


Article original : How to Get Started with PysonDB
Nous avons souvent besoin de stocker des données lors de nos projets personnels. Nous pouvons utiliser une base de données SQL ou NoSQL avec un serveur, mais cela nécessiterait un peu de configuration.
Dans l'un de mes articles précédents, nous avons vu une solution à ce problème avec l'utilisation de TinyDB.
Mais nous ne allons pas discuter de TinyDB dans cet article. Si vous êtes intéressé à en apprendre davantage, consultez ce blog.
Aujourd'hui, nous allons discuter d'une autre solution similaire à ce problème en utilisant PysonDB.
Qu'est-ce que PysonDB ?
PysonDB est une autre base de données orientée document écrite en Python pur. Développée par Fredy Somy, elle est simple, légère et efficace.

Le mot PysonDB est construit à partir des mots Python et JSON (et bien sûr, DB 😋). Ainsi, c'est une base de données basée sur JSON.
Elle possède de nombreuses fonctionnalités comme :
- Elle est légère et basée sur JSON.
- Elle supporte les opérations CRUD.
- Aucun pilote de base de données n'est requis.
- Un ID unique est attribué à chaque document JSON et ajouté automatiquement.
- Elle est stricte sur le schéma des données ajoutées.
- Elle dispose d'un CLI intégré pour supprimer, afficher et créer la base de données.
Notez que vous ne pouvez pas stocker d'images, de vidéos, etc. avec PysonDB.
Comment installer PysonDB
Il est extrêmement facile d'installer PysonDB. Il suffit d'exécuter cette commande dans votre terminal :
pip install pysondb
Comment utiliser PysonDB
Similaire au tutoriel TinyDB, considérons un exemple d'application Todo où nous devons simplement effectuer des opérations CRUD. Maintenant que nous avons installé PysonDB, voyons comment nous pouvons l'utiliser.
La toute première chose que nous allons faire est de créer une base de données appelée todo.json. C'est assez facile à faire avec PysonDB.
from pysondb import getDb
todo_db = getDb('todo.json')
Nous devons simplement appeler la méthode getDb() avec le nom de fichier JSON et lorsque vous exécutez le fichier, il créera automatiquement une base de données vide (fichier JSON) pour vous.
{ "data": [] }
Comment insérer des données dans PysonDB
L'insertion de données est assez simple dans PysonDB. Nous avons deux méthodes : add() pour insérer un objet et addMany() pour en ajouter plus d'un.
La seule chose à laquelle nous devons faire attention est le schéma de la base de données. Quelles que soient les données que vous ajoutez en premier, elles deviennent le schéma pour toute la base de données. Toute irrégularité de schéma rejette les données irrégulières. Si vous ne comprenez pas encore comment cela fonctionne, regardons cela avec un exemple.
Méthode add()
new_item = {"name": "Book", "quantity": 5}
item_id = todo_db.add(new_item)
print(item_id)
# Output
# 259596727698286139
Tout d'abord, nous avons créé un nouveau dictionnaire appelé new_item avec name et quantity définis sur Book et 5, respectivement. Ensuite, nous avons utilisé la méthode add() pour insérer les données dans notre base de données. La méthode add() retourne l'ID unique de l'objet inséré.
Voyons à quoi ressemble notre fichier JSON maintenant :
{
"data": [
{
"name": "Book",
"quantity": 5,
"id": 259596727698286139
}
]
}
Maintenant, regardons un exemple d'irrégularité de schéma. Jusqu'à présent, nous avons inséré un objet avec les champs name et quantity. Mais maintenant, ajoutons un autre champ price et essayons d'ajouter les données.
another_item = {"name": "Milk", "quantity": "5L", "price": 310}
another_item_id = todo_db.add(another_item)
print(another_item_id)
Maintenant, si vous essayez d'exécuter le programme, vous rencontrerez une SchemaError.

J'espère que l'énoncé est maintenant clair.
Méthode addMany()
Maintenant, voyons comment nous pouvons ajouter plus d'un objet en utilisant la méthode addMany().
new_items = [
{"name": "Copies", "quantity": 10},
{"name": "Pen", "quantity": 4},
]
todo_db.addMany(new_items)
Dans ce cas, nous avons créé une liste de dictionnaires appelée new_items et utilisé la méthode addMany() pour insérer les éléments. Cette méthode ne retourne rien.
Dans ce cas également, nous pourrions rencontrer le problème d'irrégularité de schéma.
other_new_items = [
{"namme": "Dictionary", "quantity": 1},
{"name": "Stickers", "quantity": 10},
]
todo_db.addMany(other_new_items)
Nous avons mal orthographié le champ name en namme, et donc nous rencontrerons la SchemaError.

Comment récupérer des données
Il existe plusieurs méthodes pour récupérer des données de la base de données. Examinons-les une par une.
Méthode get()
La méthode **get()** par défaut retourne un élément de la base de données.
data = todo_db.get()
print(data)
Sortie :
[{'name': 'Book', 'quantity': 5, 'id': 259596727698286139}]
La méthode get() prend un paramètre optionnel n où n est le nombre d'objets à récupérer.
data = todo_db.get(2)
print(data)
Sortie :
[{'name': 'Book', 'quantity': 5, 'id': 259596727698286139}, {'name': 'Copies', 'quantity': 10, 'id': 313160125004626021}]
Cependant, si nous donnons une valeur de n supérieure au nombre d'objets dans la base de données, elle retourne une liste avec un dictionnaire ayant une chaîne vide comme clé ainsi que la valeur.
data = todo_db.get(10)
print(data)
Sortie :
[{'': ''}]
Méthode getAll()
Comme son nom l'indique, getAll() retournera toutes les données de la base de données.
data = todo_db.getAll()
print(data)
Sortie :
[{'name': 'Book', 'quantity': 5, 'id': 259596727698286139}, {'name': 'Copies', 'quantity': 10, 'id': 313160125004626021}, {'name': 'Pen', 'quantity': 4, 'id': 588928180640637551}]
Méthode getByQuery()
La méthode getByQuery() prend un paramètre query où query est lui-même des données JSON. Elle retourne les données correspondant à la requête.
q = {"name": "Book"}
data = todo_db.getByQuery(query=q)
print(data)
Sortie :
[{'name': 'Book', 'quantity': 5, 'id': 259596727698286139}]
Si aucune donnée ne correspond à la requête, une liste vide est retournée.
Note : Cette méthode est un remplacement pour la méthode getBy(query) qui sera bientôt obsolète.
Méthode getById()
Si vous souhaitez obtenir un objet en utilisant son ID unique, la méthode getById() sera utile. Elle prend un paramètre entier pk qui est l'ID unique donné à chaque objet dans la base de données.
data = todo_db.getById(pk=588928180640637551)
print(data)
Sortie :
{'name': 'Pen', 'quantity': 4, 'id': 588928180640637551}
Si aucun id ne correspond à l'id fourni, nous rencontrons une IdNotFoundError.
data = todo_db.getById(2)
print(data)
Sortie :

Note : Cette méthode est un remplacement pour la méthode find(id) qui sera bientôt obsolète.
reSearch()
La méthode reSearch() prend deux paramètres : key et _re où key est l'une des clés de la base de données telle que name et quantity dans notre exemple, et _re est un motif regex pour la valeur de la clé respective.
data = todo_db.reSearch(key="name", _re=r"[A-Za-z]*")
print(data)
Ici, nous avons utilisé un motif regex pour tout mot contenant des lettres de l'alphabet et la clé est name.
[{'name': 'Book', 'quantity': 5, 'id': 259596727698286139}, {'name': 'Copies', 'quantity': 10, 'id': 313160125004626021}, {'name': 'Pen', 'quantity': 4, 'id': 588928180640637551}]
Comment mettre à jour des données
Pour mettre à jour des données dans PysonDB, nous avons trois méthodes.
Méthode updateById()
La méthode updateById() prend deux paramètres : pk et new_data, où pk est l'ID unique de l'objet qui doit être mis à jour avec new_data.
updated_data = {"name": "Book", "quantity": 100}
todo_db.updateById(pk=259596727698286139, new_data=updated_data)
Sortie :
{
"data": [
{
"name": "Book",
"quantity": 100,
"id": 259596727698286139
},
{
"name": "Copies",
"quantity": 10,
"id": 313160125004626021
},
{
"name": "Pen",
"quantity": 4,
"id": 588928180640637551
}
]
}
Si la valeur pk n'existe pas, nous obtenons une IdNotFoundError.
Méthode updateByQuery()
La méthode updateByQuery() prend deux paramètres : db_dataset et new_dataset, où db_dataset fait référence à la requête qui doit être modifiée avec new_dataset.
query_data = {"name": "Copies"}
updated_data = {"name": "Copies", "quantity": 200}
todo_db.updateByQuery(db_dataset=query_data, new_dataset=updated_data)
Sortie :
{
"data": [
{
"name": "Book",
"quantity": 100,
"id": 259596727698286139
},
{
"name": "Copies",
"quantity": 200,
"id": 313160125004626021
},
{
"name": "Pen",
"quantity": 4,
"id": 588928180640637551
}
]
}
Si la requête n'existe pas, nous obtenons une DataNotFoundError.
Comment supprimer des données
Nous avons deux méthodes pour supprimer des données de la base de données.
Méthode deleteById()
Elle prend un paramètre pk, qui est l'ID unique de toute donnée dans la base de données.
is_deleted = todo_db.deleteById(pk=259596727698286139)
print(is_deleted)
Sortie :
Elle retourne si les données ont été supprimées ou non.
True
Si aucune donnée ne correspond au pk, nous obtenons IdNotFoundError.
Méthode deleteAll()
Vous avez probablement déjà deviné ce que cette méthode fera. Elle effacera la base de données.
todo_db.deleteAll()
Lorsque cela est exécuté, nos données seront supprimées de la base de données.
{ "data": [] }
Opérations en ligne de commande avec PysonDB
L'une des fonctionnalités uniques de PysonDB est les opérations en ligne de commande que nous pouvons effectuer avec lui. Voyons ce que nous pouvons faire en utilisant la ligne de commande.
1. Créer une base de données
Si nous exécutons pysondb create [name], voici ce que nous obtenons :

Cette commande nous aide à créer une base de données en utilisant la ligne de commande.
2. Supprimer une base de données
Si nous exécutons pysondb delete [name], voici ce que nous obtenons :

Cette commande nous aide à supprimer une base de données déjà existante en utilisant la ligne de commande.
3. Afficher les données
Maintenant, regardons pysondb show [name].
Nous avons une base de données appelée todo.json avec le contenu :
{
"data": [
{
"name": "Book",
"quantity": 5,
"id": 241737821309633823
},
{
"name": "Copies",
"quantity": 10,
"id": 895733868606022035
},
{
"name": "Pen",
"quantity": 4,
"id": 314476424041647076
},
{
"name": "Dictionary",
"quantity": 1,
"id": 338909711735495602
},
{
"name": "Stickers",
"quantity": 10,
"id": 460456836143359145
}
]
}
Affichons ces données.
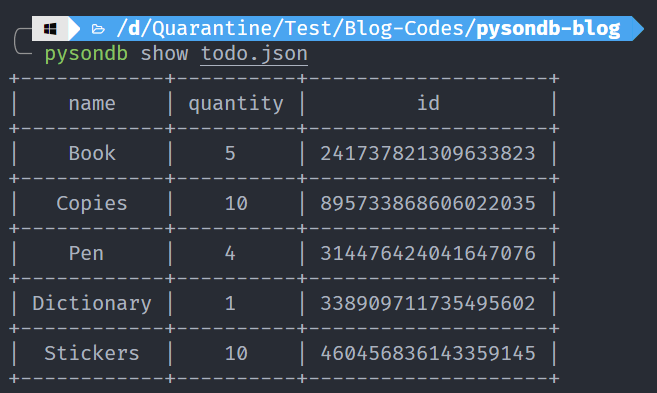
Cela a l'air cool, n'est-ce pas ?
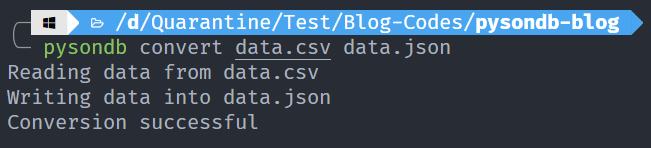
4. Convertir des données CSV en JSON
pysondb convert **[chemin du fichier csv] [chemin du fichier json]**
Cette commande nous aide à convertir des données CSV en base de données JSON.
Par exemple, nous avons un fichier CSV avec le contenu :
name,quantity,id
Book,5,241737821309633823
Copies,10,895733868606022035
Pen,4,314476424041647076
Dictionary,1,338909711735495602
Stickers,10,460456836143359145
Convertissons-le.
5. Convertir une base de données JSON en données CSV
pysondb converttocsv [chemin du fichier json] [nom optionnel pour le fichier CSV cible]
Cette commande nous aide à convertir une base de données JSON en données CSV.
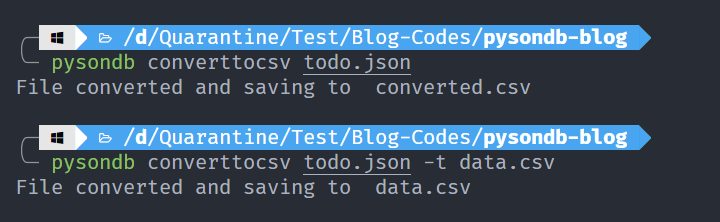
Note : Pour spécifier des chemins personnalisés pour les fichiers CSV, utilisez le drapeau -t puis le chemin du fichier CSV. Voir le deuxième exemple ci-dessus.
6. Fusionner deux fichiers JSON
pysondb merge [chemin du fichier json principal] [chemin du fichier json à fusionner] [nom optionnel pour le fichier json cible]
Nous avons deux fichiers JSON – one.json et two.json.
one.json :
{
"data": [
{ "name": "Item1", "quantity": "5", "id": 9618007132 },
{ "name": "Item2", "quantity": "10", "id": 8052463398 },
{ "name": "Item3", "quantity": "4", "id": 1677865420 },
{ "name": "Item4", "quantity": "1", "id": 4466016920 },
{ "name": "Item5", "quantity": "10", "id": 9836191198 }
]
}
two.json :
{
"data": [
{ "name": "Item6", "quantity": "5", "id": 9618007232 },
{ "name": "Item7", "quantity": "10", "id": 8052464398 },
{ "name": "Item8", "quantity": "4", "id": 1677865520 },
{ "name": "Item9", "quantity": "1", "id": 4466016020 },
{ "name": "Item10", "quantity": "10", "id": 9836181198 }
]
}
La commande suivante fusionnera les données de two.json dans one.json.
>>> pysondb merge one.json two.json
Maintenant, notre fichier one.json a le contenu suivant :
{
"data": [
{ "name": "Item6", "quantity": "5", "id": 9618007232 },
{ "name": "Item7", "quantity": "10", "id": 8052464398 },
{ "name": "Item8", "quantity": "4", "id": 1677865520 },
{ "name": "Item9", "quantity": "1", "id": 4466016020 },
{ "name": "Item10", "quantity": "10", "id": 9836181198 },
{ "name": "Item1", "quantity": "5", "id": 9618007132 },
{ "name": "Item2", "quantity": "10", "id": 8052463398 },
{ "name": "Item3", "quantity": "4", "id": 1677865420 },
{ "name": "Item4", "quantity": "1", "id": 4466016920 },
{ "name": "Item5", "quantity": "10", "id": 9836191198 }
]
}
Avez-vous vu que les données de two.json sont ajoutées au-dessus des données dans le fichier one.json ?
Nous pouvons également mettre le contenu fusionné dans un fichier séparé sans modifier les données de l'un des fichiers :
>>> pysondb merge one.json two.json -o merged.json
La commande ci-dessus créera un fichier merged.json et y mettra le contenu fusionné. Dans ce cas, one.json et two.json ne seront pas modifiés du tout.
Remarquez le drapeau -o dans la commande ci-dessus avant le nom du fichier de sortie.
Conclusion
Dans cet article, nous avons parlé de PysonDB et de la manière d'effectuer des opérations CRUD sur la base de données. Nous avons également vu comment nous pouvons interagir avec PysonDB en utilisant la ligne de commande.
Merci d'avoir lu !
Si vous avez aimé l'article, vous pouvez envisager de vous abonner à ma newsletter.