

Article original : How to Automate Machine Learning Model Publishing with the Gitlab Package Registry
Par Yacine Mahdid
Dans ce tutoriel, nous allons apprendre comment publier automatiquement des modèles de machine learning dans un registre de packages Gitlab et les rendre disponibles pour vos coéquipiers. Vous pouvez également utiliser cette technique pour partager une version packagée de votre code sous forme de binaire.
Si vous êtes un utilisateur débutant de Gitlab et que vous n'êtes pas familier avec les techniques CI/CD, ce tutoriel est fait pour vous ! Une compréhension de base du machine learning et du deep learning est un plus, mais ce n'est pas une exigence pour comprendre la partie publication CI/CD.
Voici ce que nous allons couvrir :
- Configuration du code Gitlab
- Code du réseau de neurones convolutionnel profond
- Code de reconnaissance d'images
- Méthodologie de branchement
- Téléchargement CI/CD
- Conclusion
D'abord, un peu de contexte
À un moment donné de votre carrière d'ingénieur en machine learning, vous devrez peut-être partager un modèle que vous avez entraîné avec d'autres développeurs. Il existe plusieurs façons de faire cela.
Donner accès au dépôt
Si vous ne craignez pas de montrer tout votre code, c'est une option très viable.
Si vous utilisez une bonne méthodologie de branchement, vos collègues n'auront besoin de regarder que la branche principale pour savoir quel est le modèle le plus à jour qu'ils peuvent utiliser. Ensuite, ils peuvent consulter le README.md pour apprendre comment l'utiliser.
Cependant, donner un accès complet au dépôt peut ne pas être une option viable pour vous.
Partager le dernier modèle manuellement
Une autre façon serait d'extraire le code pertinent que vous souhaitez rendre public et de l'envoyer manuellement.
Cela peut devenir un peu désordonné si vous travaillez avec plus d'une personne, car le modèle que vous envoyez peut ne pas être à jour. Cela vous met également à la charge de vous assurer que les gens utilisent toujours la dernière version de votre modèle.
Partager le dernier modèle automatiquement
Une solution plus simple, même dans le cas où le code du dépôt est disponible, est de confier la charge de packaging à un pipeline CI/CD.
C'est le sujet de ce tutoriel, et notre configuration ressemblera à ceci :
- Le dépôt de code, l'ensemble d'outils CI/CD et le registre de packages seront sur Gitlab
- Le code que nous allons packager sera un simple réseau de neurones PyTorch entraîné sur le jeu de données MNIST pour la reconnaissance de chiffres.
- Toutes les instructions et les exigences seront disponibles dans le package.
⚠️ Avertissement ⚠️ : Ce n'est pas ainsi que vous devriez déployer un modèle PyTorch prêt pour la production ! Pour apprendre comment faire cela, consultez ce tutoriel sur TorchScript.
Commençons.
Configuration du code Gitlab
Pour ce tutoriel, nous allons regrouper quatre fichiers :
- model.pth : qui est une version picklée de la dernière version du modèle entraîné.
- run_mnist.py : script Python simple pour exécuter le modèle afin de détecter un chiffre à partir d'une image png.
- requirements.txt : fichier texte contenant toutes les dépendances nécessaires pour exécuter le modèle.
- INSTRUCTION.md : instructions étape par étape pour utiliser le package.
Le package peut ensuite être utilisé librement par toute personne ayant accès au registre de packages et sera automatiquement mis à jour.
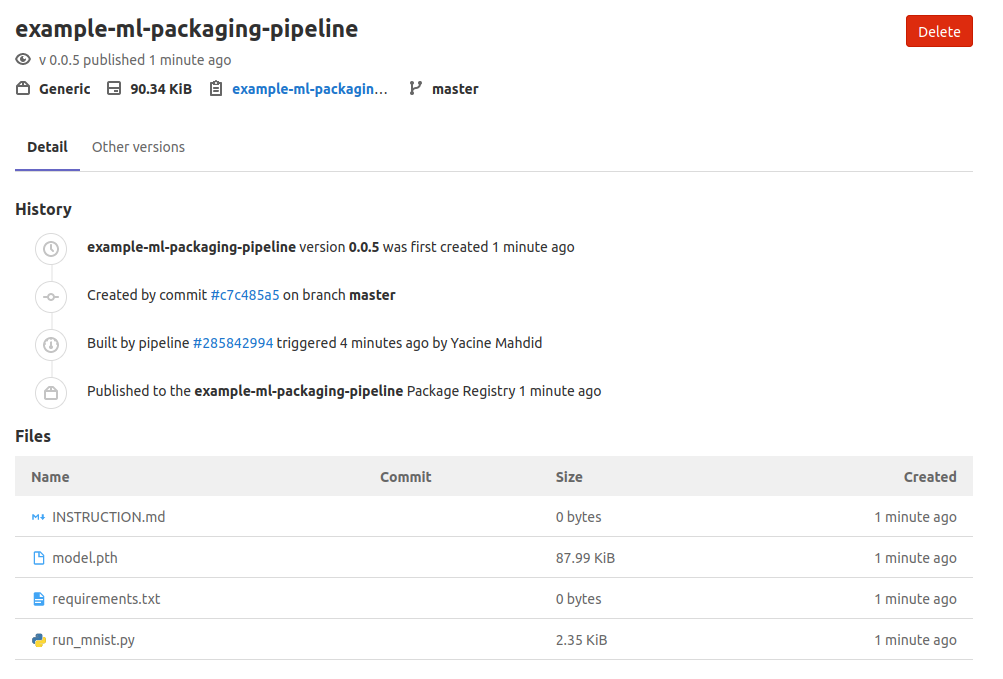 Le package ressemblera alors à ceci sur le registre de packages Gitlab !
Le package ressemblera alors à ceci sur le registre de packages Gitlab !
Plongeons dans le code du réseau de neurones, qui est une version modifiée de cet article complet sur la reconnaissance de chiffres. Le code modifié peut être trouvé sur mon dépôt public Gitlab.
Code du réseau de neurones convolutionnel profond
Dans la section ci-dessous, vous verrez beaucoup de terminologie sur les réseaux de neurones profonds. Ce n'est pas un tutoriel sur les réseaux de neurones, donc si vous vous sentez un peu submergé par les détails, vous pouvez sauter directement à la section Méthodologie de branchement.
Gardez simplement à l'esprit que nous avons entraîné une sorte de programme de reconnaissance d'images qui, étant donné un fichier .png représentant un chiffre, sera capable de vous dire quel nombre il contient.
Cependant, pour ceux qui veulent mieux comprendre comment les réseaux de neurones profonds fonctionnent sous le capot, vous pouvez consulter mon tutoriel où j'en construis un à partir de zéro ou consulter directement le code dans mon Github.
Définition du réseau de neurones
Le code de définition du réseau est très simple puisque le réseau que nous allons utiliser est simple. Il a les caractéristiques suivantes :
- 2 couches convolutionnelles.
- Dropout est appliqué sur la deuxième couche convolutionnelle.
- Fonctions d'activation Relu appliquées sur tous les neurones.
- 2 couches entièrement connectées à la fin pour l'inférence.
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# Définir le réseau
# C'est un réseau à 2 couches convolutionnelles avec dropout sur la 2ème et enfin 2 couches entièrement connectées
# Toutes les couches utilisent relu
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
Fonction d'entraînement
Nous avons ensuite créé une fonction d'entraînement utilitaire afin d'améliorer de manière itérative notre réseau défini en utilisant la descente de gradient. Si vous voulez en savoir plus sur le fonctionnement de la descente de gradient, consultez mon court tutoriel à ce sujet.
Ce régime d'entraînement fera ce qui suit :
- Itérer sur des lots de données d'entraînement représentant des chiffres de 28 par 28.
- Utiliser la fonction de coût de la log-vraisemblance négative pour calculer la perte.
- Calculer les gradients.
- Optimiser les poids du réseau en utilisant la descente de gradient.
- Sauvegarder le modèle à des intervalles fixes.
def train(network, optimizer, train_loader, epoch_id, log_interval=10):
"""Exécuter le régime d'entraînement sur l'ensemble d'entraînement en utilisant train_loader
Args:
network: Le réseau instancié.
optimizer: L'optimiseur utilisé pour changer les poids.
train_loader: le chargeur pour l'ensemble d'entraînement déjà configuré
epoch_id: l'id actuel de l'époque utilisé pour des raisons cosmétiques.
log_interval: intervalle auquel nous imprimons une sortie
Returns:
rien, sauvegardera directement au niveau racine l'état du modèle et de l'optimiseur
"""
# Mettre le réseau en mode entraînement
network.train()
# Itérer sur l'ensemble complet de l'ensemble d'entraînement
for batch_idx, (data, target) in enumerate(train_loader):
# Calculer les gradients pour ce lot de données
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
# Optimiser le réseau
optimizer.step()
# Journaliser et sauvegarder à chaque intervalle sélectionné
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch_id, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# Cela sauvegardera l'état sous forme d'objet picklé
torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
Les données pour l'entraînement peuvent être trouvées sur le site web de Yan LeCun. Ici, nous utilisons les jeux de données formatés en tenseurs PyTorch de 28 par 28 pour l'entraînement.
Fonction de test
La fonction suivante que nous créons est une fonction de test pour valider si notre réseau a appris quelque chose sans réutiliser les mêmes données d'entraînement. Cette fonction est simple dans le sens où elle comptera simplement les prédictions correctes et incorrectes.
def test(network, test_loader):
"""Exécuter le régime de test sur l'ensemble de test en utilisant test_loader
Args:
network: Le réseau instancié et entraîné.
test_loader: le chargeur pour l'ensemble de test déjà configuré
Returns:
rien, imprimera uniquement le résultat
"""
# Initialisation des variables
test_loss = 0
correct = 0
# Passer le réseau en mode évaluation au lieu de l'entraînement
network.eval()
# Configurer torch pour ne pas suivre de gradient
with torch.no_grad():
# Itérer sur toutes les données de test et accumuler la perte
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
# Calcul et impression de la perte moyenne
test_loss /= len(test_loader.dataset)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
Cette fonction sera utile pour vérifier à quel point notre réseau a appris après chaque itération d'entraînement.
Régime d'entraînement
Enfin, nous pouvons rassembler tout ce qui précède avec le corps principal du script d'entraînement ! Plusieurs choses se passent, mais les points les plus importants sont les suivants :
- Nous définissons nos hyperparamètres de manière statique. Une meilleure façon de les définir serait d'utiliser un ensemble de validation pour les déterminer en fonction des données.
- Nous créons notre chargeur de données qui ingérera les données et produira des tenseurs de la bonne forme pour le réseau. Ces chargeurs transformeront les données en les normalisant avec la moyenne globale et l'écart-type des jeux de données MNIST.
- Nous utilisons la descente de gradient stochastique avec momentum comme méthode d'optimisation, qui est l'une des nombreuses variantes de la descente de gradient que nous pouvons utiliser.
- Nous parcourons l'ensemble complet des données d'entraînement "epoch", la durée d'entraînement du réseau tout en testant sur les jeux de données de test mis de côté.
# Paramètres expérimentaux que nous pouvons ajuster
n_epochs = 3
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
# Variable du jeu de données qui devrait rester telle quelle
global_mean_mnist = 0.1307
global_std_mnist = 0.3081
# Graine aléatoire pour l'expérimentation reproductible
random_seed = 42
torch.backends.cudnn.enabled = False
torch.manual_seed(random_seed)
# Chargeur de données pour collecter les données puis les normaliser
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(global_mean_mnist,), (global_std_mnist,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(global_mean_mnist,), (global_std_mnist,))
])),
batch_size=batch_size_test, shuffle=True)
# Initialiser le réseau et l'optimiseur
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
# Tester d'abord pour montrer que le modèle n'a rien appris
test(network, test_loader)
# Entraîner sur l'ensemble du jeu de données plusieurs fois et tester
for epoch_id in range(1, n_epochs + 1):
train(network, optimizer, train_loader, epoch_id)
test(network, test_loader)
Notez qu'il est très important de tester votre réseau sur un ensemble mis de côté pour éviter le sur-apprentissage sur les données d'entraînement.
Tous les scripts ci-dessus peuvent être trouvés dans le fichier train_mnist.py dans le dépôt.
À ce stade, nous pouvons entraîner un modèle et le sauvegarder à intervalles réguliers dans un format picklé.
Nous pouvons maintenant utiliser ce modèle entraîné sauvegardé pour évaluer un chiffre dans un fichier .png.
Code de reconnaissance d'images
Supposons que nous avons en entrée l'image suivante :
 un petit chiffre 0
un petit chiffre 0
ou celle-ci :
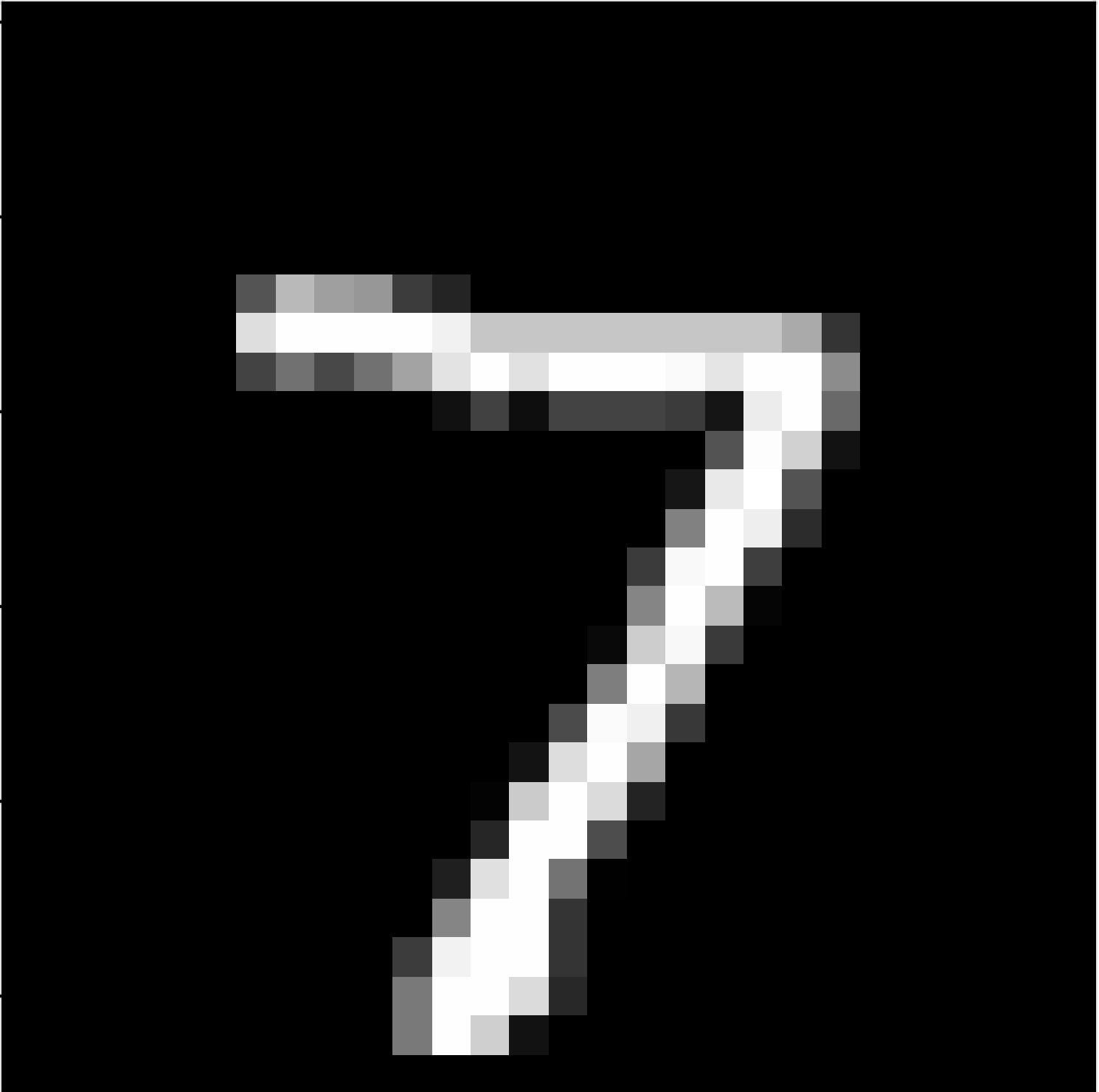 un plus grand chiffre 7
un plus grand chiffre 7
Comment pouvons-nous faire en sorte que notre réseau, qui fonctionne sur un tenseur PyTorch de 28 par 28, évalue les nombres ?
C'est assez simple si nous suivons à peu près le même processus que les jeux de données d'entraînement, qui est :
- Avoir des images en niveaux de gris (pas de canaux de couleur ou alpha)
- Redimensionner les images pour qu'elles soient de 28 par 28 pixels
- Normaliser les images en utilisant la moyenne et l'écart-type des jeux de données MNIST.
if __name__ == "__main__":
# Initialisation des variables
global_mean_mnist = 0.1307
global_std_mnist = 0.3081
# Chargement du réseau avec les bons poids
result_path = './model.pth'
model = Net()
model.load_state_dict(torch.load(result_path))
model.eval()
# Configuration de la transformation de l'image en tenseurs normalisés
transform = transforms.Compose([
transforms.Resize((28,28)),
transforms.ToTensor(),
transforms.Normalize(
(global_mean_mnist,), (global_std_mnist,))
])
# Analyse de l'entrée de l'utilisateur qui devrait être un nom de fichier avec le flag --image
parser = OptionParser()
parser.add_option("--image", dest = "input_image_path",
help = "Chemin de l'image d'entrée")
(options, args) = parser.parse_args()
# Obtenir le chemin de l'image à décoder
input_image_path = str(options.input_image_path)
# Ouvrir l'image(s) et faire l'inférence
images=glob.glob(input_image_path)
for image in images:
# Convertir l'image en niveaux de gris
img = Image.open(image).convert('L')
# Transformer l'image en tenseur normalisé
img_tensor = transform(img).unsqueeze(0)
# Faire et imprimer la prédiction
output = model(img_tensor).data.max(1, keepdim=True)[1][0][0]
print(f"L'image est un {int(output)}")
Comme vous pouvez le voir, nous utilisons un parseur pour accepter un chemin d'image sur la ligne de commande avant d'appliquer nos transformations. Une fois qu'elles sont appliquées, nous pouvons alimenter cela dans notre modèle chargé et collecter la prédiction de sortie.
⚠️ N'oubliez pas d'inclure la définition du réseau dans le script (en important ou en copiant-collant), sinon le modèle picklé ne pourra pas se charger correctement.
Nous pouvons maintenant exécuter notre code comme ceci :
python run_mnist.py --image NOM_DE_LIMAGE.png
Cela imprimera simplement l'inférence du modèle sur ce que contient cette image particulière.
Maintenant que nous avons le code d'entraînement et d'évaluation de base configuré, discutons un peu plus de la façon d'utiliser le branchement git à notre avantage pour publier ce modèle dans le registre de packages.
Méthodologie de branchement
Si vous travaillez seul sur un projet, il est très tentant de simplement commiter sur master/main et en finir avec ça. Cependant, cette façon de travailler est très difficile à maintenir et elle rend l'incorporation d'outils CI/CD appropriés pénible.
Une stratégie de branche main / develop comme illustré ci-dessous est plus maintenable :
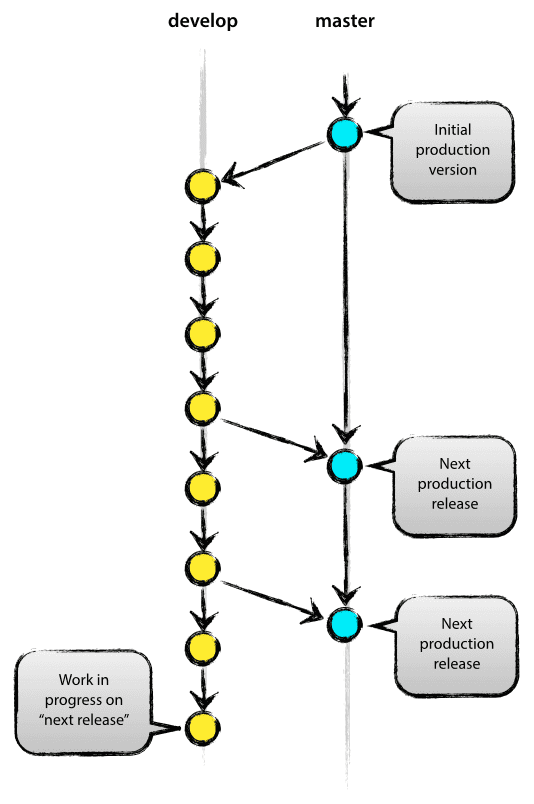 Image de : https://nvie.com/posts/a-successful-git-branching-model/
Image de : https://nvie.com/posts/a-successful-git-branching-model/
En gardant toujours la branche principale propre, nous pouvons facilement déclencher notre pipeline CI/CD dès que nous poussons sur la branche principale. Nous serons également libres de commiter autant que nécessaire dans la branche develop pendant que nous améliorons nos modèles.
Lorsque nous sommes prêts pour un nouveau déploiement, nous n'aurons besoin que de fusionner avec la branche principale (ou mieux encore, faire une demande de fusion / pull-request puis fusionner).
Cette fusion avec la branche principale devrait déclencher Gitlab pour télécharger la nouvelle version de notre modèle dans le registre de packages.
Examinons la manière simple d'automatiser la publication dans le registre de packages en utilisant le fichier .gitlab-ci.yml.
Pipeline CI/CD
Le fichier .gitlab-ci.yml est un fichier spécial dans votre dépôt utilisé par Gitlab pour définir ce que le serveur Gitlab doit faire lorsque vous poussez vers un dépôt.
Pour en savoir plus sur le fonctionnement de CI/CD dans Gitlab, rendez-vous sur ce cours accéléré sur Gitlab CI/CD.
Dans ce tutoriel, notre fichier .gitlab-ci.yml ressemble à ceci :
image: pytorch/pytorch
variables:
VERSION: "0.0.4" # À changer si nécessaire
stages:
- upload
upload:
stage: upload
only:
- master
script:
- apt-get update
- apt-get install -y curl wget
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./model.pth "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/model.pth"'
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./run_mnist.py "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/run_mnist.py"'
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./requirements.txt "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/requirements.txt"'
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./INSTRUCTION.md "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/INSTRUCTION.md"'
L'anatomie de ce fichier .yml est très basique. Nous n'avons qu'une seule étape dans notre pipeline qui est l'étape upload.
Dans l'étape de téléchargement, nous exécuterons la section script uniquement lorsque la branche master est mise à jour. Le script que nous avons exécuté utilise simplement curl pour transférer les données de ce dépôt (4 fichiers) dans le registre de packages.
Examinons l'anatomie de la commande curl que nous utilisons :
- 'curl --header "JOB-TOKEN: $CI_JOB_TOKEN" --upload-file ./NOM_DU_FICHIER "${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/NOM_DU_FICHIER"'
--headerest utilisé pour indiquer à curl que vous inclurez un en-tête supplémentaire à la requête.JOB-TOKENest notre en-tête et$CI_JOB_TOKENest sa valeur. C'est une variable qui vit dans les serveurs Gitlab lorsqu'un travail est créé--upload-fileest un flag pour indiquer que nous allons transférer un fichier local vers l'URL distante../NOM_DU_FICHIERest le nom du fichier local que nous voulons transférer.${CI_API_V4_URL}/projects/${CI_PROJECT_ID}/packages/generic/example-ml-packaging-pipeline/${VERSION}/NOM_DU_FICHIERest l'emplacement de l'URL distante vers laquelle nous voulons transférer un fichier.
Ici, $CI_API_V4_URL est l'URL de l'API Gitlab que nous utilisons, $CI_PROJECT_ID est défini dans Gitlab CI comme l'id pour notre projet, et enfin VERSION est le numéro de version que nous avons défini en haut du fichier .yml.
C'est tout ! Lorsque vous mettez à jour la branche principale vers le dépôt distant sur Gitlab, cela déclenchera un pipeline qui exécutera votre travail de packaging.
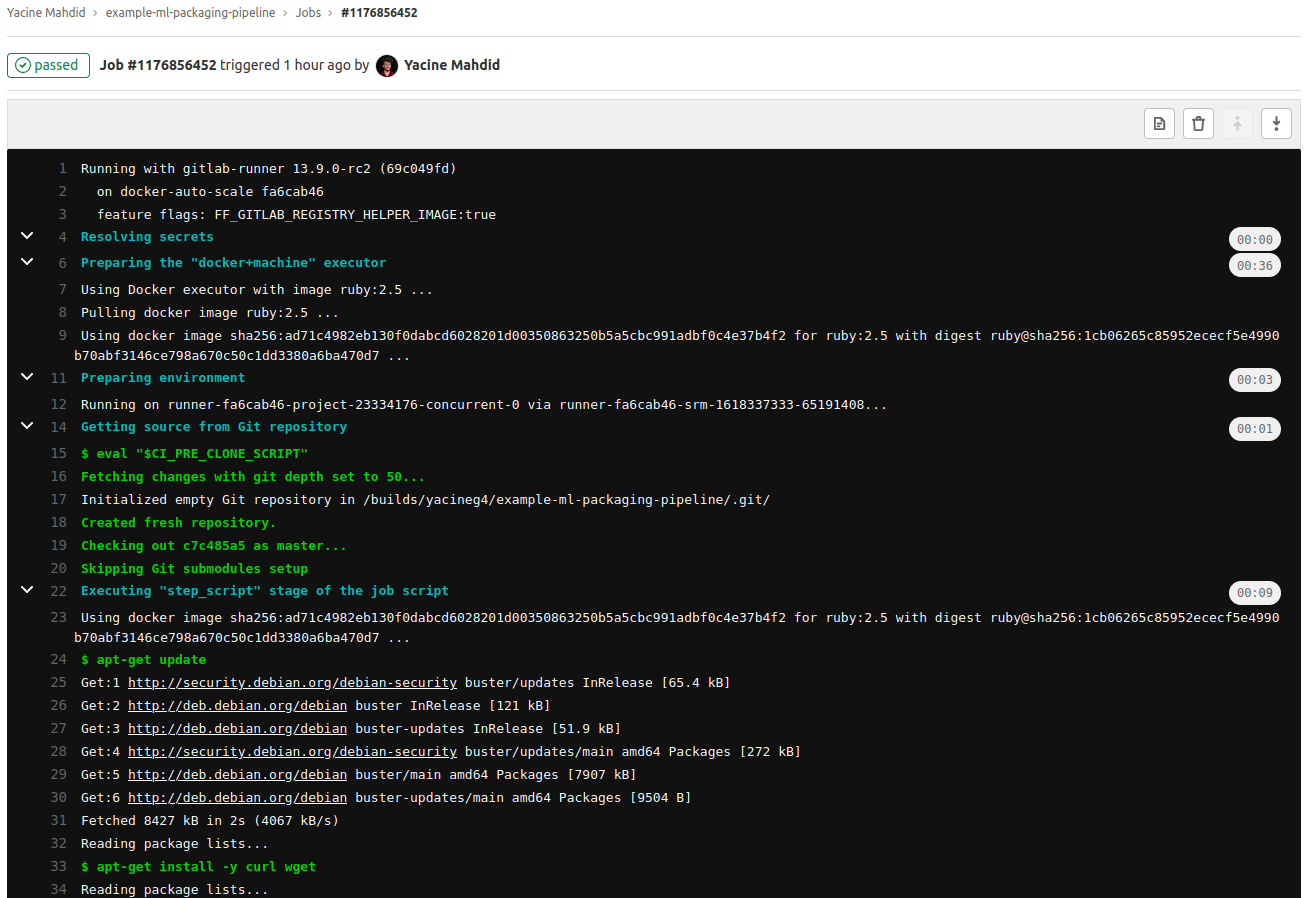 Le travail sera alors disponible et vous pourrez vérifier la trace sur Gitlab !
Le travail sera alors disponible et vous pourrez vérifier la trace sur Gitlab !
Vous et vos coéquipiers pourrez voir le document dans la section du registre de packages et obtenir les bons fichiers versionnés dans le package :
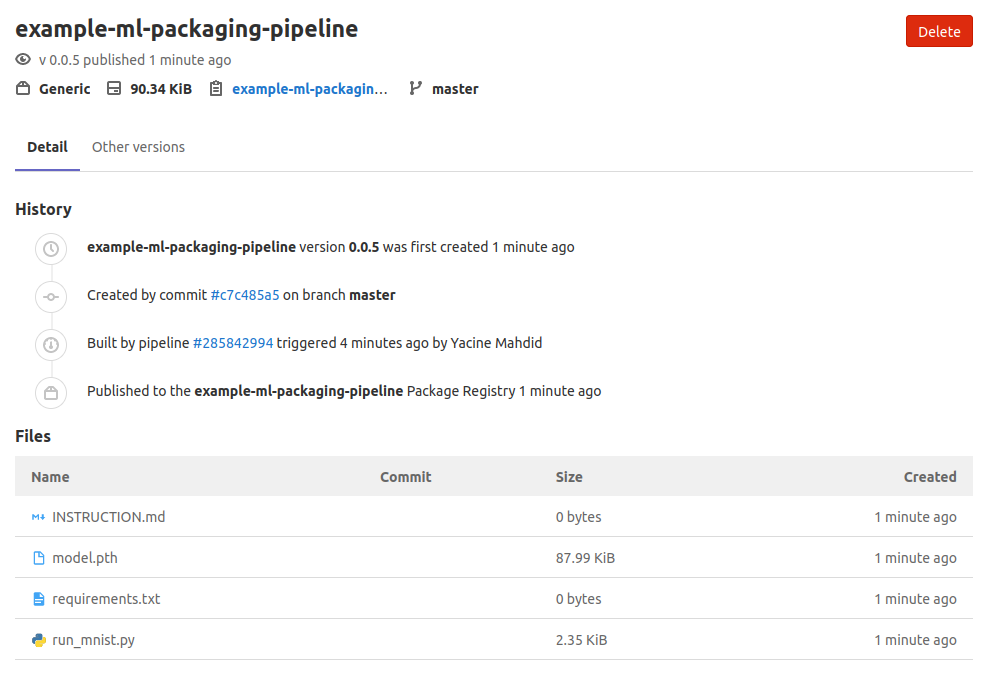 C'est notre v.0.0.5 du package exemple !
C'est notre v.0.0.5 du package exemple !
Pour avoir une idée plus complète de ce qui est possible avec l'API Packages, rendez-vous sur la documentation officielle.
Conclusion
Dans ce tutoriel, vous avez appris comment regrouper, télécharger et automatiser le packaging d'un modèle de machine learning en utilisant Gitlab CI/CD.
Félicitations ! 🎉🎉🎉
Il y a encore beaucoup plus de choses que vous pouvez faire avec Gitlab CI/CD, par exemple :
- Ajouter une étape de test avant le regroupement afin de vous assurer qu'il n'y a pas de régression dans le code.
- Ajouter une étape de test après le regroupement pour vous assurer que les performances de votre modèle sont satisfaisantes en termes de latence d'inférence.
- Utiliser une version plus optimisée du modèle avec TorchScript.
- Ajouter une notification sociale automatique de nouvelle version après l'étape de téléchargement.
Pour en savoir plus sur Gitlab CI/CD, la documentation officielle est un excellent point de départ, et la section de démarrage est très adaptée aux débutants.
Si vous voulez lire plus de ce type de contenu, consultez mes articles sur l'ingénierie mécanique/logicielle. Si vous voulez discuter de tout cela, n'hésitez pas à m'envoyer un DM sur LinkedIn ou Twitter 😊