

Article original : How to Start Building Projects with LLMs
Si vous êtes un professionnel de l'IA en devenir, devenir un ingénieur LLM offre un parcours de carrière passionnant et prometteur.
Mais par où commencer ? À quoi devrait ressembler votre trajectoire ? Comment devriez-vous apprendre ?
Dans l'un de mes articles précédents, j'ai tracé la feuille de route complète pour devenir un ingénieur IA / LLM. La lecture de cet article vous donnera un aperçu des types de compétences que vous devrez acquérir et de la manière de commencer à apprendre.
La meilleure façon d'apprendre est de CONSTRUIRE !
Comme le dit Andrej Karpathy :

Andrej souligne que vous devriez construire des projets concrets et expliquer tout ce que vous apprenez avec vos propres mots. (Il nous conseille également de ne nous comparer qu'à une version plus jeune de nous-mêmes – jamais aux autres.)
Et je suis d'accord – construire des projets est le meilleur moyen non seulement d'apprendre, mais de vraiment bien assimiler ces concepts. Cela affinera davantage les compétences que vous apprenez pour réfléchir à des cas d'utilisation de pointe.
Mais le principal défi de cette philosophie d'apprentissage est que les bons projets peuvent être difficiles à trouver.
Et c'est le problème que j'essaie de résoudre. Je veux aider les gens, moi-même y compris, à découvrir et à construire des projets pratiques et concrets qui vous aident à développer des compétences dignes d'être présentées dans votre portfolio.
Voici ce que nous allons couvrir :
Quel devrait être votre premier projet ?
Si vous êtes un débutant ayant des bases en programmation, vos projets initiaux devraient montrer que vous pouvez construire confortablement des applications avec des LLM.
Ils devraient démontrer que :
vous savez ce que sont les API
vous savez comment les consommer
vous savez comment construire des produits que les gens veulent réellement utiliser
Construire un chatbot offre un excellent point de départ, mais à ce stade, tout le monde en a développé un. Et il existe de nombreuses solutions pour des prototypes simples basés sur Streamlit. Vous devez donc développer quelque chose qui soit réellement utilisable et qui ait le potentiel d'atteindre un public plus large.
Je suggérerais de construire un chatbot pour WhatsApp, Discord ou Telegram. Construisez un chatbot qui résout un problème auquel les gens sont confrontés, un problème pour lequel les entreprises ont commencé à construire des solutions.
Si je devais choisir un bon projet d'IA, et sans doute le plus courant sur lequel chaque entreprise a commencé à travailler, ce serait les chatbots propulsés par RAG.
Mais avant de passer à la construction de bots propulsés par RAG, vous devriez commencer par construire quelque chose d'un peu plus basique mais pratique avec les LLM.
Pour commencer, construisons un résumeur YouTube.
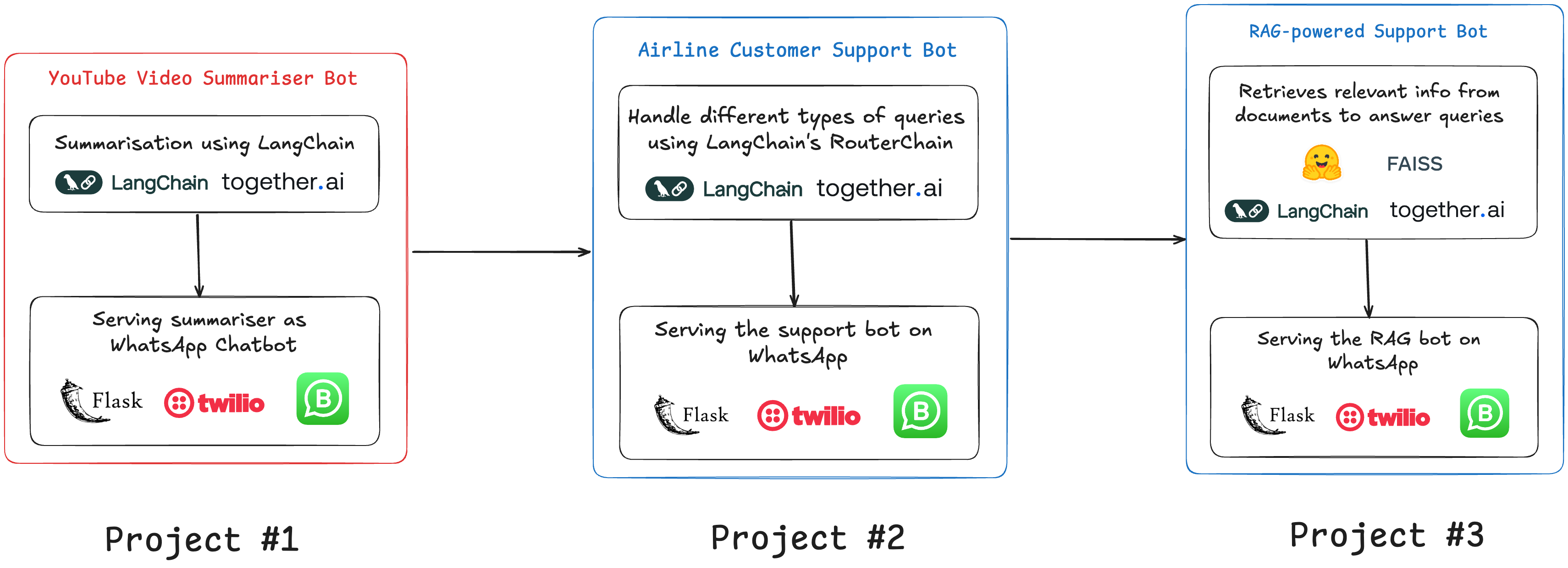
Projet n°1 : Résumer des vidéos YouTube
Nous allons construire la première partie de ce projet dans ce tutoriel : la fonctionnalité de base d'un outil de résumé de vidéos YouTube.
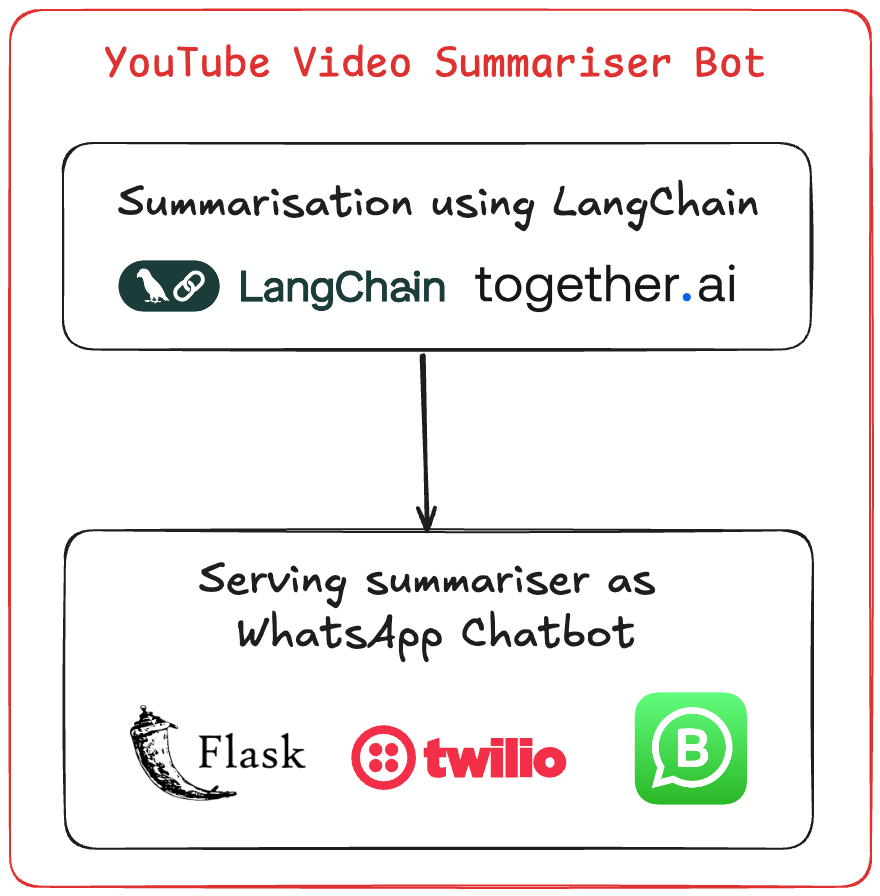
Notre bot va :
Recevoir l'URL YouTube.
Valider si l'URL est correcte.
Récupérer la transcription de la vidéo.
Utiliser un LLM pour analyser et résumer le contenu de la vidéo.
Renvoyer le résumé à l'utilisateur.
Installation et prérequis
Pour ce projet, nous allons coder la fonctionnalité de base dans un Jupyter Notebook en utilisant les packages Python suivants :
langchain-together— pour le LLM en utilisant l'intégration LangChain <> Together AIlangchain-community— pour les chargeurs de données spécifiqueslangchain— pour la programmation avec les LLMpytube— pour récupérer les informations de la vidéoyoutube-transcript-api— pour la transcription de la vidéo YouTube
Nous utiliserons le modèle Llama 3.1 proposé comme API par Together AI.
Together AI est une plateforme cloud qui propose des modèles open source sous forme d'API d'inférence, sans se soucier de l'infrastructure sous-jacente.
Commençons par installer ceux-ci :
!pip install — upgrade — quiet langchain
!pip install — quiet langchain-community
!pip install — upgrade — quiet langchain-together
!pip install youtube_transcript_api
!pip install pytube
Configurons maintenant notre LLM :
## configuration du modèle de langage
from langchain_together import ChatTogether
import api_key
llm = ChatTogether(api_key=api_key.api,temperature=0.0,
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo")
L'étape suivante consiste à traiter les vidéos YouTube comme une source de données. Pour cela, nous devrons comprendre le concept de chargeurs de documents (document loaders).
Introduction aux chargeurs de documents
Les chargeurs de documents fournissent une interface unifiée pour charger des données de diverses sources dans un format Document standardisé.
Ils extraient et attachent automatiquement des métadonnées pertinentes au contenu chargé.
Les métadonnées peuvent inclure des informations sur la source, des horodatages ou d'autres données contextuelles précieuses pour le traitement en aval.
LangChain propose des chargeurs pour CSV, PDF, HTML, JSON, et même des chargeurs spécialisés pour des sources comme les transcriptions YouTube ou les dépôts GitHub, comme indiqué sur leur page d'intégrations.
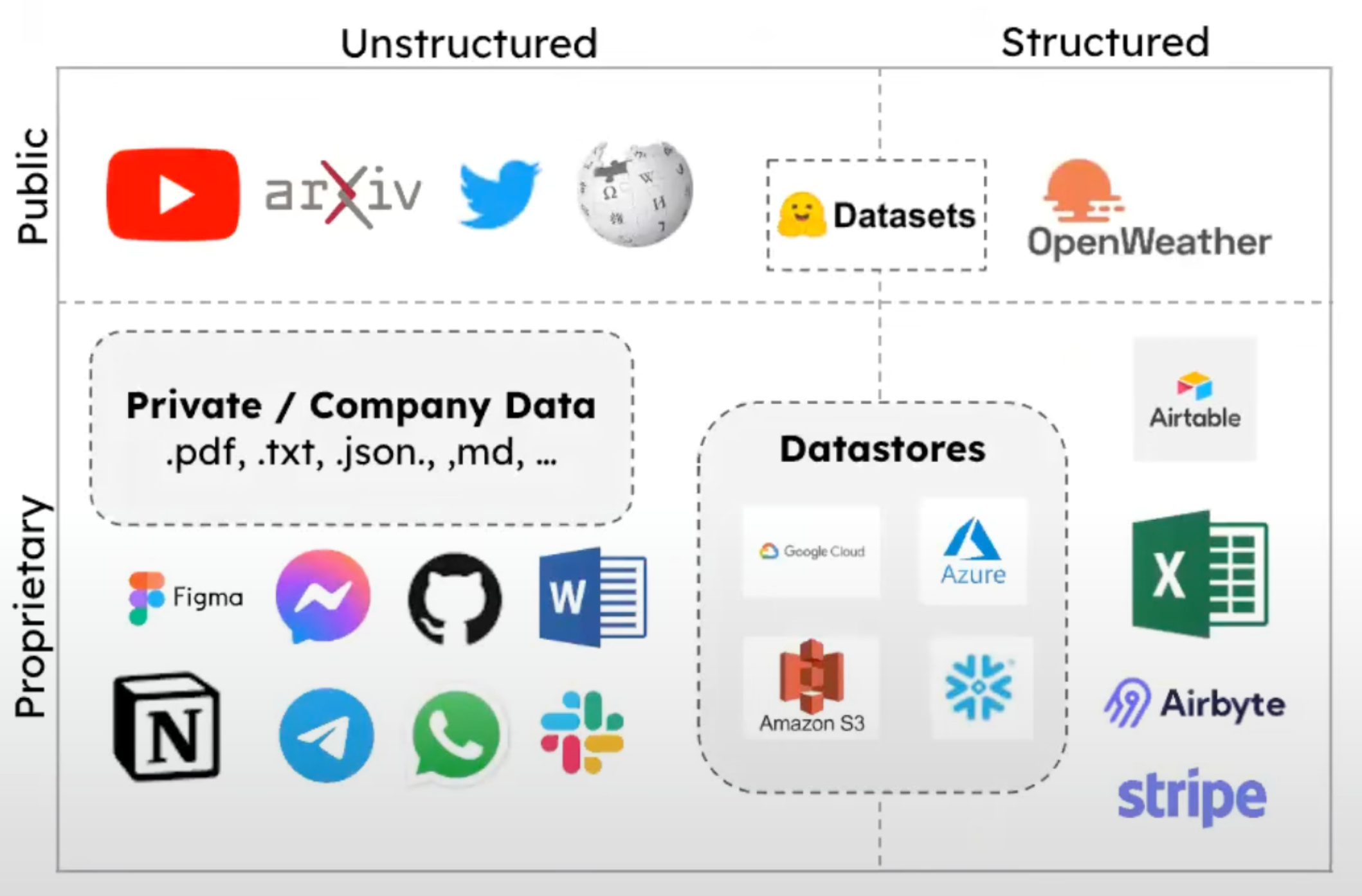
Catégories de chargeurs de documents
Les chargeurs de documents dans LangChain peuvent être globalement classés en deux types :
- Chargeurs basés sur le type de fichier
Analysent et chargent des documents basés sur des formats de fichiers spécifiques
Exemples : CSV, PDF, HTML, Markdown
2. Chargeurs basés sur la source de données
Récupèrent des données de diverses sources externes
Chargent les données dans des objets Document
Exemples : YouTube, Wikipedia, GitHub
Capacités d'intégration
Les chargeurs de documents de LangChain peuvent s'intégrer à presque tous les formats de fichiers dont vous pourriez avoir besoin.
Ils prennent également en charge de nombreuses sources de données tierces.
Pour notre projet, nous utiliserons le YoutubeLoader pour obtenir les transcriptions dans le format requis.
YoutubeLoader de LangChain pour obtenir la transcription :
## importer le chargeur de documents youtube de LangChain
from langchain_community.document_loaders import YoutubeLoader
video_url = 'https://www.youtube.com/watch?v=gaWxyWwziwE'
loader = YoutubeLoader.from_youtube_url(video_url, add_video_info=False)
data = loader.load()
Traiter la transcription YouTube
Afficher le contenu brut de la transcription
Utiliser le LLM pour résumer et extraire les points clés de la transcription :
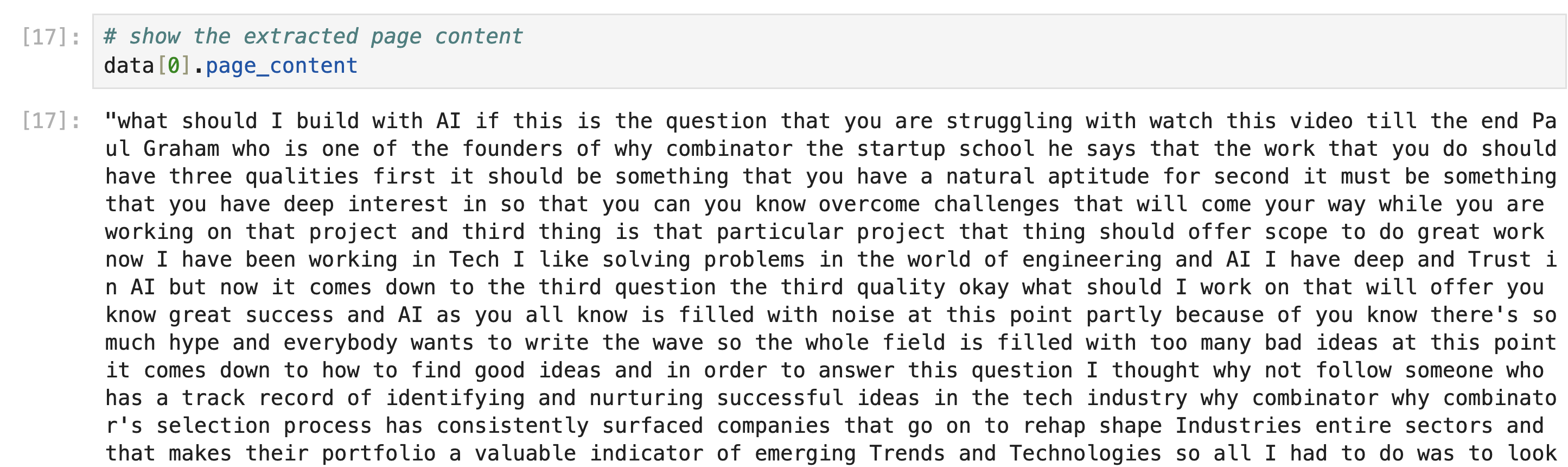
# afficher le contenu de la page extrait
data[0].page_content
L'attribut page_content contient la transcription complète comme indiqué dans la sortie ci-dessous :
Maintenant que nous avons la transcription, il nous suffit de la passer au LLM que nous avons configuré ci-dessus avec le prompt pour résumer.
Tout d'abord, comprenons une méthode simple :
Langchain propose la méthode invoke() à laquelle vous devez passer le message système et le message utilisateur ou humain.
Le message système est essentiellement les instructions pour le LLM sur la façon dont il est censé traiter la demande humaine.
Et le message humain est simplement ce que nous voulons que le LLM fasse.
# Ce code crée une liste de messages pour le modèle de langage :
# 1. Un message système avec des instructions sur la façon de résumer la transcription vidéo
# 2. Un message humain contenant la transcription vidéo réelle
# Les messages sont ensuite transmis au modèle de langage (llm) pour traitement
# La réponse du modèle est stockée dans la variable 'ai_msg' et renvoyée
messages = [
(
"system",
"""Lisez attentivement l'intégralité de la transcription.
Fournissez un résumé concis du sujet principal et de l'objectif de la vidéo.
Extrayez et listez les cinq points les plus intéressants ou importants de la transcription. Pour chaque point : Énoncez l'idée clé de manière claire et concise.
- Assurez-vous que votre résumé et vos points clés capturent l'essence de la vidéo sans inclure de détails inutiles.
- Utilisez un langage clair et engageant, accessible à un public général.
- Si la transcription comprend des données statistiques, des avis d'experts ou des idées uniques, donnez la priorité à leur inclusion dans votre résumé ou vos points clés.""",
),
("human", data[0].page_content),
]
ai_msg = llm.invoke(messages)
ai_msg
Mais cette méthode ne fonctionnera pas lorsque vous aurez plus de variables et que vous voudrez une solution plus dynamique.
Pour cela, LangChain propose PromptTemplate :
Un PromptTemplate dans LangChain est un outil puissant qui aide à créer des prompts dynamiques pour les grands modèles de langage (LLM). Il vous permet de définir un modèle avec des placeholders pour les variables qui peuvent être remplies avec des valeurs réelles au moment de l'exécution.
Cela aide à gérer et à réutiliser les prompts efficacement, assurant la cohérence et réduisant la probabilité d'erreurs lors de la création de prompts.
Un PromptTemplate se compose de :
Chaîne de modèle (Template String) : Le texte réel du prompt avec des placeholders pour les variables.
Variables d'entrée (Input Variables) : Une liste de variables qui seront remplacées dans la chaîne de modèle au moment de l'exécution.
# Configurer un modèle de prompt pour résumer une transcription vidéo en utilisant LangChain
# Importer les classes nécessaires depuis LangChain
from langchain.prompts import PromptTemplate
from langchain import LLMChain
# Définir un PromptTemplate pour résumer les transcriptions vidéo
# Le modèle inclut des instructions pour le modèle d'IA sur la façon de traiter la transcription
product_description_template = PromptTemplate(
input_variables=["video_transcript"],
template="""
Lisez attentivement l'intégralité de la transcription.
Fournissez un résumé concis du sujet principal et de l'objectif de la vidéo.
Extrayez et listez les cinq points les plus intéressants ou importants de la transcription.
Pour chaque point : Énoncez l'idée clé de manière claire et concise.
- Assurez-vous que votre résumé et vos points clés capturent l'essence de la vidéo sans inclure de détails inutiles.
- Utilisez un langage clair et engageant, accessible à un public général.
- Si la transcription comprend des données statistiques, des avis d'experts ou des idées uniques,
donnez la priorité à leur inclusion dans votre résumé ou vos points clés.
Transcription de la vidéo : {video_transcript} """
)
Comment utiliser LLMChain / LCEL pour le résumé
Une chaîne (chain) est une séquence d'étapes composée d'un modèle de langage, d'un PromptTemplate et d'un parseur de sortie optionnel.
Créer une
LLMChainavec le modèle de prompt personnaliséGénérer un résumé de la transcription vidéo en utilisant la chaîne
Ici, nous utilisons LLMChain mais vous pouvez également utiliser le LangChain Expression Language (LCEL) pour faire cela :
## invoquer la chaîne avec la transcription vidéo
chain = LLMChain(llm=llm, prompt=product_description_template)
# Exécuter la chaîne avec les détails de la vidéo fournis
summary = chain.invoke({
"video_transcript": data[0].page_content
})
Cela vous donnera l'objet summary qui possède l'attribut text contenant la réponse au format Markdown.
summary['text']
La réponse brute ressemblera à ceci :

Pour voir la réponse formatée en Markdown :
from IPython.display import Markdown, display
display(Markdown(summary['text']))
Et voilà :

Ainsi, la fonctionnalité de base de notre résumeur YouTube fonctionne maintenant.
Mais cela fonctionne dans votre Jupyter Notebook ; pour le rendre plus accessible, nous devrions déployer cette fonctionnalité sur WhatsApp.
Comment servir le résumeur YT sur WhatsApp

Pour cela, nous devrons servir notre fonctionnalité de résumé YT comme un point de terminaison API pour lequel nous allons utiliser Flask. Vous pouvez également utiliser FastAPI.
Maintenant, nous allons transformer tout le code du Jupyter Notebook en fonctions. Ainsi, ajoutez une fonction pour vérifier s'il s'agit d'une URL YouTube valide, puis définissez la fonction summarise qui est essentiellement une compilation de ce que nous avons écrit dans le notebook.
Vous pouvez configurer notre endpoint de la manière suivante :
@app.route('/summary', methods=['POST'])
def summary():
url = request.form.get('Body') # Récupérer les données du corps de la requête
print(url)
if is_youtube_url(url):
response = summarise(url)
else:
response = "veuillez vérifier s'il s'agit d'une URL de vidéo YouTube correcte"
print(response)
resp = MessagingResponse()
msg = resp.message()
msg.body(response)
return str(resp)
Une fois que votre app.py est prêt avec votre API Flask, lancez le script Python, et vous devriez avoir votre serveur fonctionnant localement sur votre système.
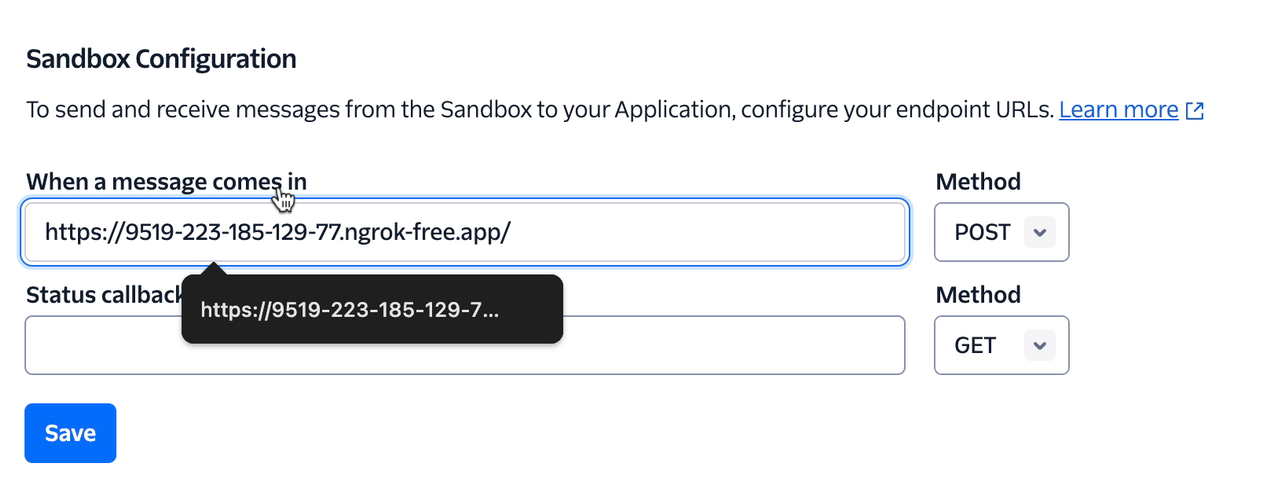
L'étape suivante consiste à connecter votre serveur local avec WhatsApp, et c'est là que nous utiliserons Twilio.
Twilio nous permet d'implémenter cette connexion en offrant un bac à sable (sandbox) WhatsApp pour tester votre bot. Vous pouvez suivre les étapes de ce guide ici pour construire cette connexion.
J'ai réussi à établir la connexion :
Maintenant, nous pouvons commencer à tester notre bot WhatsApp :
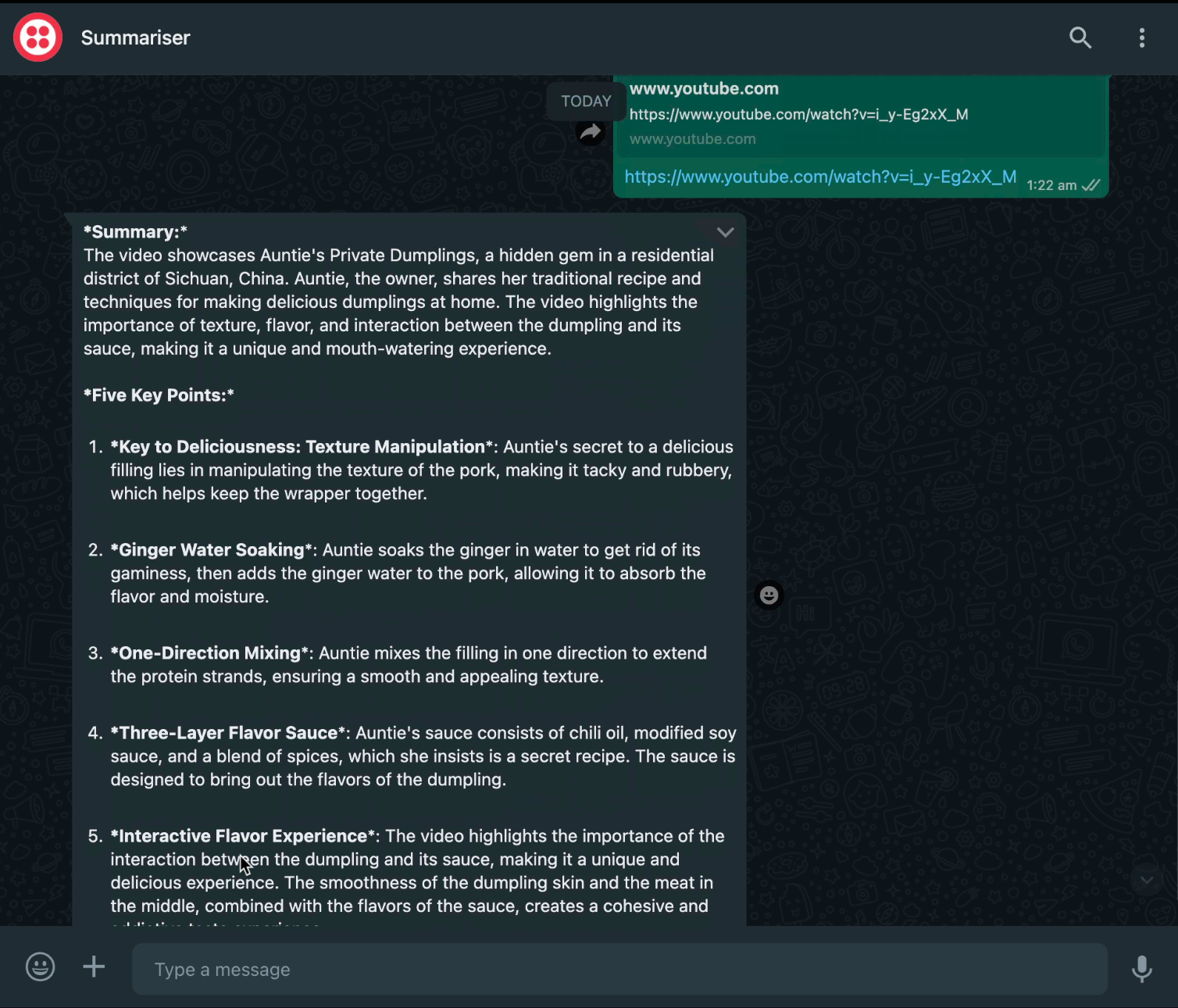
Incroyable !
J'explique toutes les étapes en détail dans mon cours basé sur des projets sur la construction de chatbots WhatsApp propulsés par LLM.
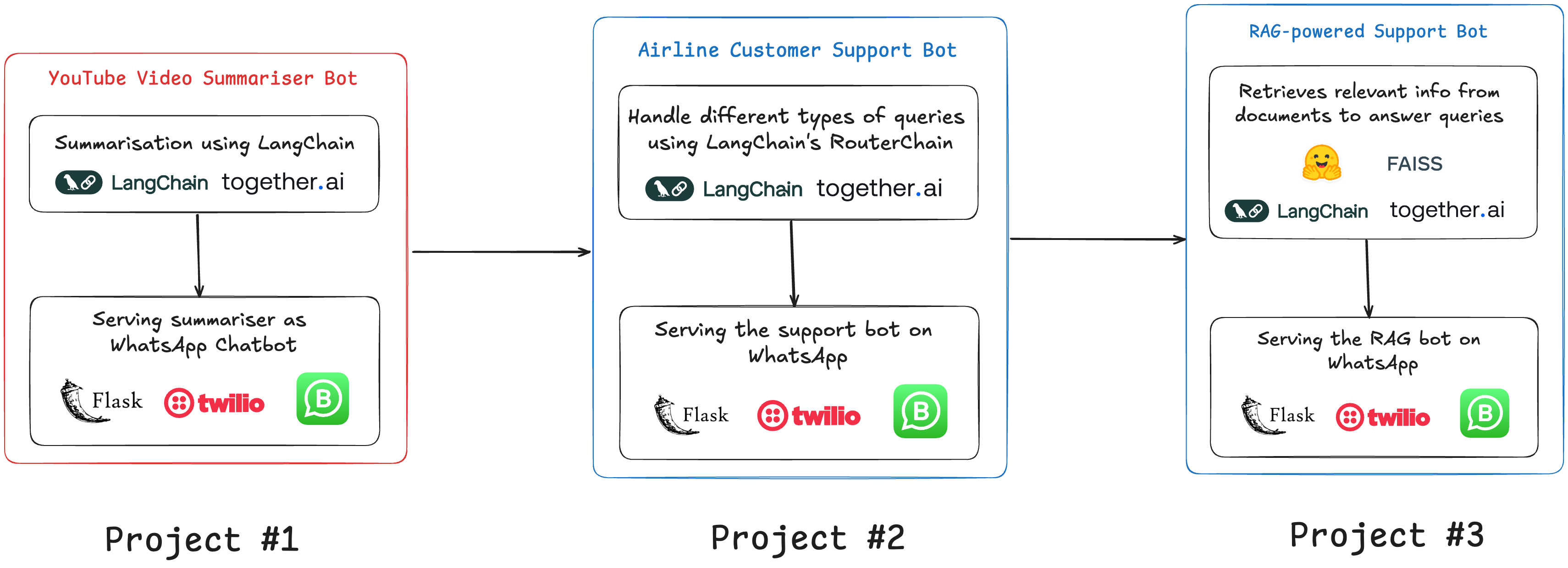
C'est un cours de 3 projets qui contient deux autres projets plus complexes. Je vais vous donner un bref résumé de ces autres projets ici afin que vous puissiez les essayer par vous-mêmes. Et si vous êtes intéressé, vous pouvez également consulter le cours.
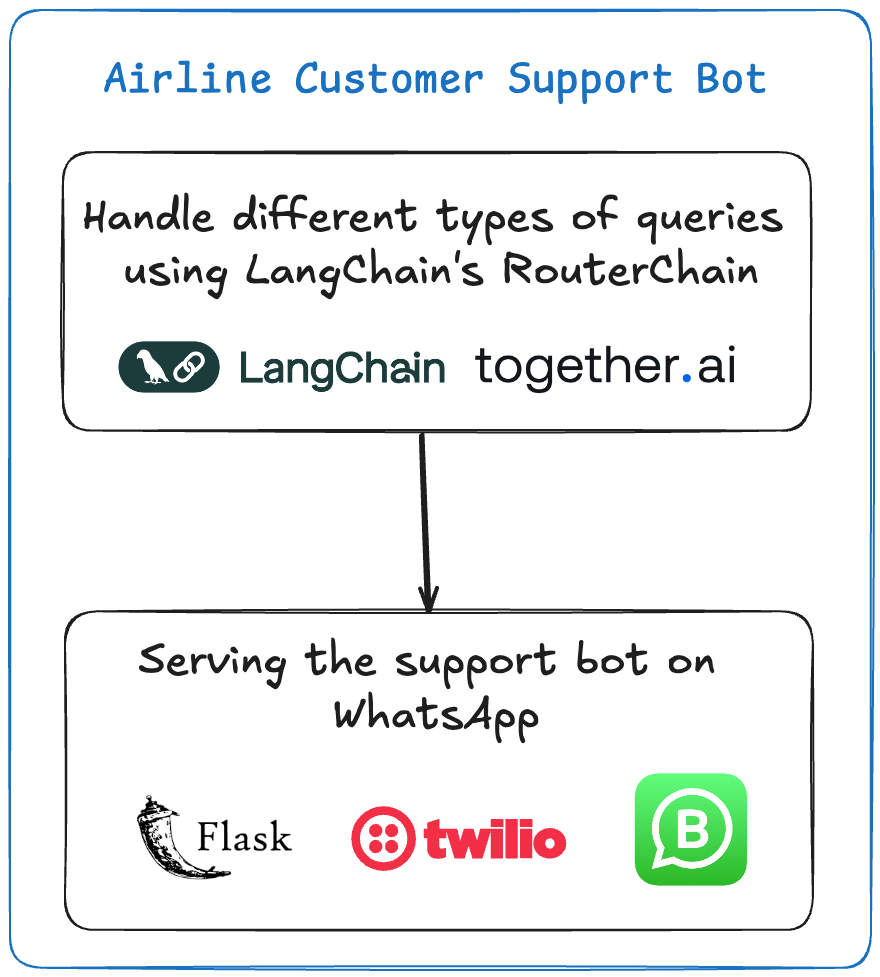
Projet n°2 — Construire un bot capable de gérer différents types de requêtes utilisateurs
Ce bot agit comme un représentant du service client pour une compagnie aérienne. Il peut répondre à des questions liées au statut des vols, aux demandes de bagages, à la réservation de billets, et plus encore. Il utilise le Router de LangChain et des modèles LLM pour générer dynamiquement des réponses basées sur l'entrée de l'utilisateur.
Différents modèles de prompts sont définis pour diverses requêtes clients, telles que le statut du vol, les demandes de bagages et les plaintes.
En fonction de la requête, le routeur sélectionne le modèle approprié et génère une réponse.
Twilio renvoie ensuite la réponse au chat WhatsApp.
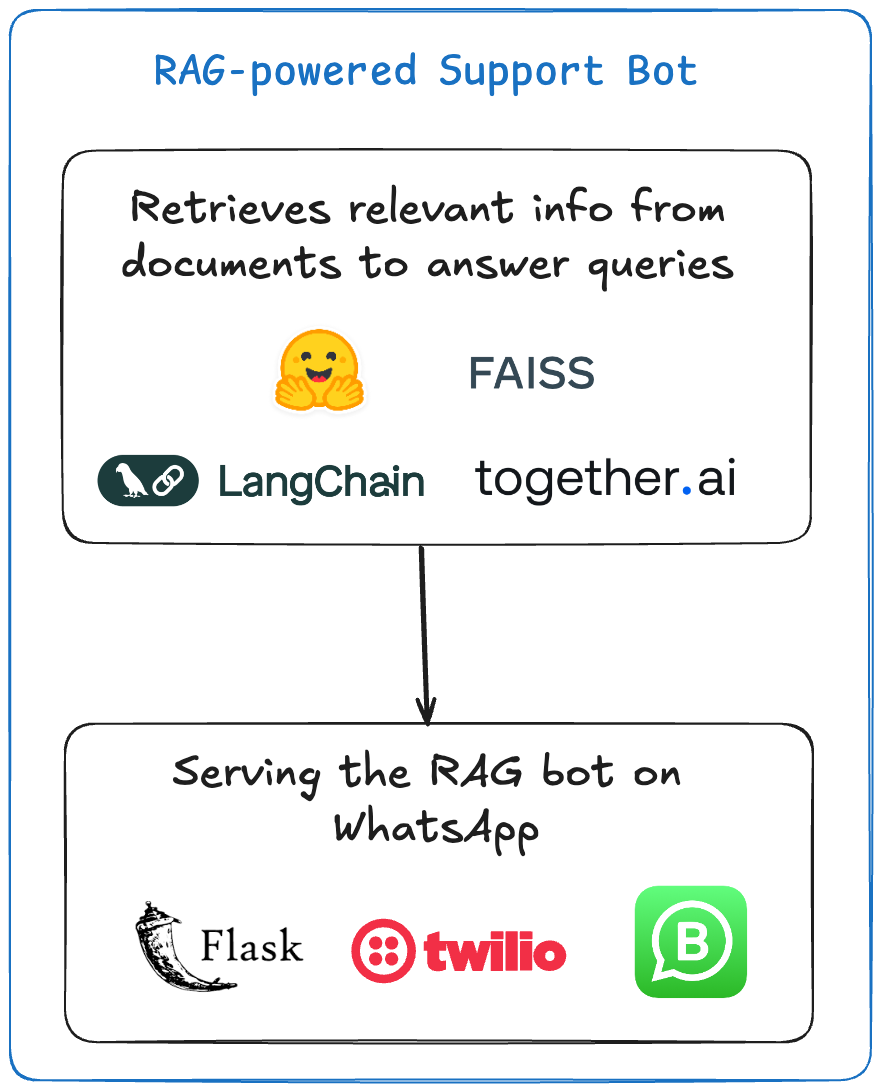
Projet n°3 — Bot de support propulsé par RAG
Ce chatbot répond aux questions liées aux services aériens en utilisant un système basé sur des documents. Le document est converti en embeddings, qui sont ensuite interrogés en utilisant le système RAG de LangChain pour générer des réponses. Les entreprises recherchent aujourd'hui des développeurs possédant ces compétences, c'est donc un projet particulièrement pratique.
Le document des directives/règles est incorporé en utilisant FAISS et les modèles HuggingFace.
Lorsqu'un utilisateur soumet une question, le système RAG récupère les informations pertinentes du document.
Le système génère ensuite une réponse en utilisant un LLM pré-entraîné et la renvoie via Twilio.
Ces 3 projets vous permettront de démarrer afin que vous puissiez continuer à expérimenter et à en apprendre davantage sur l'ingénierie de l'IA.
Le support client est la catégorie la plus financée en IA car elle réduit instantanément les coûts si l'IA peut gérer la communication avec les utilisateurs mécontents.
C'est pourquoi nous construisons des bots capables de gérer différents types de requêtes, des bots intelligents propulsés par RAG qui auront accès à des documents propriétaires pour fournir des informations à jour aux utilisateurs.
C'est pour cela que j'ai créé ce cours basé sur des projets pour vous aider à commencer à construire avec les LLM.
Consultez l'aperçu du cours ici :
Et pour vous remercier d'avoir lu ce guide, vous pouvez utiliser le code FREECODECAMP pour obtenir une réduction de 20 % sur mon cours.
Je veux rendre cela accessible à tous ceux qui souhaitent sincèrement construire avec l'IA, je l'ai donc proposé au prix abordable de 14,99 $ USD.
Conclusion
Dans ce tutoriel, nous nous sommes concentrés sur la construction d'un outil amusant de résumé de vidéos YouTube servi sur WhatsApp.
La fonctionnalité de base du bot comprend :
La réception d'une URL YouTube
La validation de l'URL
La récupération de la transcription de la vidéo
L'utilisation d'un LLM pour résumer le contenu
Le renvoi du résumé à l'utilisateur
Nous avons utilisé un certain nombre de packages Python, notamment langchain-together, langchain-community, langchain, pytube et youtube-transcript-api.
Le projet utilise le modèle Llama 3.1 via l'API de Together AI.
Nous avons construit la fonctionnalité de résumé de base en utilisant :
La méthode
invoke()de LangChain avec des messages système et humainsPromptTemplateetLLMChainpour des solutions plus dynamiques
Pour rendre l'outil accessible via WhatsApp :
La fonctionnalité est servie comme un point de terminaison API en utilisant Flask
Twilio est utilisé pour connecter le serveur local à WhatsApp
Un bac à sable WhatsApp est utilisé pour tester le bot
Pour continuer à construire d'autres projets, consultez le cours.
C'est un parcours pour débutants où vous commencez par apprendre à construire avec des LLM, puis appliquez ces compétences pour construire 3 types différents d'applications LLM. Pas seulement cela – vous apprenez à servir vos applications sous forme de chatbots WhatsApp (WA).