


Article original : How to Automate Documentation Conversion with Pandoc in CI/CD Pipelines
Dans tout projet logiciel, la documentation joue un rôle crucial en guidant les développeurs, les utilisateurs et les parties prenantes à travers les fonctionnalités et les fonctionnalités du projet.
À mesure que les projets grandissent et évoluent, la gestion de la documentation dans divers formats—qu'il s'agisse de markdown, HTML ou PDF pour une utilisation hors ligne—peut devenir une tâche chronophage et sujette aux erreurs.
Pandoc est un outil puissant qui permet de convertir la documentation entre différents formats de manière transparente.
Néanmoins, même avec Pandoc, la conversion manuelle des fichiers pour chaque mise à jour peut devenir un goulot d'étranglement dans les grands projets ou les équipes où la documentation est fréquemment mise à jour.
Dans cet article, je vais vous guider à travers la configuration de scripts shell, l'utilisation de Makefiles et l'intégration de Pandoc dans les pipelines CI/CD pour rationaliser votre flux de travail et maintenir votre documentation à jour avec un effort minimal.
Table des matières

Pourquoi automatiser la conversion de documentation ?
La conversion manuelle de la documentation entre différents formats dans les grands projets peut devenir une tâche ardue.
Que vous génériez des versions HTML, PDF ou DOCX à partir de la même source, la répétition de ce processus pour chaque mise à jour entraîne divers défis :
Chronophage : Exécuter manuellement des commandes pour convertir la documentation à chaque modification prend du temps de développement précieux lorsque les mises à jour sont fréquentes.
Sujet aux erreurs : Le processus manuel augmente la probabilité de faire des erreurs, comme utiliser des commandes incorrectes, sauter des étapes ou générer des versions obsolètes de votre documentation. Ces incohérences peuvent semer la confusion tant chez les développeurs que chez les utilisateurs finaux.
Difficile à mettre à l'échelle : À mesure que les projets grandissent, la gestion des documents dans différents formats sans automatisation peut devenir ingérable. Les équipes travaillant en parallèle peuvent avoir du mal à maintenir la documentation synchronisée, entraînant des incohérences entre les formats.

En automatisant le processus de conversion avec des outils comme Pandoc, vous pouvez surmonter ces défis et profiter d'une série d'avantages :
Cohérence : L'automatisation garantit que toutes les versions de votre documentation sont toujours à jour et précises. Peu importe le nombre de formats que vous générez, le processus reste standardisé.
Efficacité : Les flux de travail automatisés libèrent du temps en gérant les tâches répétitives en arrière-plan, permettant aux équipes de se concentrer sur le développement plutôt que sur la gestion manuelle des mises à jour de la documentation.
Évolutivité : Avec l'automatisation, il est simple de mettre à l'échelle les efforts de documentation à mesure que votre projet grandit. Que vous mainteniez un seul document ou une bibliothèque entière de ressources, l'automatisation garantit que tout reste synchronisé avec un effort minimal.
La section suivante explore comment automatiser le processus de conversion.
Comment automatiser Pandoc en utilisant des scripts Shell
En utilisant des scripts shell, vous pouvez rationaliser le processus d'exécution des commandes PanDoc, en gagnant du temps et en réduisant le risque d'erreurs associé à l'exécution manuelle des commandes.
Script Shell de base pour la conversion PanDoc
Pour commencer, nous allons créer un script shell qui convertit un seul fichier Markdown dans divers formats.
Par exemple, voici un script qui convertit input.md en HTML et PDF :
#!/bin/bash
# Convertir input.md en HTML et PDF
pandoc input.md -o output.html
pandoc input.md -o output.pdf
echo "Conversion terminée !"
Dans le script ci-dessus :
La ligne
#!/bin/bashindique que le script doit être exécuté en utilisant le shell Bash.Les commandes pandoc convertissent le fichier
input.mdenoutput.htmletoutput.pdf.La commande
echoconfirme que le processus de conversion est terminé.
Personnalisation du script pour plusieurs fichiers
Si vous souhaitez convertir tous les fichiers Markdown dans un répertoire, vous pouvez personnaliser votre script pour traiter plusieurs fichiers à la fois.
Par exemple, voici un script qui convertit input.md en HTML et PDF :
#!/bin/bash
# Parcourir tous les fichiers Markdown présents dans le répertoire courant
for file in *.md; do
# Convertir chaque fichier Markdown en PDF
pandoc "$file" -o "${file%.md}.pdf"
done
echo "Toutes les conversions sont terminées !"
Dans ce script :
La boucle
foritère sur chaque fichier.mddans le répertoire courant.La commande
pandocconvertit chaque fichier Markdown en PDF, en conservant le nom de fichier d'origine mais en changeant l'extension en.pdfavec la syntaxe${file%.md}.pdf.Le
echofinal confirme que toutes les conversions sont terminées.
Ajout de la gestion des erreurs et de la logique complexe
Pour améliorer la robustesse de votre script, vous pouvez ajouter la gestion des erreurs et une logique supplémentaire.
Par exemple, peut-être souhaitez-vous vous assurer que Pandoc est installé avant de continuer, et gérer les cas où le fichier d'entrée peut être manquant.
Le script sera le suivant :
#!/bin/bash
# Vérifier si Pandoc est installé
if ! command -v pandoc &> /dev/null; then
echo "Pandoc n'est pas installé. Veuillez l'installer et réessayer."
exit 1
fi
# Parcourir tous les fichiers Markdown présents dans le répertoire courant
for file in *.md; do
if [ -e "$file" ]; then
# Convertir chaque fichier Markdown en PDF
pandoc "$file" -o "${file%.md}.pdf"
echo "Converti $file en PDF."
else
echo "Aucun fichier Markdown trouvé."
fi
done
echo "Toutes les conversions sont terminées !"
Dans ce script amélioré :
La ligne
if ! command -v pandoc &> /dev/null; thenvérifie si Pandoc est installé.L'instruction
if [ -e "$file" ]; thenvérifie si chaque fichier Markdown existe avant de tenter de le convertir.Un message informatif est imprimé après chaque conversion réussie, fournissant un retour sur le processus.
À mesure que votre projet grandit en complexité, le fait de s'appuyer uniquement sur des scripts shell pour l'automatisation peut devenir difficile à gérer lorsqu'il s'agit de nombreux fichiers et de mises à jour fréquentes.
C'est là que les Makefiles deviennent pratiques.
Automatisation avec Makefiles
Un Makefile est un fichier spécial qui définit des règles et des commandes pour automatiser des tâches dans un projet.
Il est largement utilisé par les développeurs pour compiler du code, mais les développeurs peuvent également l'utiliser pour des tâches non liées à la compilation, telles que la conversion de formats de documentation avec Pandoc.
Un Makefile pour les conversions Pandoc
Voici un exemple de la manière dont vous pouvez créer un Makefile pour automatiser les conversions Pandoc :
all: html pdf
html:
pandoc input.md -o output.html
pdf:
pandoc input.md -o output.pdf
Dans ce Makefile :
allest la cible par défaut. Lorsque vous exécutezmakesans spécifier de cible, il exécutera les cibleshtmletpdfséquentiellement.La cible
htmlexécute une commande PanDoc pour convertirinput.mdenoutput.html.La cible
pdfexécute une commande PanDoc pour convertirinput.mdenoutput.pdf.
Pour utiliser ce Makefile, exécutez la commande suivante dans votre terminal :
codemake
Cela exécutera les cibles html et pdf, convertissant le fichier Markdown dans les deux formats.
Définition des dépendances dans les Makefiles
L'un des principaux atouts des Makefiles est leur capacité à gérer les dépendances.
Dans le contexte de la conversion de documentation, vous pouvez spécifier quels fichiers mettre à jour lorsque vous détectez des changements dans le fichier source.
Examinons un exemple :
output.html: input.md
pandoc input.md -o output.html
output.pdf: input.md
pandoc input.md -o output.pdf
Dans ce Makefile :
Les fichiers
output.htmletoutput.pdfdépendent deinput.md.Si vous exécutez make output.html ou make output.pdf, Pandoc régénérera le fichier correspondant si vous mettez à jour
input.mdaprès la dernière fois où vous avez créé le fichier de sortie.
Cela garantit que Pandoc convertit uniquement les fichiers qui ont changé, ce qui fait gagner du temps lors de la gestion de grands projets de documentation.
Pourquoi utiliser les Makefiles pour l'automatisation Pandoc ?
Les Makefiles offrent plusieurs avantages pour l'automatisation des conversions Pandoc dans les grands projets :
Efficacité : Les Makefiles reconstruisent uniquement ce qui est nécessaire, ce qui signifie que vous ne perdrez pas de temps à convertir des fichiers qui n'ont pas changé.
Simplicité : Une fois configuré, l'exécution de
makesimplifie le processus de conversion à une seule commande, facilitant ainsi la maintenance de flux de travail de documentation cohérents pour les équipes.Évolutivité : À mesure que votre projet grandit, vous pouvez ajouter plus de cibles et de dépendances au Makefile, automatisant tout, de la documentation à des processus de construction plus complexes.
Les Makefiles sont une excellente option pour automatiser les conversions de documentation, lorsqu'ils sont combinés avec Pandoc pour des sorties multi-formats.
Ils aident à garantir que votre flux de travail est efficace et que votre documentation reste à jour.
À mesure que les pratiques de développement modernes s'appuient de plus en plus sur l'intégration continue et le déploiement continu (CI/CD), l'automatisation des tâches de routine telles que la génération de documentation devient essentielle.

L'intégration de Pandoc dans vos pipelines CI/CD permet une conversion et des mises à jour de documentation transparentes, garantissant que vos documents sont toujours à jour sans intervention manuelle.
En automatisant ce processus, vous pouvez vous concentrer sur le codage et la construction, tandis que votre pipeline gère la conversion et la distribution de votre documentation de projet. Explorons comment configurer Pandoc dans un pipeline CI/CD pour rationaliser vos flux de travail de documentation.
Comment intégrer Pandoc avec les pipelines CI/CD
L'automatisation de la génération de documentation dans votre pipeline CI/CD apporte des avantages significatifs, notamment la cohérence, l'efficacité et les mises à jour sans intervention manuelle.
Que vous utilisiez GitHub Actions, GitLab CI, Jenkins, ou un autre outil d'automatisation, l'intégration de Pandoc garantit que la documentation est générée et distribuée chaque fois que des changements se produisent.
Cette approche réduit le risque de documentation obsolète ou incohérente.
Exemple : Configuration de Pandoc avec GitHub Actions
Parcourons un exemple clair de la manière dont vous pouvez utiliser GitHub Actions pour automatiser le processus de génération de documentation avec Pandoc.
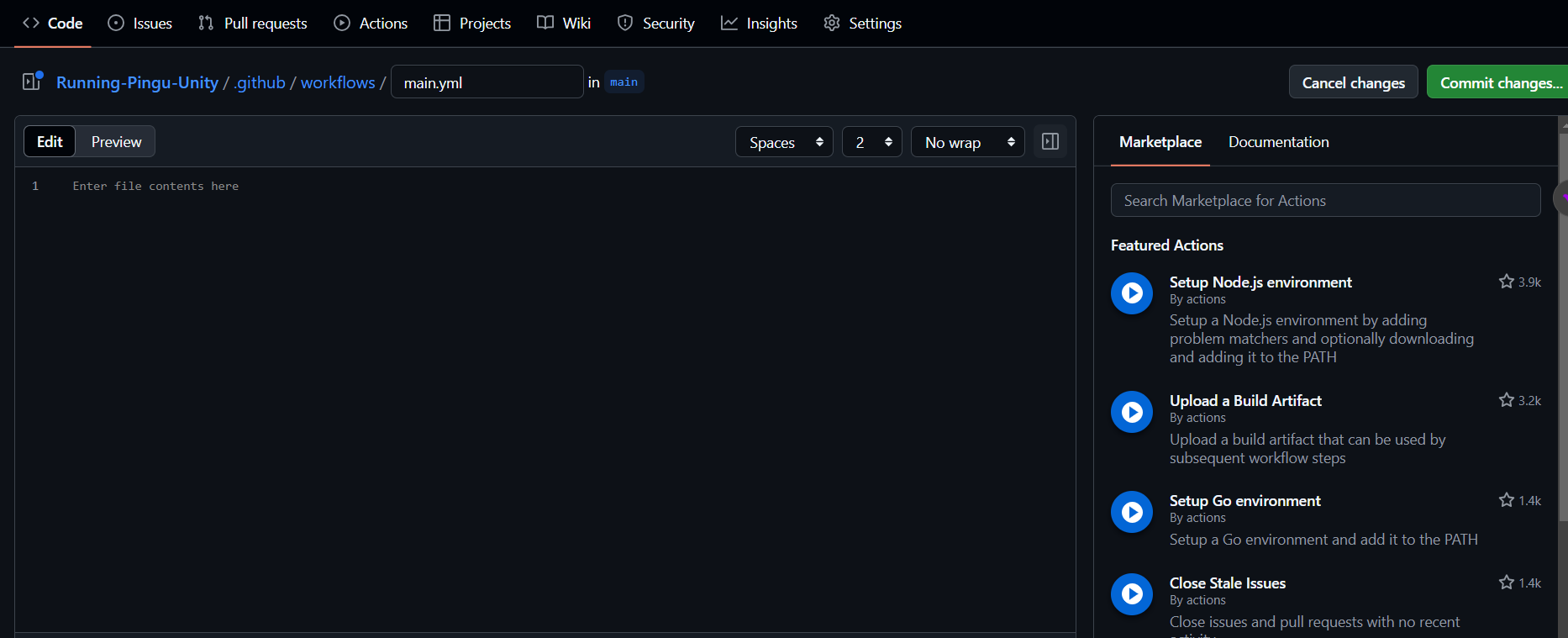
Ci-dessous se trouve un flux de travail de base qui convertit un fichier Markdown (*.md) en PDF chaque fois que du code est poussé dans le dépôt.
name: Générer la documentation
on: [push]
jobs:
build:
runs-on: ubuntu-latest
steps:
# Étape 1 : Récupérer le code du dépôt
- name: Récupérer le code
uses: actions/checkout@v2
# Étape 2 : Installer Pandoc
- name: Installer Pandoc
run: sudo apt-get install pandoc
# Étape 3 : Convertir Markdown en PDF
- name: Convertir Markdown en PDF
run: pandoc input.md -o output.pdf
# Étape 4 : Télécharger le PDF généré en tant qu'artefact
- name: Télécharger la documentation
uses: actions/upload-artifact@v2
with:
name: documentation
path: output.pdf
Voici une explication de chaque étape :
Récupérer le code : L'action
actions/checkout@v2récupère le dernier code de votre dépôt.Installer Pandoc : Cette étape installe Pandoc sur l'exécuteur (dans ce cas, une machine Ubuntu) afin qu'il puisse être utilisé pour la conversion de la documentation.
Convertir Markdown en PDF : La commande PanDoc convertit le fichier
input.mdenoutput.pdf.Télécharger la documentation : Cette étape sauvegarde le PDF généré en tant qu'artefact dans le pipeline CI/CD, le rendant téléchargeable ou accessible plus tard.
Déclenchement lors des mises à jour de la documentation
Vous pouvez configurer votre pipeline CI/CD pour qu'il se déclenche lorsque des mises à jour de la documentation se produisent, par exemple, lorsque des changements sont poussés vers une branche docs :
on:
push:
branches:
- docs
Cette configuration garantit que votre documentation est régénérée lorsque des changements sont spécifiquement apportés à la branche de documentation, réduisant ainsi les reconstructions inutiles.
Adaptation pour GitLab CI ou Jenkins
Bien que l'exemple ci-dessus utilise GitHub Actions, les mêmes principes s'appliquent à d'autres systèmes CI/CD comme GitLab CI ou Jenkins.

Par exemple, dans GitLab CI, vous pourriez définir un fichier .gitlab-ci.yml qui suit des étapes similaires pour récupérer le code, installer Pandoc, convertir les fichiers et stocker la documentation résultante.
L'intégration de Pandoc dans votre pipeline CI/CD offre un moyen fiable d'automatiser vos flux de travail de documentation, garantissant que les documents de votre projet sont toujours à jour, précis et accessibles.
Techniques d'automatisation avancées
Lorsque votre projet atteint un stade où la documentation doit être générée fréquemment ou dans plusieurs environnements, il est essentiel d'étendre votre stratégie d'automatisation pour maintenir la cohérence et la fiabilité.
Automatisation avec des tâches Cron
Pour les projets où les mises à jour de la documentation se produisent fréquemment, mais pas toujours en raison de poussées de code ou de commits, vous pouvez automatiser le processus en utilisant des tâches cron.
Cron permet de planifier des tâches à des intervalles spécifiques, ce qui signifie que votre documentation peut être automatiquement mise à jour à des heures fixes sans nécessiter d'entrée manuelle.
Par exemple, configurer une tâche cron pour s'exécuter tous les jours à minuit afin de convertir des fichiers Markdown en PDF :
0 0 * * * /path/to/pandoc /path/to/input.md -o /path/to/output.pdf
Avec cette tâche cron en place, Pandoc convertira automatiquement vos fichiers Markdown en PDF à l'heure spécifiée, garantissant que votre documentation reste à jour sans intervention manuelle.
Assurer la cohérence avec Docker
Lorsque vous travaillez en équipe ou sur divers systèmes, garantir que Pandoc s'exécute de manière cohérente dans différents environnements peut être un défi.
Docker offre une solution à cela en vous permettant d'emballer Pandoc et toutes ses dépendances dans un conteneur, garantissant que la même configuration est utilisée partout.
Cela est utile dans les pipelines CI/CD, où différents environnements (comme les machines locales, les environnements de staging et les serveurs de production) peuvent avoir des configurations différentes.
Vous pouvez utiliser l'image Docker officielle Pandoc pour simplifier le processus de configuration :
docker run --rm -v $(pwd):/data pandoc/core:latest input.md -o output.pdf
Cette commande exécute Pandoc à l'intérieur d'un conteneur Docker, en utilisant la dernière version de Pandoc, et monte votre répertoire courant dans le répertoire /data du conteneur.
En faisant cela, vous garantissez que, peu importe où le pipeline s'exécute, la conversion fonctionnera de la même manière à chaque fois.
Combinaison d'outils pour l'efficacité
En combinant des outils comme les tâches cron et Docker, vous pouvez mettre en place un pipeline d'automatisation avancé qui garantit :
Mises à jour planifiées : Les tâches cron déclenchent la génération de documentation à intervalles réguliers.
Cohérence entre les environnements : Docker garantit que Pandoc et ses dépendances sont les mêmes sur chaque machine.
Fiabilité : Ensemble, ces outils aident à garantir que votre documentation est toujours précise, peu importe où et quand elle est générée.
Ces techniques avancées vous permettent de rationaliser davantage vos flux de travail de documentation, améliorant à la fois l'efficacité et la fiabilité à mesure que votre projet grandit.
Conclusion
L'automatisation de la conversion de documentation avec Pandoc non seulement fait gagner du temps, mais garantit également la cohérence et l'évolutivité à mesure que votre projet grandit.
Que vous gériez des projets petits ou grands, ces techniques vous permettent de vous concentrer sur le codage et la construction, en sachant que votre documentation est automatiquement à jour et prête pour la distribution.
En adoptant l'automatisation, vous rationalisez votre processus de développement et améliorez la collaboration entre les équipes, garantissant que votre documentation évolue aussi efficacement que votre code.
Il est maintenant temps d'appliquer ces outils à vos projets et de profiter des avantages d'un pipeline de documentation entièrement automatisé.
Restons en contact :
Connectez-vous avec moi sur LinkedIn. Je poste régulièrement, donc me suivre est une excellente idée.
N'hésitez pas à me contacter via les canaux ci-dessus si vous avez des questions. Je serai ravi de vous aider.