et tweeter des données depuis Google Sheets
Si vous souhaitez tweeter une liste de liens, vous pouvez utiliser [tabletop](https://www.npmjs.com/package/tabletop) pour parcourir la liste. Dans cet exemple, encore une fois de egghead.io, nous allons parcourir une liste de liens.
Donc, configurez le bot et nécessitez tabletop :
const Twit = require('twit')
const config = require('./config')
const Tabletop = require('tabletop')
const bot = new Twit(config)
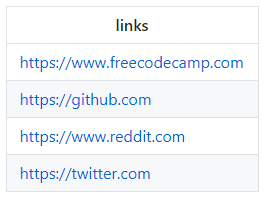
Sur votre [feuille de calcul Google](https://github.com/spences10/twitter-bot-playground/blob/master/sheets.google.com), vous devrez avoir un en-tête défini puis ajouter vos liens, nous utiliserons ce qui suit pour un exemple :
Maintenant, depuis Google Sheets, nous pouvons sélectionner 'Fichier' > 'Publier sur le web' et copier le lien qui est généré pour l'utiliser dans tabletop.
Maintenant, initialisez Tabletop avec trois paramètres, key: qui est l'URL de la feuille de calcul, une fonction callback: pour obtenir les données et simpleSheet: qui est true si vous n'avez qu'une seule feuille, comme dans notre exemple ici :
const spreadsheetUrl = 'https://docs.google.com/spreadsheets/d/1842GC9JS9qDWHc-9leZoEn9Q_-jcPUcuDvIqd_MMPZQ/pubhtml'
Tabletop.init({
key: spreadsheetUrl,
callback(data, tabletop) {
console.log(data)
},
simpleSheet: true
})
L'exécution du bot maintenant devrait donner une sortie comme ceci :
$ node index.js
[ { 'links': 'https://www.freecodecamp.com' },
{ 'links': 'https://github.com' },
{ 'links': 'https://www.reddit.com' },
{ 'links': 'https://twitter.com' } ]
Nous pouvons maintenant les tweeter en utilisant .post('statuses/update',... avec un forEach sur les data qui sont retournés dans le callback :
Tabletop.init({
key: spreadsheetUrl,
callback(data, tabletop) {
data.forEach(d => {
const status = `${d.links} un lien depuis une feuille de calcul Google`;
bot.post('statuses/update', {
status
}, (err, response, data) => {
if (err) {
console.log(err)
} else {
console.log('Post success!')
}
})
})
},
simpleSheet: true
})
Notez que ${d.links} est le nom de l'en-tête que nous utilisons dans la feuille de calcul Google, j'ai essayé d'utiliser le squelette et le camel case et les deux ont retourné des erreurs, donc je suis allé avec un en-tête de nom unique sur la feuille de calcul.
Le code complet ici :
const Twit = require('twit')
const config = require('./config')
const Tabletop = require('tabletop')
const bot = new Twit(config)
const spreadsheetUrl = 'https://docs.google.com/spreadsheets/d/1842GC9JS9qDWHc-9leZoEn9Q_-jcPUcuDvIqd_MMPZQ/pubhtml'
Tabletop.init({
key: spreadsheetUrl,
callback(data, tabletop) {
data.forEach(d => {
const status = `${d.links} un lien depuis une feuille de calcul Google`
console.log(status)
bot.post('statuses/update', {
status
}, (err, response, data) => {
if (err) {
console.log(err)
} else {
console.log('Post success!')
}
})
})
},
simpleSheet: true
})
Mettre tout ensemble
D'accord, ces exemples étaient bons et tout, mais nous n'avons pas vraiment obtenu un bot de tout cela, n'est-ce pas ? Je veux dire, vous l'exécutez depuis le terminal et c'est fait, mais nous voulons pouvoir lancer le bot et le laisser faire son travail.
Une façon que j'ai trouvée pour faire cela est d'utiliser setInterval qui lancera des événements depuis le module principal bot.js.
Prenez l'exemple que nous avons fait pour tweeter une image et ajoutez-le à son propre module, donc depuis le répertoire racine de notre projet :
cd src
touch picture-bot.js
Prenez le code d'exemple de cela et collez-le dans le nouveau module. Ensuite, nous allons apporter les modifications suivantes à getPhoto :
const getPhoto = () => {
const parameters = {
url: 'https://api.nasa.gov/planetary/apod',
qs: {
api_key: process.env.NASA_KEY
},
encoding: 'binary'
}
request.get(parameters, (err, respone, body) => {
body = JSON.parse(body)
saveFile(body, 'nasa.jpg')
})
}
Ensuite, en bas du module, ajoutez :
module.exports = getPhoto
Ainsi, nous pouvons maintenant appeler la fonction getPhoto depuis le module picture-bot.js dans notre module bot.js. Notre module bot.js devrait ressembler à ceci :
const picture = require('./picture-bot')
picture()
C'est tout, deux lignes de code, essayez de l'exécuter depuis le terminal maintenant :
yarn start
Nous devrions obtenir une sortie comme ceci :
yarn start v0.23.4
$ node index.js
Media saved!
file PATH C:\Users\path\to\project\tweebot-play\nasa.jpg
{ media_id: 863020197799764000,
media_id_string: '863020197799763968',
size: 371664,
expires_after_secs: 86400,
image: { image_type: 'image/jpeg', w: 954, h: 944 } }
Status posted!
Done in 9.89s.
L'image du jour est configurée, mais elle a été exécutée une fois et terminée. Nous devons la mettre sur un intervalle avec setInterval. Il prend deux options, la fonction qu'il va appeler et la valeur de délai d'attente.
L'image est mise à jour toutes les 24 heures, donc ce sera le nombre de millisecondes en 24 heures [8.64e+7].
La formule est 1000 60 = 1 minute, donc 1000 60 60 24, alors pour l'instant, ajoutons cela directement dans la fonction setInterval :
const picture = require('./picture-bot')
picture()
setInterval(picture, 1000 * 60 * 60 * 24)
Cool, c'est un bot qui publiera l'image NASA du jour toutes les 24 heures !
Continuons, maintenant ajoutons un peu d'aléatoire avec le bot Markov. Comme nous l'avons fait pour l'exemple de l'image du jour, créons un nouveau module pour le bot Markov et ajoutons tout le code dedans à partir de l'exemple précédent, donc depuis le terminal :
cd src
touch markov-bot.js
Ensuite, copiez et collez l'exemple du bot Markov dans le nouveau module, et apportez les modifications suivantes :
const tweetData = () => {
fs.createReadStream(filePath)
.pipe(csvparse({
delimiter: ','
}))
.on('data', row => {
inputText = `${inputText} ${cleanText(row[5])}`
})
.on('end', () => {
const markov = new rita.RiMarkov(10)
markov.loadText(inputText)
.toString()
.substring(0, 140)
const sentence = markov.generateSentences(1)
bot.post('statuses/update', {
status: sentence
}, (err, data, response) => {
if (err) {
console.log(err)
} else {
console.log('Markov status tweeted!', sentence)
}
})
})
}
Ensuite, en bas du module, ajoutez :
module.exports = tweetData
Similaire à l'exemple du bot d'image, nous allons ajouter l'export tweetData de markov-bot.js à notre module bot.js, qui devrait maintenant ressembler à ceci :
const picture = require('./picture-bot')
const markov = require('./markov-bot')
picture()
setInterval(picture, 1000 * 60 * 60 * 24)
markov()
Faisons en sorte que le bot Markov tweete à des intervalles aléatoires entre 5 minutes et 3 heures
const picture = require('./picture-bot')
const markov = require('./markov-bot')
picture()
setInterval(picture, 1000 * 60 * 60 * 24)
const markovInterval = (Math.floor(Math.random() * 180) + 1) * 1000
markov()
setInterval(markov, markovInterval)
D'accord ! Bot d'image et bot Markov, tous les deux terminés.
Faire de même avec le bot de lien ? D'accord, comme avant, vous avez compris maintenant, non ?
Créez un nouveau fichier dans le dossier src pour le bot de lien :
touch link-bot.js
Copiez et collez le code de l'exemple du bot de lien dans le nouveau module, comme ceci :
const link = () => {
Tabletop.init({
key: spreadsheetUrl,
callback(data, tabletop) {
data.forEach(d => {
const status = `${d.links} un lien depuis une feuille de calcul Google`
console.log(status)
bot.post('statuses/update', {
status
}, (err, response, data) => {
if (err) {
console.log(err)
} else {
console.log('Post success!')
}
})
})
},
simpleSheet: true
})
}
module.exports = link
Ensuite, nous pouvons l'appeler depuis le bot, donc il devrait ressembler à ceci :
const picture = require('./picture-bot')
const markov = require('./markov-bot')
const link = require('./link-bot')
picture()
setInterval(picture, 1000 * 60 * 60 * 24)
const markovInterval = (Math.floor(Math.random() * 180) + 1) * 1000
markov()
setInterval(markov, markovInterval)
link()
setInterval(link, 1000 * 60 * 60 * 24)
Nous pouvons maintenant laisser le bot fonctionner pour faire son travail !!
Déployer sur now
Nous avons un bot qui fait quelques choses, mais il est sur notre environnement de développement et ne peut pas y rester éternellement. (Il pourrait, mais ce serait assez impratique). Déployons notre bot sur un serveur quelque part pour qu'il fasse son travail.
Nous allons utiliser la plateforme now de Zeit, qui permet des déploiements simples depuis la CLI. Si vous ne la connaissez pas, jetez un rapide coup d'œil à la documentation. Dans ces exemples, nous allons utiliser le now-cli.
Il y a quelques choses que nous devons faire pour préparer notre bot à être déployé sur now. Listons-les rapidement puis entrons dans les détails.
- S'inscrire et installer
now-cli - Ajouter les paramètres
now+ fichier.npmignore - Ajouter les variables
.envcomme secrets - Ajouter le script npm
deploy - Reconfigurer
picture-bot.js
Prêt ? C'est parti !
S'inscrire et installer now-cli
Tout d'abord, inscrivez-vous sur Zeit en créant un compte et en l'authentifiant, puis installez la CLI.
Installez now globalement sur votre machine pour pouvoir l'utiliser partout.
npm install -g now
Une fois terminé, connectez-vous avec :
now --login
La première fois que vous exécutez now, il vous demandera votre adresse e-mail afin de vous identifier. Allez dans le compte e-mail que vous avez fourni lors de l'inscription, cliquez sur l'e-mail qui vous a été envoyé par now, et vous serez connecté automatiquement.
Si vous devez changer de compte ou vous réauthentifier, exécutez la même commande à nouveau.
Vous pouvez toujours consulter la documentation now-cli pour plus d'informations ainsi que le guide [votre premier déploiement](https://zeit.co/docs/getting-started/your-first-deployments#deploying-node).
Ajouter les paramètres now
Avec l'inscription et l'installation terminées, nous pouvons configurer le bot pour le déploiement sur now. Tout d'abord, ajoutons les paramètres now à notre fichier package.json. Je l'ai placé entre mes scripts npm et le nom de l'auteur dans mon package.json :
"scripts": {
"start": "node index.js"
},
"now": {
"alias": "my-awesome-alias",
"files": [
"src",
"index.js"
]
},
"author": "Scott Spence",
Cela a été une source de grande confusion pour moi, donc j'espère pouvoir vous épargner la douleur que j'ai endurée en essayant de configurer cela. Toute la documentation pertinente est là, il suffit de tout rassembler.
Si vous trouvez quelque chose ici qui n'a pas de sens ou semble incorrect, veuillez signaler un problème ou créer une demande de tirage.
Les paramètres now alias servent à donner à votre déploiement un nom abrégé au lieu de l'URL générée automatiquement que now crée. La section files couvre ce que nous voulons inclure dans le déploiement sur now, ce que je vais couvrir bientôt. En gros, ce qui est inclus dans le tableau files est tout ce qui est envoyé aux serveurs now.
Maintenant, nous devons ajouter un fichier .npmignore à la racine du projet et y ajouter la ligne suivante :
!tweets.csv
Le fichier tweets.csv doit être envoyé au serveur now pour être utilisé par le bot, mais nous l'avons précédemment inclus dans notre .gitignore. C'est ce que now utilise pour construire votre projet lorsqu'il est chargé sur le serveur. Cela signifie que le fichier ne sera pas chargé sauf si nous modifions le .npmignore pour ne pas ignorer le tweets.csv.
Ajouter les variables .env comme secrets
Nos super clés secrètes Twitter devront être stockées comme secrets dans now. C'est une fonctionnalité assez géniale où vous pouvez définir n'importe quoi comme un secret et y faire référence comme un alias.
La syntaxe est now secrets add my-secret "my value" donc pour nos clés .env, ajoutez-les toutes, en leur donnant un nom descriptif (mais court !).
Vous n'aurez pas besoin d'entourer votre "my value" de guillemets, mais la documentation dit "en cas de doute, entourez votre valeur de guillemets".
Dans le terminal, now secrets ls devrait lister vos secrets que vous venez de créer :
$ now secrets ls
> 5 secrets found under spences10 [1s]
id name created
sec_xxxxxxxxxxZpLDxxxxxxxxxx ds-twit-key 23h ago
sec_xxxxxxxxxxTE5Kxxxxxxxxxx ds-twit-secret 23h ago
sec_xxxxxxxxxxNorlxxxxxxxxxx ds-twit-access 23h ago
sec_xxxxxxxxxxMe1Cxxxxxxxxxx ds-twit-access-secret 23h ago
sec_xxxxxxxxxxMJ2jxxxxxxxxxx nasa-key 23h ago
Ajouter le script npm deploy
Avec nos secrets définis, nous pouvons créer un script de déploiement pour déployer sur now. Dans notre package.json, ajoutez un script supplémentaire :
"main": "index.js",
"scripts": {
"start": "node index.js",
"deploy": "now -e CONSUMER_KEY=@ds-twit-key -e CONSUMER_SECRET=@ds-twit-secret -e ACCESS_TOKEN=@ds-twit-access -e ACCESS_TOKEN_SECRET=@ds-twit-access-secret -e NASA_KEY=@nasa-key"
},
"now": {
Nous avons ajouté deploy, qui exécutera la commande now et lui passera toutes nos variables d'environnement -e et la valeur secret associée. Si nous le décomposons en lignes séparées, ce sera un peu plus clair :
now
-e CONSUMER_KEY=@ds-twit-key
-e CONSUMER_SECRET=@ds-twit-secret
-e ACCESS_TOKEN=@ds-twit-access
-e ACCESS_TOKEN_SECRET=@ds-twit-access-secret
-e NASA_KEY=@nasa-key
Reconfigurer picture-bot.js
Parce que les déploiements now sont immutables, cela signifie qu'il n'y a pas d'accès en écriture au disque où nous voulons enregistrer notre photo NASA du jour. Pour contourner cela, nous devons utiliser l'emplacement de fichier /tmp.
Merci à Tim de Zeit pour m'avoir aidé avec cela !
Dans le module picture-bot.js, ajoutez les deux lignes suivantes en haut du module :
const os = require('os')
const tmpDir = os.tmpdir()
Ces deux lignes nous donnent le répertoire temp du système d'exploitation. Si vous êtes comme moi et que vous utilisez Windows, cela fonctionnera aussi bien que si vous êtes sur un autre système comme un système basé sur linux (ce que now est). Dans notre fonction saveFile, nous allons utiliser tmpDir pour enregistrer notre fichier.
Nous avons retiré le nasa.jpg de la fonction getPhoto puisque nous pouvons définir ces informations dans la fonction saveFile. La photo NASA du jour n'est pas toujours un jpeg, certains éléments publiés là-bas sont des vidéos. Nous pouvons définir le type avec une fonction ternaire à partir du body qui est passé, cela enverra un tweet avec un lien vers la vidéo :
function saveFile(body) {
const fileName = body.media_type === 'image/jpeg' ? 'nasa.jpg' : 'nasa.mp4';
const filePath = path.join(tmpDir + `/${fileName}`)
console.log(`saveFile: file PATH ${filePath}`)
if (fileName === 'nasa.mp4') {
// tweeter le lien
const params = {
status: 'NASA video link: ' + body.url
}
postStatus(params)
return
}
const file = fs.createWriteStream(filePath)
request(body).pipe(file).on('close', err => {
if (err) {
console.log(err)
} else {
console.log('Media saved!')
const descriptionText = body.title
uploadMedia(descriptionText, filePath)
}
})
}
Le code complet ici :
const Twit = require('twit')
const request = require('request')
const fs = require('fs')
const config = require('./config')
const path = require('path')
const bot = new Twit(config)
const os = require('os')
const tmpDir = os.tmpdir()
const getPhoto = () => {
const parameters = {
url: 'https://api.nasa.gov/planetary/apod',
qs: {
api_key: process.env.NASA_KEY
},
encoding: 'binary'
}
request.get(parameters, (err, respone, body) => {
body = JSON.parse(body)
saveFile(body)
})
}
function saveFile(body) {
const fileName = body.media_type === 'image/jpeg' ? 'nasa.jpg' : 'nasa.mp4';
const filePath = path.join(tmpDir + `/${fileName}`)
console.log(`saveFile: file PATH ${filePath}`)
if (fileName === 'nasa.mp4') {
// tweeter le lien
const params = {
status: 'NASA video link: ' + body.url
}
postStatus(params)
return
}
const file = fs.createWriteStream(filePath)
request(body).pipe(file).on('close', err => {
if (err) {
console.log(err)
} else {
console.log('Media saved!')
const descriptionText = body.title
uploadMedia(descriptionText, filePath)
}
})
}
function uploadMedia(descriptionText, fileName) {
console.log(`uploadMedia: file PATH ${fileName}`)
bot.postMediaChunked({
file_path: fileName
}, (err, data, respone) => {
if (err) {
console.log(err)
} else {
console.log(data)
const params = {
status: descriptionText,
media_ids: data.media_id_string
}
postStatus(params)
}
})
}
function postStatus(params) {
bot.post('statuses/update', params, (err, data, respone) => {
if (err) {
console.log(err)
} else {
console.log('Status posted!')
}
})
}
module.exports = getPhoto
D'accord, c'est tout ! Nous sommes prêts à déployer sur now !
Dans le terminal, nous appelons notre script de déploiement que nous avons défini précédemment :
yarn deploy
Vous obtiendrez une sortie :
yarn deploy
yarn deploy v0.24.4
$ now -e CONSUMER_KEY=@ds-twit-key -e CONSUMER_SECRET=@ds-twit-secret -e ACCESS_TOKEN=@ds-twit-access -e ACCESS_TOKEN_SECRET=@ds-twit-access-secret -e NASA_KEY=@nasa-key
> Deploying ~\gitrepos\tweebot-play under spences10
> Using Node.js 7.10.0 (default)
> Ready! https://twee-bot-play-rapjuiuddx.now.sh (copied to clipboard) [5s]
> Upload [====================] 100% 0.0s
> Sync complete (1.54kB) [2s]
> Initializing
> Building
>
npm install
>
Installing:
>
csv-parse@^1.2.0
>
dotenv@^4.0.0
>
rita@^1.1.63
>
tabletop@^1.5.2
>
twit@^2.2.5
>
Installed 106 modules [3s]
>
npm start
> > tweet-bot-playground@1.0.0 start /home/nowuser/src
> > node index.js
> saveFile: file PATH /tmp/nasa.jpg
> Media saved!
> uploadMedia: file PATH /tmp/nasa.jpg
Woot ! Vous avez déployé votre bot !
Si vous cliquez sur le lien produit, vous pourrez inspecter le bot tel qu'il est sur now. Il y a également une section de logs pratique sur la page où vous pouvez vérifier la sortie.
Ressources
Merci d'avoir lu ! Si vous avez aimé cette histoire, n'oubliez pas de la recommander en cliquant sur le bouton sur le côté, et en la partageant avec vos amis sur les réseaux sociaux.
Si vous voulez en savoir plus sur moi, vous pouvez me poser n'importe quelle question, consulter mon Github, ou me tweeter @ScottDevTweets.
Vous pouvez lire d'autres articles comme celui-ci sur mon blog.