


Article original : How to Architect a Blockchain on Kubernetes – K8S Microservice Tutorial
Dans cet article, je vais décrire comment utiliser l'architecture de microservices et Kubernetes pour construire une blockchain.
Les technologies généralement utilisées pour les blockchains sont spécifiques, et vous pouvez les utiliser pour d'autres projets également.
Les exemples dans cet article peuvent facilement gérer des charges lourdes et rester réactifs et rapides pour exécuter les requêtes des utilisateurs.
Étant donné que l'industrie des cryptomonnaies se développe rapidement, de nombreux pays établissent des règles sur la manière dont tout doit être géré. Par conséquent, je vais respecter certaines réglementations et prendre en compte certains détails, tels que les caractéristiques de la technologie blockchain.
Par exemple, vous pouvez avoir des surcharges et des problèmes de performance avec la technologie blockchain. Et à mesure que le marché des cryptomonnaies et de la technologie blockchain s'étend, de nouveaux produits sont plus susceptibles de plaire à un large éventail d'utilisateurs actifs de la technologie blockchain.
Pour cette raison, j'ai dû trouver un moyen d'empêcher le programme de devenir surchargé en cas d'augmentation significative du nombre d'utilisateurs.
Prérequis du tutoriel
Pour ce guide, voici les technologies que nous allons utiliser. Vous devriez être familier avec elles :
- Node.js (plus précisément, le framework NestJS) pour le développement backend. Nest.js vous oblige à utiliser une structure modulaire où chaque fonctionnalité peut être isolée et facilement connectée/déconnectée des autres modules. Nest supporte TypeScript dès la sortie de la boîte.
- PostgreSQL est la base de données que nous utiliserons pour collecter les données.
- Kafka JS sert les charges entrantes et établit la communication entre les microservices.
- Helm charts et Kubernetes (k8s) pour le déploiement. Ces outils permettront un déploiement facile de l'infrastructure de microservices évolutifs sur toute plateforme cloud (nous utiliserons AWS EKS)
De plus, cet article suppose que vous avez un niveau de connaissance décent de Kubernetes, Helm et Node. Plongeons-nous dans le sujet.
Méthode de développement
Notre objectif principal pour la première phase est de diviser notre application en microservices.
En plus d'aider à la communication des services, l'équilibrage de charge avec Kafka permet le traitement un par un des données d'entrée. Lorsque nous avons de nombreux clients, les temps de traitement peuvent augmenter, mais au moins le service continuera et sera préservé.
De plus, si le cluster dispose de suffisamment de ressources, nous pouvons créer des consommateurs supplémentaires pour le groupe qui gère des événements particuliers. Cela réduit les délais et accélère le traitement des tâches.
Dans cette situation, nous allons développer six microservices différents :
- Microservice Admin – Nous utiliserons le microservice admin pour toute la logique du panneau d'administration, qui doit être isolée des fonctionnalités orientées utilisateur.
- Microservice Core – La logique relative aux utilisateurs et à leurs comptes est contenue dans le microservice core. Identification, cadeaux, graphiques, profils, etc. Cependant, ce microservice n'effectue pas les tâches d'un service financier, telles que le traitement des paiements et l'échange de devises.
- Microservice de paiement – Un service financier appelé "microservice de paiement" inclut la logique pour les transactions de trading, d'échange et de retrait. Il y aura des intégrations avec des solutions CEX et DeFi.
- Service de messagerie et de notification – Ce microservice est responsable de l'envoi des emails, des notifications push et d'autres types d'alertes à l'utilisateur. Il contient une file d'attente Kafka séparée pour les requêtes des autres microservices afin d'envoyer des emails ou des notifications aux utilisateurs.
- Tâches Cron – Un microservice appelé Service de Tâches Cron transmet des événements prédéterminés pour le traitement des tâches. Les microservices n'effectuent pas les tâches par eux-mêmes. Avoir un tel microservice aide à prévenir le saut des itérations des tâches cron lorsque, par exemple, le service de traitement est hors service en raison d'un déploiement ou d'une panne. L'événement restera dans une file d'attente en attendant d'être exécuté.
- Microservice Webhooks – Le but du microservice webhooks est de prévenir la perte d'événements provenant d'API externes qui peuvent être très significatifs et contenir des statuts de transaction ou d'autres données vitales. De tels événements sont traités après avoir été mis en file d'attente (en fonction de l'API émettrice).
Maintenant, voyons comment créer ces microservices en utilisant Nest.js.
Pour le courtier de messages Kafka, vous devrez créer des options de configuration. Afin de stocker les modules partagés et les configurations de tous les microservices, nous allons établir un dossier de ressources partagées.
Options de configuration des microservices
Les applications de production doivent avoir une configuration. La configuration est cruciale pour comprendre ce que votre application de production consomme lorsque vous développez une application de microservices. Il est généralement recommandé de garder les paramètres de configuration distincts de votre code lors du développement de microservices.
import { ClientProviderOptions, Transport } from '@nestjs/microservices';
import CONFIG from '@application-config';
import { ConsumerGroups, ProjectMicroservices } from './microservices.enum';
const { BROKER_HOST, BROKER_PORT } = CONFIG.KAFKA;
export const PRODUCER_CONFIG = (name: ProjectMicroservices): ClientProviderOptions => ({
name,
transport: Transport.KAFKA,
options: {
client: {
brokers: [`${BROKER_HOST}:${BROKER_PORT}`],
},
}
});
export const CONSUMER_CONFIG = (groupId: ConsumerGroups) => ({
transport: Transport.KAFKA,
options: {
client: {
brokers: [`${BROKER_HOST}:${BROKER_PORT}`],
},
consumer: {
groupId
}
}
});
Lions notre microservice pour le panneau d'administration à Kafka en mode consommateur. Grâce à cela, nous pouvons détecter et gérer les événements des sujets.
Faisons fonctionner l'application en mode microservice afin que les événements puissent être consommés comme ceci :
app.connectMicroservice(CONSUMER_CONFIG(ConsumerGroups.ADMIN));
await app.startAllMicroservices();
Nous pouvons voir que groupId est inclus dans la configuration du consommateur. C'est un choix crucial qui permettra aux clients du même groupe de recevoir des événements des sujets et de les partager entre eux pour les traiter plus rapidement.
Par exemple, nous pouvons utiliser l'autoscaling pour lancer plus de pods afin de diviser la charge entre eux et accélérer le processus si notre microservice reçoit des événements plus rapidement qu'il ne peut les traiter.
Les consommateurs doivent être inclus dans le groupe pour que cela fonctionne, et après le scaling, les pods générés seront également inclus. Ils n'auront pas à traiter les mêmes événements de sujet à partir de plusieurs partitions Kafka car ils peuvent partager la charge.
Regardons un exemple de la manière dont nous pouvons utiliser Nest pour capturer et gérer les événements Kafka.
Contrôleur du consommateur
import { Controller } from '@nestjs/common';
import { Ctx, KafkaContext, MessagePattern, EventPattern, Payload } from '@nestjs/microservices';
@Controller('consumer')
export class ConsumerController {
@MessagePattern('hero')
readMessage(@Payload() message: any, @Ctx() context: KafkaContext) {
return message;
}
@EventPattern('event-hero')
sendNotif(data) {
console.log(data);
}
}
Les clients peuvent fonctionner en deux modes. Il accepte les événements, les traite sans envoyer de réponse (décorateur EventPattern), ou, après avoir traité un événement, retourne la réponse au producteur (décorateur MessagePattern).
Étant donné qu'il ne contient aucune couche de code source supplémentaire pour activer la fonctionnalité de requête/réponse, EventPattern est préférable et vous devriez le choisir chaque fois que possible.
Qui sont les producteurs ?
Nous devons fournir la configuration du producteur pour un module qui sera responsable de la transmission des événements afin de lier les producteurs.
Connexion du producteur
import { Module } from '@nestjs/common';
import DatabaseModule from '@shared/database/database.module';
import { ClientsModule } from '@nestjs/microservices';
import { ProducerController } from './producer.controller';
import { PRODUCER_CONFIG } from '@shared/microservices/microservices.config';
import { ProjectMicroservices } from '@shared/microservices/microservices.enum';
@Module({
imports: [
DatabaseModule,
ClientsModule.register([PRODUCER_CONFIG(ProjectMicroservices.ADMIN)]),
],
controllers: [ProducerController],
providers: [],
})
export class ProducerModule {}
Producteur basé sur les événements
import { Controller, Get, Inject } from '@nestjs/common';
import { ClientKafka } from '@nestjs/microservices';
import { ProjectMicroservices } from '@shared/microservices/microservices.enum';
@Controller('producer')
export class ProducerController {
constructor(
@Inject(ProjectMicroservices.ADMIN)
private readonly client: ClientKafka,
) {}
@Get()
async getHello() {
this.client.emit('event-hero', { msg: 'Event Based'});
}
}
Producteur basé sur la requête/réponse
import { Controller, Get, Inject } from '@nestjs/common';
import { ClientKafka } from '@nestjs/microservices';
import { ProjectMicroservices } from '@shared/microservices/microservices.enum';
@Controller('producer')
export class ProducerController {
constructor(
@Inject(ProjectMicroservices.ADMIN)
private readonly client: ClientKafka,
) {}
async onModuleInit() {
// Besoin de s'abonner à un sujet
// pour rendre possible la réception de la réponse du microservice Kafka
this.client.subscribeToResponseOf('hero');
await this.client.connect();
}
@Get()
async getHello() {
const responseBased = this.client.send('hero', { msg: 'Response Based' });
return responseBased;
}
}
Chaque microservice a la possibilité de fonctionner dans l'un des deux modes—producteur ou consommateur—ou dans les deux modes simultanément (mixte).
Les microservices emploient généralement le mode mixte pour l'équilibrage de charge, produisant des événements vers le sujet et les consommant tout en répartissant équitablement la charge.
Pour chaque microservice, nous utiliserons une configuration Kubernetes basée sur des modèles de graphiques Helm.
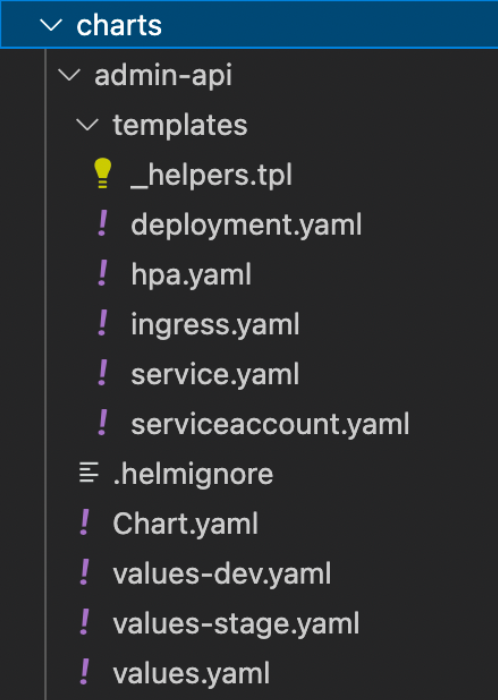
Il y a plusieurs fichiers de configuration dans le modèle :
- Hpa (horizontal pod autoscaler)
- Contrôleur d'entrée
- Service
- Déploiement
Nous allons examiner chaque fichier de configuration séparément (sans le templating Helm).
Comment déployer l'admin-API
apiVersion: apps/v1
kind: Deployment
metadata:
name: admin-api
spec:
replicas: 1
selector:
matchLabels:
app: admin-api
template:
metadata:
labels:
app: admin-api
spec:
containers:
- name: admin-api
Image: xxx208926xxx.dkr.ecr.us-east-1.amazonaws.com/project-name/stage/admin-api
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 250m
memory: 512Mi
ports:
- containerPort: 80
env:
- name: NODE_ENV
value: production
- name: APP_PORT
value: "80"
Vous pouvez inclure des configurations minimales supplémentaires, telles que des limitations de ressources, des configurations de vérification de santé, des stratégies de mise à jour, etc., dans un déploiement.
Service admin-API
---
apiVersion: v1
kind: Service
metadata:
name: admin-api
spec:
selector:
app: admin-api
ports:
- name: admin-api-port
port: 80
targetPort: 80
protocol: TCP
type: NodePort
Pour utiliser ce service, nous devons le rendre accessible au public. Utilisons la configuration SSL pour exploiter une connexion HTTPS sécurisée et exposer notre application via un équilibreur de charge.
Sur notre cluster, nous devons déployer un contrôleur d'équilibreur de charge. La réponse la plus largement utilisée est la suivante : Contrôleur d'équilibreur de charge pour AWS.
Ensuite, nous devons configurer l'entrée avec les paramètres suivants :
Contrôleur d'entrée admin-API
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: default
name: admin-api-ingress
annotations:
alb.ingress.kubernetes.io/load-balancer-name: admin-api-alb
alb.ingress.kubernetes.io/ip-address-type: ipv4
alb.ingress.kubernetes.io/tags: Environment=production,Kind=application
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:us-east-2:xxxxxxxx:certificate/xxxxxxxxxx
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS":443}]'
alb.ingress.kubernetes.io/healthcheck-protocol: HTTPS
alb.ingress.kubernetes.io/healthcheck-path: /healthcheck
alb.ingress.kubernetes.io/healthcheck-interval-seconds: '15'
alb.ingress.kubernetes.io/ssl-redirect: '443'
alb.ingress.kubernetes.io/group.name: admin-api
spec:
ingressClassName: alb
rules:
- host: example.com
http:
paths:
- path: /*
pathType: ImplementationSpecific
backend:
service:
name: admin-api
port:
number: 80
Une fois cette configuration appliquée, un nouvel équilibreur de charge alb sera formé. Nous devons construire un domaine avec le nom que nous avons spécifié dans l'option 'host' et diriger le trafic vers notre équilibreur de charge à partir de cet hôte.
Configuration de l'autoscaling admin-API
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: admin-api-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: admin-api
minReplicas: 1
maxReplicas: 2
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 90
Comment Helm entre-t-il en jeu ?
Lorsque nous voulons rendre notre infrastructure k8s moins complexe, Helm est très utile. Sans cet outil, son exécution sur un cluster nécessite l'écriture de nombreux fichiers YML.
De plus, nous devons prendre en compte les relations entre les applications, les étiquettes, les noms, etc. Helm, en revanche, peut simplifier les choses. Il fonctionne de manière similaire à un gestionnaire de paquets, nous permettant de créer un modèle d'application, de le préparer à l'aide de commandes courtes, puis de le lancer.
Créons nos modèles à l'aide de Helm.
Déploiement admin-API (Helm chart)
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.appName }}
spec:
replicas: {{ .Values.replicas }}
selector:
matchLabels:
app: {{ .Values.appName }}
template:
metadata:
labels:
app: {{ .Values.appName }}
spec:
containers:
- name: {{ .Values.appName }}
image: {{ .Values.image.repository }}:{{ .Values.image.tag }}"
imagePullPolicy: {{ .Values.image.pullPolicy }}
ports:
- containerPort: {{ .Values.internalPort }}
{{- with .Values.env }}
env: {{ tpl (. | toYaml) $ | nindent 12 }}
{{- end }}
Service admin-API (Helm chart)
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.global.appName }}
spec:
selector:
app: {{ .Values.global.appName }}
ports:
- name: {{ .Values.global.appName }}-port
port: {{ .Values.externalPort }}
targetPort: {{ .Values.internalPort }}
protocol: TCP
type: NodePort
Entrée admin-API (Helm chart)
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: default
name: ingress
annotations:
alb.ingress.kubernetes.io/load-balancer-name: {{ .Values.ingress.loadBalancerName }}
alb.ingress.kubernetes.io/ip-address-type: ipv4
alb.ingress.kubernetes.io/tags: {{ .Values.ingress.tags }}
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/certificate-arn: {{ .Values.ingress.certificateArn }}
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS":443}]'
alb.ingress.kubernetes.io/healthcheck-protocol: HTTPS
alb.ingress.kubernetes.io/healthcheck-path: {{ .Values.ingress.healthcheckPath }}
alb.ingress.kubernetes.io/healthcheck-interval-seconds: {{ .Values.ingress.healthcheckIntervalSeconds }}
alb.ingress.kubernetes.io/ssl-redirect: '443'
alb.ingress.kubernetes.io/group.name: {{ .Values.ingress.loadBalancerGroup }}
spec:
ingressClassName: alb
rules:
- host: {{ .Values.adminApi.domain }}
http:
paths:
- path: {{ .Values.adminApi.path }}
pathType: ImplementationSpecific
backend:
service:
name: {{ .Values.adminApi.appName }}
port:
number: {{ .Values.adminApi.externalPort }}
Configuration de l'autoscaling admin-API (Helm chart)
{{- if .Values.autoscaling.enabled }}
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: {{ include "ks.fullname" . }}
labels:
{{- include "ks.labels" . | nindent 4 }}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ include "ks.fullname" . }}
minReplicas: {{ .Values.autoscaling.minReplicas }}
maxReplicas: {{ .Values.autoscaling.maxReplicas }}
metrics:
{{- if .Values.autoscaling.targetCPUUtilizationPercentage }}
- type: Resource
resource:
name: cpu
targetAverageUtilization: {{ .Values.autoscaling.targetCPUUtilizationPercentage }}
{{- end }}
{{- if .Values.autoscaling.targetMemoryUtilizationPercentage }}
- type: Resource
resource:
name: memory
targetAverageUtilization: {{ .Values.autoscaling.targetMemoryUtilizationPercentage }}
{{- end }}
{{- end }}
Les fichiers "values.yml", "values-dev.yml" et "values-stage.yml" contiennent les valeurs pour les modèles. L'environnement déterminera lequel d'entre eux est utilisé.
Regardons quelques exemples de valeurs pour l'environnement de développement.
Fichier Admin-API Helm values-stage.yml
env: stage
appName: admin-api
domain: admin-api.xxxx.com
path: /*
internalPort: '80'
externalPort: '80'
replicas: 1
image:
repository: xxxxxxxxx.dkr.ecr.us-east-2.amazonaws.com/admin-api
pullPolicy: Always
tag: latest
ingress:
loadBalancerName: project-microservices-alb
tags: Environment=stage,Kind=application
certificateArn: arn:aws:acm:us-east-2:xxxxxxxxx:certificate/xxxxxx
healthcheckPath: /healthcheck
healthcheckIntervalSeconds: '15'
loadBalancerGroup: project-microservices
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 100
targetCPUUtilizationPercentage: 80
env:
- name: NODE_ENV
value: stage
- name: ADMIN_PORT
value: "80
Nous devons mettre à jour le graphique et redémarrer notre déploiement pour que la configuration prenne effet sur le cluster.
Examinons les étapes des GitHub Actions en question.
Comment appliquer la configuration Helm dans GitHub Actions
Les actions GitHub sont des services CI/CD de GitHub. Ils fournissent des processus de travail simples organisés sous forme de fichiers Yaml qui exécutent des blocs de code configurables basés sur des événements GitHub. Comme ils sont intégrés à GitHub, ils réduisent considérablement les frais généraux pour la mise en place d'un pipeline CI/CD.
- name: Admin image build and push
run: |
docker build -t project-admin-api -f Dockerfile.admin .
docker tag project-admin-api ${{ env.AWS_ECR_REGISTRY }}/project/${{ env.ENV }}/admin-api:latest
docker push ${{ env.AWS_ECR_REGISTRY }}/project/${{ env.ENV }}/admin-api:latest
- name: Helm upgrade admin-api
uses: koslib/helm-eks-action@master
env:
KUBE_CONFIG_DATA: ${{ env.KUBE_CONFIG_DATA }}
with:
command: helm upgrade --install admin-api -n project-${{ env.ENV }} charts/admin-api/ -f charts/admin-api/values-${{ env.ENV }}.yaml
- name: Deploy admin-api image
uses: kodermax/kubectl-aws-eks@master
env:
KUBE_CONFIG_DATA: ${{ env.KUBE_CONFIG_DATA }}
with:
args: rollout restart deployment/admin-api-project-admin-api --namespace=project-${{ env.ENV }}
Résumé
Dans cet article, nous avons examiné les étapes de construction d'infrastructure et de déploiement de cluster Kubernetes pour les microservices. En utilisant des exemples simples et en évitant une complexité supplémentaire avec des configurations complètes, j'espère que cela a été relativement facile à comprendre.
Connectez-vous avec moi sur LinkedIn et Twitter
Hasta la vista!