

Article original : How to Learn the Fundamentals of Software Engineering – in a More Interesting and Less Painful Way
Cet article est destiné à être un guide d'introduction aux fondamentaux du génie logiciel.
Je l'ai écrit en supposant que vous, cher lecteur, ne connaissez peut-être pas grand-chose aux bases de ce domaine, pourquoi elles sont importantes, et quand vous devriez vous donner la peine de les apprendre.
Nous aborderons chacune de ces questions et terminerons en discutant de quelques méthodes que je recommande pour les apprendre et les aborder.
Pour ceux qui connaissent déjà ce sujet, il y aura peut-être quelques nouvelles perspectives intéressantes, et particulièrement dans la dernière section, des moyens utiles pour accélérer votre processus d'apprentissage.
Dans cet article, nous discuterons de :
Ce qui a rendu le génie logiciel effrayant et intimidant pour moi, et comment cela a changé
La raison pour laquelle, et les métriques selon lesquelles nous regardons un code et concluons qu'il est moins efficace qu'une autre approche (complexité computationnelle)
Une introduction simple mais utile aux structures de données et aux algorithmes
Les choses que je fais personnellement pour apprendre les sujets en génie logiciel pour une efficacité et une compréhension maximales
Une façon de motiver vos efforts en ajoutant quelques tests de base pour mesurer la justesse et l'efficacité de vos algorithmes
Veuillez noter que j'ai essayé de structurer cet article dans une progression logique où chaque section (à part la suivante qui concerne davantage le fait de surmonter la peur de plonger dans ce sujet) s'appuie sur ou motive la suivante.
Je condense plus de mille heures de pratique et d'étude en un seul article, et j'ai fait de mon mieux pour expliquer les choses clairement et simplement.

Photo par [Unsplash](https://unsplash.com/@thisisengineering?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit">ThisisEngineering RAEng / <a href="https://unsplash.com/?utm_source=ghost&utm_medium=referral&utm_campaign=api-credit)
Où les problèmes ont commencé
Tout au long de mon éducation formelle limitée, je n'ai pas eu la meilleure relation avec le domaine des mathématiques. Et par extension, cela a impacté ma relation avec une grande partie de l'informatique (CS) et du génie logiciel (SEng).
Pour être précis, ce n'est pas que je sois mauvais en maths, mais je suis mauvais en arithmétique et en mémorisation de formules.
J'ai également constaté que la manière dont les mathématiques, l'informatique et le génie logiciel sont généralement enseignés dans les écoles ne fonctionne pas non plus pour moi.
Mon propre processus d'apprentissage à ce jour est largement guidé par le pragmatisme (insistance sur les connaissances pratiques plutôt que théoriques), la curiosité sur la nature, et comment ces informations peuvent m'aider à gagner ma vie – trois choses que j'ai rarement vues mises en avant dans mon éducation occidentale.
En dehors de ma relation difficile avec les présentations sèches et ennuyeuses de choses qui sont principalement de nature mathématique, je suis un programmeur autodidacte.
Pour être clair, j'ai suivi un seul cours de programmation dans un collège communautaire (vers 2013), et le reste de mes connaissances provient d'études autodirigées. Pendant mes premières années de ce processus, je devais également travailler divers emplois de jour pour payer le loyer, ce qui me laissait très peu de temps et d'énergie pour apprendre mon métier.
Le résultat final a été que j'ai choisi de passer la plupart de mon temps à construire des projets personnels et à apprendre des sujets spécifiquement pour ces projets.
Cela m'a conduit à être vraiment assez bon dans l'art d'écrire du code, d'apprendre de nouvelles technologies et de résoudre des problèmes. Cependant, si j'appliquais des concepts en informatique et en génie logiciel au code que j'écrivais, c'était largement par accident.
Pour résumer cette introduction, j'essaie de dire que le plus grand obstacle dans mon étude du génie logiciel était que je n'étais tout simplement pas très intéressé à l'apprendre.
Je ne connaissais pas le sentiment d'accomplissement que l'on peut obtenir en apportant une petite modification à un algorithme qui réduit son temps d'exécution d'un facteur de dizaines ou de centaines de fois.
Je ne savais pas à quel point il était important de choisir une structure de données en fonction de la nature du problème que je tentais de résoudre, et encore moins comment prendre cette décision.
Et je n'avais aucune idée de la manière dont cela était pertinent pour moi qui développons des applications mobiles pour gagner ma vie.
Donc, au cas où vous seriez dans le même bateau, avant d'aborder les détails techniques, j'aimerais tenter de répondre à certaines de ces questions pour vous. Pour rendre les choses moins ennuyeuses, je vais motiver ce sujet en partageant une histoire vraie sur ce qui a changé mon attitude envers ce sujet.
Nager avec les gros poissons
Vers la fin de 2019, j'avais fait une pause dans l'étude du développement Android pour plonger profondément dans les systèmes d'exploitation UNIX et la programmation C/C++.
Je me sentais très à l'aise avec le SDK Android, mais de nombreuses années de programmation JVM m'avaient laissé avec un fort sentiment de ne pas savoir comment les ordinateurs fonctionnaient réellement sous le capot. Ce qui me dérangeait beaucoup.
Je ne cherchais pas vraiment de travail, mais à l'époque, un recruteur d'une grande entreprise technologique m'avait contacté pour savoir si j'étais intéressé par un poste d'ingénieur logiciel Android.
Malgré plusieurs mois sans pratique d'Android, j'ai bien réussi le premier entretien (il s'agissait de concepts de base d'Android que je connaissais) et j'ai reçu un e-mail détaillant les sujets à couvrir lors des futurs entretiens.
La première section de cet e-mail, qui détaillait les connaissances spécifiques à Android, était extensive, mais j'étais au moins quelque peu familier avec la plupart des sujets et pas intimidé. Cependant, lorsque j'ai fait défiler jusqu'à la section sur les structures de données et les algorithmes, j'ai soudainement eu l'impression que j'avais lorsque j'ai commencé à écrire du code : comme un poisson hors de l'eau.
Ce n'est pas que je n'avais jamais appliqué aucun de ces concepts dans mon code, mais je ne les avais certainement pas étudiés formellement.
Bien que je ferai de mon mieux pour vous donner une introduction douce et claire à ces sujets, le génie logiciel vous frappera immédiatement avec un mur de termes jargoniques, et mon visage était figurativement très endolori et meurtri après avoir lu la liste entière des structures de données et des algorithmes que je devais apprendre dans cet e-mail.
J'ai été très franc à ce sujet avec mon recruteur, qui m'a gentiment donné quatre semaines pour me préparer avant le prochain entretien.
Je savais que je ne pouvais pas couvrir tous les sujets en quatre semaines, mais j'espérais que l'apprentissage d'une ou deux années de génie logiciel en quelques semaines montrerait un certain talent et une certaine initiative.
J'adorerais vous raconter une histoire juteuse sur la façon dont j'ai échoué de manière épique ou brillé complètement lors du prochain entretien, mais la réalité est que les choses se sont effondrées avant même que j'en aie l'occasion.
Je suis un citoyen canadien, et le poste nécessitait une relocalisation dans l'un des nombreux campus aux États-Unis, en Californie ou dans l'État de Washington.
Deux semaines après ma première plongée profonde dans le génie logiciel, j'ai reçu un e-mail de mon recruteur indiquant que leur département de l'immigration ne voulait pas me sponsoriser. Je soupçonne que cela avait à voir avec certaines difficultés à sponsoriser un travailleur sans diplôme, mais la pandémie mondiale naissante a peut-être également été un facteur.
En fin de compte, même si je voulais la chance de réussir ou d'échouer en temps réel, j'étais heureux de savoir que j'avais une idée très claire des connaissances qui me manquaient pour être ingénieur logiciel dans une grande entreprise technologique.
Avec un chemin clair mais difficile devant moi, j'ai décidé de ne plus laisser le domaine du génie logiciel m'intimider. Je voulais savoir ce que cela signifie vraiment d'être un développeur de logiciels par rapport à un ingénieur logiciel.
Avec cela en tête, nous allons aborder les idées centrales du génie logiciel, et comment rendre leur apprentissage plus facile. Pas facile – juste plus facile.
Les "trois grands" sujets en génie logiciel – et pourquoi ils comptent
Les principaux sujets en génie logiciel peuvent être résumés en utilisant un tas de grands mots et phrases effrayants – comme c'est la tradition dans tout ce qui est lié à l'informatique et aux mathématiques. Pour éviter la confusion, je vais plutôt les expliquer en utilisant la langue anglaise et des exemples qui privilégient la clarté par-dessus tout.
Je vous suggère de suivre cette section dans l'ordre que j'ai établi, car je l'ai délibérément structurée dans une progression logique.
D'abord - Qu'est-ce que le temps d'exécution et l'espace mémoire ?
Je veux commencer par expliquer la raison pour laquelle nous étudions ces sujets en premier lieu.
Étant un fan de physique, j'ai été heureux d'apprendre que l'interaction du temps et de l'espace que nous voyons dans la nature est également directement observée dans tout type d'ordinateur.
Cependant, dans ce domaine, nous faisons référence à ces qualités comme temps d'exécution et espace mémoire.
Pour mieux comprendre ce qu'est le temps d'exécution, je vous suggère d'ouvrir votre Gestionnaire des tâches, Moniteur d'activité, ou tout programme que vous avez qui vous informe sur les "processus" actifs de votre système.
Un processus est simplement un "programme en cours d'exécution", et grâce à la magie de l'avoir de multiples "processeurs", la virtualisation du CPU, et le découpage temporel, il peut sembler que nous avons des dizaines ou des centaines de processus qui s'exécutent en même temps.
J'ai ajouté ces termes jargoniques afin que vous puissiez les rechercher si vous êtes curieux de savoir comment fonctionnent les systèmes d'exploitation, mais le faire n'est pas nécessaire pour continuer avec cet article.
Dans tous les cas, le temps d'exécution d'un processus peut généralement être considéré comme n'importe quel point dans le temps pendant lequel il peut être vu dans l'outil de suivi des processus de votre système.
J'utilise cette définition pour souligner qu'un processus actif n'a pas besoin d'avoir une interface utilisateur ou même de faire quelque chose d'utile même s'il peut encore occuper du temps d'exécution dans le CPU et l'espace mémoire.
En parlant d'espace mémoire, pour qu'un processus ait un temps d'exécution, il doit aussi être quelque part. Cet endroit est l'espace mémoire physique de l'ordinateur, qui est virtualisé (encore une fois, recherchez virtualisation sur votre temps libre mais ce n'est pas nécessaire pour cet article) afin de le rendre plus sécurisé et plus facile à utiliser.
Chaque processus se voit attribuer son propre espace mémoire virtuel distinct et protégé, qui peut croître ou diminuer jusqu'à certaines limites et en fonction de divers facteurs.
Faisons une pause dans la théorie pour parler de pourquoi nous devrions nous en soucier. Puisque le temps d'exécution et l'espace mémoire peuvent être mesurés avec précision mais sont également limités, des humains comme vous et moi peuvent vraiment tout gâcher si nous ne prêtons pas attention à ces limitations !
Pour être clair, voici deux choses très importantes dont nous devons nous soucier en tant que programmeurs et ingénieurs :
Notre programme ou même le système entier va-t-il planter parce que nous avons mal géré la ressource finie de l'espace mémoire ?
Nos programmes vont-ils résoudre les problèmes de nos utilisateurs de manière opportune et efficace, ou vont-ils se bloquer si longtemps que nos utilisateurs décideront de forcer la fermeture, demander un remboursement et laisser une mauvaise critique ?
Ces questions dictent largement le succès de nos programmes, que vous les étudiiez formellement ou non. Avec un peu de chance, je vous ai motivé à apprendre ce que j'appelle les trois grands sujets du génie logiciel, que nous allons aborder maintenant.
Comment nous mesurons le temps d'exécution et l'espace mémoire
Le premier des trois grands sujets est décrit par un terme effrayant : Complexité asymptotique du temps d'exécution et de l'espace.
Ayant déjà décrit le temps d'exécution et l'espace mémoire, je pense qu'un remplacement acceptable pour le mot complexité ici est "efficacité". Et asymptotique est lié au fait que nous pouvons représenter cette efficacité (ou son manque) sur un graphique cartésien à deux dimensions. Vous savez, x et y, la montée sur la course, et tout cela.
Ne vous inquiétez pas si vous n'êtes pas familier avec ces choses. Vous n'avez besoin que d'une compréhension très basique de ces choses pour les appliquer dans votre code.
De plus, notez qu'il existe une chose appelée structure de données de graphique, mais ce concept est très éloigné d'un graphique cartésien et ce n'est pas à cela que je fais référence.
Puisque nous pouvons représenter notre code et son comportement par rapport au temps d'exécution ou à l'espace mémoire sur un graphique cartésien, il s'ensuit qu'il doit y avoir des fonctions qui décrivent comment dessiner un tel graphique.
La manière dont nous décrivons l'efficacité de notre code de cette manière est d'utiliser la notation "Big O".
Voici l'introduction la plus simple que je puisse vous donner pour comprendre ce sujet. J'utiliserai le langage de programmation moderne Kotlin pour mes exemples de code qui, je l'espère, fournira un juste milieu pour vous, développeurs web et natifs.
Supposons trois fonctions (également parfois appelées méthodes, algorithmes, commandes ou procédures) :
Fonction printStatement :
fun printStatement(){
//imprimer sur le flux de sortie textuel du système ou du programme/console
println("Hello World!")
}
Fonction printArray :
fun printArray(arr: Array<String>){
//si 'arr' était {"Hello", "World!"} alors la sortie de cette fonction serait :
//Hello
//World!
arr.forEach { string ->
// "string" est une référence temporaire donnée à chaque élément de 'arr'
println(string)
}
}
Fonction printArraySums :
fun printArraySums(arrOne: Array<Int>, arrTwo: Array<Int>){
//Imprime la somme de chaque valeur dans les deux tableaux
arrOne.forEach { aInt ->
arrTwo.forEach { bInt ->
println(aInt + bInt)
}
}
}
Pour faciliter la compréhension, supposons que chaque fois que println(...) est appelé, il prend 100 ms, ou 1/10ème de seconde en moyenne pour se compléter (en réalité, 100 ms pour une seule commande d'impression est terriblement lent, mais c'est plus facile à imaginer qu'une microseconde ou une picoseconde).
Avec cela en tête, réfléchissons de manière critique à la façon dont ces fonctions peuvent être attendues pour se comporter différemment, en fonction des entrées qui leur sont données.
printStatement, à moins d'une défaillance catastrophique du système lui-même, prendra toujours un temps moyen de 100 ms pour se compléter.
En fait, bien que la notation Big O soit très préoccupée par la taille des arguments donnés à une fonction (cela aura plus de sens bientôt), cette fonction n'a même pas d'arguments pour changer son comportement.
Par conséquent, nous pouvons dire que la complexité du temps d'exécution (temps pris jusqu'à la complétion) est constante, ce qui peut être représenté par la fonction mathématique et le graphique suivants :
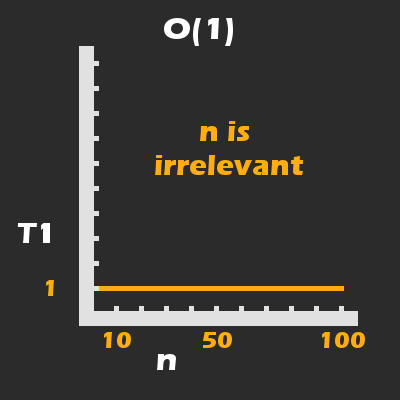
Le temps d'exécution (T) pour printStatement est toujours en moyenne de 100 millisecondes et est donc constant.
Dans le graphique ci-dessus, T représente le temps d'exécution pour println(...) que nous avons établi à une moyenne de 100 millisecondes. Je vais expliquer à quoi n fait référence dans un instant.
printArray présente un nouveau problème. Il est raisonnable de penser que le temps qu'il faut à printArray pour se compléter sera directement proportionnel à la taille du tableau, arr, qui lui est passé.
Si le tableau a quatre éléments, cela entraînerait l'appel de println(...) quatre fois, pour un temps d'exécution moyen total de 400 ms pour printArray lui-même. Pour être plus précis mathématiquement, nous dirions que la complexité du temps d'exécution de printArray est linéaire :
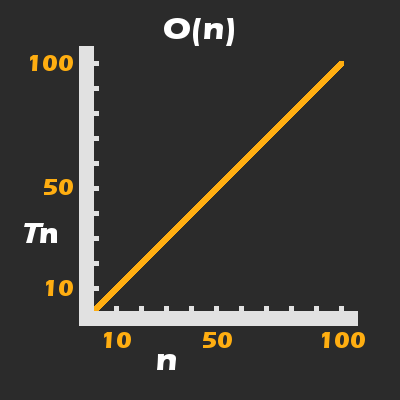
Le nombre de fois où println(...) est appelé, est directement proportionnel (c'est-à-dire croît linéairement) par rapport à n.
printArraySums va plus loin dans quelque chose qui devrait vous préoccuper même en tant que développeur junior ou intermédiaire. Le nombre d'arguments/entrées pour une fonction donnée est désigné par un petit n, lorsque l'on utilise la notation Big O.
Dans notre deuxième fonction, cela fait exclusivement référence à la taille du tableau (c'est-à-dire arr.size), mais dans la troisième fonction, cela fait référence à la taille collective de plusieurs arguments (c'est-à-dire arrOne et arrTwo).
En notation Big O, il y a en fait trois qualités différentes d'un morceau de code donné auxquelles nous pouvons prêter attention :
À quel point le code est-il efficace si n est petit (performance dans le meilleur des cas) ?
À quel point le code est-il efficace si n est de taille moyenne attendue (performance moyenne) ?
À quel point le code est-il efficace si n est proche ou à sa valeur maximale autorisée pour le système (performance dans le pire des cas) ?
En général, dans le même sens qu'un ingénieur civil est surtout préoccupé par le nombre maximum de véhicules qu'un pont peut supporter, un ingénieur logiciel est généralement le plus préoccupé par la performance dans le pire des cas.
En regardant printArraySums, vous devriez être en mesure de raisonner que nous pouvons représenter sa complexité de temps d'exécution dans le pire des cas (le nombre de fois où println(...) sera appelé) comme n n ; où n* est à ou près de la taille maximale autorisée d'un tableau dans le système.
Au cas où ce ne serait pas clair, nous ne faisons pas que l'appariement et la somme des éléments de arrOne et arrTwo aux mêmes index, nous faisons littéralement la somme de toutes leurs valeurs ensemble dans une boucle imbriquée.
À partir de là, vous pouvez commencer à vraiment comprendre l'importance de la complexité asymptotique du temps d'exécution et de l'espace. Dans un scénario de pire cas, le temps d'exécution croît de manière exponentielle dans une courbe quadratique :
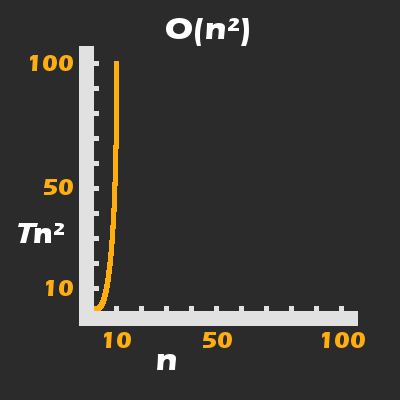
printArraySums(...) a son temps d'exécution croître dans une courbe quadratique. Pour T = 100 ms, n n'a même pas besoin d'être très grand pour entraîner une mauvaise expérience utilisateur.
Deux dernières notes sur ce sujet : Premièrement, si je vous ai soudainement rendu un peu craintif des boucles imbriquées (et oui, chaque boucle imbriquée ajoute potentiellement un autre facteur de n), alors j'ai fait un bon travail.
Même ainsi, comprenez que si vous êtes certain que n ne dépassera pas une taille raisonnable même dans une fonction qui a une croissance exponentielle, alors il n'y a pas réellement de problème.
Si vous souhaitez savoir comment déterminer si n aura un impact négatif sur les performances, restez pour la dernière section de cet article.
Deuxièmement, vous avez peut-être remarqué que tous mes exemples concernaient la complexité du temps d'exécution, et non la complexité de l'espace mémoire.
La raison en est simple : Nous représentons la complexité de l'espace exactement de la même manière et avec la même notation. Puisque nous n'allouons pas réellement de nouvelle mémoire à part une ou deux références temporaires dans chaque cadre des boucles forEach{...}, asymptotiquement parlant, les deuxième et troisième fonctions sont toujours linéaires, O(n), en ce qui concerne l'allocation de mémoire.
Structures de données
Le terme Structure de données, malgré ce que tout enseignant peut vous dire, n'a pas de définition unique.
Certains enseignants insisteront sur leur nature abstraite et sur la manière dont nous pouvons les représenter en mathématiques, certains enseignants insisteront sur la manière dont elles sont physiquement organisées dans l'espace mémoire, et certains insisteront sur la manière dont elles sont implémentées dans une spécification de langage particulière.
Je déteste vous dire cela, mais c'est en fait un problème très courant en informatique et en ingénierie : Un mot signifiant plusieurs choses et plusieurs mots signifiant une seule chose, tout en même temps.
Par conséquent, plutôt que d'essayer de rendre chaque type d'expert de chaque type de milieu académique ou professionnel heureux en utilisant une pléthore de définitions techniques, laissez-moi mécontenter tout le monde également en expliquant les choses aussi clairement que possible en anglais simple.
Aux fins de cet article, les Structures de données (DS) font référence aux manières dont nous représentons et regroupons les données de notre application dans nos programmes. Des choses comme les profils utilisateurs, les listes d'amis, les réseaux sociaux, les états de jeu, les meilleurs scores, etc.
Lorsqu'on considère les DS du point de vue physique du matériel et du système d'exploitation, il existe deux principales façons de construire une DS. Les deux façons tirent parti du fait que la mémoire physique est discrète (un mot sophistiqué pour comptable), et donc adressable.
Une façon facile d'imaginer cela est de penser aux adresses de rue et à la manière dont, selon la direction dans laquelle vous vous déplacez physiquement (et selon la manière dont votre pays organise les adresses de rue), l'adresse augmente ou diminue en valeur.
Tableau physique
La première façon tire parti du fait que nous pouvons regrouper des morceaux de données (par exemple une liste d'amis dans une application de médias sociaux) en un bloc de mémoire contiguë (physiquement les uns à côté des autres).
Il s'avère que c'est une manière très rapide et efficace pour un ordinateur de parcourir l'espace mémoire. Au lieu de donner à l'ordinateur une liste de taille n d'adresses pour chaque morceau de données, nous donnons à l'ordinateur une seule adresse désignant le début de cette DS dans la mémoire physique, et la taille de (c'est-à-dire, n) la DS en tant que valeur unique.
L'ensemble d'instructions pour faire cela pourrait être aussi simple que de dire à la machine de se déplacer de gauche à droite (ou dans n'importe quelle direction), de décrémenter la valeur de n de 1 à chaque mouvement, et de s'arrêter/retourner lorsque cette valeur atteint 0.
Listes de liens (adresses)
La deuxième façon nécessite que chaque morceau de données dans la structure elle-même contienne l'adresse(s) de l'élément suivant ou précédent (peut-être les deux ?) à l'intérieur de lui-même.
L'un des grands problèmes avec les espaces mémoire contigus est qu'ils présentent des problèmes lorsqu'il s'agit de croître (ajouter plus d'éléments) ou de rétrécir (cela peut fragmenter l'espace mémoire, ce que je n'expliquerai pas mais suggère une recherche rapide sur Google).
En ayant chaque morceau de données lier aux autres morceaux (généralement juste le précédent ou le suivant), il devient largement irrelevant où chaque morceau se trouve dans l'espace mémoire physique.
Par conséquent, nous pouvons faire croître ou rétrécir la structure de données avec une relative facilité. Vous devriez être en mesure de raisonner que puisque chaque partie de la structure stocke non seulement ses propres données, mais aussi l'adresse de l'élément suivant (ou plus que cela), alors chaque morceau nécessiterait nécessairement plus d'espace mémoire que avec l'approche de tableau contigu.
Cependant, si elle est finalement plus efficace dépend du type de problème que vous essayez de résoudre.
Les deux approches que j'ai discutées sont généralement connues sous le nom de Tableau et de Liste Chaînée. Avec très peu d'exceptions, la plupart de ce qui nous intéresse dans l'étude des DS est comment regrouper des collections de données qui ont une raison d'être regroupées, et comment le faire au mieux.
Comme j'ai essayé de le souligner, ce qui rend une structure meilleure dans une certaine situation peut la rendre pire dans une autre.
Vous devriez être en mesure de raisonner à partir des quelques paragraphes précédents qu'une Liste Chaînée est généralement plus adaptée à une collection dynamique (changeante), tandis qu'un Tableau est généralement plus adapté à une collection fixe – au moins en ce qui concerne l'efficacité du temps d'exécution et de l'espace.
Ne vous laissez pas tromper, cependant ! Ce n'est pas toujours le cas que notre principale préoccupation est de choisir la DS (ou l'algorithme) la plus efficace en termes de temps d'exécution et d'espace mémoire. Rappelez-vous, si n est très petit, alors s'inquiéter d'une nanoseconde ou de quelques bits de mémoire ici et là ne sont pas nécessairement aussi importants que la facilité d'utilisation et la lisibilité.
La dernière chose que je voudrais dire sur les DS est que j'ai observé un profond manque de consensus sur la différence entre une DS et un Type de Données (DT).
Encore une fois, je pense que cela est largement dû à différents experts abordant cela depuis différents horizons (mathématiques, circuits numériques, programmation de bas niveau, programmation de haut niveau) et au fait qu'il est vraiment assez difficile de faire une définition verbale de l'un qui ne décrit pas au moins partiellement (ou entièrement) l'autre.
Au risque de rendre la situation encore plus confuse, sur un niveau purement pratique, je considère les structures de données comme des choses qui sont indépendantes du système de types d'un langage de programmation de haut niveau (en supposant qu'il en ait un). D'un autre côté, un type de données est défini par et dans un tel système de types.
Mais je sais que la théorie des types elle-même est indépendante de tout système de types particulier, donc vous pouvez espérons-le voir à quel point il est délicat de dire quoi que ce soit de concret sur ces deux termes.
Algorithmes
J'ai pris beaucoup de temps pour expliquer les deux sujets précédents car ils me permettent d'introduire et de motiver ce sujet assez facilement.
Avant de continuer, je dois très brièvement essayer de démêler un autre gâchis de jargon. Pour expliquer le terme "algorithme" à ma manière, c'est en fait très simple : Un algorithme est un ensemble d'instructions (commandes) qui peuvent être comprises et exécutées (agies) par un Système de Traitement de l'Information (IPS).
Par exemple, si vous deviez suivre une recette pour cuisiner quelque chose, alors vous seriez l'IPS, l'algorithme serait la recette, et les ingrédients et les ustensiles de cuisine seraient les entrées de données (arguments).
Maintenant, selon cette définition, les mots fonction, méthode, procédure, opération, programme, script, sous-routine et algorithme pointent tous vers le même concept sous-jacent.
Ce n'est pas un accident – ces mots signifient tous fondamentalement la même chose. La confusion vient du fait que différents informaticiens et concepteurs de langages implémenteront (construiront) la même idée de manière légèrement différente. Ou encore plus déprimant, ils les construiront de la même manière mais donneront un nom différent. Je souhaite que ce ne soit pas le cas, mais le mieux que je puisse faire est de vous avertir.
C'est tout ce que vous devez savoir sur les algorithmes en général, alors soyons plus spécifiques sur la manière dont ils peuvent nous aider à écrire un meilleur code.
Rappelez-vous que notre principale préoccupation en tant qu'ingénieurs logiciels est d'écrire du code qui est garanti d'être efficace (au moins de manière à garder nos utilisateurs heureux) et sûr par rapport aux ressources système limitées.
Rappelez-vous également que j'ai précédemment déclaré que certaines structures de données performaient mieux que d'autres en termes de temps d'exécution et d'espace mémoire, en particulier lorsque n devient grand.
Il en va de même pour les algorithmes. Selon ce que vous essayez de faire, différents algorithmes performeront mieux que d'autres.
Il est également utile de noter que la structure de données tendra à façonner les algorithmes qui peuvent être appliqués au problème, donc sélectionner la bonne structure de données et le bon algorithme est le véritable art du génie logiciel.
Pour terminer ce troisième sujet principal, nous allons examiner deux méthodes courantes mais très différentes pour résoudre un problème : Rechercher un tableau ordonné. Par ordonné, je veux dire qu'il est ordonné de la plus petite à la plus grande, de la plus grande à la plus petite, ou même alphabétiquement.
De plus, supposez que l'algorithme reçoit une sorte de valeur cible en tant qu'argument, qui est ce que nous utilisons pour localiser un élément particulier. Cela devrait devenir clair dans l'exemple au cas où il y aurait une confusion.
Le problème d'exemple est le suivant : Nous avons une collection d'utilisateurs (peut-être chargés à partir d'une base de données ou d'un serveur), qui est triée de la plus petite à la plus grande par un champ appelé userId, qui est une valeur entière.
Supposons que cet userId provient de la prise de l'heure système (consultez Unix Time pour plus d'informations) juste avant la création du nouvel utilisateur. Arrondi à la plus petite valeur qui garantit toujours aucune valeur répétée.
Si la phrase précédente n'avait pas de sens, tout ce que vous devez savoir est que ceci est une collection triée sans répétitions.
Une manière simple d'écrire cet algorithme serait d'écrire ce que nous appellerons une Recherche Naïve (NS). Naïve, dans ce contexte, signifie simple, mais de manière mauvaise, ce qui fait référence au fait que nous disons simplement à l'ordinateur de commencer à une extrémité de la collection et de se déplacer vers l'autre jusqu'à ce qu'il trouve une correspondance avec l'index cible.
Cela est généralement réalisé en utilisant une sorte de boucle :
Fonction naiveSearch :
//cette fonction accepte un targetId entier à faire correspondre,
// et un tableau d'objets User comme arguments.
// Supposons pour simplifier que la recherche d'un User est garantie.
fun naiveSearch(targetId: Int, a: Array<User>): User {
a.forEach { user ->
if (targetId == user.userId) return user
}
}
Si nous n'avons que quelques centaines, ou même quelques milliers d'utilisateurs dans cette collection, alors nous pouvons nous attendre à ce que cette fonction retourne assez rapidement.
Mais supposons que nous travaillons dans une startup technologique de médias sociaux prospère, et que nous venons d'atteindre un million d'utilisateurs.
Vous devriez être en mesure de raisonner que naiveSearch a une complexité asymptotique de O(n) comme sa complexité de temps d'exécution dans le pire des cas. La raison en bref est que si l'utilisateur cible se trouve être situé à n, alors nous devons inévitablement parcourir toute la collection pour y arriver.
Si vous n'êtes pas déjà familier avec l'algorithme de Recherche Binaire (BS), alors préparez-vous à avoir l'esprit soufflé.
Que diriez-vous si je vous disais qu'en utilisant un algorithme BS pour rechercher notre collection avec un million d'éléments, vous ne ferez jamais plus de 20 comparaisons ? C'est exact ; 20 comparaisons (par opposition à 1 million avec NS) est le scénario du pire cas.
Maintenant, je vais expliquer comment BS fonctionne en principe, mais mon seul devoir à la maison pour vous est de l'implémenter dans votre langage de programmation préféré. Il se peut que le langage que vous choisissez ait déjà une implémentation BS dans sa bibliothèque standard, mais c'est un exercice d'apprentissage important !
En principe, plutôt que de rechercher une collection ordonnée une par une, de manière unidirectionnelle, nous commençons par regarder la valeur à l'index n/2. Donc dans une collection avec 10 éléments, nous vérifierions le cinquième élément. L'ordre est important, car nous pouvons ensuite comparer l'élément à n/2 avec notre cible :
Si la valeur de cet élément est supérieure à la cible, nous savons que l'élément que nous voulons doit être situé plus tôt dans la collection
Si la valeur de cet élément est inférieure à la cible, alors nous savons que l'élément que nous voulons doit être situé plus loin dans la collection
Vous devriez être en mesure de deviner ce qui se passe si nous avons une correspondance
Maintenant, l'idée est que nous divisons l'ensemble de données en deux à chaque itération. Supposons que la valeur à l'élément n/2 était inférieure à notre valeur cible. Nous sélectionnerions ensuite l'index du milieu entre n/2 et n.
À partir de là, notre algorithme continue à découper en arrière ou en avant en utilisant la même logique sur une plage d'index de plus en plus petite dans notre collection.
Cela nous amène à la beauté de l'algorithme BS appliqué à une collection triée : Plutôt que le temps qu'il faut pour compléter croître linéairement, ou exponentiellement par rapport à n, il croît logarithmiquement :
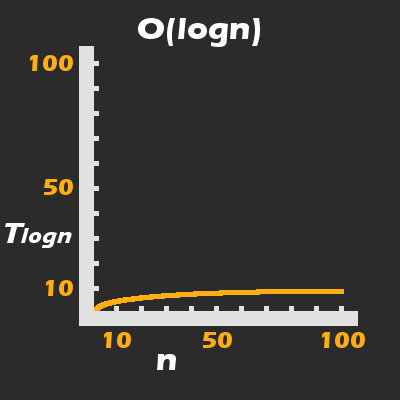
Une recherche binaire a une complexité de temps d'exécution logarithmique, ce qui signifie qu'elle gère les grandes valeurs de n comme un patron (très bien)
Si cet article est vraiment votre première introduction aux idées principales du génie logiciel, alors ne vous attendez pas à ce que tout ait un sens immédiatement.
Bien que j'espère que certaines de mes explications ont aidé, mon objectif principal était de vous donner une liste de base d'idées à étudier vous-même, et ce que je crois être un bon ordre dans lequel étudier ces idées.
La prochaine étape pour vous est de faire un plan pour apprendre ce domaine, et de passer à l'action. La section suivante est entièrement consacrée à la manière de procéder.
Comment apprendre le génie logiciel – quelques conseils pratiques
Je vais maintenant discuter de quelques idées et approches que j'ai personnellement utilisées pour rendre le processus d'apprentissage de diverses structures de données et algorithmes plus facile (mais pas facile !), à la fois sur le plan pratique et sur le plan motivationnel.
Je suis confiant qu'il y aura au moins un ou deux points ici qui seront utiles (en supposant que vous ne les ayez pas déjà découverts par vous-même), mais je veux également souligner que nos cerveaux peuvent fonctionner légèrement différemment. Prenez ce qui est utile et jetez le reste.
En tant qu'aide à l'apprentissage, vous pourriez également vouloir regarder ma leçon en direct sur YouTube où je couvre ce sujet. Ne sautez pas le reste de cet article cependant ; je vais beaucoup plus en détail ici !
Suivre une approche d'apprentissage basée sur des projets
C'est en fait la première chose que je dis à tout nouveau programmeur qui me demande la "meilleure façon" d'apprendre à coder. J'ai donné une version plus longue de cette explication à plusieurs reprises, mais je vais résumer l'idée générale.
Dans tout domaine de la programmation, vous remarquerez qu'il y a un nombre incroyablement grand de sujets à étudier, et le domaine lui-même évolue constamment, tant pour les universitaires que pour les professionnels de l'industrie.
Comme je l'ai mentionné dans l'introduction, non seulement je n'avais pas de programme pour guider mes études, mais j'avais également un temps limité pour étudier car j'avais un loyer à payer à la fin de chaque mois. Cela m'a conduit, par pure nécessité, à développer et à suivre mon approche d'apprentissage basée sur des projets.
En essence, ce que je vous suggère de faire est d'éviter d'apprendre les structures de données et les algorithmes en étudiant simplement les choses sujet par sujet et en prenant des notes sur chacun.
Au lieu de cela, vous allez commencer par choisir un sujet de base (comme ceux que j'ai couverts précédemment) et écrire immédiatement un extrait de code ou une petite application qui l'utilise.
J'ai créé un dépôt qui avait un package pour chaque famille de structures de données et d'algorithmes que je voulais apprendre. Pour les algorithmes généraux, c'était surtout les tris et les recherches (Tri à bulles, Tri par fusion, Tri rapide, Recherche binaire, etc.). Pour des structures de données plus spécifiques comme les listes chaînées, les arbres, les tas, les piles et autres, j'ai écrit à la fois la structure de données elle-même et quelques algorithmes spécifiques à cette structure de données particulière.
Maintenant, j'ai trouvé que certains types de structures de données étaient difficiles à comprendre et à implémenter au début.
Une famille de structures de données qui m'a posé problème pendant un certain temps s'appelait "Graphes". Le domaine en général est rempli de certains jargons particulièrement horribles et surchargés, mais ce sujet particulier a même un nom trompeur (indice : un meilleur nom serait "Réseaux").
Après avoir tourné en rond pendant plusieurs semaines (bien que, pour être honnête, j'apprenais cela en parallèle), j'ai finalement admis que j'avais besoin d'une raison claire d'utiliser cette structure de données dans un code d'application. Quelque chose pour justifier et motiver les nombreuses heures que j'allais passer à apprendre ce sujet.
Ayant précédemment construit un jeu de Sudoku en utilisant des algorithmes qui fonctionnaient avec des tableaux à deux et une dimension, je me suis souvenu avoir lu quelque part qu'il était possible de représenter et de résoudre un jeu de Sudoku en utilisant un Graphe Coloré Non Orienté.
Cela a été incroyablement utile, car j'étais déjà familier avec le domaine du problème du Sudoku, donc je pouvais me concentrer intensément sur les structures de données et les algorithmes.
Bien qu'il y ait encore beaucoup de choses que j'ai à apprendre, je ne peux pas décrire à quel point c'était satisfaisant lorsque j'ai écrit un algorithme qui a généré et résolu 102 puzzles de Sudoku en 450 millisecondes.
En parlant de cela, laissez-moi parler d'une autre façon d'écrire de meilleurs algorithmes qui peut également être une grande source de motivation et de fixation d'objectifs.
Testez votre code
Écoutez, je sais que beaucoup de gens rendent le sujet des tests un véritable cauchemar pour les débutants. Cela se produit parce qu'ils confondent l'idée très simple de la façon de tester le code avec certains outils très élaborés et déroutants que l'on peut optionnellement utiliser pour tester leur code. Mais celui-ci est important, alors restez avec moi.
Pour revenir aux bases, sans même parler de la notation Big O, comment savons-nous si un algorithme est plus efficace qu'un autre ? Bien sûr, nous devons les tester tous les deux.
Maintenant, il est important de mentionner que les tests de référence peuvent vous donner une bonne (ou même excellente) idée générale, mais ils sont également fortement influencés par le système dans lequel ils sont testés.
Plus vos tests doivent être précis, plus vous devrez vous soucier de votre environnement de test, de sa configuration et de sa précision. Cependant, pour le type de code que j'écris généralement, une bonne idée générale est tout ce dont j'ai besoin.
Il y a deux types de tests que je trouve les plus utiles lorsque j'écris mes algorithmes, à la fois pour la pratique et le code de production. Le premier type de test répond à une question très simple : Est-ce que cela fonctionne ?
Pour prendre un exemple de mon application Graph Sudoku, l'un des premiers obstacles pour moi a été de construire ce qu'on appelle une Liste d'Adjacence pour des Sudokus de tailles variées (j'ai testé 4, 9, 16 et 25, qui sont, non par accident, des carrés parfaits (mathématiquement parlant).
Je ne peux pas expliquer en détail ce qu'est une Liste d'Adjacence, mais pensez-y conceptuellement comme un Réseau de nœuds et de lignes (appelées arêtes pour une raison quelconque). En pratique, elle forme la structure virtuelle du "Graphique".
Dans les règles du Sudoku, chaque colonne, ligne ou sous-grille de nombres ne peut pas contenir de répétitions. À partir de ces règles, nous pouvons déduire que dans un Sudoku 9x9, il doit y avoir 81 nœuds (un pour chaque nombre), et chaque nœud devrait posséder 21 arêtes (une pour chaque autre nœud dans une colonne, ligne ou sous-grille donnée).
La première étape consistait simplement à vérifier pour s'assurer que je construisais le bon nombre de nœuds :
@Test
fun verifyGraphSize() {
//note : En Kotlin, les crochets suivant un nom de classe désignent
//une instruction d'assignation ; il n'utilise pas de mot-clé "new"
val fourGraph = SudokuPuzzle(4, Difficulty.MEDIUM)
val nineGraph = SudokuPuzzle(9, Difficulty.MEDIUM)
val sixteenGraph = SudokuPuzzle(16, Difficulty.MEDIUM)
assert(fourGraph.graph.size == 16)
assert(nineGraph.graph.size == 81)
assert(sixteenGraph.graph.size == 256)
}
L'algorithme pour cela était vraiment assez facile à écrire, mais les choses étaient légèrement plus difficiles pour le suivant.
Maintenant, je devais, comme on dit en jargon de Graphique, construire les arêtes. Cela était un peu plus délicat car j'ai dû écrire quelques algorithmes pour sélectionner les lignes, les colonnes et les sous-grilles de taille dynamique. Encore une fois, pour confirmer que j'étais sur la bonne voie, j'ai écrit un autre test :
@Test
fun verifyEdgesBuilt() {
val fourGraph = SudokuPuzzle(4, Difficulty.MEDIUM)
val nineGraph = SudokuPuzzle(9, Difficulty.MEDIUM)
val sixteenGraph = SudokuPuzzle(16, Difficulty.MEDIUM)
fourGraph.graph.forEach {
assert(it.value.size == 8)
}
nineGraph.graph.forEach {
assert(it.value.size == 21)
}
sixteenGraph.graph.forEach {
assert(it.value.size == 40)
}
}
Parfois, je suivais l'approche du Développement Piloté par les Tests (TDD) et j'écrivais les tests avant les algorithmes, et parfois j'écrivais les tests après les algorithmes.
Dans tous les cas, une fois que j'ai pu vérifier la justesse de chaque algorithme au point où je générais un puzzle de Sudoku résolu, de taille variable, il était temps d'écrire un ensemble différent de tests : des Benchmarks !
Ce type particulier de test de benchmark est assez direct, mais c'est tout ce dont j'avais besoin. Pour tester l'efficacité de mes algorithmes, qui à ce stade pouvaient construire et résoudre un Sudoku généré aléatoirement, j'ai écrit un test qui générait 101 puzzles de Sudoku :
@Test
fun solverBenchmarks() {
//Exécuter le code une fois pour espérer réchauffer le JIT
SudokuPuzzle(9, Difficulty.EASY).graph.values.forEach {
assert(it.first.color != 0)
}
//boucle 100 fois
(1..100).forEach {
SudokuPuzzle(9, Difficulty.EASY)
}
}
Initialement, j'avais deux appels à System.nanoTime() immédiatement avant et après la génération de 100 puzzles, et j'ai soustrait la différence pour obtenir un nombre incompréhensible.
Cependant, mon IDE suivait également le temps qu'un test mettait pour se compléter en minutes, secondes et millisecondes, donc j'ai finalement opté pour cela. Le premier ensemble de benchmarks (pour les puzzles 9x9) s'est déroulé comme suit :
/**
* Premiers benchmarks (101 puzzles) :
* 2.423313576E9 (4 m 3 s 979 ms pour compléter)
* 2.222165776E9 (3 m 42 s 682 ms pour compléter)
* 2.002508687E9 (3 m 20 s 624 ms ...)
* ...
*/
Bien que je n'avais pas beaucoup de point de référence, je savais qu'il fallait plus d'une seconde pour générer un Sudoku 9x9, ce qui était un très mauvais signe.
Je n'étais pas satisfait de la manière dont je préchargeais le Graphique avec certains nombres valides à l'avance, donc j'ai décidé de refactoriser mon approche.
Naturellement, le résultat après avoir imaginé une nouvelle façon de faire cela était pire :
/**
* ...
* Deuxièmes benchmarks après refactorisation de l'algorithme de graine : (101 puzzles)
* 3.526342681E9 (6 m 1 s 89 ms)
* 3.024547185E9 (5 m 4 s 971 ms)
* ...
*/
Après plusieurs autres benchmarks qui semblaient empirer légèrement avec le temps, j'étais assez démoralisé et me demandais quoi faire.
J'avais ce que je pensais être une manière très ingénieuse de rendre mon algorithme plus ou moins pointilleux en fonction de sa certitude à placer un nombre dans le puzzle. Cela ne fonctionnait pas très bien en pratique, cependant.
Comme c'est souvent le cas, lors de la 400ème passe de mon code via un stepper de code (partie d'un outil de débogage), j'ai remarqué que j'avais une légère erreur qui concernait la manière dont j'ajustais la valeur qui dictait à quel point mon algorithme était pointilleux.
Ce qui s'est passé ensuite m'a soufflé l'esprit.
J'ai exécuté un autre test de benchmark et obtenu un résultat étrange :
/**
* ...
* Cinquièmes benchmarks niceValue ajusté uniquement après une
* recherche assez complète (boundary * boundary)
* pour une allocation appropriée 101 puzzles :
* 3774511.0 (480 ms)
* ...
*/
J'étais dans un complet état d'incrédulité, donc la première chose que j'ai faite a été d'annuler la modification que je venais de faire et de relancer le test. Après 5 minutes, j'ai arrêté le test car c'était clairement la différence qui changeait la donne, et j'ai procédé à l'exécution de cinq autres benchmarks :
/**
* 3482333.0 (456 ms)
* 3840088.0 (468 ms)
* 3813932.0 (469 ms)
* 3169410.0 (453 ms)
* 3908975.0 (484 ms)
* ...
*/
Juste pour le plaisir, j'ai décidé d'essayer de construire 101 puzzles 16x16. Auparavant, je ne pouvais même pas en construire un (au moins j'ai arrêté d'essayer après que le test ait duré 10 minutes) :
/**
* 16x16 (tous les benchmarks précédents étaient pour 9 * 9) :
* 9.02626914E8 (1 m 31 s 45 ms)
* 7.75323967E8 (1 m 20 s 155 ms)
* 7.06454975E8 (1 m 11 s 838 ms)
* ...
*/
Le point que j'essaie de communiquer est le suivant : Ce n'est pas seulement que l'écriture de tests m'a permis de vérifier que mes algorithmes fonctionnaient. Ils m'ont permis d'avoir une manière objective d'établir leur efficacité.
Par extension, cela m'a donné un moyen très clair de savoir laquelle des 50 modifications différentes de l'algorithme que j'ai apportées avait réellement un effet positif ou négatif sur le résultat.
Cela est important pour le succès de l'application, mais c'était également incroyablement positif pour ma propre motivation et ma santé psychologique.
Ce que je n'ai pas encore mentionné, c'est que le temps qu'il m'a fallu pour passer du premier benchmark au cinquième (le rapide), était d'environ 40 heures (quatre jours à 10 heures par jour).
J'étais vraiment assez démoralisé au quatrième jour, mais lorsque j'ai finalement ajusté les choses de la bonne manière, c'était la première fois que je me sentais comme un vrai ingénieur logiciel au lieu de quelqu'un qui l'étudiait juste pour le plaisir.
Pour vous laisser avec une grande image, après avoir exécuté les tests 16x16 et vu qu'ils étaient prometteurs, j'ai pris un bon quart d'heure pour courir autour de ma propriété rurale en hurlant comme un chimpanzé excité qui vient de recevoir une dose d'adrénaline.
Ma dernière suggestion
Je vais garder celle-ci courte et douce. La pire chose que vous puissiez faire en tant qu'étudiant, lorsque vous n'arrivez pas à comprendre quelque chose de difficile et de compliqué, est de vous en vouloir.
Les bons enseignants et les bonnes explications sont rares, et cela est particulièrement vrai pour les sujets que la plupart d'entre nous trouvent relativement secs et ennuyeux.
J'ai dû regarder environ quatre vidéos, lire environ cinq articles/chapitres de manuels, et plonger à l'aveugle dans l'écriture de code qui n'avait initialement aucun sens pour moi, juste pour commencer avec les Graphes.
Cela peut être une bonne ou une mauvaise nouvelle pour vous, mais je travaille très dur dans ce que je fais, et je trouve rarement des choses dans mon domaine qui sont naturelles ou faciles pour moi.
Mon objectif avec cet article n'a jamais été de laisser entendre que l'apprentissage du génie logiciel était facile pour moi, ni qu'il le sera pour vous.
La différence est que l'on me dit de temps en temps que j'explique bien les choses, et que contrairement aux personnes qui se contentent de régurgiter ce que disent les autres enseignants, je prends le temps de découvrir ce qui fonctionne ou ne fonctionne pas pour moi, et j'essaie de partager cela avec vous.
J'espère vraiment que quelque chose dans cet article vous a été utile. Bonne chance avec vos objectifs d'apprentissage, et bon codage !
Avant de partir...
Si vous aimez mes écrits, vous aimerez probablement mon contenu vidéo. Je crée tout, depuis des tutoriels dédiés sur des sujets spécifiques, jusqu'à des sessions de questions-réponses en direct hebdomadaires, en passant par des marathons de codage de 10 heures et plus où je construis une application entière en une seule séance.