

Article original : How to Setup a CI/CD Pipeline with GitHub Actions and AWS
Par Nyior Clement
Dans cet article, nous allons apprendre à configurer un pipeline CI/CD avec GitHub Actions et AWS. J'ai divisé le guide en trois parties pour vous aider à le suivre :
Tout d'abord, nous allons couvrir quelques termes importants afin que vous ne soyez pas perdu dans un tas de gros mots à la mode.
Ensuite, nous allons configurer l'intégration continue afin de pouvoir exécuter automatiquement les builds et les tests.
Et enfin, nous allons configurer la livraison continue afin de pouvoir déployer automatiquement notre code sur AWS.
D'accord, c'était beaucoup. Commençons par plonger dans chacun de ces termes afin que vous compreniez exactement ce que nous faisons ici.
Partie 1 : Démystifier les gros mots à la mode
La clé pour comprendre le titre de cet article réside dans la compréhension des termes CI/CD Pipeline, GitHub Actions et AWS.
Si vous avez déjà une bonne compréhension de ces termes, vous pouvez sauter directement à la partie 2.
Qu'est-ce qu'un pipeline CI/CD ?
Un pipeline CI/CD est simplement une pratique de développement. Il essaie de répondre à cette question : Comment pouvons-nous livrer des fonctionnalités de qualité à notre environnement de production plus rapidement ? En d'autres termes, comment pouvons-nous accélérer le processus de livraison des fonctionnalités sans compromettre la qualité ?
Comment le pipeline CI/CD nous aide-t-il à accélérer le processus de livraison des fonctionnalités, pourriez-vous demander ?
Le diagramme ci-dessous représente un cycle typique de livraison de fonctionnalités avec ou sans le pipeline CI/CD.
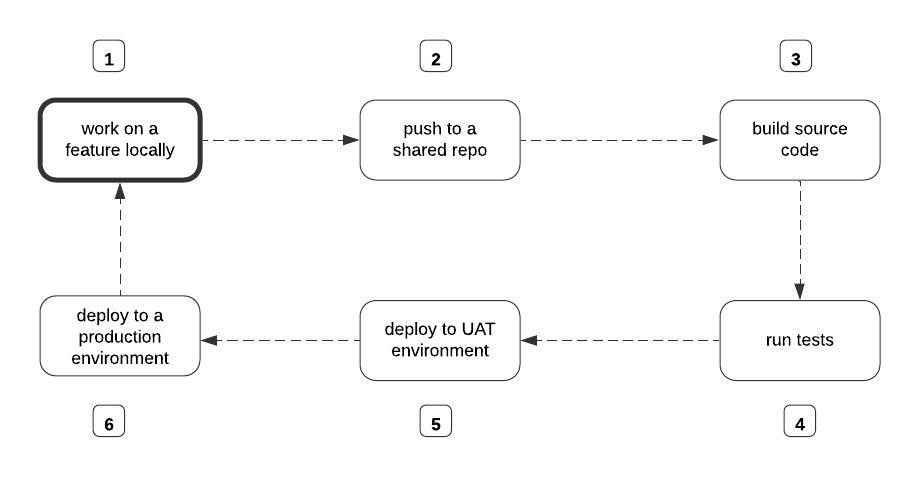 le processus de livraison des fonctionnalités. Source : Auteur
le processus de livraison des fonctionnalités. Source : Auteur
Sans le pipeline CI/CD, chaque étape du diagramme ci-dessus sera effectuée manuellement par le développeur. En essence, pour construire le code source, quelqu'un de votre équipe doit exécuter manuellement la commande pour initier le processus de construction. Même chose pour l'exécution des tests et le déploiement.
L'approche CI/CD est un changement radical par rapport à la méthode manuelle de faire les choses. Elle est entièrement basée sur le principe que nous pouvons accélérer raisonnablement le processus de livraison des fonctionnalités si nous automatisons les étapes 3 à 6 du diagramme ci-dessus.
Avec le pipeline CI/CD, nous mettons en place un mécanisme qui démarre automatiquement le processus de construction, exécute les tests, déploie dans l'environnement de test d'acceptation utilisateur (UAT) et enfin dans l'environnement de production chaque fois qu'un membre de l'équipe pousse son changement vers le dépôt partagé, par exemple.
L'intégration continue se produit chaque fois que le processus de construction est initié et que les tests sont exécutés sur un nouveau changement.
La livraison continue se produit lorsqu'un changement nouvellement intégré est automatiquement déployé dans l'environnement UAT, puis manuellement déployé dans l'environnement de production à partir de là.
Le déploiement continu se produit lorsqu'une mise à jour dans l'environnement UAT est automatiquement déployée dans l'environnement de production en tant que version officielle.
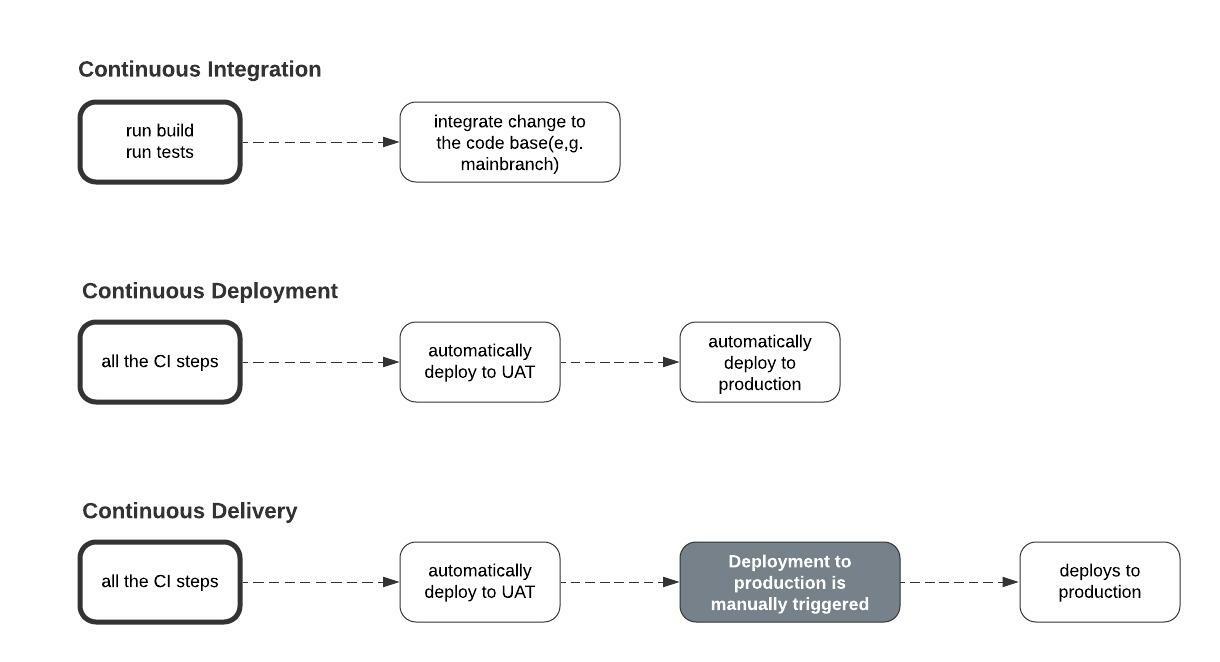 Intégration continue vs déploiement continu vs livraison continue. Source : Auteur
Intégration continue vs déploiement continu vs livraison continue. Source : Auteur
Note : Si le déploiement de l'environnement UAT vers l'environnement de production est initié manuellement, alors il s'agit d'une configuration d'intégration continue/livraison continue. Sinon, il s'agit d'une configuration d'intégration continue/déploiement continu.
Cependant, nous ne pouvons pas nous empêcher de demander, quelle est cette entité qui automatise les différentes phases du pipeline CI/CD ?
Il existe une variété d'outils que nous pouvons utiliser pour automatiser les étapes de construction, de test et de déploiement dans le pipeline CI/CD – par exemple, CI Circle, Travis CI, Jenkins, GitHub Actions, et ainsi de suite. Dans cet article, nous allons nous concentrer sur GitHub Actions.
Qu'est-ce que GitHub Actions ?
Pour rendre le terme GitHub Actions super compréhensible, je vais le simplifier à l'extrême.
Dans le pipeline CI/CD, GitHub Actions est l'entité qui automatise les tâches ennuyeuses. Pensez-y comme un plugin qui est inclus avec chaque dépôt GitHub que vous créez.
Le plugin existe sur votre dépôt pour exécuter toute tâche que vous lui demandez. Habituellement, vous spécifiez quelles tâches le plugin doit exécuter via un fichier de configuration YAML. Toute commande que vous ajoutez au fichier de configuration se traduira par quelque chose comme ceci en anglais simple :
"Hey GitHub Actions, chaque fois qu'une PR est ouverte sur la branche X, construis et teste automatiquement le nouveau changement. Et chaque fois qu'un nouveau changement est fusionné ou poussé vers la branche X, déploie ce changement sur le serveur Y."
Au cœur de GitHub Actions se trouvent cinq concepts : jobs, workflows, événements, actions et runners.
Jobs sont les tâches que vous commandez à GitHub Actions d'exécuter via le fichier de configuration YAML. Un job pourrait être quelque chose comme dire à GitHub Actions de construire votre code source, d'exécuter des tests ou de déployer le code qui a été construit sur un serveur distant.
Workflows sont essentiellement des processus automatisés qui contiennent un ou plusieurs jobs logiquement liés. Par exemple, vous pourriez mettre les jobs de construction et d'exécution des tests dans le même workflow, et le job de déploiement dans un workflow différent.
Rappelez-vous, nous avons mentionné que vous dites à GitHub Actions quel(s) job(s) exécuter via un fichier de configuration, n'est-ce pas ? GitHub Actions considère chaque fichier de configuration que vous placez dans un dossier de votre dépôt comme un workflow. Nous parlerons plus de ce dossier dans la partie suivante.
Donc, pour créer un workflow séparé pour le job de déploiement et ensuite un workflow différent qui combine les jobs de construction et de tests, vous devriez ajouter deux fichiers de configuration à votre dépôt. Mais si vous fusionnez les trois jobs en un seul workflow, alors vous n'aurez besoin d'ajouter qu'un seul fichier de configuration.
Événements sont littéralement les événements qui déclenchent l'exécution d'un job par GitHub Actions. Rappelez-vous, nous avons mentionné le passage des jobs à exécuter via un fichier de configuration ? Dans ce fichier de configuration, vous devriez également spécifier quand un job doit être exécuté.
Par exemple, est-ce sur PR vers main ? Est-ce sur push vers main ? Est-ce sur fusion vers main ? Un job ne peut être exécuté par une GitHub Action que lorsqu'un événement se produit.
D'accord, laissez-moi me corriger rapidement. Ce n'est pas toujours le cas qu'un événement doive se produire avant qu'un job puisse être exécuté. Vous pourriez également planifier des jobs.
Par exemple, dans votre fichier de configuration, au lieu de spécifier que l'événement qui devrait déclencher l'exécution, disons, du job de construction et de test, vous pourriez le planifier pour qu'il se produise à 2h du matin tous les jours. En fait, vous pourriez à la fois planifier un job et spécifier un événement pour ce même job.
Actions sont les commandes réutilisables que vous pouvez réutiliser dans votre fichier de configuration. Vous pouvez écrire vos actions personnalisées ou utiliser celles existantes.
Un runner est l'ordinateur distant que GitHub Actions utilise pour exécuter les jobs que vous lui demandez.
Par exemple, lorsque le job de construction et de test est déclenché en fonction d'un événement, GitHub Actions tirera votre code sur cet ordinateur et exécutera le job.
La même chose se produit dans le cas du job de déploiement. Le runner déclenche le déploiement du code construit sur un serveur distant que vous spécifiez. Dans notre cas, nous allons utiliser un service appelé AWS.
Qu'est-ce qu'AWS ?
AWS signifie Amazon Web Services. Il s'agit d'une plateforme appartenant à Amazon, et cette plateforme vous permet d'accéder à une large gamme de services de cloud computing.
Cloud computing – Je pensais que vous aviez dit pas de gros mots ? La plupart du temps, les entreprises et même les développeurs individuels construisent des applications simplement pour que d'autres personnes puissent les utiliser. Pour cette raison, ces applications doivent être disponibles sur l'internet.
Rendre une application accessible à certains utilisateurs cibles, idéalement, implique de télécharger cette application sur un ordinateur spécial qui fonctionne 24h/24 et 7j/7 et qui est super rapide.
Imaginez si c'était le cas que, avant de pouvoir rendre vos applications disponibles aux autres utilisateurs d'internet, vous deviez posséder et configurer un tel ordinateur. C'est tout à fait faisable, mais cela comporte beaucoup d'obstacles.
Par exemple, que se passe-t-il si vous voulez simplement tester l'application ? Vous devriez passer par tout le stress de la configuration d'une infrastructure matérielle juste pour les tests ? De plus, que se passe-t-il si vous voulez télécharger 1000 applications différentes ou si votre application commence à gérer 1 milliard de requêtes simultanées ? Les choses commencent à se compliquer.
Les plateformes de cloud computing comme AWS existent pour vous éviter tout ce stress. Ces plateformes ont déjà de nombreux ordinateurs spéciaux configurés et conservés dans des bâtiments appelés centres de données.
Au lieu de devoir configurer votre propre infrastructure matérielle à partir de zéro, elles vous permettent de télécharger votre application sur l'un de leurs ordinateurs préconfigurés via l'internet. En retour, vous payez un certain montant à ces plateformes.
En fait, certaines de ces plateformes ont des plans gratuits qui vous permettent de tester de petites applications. En plus de télécharger le code de votre application, certaines de ces plateformes vous permettent également d'héberger votre base de données et de stocker vos fichiers multimédias, parmi d'autres fonctionnalités.
Dans sa forme la plus simpliste, le cloud computing consiste principalement à stocker ou exécuter (parfois les deux) certaines choses sur l'ordinateur de quelqu'un d'autre, généralement via un réseau.
Donc, lorsque j'ai dit qu'AWS donne accès à une large gamme de services cloud, je voulais simplement dire qu'il fournit aux entreprises et aux particuliers un ordinateur spécial où ils pourraient télécharger leur code, leurs bases de données et leurs fichiers multimédias en tant que service.
D'accord, maintenant que nous comprenons pleinement les différentes parties de notre titre, nous allons maintenant le reformuler sous forme d'objectifs. Ces objectifs dicteront ensuite ce que les deux parties restantes de cet article contiendront.
Objectif 1 : Comment construire automatiquement et exécuter des tests unitaires lors d'un push ou d'une PR vers la branche principale avec GitHub Actions.
Objectif 2 : Comment déployer automatiquement sur AWS lors d'un push ou d'une PR vers la branche principale avec GitHub Actions.
Partie 2 : Intégration continue – Comment exécuter automatiquement les builds et les tests
Dans cette section, nous verrons comment configurer GitHub Actions pour exécuter automatiquement les builds et les tests lors d'un push ou d'une pull request vers la branche principale d'un dépôt.
Prérequis
- Un projet Django configuré localement avec au moins une vue qui retourne une réponse définie.
- Un cas de test écrit pour la ou les vues que vous avez définies.
J'ai créé un projet Django de démonstration que vous pouvez récupérer depuis ce dépôt :
git clone [https://github.com/Nyior/django-github-actions-aws](https://github.com/Nyior/django-github-actions-aws)
Après avoir téléchargé le code, créez un environnement virtuel et installez les dépendances via pip :
pip install -r requirements.txt
Note : Le projet contient déjà tous les fichiers que nous allons ajouter progressivement. Peut-être pourriez-vous encore télécharger et essayer de comprendre le contenu des fichiers au fur et à mesure. Le projet n'est certainement pas intéressant. Il est juste créé à des fins de démonstration.
Maintenant que vous avez un projet Django configuré localement, configurons GitHub Actions.
Comment configurer GitHub Actions
D'accord, nous avons donc notre projet configuré. Nous avons également un cas de test écrit pour la vue que nous avons définie, mais surtout, nous avons poussé notre changement brillant vers GitHub.
Le but est d'avoir GitHub déclencher une construction et exécuter nos tests chaque fois que nous poussons ou ouvrons une pull request sur main/master. Nous venons de pousser notre changement vers main, mais GitHub Actions n'a pas déclenché la construction ou exécuté nos tests.
Pourquoi pas ? Parce que nous n'avons pas encore défini de workflow. Rappelez-vous, un workflow est l'endroit où nous spécifions les jobs que nous voulons que GitHub Actions exécute.
En fait, Nyior, comment as-tu su qu'aucun build n'a été déclenché et, par extension, qu'aucun workflow n'a été défini ? Chaque dépôt GitHub a un onglet Action. Si vous naviguez vers cet onglet, vous saurez si un dépôt a un workflow défini ou non.
Comment ? Voir les images ci-dessous.
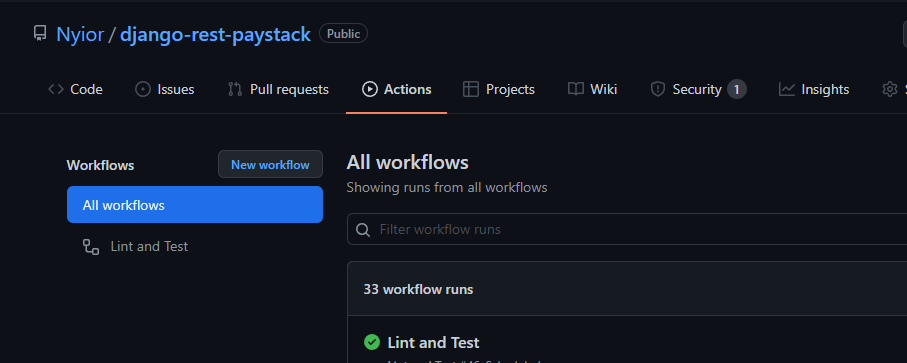 Un dépôt GitHub avec un workflow défini
Un dépôt GitHub avec un workflow défini
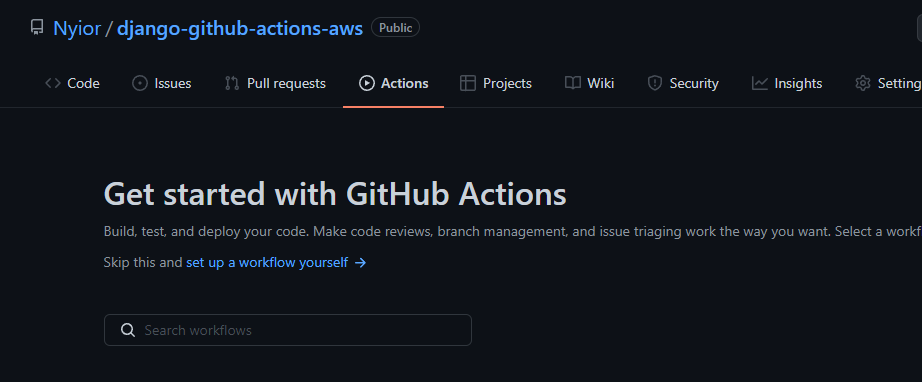 Un dépôt GitHub sans workflow défini
Un dépôt GitHub sans workflow défini
Le premier dépôt de la première image a un workflow défini nommé 'Lint and Test'. Le deuxième dépôt de la deuxième image n'a pas de workflow – c'est pourquoi vous ne voyez pas de liste avec l'en-tête 'All Workflows' comme c'est le cas avec le premier dépôt.
Oh d'accord, maintenant je comprends. Alors comment définir un workflow sur mon dépôt ?
- Créez un dossier nommé
.githubà la racine de votre répertoire de projet. - Créez un dossier nommé
workflowsdans le répertoire.github: C'est ici que vous créerez tous vos fichiers YAML. - Créons notre premier workflow qui contiendra nos jobs de build et de test. Nous le faisons en créant un fichier avec une extension
.yml. Nommons ce fichierbuild_and_test.yml - Ajoutez le contenu ci-dessous dans le fichier
yamlque vous venez de créer :
name: Build and Test
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python Environment
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install Dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Run Tests
run: |
python manage.py test
Comprenons chaque ligne du fichier ci-dessus.
name: Build and TestC'est le nom de notre workflow. Lorsque vous naviguez vers l'onglet actions, chaque workflow que vous définissez sera identifié par le nom que vous lui donnez ici dans cette liste.on:C'est ici que vous spécifiez les événements qui doivent déclencher l'exécution de notre workflow. Dans notre fichier de configuration, nous lui avons passé deux événements. Nous avons spécifié la branche main comme branche cible.jobs:Rappelez-vous, un workflow est simplement une collection de jobs.test:C'est le nom du job que nous avons défini dans ce workflow. Vous pourriez le nommer n'importe quoi, vraiment. Remarquez qu'il est le seul job et que le job de build n'est pas là ? Eh bien, c'est du code Python, donc aucune étape de build n'est requise. C'est pourquoi nous n'avons pas défini le job de build.runs-onGitHub fournit des runners Ubuntu Linux, Microsoft Windows et macOS pour exécuter vos workflows. C'est ici que vous spécifiez le type de runner que vous souhaitez utiliser. Dans notre cas, nous utilisons le runner Ubuntu Linux.- Un job est composé d'une série d'étapes qui sont généralement exécutées séquentiellement sur le même runner. Dans notre fichier ci-dessus, chaque étape est marquée par un tiret.
namereprésente le nom de l'étape. Chaque étape peut être soit un script shell qui est exécuté, soit uneaction. Vous définissez une étape avecusessi elle exécute uneaction, ou vous définissez une étape avecrunsi elle exécute un script shell.
Maintenant que vous avez défini un workflow en ajoutant le fichier de configuration dans le dossier désigné, vous pouvez commiter et pousser votre changement vers votre dépôt distant.
Si vous naviguez vers l'onglet Actions de votre dépôt distant, vous devriez voir un workflow avec le nom Build and Test (le nom que nous lui avons donné) listé là.
Partie 3 : Livraison continue – Comment déployer automatiquement notre code sur AWS
Dans cette section, nous verrons comment faire en sorte que GitHub Actions déploie automatiquement notre code sur AWS lors d'un push ou d'une pull request vers la branche principale. AWS offre une large gamme de services. Pour ce tutoriel, nous allons utiliser un service de calcul appelé Elastic Beanstalk.
Service de calcul ? Elastic Beanstalk ? Allez, oh non :(
Pas de soucis, détendez-vous, vous allez comprendre. Rappelez-vous que nous avons mentionné que le cloud computing consiste à stocker et exécuter certaines choses sur l'ordinateur de quelqu'un d'autre via l'internet, n'est-ce pas – certaines choses ?
Oui. Par exemple, nous pouvons stocker et exécuter du code source ou nous pouvons simplement stocker des fichiers multimédias. Amazon le sait, et par conséquent, leur infrastructure cloud englobe une pléthore de catégories de services. Chaque catégorie de service nous permet de faire une certaine chose parmi les certaines choses que nous pouvons faire.
Par exemple, il existe une catégorie de service qui permet le téléchargement et l'exécution de codes sources qui alimentent nos applications (Service de calcul). Il existe la catégorie de service qui nous permet de persister nos fichiers multimédias (Service de stockage). Ensuite, il y a la catégorie de service qui nous permet de gérer nos bases de données (Service de base de données).
Chaque catégorie de service est composée d'un ou plusieurs services. Chaque service d'une catégorie nous présente simplement une manière différente de résoudre le problème que la catégorie à laquelle il appartient aborde.
Par exemple, chaque service de la catégorie de calcul nous fournit une approche différente pour déployer et exécuter notre code d'application sur le cloud – un problème, différentes approches. Elastic Beanstalk est l'un des services de la catégorie de calcul. D'autres sont, sans s'y limiter, EC2 et Lambda.
Amazon S3 est l'un des services de la catégorie de stockage. Et Amazon RDS est l'un des services de la catégorie de base de données.
Espérons que vous comprenez maintenant ce que je veux dire par "nous allons utiliser un service de calcul appelé Elastic Beanstalk." Parmi tous les services de calcul, pourquoi Elastic Beanstalk ? Eh bien, parce que c'est l'un des plus faciles à utiliser.
Cela étant dit, configurons des trucs <3
Pour des raisons de brièveté, nous optons pour la configuration de livraison continue. De plus, nous allons avoir un seul environnement de déploiement qui servira d'environnement UAT.
Pour vous aider à avoir une vue d'ensemble, en résumé, voici comment notre configuration de déploiement va fonctionner : lors d'un push ou d'une pull request vers main, GitHub Actions testera et téléchargera notre code source vers Amazon S3. Le code est ensuite tiré d'Amazon S3 vers notre environnement Elastic Beanstalk. Imaginez le flux de cette manière :
GitHub -> Amazon S3 -> Elastic Beanstalk
Pourquoi ne poussons-nous pas directement vers Elastic Beanstalk, pourriez-vous demander ?
La seule autre façon dont nous pourrions télécharger du code directement vers une instance Elastic Beanstalk avec notre configuration actuelle, c'est si nous utilisions le AWS Elastic Beanstalk CLI (EB CLI).
L'utilisation de l'EB CLI nécessite l'exécution de certaines commandes shell qui nécessiteraient ensuite que nous répondions avec certaines entrées.
Maintenant, si nous déployons depuis notre machine locale vers Elastic Beanstalk, lorsque nous exécutons les commandes EB CLI, nous serons là pour taper les réponses requises. Mais avec notre configuration actuelle, ces commandes seraient exécutées sur les GitHub Runners. Nous ne serions pas là pour fournir les réponses requises. L'EB CLI n'est pas l'outil de déploiement le plus facile pour notre cas d'utilisation.
Avec l'approche que nous avons choisie, nous exécuterions une commande shell qui télécharge notre code vers S3, puis une autre commande qui tire le code téléchargé vers notre instance Elastic Beanstalk. Ces commandes, lorsqu'elles sont exécutées, ne nécessitent pas que nous soumettions certaines réponses. Avoir l'étape Amazon S3 est la manière la plus facile de procéder.
Pour mettre en œuvre notre approche et avoir notre code déployé sur Elastic Beanstalk, suivez les étapes ci-dessous :
Étape 1 : Configurer un compte AWS
Créez un IAM. Pour garder les choses simples, lors de l'ajout des permissions, ajoutez simplement "Administrator Access" à l'utilisateur (ceci comporte quelques pièges de sécurité, cependant). Pour accomplir cela, suivez les étapes des modules 1 et 2 de ce guide.
À la fin, assurez-vous de récupérer et de conserver votre clé secrète AWS et vos clés d'accès. Nous en aurons besoin dans les sections suivantes.
Maintenant que nous avons un compte AWS correctement configuré, il est temps de configurer notre environnement Elastic Beanstalk.
Étape 2 : Configurer votre environnement Elastic Beanstalk
Une fois connecté à votre compte AWS, suivez les étapes suivantes pour configurer votre environnement Elastic Beanstalk.
Tout d'abord, recherchez "elastic beanstalk" dans le champ de recherche comme montré dans l'image ci-dessous. Ensuite, cliquez sur le service Elastic Beanstalk.
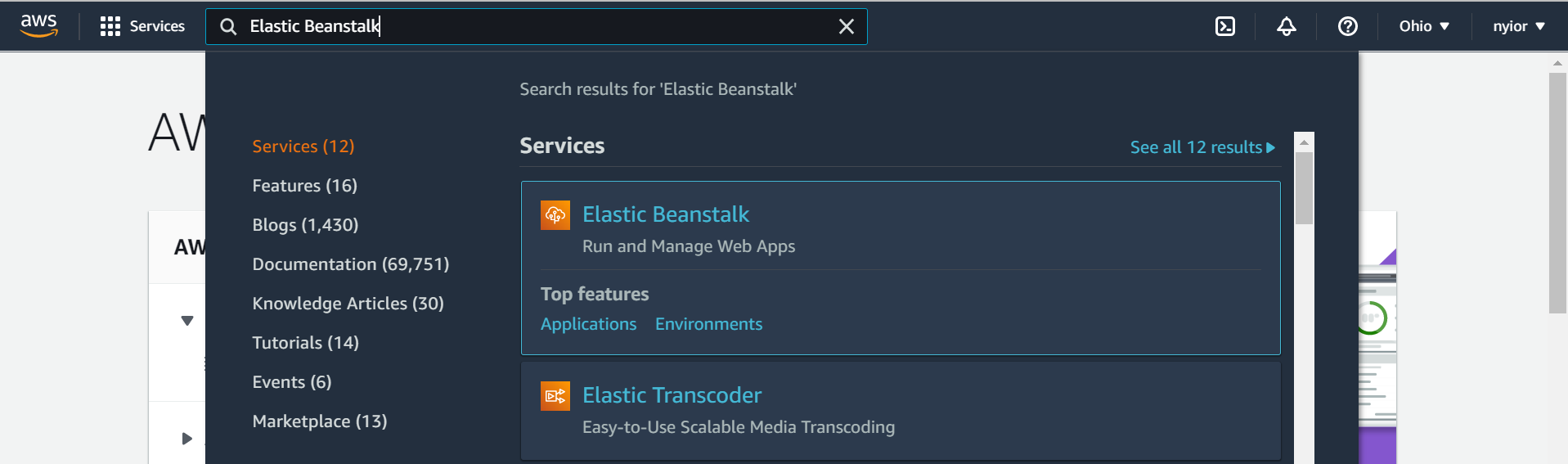 recherche d'elastic beanstalk.
recherche d'elastic beanstalk.
Une fois que vous avez cliqué sur le service Elastic Beanstalk dans l'étape précédente, vous serez redirigé vers la page montrée dans l'image ci-dessous. Sur cette page, cliquez sur l'invite "Create a New Environment". Assurez-vous de sélectionner "Web server environment" dans l'étape suivante.
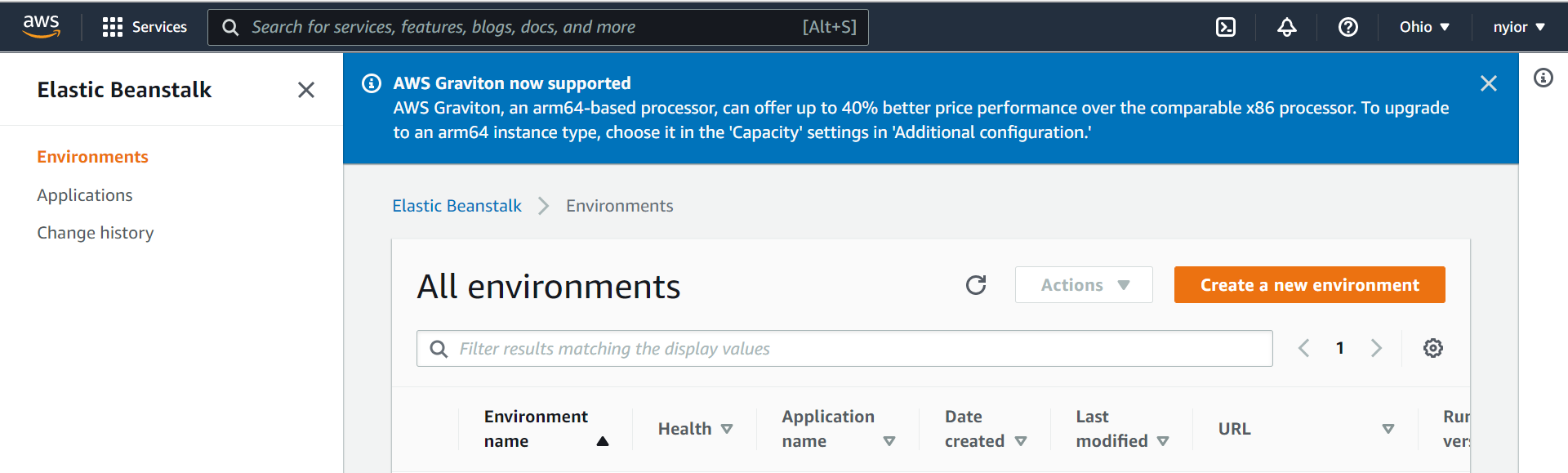 création d'un environnement
création d'un environnement
Après avoir sélectionné "Web server environment" dans la page précédente, vous serez redirigé vers la page montrée dans les images ci-dessous.
Sur cette page, soumettez un nom d'application, un nom d'environnement, et sélectionnez également une plateforme. Pour ce tutoriel, nous utilisons la plateforme Python.
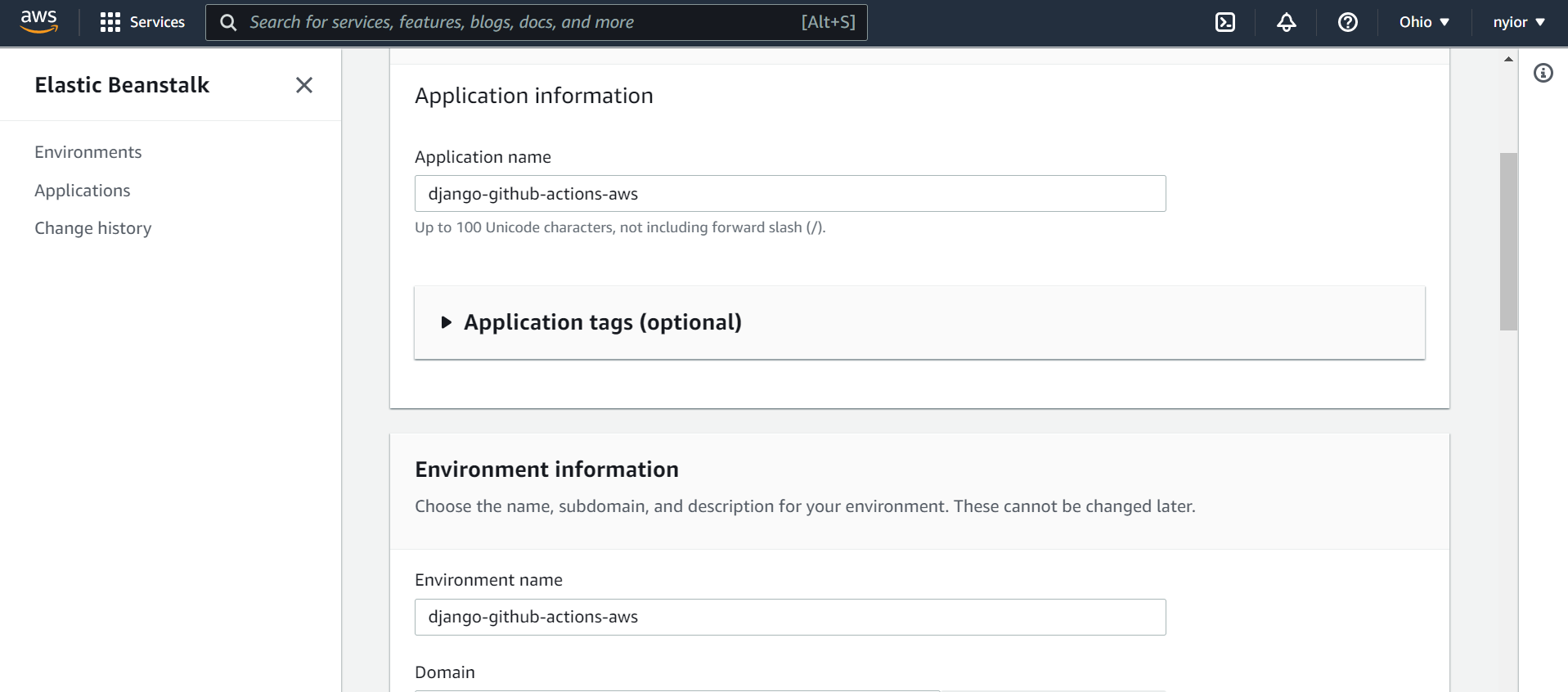 un nom d'application et un nom d'environnement
un nom d'application et un nom d'environnement
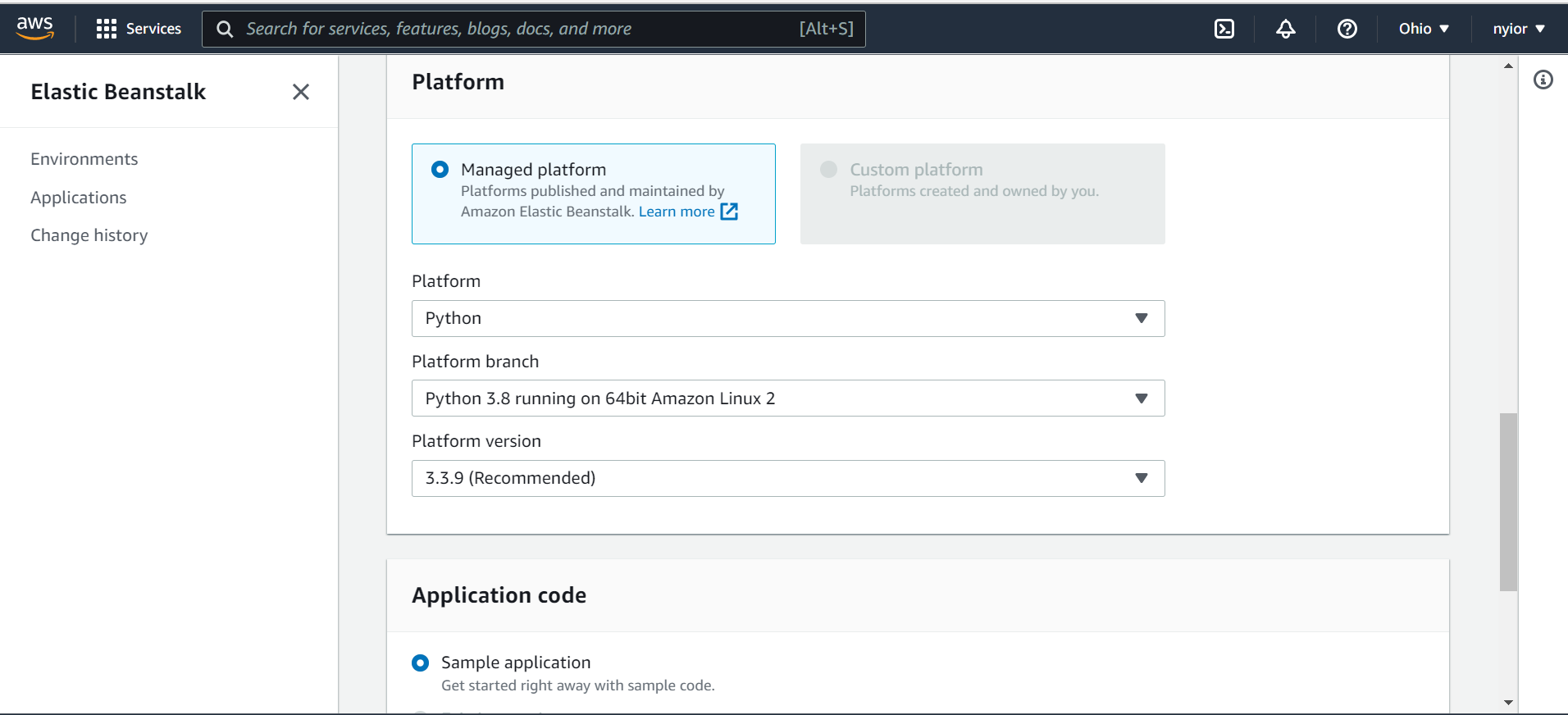 sélection d'une plateforme
sélection d'une plateforme
Une fois que vous avez soumis le formulaire rempli dans l'étape précédente, après un certain temps, votre application et son environnement associé seront créés. Vous devriez voir les noms que vous avez soumis affichés dans la barre latérale de gauche.
Récupérez le nom de l'application et le nom de l'environnement. Nous en aurons besoin dans les étapes suivantes.
Maintenant que nous avons notre environnement Elastic Beanstalk entièrement configuré, il est temps de configurer GitHub Actions pour déclencher le déploiement automatique vers AWS lors d'un push ou d'une pull request vers main.
Étape 3 : Configurer votre projet pour Elastic Beanstalk
Par défaut, Elastic Beanstalk recherche un fichier nommé application.py dans notre projet. Il utilise ce fichier pour exécuter notre application, mais nous n'avons pas ce fichier dans notre projet. N'est-ce pas ? Nous devons dire à Elastic Beanstalk d'utiliser le fichier wsgi.py dans notre projet pour exécuter notre application à la place. Pour ce faire, suivez l'étape suivante :
Créez un dossier nommé .ebextensions dans votre répertoire de projet. Dans ce dossier, créez un fichier de configuration. Vous pouvez le nommer comme vous le souhaitez. J'ai nommé le mien eb.config. Ajoutez le contenu ci-dessous à votre fichier de configuration :
option_settings:
aws:elasticbeanstalk:container:python:
WSGIPath: django_github_actions_aws.wsgi:application
Après avoir complété l'étape ci-dessus, votre répertoire de projet devrait maintenant ressembler à celui de l'image ci-dessous :
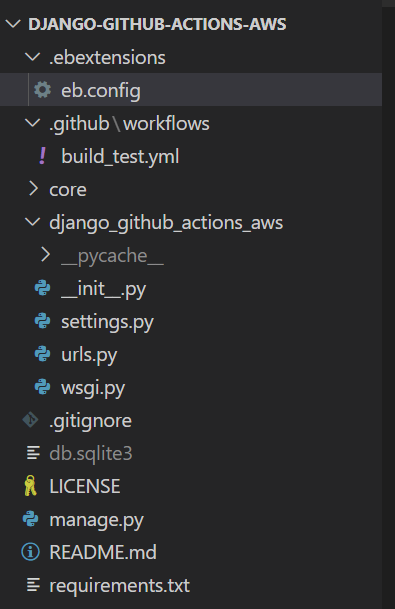 structure du projet de démonstration
structure du projet de démonstration
Une dernière chose que vous devez faire dans cette section est d'aller dans votre fichier settings.py et de mettre à jour le paramètre ALLOWED_HOSTS à all :
ALLOWED_HOSTS = ['*']
Notez que l'utilisation du wildcard présente des inconvénients majeurs en termes de sécurité. Nous l'utilisons ici uniquement à des fins de démonstration.
Maintenant que nous avons terminé la configuration de notre projet pour Elastic Beanstalk, il est temps de mettre à jour notre fichier de workflow.
Étape 4 : Mettre à jour votre fichier de workflow
Il y a cinq informations importantes dont nous avons besoin pour compléter cette étape : le nom de l'application, le nom de l'environnement, l'ID de la clé d'accès, la clé d'accès secrète et la région du serveur (après la connexion, vous pouvez récupérer la région dans la section la plus à droite de la barre de navigation).
Parce que l'ID de la clé d'accès et la clé d'accès secrète sont des données sensibles, nous allons les cacher quelque part dans notre dépôt et y accéder dans notre fichier de workflow.
Pour ce faire, rendez-vous dans l'onglet des paramètres de votre dépôt, puis cliquez sur secrets comme montré dans l'image ci-dessous. Là, vous pouvez créer vos secrets sous forme de paires clé-valeur.
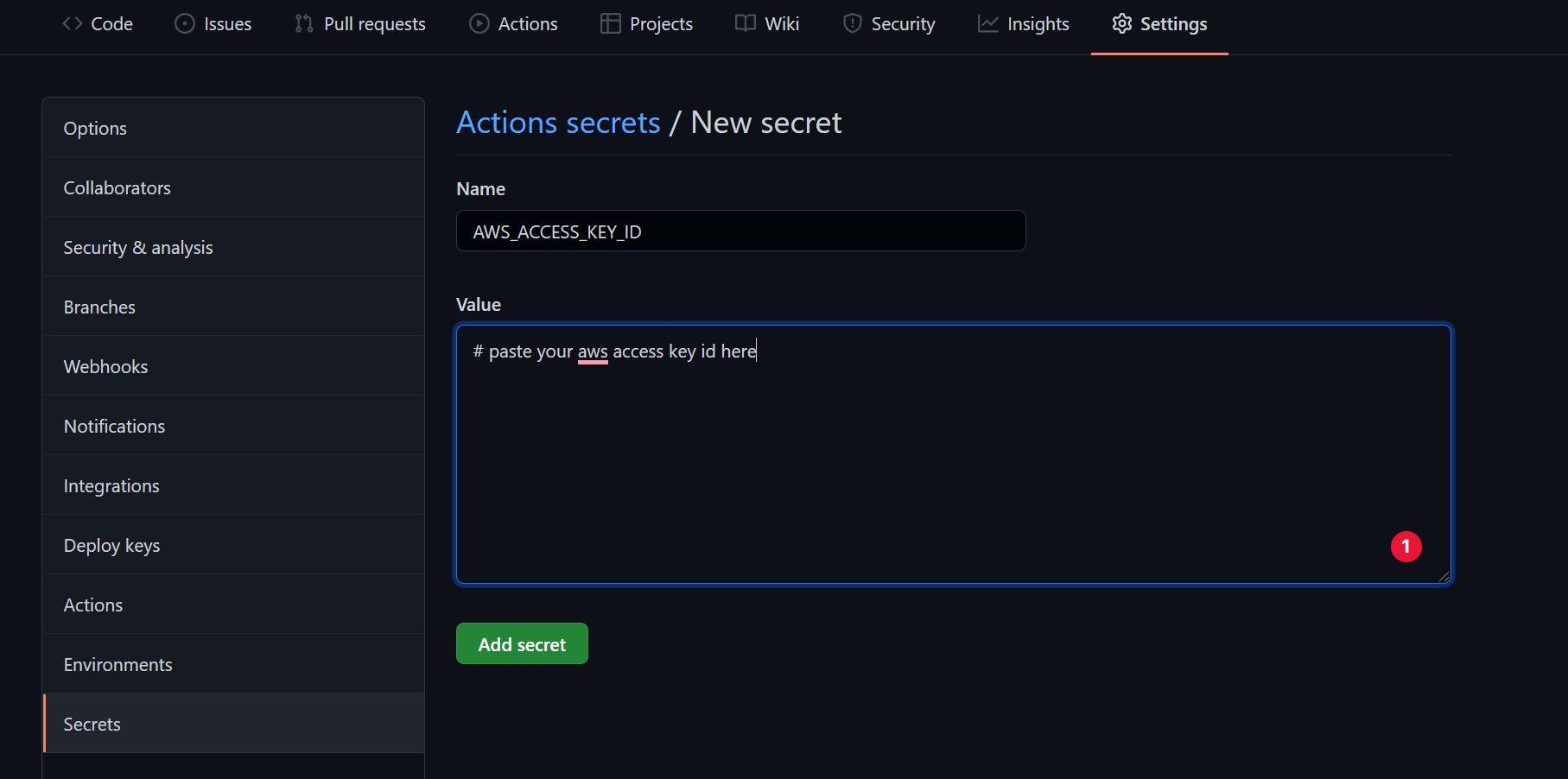 intégration de données secrètes dans votre dépôt
intégration de données secrètes dans votre dépôt
Ensuite, ajoutez le job de déploiement à la fin de votre fichier de workflow existant :
deploy:
needs: [test]
runs-on: ubuntu-latest
steps:
- name: Checkout source code
uses: actions/checkout@v2
- name: Generate deployment package
run: zip -r deploy.zip . -x '*.git*'
- name: Deploy to EB
uses: einaregilsson/beanstalk-deploy@v20
with:
// Remember the secrets we embedded? this is how we access them
aws_access_key: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws_secret_key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
// Replace the values here with your names you submitted in one of
// The previous sections
application_name: django-github-actions-aws
environment_name: django-github-actions-aws
// The version number could be anything. You can find a dynamic way
// Of doing this.
version_label: 12348
region: "us-east-2"
deployment_package: deploy.zip
needs indique simplement à GitHub Actions de ne commencer à exécuter le job deployment qu'après que le job test a été complété avec un statut de réussite.
L'étape Deploy to EB utilise une action existante, einaregilsson/beanstalk-deploy@v20. Rappelez-vous comment nous avons dit que les actions sont des applications réutilisables qui prennent en charge certaines tâches fréquemment répétées pour nous ? einaregilsson/beanstalk-deploy@v20 est l'une de ces actions.
Pour renforcer ce qui précède, rappelez-vous que notre déploiement devait passer par les étapes suivantes : GitHub -> Amazon S3 -> Elastic Beanstalk.
Cependant, tout au long de ce tutoriel, nous n'avons pas fait de configuration Amazon S3. De plus, dans notre fichier de workflow, nous n'avons pas téléchargé vers un bucket S3 ni tiré d'un bucket S3 vers notre environnement Elastic Beanstalk.
Normalement, nous devrions faire tout cela, mais nous ne l'avons pas fait ici – parce que sous le capot, l'action einaregilsson/beanstalk-deploy@v20 fait tout le travail difficile pour nous. Vous pouvez également créer votre propre action qui prend en charge certaines tâches répétitives et la rendre disponible aux autres développeurs via le GitHub Marketplace.
Maintenant que vous avez mis à jour votre fichier de workflow localement, vous pouvez ensuite commiter et pousser ce changement vers votre dépôt distant. Vos jobs s'exécuteront et votre code sera déployé sur l'instance Elastic Beanstalk que vous avez créée. Et c'est tout. Nous avons terminé >>>
Conclusion
Wow ! C'était vraiment long, n'est-ce pas ? En résumé, j'ai expliqué ce que signifient les termes GitHub Actions, CI/CD Pipeline et AWS. De plus, nous avons vu comment configurer GitHub Actions pour déployer automatiquement notre code sur une instance Elastic Beanstalk sur AWS.
Si vous aimez ce travail et souhaitez rester à jour sur les futurs articles que je publierai, connectons-nous sur Twitter, Linkedin, ou GitHub. J'utilise ces canaux pour partager ce sur quoi je travaille, immédiatement après les avoir publiés.
Crédits :
Image de couverture : www.freepik.com