


Article original : How to Set Up Azure CosmosDB – Database Guide for Beginners
Dans cet article, nous allons passer en revue les bases d'Azure Cosmos DB et comprendre les options de configuration disponibles.
Nous aborderons les concepts de gestion des ressources, le modèle de données, les API et les options de configuration.
1. Qu'est-ce qu'Azure Cosmos DB ?
Azure Cosmos DB est un service de base de données de documents qui nous permet de stocker, interroger et indexer nos données dans une base de données NoSQL hautement disponible, globalement cohérente et évolutive basée sur le cloud.
Il est entièrement géré, ce qui signifie que la disponibilité, la fiabilité et la sécurité sont toutes gérées pour nous.
API Cosmos DB
La fonctionnalité phare de Cosmos DB est que vous pouvez le configurer pour utiliser soit SQL soit NoSQL pour interagir avec vos données. Il le fait en fournissant différentes API pour chaque type de données que vous souhaitez stocker.
Les API sont :
- API SQL – pour stocker et interroger des données en utilisant une syntaxe de type SQL. Il s'agit de l'API par défaut et recommandée.
- API Gremlin – si nous voulons interagir avec des données en utilisant une syntaxe de type base de données de graphes.
- API Table – pour les applications migrant d'Azure Table Storage vers Cosmos DB.
- API Cassandra – pour travailler avec des données conçues pour la base de données Cassandra.
- API MongoDB – pour travailler avec des données conçues pour la base de données MongoDB.
En fournissant ces API, Cosmos DB facilite la migration d'un magasin de données existant vers Cosmos DB. Plus d'informations à ce sujet lorsque nous explorerons comment se connecter à Cosmos DB par programmation.
Notez que les API ne déterminent pas comment les données sont stockées. Les données sont stockées dans une base de données NoSQL.
Pourquoi choisir Cosmos DB ?
Puisqu'il existe d'autres bases de données basées sur le cloud que vous pouvez utiliser pour stocker des données, il est important de comprendre pourquoi vous pourriez vouloir migrer vers Cosmos DB.
Cosmos DB offre certaines capacités premium qui peuvent ne pas être disponibles dans d'autres bases de données basées sur le cloud :
- Distribution globale facile des données – ce qui augmente la disponibilité et la vitesse avec des opérations d'écriture et de lecture multi-régions.
- Débit dédié
- Latence en millisecondes à un chiffre.
- Disponibilité garantie
- Indexation et partitionnement avancés
et plus encore.
En plus de cela, les API facilitent le passage entre différentes approches de base de données sans migrer physiquement les données.
2. Concepts de base d'Azure Cosmos DB
Examinons quelques concepts de base d'Azure Cosmos DB.
Hiérarchie des ressources
Ci-dessous se trouve la hiérarchie des ressources d'Azure Cosmos DB.
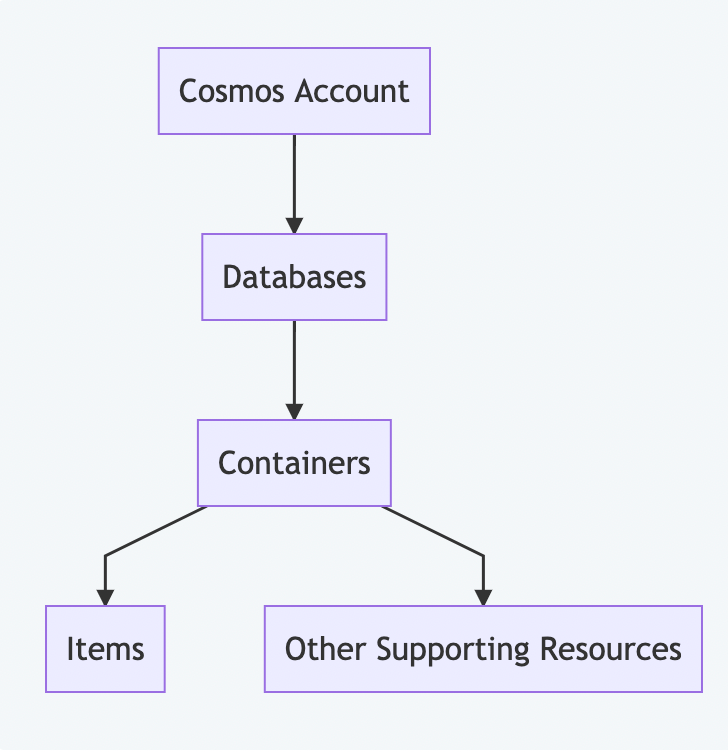 Hiérarchie des ressources Cosmos DB
Hiérarchie des ressources Cosmos DB
Comprenons chaque niveau et les configurations disponibles aux différents niveaux de la hiérarchie.
Compte Cosmos
Un compte Cosmos est la ressource de niveau supérieur dans Azure Cosmos DB. Il est le point d'entrée de nos instances Cosmos DB.
Les fonctionnalités suivantes sont définies au niveau du compte Cosmos :
- Un nom DNS unique utilisé pour se connecter aux instances de base de données comme https://{account}.documents.azure.com/
- Capacités de distribution globale – vous pouvez définir combien de régions vous souhaitez distribuer vos données.
- Le niveau de cohérence par défaut pour toutes les ressources du compte. Vous pouvez remplacer cela pour des ressources individuelles.
Bases de données et conteneurs
Un compte peut contenir plusieurs bases de données qui ont les mêmes besoins de distribution. Chaque base de données peut contenir plusieurs conteneurs. Vous pouvez également utiliser des bases de données pour gérer les utilisateurs, les permissions et le débit pour les conteneurs sous-jacents.
Chaque conteneur est analogue à une table en SQL, une collection en MongoDB, un graphe en Gremlin, etc. Les conteneurs sont des unités fondamentales d'évolutivité pour le stockage et le débit. Ils sont partitionnés horizontalement et répliqués dans plusieurs régions comme défini par le compte.
Le débit d'un conteneur peut être défini de deux manières :
- Mode de débit approvisionné dédié – Chaque instance de conteneur peut se voir attribuer un débit fixe. Plus coûteux et soutenu par des SLA.
- Mode de débit approvisionné partagé – Le débit total de toutes les instances de conteneurs exécutées en mode partagé reste le même tandis que les conteneurs individuels peuvent avoir différents débits en temps réel.
Au niveau du conteneur, nous avons également la possibilité de configurer la stratégie d'indexation et le TTL par défaut.
Contenu d'un conteneur
Similaire à une table SQL, un conteneur peut contenir plusieurs ressources. La ressource la plus importante est l'élément(s).
Un élément est une unité unique d'enregistrement. Par exemple, une ligne dans une table, un document dans une collection, un nœud dans un graphe, etc.
D'autres ressources incluent des éléments basés sur JavaScript :
- Procédures stockées
- Fonctions définies par l'utilisateur
- Déclencheurs
Niveaux de cohérence
Les données peuvent être répliquées dans plusieurs régions et les écritures peuvent être autorisées. Dans de tels scénarios, il est important de déterminer les exigences de cohérence des données.
Examinons les différents niveaux de cohérence disponibles dans Azure Cosmos DB et ce qu'ils signifient :
- Forte – Les données restent exactement les mêmes dans toutes les régions. Cela signifie que l'opération d'écriture est coûteuse et ne se termine pas tant que toutes les régions n'ont pas les données.
- Staleness bornée – Le délai dans l'opération d'écriture est borné par un intervalle de temps fixe entre les régions. Par exemple, après qu'une opération d'écriture a été effectuée, les données sont garanties d'être disponibles dans les t secondes suivantes.
- Session – Les données écrites dans une session seront disponibles pour la lecture lorsqu'une lecture est effectuée dans la même session. Cela est bon lorsqu'une session utilisateur prend en charge toutes les lectures et écritures dans une seule région.
- Préfixe cohérent – Les données seront lues dans la même séquence dans laquelle elles sont écrites. Par exemple, si dans la région 1 nous écrivons les données A puis B, alors dans la région 2, A sera disponible avant B.
- Éventuelle – Ni l'ordre ni la staleness n'ont d'importance, la seule chose importante est que les données seront éventuellement disponibles dans toutes les régions. Fonctionne rapidement mais a la moindre cohérence.
Explorez – Scénarios nécessitant différents niveaux de cohérence.
Unités de requête (RU)
Selon la définition sur Microsoft Learn :
Le coût pour effectuer une lecture ponctuelle, qui consiste à récupérer un seul élément par son ID et sa valeur de clé de partition, pour un élément de 1 Ko est de 1 RU.
Le coût est basé sur les ressources système telles que le CPU, les IOPS et la mémoire nécessaires pour effectuer les opérations de base de données. Les RU consommées par notre application sont finalement facturées au compte. Il existe différents modes dans lesquels le compte Cosmos peut être configuré, ce qui affectera la facturation :
- Mode de débit approvisionné – Configurez le débit attendu en termes de RU par seconde. Le mode est choisi au niveau du compte, mais les RU peuvent être approvisionnées au niveau de la base de données ou du conteneur.
- Mode sans serveur – Payez pour les unités réellement consommées.
- Mode d'échelle automatique – Le compte est configuré pour s'adapter automatiquement en fonction de l'utilisation. Cela est bon pour les applications avec une utilisation variable ou imprévisible.
Partitionnement de la base de données
Comme mentionné précédemment dans la section sur les conteneurs, un conteneur peut être partitionné en plusieurs partitions. Vous faites cela en définissant la clé de partition.
Partitions et index
- Partitions logiques
Une partition logique est une collection d'éléments qui partagent la même valeur de clé de partition. Par exemple, si un conteneur appelé "Utilisateurs" est partitionné par une clé "État", alors une partition logique est une collection d'éléments qui partagent la même valeur "État".
- Index
Les index sont utilisés pour améliorer les performances des requêtes. Dans une base de données SQL régulière, un index est créé par défaut basé sur une clé primaire. Les éléments Cosmos DB contiennent également un champ unique appelé ID d'élément.
L'index par défaut dans Cosmos DB est une combinaison de la clé de partition et de l'ID d'élément. La clé de partition est utilisée pour localiser la partition logique et l'ID d'élément est utilisé pour localiser l'élément spécifique. Ainsi, pour un accès plus rapide, il est important de choisir une bonne clé de partition qui distribue les données uniformément dans les partitions.
- Partitions physiques
Le rôle des partitions physiques est de fournir une évolutivité horizontale. Une partition physique est une collection d'une ou plusieurs partitions logiques. Les données d'une seule partition logique ne peuvent pas exister dans plus d'une partition physique.
L'utilisateur n'a aucun contrôle sur la manière dont les données sont distribuées dans les partitions physiques. Cosmos DB est un service géré et le système distribuera automatiquement les données dans les partitions physiques lorsque l'évolutivité est nécessaire.
Cela constitue la base d'une autre directive selon laquelle les clés de partition doivent conduire à des partitions logiques plus petites. Si les partitions logiques sont trop grandes, cela affectera la limite à laquelle le système peut évoluer.
Comment choisir une clé de partition
À présent, nous savons ce qu'est une clé de partition. Mais comment choisir une bonne clé de partition ? Voici quelques directives :
- Immuable – La clé de partition ne peut pas être modifiée après la création des données.
- Cardinalité élevée – Un grand nombre de valeurs possibles pour la clé de partition conduira à un grand nombre de petites partitions logiques. Bon pour l'indexation et l'évolutivité.
- Distribution uniforme – En plus de la cardinalité élevée, il est également important que chaque valeur possible soit également probable. Cela est bon pour une distribution uniforme des données dans les partitions.
- Conteneurs à lecture intensive – Pour les conteneurs à lecture intensive, il est important de choisir une clé de partition qui apparaît fréquemment dans les requêtes de lecture. Sinon, l'avantage de l'index basé sur la clé de partition sera perdu. Il est également bénéfique que la plupart des requêtes puissent lire les données d'une seule partition et que les requêtes inter-partitions soient minimisées.
- Utilisation de l'ID d'élément comme clé de partition – Cosmos DB prend en charge un champ unique appelé ID d'élément. Ce champ est généré automatiquement et est garanti d'être unique. Il s'agit d'un bon choix pour les clés de partition.
Explorez – Pourquoi ne pas utiliser l'ID d'élément comme clé de partition ?
Voici plus d'informations sur le choix d'une clé de partition.
Clés de partition synthétiques
- Concaténer plusieurs champs pour créer une clé de partition.
- Utiliser une fonction de hachage pour créer un suffixe de clé de partition.
- Utiliser une chaîne aléatoire pour créer un suffixe de clé de partition.
3. Modèle de données Cosmos DB
Comme mentionné précédemment, toutes les données dans CosmosDB sont stockées de manière NoSQL. Examinons quelques aspects du modèle de données.
Modèle de données de document
Dans un modèle de données de document, chaque entrée est appelée un document. En terminologie Cosmos DB, les documents peuvent être appelés des éléments.
Une base de données orientée document aura les caractéristiques suivantes :
- Non relationnelle – Chaque élément est une entité individuelle.
- Facile à évoluer – Il est possible de créer des partitions physiques pour les données afin d'améliorer les performances et d'évoluer le stockage.
- Pas de schéma – La base de données en elle-même n'imposera aucun schéma. Cela donne la flexibilité de stocker des entités de différents formats de données. Cela aide également la structure à évoluer au fil du temps.
Éléments
Chaque élément dans Cosmos DB est un document JSON. Les opérations d'écriture sur ces documents sont atomiques. Les éléments contiennent un ID d'élément unique et une clé de partition qui est utilisée pour partitionner les données dans plusieurs partitions logiques.
Les clés de partition peuvent également être des champs imbriqués. Par exemple, dans le JSON ci-dessous, le champ ville peut être utilisé comme clé de partition même s'il n'est pas au niveau racine.
{
"id": "1",
"name": "John",
"address": {
"street": "1 Main St",
"city": "New York"
}
}
Lors de la création de conteneurs, il est obligatoire de fournir le chemin de la clé de partition. Dans l'exemple ci-dessus, le chemin sera /address/city.
4. Comment configurer Cosmos DB
Dans Cosmos DB, l'API SQL est un langage de requête qui nous permet d'interroger des données dans une base de données de documents en utilisant une syntaxe de type SQL. Il y a de nombreuses raisons de choisir l'API SQL plutôt que d'autres API :
- Faible latence
- Mise à l'échelle automatique
- Disponibilité de 99,999 % garantie par des SLA
Elle est bien adaptée pour les applications haute performance comme :
- Collecte et interrogation de données provenant d'appareils IoT – qui génèrent beaucoup de données et doivent être traitées rapidement.
- Applications de vente au détail – qui ont des schémas d'utilisation variés et peuvent bénéficier d'une mise à l'échelle élastique.
- Applications multi-plateformes – qui peuvent bénéficier de la flexibilité dans la structure des documents.
Approvisionnement du débit
Lors de la configuration d'Azure Cosmos DB, nous pouvons approvisionner le débit au niveau de la base de données, du conteneur ou des deux.
Débit au niveau du conteneur
Un débit approvisionné au niveau du conteneur s'applique uniquement au conteneur. Il n'affecte pas les autres conteneurs de la base de données. Par exemple, dans l'image ci-dessous, chaque conteneur a un débit différent.
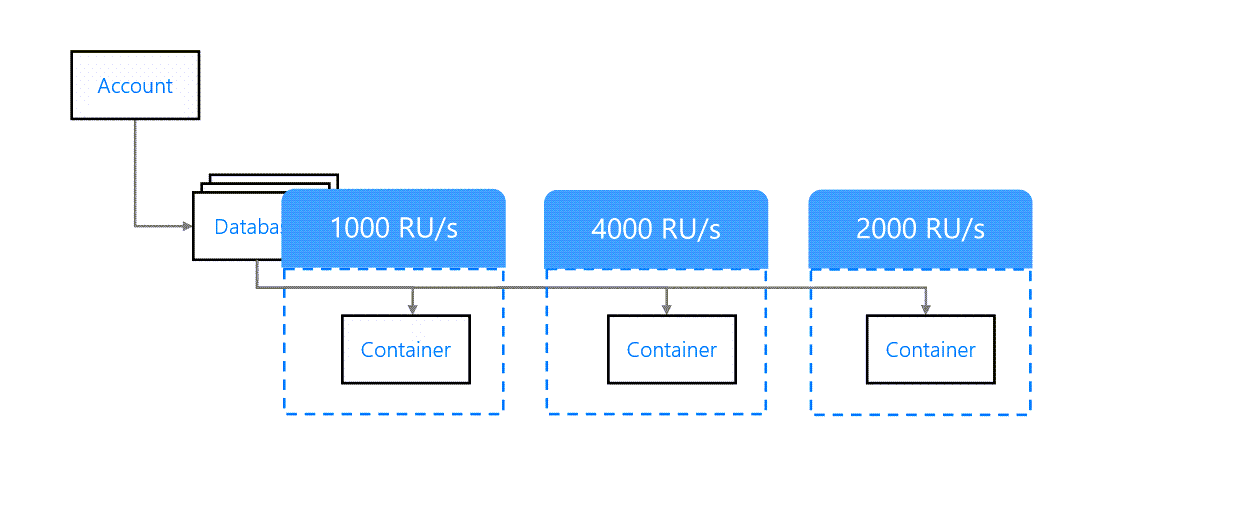 Approvisionnement du débit au niveau du conteneur
Approvisionnement du débit au niveau du conteneur
Il s'agit de la méthode recommandée pour approvisionner le débit. Si chaque conteneur est mappé à une fonction d'application distincte, il est alors logique d'approvisionner le débit au niveau du conteneur.
Débit au niveau de la base de données
Nous pouvons également approvisionner le débit au niveau de la base de données. Celui-ci sera partagé entre tous les conteneurs de la base de données.
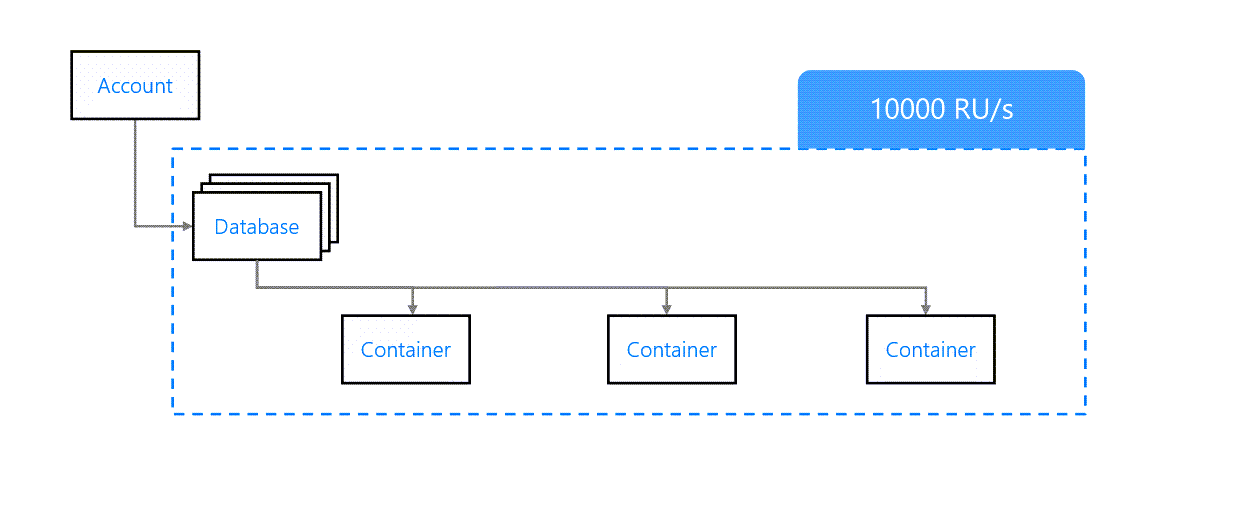 Approvisionnement du débit au niveau de la base de données
Approvisionnement du débit au niveau de la base de données
Cela est acceptable si tous les conteneurs sont censés avoir des schémas de charge similaires, mais dans la plupart des cas, cela entraînera des résultats imprévisibles.
Débit mixte
Il est possible de mélanger l'approvisionnement du débit au niveau du conteneur et de la base de données. Pour ce faire, nous définissons d'abord un débit au niveau de la base de données. Ensuite, lors de la création d'un conteneur, nous pouvons spécifier quel mode de débit utiliser.
Les conteneurs configurés en mode de débit partagé partageront le débit approvisionné au niveau de la base de données. Les conteneurs configurés en mode de débit dédié auront leur propre débit approvisionné au niveau du conteneur.
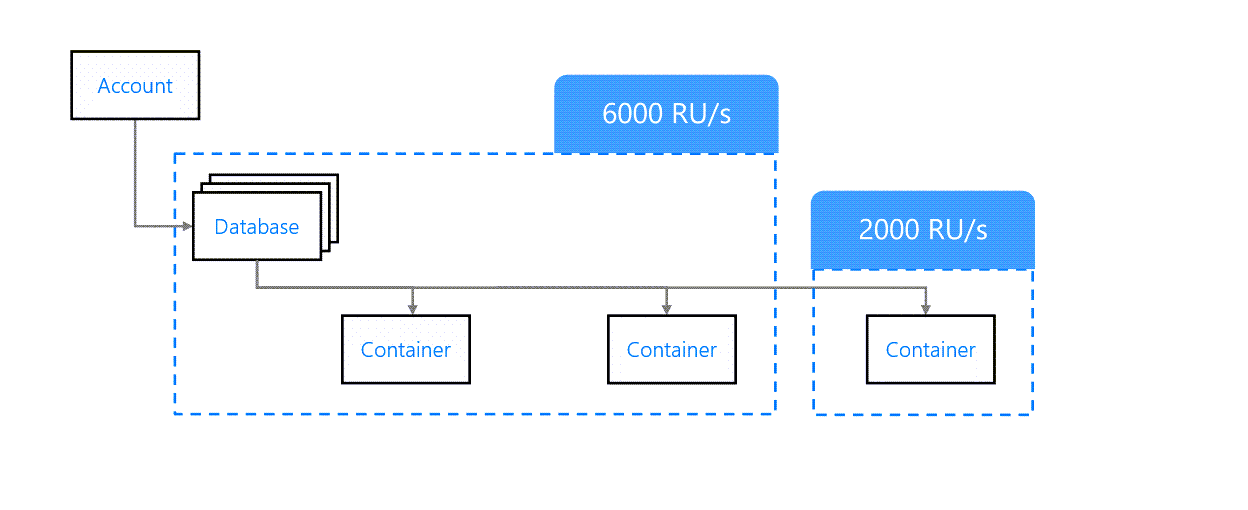 Approvisionnement du débit mixte
Approvisionnement du débit mixte
Notez que nous ne pouvons pas convertir un conteneur du mode de débit partagé au mode de débit dédié ou vice versa. Pour changer cela, nous devons supprimer le conteneur et en créer un nouveau.
Stockage
Pour estimer les besoins en stockage, nous pouvons utiliser le calculateur de capacité Azure Cosmos DB.
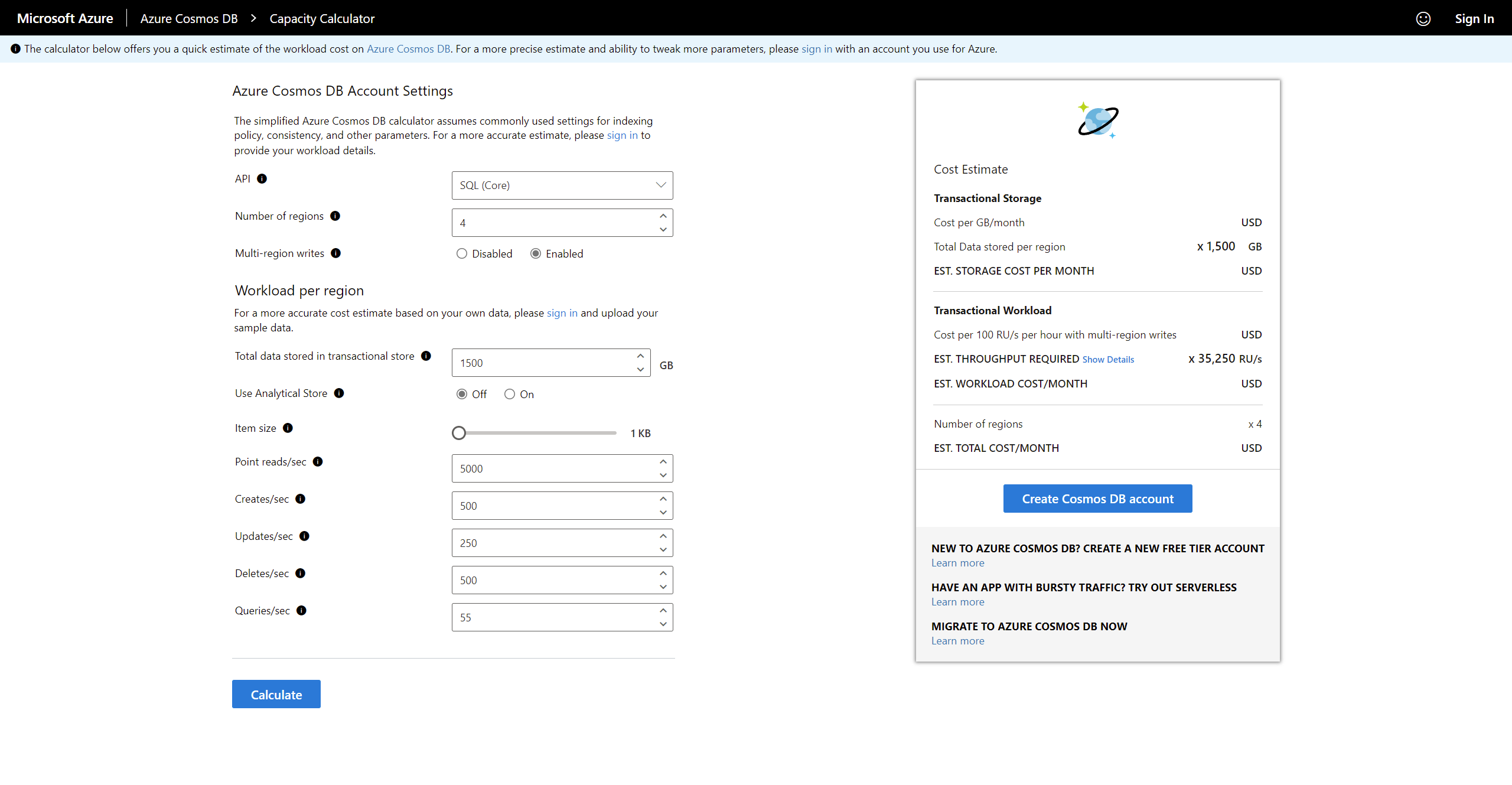 Calculateur de capacité Cosmos DB
Calculateur de capacité Cosmos DB
Après avoir entré la charge estimée, la stratégie de réplication et les besoins en stockage, le calculateur peut fournir une estimation des coûts d'une telle configuration.
Durée de vie (TTL)
Il est possible de définir une durée de vie (TTL) sur les documents dans un conteneur. Cela est utile pour les documents qui doivent être supprimés dans un court laps de temps. Il peut être configuré au niveau du conteneur et peut être remplacé au niveau du document. La valeur maximale de TTL est 2147483647.
Au niveau du conteneur, le TTL doit être défini sur l'une des valeurs suivantes :
- N'existe pas – Pas de TTL et pas d'expiration même en essayant de définir un TTL sur un document.
- -1 – Pas de TTL par défaut mais peut être ajouté au niveau du document.
- Nombre de secondes – Le TTL par défaut est le nombre de secondes fourni. Cela peut être remplacé au niveau du document.
L'expiration des documents et l'optimisation du stockage consommé peuvent entraîner de meilleures performances et des coûts réduits. Il est donc important de décider quelle valeur de TTL utiliser et quels éléments expirer.
Certaines solutions peuvent nécessiter Cosmos DB comme stockage intermédiaire pour effectuer des requêtes et transmettre les résultats au stockage final. Dans ce cas, vous devez utiliser des TTL pour expirer les documents dès que possible afin de minimiser les coûts.
Modèles de consommation Cosmos DB
Examinons en détail les différents modèles de consommation.
Sans serveur
Dans le modèle sans serveur, le service est facturé en fonction du nombre réel de RU consommées. Cela est idéal lorsque le schéma de consommation est imprévisible et peut dépendre de facteurs comme les campagnes, les lancements de fonctionnalités, l'heure de la journée, les ventes saisonnières, les vacances, etc.
Cela est également idéal dans les situations suivantes :
- Une nouvelle application est lancée et nous n'avons pas beaucoup de charge au départ. Nous ne savons pas non plus comment la charge va évoluer.
- La base de données prend en charge une application sans serveur hébergée sur Azure Functions. À mesure que l'application obtient plus d'utilisateurs, la base de données recevra également plus de requêtes.
- Débuter avec Cosmos DB et ne pas avoir beaucoup d'expérience avec l'approvisionnement et les coûts.
- Le service n'est pas censé évoluer et consommera probablement moins que le minimum de RU configurables.
Approvisionné vs Sans serveur
Décider entre les modèles de consommation sans serveur et approvisionné est un compromis entre coût et performance. Utilisez les points suivants pour vous aider à décider :
- La charge de travail – une charge de travail prévisible et suffisamment grande favorise le modèle de consommation approvisionné.
- Limitation des RU – Le débit approvisionné ne dépassera pas le RU maximum décidé tandis que le sans serveur peut évoluer jusqu'au maximum de RU/s autorisé dans Cosmos DB. En cas de situations de pic, vous pouvez utiliser le sans serveur.
- Distribution globale – Il s'agit d'un facteur important. Les modèles sans serveur ne sont pas distribués dans les régions et peuvent donc être utilisés pour une seule région. Les modèles approvisionnés sont distribués dans les régions et peuvent être utilisés pour plusieurs régions.
- Limites de stockage – Le sans serveur ne stocke que 50 Go de données par conteneur tandis que l'approvisionné peut stocker des données illimitées par conteneur.
Modèle d'échelle automatique
Le modèle d'échelle automatique trouve un équilibre entre les modèles de consommation approvisionnés et sans serveur. Il fonctionne en approvisionnant dynamiquement les ressources selon les besoins, mais dans une plage spécifiée.
Examinons une comparaison entre le débit d'échelle automatique et approvisionné :
- La charge de travail – Le débit d'échelle automatique oscille entre la performance minimale acceptable et le coût maximum que nous souhaitons engager. L'approvisionné est toujours meilleur si la charge de travail est prévisible car nous ne voulons ni perdre en performance ni engager plus de coûts à long terme.
- Consommation de RU – Avec l'échelle automatique, nous pouvons définir une limite de RU comme avec l'approvisionné. La différence est que la facturation approvisionnée est toujours effectuée sur les RU spécifiées, mais la facturation d'échelle automatique est basée sur – les RU consommées en temps réel ou 10 % des RU approvisionnées – selon la valeur la plus élevée. En gardant cela à l'esprit, il est recommandé d'utiliser le modèle de consommation approvisionné uniquement si la consommation réelle est proche de la limite approvisionnée pendant plus de 66 % du temps.
Il est également possible de migrer des conteneurs de l'échelle automatique vers le débit approvisionné et vice versa. Pendant la migration, une valeur RU est automatiquement choisie par le système et doit être vérifiée ou définie manuellement après la migration.
Conclusion
Merci d'avoir lu cet article. Cela devrait vous donner une idée de la manière dont le service CosmosDB d'Azure fonctionne et comment le configurer. Si vous souhaitez me contacter, vous pouvez me trouver sur Twitter.