
Article original : How to Set Up a Continuous Integration Pipeline with GitHub Actions and Puppeteer
Par Dor Shinar
Récemment, j'ai ajouté l'intégration continue à mon blog en utilisant Puppeteer pour les tests de bout en bout. Mon objectif principal était de permettre les mises à jour automatiques des dépendances en utilisant Dependabot. Dans ce guide, je vais vous montrer comment créer un tel pipeline vous-même.
En tant que plateforme CI, j'ai choisi GitHub Actions, car c'est super facile à utiliser. Il s'intègre également parfaitement avec n'importe quel dépôt GitHub que vous avez déjà. Tout cela n'a pris qu'environ deux jours de travail intermittent, et je pense que les résultats sont assez impressionnants.
Je tiens à rendre hommage à Nick Taylor, qui a publié son article sur le sujet, et a posé les bases de mes efforts ici. Je vous encourage à lire son article également.
Ma stack technique est cependant assez différente. J'ai choisi puppeteer comme framework de bout en bout pour plusieurs raisons. La première est qu'il est écrit et maintenu par les gens derrière les outils de développement Chrome, donc je suis garanti un support à vie (jusqu'à ce que Chrome disparaisse, ce qui n'est pas pour bientôt), et il est vraiment facile à utiliser.
Une autre raison est qu'à la maison je travaille sur un ordinateur portable Windows avec WSL (sur lequel j'exécute zshell avec oh-my-zsh). La configuration de Cypress est un peu plus difficile (bien que dans notre monde rien ne soit impossible). Ces deux raisons m'ont conduit à choisir Puppeteer, et jusqu'à présent je ne le regrette pas.
Tests de bout en bout
Les tests de bout en bout (ou E2E) sont différents des autres types de tests automatisés. Les tests E2E simulent un utilisateur réel, effectuant des actions sur l'écran. Ce type de test devrait aider à combler l'espace vide entre les tests "statiques" - tels que les tests unitaires, où vous ne démarrez généralement pas toute l'application - et les tests de composants, qui s'exécutent généralement contre un seul composant (ou un service dans une architecture de microservices).
En simulant l'interaction de l'utilisateur, vous pouvez tester l'expérience d'utilisation de votre application ou service de la même manière qu'un utilisateur régulier l'expérimenterait.
Le mantra que nous essayons de suivre est qu'il n'a pas d'importance si votre code fonctionne parfaitement si le bouton que l'utilisateur doit presser est caché en raison d'un caprice CSS. Le résultat final est que l'utilisateur ne pourra jamais ressentir la grandeur de votre code.
Commencer avec Puppeteer
Puppeteer a quelques options de configuration qui le rendent vraiment génial à utiliser pour écrire et valider des tests.
Les tests Puppeteer peuvent s'exécuter dans un état "head-full". Cela signifie que vous pouvez ouvrir une vraie fenêtre de navigateur, naviguer vers le site testé et effectuer des actions sur la page donnée. De cette façon, vous - les développeurs écrivant les tests - pouvez voir exactement ce qui se passe dans le test, quels boutons sont pressés et à quoi ressemble l'interface utilisateur résultante.
L'opposé de "head-full" serait headless, où Puppeteer n'ouvre pas de fenêtre de navigateur, ce qui le rend idéal pour les pipelines CI.
Puppeteer est assez facile à utiliser, mais vous serez surpris par le nombre d'actions que vous pouvez effectuer à l'aide d'un outil automatisé.
Nous commencerons par un scraper de base qui imprime le titre de la page lorsque nous allons sur https://dorshinar.me. Afin d'exécuter des tests Puppeteer, nous devons l'installer en tant que dépendance :
npm i puppeteer
Maintenant, notre scraper de base ressemble à ceci :
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://dorshinar.me");
console.log(await page.title());
await browser.close();
})();
Ce que nous faisons ici est très simple : nous ouvrons le navigateur avec puppeteer.launch(), créons une nouvelle page avec browser.newPage() et naviguons vers ce blog avec page.goto(), puis nous imprimons le titre.
Il y a un tas de choses que nous pouvons faire avec l'API Puppeteer, comme :
Exécuter du code dans le contexte de la page :
(async () => {
await page.evaluate(() => document.querySelector(".awesome-button").click());
})();
Cliquer sur des éléments à l'écran en utilisant un sélecteur CSS :
(async () => {
await page.click(".awesome-button");
})();
Utiliser le sélecteur $ (style jQuery) :
(async () => {
await page.$(".awesome-button");
})();
Prendre une capture d'écran :
(async () => {
await page.screenshot({ path: "screenshot.png" });
})();
Il y a beaucoup plus de choses que vous pouvez faire avec l'API Puppeteer, et je vous suggère de jeter un coup d'œil avant de vous lancer dans l'écriture de tests. Mais les exemples que j'ai montrés devraient vous donner une base solide pour construire.
Intégration de Puppeteer avec Jest
jest est un excellent exécuteur de tests et une bibliothèque d'assertions. D'après leur documentation :
Jest est un framework de test JavaScript délicieux avec un focus sur la simplicité.
Jest vous permet d'exécuter des tests, de simuler des imports et de faire des assertions complexes vraiment facilement. Jest est également fourni avec create-react-app, donc je l'utilise souvent au travail.
Écrire votre premier test Jest
Les tests Jest sont super faciles à écrire, et ils peuvent être familiers à ceux qui connaissent d'autres frameworks de test (car Jest utilise it, test, describe et d'autres conventions familières).
Un test de base pourrait ressembler à ceci :
function subtract(a, b) {
return a - b;
}
it("soustrait 4 de 6 et retourne 2", () => {
expect(subtract(6, 4)).toBe(2);
});
Vous pouvez également regrouper plusieurs tests sous un seul describe, afin de pouvoir exécuter différents describes ou l'utiliser pour des rapports pratiques :
function divide(a, b) {
if (b === 0) {
throw new Error("Impossible de diviser par zéro !");
}
return a / b;
}
describe("divide", () => {
it("lance une erreur lors de la division par zéro", () => {
expect(() => divide(6, 0)).toThrow();
});
it("retourne 3 lors de la division de 6 par 3", () => {
expect(divide(6, 3)).toBe(2);
});
});
Vous pouvez, bien sûr, créer des tests beaucoup plus compliqués en utilisant des mocks et d'autres types d'assertions (ou attentes), mais pour l'instant, c'est suffisant.
L'exécution des tests est également très simple :
jest
Jest recherchera les fichiers de test avec l'une des conventions de nommage populaires suivantes :
- Fichiers avec le suffixe
.jsdans les dossiers__tests__. - Fichiers avec le suffixe
.test.js. - Fichiers avec le suffixe
.spec.js.
jest-puppeteer
Maintenant, nous devons faire en sorte que Puppeteer fonctionne bien avec Jest. Ce n'est pas un travail particulièrement difficile à faire, car il existe un excellent package nommé jest-puppeteer qui vient à notre aide.
Tout d'abord, nous devons l'installer en tant que dépendance :
npm i jest-puppeteer
Et maintenant, nous devons étendre notre configuration Jest. Si vous n'en avez pas encore, il existe plusieurs façons de le faire. Je vais opter pour un fichier de configuration. Créez un fichier nommé jest.config.js à la racine de votre projet :
touch jest.config.js
Dans le fichier, nous devons dire à Jest d'utiliser le preset de jest-puppeteer, alors ajoutez le code suivant au fichier :
module.exports = {
preset: "jest-puppeteer"
// Le reste de votre fichier...
};
Vous pouvez spécifier une configuration de lancement spéciale dans un fichier jest-puppeteer.config.js, et jest-puppeteer transmettra cette configuration à puppeteer.launch(). Par exemple :
module.exports = {
launch: {
headless: process.env.CI === "true",
ignoreDefaultArgs: ["--disable-extensions"],
args: ["--no-sandbox"],
executablePath: "chrome.exe"
}
};
jest-puppeteer se chargera d'ouvrir un nouveau navigateur et une nouvelle page et les stockera dans la portée globale. Ainsi, dans vos tests, vous pouvez simplement utiliser les objets browser et page disponibles globalement.
Une autre fonctionnalité géniale que nous pouvons utiliser est la capacité de jest-puppeteer à exécuter votre serveur pendant vos tests, et à le tuer ensuite, avec la clé server :
module.exports = {
launch: {},
server: {
command: "npm run serve",
port: 9000,
launchTimeout: 180000
}
};
Maintenant, jest-puppeteer exécutera npm run serve, avec un délai d'attente de 180 secondes (3 minutes), et écoutera sur le port 9000 pour voir quand il sera opérationnel. Une fois le serveur démarré, les tests s'exécuteront.
Vous pouvez maintenant écrire une suite de tests complète en utilisant Jest et Puppeteer. La seule chose qui reste est de créer un pipeline CI, pour lequel nous utiliserons GitHub Actions.
Vous pouvez ajouter un script à votre fichier package.json pour exécuter vos tests :
{
"scripts": {
"test:e2e": "jest"
}
}
GitHub Actions en bref
Récemment, GitHub a publié une nouvelle fonctionnalité majeure appelée Actions. Basiquement, les actions vous permettent de créer des workflows en utilisant une syntaxe yaml simple, et de les exécuter sur des machines virtuelles dédiées.
Dans votre workflow, vous pouvez faire presque tout ce que vous voulez, de npm ci && npm build && npm run test à des choses plus compliquées.
Je vais vous montrer comment configurer un workflow de base exécutant votre suite de tests Puppeteer, et empêcher la fusion si vos tests ne passent pas.
Le moyen le plus simple de commencer est de cliquer sur l'onglet Actions dans votre dépôt GitHub. Si vous n'avez configuré aucune action auparavant, vous verrez une liste de workflows précédemment configurés, parmi lesquels vous pouvez choisir celui avec une configuration prédéfinie.
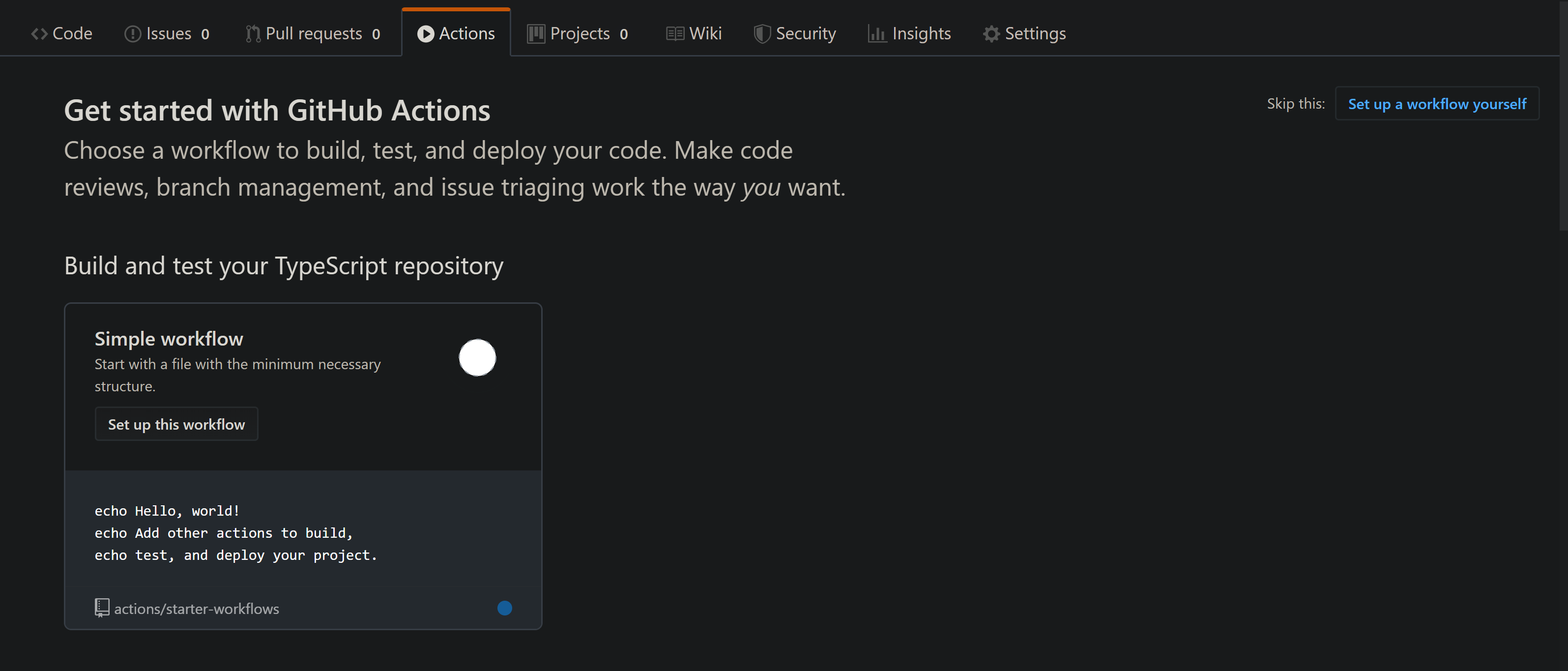
Pour notre cas, choisir l'action Node.js prédéfinie est suffisant. Le yaml généré ressemble à ceci :
name: Node CI
on: [push]
jobs:
build:
runs-on: ubuntu-latest
strategy:
matrix:
node-version: [8.x, 10.x, 12.x]
steps:
- uses: actions/checkout@v1
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v1
with:
node-version: ${{ matrix.node-version }}
- name: npm install, build, and test
run: |
npm ci
npm run build --if-present
npm test
env:
CI: true
Dans le fichier, vous pouvez configurer le nom du workflow, les jobs à exécuter et quand exécuter le workflow. Vous pouvez exécuter votre workflow à chaque push, sur de nouvelles pull requests, ou en tant qu'événement récurrent.
Les jobs dans un workflow s'exécutent en parallèle par défaut, mais peuvent être configurés pour s'exécuter en séquence. Dans le workflow ci-dessus, il y a un job nommé build.
Vous pouvez également choisir le système d'exploitation sur lequel votre workflow s'exécutera (par défaut, vous pouvez utiliser Windows Server 2019, Ubuntu 18.04, Ubuntu 16.04 et macOS Catalina 10.15 - au moment de la publication) avec la clé runs-on.
La clé strategy peut nous aider à exécuter nos tests sur une matrice de versions de Node. Dans ce cas, nous avons les dernières versions des dernières LTS majeures - 8.x, 10.x et 12.x. Si vous êtes intéressé par cela, vous pouvez le laisser tel quel, ou simplement le supprimer et utiliser n'importe quelle version spécifique que vous souhaitez.
L'option de configuration la plus intéressante est steps. Avec elle, nous définissons ce qui se passe réellement dans notre pipeline.
Chaque étape représente une action que vous pouvez effectuer, telle que la récupération de code depuis le dépôt, la configuration de votre version de Node, l'installation de dépendances, l'exécution de tests, le téléchargement d'artifacts (à utiliser plus tard ou à télécharger) et bien plus encore.
Vous pouvez trouver une liste très complète d'actions disponibles dans le Marketplace des Actions.
La configuration de base installera les dépendances, construira notre projet et exécutera nos tests. Si vous avez besoin de plus (par exemple, si vous souhaitez servir votre application pour les tests e2e), vous pouvez la modifier à votre guise. Une fois terminé, validez vos modifications et vous êtes prêt à partir.
Forcer les vérifications à passer avant la fusion
La seule chose qui nous reste à faire est de nous assurer qu'aucun code ne peut être fusionné avant que notre workflow ne passe avec succès. Pour cela, allez dans les paramètres de votre dépôt et cliquez sur Branches :
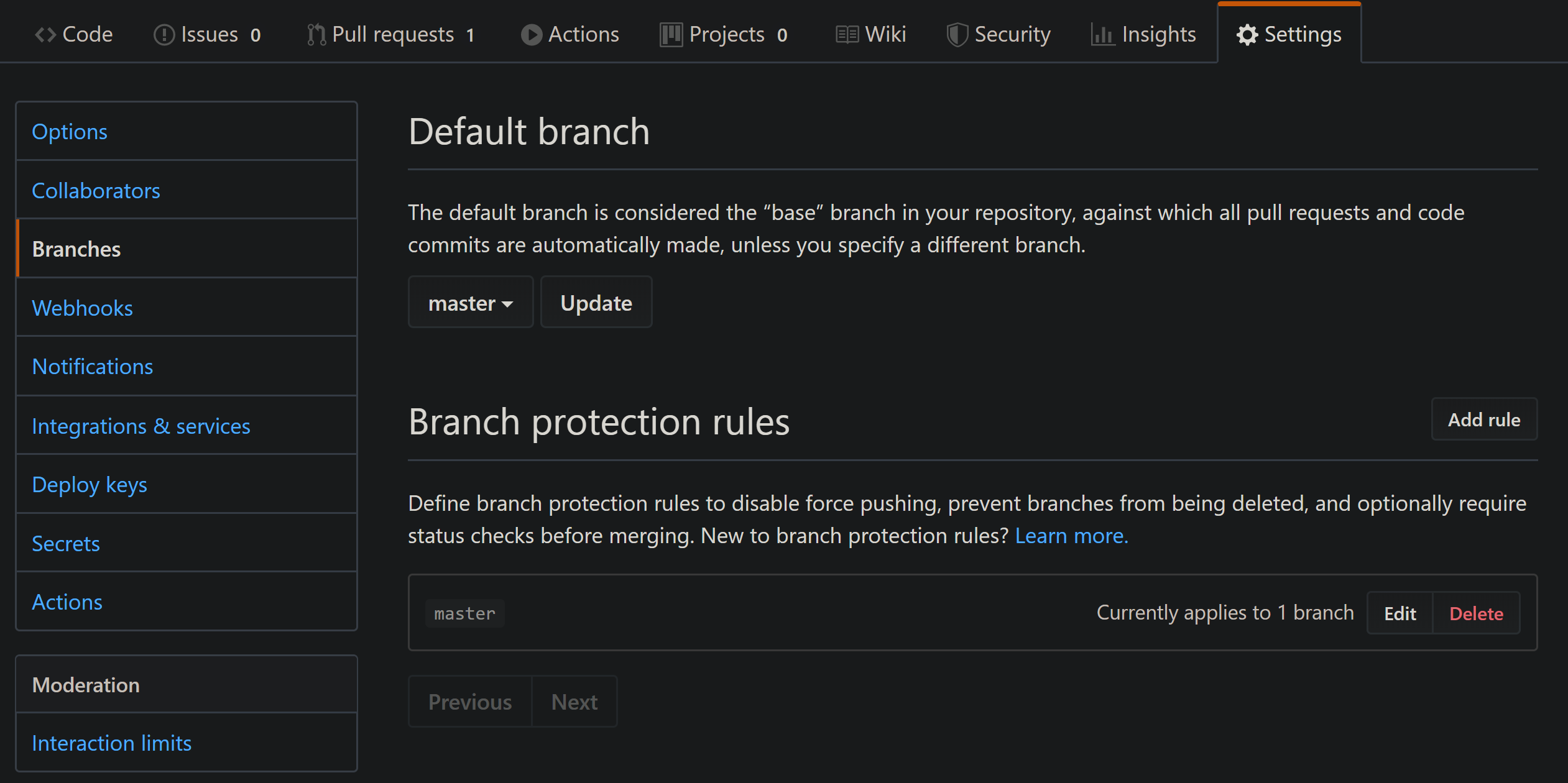
Nous devons définir une règle de protection de branche afin que le code malveillant (ou au moins le code qui ne passe pas nos tests) ne soit pas fusionné. Cliquez sur Add rule, et sous Branch name pattern, mettez votre branche protégée (master, dev ou celle que vous choisissez). Assurez-vous que Require status checks to pass before merging est coché, et vous pourrez choisir quelles vérifications doivent passer :
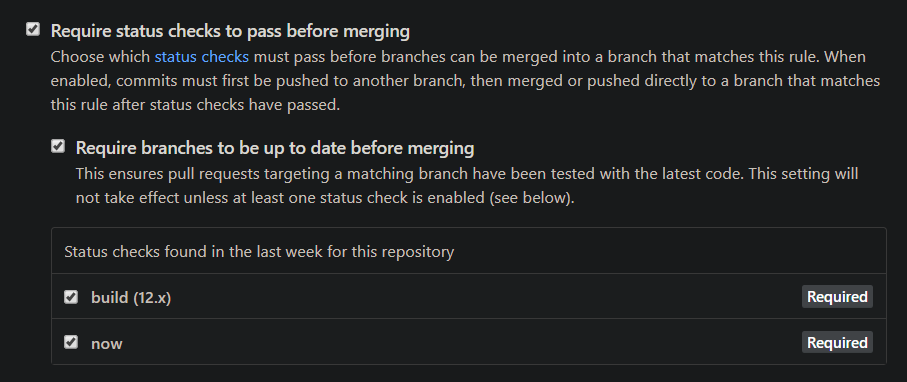
Cliquez sur Save changes ci-dessous, et vous êtes prêt à partir !
Merci d'avoir lu ! Cet article a été précédemment publié sur mon blog : dorshinar.me. Si vous souhaitez lire plus de contenu, vous pouvez consulter mon blog, cela signifierait beaucoup pour moi.
Si vous souhaitez me soutenir, vous pouvez 