

Article original : How to Setup a Basic Serverless REST API with AWS Lambda and API Gateway
Par Nyior Clement
En tant que développeurs, nous cherchons toujours à optimiser tout, de la manière dont les gens communiquent à la manière dont ils achètent des choses. L'objectif est de rendre les humains plus productifs.
Dans cet esprit, le paysage du développement logiciel a vu une augmentation spectaculaire des outils de productivité pour les développeurs.
Cela est particulièrement vrai dans le domaine de l'infrastructure logicielle. Les innovateurs créent des solutions qui permettent aux développeurs de se concentrer davantage sur l'écriture de la logique métier réelle et moins sur les préoccupations de déploiement banales.
Le besoin d'améliorer l'expérience des développeurs et de réduire les coûts sont certains des principaux moteurs de l'informatique sans serveur. Mais qu'est-ce que l'informatique sans serveur ? C'est le cœur de ce guide. C'est la seule question qui compte ici, et nous y viendrons.
Pour vous aider à suivre ce guide, je l'ai divisé en deux parties :
- Dans la première partie, nous allons commencer par apprendre ce qu'est le serverless.
- Dans la deuxième partie, nous allons configurer une API REST serverless rudimentaire avec AWS Lambda et API Gateway.
Commençons déjà, d'accord ?
Qu'est-ce que le Serverless ?
Pour comprendre ce qu'est le serverless, nous devons d'abord comprendre ce que sont les serveurs et comment ils ont évolué au fil du temps. Attendez, des serveurs ?
Oui, lorsque nous construisons des systèmes logiciels, la plupart du temps, nous les construisons pour les gens. Pour cette raison, nous rendons ces applications trouvables sur l'internet.
Rendre une application découvrable, idéalement, implique de télécharger cette application sur un ordinateur spécial qui fonctionne 24h/24 et 7j/7 et qui est super rapide. Cet ordinateur spécial est appelé un serveur.
L'Évolution des Serveurs
Il y a deux décennies, lorsque les entreprises voulaient télécharger un logiciel qu'elles avaient construit sur un serveur, elles devaient acheter un ordinateur physique, configurer l'ordinateur, puis déployer leur application sur cet ordinateur.
Dans les cas où elles devaient télécharger plusieurs applications, elles devaient également obtenir et configurer plusieurs serveurs. Tout était fait sur site.
Mais il n'a pas fallu longtemps pour que les gens remarquent les nombreux problèmes qui accompagnent cette approche des serveurs.
Il y a le problème de la productivité des développeurs : l'attention d'un développeur est divisée entre l'écriture de code et la gestion de l'infrastructure qui sert le code. Ce problème pourrait facilement être résolu en faisant appel à d'autres personnes pour gérer les problèmes d'infrastructure – mais cela conduit à un deuxième problème :
Le problème du coût. Ces personnes qui s'occupent des problèmes d'infrastructure doivent être payées, n'est-ce pas ? En fait, le simple fait d'avoir à acheter un serveur même pour des applications de test apparemment basiques est en soi une affaire coûteuse.
De plus, si nous commençons à prendre en compte d'autres éléments comme la mise à l'échelle de la capacité de calcul d'un serveur en cas de pic de trafic ou simplement la mise à jour du système d'exploitation et des pilotes du serveur au fil du temps... eh bien, vous commencerez à voir à quel point il est épuisant de maintenir un serveur interne. Les gens désiraient quelque chose de mieux. Il y avait un besoin.
Amazon a répondu à ce besoin lorsqu'il a annoncé la sortie d'Amazon Web Services (AWS) en 2006. AWS a notoirement perturbé le domaine de l'infrastructure logicielle. C'était un changement révolutionnaire par rapport aux serveurs traditionnels.
AWS a éliminé le besoin pour les organisations de configurer leur serveur interne. Au lieu de cela, les organisations et même les particuliers pouvaient simplement télécharger leurs applications sur les ordinateurs d'Amazon via Internet moyennant des frais. Et ce modèle de serveur-en-tant-que-service a annoncé le début de l'informatique en nuage.
Qu'est-ce que le Cloud Computing ?
Le Cloud Computing consiste fondamentalement à stocker des fichiers ou à exécuter du code (parfois les deux) sur l'ordinateur de quelqu'un d'autre, généralement via un réseau.
Les plateformes de cloud computing comme AWS, Microsoft Azure, Google Cloud Platform, Heroku et autres existent pour éviter aux gens le stress de devoir configurer et maintenir leurs propres serveurs.
Ce qui est remarquablement unique dans le cloud computing, c'est le fait que vous pouvez être au Nigeria et louer un ordinateur qui se trouve aux États-Unis. Vous pouvez ensuite accéder à cet ordinateur que vous avez loué et faire des choses avec lui via Internet. Essentiellement, les fournisseurs de cloud nous fournissent des environnements de calcul pour télécharger et exécuter notre logiciel personnalisé.
L'environnement que nous obtenons de ces fournisseurs est quelque chose qui a progressé et existe maintenant sous différentes formes.
Dans le jargon du cloud computing, nous utilisons le terme modèles de cloud computing pour désigner les différents environnements que la plupart des fournisseurs de cloud offrent. Chaque nouveau modèle dans le paysage du cloud computing est généralement créé pour améliorer la productivité des développeurs et réduire les coûts d'infrastructure et de main-d'œuvre.
Par exemple, lorsque AWS a été lancé pour la première fois, il disposait du service Elastic Compute Cloud (EC2). L'EC2 est structurellement une machine basique. Les personnes qui paient pour le service EC2 doivent effectuer de nombreuses configurations comme l'installation d'un système d'exploitation, d'une base de données, et maintenir ces éléments aussi longtemps qu'elles possèdent le service.
Bien que l'EC2 offre beaucoup de flexibilité (par exemple, vous pouvez installer le système d'exploitation que vous souhaitez), il nécessite également beaucoup d'efforts pour travailler avec. L'EC2 et d'autres services similaires chez d'autres fournisseurs de cloud relèvent du modèle de cloud computing appelé Infrastructure en tant que Service (IaaS).
Le fait de ne pas avoir à acheter une machine physique et à la configurer sur site rend le modèle IaaS assez supérieur au modèle de serveur sur site. Mais malgré tout, le fait que les propriétaires doivent configurer et maintenir de nombreuses choses rend le modèle IaaS difficile à utiliser.
Les exigences quelque peu intensives en main-d'œuvre (du point de vue du développeur/client) du modèle IaaS sont également devenues une source de préoccupation. Pour y remédier, le modèle de cloud computing suivant, Platform as a Service (PaaS), est né.
Le principal problème avec l'IaaS est d'avoir à configurer et maintenir beaucoup de choses. Par exemple, l'installation du système d'exploitation, les mises à jour de correctifs, la découverte, etc.
Dans le modèle PaaS, tout cela est abstrait. Une machine dans le modèle PaaS vient préinstallée avec un système d'exploitation, et les mises à jour de correctifs sur la machine, entre autres, sont de la responsabilité du fournisseur.
Dans le modèle PaaS, les développeurs ne font que déployer leurs applications, et les fournisseurs de cloud gèrent certaines des tâches de bas niveau. Bien que ce modèle soit plus facile à utiliser, il implique également moins de flexibilité. Elastic Beanstalk d'AWS et Heroku sont quelques exemples d'offres dans ce modèle.
Le modèle PaaS a indéniablement éliminé la plupart des tâches de configuration et de maintenance fastidieuses. Mais au-delà des tâches qui rendent notre logiciel disponible sur Internet, les gens ont également commencé à reconnaître certaines des limitations du modèle PaaS.
Par exemple, dans les modèles IaaS et PaaS, les développeurs devaient gérer manuellement la mise à l'échelle des capacités de calcul d'un serveur. De plus, avec les plateformes IaaS et PaaS, la plupart des fournisseurs facturent un tarif fixe (pensez à Heroku) pour leurs services – ce n'est pas basé sur l'utilisation.
Dans les situations où le tarif est basé sur l'utilisation, il n'est généralement pas très précis. Enfin, dans les modèles IaaS et PaaS, les applications sont de longue durée (toujours en cours d'exécution même lorsqu'il n'y a pas de requêtes entrantes). Cela entraîne une utilisation inefficace des ressources du serveur.
Les préoccupations ci-dessus ont suscité la prochaine évolution du cloud.
L'Essor de l'Informatique Sans Serveur
Tout comme l'IaaS et le PaaS, le Serverless est un modèle de cloud computing. C'est l'évolution la plus récente du cloud, juste après le PaaS. Comme l'IaaS et le PaaS, avec le serverless, vous n'avez pas à acheter d'ordinateurs physiques.
De plus, tout comme dans le modèle PaaS, vous n'avez pas à configurer et maintenir significativement les serveurs. De plus, le modèle serverless est allé plus loin : il a éliminé le besoin de gérer des instances d'applications de longue durée et de mettre à l'échelle manuellement les ressources du serveur en fonction du trafic. Le paiement est précisément basé sur l'utilisation, et les préoccupations de sécurité sont également abstraites.
Dans le modèle serverless, vous n'avez plus à vous soucier de quoi que ce soit lié à l'infrastructure car les fournisseurs de cloud gèrent tout cela. Et c'est exactement de quoi il s'agit dans le modèle serverless : permettre aux développeurs et aux organisations entières de se concentrer sur les aspects dynamiques de leur projet tout en laissant toutes les préoccupations d'infrastructure au fournisseur de cloud.
Littéralement toutes les préoccupations d'infrastructure, de la configuration et de la maintenance du serveur à la mise à l'échelle automatique des ressources du serveur de zéro et aux préoccupations de sécurité. Et en fait, l'une des fonctionnalités phares du modèle serverless est le fait que les utilisateurs sont facturés précisément en fonction du nombre de requêtes que le logiciel qu'ils ont déployé a traitées.
Nous pouvons donc maintenant dire que le serverless est le terme que nous utilisons pour désigner toute solution cloud qui élimine toutes les préoccupations d'infrastructure que nous devrions normalement avoir à gérer. Par exemple, AWS Lambda, Azure Functions, et autres.
Nous utilisons également le terme serverless pour décrire les applications conçues pour être déployées sur ou interagir avec un environnement serverless. Hmmm, comment cela ?
Function as a Service vs Backend as a Service
Toutes les solutions serverless appartiennent à l'une des deux catégories :
- Function as a Service (FaaS) et
- Backend as a Service (BaaS).
BaaS, FaaS – Nyior, cela devient assez compliqué :-(
Je sais, mais ne vous inquiétez pas – vous allez comprendre <3
Une offre cloud est considérée comme un BaaS et par extension serverless si elle remplace certains composants de notre application que nous coderions ou gérerions normalement nous-mêmes.
Par exemple, lorsque vous utilisez le service d'authentification Firebase de Google ou le service Cognito d'Amazon pour gérer l'authentification des utilisateurs dans votre projet, vous avez alors utilisé une offre BaaS.
Une offre cloud est considérée comme un FaaS et par extension serverless si elle élimine le besoin de déployer nos applications en tant qu'instances uniques qui sont ensuite exécutées en tant que processus au sein d'un hôte. Au lieu de cela, nous décomposons notre application en fonctions granulaires (chaque fonction encapsulant idéalement la logique d'une seule opération). Chaque fonction est ensuite déployée sur la plateforme FaaS.
Trop abstrait ? D'accord, voyez l'image ci-dessous :
 De gauche à droite : Déploiement d'une application sur une plateforme FaaS, Déploiement d'une application sur une plateforme non-FaaS. Source : Auteur
De gauche à droite : Déploiement d'une application sur une plateforme FaaS, Déploiement d'une application sur une plateforme non-FaaS. Source : Auteur
D'après l'image ci-dessus, vous pouvez voir que les plateformes FaaS offrent une manière entièrement différente de déployer des applications. Nous n'avons jamais vu cela auparavant : il n'y a pas d'hôtes et de processus d'application. Par conséquent, nous n'avons pas de code qui s'exécute constamment et écoute les requêtes.
Au lieu de cela, nous avons des fonctions qui ne s'exécutent que lorsqu'elles sont invoquées, et elles sont supprimées dès qu'elles ont terminé le traitement de la tâche pour laquelle elles ont été appelées.
Si ces fonctions ne s'exécutent pas toujours et n'écoutent pas les requêtes, comment sont-elles invoquées, pourriez-vous demander ?
Toutes les plateformes FaaS sont basées sur des événements. Essentiellement, chaque fonction que nous déployons est mappée à un événement. Et lorsque cet événement se produit, la fonction est déclenchée.
En résumé, nous utilisons le terme serverless pour décrire une solution cloud de type Function as a Service ou Backend as a Service où :
- Nous n'avons pas à gérer des instances d'applications de longue durée ou des hôtes pour les applications que nous déployons.
- Nous n'avons pas à mettre à l'échelle manuellement les ressources de calcul en fonction du trafic car le serveur le fait automatiquement pour nous.
- La tarification est précisément basée sur l'utilisation
De plus, toute application construite sur un nombre significatif de solutions BaaS ou conçue pour être déployée sur une plateforme FaaS, ou même les deux, peut également être considérée comme serverless.
Maintenant que nous sommes bien ancrés dans ce qu'est le serverless, voyons comment nous pouvons configurer une API REST serverless minimale avec AWS Lambda en tandem avec AWS API Gateway.
Projet d'Exemple Serverless
Ici, nous allons configurer une API REST serverless minimale, peut-être sans intérêt, avec AWS Lambda et API Gateway.
AWS Lambda, API Gateway – Quelles sont ces choses, s'il vous plaît ?
Ce sont des solutions cloud serverless. Rappelez-vous que nous avons déclaré que toutes les solutions cloud serverless appartiennent à l'une des deux catégories : BaaS et FaaS. AWS Lambda est une plateforme Function as a Service et API Gateway est une solution Backend as a Service.
Comment API Gateway est-elle une plateforme Backend as a Service, pourriez-vous demander ?
Eh bien, normalement, nous implémentons le routage dans nos applications nous-mêmes. Avec API Gateway, nous n'avons pas à le faire – au lieu de cela, nous cédons la tâche de routage à API Gateway.
AWS Lambda, API Gateway, Notre Application – Comment tout cela est-il connecté ?
La connexion est simple. AWS Lambda est l'endroit où nous allons déployer notre code d'application réel. Mais parce qu'AWS Lambda est une plateforme FaaS, nous allons décomposer notre application en fonctions granulaires, chaque fonction gérant une seule opération. Nous allons ensuite déployer chaque fonction sur AWS Lambda.
Oh d'accord, mais où intervient API Gateway ?
AWS Lambda, comme toutes les autres plateformes FaaS, est basée sur des événements. Cela signifie que lorsque vous déployez une fonction sur la plateforme, cette fonction ne fait quelque chose que lorsqu'un événement auquel elle est liée se produit.
Un événement peut être n'importe quoi, d'une requête HTTP à un fichier téléchargé sur s3.
Dans notre cas, nous allons déployer un backend d'API REST minimal. Parce que nous allons serverless et plus spécifiquement de la manière FaaS, nous allons décomposer notre backend REST en fonctions indépendantes. Chaque fonction sera liée à une requête HTTP.
En fait, nous allons écrire une seule fonction.
API Gateway est l'outil que nous allons utiliser pour lier une requête à une fonction que nous avons déployée. Donc, lorsque cette requête particulière arrive, la fonction est invoquée.
Considérez API Gateway comme un outil de routage-en-tant-que-service :-). L'image ci-dessous représente la relation entre les entités ci-dessus.
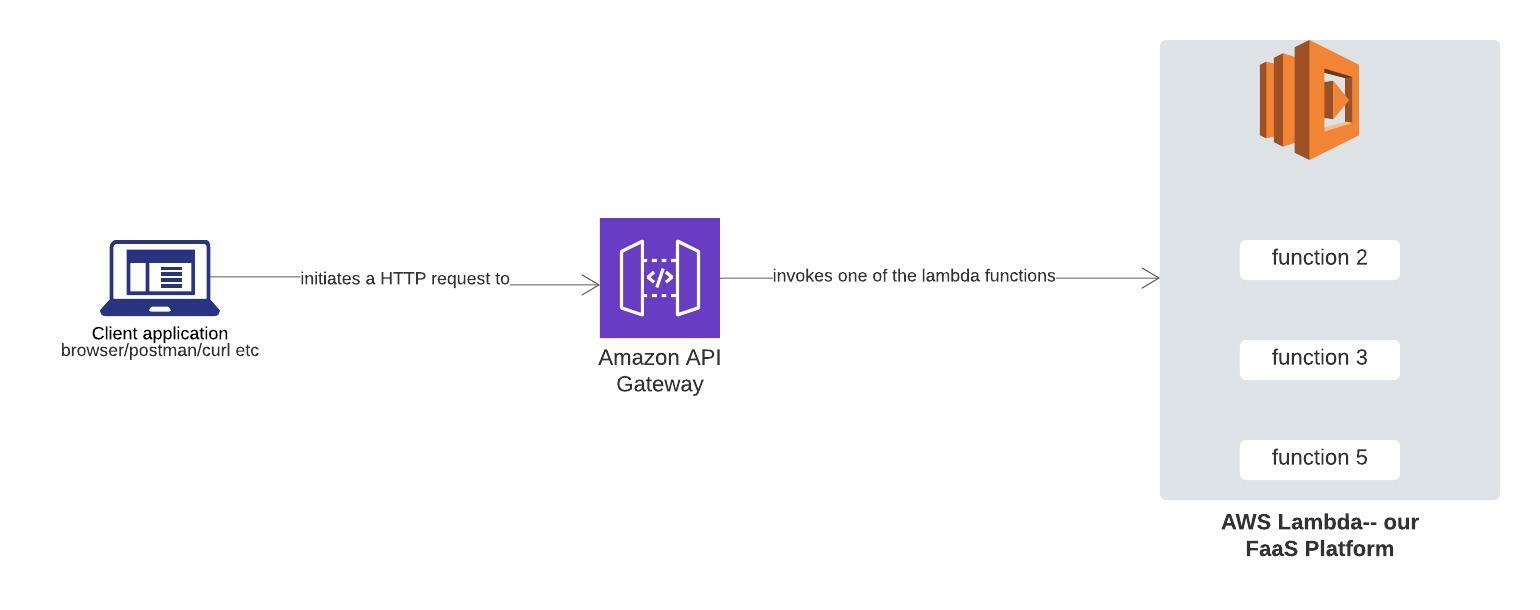 API Gateway + AWS Lambda. Source : Auteur
API Gateway + AWS Lambda. Source : Auteur
D'accord, je comprends la connexion. Qu'est-ce qui suit ?
Configurons des Choses sur AWS xD
La tâche principale ici est de construire un outil de paraphrase minimal. Nous allons créer un endpoint REST qui accepte une requête POST avec du texte comme payload. Notre endpoint retournera ensuite une version paraphrasée de ce texte comme réponse.
Pour y parvenir, nous allons coder une fonction lambda qui effectue la paraphrase réelle des blocs de texte. Nous allons ensuite connecter notre fonction à la passerelle API, juste pour que chaque fois qu'il y a une requête POST, notre fonction sera déclenchée.
Mais d'abord, il y a certaines choses que nous devons configurer. Suivez les étapes des sections suivantes pour configurer tout ce dont vous aurez besoin pour accomplir la tâche de cette partie.
Note : Certaines des étapes des sections suivantes ont été adaptées directement du tutoriel d'AWS sur le serverless.
Étape 1 : Créer un Compte AWS
Pour créer un compte sur AWS, suivez les étapes du module 1 de ce guide.
Étape 2 : Coder notre Fonction Lambda sur AWS
Rappelez-vous, nous allons avoir besoin d'une fonction qui effectue la paraphrase réelle du texte, et c'est ici que nous le faisons. Suivez les étapes ci-dessous pour créer la fonction lambda :
- Connectez-vous à votre compte AWS en utilisant les identifiants de l'étape 1. Dans le champ de recherche, entrez 'lambda', puis sélectionnez Lambda dans la liste des services affichés.
- Cliquez sur le bouton créer une fonction sur la page Lambda.
- Gardez la carte Auteur à partir de zéro sélectionnée par défaut.
- Entrez _paraphrasetext dans le champ Nom.
- Sélectionnez Python 3.9 pour le Runtime.
- Laissez tous les autres paramètres par défaut tels quels et cliquez sur créer une fonction.
- Faites défiler vers le bas jusqu'à la section Code de la fonction et remplacez le code existant dans l'éditeur de code lamda_function.py par le code ci-dessous :
import http.client
def lambda_handler(event, context):
# TODO implement
conn = http.client.HTTPSConnection("paraphrasing-tool1.p.rapidapi.com")
payload = event['body']
headers = {
'content-type': "application/json",
'x-rapidapi-host': "paraphrasing-tool1.p.rapidapi.com",
'x-rapidapi-key': "votre clé api ici"
}
conn.request("POST", "/api/rewrite", payload, headers)
res = conn.getresponse()
data = res.read()
return {
'statusCode': 200,
'body': data
}
Nous utilisons cette API pour la fonctionnalité de paraphrase. Rendez-vous sur cette page, abonnez-vous au plan de base et récupérez la clé API (c'est gratuit).
Étape 3 : Tester notre Fonction Lambda sur AWS
Ici, nous allons tester notre fonction lambda avec une entrée d'exemple pour voir qu'elle produit le comportement attendu : paraphraser tout texte qui lui est passé.
Pour tester votre fonction lambda nouvellement créée, suivez les étapes suivantes :
- À partir de l'écran d'édition principal de votre fonction, sélectionnez Configurer l'événement de test dans le menu déroulant Test.
- Gardez Créer un nouvel événement de test sélectionné.
- Entrez TestRequestEvent dans le champ Nom de l'événement
- Copiez et collez l'événement de test suivant dans l'éditeur :
{
"path": "/paraphrase",
"httpMethod": "POST",
"headers": {
"Accept": "*/*",
"content-type": "application/json; charset=UTF-8"
},
"queryStringParameters": null,
"pathParameters": null,
"body": "{\r\"sourceText\": \"Le point de discorde en ce moment est de savoir comment gagner beaucoup d'argent. \"\r\r\n }"
}
Vous pouvez remplacer le texte du corps par le contenu que vous souhaitez. Une fois que vous avez terminé de coller le code ci-dessus, procédez aux étapes suivantes :
- Cliquez sur créer.
- Sur l'écran d'édition principal de la fonction, cliquez sur Test avec TestRequestEvent sélectionné dans le menu déroulant.
- Faites défiler vers le haut de la page et développez la section Détails de la section Résultat de l'exécution.
- Vérifiez que l'exécution a réussi et que le résultat de la fonction ressemble à ce qui suit :
Réponse
{
"statusCode": 200,
"body": "{\"newText\":\"Le point de discorde en ce moment est de savoir comment gagner beaucoup d'argent.\"}"
}
Comme on peut le voir ci-dessus, le texte original que nous avons passé à notre fonction lambda a été paraphrasé.
Étape 3 : Exposer notre Fonction Lambda via l'API Gateway.
Maintenant que nous avons codé notre fonction lambda et qu'elle fonctionne, ici, nous allons exposer la fonction via un endpoint REST qui accepte une requête POST. Une fois qu'une requête est envoyée à cet endpoint, notre fonction lambda sera appelée.
Suivez les étapes ci-dessous pour exposer votre fonction lambda via l'API Gateway :
Créer l'API
- Dans le champ de recherche, recherchez et sélectionnez API Gateway
- Sur la page API Gateway, il y a quatre cartes sous l'en-tête choisir un type d'API. Allez à la carte REST API et cliquez sur construire.
- Ensuite, fournissez toutes les informations requises comme indiqué dans l'image ci-dessous et cliquez sur Créer l'API.
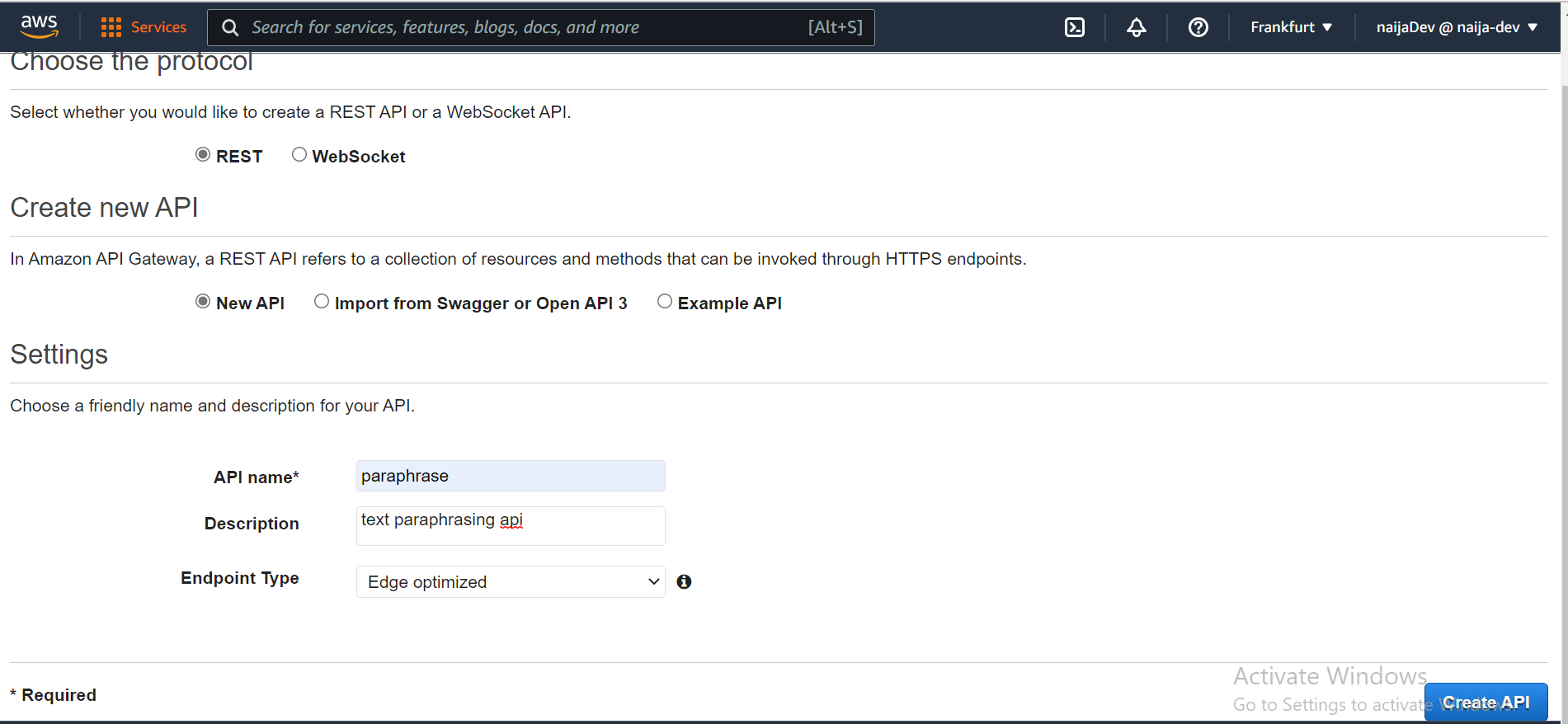 Pour le type d'endpoint, sélectionnez Edge optimisé
Pour le type d'endpoint, sélectionnez Edge optimisé
Créer la Ressource et la Méthode
Ressource, Méthode ? Dans les étapes ci-dessus, nous avons créé une API. Mais une API a généralement des endpoint(s). Un endpoint spécifie généralement un chemin et la méthode HTTP qu'il prend en charge. Par exemple, GET /get-user. Ici, nous appelons le chemin ressource, et le verbe HTTP lié à un chemin méthode. Ainsi, ressource + méthode = endpoint REST.
Ici, nous allons créer un endpoint REST qui permettra aux utilisateurs de passer un bloc de texte à paraphraser à notre fonction lambda. Suivez les étapes ci-dessous pour accomplir cela :
- Tout d'abord, dans le menu déroulant Actions, sélectionnez Créer une Ressource. Ensuite, remplissez les champs d'entrée et cochez la case comme indiqué dans l'image ci-dessous et cliquez sur Créer une Ressource.
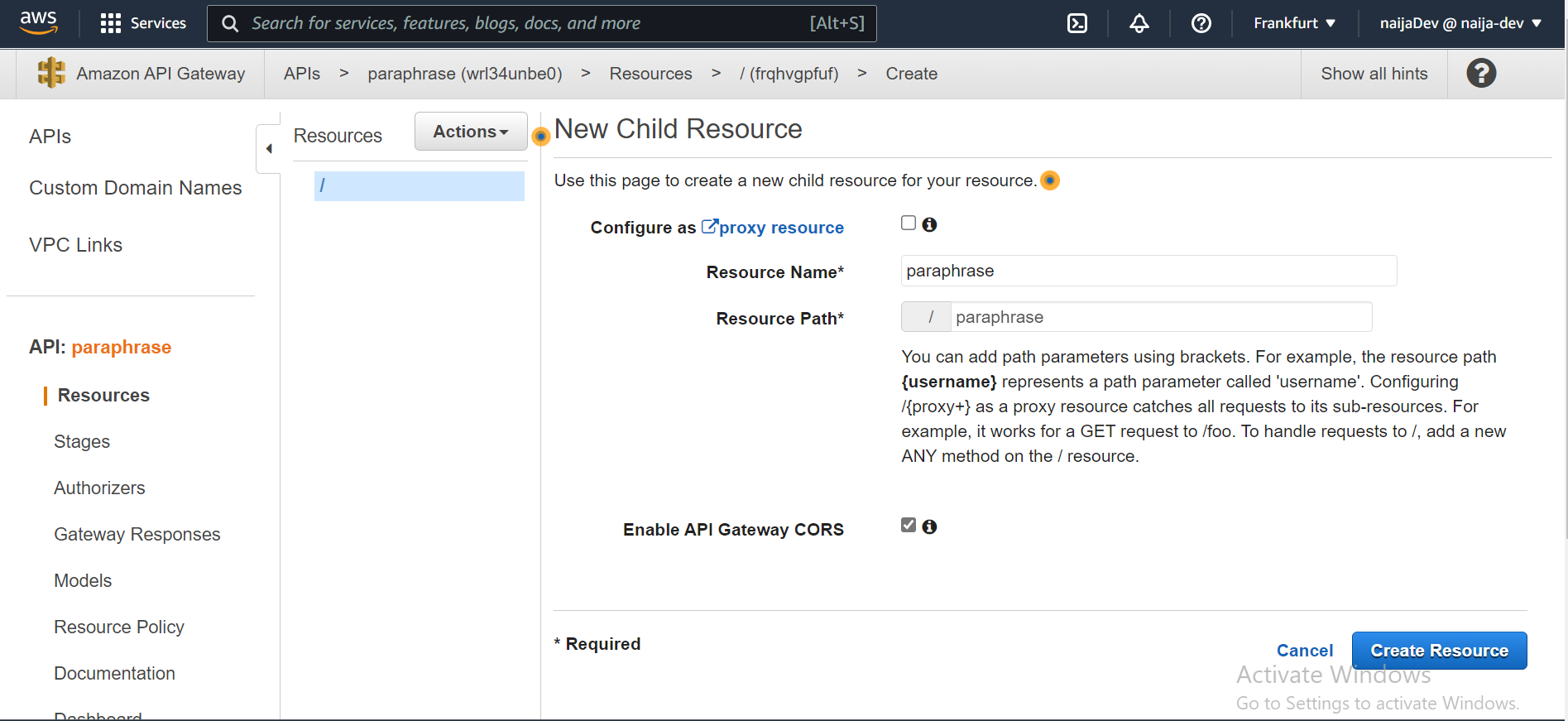 Vous pourriez remplacer le nom de la ressource et le chemin de la ressource par ce que vous souhaitez. Remarquez comment nous avons également activé CORS.
Vous pourriez remplacer le nom de la ressource et le chemin de la ressource par ce que vous souhaitez. Remarquez comment nous avons également activé CORS.
- Avec la nouvelle ressource /paraphrase sélectionnée, dans le menu déroulant Action, sélectionnez Créer une Méthode.
- Sélectionnez POST dans le nouveau menu déroulant qui apparaît, puis cliquez sur la coche.
- Fournissez toutes les autres informations montrées dans l'image ci-dessous et cliquez sur enregistrer.
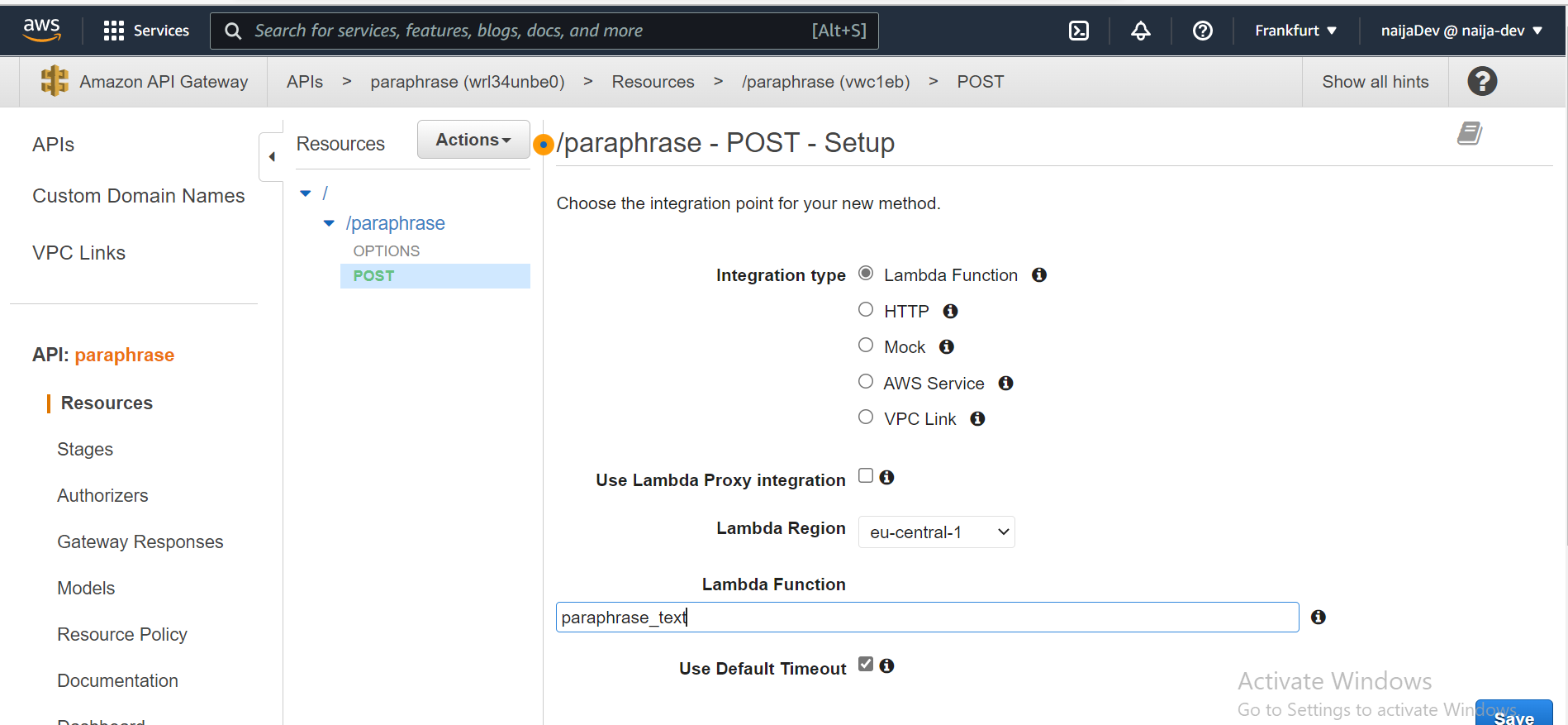 lambda function est le nom de la fonction que nous créons dans l'une des étapes précédentes.
lambda function est le nom de la fonction que nous créons dans l'une des étapes précédentes.
Déployer l'API
- Dans la liste déroulante Actions, sélectionnez Déployer l'API.
- Sélectionnez [Nouvel Étape] dans la liste déroulante Étape de Déploiement.
- Entrez production ou ce que vous souhaitez pour le Nom de l'Étape.
- Choisissez Déployer.
- Notez que l'URL d'invocation est l'URL de base de votre API. Elle devrait ressembler à ceci : https://wrl34unbe0.execute-api.eu-central-1.amazonaws.com/{nom de l'étape}
- Pour tester votre endpoint, vous pouvez utiliser postman ou curl. Ajoutez le chemin de votre endpoint à la fin de l'URL d'invocation comme suit : https://wrl34unbe0.execute-api.eu-central-1.amazonaws.com/{nom de l'étape}/paraphrase. Et bien sûr, la méthode de requête doit être POST.
- Lors du test, ajoutez également le payload attendu à la requête comme suit :
{
"sourceText": "Le point de discorde en ce moment est de savoir comment gagner beaucoup d'argent.
}
Conclusion
Eh bien, c'est tout. D'abord, nous avons tout appris sur le terme serverless, puis nous avons continué à configurer une API REST serverless légère avec AWS Lambda et API Gateway.
Serverless n'implique pas l'absence totale de serveurs, cependant. Il s'agit essentiellement d'avoir un flux de déploiement où vous n'avez pas à vous soucier des serveurs. Les serveurs sont toujours présents, mais ils sont pris en charge par le fournisseur de cloud.
Nous allons serverless chaque fois que nous construisons des composants significatifs de notre application sur des technologies BaaS ou lorsque nous structurons notre application pour qu'elle soit compatible avec une plateforme FaaS (ou lorsque nous faisons les deux).
Merci d'avoir lu jusqu'à ce point. Vous voulez vous connecter ? Vous pouvez me trouver sur Twitter, LinkedIn, ou GitHub.
Références
Image de couverture : hestabit.com