


Article original : How to Match Parentheses in JavaScript without Using Regex
Lors de l'écriture de mon interpréteur Lisp (pour le dialecte Scheme, plus précisément), j'ai décidé d'inclure la prise en charge des crochets. Je l'ai fait parce que certains livres sur Scheme les utilisent de manière interchangeable avec les parenthèses. Mais je ne voulais pas rendre l'analyseur syntaxique trop complexe, donc je n'ai pas vérifié si les paires de crochets correspondaient.
Dans mon interpréteur Lisp, les crochets pouvaient être mélangés comme ceci :
(let [(x 10])
[+ x x)]
Le code ci-dessus est un exemple d'une S-Expression où nous avons des tokens, une séquence de caractères avec une signification (comme le nom let ou le nombre 10), et des crochets/parenthèses. Cependant, le code n'est pas valide car il mélange des paires de parenthèses et de crochets.
(let [(x 10)]
[+ x x])
Il s'agit de la syntaxe Lisp correcte (si les crochets sont pris en charge), où les parenthèses ouvrantes correspondent toujours aux parenthèses fermantes et les crochets ouvrants correspondent toujours aux crochets fermants.
Dans cet article, je vais vous montrer comment détecter si l'entrée est la deuxième S-Expression valide et non la première S-Expression invalide.
Nous allons également gérer des cas comme celui-ci :
(define foo 10))))
Dans le code ci-dessus, vous voyez une syntaxe invalide avec plus de parenthèses fermantes que d'ouvrantes.
En termes simples, nous allons détecter si les paires de caractères ouvrants et fermants comme (), [] et {} correspondent à l'intérieur de la chaîne comme "[foo () {bar}]".
La solution à ce problème peut être utile lors de l'implémentation d'un analyseur Lisp, mais vous pouvez également l'utiliser à d'autres fins (comme une sorte de validation ou une partie d'un évaluateur d'expressions mathématiques). C'est aussi un bon exercice.
NOTE : pour comprendre cet article et le code, vous n'avez pas besoin de connaître quoi que ce soit sur Lisp. Mais si vous voulez plus de contexte, vous pouvez lire cet article : Qu'est-ce que Lisp et Scheme ?
Appariement avec la structure de données Stack
Vous pourriez penser que la manière la plus simple de résoudre ce problème est d'utiliser des Expressions Régulières (RegExp). Il peut être possible d'utiliser Regex pour des cas simples, mais cela deviendra rapidement trop complexe et posera plus de problèmes que cela n'en résout.
En fait, la manière la plus simple d'apparier les caractères ouvrants et fermants est d'utiliser la stack. Stack est la structure de données la plus simple. Nous avons deux opérations de base : push, pour ajouter un élément à la stack, et pop, pour retirer un élément.
Cela fonctionne de manière similaire à une pile de livres. Le dernier élément que vous placez sur la pile sera le premier que vous retirez.
Vous pouvez en savoir plus sur cette structure de données dans cet article : Data Structures 101: Stacks.
Avec une stack, il est plus facile de traiter (analyser) les caractères qui ont un début et une fin, comme les balises XML ou les simples parenthèses.
Par exemple, disons que nous avons ce code XML :
<element><item><sub-item>text</sub-item></item></element>
Lorsque nous utilisons la stack, la dernière balise que nous ouvrons (par exemple, <sub-item> interne) sera toujours la première que nous devons fermer (si le XML est valide).
Ainsi, si nous utilisons la stack, nous pouvons pousser l'élément <sub-item> lorsque nous l'ouvrons, et lorsque nous devons le fermer, nous pouvons le retirer de la stack. Nous devons simplement nous assurer que le dernier élément de la stack (qui est toujours la balise ouvrante) correspond à la balise fermante.
Nous aurons exactement la même logique avec les parenthèses.
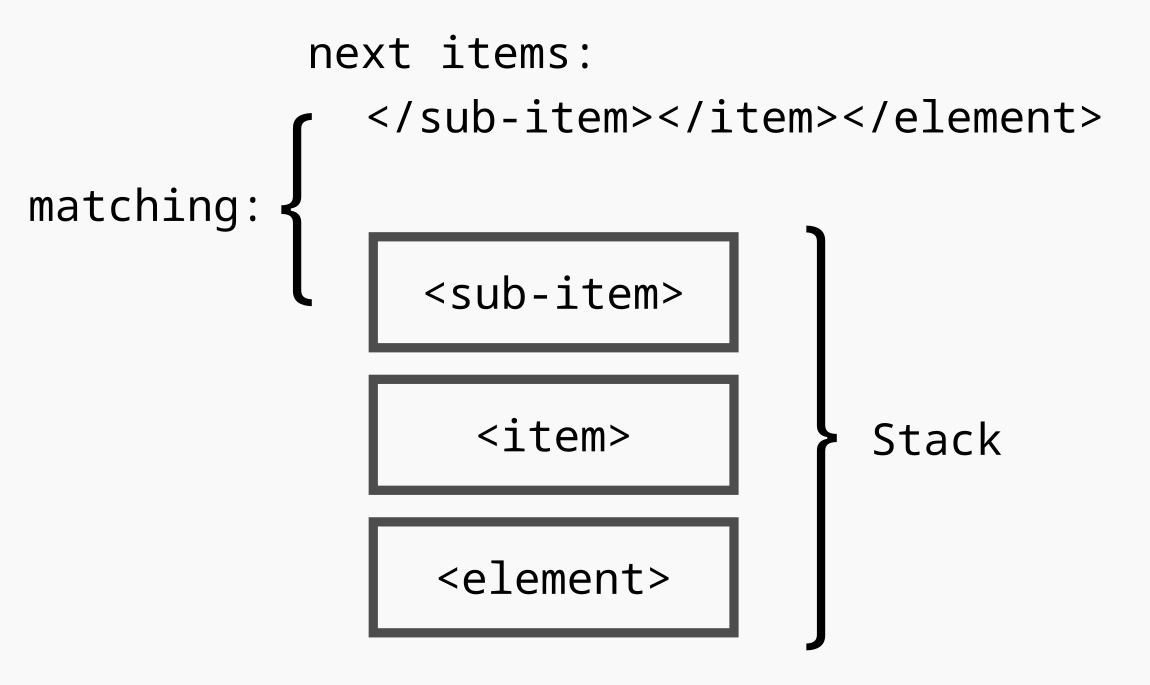
Notez que si nous avons des balises XML auto-fermantes, nous pouvons les ignorer puisqu'elles sont ouvertes et automatiquement fermées.
Les tableaux en JavaScript ont les deux méthodes (push et pop), donc ils peuvent être utilisés comme une Stack. Mais il est plus pratique de créer une abstraction sous la forme d'une classe, afin que nous puissions ajouter des méthodes supplémentaires comme top() et is_empty() qui sont plus faciles à lire.
Mais même si nous n'ajoutions pas de nouvelles méthodes, il est toujours préférable de créer des abstractions comme celle-ci, car cela rend le code plus simple et plus facile à lire.
La plupart des développeurs connaissent les structures de données courantes et les reconnaîtront immédiatement sans avoir besoin d'y réfléchir. La chose la plus importante en programmation est d'oublier les éléments non liés qui sont requis à un moment donné. La mémoire humaine est limitée et ne peut retenir qu'environ 4 ± 1 éléments à la fois. Vous pouvez en savoir plus sur la mémoire à court terme sur Wikipedia.
class Stack {
#data;
constructor() {
// création d'un nouveau tableau vide en tant que propriété cachée
this.#data = [];
}
push(item) {
// la méthode push utilise simplement la méthode native Array::push()
// et ajoute l'élément à la fin du tableau
this.#data.push(item);
}
len() {
// taille de la Stack
return this.#data.length;
}
top() {
// puisque les éléments sont ajoutés à la fin
// le sommet de la stack est le dernier élément
return this.#data[this.len() - 1];
}
pop() {
// pop est similaire à push et utilise la méthode native Array::pop()
// elle supprime et retourne le dernier élément du tableau
return this.#data.pop();
}
is_empty() {
// ce raccourci de commentaire !0 est vrai
// puisque 0 peut être coercé en false
return !this.len();
}
}
Le code ci-dessus utilise la classe ES6 (ES2015) et les propriétés privées ES2022.
L'algorithme d'appariement des parenthèses
Maintenant, je vais décrire l'algorithme (les étapes) nécessaires pour analyser les parenthèses.
Nous avons besoin d'une boucle qui passera par chaque token – et il est préférable que tous les autres tokens soient supprimés avant le traitement.
Lorsque nous avons une parenthèse ouvrante, nous devons pousser cet élément dans la stack. Lorsque nous avons une parenthèse fermante, nous devons vérifier si le dernier élément de la stack correspond à celui que nous traitons.
Si l'élément correspond, nous le supprimons de la stack. Sinon, cela signifie que nous avons des parenthèses mal appariées, et nous devons lancer une exception.
Lorsque nous avons une parenthèse fermante, mais qu'il n'y a rien sur la stack, nous devons également lancer une exception, car il n'y a pas de parenthèse ouvrante qui correspond à la parenthèse fermante que nous avons.
Après avoir vérifié tous les caractères (tokens), si quelque chose reste sur la stack, cela signifie que nous n'avons pas fermé toutes les parenthèses. Mais ce cas est acceptable, car l'utilisateur peut être en train d'écrire. Donc dans ce cas, nous retournons false, et non une exception.
Si la stack est vide, nous retournons true. Cela signifie que nous avons une expression complète. Si cela était une S-Expression, nous pourrions utiliser l'analyseur pour la traiter, et nous n'aurions pas à nous soucier des résultats invalides (bien sûr, si l'analyseur était correct).
Le code source
function balanced(str) {
// paires de caractères correspondants
const maching_pairs = {
'[': ']',
'(': ')',
'{': '}'
};
const open_tokens = Object.keys(maching_pairs);
const brackets = Object.values(maching_pairs).concat(open_tokens);
// nous filtrons ce qui n'est pas nos caractères correspondants
const tokens = tokenize(str).filter(token => {
return brackets.includes(token);
});
const stack = new Stack();
for (const token of tokens) {
if (open_tokens.includes(token)) {
stack.push(token);
} else if (!stack.is_empty()) {
// il y a des caractères correspondants sur la stack
const last = stack.top();
// le dernier caractère ouvrant doit correspondre
// à la parenthèse fermante que nous avons
const closing_token = maching_pairs[last];
if (token === closing_token) {
stack.pop();
} else {
// les caractères ne correspondent pas
throw new Error(`Erreur de syntaxe : parenthèse fermante manquante ${closing_token}`);
}
} else {
// ce cas lorsque nous avons un token fermant mais pas d'ouvrant,
// car la stack est vide
throw new Error(`Erreur de syntaxe : parenthèse fermante non appariée ${token}`);
}
}
return stack.is_empty();
}
Le code ci-dessus a été implémenté dans le cadre de mon analyseur de S-Expressions, mais la seule chose que j'ai utilisée de cet article est une fonction tokenize() qui divise la chaîne en tokens (où un token est un objet unique comme le nombre 123 ou une chaîne "hello"). Si vous voulez traiter simplement les caractères, vous pouvez utiliser str.split(''), de sorte que les tokens seraient un tableau de caractères.
Le code est beaucoup plus simple que l'analyseur de S-Expressions car nous n'avons pas besoin de traiter tous les tokens. Mais lorsque nous utilisons la fonction tokenize() de l'article ci-dessus, nous pourrons tester une entrée comme celle-ci :
(this "))))")
Le code source complet (y compris la fonction tokenize()) peut être trouvé sur GitHub.
Résumé
Vous ne devriez même pas commencer à traiter des expressions qui ont des caractères ouvrants et fermants avec des expressions régulières. Sur StackOverflow, il y a cette réponse célèbre à cette question :
RegEx match open tags except XHTML self-contained tags
L'appariement des parenthèses présente exactement le même problème que l'analyse du HTML. Comme vous pouvez le voir dans le code ci-dessus, c'est un problème plus simple à résoudre si nous utilisons la stack.
Il est possible que nous puissions écrire une expression régulière qui vérifierait si la séquence de caractères a des parenthèses correspondantes. Mais cela deviendrait rapidement compliqué si nous avions des chaînes comme tokens (séquence de caractères), comme avec les S-Expressions, et les parenthèses à l'intérieur de ces chaînes devraient être ignorées. Il s'avère que la solution est plutôt simple si nous utilisons les bons outils.
Personnellement, j'adore les expressions régulières, mais vous devez toujours décider si elles sont l'outil approprié pour le travail.
NOTE : Cet article était basé sur un article du blog polonais Głównie JavaScript (ang. Mostly JavaScript), avec un titre : Jak parować nawiasy lub inne znaki w JavaScript?
Si vous aimez cet article, vous pouvez me suivre sur les réseaux sociaux : (Twitter/X et/ou LinkedIn). Vous pouvez également consulter mon site personnel et mon nouveau blog.