

Article original : How Apache Nifi works — surf on your dataflow, don’t drown in it
Par François Paupier
Introduction
C'est un flux fou d'eau. Tout comme votre application traite un flux fou de données. Acheminer les données d'un stockage à un autre, appliquer des règles de validation et répondre aux questions de gouvernance des données, de fiabilité dans un écosystème Big Data est difficile à réussir si vous le faites tout seul.
Bonne nouvelle, vous n'avez pas à construire votre solution de flux de données à partir de zéro — Apache NiFi est là pour vous !
À la fin de cet article, vous serez un expert NiFi — prêt à construire votre pipeline de données.
Ce que je vais couvrir dans cet article :
- Ce qu'est Apache NiFi, dans quelle situation l'utiliser, et quels sont les concepts clés à comprendre dans NiFi.
Ce que je ne couvrirai pas :
- Installation, déploiement, surveillance, sécurité et administration d'un cluster NiFi.
Pour votre commodité, voici la table des matières, n'hésitez pas à aller directement là où votre curiosité vous mène. Si vous êtes un débutant avec NiFi, il est conseillé de parcourir cet article dans l'ordre indiqué.
Table des matières
- I — Qu'est-ce qu'Apache NiFi ?
- Définition de NiFi
- Pourquoi utiliser NiFi ?
- II — Apache NiFi sous le microscope
- FlowFile
- Processor
- Process Group
- Connection
- Flow Controller
- Conclusion et appel à l'action
Qu'est-ce qu'Apache NiFi ?
Sur le site web du projet Apache NiFi, vous pouvez trouver la définition suivante :
Un système facile à utiliser, puissant et fiable pour traiter et distribuer des données.
Analysons les mots clés.
Définition de NiFi
Traiter et distribuer des données
C'est l'essence de NiFi. Il déplace les données entre les systèmes et vous donne des outils pour traiter ces données.
NiFi peut gérer une grande variété de sources et de formats de données. Vous prenez des données d'une source, vous les transformez et vous les envoyez vers une autre destination de données.
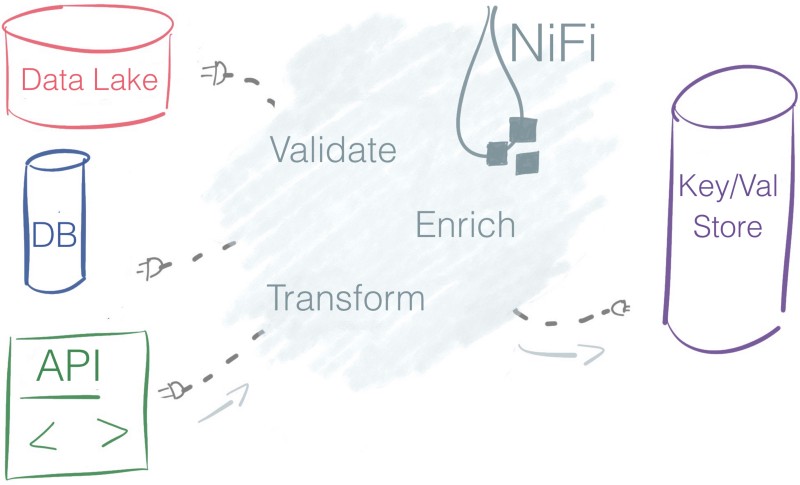
Facile à utiliser
Les processeurs — les boîtes — liés par des connecteurs — les flèches — créent un flux. NiFi offre une expérience de programmation basée sur les flux.
NiFi permet de comprendre, en un coup d'œil, un ensemble d'opérations de flux de données qui prendraient des centaines de lignes de code source à implémenter.
Considérez le pipeline ci-dessous :
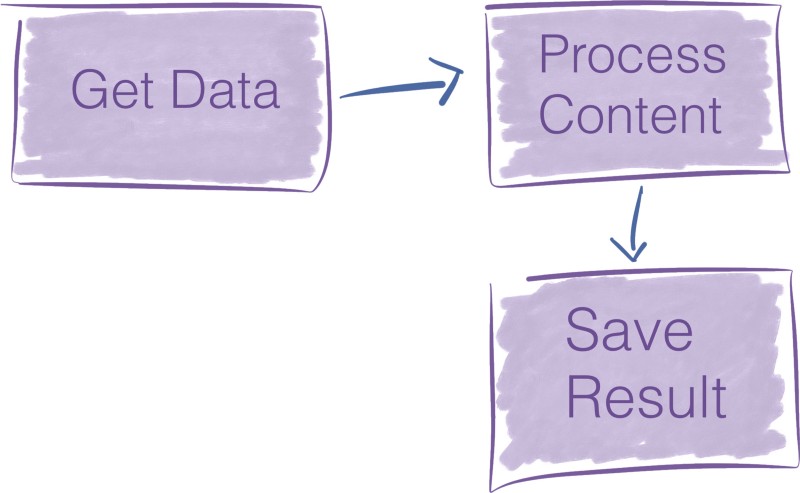
Pour traduire le flux de données ci-dessus dans NiFi, vous allez dans l'interface utilisateur graphique de NiFi, vous faites glisser et déposez trois composants sur le canevas, et c'est tout. Cela prend deux minutes à construire.
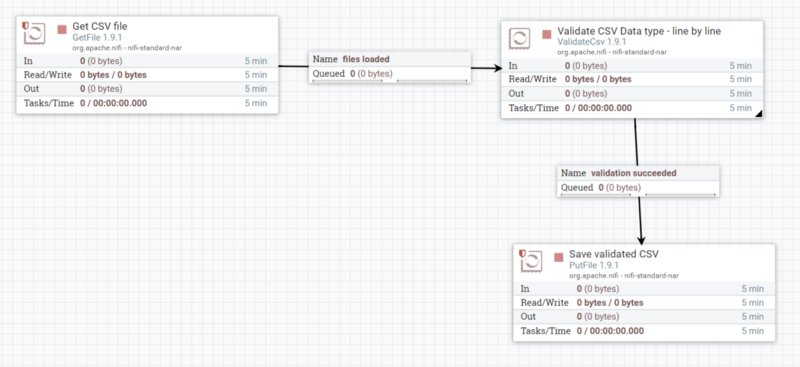
Maintenant, si vous écrivez du code pour faire la même chose, il est probable que cela fasse plusieurs centaines de lignes pour obtenir un résultat similaire.
Vous ne capturez pas l'essence du pipeline à travers le code comme vous le faites avec une approche basée sur les flux. NiFi est plus expressif pour construire un pipeline de données ; il est conçu pour cela.
Puissant
NiFi fournit de nombreux processeurs prêts à l'emploi (293 dans NiFi 1.9.2). Vous êtes sur les épaules d'un géant. Ces processeurs standard gèrent la grande majorité des cas d'utilisation que vous pouvez rencontrer.
NiFi est hautement concurrent, mais ses mécanismes internes encapsulent la complexité associée. Les processeurs vous offrent une abstraction de haut niveau qui masque la complexité inhérente à la programmation parallèle. Les processeurs s'exécutent simultanément, et vous pouvez répartir plusieurs threads d'un processeur pour faire face à la charge.
La concurrence est une boîte de Pandore informatique que vous ne voulez pas ouvrir. NiFi protège efficacement le constructeur de pipeline des complexités de la concurrence.
Fiable
La théorie derrière NiFi n'est pas nouvelle ; elle a des ancrages théoriques solides. Elle est similaire à des modèles comme SEDA.
Pour un système de flux de données, l'un des principaux sujets à aborder est la fiabilité. Vous voulez être sûr que les données envoyées quelque part sont effectivement reçues.
NiFi atteint un haut niveau de fiabilité grâce à plusieurs mécanismes qui gardent une trace de l'état du système à tout moment. Ces mécanismes sont configurables afin que vous puissiez faire les compromis appropriés entre latence et débit requis par vos applications.
NiFi suit l'historique de chaque morceau de données avec ses fonctionnalités de lignée et de provenance. Cela permet de savoir quelles transformations sont appliquées à chaque morceau d'information.
La solution de lignée de données proposée par Apache NiFi s'avère être un excellent outil pour auditer un pipeline de données. Les fonctionnalités de lignée de données sont essentielles pour renforcer la confiance dans les systèmes de big data et d'IA dans un contexte où des acteurs transnationaux comme l'Union européenne proposent des lignes directrices pour soutenir le traitement précis des données.
Pourquoi utiliser NiFi ?
Tout d'abord, je veux clarifier que je ne suis pas ici pour évangéliser NiFi. Mon objectif est de vous donner suffisamment d'éléments pour que vous puissiez prendre une décision éclairée sur la meilleure façon de construire votre pipeline de données.
Il est utile de garder à l'esprit les quatre V du big data lors du dimensionnement de votre solution.

- Volume — À quelle échelle opérez-vous ? En ordre de grandeur, êtes-vous plus proche de quelques gigaoctets ou de centaines de pétaoctets ?
- Variété — Combien de sources de données avez-vous ? Vos données sont-elles structurées ? Si oui, le schéma varie-t-il souvent ?
- Vélocité — Quelle est la fréquence des événements que vous traitez ? S'agit-il de paiements par carte de crédit ? S'agit-il d'un rapport de performance quotidien envoyé par un appareil IoT ?
- Véracité — Pouvez-vous faire confiance aux données ? Sinon, devez-vous appliquer plusieurs opérations de nettoyage avant de les manipuler ?
NiFi ingère de manière transparente les données de plusieurs sources de données et fournit des mécanismes pour gérer différents schémas dans les données. Ainsi, il excelle lorsqu'il y a une grande variété dans les données.
NiFi est particulièrement précieux si les données sont de faible véracité. Puisqu'il fournit plusieurs processeurs pour nettoyer et formater les données.
Avec ses options de configuration, NiFi peut répondre à une large gamme de situations de volume/vélocité.
Une liste croissante d'applications pour les solutions de routage de données
De nouvelles réglementations, l'essor de l'Internet des objets et le flux de données qu'il génère soulignent la pertinence d'outils tels qu'Apache NiFi.
- Les microservices sont à la mode. Dans ces services faiblement couplés, les données sont le contrat entre les services. NiFi est un moyen robuste de router les données entre ces services.
- L'Internet des objets apporte une multitude de données dans le cloud. Ingesting et valider les données de la périphérie vers le cloud pose de nombreux nouveaux défis que NiFi peut efficacement relever (principalement grâce à MiniFi, le projet NiFi pour les appareils de périphérie).
- De nouvelles lignes directrices et réglementations sont mises en place pour réajuster l'économie du Big Data. Dans ce contexte de surveillance croissante, il est vital pour les entreprises d'avoir une vue d'ensemble claire de leur pipeline de données. La lignée de données NiFi, par exemple, peut être utile dans un chemin vers la conformité aux réglementations.
Combler le fossé entre les experts du big data et les autres
Comme vous pouvez le voir par l'interface utilisateur, un flux de données exprimé dans NiFi est excellent pour communiquer sur votre pipeline de données. Il peut aider les membres de votre organisation à devenir plus connaisseurs de ce qui se passe dans le pipeline de données.
- Un analyste demande des informations sur pourquoi ces données arrivent ici de cette manière ? Asseyez-vous ensemble et parcourez le flux. En cinq minutes, vous donnez à quelqu'un une forte compréhension du pipeline Extract Transform and Load — ETL.
- Vous voulez des commentaires de vos pairs sur un nouveau flux de gestion des erreurs que vous avez créé ? NiFi fait de la décision de conception de considérer les chemins d'erreur comme des résultats valides. Attendez-vous à ce que la révision du flux soit plus courte qu'une révision de code traditionnelle.
Devriez-vous l'utiliser ? Oui, Non, Peut-être ?
NiFi se présente comme facile à utiliser. Pourtant, il s'agit d'une plateforme de flux de données d'entreprise. Elle offre un ensemble complet de fonctionnalités dont vous n'aurez peut-être besoin que d'un sous-ensemble réduit. Ajouter un nouvel outil à la pile n'est pas anodin.
Si vous commencez à partir de zéro et gérez quelques données provenant de sources de données fiables, vous pourriez être mieux loti en configurant votre pipeline Extract Transform and Load — ETL. Peut-être qu'un capture de données de changement à partir d'une base de données et quelques scripts de préparation de données sont tout ce dont vous avez besoin.
D'un autre côté, si vous travaillez dans un environnement avec des solutions de big data existantes en place (qu'il s'agisse de stockage, de traitement ou de messagerie), NiFi s'intègre bien avec elles et est plus susceptible d'être une victoire rapide. Vous pouvez tirer parti des connecteurs prêts à l'emploi vers ces autres solutions Big Data.
Il est facile d'être enthousiasmé par de nouvelles solutions. Listez vos exigences et choisissez la solution qui répond à vos besoins aussi simplement que possible.
Maintenant que nous avons vu le tableau général d'Apache NiFi, nous examinons ses concepts clés et disséquons ses mécanismes internes.
Apache NiFi sous le microscope
« NiFi est une programmation par boîtes et flèches » peut être acceptable pour communiquer le tableau général. Cependant, si vous devez opérer avec NiFi, vous pourriez vouloir comprendre un peu plus comment il fonctionne.
Dans cette deuxième partie, j'explique les concepts critiques d'Apache NiFi avec des schémas. Ce modèle de boîte noire ne sera plus une boîte noire pour vous ensuite.
Déballage d'Apache NiFi
Lorsque vous démarrez NiFi, vous arrivez sur son interface web. L'interface utilisateur web est le plan sur lequel vous concevez et contrôlez votre pipeline de données.
Dans NiFi, vous assemblez des processeurs liés ensemble par des connexions. Dans l'exemple de flux de données introduit précédemment, il y a trois processeurs.
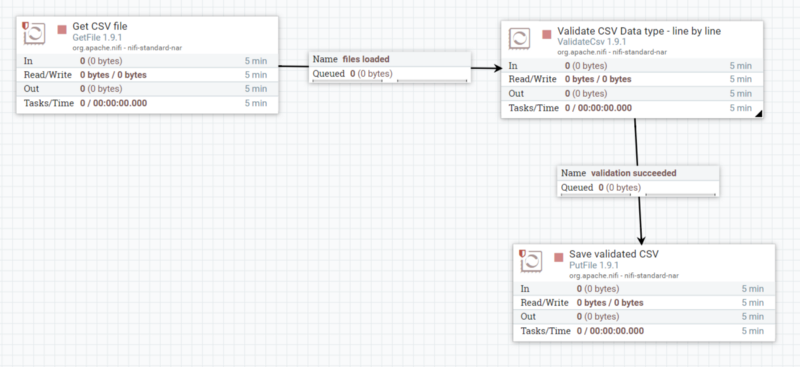
L'interface utilisateur du canevas NiFi est le cadre dans lequel le constructeur de pipeline évolue.
Comprendre la terminologie NiFi
Pour exprimer votre flux de données dans NiFi, vous devez d'abord maîtriser son langage. Pas de soucis, quelques termes suffisent pour saisir le concept derrière.
Les boîtes noires sont appelées processeurs, et elles échangent des morceaux d'informations nommés FlowFiles à travers des files d'attente qui sont nommées connexions. Enfin, le FlowFile Controller est responsable de la gestion des ressources entre ces composants.
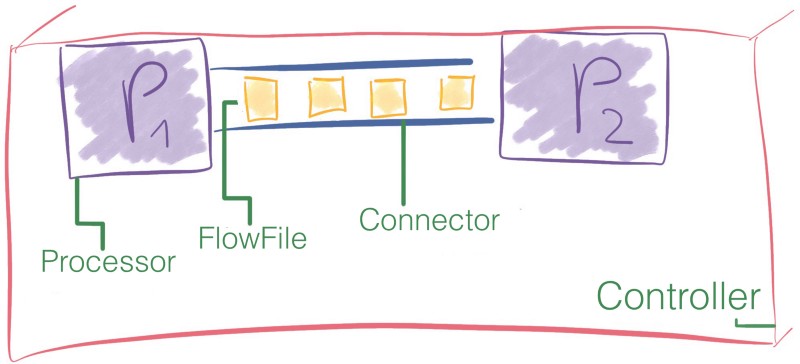
Regardons comment cela fonctionne sous le capot.
FlowFile
Dans NiFi, le FlowFile est le paquet d'informations se déplaçant à travers les processeurs du pipeline.

Un FlowFile se compose de deux parties :
- Attributs, qui sont des paires clé/valeur. Par exemple, le nom du fichier, le chemin du fichier et un identifiant unique sont des attributs standard.
- Contenu, une référence au flux d'octets composant le contenu du FlowFile.
Le FlowFile ne contient pas les données elles-mêmes. Cela limiterait sévèrement le débit du pipeline.
Au lieu de cela, un FlowFile contient un pointeur qui référence les données stockées à un endroit dans le stockage local. Cet endroit est appelé le Content Repository.
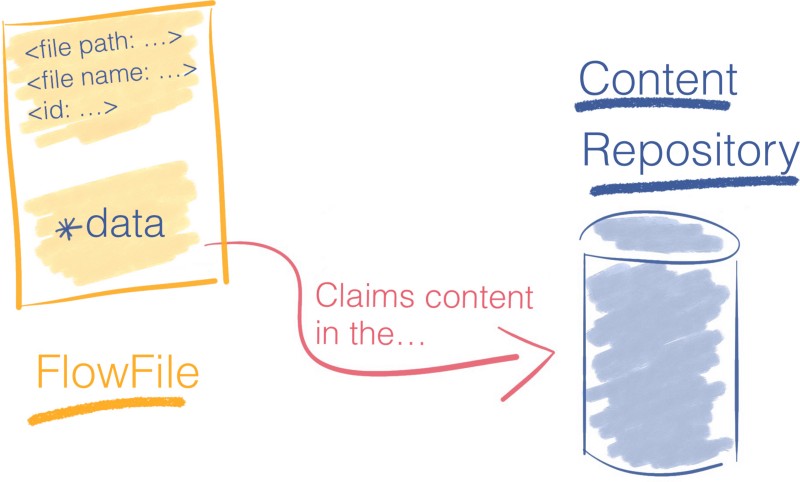
Pour accéder au contenu, le FlowFile réclame la ressource du Content Repository. Ce dernier garde une trace du décalage exact du disque à partir duquel le contenu est et le diffuse en retour vers le FlowFile.
Tous les processeurs n'ont pas besoin d'accéder au contenu du FlowFile pour effectuer leurs opérations — par exemple, l'agrégation du contenu de deux FlowFiles ne nécessite pas de charger leur contenu en mémoire.
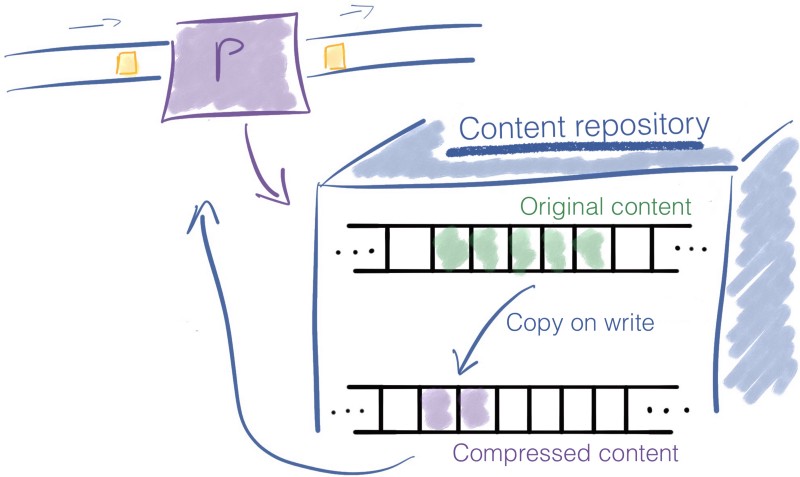
Lorsque un processeur modifie le contenu d'un FlowFile, les données précédentes sont conservées. NiFi copie-écriture, il modifie le contenu tout en le copiant vers un nouvel emplacement. L'information originale est laissée intacte dans le Content Repository.
Exemple
Considérons un processeur qui compresse le contenu d'un FlowFile. Le contenu original reste dans le Content Repository, et une nouvelle entrée est créée pour le contenu compressé.
Le Content Repository retourne finalement la référence au contenu compressé. Le FlowFile est mis à jour pour pointer vers les données compressées.
Le dessin ci-dessous résume l'exemple avec un processeur qui compresse le contenu des FlowFiles.
Fiabilité
NiFi affirme être fiable, comment cela se traduit-il en pratique ? Les attributs de tous les FlowFiles actuellement en cours d'utilisation, ainsi que la référence à leur contenu, sont stockés dans le FlowFile Repository.
À chaque étape du pipeline, une modification d'un FlowFile est d'abord enregistrée dans le FlowFile Repository, dans un journal d'écriture anticipée, avant d'être effectuée.
Pour chaque FlowFile qui existe actuellement dans le système, le dépôt de FlowFile stocke :
- Les attributs du FlowFile
- Un pointeur vers le contenu du FlowFile situé dans le dépôt de FlowFile
- L'état du FlowFile. Par exemple : à quelle file d'attente appartient le FlowFile à cet instant.
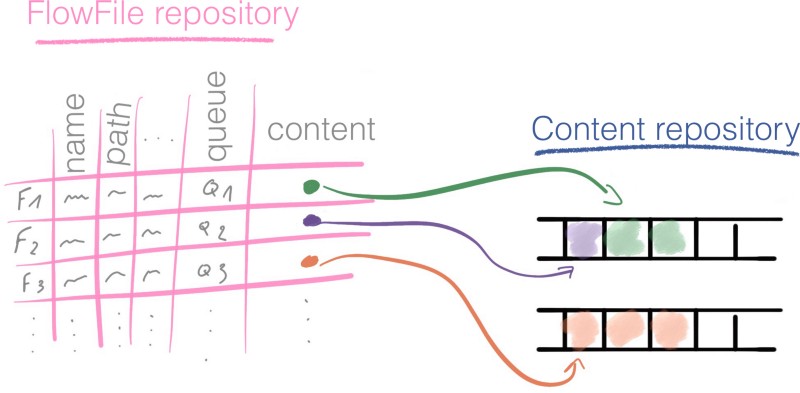
Le dépôt de FlowFile nous donne l'état le plus récent du flux ; ainsi, c'est un outil puissant pour récupérer après une panne.
NiFi fournit un autre outil pour suivre l'historique complet de tous les FlowFiles dans le flux : le Provenance Repository.
Provenance Repository
Chaque fois qu'un FlowFile est modifié, NiFi prend un instantané du FlowFile et de son contexte à ce moment-là. Le nom de cet instantané dans NiFi est un Provenance Event. Le Provenance Repository enregistre les Provenance Events.
La Provenance nous permet de retracer la lignée des données et de construire la chaîne de garde complète pour chaque morceau d'information traité dans NiFi.
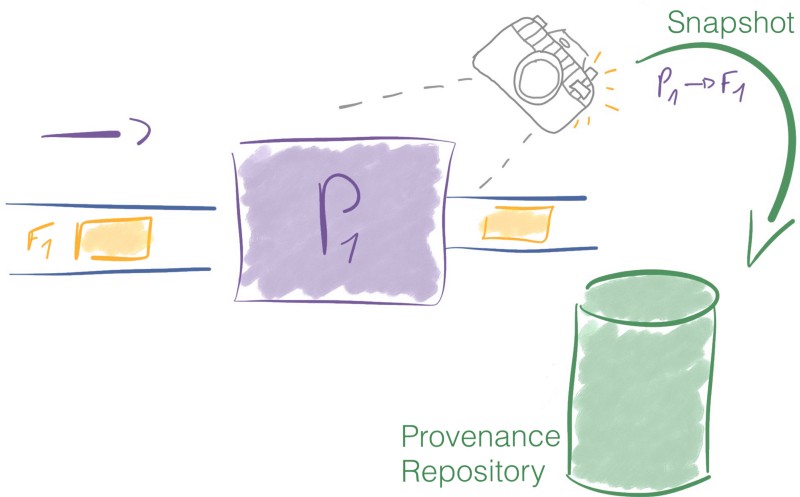
En plus d'offrir la lignée complète des données, le dépôt de Provenance offre également la possibilité de rejouer les données à partir de n'importe quel point dans le temps.
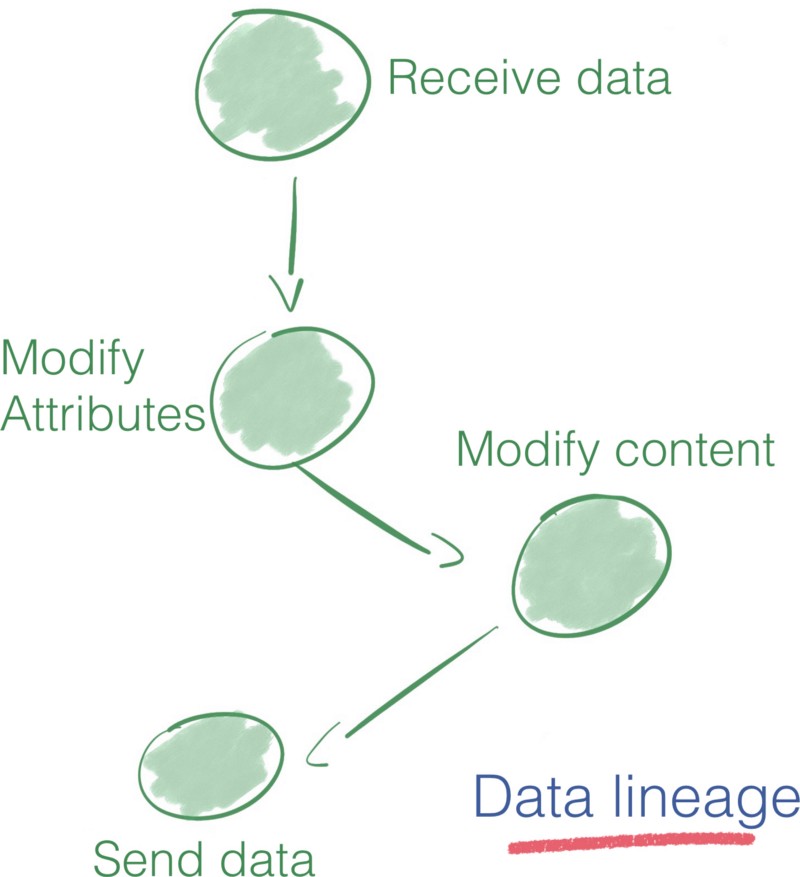
Attendez, quelle est la différence entre le dépôt de FlowFile et le dépôt de Provenance ?
L'idée derrière le dépôt de FlowFile et le dépôt de Provenance est assez similaire, mais ils ne traitent pas le même problème.
- Le dépôt de FlowFile est un journal qui contient uniquement le dernier état des FlowFiles en cours d'utilisation dans le système. C'est l'image la plus récente du flux et il permet de récupérer rapidement après une panne.
- Le dépôt de Provenance, en revanche, est plus exhaustif puisqu'il suit le cycle de vie complet de chaque FlowFile qui a été dans le flux.
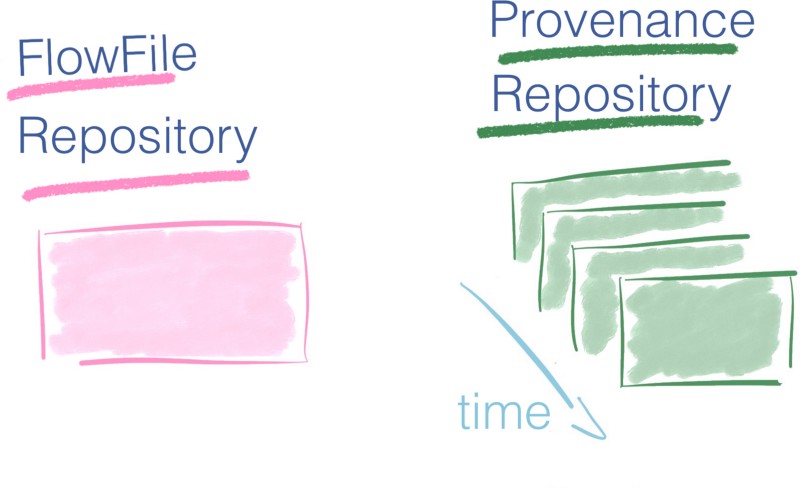
Si vous n'avez que l'image la plus récente du système avec le dépôt de FlowFile, le dépôt de Provenance vous donne une collection de photos — une vidéo. Vous pouvez rembobiner à n'importe quel moment dans le passé, enquêter sur les données, rejouer les opérations à partir d'un temps donné. Il fournit une lignée complète des données.
FlowFile Processor
Un processeur est une boîte noire qui effectue une opération. Les processeurs ont accès aux attributs et au contenu du FlowFile pour effectuer toutes sortes d'actions. Ils vous permettent d'effectuer de nombreuses opérations dans l'ingestion de données, les tâches standard de transformation/validation de données et l'enregistrement de ces données dans divers puits de données.
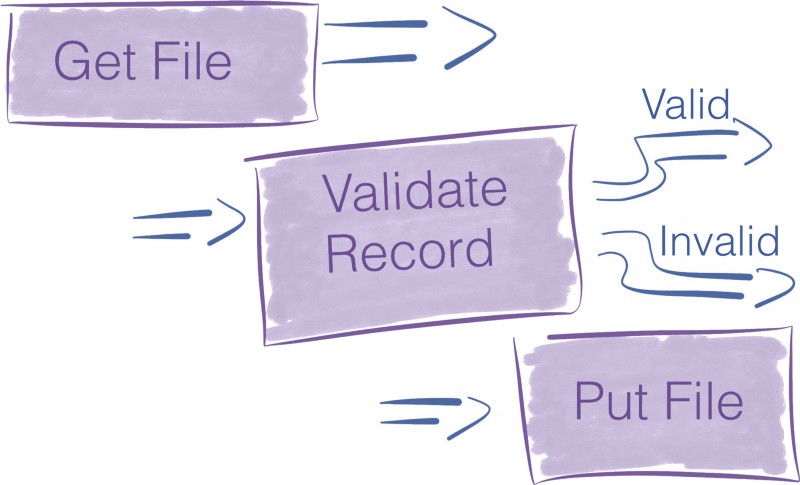
NiFi est livré avec de nombreux processeurs lors de son installation. Si vous ne trouvez pas celui qui convient parfaitement à votre cas d'utilisation, il est toujours possible de construire votre propre processeur. L'écriture de processeurs personnalisés est hors du cadre de cet article de blog.
Les processeurs sont des abstractions de haut niveau qui remplissent une tâche. Cette abstraction est très pratique car elle protège le constructeur de pipeline des difficultés inhérentes à la programmation concurrente et à la mise en œuvre de mécanismes de gestion des erreurs.
Les processeurs exposent une interface avec plusieurs paramètres de configuration pour affiner leur comportement.
Les propriétés de ces processeurs sont le dernier lien entre NiFi et la réalité commerciale des exigences de votre application.
Le diable est dans les détails, et les constructeurs de pipelines passent la plupart de leur temps à affiner ces propriétés pour correspondre au comportement attendu.
Mise à l'échelle
Pour chaque processeur, vous pouvez spécifier le nombre de tâches simultanées que vous souhaitez exécuter simultanément. Ainsi, le Flow Controller alloue plus de ressources à ce processeur, augmentant son débit. Les processeurs partagent des threads. Si un processeur demande plus de threads, d'autres processeurs ont moins de threads disponibles pour s'exécuter. Les détails sur la manière dont le Flow Controller alloue les threads sont disponibles ici.
Mise à l'échelle horizontale. Une autre façon de mettre à l'échelle est d'augmenter le nombre de nœuds dans votre cluster NiFi. Les serveurs de clustering permettent d'augmenter votre capacité de traitement en utilisant du matériel standard.
Process Group
Celui-ci est simple maintenant que nous avons vu ce que sont les processeurs.
Un ensemble de processeurs mis ensemble avec leurs connexions peut former un groupe de processus. Vous ajoutez un port d'entrée et un port de sortie afin qu'il puisse recevoir et envoyer des données.
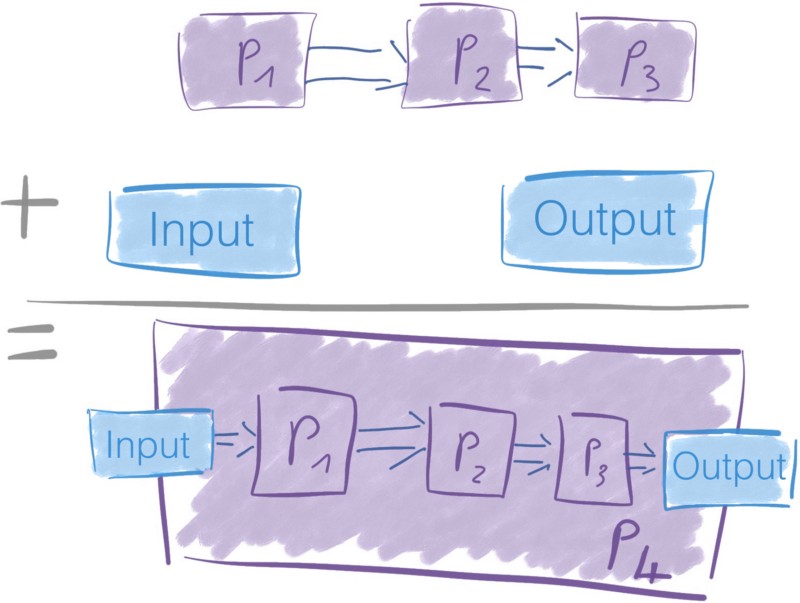
Les groupes de processeurs sont un moyen facile de créer de nouveaux processeurs à partir de ceux existants.
Connections
Les connexions sont les files d'attente entre les processeurs. Ces files d'attente permettent aux processeurs d'interagir à des rythmes différents. Les connexions peuvent avoir différentes capacités comme il existe différentes tailles de tuyaux d'eau.
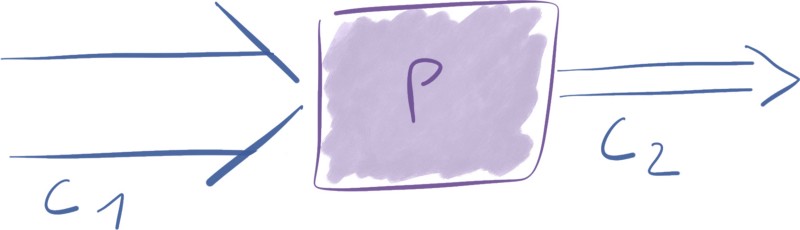
Parce que les processeurs consomment et produisent des données à des rythmes différents selon les opérations qu'ils effectuent, les connexions agissent comme des tampons de FlowFiles.
Il y a une limite sur le nombre de données qui peuvent être dans la connexion. De même, lorsque votre tuyau d'eau est plein, vous ne pouvez plus ajouter d'eau, ou il déborde.
Dans NiFi, vous pouvez définir des limites sur le nombre de FlowFiles et la taille de leur contenu agrégé passant par les connexions.
Que se passe-t-il lorsque vous envoyez plus de données que la connexion ne peut en gérer ?
Si le nombre de FlowFiles ou la quantité de données dépasse le seuil défini, une contre-pression est appliquée. Le Flow Controller ne planifiera pas le processeur précédent pour s'exécuter à nouveau jusqu'à ce qu'il y ait de la place dans la file d'attente.
Disons que vous avez une limite de 10 000 FlowFiles entre deux processeurs. À un moment donné, la connexion contient 7 000 éléments. C'est acceptable puisque la limite est de 10 000. P1 peut toujours envoyer des données à travers la connexion vers P2.

Maintenant, disons que le processeur un envoie 4 000 nouveaux FlowFiles à la connexion.
7 0000 + 4 000 = 11 000 → Nous dépassons le seuil de connexion de 10 000 FlowFiles.
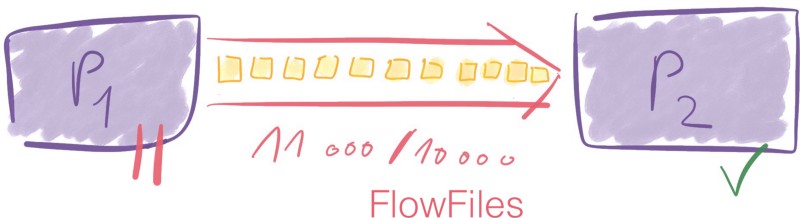
Les limites sont des limites souples, ce qui signifie qu'elles peuvent être dépassées. Cependant, une fois qu'elles le sont, le processeur précédent, P1, ne sera pas planifié jusqu'à ce que le connecteur redescende en dessous de sa valeur de seuil — 10 000 FlowFiles.
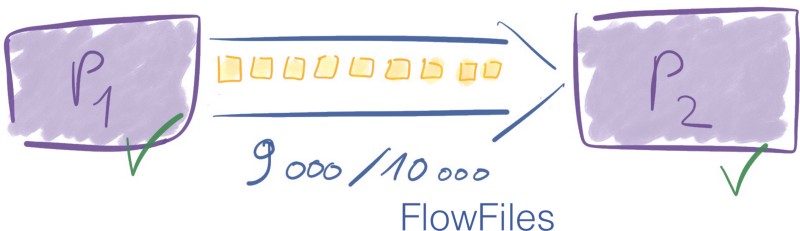
Cet exemple simplifié donne une vue d'ensemble de la manière dont la contre-pression fonctionne.
Vous souhaitez configurer des seuils de connexion appropriés au volume et à la vélocité des données à gérer. Gardez à l'esprit les quatre V.
L'idée de dépasser une limite peut sembler étrange. Lorsque le nombre de FlowFiles ou les données associées dépassent le seuil, un mécanisme de swap est déclenché.
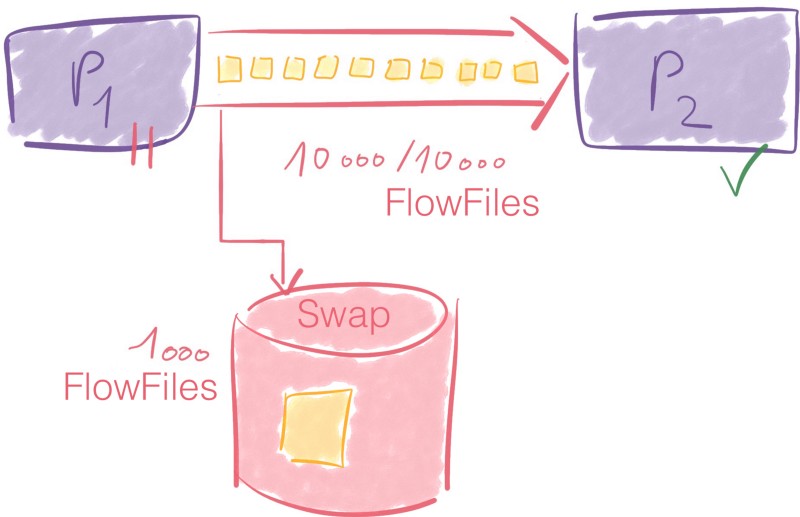
Pour un autre exemple sur la contre-pression, ce fil de discussion peut aider.
Priorisation des FlowFiles
Les connecteurs dans NiFi sont hautement configurables. Vous pouvez choisir comment vous priorisez les FlowFiles dans la file d'attente pour décider lequel traiter ensuite.
Parmi les possibilités disponibles, il y a, par exemple, l'ordre Premier Entré Premier Sorti — FIFO. Cependant, vous pouvez même utiliser un attribut de votre choix à partir du FlowFile pour prioriser les paquets entrants.
Flow Controller
Le Flow Controller est le lien qui rassemble tout. Il alloue et gère les threads pour les processeurs. C'est ce qui exécute le flux de données.
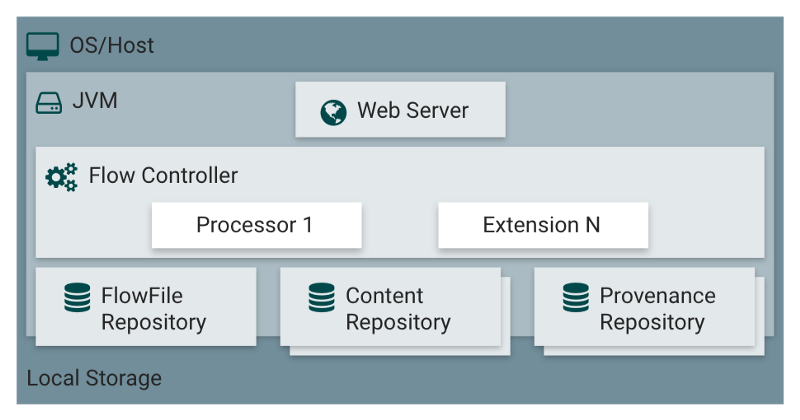
De plus, le Flow Controller permet d'ajouter des services de contrôleur.
Ces services facilitent la gestion des ressources partagées comme les connexions de base de données ou les informations d'identification des fournisseurs de services cloud. Les services de contrôleur sont des daemons. Ils s'exécutent en arrière-plan et fournissent une configuration, des ressources et des paramètres pour que les processeurs s'exécutent.
Par exemple, vous pouvez utiliser un service de fournisseur d'informations d'identification AWS pour permettre à vos services d'interagir avec les buckets S3 sans avoir à vous soucier des informations d'identification au niveau du processeur.
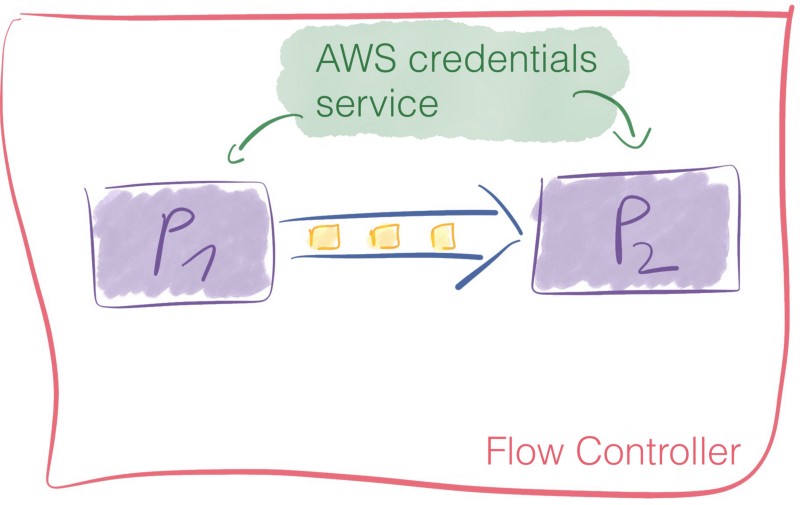
Tout comme avec les processeurs, une multitude de services de contrôleur est disponible prêt à l'emploi.
Vous pouvez consulter cet article pour plus de contenu sur les services de contrôleur.
Conclusion et appel à l'action
Au cours de cet article, nous avons discuté de NiFi, une solution de flux de données d'entreprise. Vous avez maintenant une solide compréhension de ce que fait NiFi et de la manière dont vous pouvez exploiter ses fonctionnalités de routage de données pour vos applications.
Si vous lisez ceci, félicitations ! Vous en savez maintenant plus sur NiFi que 99,99 % de la population mondiale.
La pratique rend parfait. Vous maîtrisez tous les concepts nécessaires pour commencer à construire votre propre pipeline. Rendez-le simple ; faites-le fonctionner d'abord.
Voici une liste de ressources passionnantes que j'ai compilées en plus de mon expérience de travail pour écrire cet article.
Ressources ?
La vue d'ensemble
Parce que la conception de pipelines de données dans un écosystème complexe nécessite une maîtrise dans plusieurs domaines, je recommande vivement le livre Designing Data-Intensive Applications de Martin Kleppmann. Il couvre les fondamentaux.
- Une feuille de triche avec toutes les références citées dans le livre de Martin est disponible sur son dépôt Github.
Cette feuille de triche est un excellent point de départ si vous savez déjà quel type de sujet vous aimeriez étudier en profondeur et que vous souhaitez trouver des matériaux de qualité.
Alternatives à Apache NiFi
D'autres solutions de flux de données existent.
Open source :
- Streamsets est similaire à NiFi ; une bonne comparaison est disponible sur ce blog
La plupart des fournisseurs de cloud existants offrent des solutions de flux de données. Ces solutions s'intègrent facilement avec d'autres produits que vous utilisez de ce fournisseur de cloud. En même temps, cela vous lie solidement à un fournisseur particulier.
- Azure Data Factory, une solution Microsoft
- IBM a son InfoSphere DataStage
- Amazon propose un outil nommé Data Pipeline
- Google offre son Dataflow
- Alibaba cloud introduit un service DataWorks avec des fonctionnalités similaires
Ressources liées à NiFi
- La documentation officielle NiFi et en particulier la section NiFi In-depth sont des mines d'or.
- S'inscrire à la liste de diffusion des utilisateurs de NiFi est également un excellent moyen de rester informé — par exemple, cette conversation explique la contre-pression.
- Hortonworks, un fournisseur de solutions de big data, dispose d'un site communautaire rempli de ressources engageantes et de how-to pour Apache NiFi.
— Cet article approfondit les connecteurs, l'utilisation du tas et la contre-pression.
— Celui-ci partage les meilleures pratiques de dimensionnement lors du déploiement d'un cluster NiFi. - Le blog NiFi distille de nombreuses informations sur les modèles d'utilisation de NiFi ainsi que des conseils sur la construction de pipelines.
- Modèle de vérification de réclamation expliqué
- La théorie derrière Apache NiFi n'est pas nouvelle, Seda référencé dans la documentation NiFi est extrêmement pertinent
— Matt Welsh. Berkeley. SEDA : Une Architecture pour des Services Internet Bien Conditionnés et Évolutifs [en ligne]. Récupéré le 21 avril 2019, de http://www.mdw.la/papers/seda-sosp01.pdf