

Article original : How to Learn Software Design and Architecture - a Roadmap
Par Khalil Stemmler
Cet article est un résumé de ce que j'écris dans mon nouveau projet, solidbook.io - Le Guide de la Conception et de l'Architecture Logicielle avec TypeScript. Allez y jeter un coup d'œil si vous aimez cet article.
C'est fou pour moi de penser au fait que Facebook était autrefois un fichier texte vide sur l'ordinateur de quelqu'un.
Lol.
Cette dernière année, je me suis plongé dans la conception et l'architecture logicielle, la Conception Pilotée par le Domaine, et l'écriture d'un livre à ce sujet, et je voulais prendre un moment pour essayer de rassembler tout cela en quelque chose d'utile que je pourrais partager avec la communauté.
Voici ma feuille de route pour apprendre la conception et l'architecture logicielle.
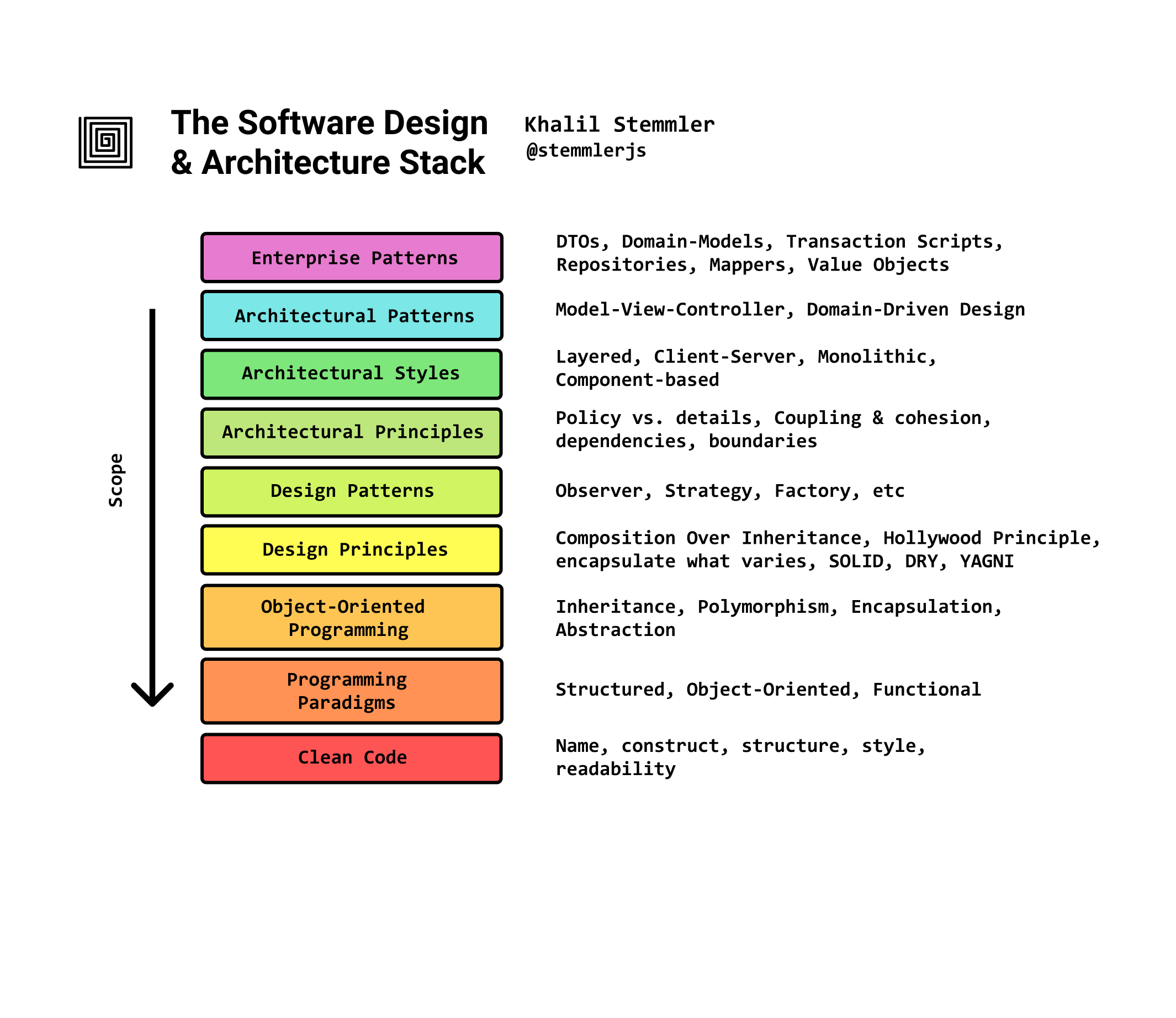
Je l'ai divisée en deux artefacts : la pile et la carte.
La Pile
Similaire au modèle OSI en réseau, chaque couche se construit sur la fondation de la précédente.
La Carte
Bien que je pense que la pile est bonne pour voir le tableau d'ensemble de la façon dont tout fonctionne ensemble, la carte est un peu plus détaillée (et inspirée par la feuille de route du développeur web) et, par conséquent, je pense qu'elle est plus utile.
La voici ci-dessous ! Pour forker le dépôt, lire mon article détaillé et le télécharger en haute résolution, cliquez ici.

Étape 1 : Code propre
La toute première étape pour créer un logiciel durable est de savoir comment écrire du code propre.
Le code propre est un code facile à comprendre et à modifier. À bas niveau, cela se manifeste par quelques choix de conception comme :
- être cohérent
- préférer des noms de variables, méthodes et classes significatifs plutôt que d'écrire des commentaires
- s'assurer que le code est correctement indenté et espacé
- s'assurer que tous les tests peuvent s'exécuter
- écrire des fonctions pures sans effets secondaires
- ne pas passer de null
Écrire du code propre est incroyablement important.
Pensez à cela comme à un jeu de jenga.
Pour garder la structure de notre projet stable dans le temps, des choses comme l'indentation, les petites classes et méthodes, et les noms significatifs, portent leurs fruits à long terme.
La meilleure ressource pour apprendre à écrire du code propre est le livre d'Uncle Bob, "Clean Code".
Étape 2 : Paradigmes de programmation
Maintenant que nous écrivons du code lisible et facile à maintenir, il serait bon de vraiment comprendre les 3 principaux paradigmes de programmation et la manière dont ils influencent notre façon d'écrire du code.
Dans le livre d'Uncle Bob, "Clean Architecture", il attire l'attention sur le fait que :
- La Programmation Orientée Objet est l'outil le mieux adapté pour définir comment nous franchissons les limites architecturales avec le polymorphisme et les plugins
- La programmation fonctionnelle est l'outil que nous utilisons pour pousser les données vers les limites de nos applications
- et la programmation structurée est l'outil que nous utilisons pour écrire des algorithmes
Cela implique que les logiciels efficaces utilisent un hybride des 3 styles de paradigmes de programmation à différents moments.
Bien que vous pourriez adopter une approche strictement fonctionnelle ou strictement orientée objet pour écrire du code, comprendre où chacun excelle améliorera la qualité de vos conceptions.
Si tout ce que vous avez est un marteau, tout semble être un clou.
Ressources
Pour la programmation fonctionnelle, consultez :
Étape 3 : Programmation Orientée Objet
Il est important de savoir comment chacun des paradigmes fonctionne et comment ils vous incitent à structurer le code à l'intérieur, mais en ce qui concerne l'architecture, la Programmation Orientée Objet est clairement l'outil adapté.
Non seulement la programmation orientée objet nous permet de créer une architecture de plugin et d'intégrer de la flexibilité dans nos projets ; la POO vient avec les 4 principes de la POO (encapsulation, héritage, polymorphisme et abstraction) qui nous aident à créer des modèles de domaine riches.
La plupart des développeurs apprenant la Programmation Orientée Objet n'arrivent jamais à cette partie : apprendre à créer une implémentation logicielle du domaine problème, et la situer au centre d'une application web en couches.
La programmation fonctionnelle peut sembler être la solution à tous les problèmes dans ce scénario, mais je recommanderais de se familiariser avec la conception pilotée par les modèles et la Conception Pilotée par le Domaine pour comprendre le tableau d'ensemble de la manière dont les modélisateurs d'objets sont capables d'encapsuler une entreprise entière dans un modèle de domaine sans dépendance.
Pourquoi est-ce un énorme avantage ?
C'est énorme parce que si vous pouvez créer un modèle mental d'une entreprise, vous pouvez créer une implémentation logicielle de cette entreprise.
Étape 4 : Principes de conception
À ce stade, vous comprenez que la Programmation Orientée Objet est très utile pour encapsuler des modèles de domaine riches et résoudre le 3ème type de "Problèmes Logiciels Difficiles" - Domaines Complexes.
Mais la POO peut introduire certains défis de conception.
Quand devrais-je utiliser la composition ?
Quand devrais-je utiliser l'héritage ?
Quand devrais-je utiliser une classe abstraite ?
Les principes de conception sont des meilleures pratiques orientées objet bien établies et testées en combat que vous utilisez comme garde-fous.
Voici quelques exemples de principes de conception courants que vous devriez vous familiariser :
- Composition plutôt que héritage
- Encapsuler ce qui varie
- Programmer contre des abstractions, pas des concretions
- Le principe hollywoodien : "Ne nous appelez pas, nous vous appellerons"
- Les principes SOLID, en particulier le principe de responsabilité unique
- DRY (Ne vous répétez pas)
- YAGNI (Vous n'en aurez pas besoin)
Assurez-vous de tirer vos propres conclusions, cependant. Ne suivez pas simplement ce que quelqu'un d'autre dit que vous devriez faire. Assurez-vous que cela a du sens pour vous.
Étape 5 : Modèles de conception
Presque tous les problèmes en logiciel ont été catégorisés et résolus déjà. Nous appelons ces modèles : des modèles de conception, en fait.
Il existe 3 catégories de modèles de conception : créationnels, structurels, et comportementaux.
Créationnels
Les modèles créationnels sont des modèles qui contrôlent la manière dont les objets sont créés.
Exemples de modèles créationnels :
- Le modèle Singleton, pour s'assurer qu'une seule instance d'une classe peut exister
- Le modèle Abstract Factory, pour créer une instance de plusieurs familles de classes
- Le modèle Prototype, pour commencer avec une instance qui est clonée à partir d'une existante
Structurels
Les modèles structurels sont des modèles qui simplifient la manière dont nous définissons les relations entre les composants.
Exemples de modèles de conception structurels :
- Le modèle Adapter, pour créer une interface permettant à des classes qui normalement ne peuvent pas travailler ensemble, de travailler ensemble.
- Le modèle Bridge, pour diviser une classe qui devrait en fait être une ou plusieurs, en un ensemble de classes appartenant à une hiérarchie, permettant aux implémentations d'être développées indépendamment les unes des autres.
- Le modèle Decorator, pour ajouter des responsabilités aux objets dynamiquement.
Comportementaux
Les modèles comportementaux sont des modèles courants pour faciliter une communication élégante entre les objets.
Exemples de modèles comportementaux :
- Le modèle Template, pour reporter les étapes exactes d'un algorithme à une sous-classe.
- Le modèle Mediator, pour définir les canaux de communication exacts autorisés entre les classes.
- Le modèle Observer, pour permettre aux classes de s'abonner à quelque chose d'intéressant, et d'être notifiées lorsqu'un changement se produit.
Critiques des modèles de conception
Les modèles de conception sont formidables et tout, mais parfois ils peuvent ajouter une complexité supplémentaire à nos conceptions. Il est important de se rappeler YAGNI et d'essayer de garder nos conceptions aussi simples que possible. N'utilisez les modèles de conception que lorsque vous êtes vraiment sûr d'en avoir besoin. Vous saurez quand ce sera le cas.
Si nous savons ce que chacun de ces modèles est, quand les utiliser, et quand ne même pas se donner la peine de les utiliser, nous sommes en bonne voie pour commencer à comprendre comment architecturer des systèmes plus grands.
La raison derrière cela est que les modèles architecturaux ne sont que des modèles de conception agrandis à l'échelle du haut niveau, où les modèles de conception sont des implémentations de bas niveau (plus proches des classes et fonctions).
Ressources
Refactoring Guru - Design Patterns
Étape 6 : Principes architecturaux
Nous sommes maintenant à un niveau de réflexion plus élevé, au-delà du niveau des classes.
Nous comprenons maintenant que les décisions que nous prenons pour organiser et construire des relations entre les composants au niveau haut et bas, auront un impact significatif sur la maintenabilité, la flexibilité et la testabilité de notre projet.
Apprenez les principes directeurs qui vous aident à construire la flexibilité dont votre base de code a besoin afin de pouvoir réagir aux nouvelles fonctionnalités et exigences, avec le moins d'efforts possible.
Voici ce que je recommanderais d'apprendre dès le départ :
- Principes de conception des composants : Le Principe d'Abstraction Stable, Le Principe de Dépendance Stable, et Le Principe de Dépendance Acyclique, pour savoir comment organiser les composants, leurs dépendances, quand les coupler, et les implications de la création accidentelle de cycles de dépendance et de la dépendance à des composants instables.
- Politique vs. Détail, pour comprendre comment séparer les règles de votre application des détails d'implémentation.
- Limites, et comment identifier les sous-domaines auxquels appartiennent les fonctionnalités de votre application.
Uncle Bob a découvert et documenté à l'origine bon nombre de ces principes, donc la meilleure ressource pour en apprendre davantage est à nouveau, "Clean Architecture".
Étape 7 : Styles architecturaux
L'architecture concerne les éléments qui comptent.
Il s'agit d'identifier ce dont un système a besoin pour réussir, puis de maximiser les chances de succès en choisissant l'architecture qui correspond le mieux aux exigences.
Par exemple, un système qui a beaucoup de complexité logique métier bénéficierait de l'utilisation d'une architecture en couches pour encapsuler cette complexité.
Un système comme Uber doit pouvoir gérer beaucoup d'événements en temps réel à la fois et mettre à jour les positions des conducteurs, donc une architecture de style publication-abonnement pourrait être la plus efficace.
Je me répète ici parce qu'il est important de noter que les 3 catégories de styles architecturaux sont similaires aux 3 catégories de modèles de conception, car les styles architecturaux sont des modèles de conception à haut niveau.
Structurel
Les projets avec des niveaux variables de composants et une fonctionnalité étendue bénéficieront ou souffriront de l'adoption d'une architecture structurelle.
Voici quelques exemples :
- Les architectures basées sur les composants mettent l'accent sur la séparation des préoccupations entre les composants individuels d'un système. Pensez à Google pendant une seconde. Considérez combien d'applications ils ont dans leur entreprise (Google Docs, Google Drive, Google Maps, etc). Pour les plateformes avec beaucoup de fonctionnalités, les architectures basées sur les composants divisent les préoccupations en composants indépendants faiblement couplés. Il s'agit d'une séparation horizontale.
- Monolithique signifie que l'application est combinée en une seule plateforme ou programme, déployée en une seule fois. Note : Vous pouvez avoir une architecture basée sur les composants ET monolithique si vous séparez correctement vos applications, mais les déployez toutes en une seule pièce.
- Les architectures en couches séparent les préoccupations verticalement en découpant le logiciel en couches d'infrastructure, d'application et de domaine.

Un exemple de découpage des préoccupations d'une application verticalement en utilisant une architecture en couches. Lisez ici pour plus d'informations sur la façon de faire cela.
Messagerie
Selon votre projet, la messagerie peut être un composant vraiment important pour le succès du système. Pour des projets comme celui-ci, les architectures basées sur les messages s'appuient sur les principes de la programmation fonctionnelle et les modèles de conception comportementaux comme le modèle d'observateur.
Voici quelques exemples de styles architecturaux basés sur les messages :
- Les architectures basées sur les événements considèrent tous les changements significatifs d'état comme des événements. Par exemple, dans une application d'échange de vinyles, l'état d'une offre peut passer de "en attente" à "acceptée" lorsque les deux parties sont d'accord sur l'échange.
- Les architectures publication-abonnement s'appuient sur le modèle de conception Observer en en faisant la méthode de communication principale entre le système lui-même, les utilisateurs finaux/clients, et d'autres systèmes et composants.
Distribué
Une architecture distribuée signifie simplement que les composants du système sont déployés séparément et fonctionnent en communiquant via un protocole réseau. Les systèmes distribués peuvent être très efficaces pour mettre à l'échelle le débit, mettre à l'échelle les équipes et déléguer (des tâches potentiellement coûteuses ou) la responsabilité à d'autres composants.
Quelques exemples de styles architecturaux distribués sont :
- L'architecture client-serveur. L'une des architectures les plus courantes, où nous divisons le travail à faire entre le client (présentation) et le serveur (logique métier).
- Les architectures pair-à-pair distribuent les tâches de la couche application entre des participants ayant les mêmes privilèges, formant un réseau pair-à-pair.
Étape 8 : Modèles architecturaux
Les modèles architecturaux expliquent en détail tactique comment implémenter réellement l'un de ces styles architecturaux.
Voici quelques exemples de modèles architecturaux et des styles dont ils héritent :
- Domain-Driven Design est une approche du développement logiciel contre des domaines problème vraiment complexes. Pour que DDD soit le plus réussi, nous devons implémenter une architecture en couches afin de séparer les préoccupations d'un modèle de domaine des détails infrastructurels qui font fonctionner l'application, comme les bases de données, les serveurs web, les caches, etc.
- Model-View Controller est probablement le modèle architectural le plus connu pour développer des applications basées sur une interface utilisateur. Il fonctionne en divisant l'application en 3 composants : modèle, vue et contrôleur. MVC est incroyablement utile lorsque vous commencez, et il vous aide à vous appuyer sur d'autres architectures, mais il arrive un moment où nous réalisons que MVC n'est pas suffisant pour les problèmes avec beaucoup de logique métier.
- Event sourcing est une approche fonctionnelle où nous stockons uniquement les transactions, et jamais l'état. Si nous avons besoin de l'état, nous pouvons appliquer toutes les transactions depuis le début des temps.
Étape 9 : Modèles d'entreprise
Tout modèle architectural que vous choisissez introduira un certain nombre de constructions et de jargon technique à vous familiariser et à décider s'il vaut la peine de l'utiliser ou non.
Prenons un exemple que beaucoup d'entre nous connaissent, dans MVC, la vue contient tout le code de la couche de présentation, le contrôleur traduit les commandes et requêtes de la vue en requêtes qui sont traitées par le modèle et retournées par le contrôleur.
Où dans le Modèle (M) traitons-nous ces choses ?:
- logique de validation
- règles invariantes
- événements de domaine
- cas d'utilisation
- requêtes complexes
- et logique métier
Si nous utilisons simplement un ORM (mappeur objet-relationnel) comme Sequelize ou TypeORM comme modèle, toutes ces choses importantes sont laissées à l'interprétation de l'endroit où elles devraient aller, et se retrouvent dans une couche non spécifiée entre (ce qui devrait être un modèle riche) et le contrôleur.

Tiré de "3.1 - Slim (Logic-less) models" dans solidbook.io.
Si j'ai appris une chose jusqu'à présent dans mon parcours au-delà de MVC, c'est que il existe une construction pour tout.
Pour chacune de ces choses que MVC ne parvient pas à adresser, il existe d'autres modèles d'entreprise pour les résoudre. Par exemple :
- Entités décrivent des modèles qui ont une identité.
- Objets de Valeur sont des modèles qui n'ont pas d'identité, et peuvent être utilisés pour encapsuler la logique de validation.
- Événements de Domaine sont des événements qui signifient qu'un événement métier pertinent s'est produit, et peuvent être souscrits par d'autres composants.
Selon le style architectural que vous avez choisi, il y aura une tonne d'autres modèles d'entreprise à apprendre pour implémenter ce modèle à son plein potentiel.
Modèles d'intégration
Une fois votre application opérationnelle, à mesure que vous obtenez de plus en plus d'utilisateurs, vous pourriez rencontrer des problèmes de performance. Les appels API peuvent prendre beaucoup de temps, les serveurs peuvent planter à cause d'une surcharge de requêtes, etc. Pour résoudre ces problèmes, vous pourriez lire sur l'intégration de choses comme les files d'attente de messages ou les caches afin d'améliorer les performances.
C'est probablement le truc le plus difficile : l'évolutivité, les audits et les performances.
Concevoir un système pour l'évolutivité peut être incroyablement difficile. Cela nécessite une compréhension approfondie des limitations de chaque composant au sein de l'architecture, et un plan d'action pour atténuer le stress sur votre architecture et continuer à servir les requêtes dans des situations de trafic élevé.
Il y a aussi le besoin d'auditer ce qui se passe dans votre application. Les grandes entreprises ont besoin de pouvoir effectuer des audits pour identifier les problèmes de sécurité potentiels, comprendre comment les utilisateurs utilisent leurs applications, et avoir un journal de tout ce qui s'est passé.
Cela peut être difficile à implémenter, mais les architectures courantes finissent par être basées sur les événements et s'appuient sur une large gamme de concepts, principes et pratiques de conception de logiciels et de systèmes comme Event Storming, DDD, CQRS (ségrégation des commandes et requêtes), et Event Sourcing.
J'espère que cela vous a été utile !
Faites-moi savoir si vous avez des suggestions ou des questions.
Santé !
Lisez le livre sur la conception et l'architecture logicielle
khalilstemmler.com - J'enseigne les meilleures pratiques avancées de TypeScript & Node.js pour les applications à grande échelle et comment écrire des logiciels flexibles et maintenables.