

Article original : How to Set Up Continuous Integration for a Monorepo Using Buildkite
Par subash adhikari
Un monorepo est un seul dépôt qui contient tout le code et plusieurs projets dans un seul dépôt Git.
Cette configuration est assez agréable à utiliser en raison de sa flexibilité et de sa capacité à gérer divers services et frontends dans un seul dépôt. Elle élimine également le tracas de suivre les changements dans plusieurs dépôts et de mettre à jour les dépendances à mesure que les projets changent.
D'autre part, les monorepos viennent également avec leurs propres défis, spécifiquement en ce qui concerne l'intégration continue. À mesure que les sous-projets individuels au sein du monorepo changent, nous devons identifier quels sous-projets ont changé pour les construire et les déployer.
Cet article servira de guide étape par étape pour :
- Configurer l'intégration continue pour les monorepos dans Bulidkite.
- Déployer des agents Buildkite sur des instances AWS EC2 avec autoscaling.
- Configurer GitHub pour déclencher des pipelines CI Buildkite.
- Configurer Buildkite pour déclencher les pipelines appropriés lorsque des sous-projets au sein d'un monorepo changent.
- Automatiser tout ce qui précède en utilisant des scripts bash.
Prérequis
- Un compte AWS pour déployer les agents Buildkite.
- Configurer AWS CLI pour communiquer avec le compte AWS.
- Un compte Buildkite pour créer des pipelines d'intégration continue.
- Un compte GitHub pour héberger le code source du monorepo.
Le code source complet est disponible dans buildkite-monorepo sur GitHub.
Configuration du projet
Le workflow Buildkite se compose de Pipelines et d'étapes. Les conteneurs de niveau supérieur pour modéliser et définir les workflows sont appelés Pipelines. Les étapes exécutent des tâches ou des commandes individuelles.
Le diagramme suivant liste les pipelines que nous configurons, leurs déclencheurs associés et chaque étape que le pipeline exécute.

Workflow de Pull Request
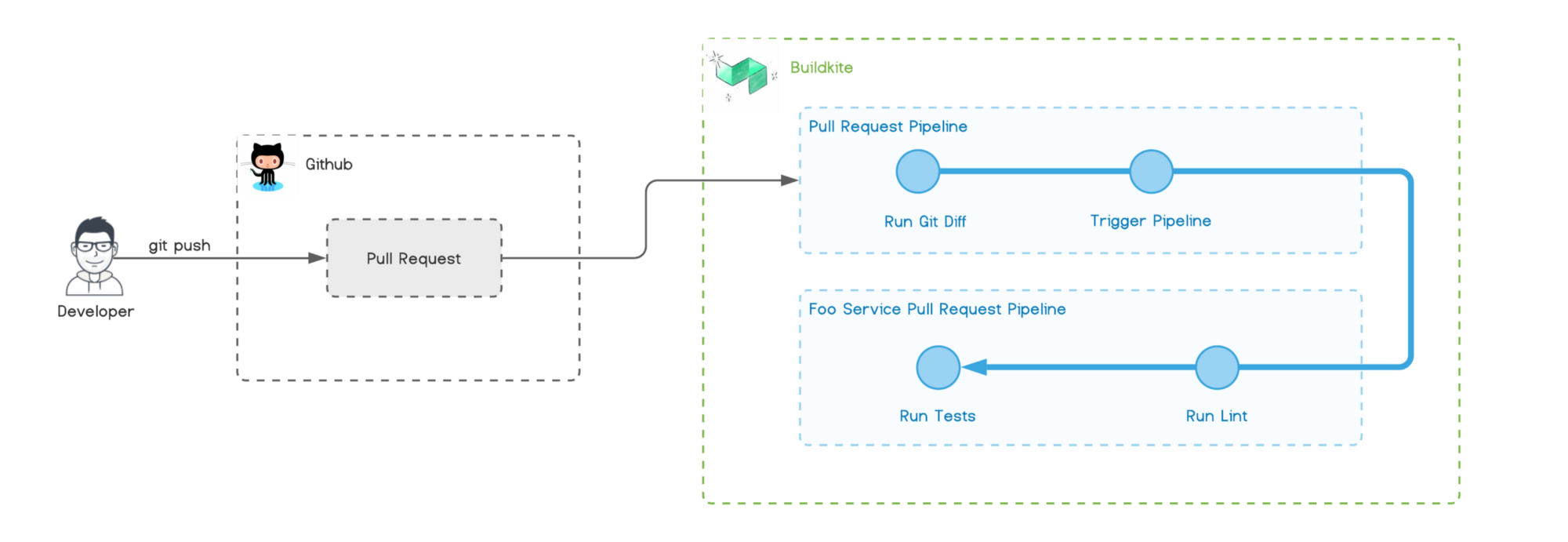
Le diagramme ci-dessus visualise le workflow pour le pipeline de Pull Request.
La création d'une nouvelle Pull Request dans GitHub déclenche le pipeline pull-request dans Buildkite. Ce pipeline exécute ensuite git diff pour identifier quels dossiers (projets) au sein du monorepo ont changé.
S'il détecte des changements, il déclenchera dynamiquement le pipeline de Pull Request approprié défini pour ce projet. Buildkite rapporte l'état de chaque pipeline à GitHub status check.
Workflow de Merge
La Pull Request est fusionnée lorsque toutes les vérifications de statut dans GitHub passent. La fusion de la Pull Request déclenche le pipeline merge dans Buildkite.

Similaire au pipeline précédent, le pipeline de merge identifie les projets qui ont changé et déclenche le pipeline deploy correspondant. Le pipeline de déploiement déploie initialement les changements dans l'environnement de staging.
Une fois le déploiement dans l'environnement de staging terminé, le déploiement en production est libéré manuellement.
Structure finale du projet
├── .buildkite
│ ├── diff
│ ├── merge.yml
│ ├── pipelines
│ │ ├── deploy.json
│ │ ├── merge.json
│ │ └── pull-request.json
│ └── pull-request.yml
├── bar-service
│ ├── .buildkite
│ │ ├── deploy.yml
│ │ ├── merge.yml
│ │ └── pull-request.yml
│ └── bin
│ └── deploy
├── bin
│ ├── create-pipeline
│ ├── create-secrets-bucket
│ ├── deploy-ci-stack
│ └── stack-config
└── foo-service
├── .buildkite
│ ├── deploy.yml
│ ├── merge.yml
│ └── pull-request.yml
└── bin
└── deploy
Configurer le projet
Créez un nouveau projet Git et poussez-le sur GitHub. Exécutez les commandes suivantes dans le CLI.
mkdir buildkite-monorepo-example
cd buildkite-monorepo-example
git init
echo node_modules/ > .gitignore
git add .
git commit -m "initialiser le dépôt"
git remote add origin <YOUR_GITHUB_REPO_URL>
git push origin master

Configurer l'infrastructure Buildkite
- Créez un répertoire bin avec quelques scripts exécutables à l'intérieur.
mkdir bin
cd bin
touch create-pipeline create-secrets-bucket deploy-ci-stack
chmod +x ./*
- Copiez le contenu suivant dans
create-secrets-bucket.
#!/bin/bash
set -eou pipefail
CURRENT_DIR=$(pwd)
ROOT_DIR="$( dirname "${BASH_SOURCE[0]}" )"/..
BUCKET_NAME="buildkite-secrets-adikari"
KEY="id_rsa_buildkite"
echo "création du bucket $BUCKET_NAME.."
aws s3 mb s3://$BUCKET_NAME
# Générer une clé SSH
ssh-keygen -t rsa -b 4096 -f $KEY -N ''
# Copier les clés SSH dans le bucket S3
aws s3 cp --acl private --sse aws:kms $KEY "s3://$BUCKET_NAME/private_ssh_key"
aws s3 cp --acl private --sse aws:kms $KEY.pub "s3://$BUCKET_NAME/public_key.pub"
if [[ "$OSTYPE" == "darwin"* ]]; then
pbcopy < id_rsa_buildkite.pub
echo "contenu de la clé publique copié dans le presse-papiers."
else
cat id_rsa_buildkite.pub
fi
# Déplacer les clés SSH dans le répertoire ~/.ssh
mv ./$KEY* ~/.ssh
chmod 600 ~/.ssh/$KEY
chmod 644 ~/.ssh/$KEY.pub
cd $CURRENT_DIR
Le script ci-dessus crée un bucket S3 qui est utilisé pour stocker les clés ssh. Buildkite utilise cette clé pour se connecter au dépôt Github. Le script génère également une clé ssh et définit ses permissions correctement.
Exécuter le script

Le script copie les clés publique et privée générées dans le dossier ~/.ssh. Ces clés peuvent être utilisées plus tard pour se connecter en SSH à l'instance EC2, exécutant l'agent Buildkite pour le débogage.
Ensuite, vérifiez que le bucket existe et que les clés sont présentes dans le nouveau bucket S3.

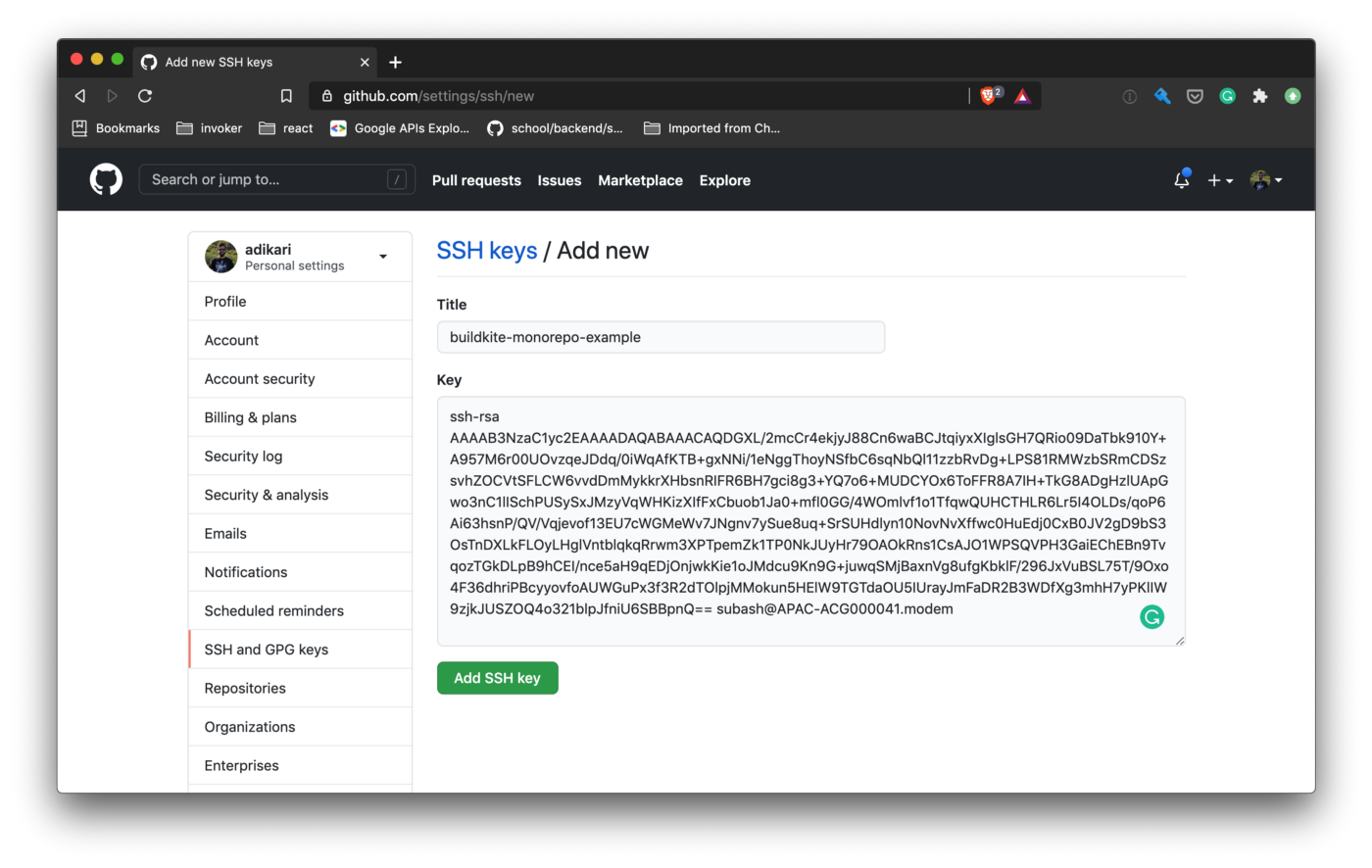
Accédez à https://github.com/settings/keys, ajoutez une nouvelle clé SSH, puis collez le contenu de id_rsa_buildkite.pub.
Déployer la pile Cloudformation AWS Elastic CI
Les gens de Buildkite ont créé la Elastic CI Stack pour AWS, qui crée un cluster privé d'agents Buildkite avec autoscaling dans AWS. Déployons l'infrastructure dans notre compte AWS.
Créez un nouveau fichier bin/deploy-ci-stack et copiez le contenu du script suivant.
#!/bin/bash
set -euo pipefail
[ -z $BUILDKITE_AGENT_TOKEN ] && { echo "BUILDKITE_AGENT_TOKEN n'est pas défini."; exit 1;}
CURRENT_DIR=$(pwd)
ROOT_DIR="$( dirname "${BASH_SOURCE[0]}" )"/..
PARAMETERS=$(cat ./bin/stack-config | envsubst)
cd $ROOT_DIR
echo "téléchargement du modèle de pile elastic ci.."
curl -s https://s3.amazonaws.com/buildkite-aws-stack/latest/aws-stack.yml -O
aws cloudformation deploy \
--capabilities CAPABILITY_NAMED_IAM \
--template-file ./aws-stack.yml \
--stack-name "buildkite-elastic-ci" \
--parameter-overrides $PARAMETERS
rm -f aws-stack.yml
cd $CURRENT_DIR
Vous pouvez obtenir le BUILDKITE_AGENT_TOKEN à partir de l'onglet Agents dans la console de Buildkite.

Ensuite, créez un nouveau fichier appelé bin/stack-config. La configuration dans ce fichier remplace les paramètres de Cloudformation. La liste complète des paramètres est disponible dans le modèle Cloudformation utilisé par Elastic CI.
À la ligne 2, remplacez le nom du bucket par le bucket créé précédemment.
BuildkiteAgentToken=$BUILDKITE_AGENT_TOKEN
SecretsBucket=buildkite-secrets-adikari
InstanceType=t2.micro
MinSize=0
MaxSize=3
ScaleUpAdjustment=2
ScaleDownAdjustment=-1
Ensuite, exécutez le script dans le CLI pour déployer la pile Cloudformation.
./bin/deploy-ci-stack
Le script prendra un certain temps pour se terminer. Ouvrez la console AWS Cloudformation pour voir la progression.

La pile Cloudformation aurait créé un groupe d'autoscaling que Buildkite utilisera pour lancer des instances EC2. Les agents Buildkite et les builds s'exécutent à l'intérieur de ces instances EC2.

Créer des pipelines de build dans Bulidkite
À ce stade, nous avons l'infrastructure prête qui est nécessaire pour exécuter Buildkite. Ensuite, nous configurons Buildkite et créons quelques pipelines.
Créez un jeton d'accès nAPI à https://buildkite.com/user/api-access-tokens et définissez la portée sur write_builds, read_pipelines, et write_pipelines. Plus d'informations sur les jetons d'agent sont dans ce document.
Assurez-vous que BUILDKITE_API_TOKEN est défini dans l'environnement. Utilisez soit dotenv soit exportez-le dans l'environnement avant d'exécuter le script.
Copiez le contenu du script suivant dans bin/create-pipeline. Les pipelines peuvent être créés manuellement dans la console Buildkite, mais il est toujours préférable d'automatiser et de créer une infrastructure reproductible.
#!/bin/bash
set -euo pipefail
export SERVICE="."
export PIPELINE_TYPE=""
export REPOSITORY=git@github.com:adikari/buildkite-docker-example.git
CURRENT_DIR=$(pwd)
ROOT_DIR="$( dirname "${BASH_SOURCE[0]}" )"/..
STATUS_CHECK=false
BUILDKITE_ORG_SLUG=adikari # mettre à jour avec votre slug d'organisation buildkite
USAGE="USAGE: $(basename "$0") [-s|--service] service_name [-t|--type] pipeline_type
Ex: create-pipeline --type pull-request
create-pipeline --type merge --service foo-service
create-pipeline --type merge --status-checks
NOTE: BUILDKITE_API_TOKEN doit être défini dans l'environnement
ARGUMENTS:
-t | --type type de pipeline buildkite <merge|pull-request|deploy> (requis)
-s | --service nom du service (optionnel, par défaut: pipeline racine deploy)
-r | --repository url du dépôt github (optionnel, par défaut: buildkite-docker-example)
-c | --status-checks activer les vérifications de statut github (optionnel, par défaut: true)
-h | --help afficher ce texte d'aide"
[ -z $BUILDKITE_API_TOKEN ] && { echo "BUILDKITE_API_TOKEN n'est pas défini."; exit 1;}
while [ $# -gt 0 ]; do
if [[ $1 =~ "--"* ]]; then
case $1 in
--help|-h) echo "$USAGE"; exit; ;;
--service|-s) SERVICE=$2;;
--type|-t) PIPELINE_TYPE=$2;;
--repository|-r) REPOSITORY=$2;;
--status-check|-c) STATUS_CHECK=${2:-true};;
esac
fi
shift
done
[ -z "$PIPELINE_TYPE" ] && { echo "$USAGE"; exit 1; }
export PIPELINE_NAME=$([ $SERVICE == "." ] && echo "" || echo "$SERVICE-")$PIPELINE_TYPE
BUILDKITE_CONFIG_FILE=.buildkite/pipelines/$PIPELINE_TYPE.json
[ ! -f "$BUILDKITE_CONFIG_FILE" ] && { echo "Type de pipeline invalide: Fichier non trouvé $BUILDKITE_CONFIG_FILE"; exit; }
BUILDKITE_CONFIG=$(cat $BUILDKITE_CONFIG_FILE | envsubst)
if [ $STATUS_CHECK == "false" ]; then
pipeline_settings='{ "provider_settings": { "trigger_mode": "none" } }'
BUILDKITE_CONFIG=$((echo $BUILDKITE_CONFIG; echo $pipeline_settings) | jq -s add)
fi
cd $ROOT_DIR
echo "Création du pipeline $PIPELINE_TYPE.."
RESPONSE=$(curl -s POST "https://api.buildkite.com/v2/organizations/$BUILDKITE_ORG_SLUG/pipelines" \
-H "Authorization: Bearer $BUILDKITE_API_TOKEN" \
-d "$BUILDKITE_CONFIG"
)
[[ "$RESPONSE" == *errors* ]] && { echo $RESPONSE | jq; exit 1; }
echo $RESPONSE | jq
WEB_URL=$(echo $RESPONSE | jq -r '.web_url')
WEBHOOK_URL=$(echo $RESPONSE | jq -r '.provider.webhook_url')
echo "URL du pipeline: $WEB_URL"
echo "URL du webhook: $WEBHOOK_URL"
echo "Pipeline $PIPELINE_NAME créé."
cd $CURRENT_DIR
unset REPOSITORY
unset PIPELINE_TYPE
unset SERVICE
unset PIPELINE_NAME
Rendez le script exécutable en définissant les permissions correctes (chmod +x). Exécutez ./bin/create-pipeline -h dans le CLI pour obtenir de l'aide.

Le script utilise l'API REST Buildkite pour créer les pipelines avec la configuration donnée. Le script utilise une configuration de pipeline définie comme un document json et la publie à l'API REST. Les configurations de pipeline se trouvent dans le dossier .bulidkite/pipelines.
Pour définir la configuration pour le pipeline pull-request, créez .buildkite/pipelines/pull-request.json avec le contenu suivant:
{
"name": "$PIPELINE_NAME",
"description": "Pipeline pour les pull requests $PIPELINE_NAME",
"repository": "$REPOSITORY",
"default_branch": "",
"steps": [
{
"type": "script",
"name": ":buildkite: $PIPELINE_TYPE",
"command": "buildkite-agent pipeline upload $SERVICE/.buildkite/$PIPELINE_TYPE.yml"
}
],
"cancel_running_branch_builds": true,
"skip_queued_branch_builds": true,
"branch_configuration": "!master",
"provider_settings": {
"trigger_mode": "code",
"publish_commit_status_per_step": true,
"publish_blocked_as_pending": true,
"pull_request_branch_filter_enabled": true,
"pull_request_branch_filter_configuration": "!master",
"separate_pull_request_statuses": true
}
}
Ensuite, créez ./buildkite/pipelines/merge.json avec le contenu suivant:
{
"name": "$PIPELINE_NAME",
"description": "Pipeline pour la fusion $PIPELINE_NAME",
"repository": "$REPOSITORY",
"default_branch": "master",
"steps": [
{
"type": "script",
"name": ":buildkite: $PIPELINE_TYPE",
"command": "buildkite-agent pipeline upload $SERVICE/.buildkite/$PIPELINE_TYPE.yml"
}
],
"cancel_running_branch_builds": true,
"skip_queued_branch_builds": true,
"branch_configuration": "master",
"provider_settings": {
"trigger_mode": "code",
"build_pull_requests": false,
"publish_blocked_as_pending": true,
"publish_commit_status_per_step": true
}
}
Enfin, créez .buildkite/pipelines/deploy.yml avec le contenu suivant:
{
"name": "$PIPELINE_NAME",
"description": "Pipeline pour le déploiement $PIPELINE_NAME",
"repository": "$REPOSITORY",
"default_branch": "master",
"steps": [
{
"type": "script",
"name": ":buildkite: $PIPELINE_TYPE",
"command": "buildkite-agent pipeline upload $SERVICE/.buildkite/$PIPELINE_TYPE.yml"
}
],
"provider_settings": {
"trigger_mode": "none"
}
}
Maintenant, exécutez la commande ./bin/create-pipeline pour créer un pipeline de pull-request.
./bin/create-pipeline --type pull-request --status-checks
./bin/create-pipeline --type merge --status-checks
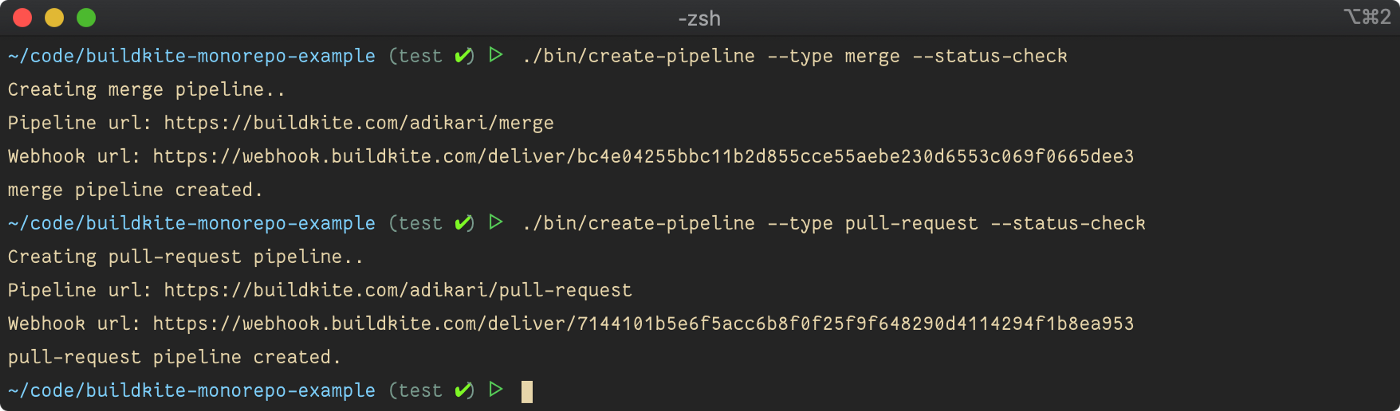
Copiez l'URL du webhook à partir de la sortie de la console et créez une intégration de webhook dans GitHub. L'URL du webhook est disponible dans les paramètres du pipeline dans la console Buildkite si nécessaire à l'avenir.
Nous devons configurer le webhook uniquement pour les pipelines pull-request et merge. Tous les autres pipelines sont déclenchés dynamiquement.
Accédez au dépôt GitHub Settings > Webhooks et ajoutez un webhook. Sélectionnez Just the push event, puis ajoutez le webhook. Répétez cela pour les deux pipelines.

Maintenant, dans la console Buildkite, il devrait y avoir deux nouveaux pipelines créés. 🎉

Ensuite, ajoutez l'intégration GitHub pour permettre à Buildkite d'envoyer des mises à jour de statut à GitHub. Vous n'avez besoin de configurer cette intégration qu'une seule fois par compte. Elle est disponible à Setting > Integrations > Github dans la console Buildkite.

Ensuite, créez les pipelines restants. Ces pipelines seront déclenchés dynamiquement par les pipelines pull-request et merge, donc nous n'avons pas besoin de créer d'intégration GitHub.
# pipelines de service foo
./bin/create-pipeline --type pull-request --service foo-service
./bin/create-pipeline --type merge --service foo-service
./bin/create-pipeline --type deploy --service foo-service
# pipelines de service bar
./bin/create-pipeline --type pull-request --service bar-service
./bin/create-pipeline --type merge --service bar-service
./bin/create-pipeline --type deploy --service bar-service

La console Buildkite devrait maintenant avoir tous les pipelines listés. 🤷

Configurer les étapes Buildkite
Maintenant que les pipelines sont prêts, configurons les étapes à exécuter pour chaque pipeline.
Ajoutez le script suivant dans .buildkite/diff. Ce script compare tous les fichiers modifiés dans un commit par rapport à la branche master. La sortie du script est utilisée pour déclencher les pipelines respectifs dynamiquement.
#!/bin/bash
[ $# -lt 1 ] && { echo "argument est manquant."; exit 1; }
COMMIT=$1
BRANCH_POINT_COMMIT=$(git merge-base master $COMMIT)
echo "diff entre $COMMIT et $BRANCH_POINT_COMMIT"
git --no-pager diff --name-only $COMMIT..$BRANCH_POINT_COMMIT
Changez les permissions du script pour le rendre exécutable.
chmod +x .buildkite/diff
Créez un nouveau fichier .buildkite/pullrequest.yml et ajoutez la configuration d'étape suivante. Nous utilisons le plugin buildkite-monorepo-diff pour exécuter le script diff et télécharger et déclencher automatiquement les pipelines respectifs.
steps:
- label: "Déclenchement du pipeline de pull request"
plugins:
chronotc/monorepo-diff#v1.1.1:
diff: ".buildkite/diff ${BUILDKITE_COMMIT}"
wait: false
watch:
- path: "foo-service"
config:
trigger: "foo-service-pull-request"
- path: "bar-service"
config:
trigger: "bar-service-pull-request"
Maintenant, créez la configuration pour le pipeline de merge en ajoutant le contenu suivant dans .buildkite/merge.yml.
steps:
- label: "Déclenchement du pipeline de merge"
plugins:
chronotc/monorepo-diff#v1.1.1:
diff: "git diff --name-only HEAD~1"
wait: false
watch:
- path: "foo-service"
config:
trigger: "foo-service-merge"
- path: "bar-service"
config:
trigger: "bar-service-merge"
À ce stade, nous avons configuré les pipelines de niveau supérieur pull-request et merge. Maintenant, nous devons configurer les pipelines individuels pour chaque service.
Nous allons configurer les pipelines pour foo-service en premier. Créez foo-service/.buildkite/pull-request.yml avec le contenu suivant. Lorsque le pipeline pull-request pour le service foo s'exécute, spécifiez que les commandes lint et test doivent s'exécuter. L'option command peut également déclencher d'autres scripts.
steps:
- label: "Pull request du service Foo"
command:
- "echo linting"
- "echo testing"
Ensuite, configurez un pipeline de merge pour le service foo en ajoutant le contenu suivant dans foo-service/.buildkite/merge.yml:
steps:
- label: "Exécuter les vérifications de sanity"
command:
- "echo linting"
- "echo testing"
- label: "Déployer en staging"
trigger: "foo-deploy"
build:
env:
STAGE: "staging"
- wait
- block: ":rocket: Release to Production"
- label: "Déployer en production"
trigger: "foo-deploy"
build:
env:
STAGE: "production"
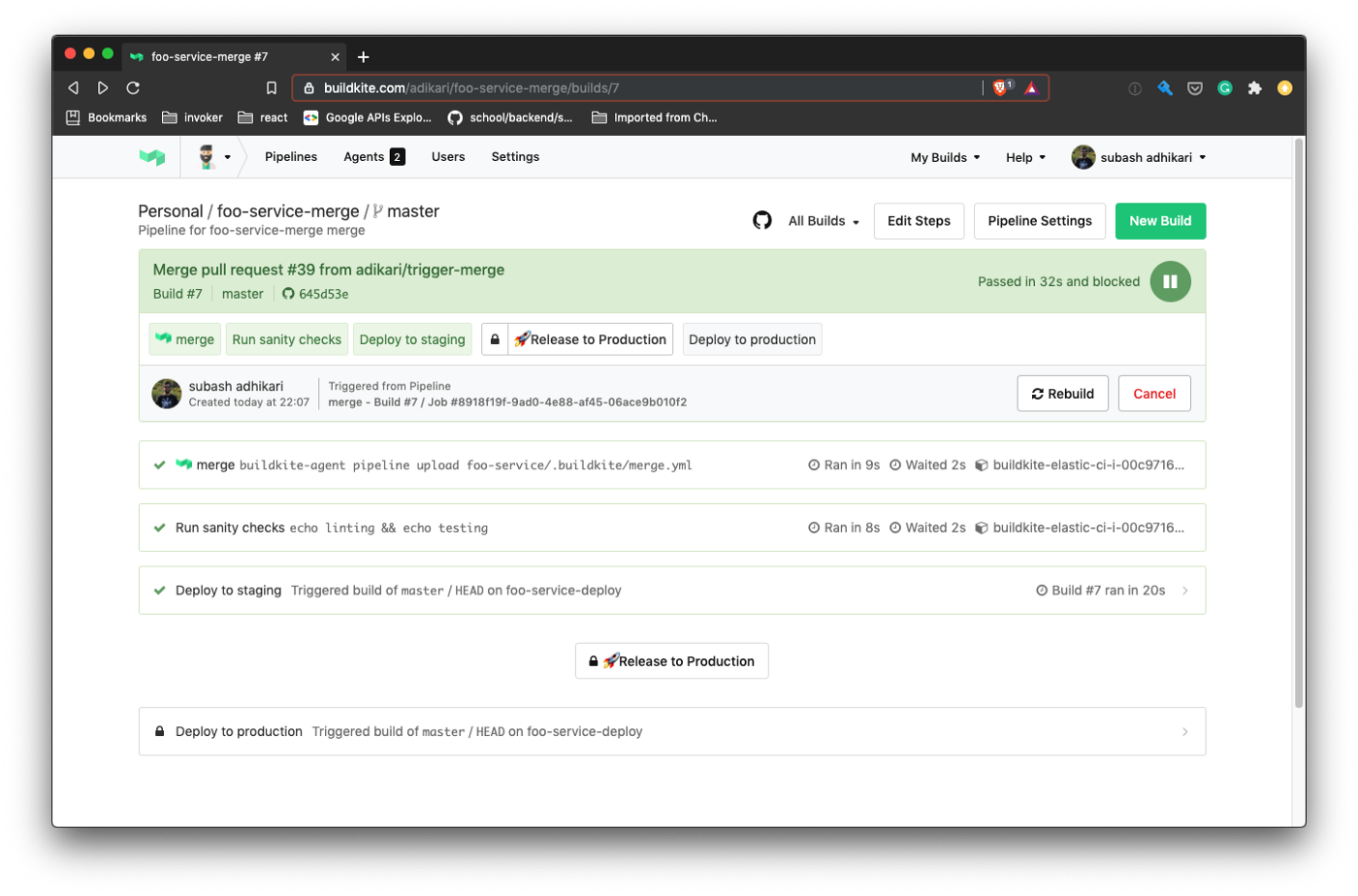
Lorsque le pipeline foo-service-merge s'exécute, voici ce qui se passe:
- Le pipeline exécute la vérification de sanity.
- Ensuite, le pipeline
foo-deployest déclenché dynamiquement. Nous passons l'environnementSTAGEpour identifier quel environnement exécuter le déploiement contre. - Une fois le déploiement en staging terminé, le pipeline est bloqué et le pipeline suivant n'est pas déclenché automatiquement. Le pipeline peut être repris en appuyant sur le bouton "Release to Production".
- Le débloquage du pipeline déclenche à nouveau le pipeline
foo-deploy, mais cette fois avec l'étapeproduction.
Enfin, ajoutez la configuration pour le pipeline foo-deploy en ajoutant foo-service/.buildkite/deploy.yml. Dans la configuration de déploiement, nous déclenchons un script bash et passons la variable STAGE qui a été reçue du pipeline foo-service-merge.
steps:
- label: "Déploiement du service foo vers ${STAGE}"
command: "./foo-service/bin/deploy ${STAGE}"
Maintenant, créez le script de déploiement foo-service/bin/deploy et ajoutez le contenu suivant:
#!/bin/bash
set -euo pipefail
STAGE=$1
echo "Déploiement du service foo vers $STAGE"
Rendez le script de déploiement exécutable comme ceci:
chmod +x ./foo-service/bin/deploy
La configuration du pipeline et des étapes pour foo-service est maintenant complète. Répétez toutes les étapes ci-dessus pour configurer les pipelines pour bar service.
Tester le workflow global
Nous avons configuré Buildkite et GitHub et nous avons mis en place l'infrastructure appropriée pour exécuter les builds. Ensuite, testons l'ensemble du workflow et voyons-le en action.
Pour tester le workflow, commencez par créer une nouvelle branche et modifier un fichier dans foo-service. Poussez les changements vers GitHub et créez une Pull Request.
git checkout -b change-foo-service
cd foo-service && touch test.txt
echo testing >> test.txt
git add .
git commit -m 'making some change'
git push origin master

Pousser les changements vers GitHub devrait déclencher le pipeline pull-request dans Buildkite, qui déclenche ensuite le pipeline foo-service-pull-request.
GitHub devrait rapporter le statut dans les vérifications GitHub. Vous pouvez activer la protection de branche de GitHub pour exiger que les vérifications passent avant de fusionner la Pull Request.

Une fois que toutes les vérifications ont passé dans GitHub, fusionnez la Pull Request. Cette fusion déclenchera le pipeline merge dans Buildkite.

Les changements dans le service foo sont détectés, et le pipeline foo-service-merge est déclenché. Le pipeline sera finalement bloqué lorsque foo-service-deploy s'exécute contre l'environnement de staging.
Débloquez le pipeline en cliquant manuellement sur le bouton Release to Production pour exécuter le déploiement contre la production.
Résumé
Dans cet article, nous avons configuré un pipeline d'intégration continue pour un monorepo en utilisant Buildkite, Github et AWS.
Le pipeline prend notre code de la machine de développement à la staging, puis à la production. Les agents de build et les étapes s'exécutent dans des instances AWS EC2 avec autoscaling.
Nous avons également créé un ensemble de scripts bash pour créer facilement des versions reproductibles de cette configuration.
En tant qu'amélioration de la conception actuelle, envisagez d'utiliser le buildkite-docker-compose-plugin pour isoler les builds dans des conteneurs Docker.