
Article original : How to embrace event-driven graph analytics using Neo4j and Apache Kafka
Par Ljubica Lazarevic
Introduction
Avec les nouveaux Neo4j Kafka streams désormais disponibles, mon collègue de Neo4j Tom Geudens et moi avions hâte de l'essayer. Nous avons de nombreux cas d'utilisation en tête qui exploitent la puissance des bases de données de graphes et des architectures basées sur les événements. Le premier que nous explorons combine la puissance des algorithmes de graphes avec une base de données transactionnelle.
La nouvelle bibliothèque Neo4j Kafka streams est un plugin Neo4j que vous pouvez ajouter à chacune de vos instances Neo4j. Elle permet trois types de mécanismes Apache Kafka :
- Producteur : basé sur les sujets configurés dans le fichier de configuration de Neo4j. Les sorties vers ces sujets se produisent lorsque des types de nœuds ou de relations spécifiés changent.
- Consommateur : basé sur les sujets configurés dans le fichier de configuration de Neo4j. Lorsque des événements pour ces sujets sont détectés, la requête Cypher spécifiée pour chaque sujet sera exécutée.
- Procédure : un appel direct en Cypher pour publier une charge utile donnée vers un sujet spécifié.
Vous pouvez obtenir un aperçu plus détaillé de ce à quoi chacun de ces éléments peut ressembler ici.
Aperçu de la situation
Les algorithmes de graphes offrent des capacités analytiques puissantes. Ils nous aident à mieux comprendre le contexte de nos données en analysant les relations. Par exemple, les algorithmes de graphes sont utilisés pour :
- Comprendre les dépendances du réseau
- Détecter les communautés
- Identifier les influenceurs
- Calculer les recommandations
- Et ainsi de suite.
Neo4j propose un ensemble d'algorithmes de graphes prêts à l'emploi via un plugin qui peut s'exécuter directement sur les données dans Neo4j. Cette bibliothèque d'algorithmes a été très bien accueillie. À plusieurs reprises, j'ai reçu des retours indiquant que les plugins sont aussi rapides ou plus rapides que ce que les clients ont utilisé auparavant. Avec de tels retours positifs, pourquoi ne pas appliquer ces algorithmes optimisés et performants sur une base de données Neo4j ?
Pour tirer pleinement parti de tout processus analytique, des ressources sont nécessaires. Pour obtenir une expérience performante, nous voulons fournir autant de CPU et de mémoire que possible.
Maintenant, nous pourrions exécuter ce type de travail sur notre cluster transactionnel. Mais dans cette architecture typique, nous allons rencontrer certains défis. Par exemple, si une machine est grande, les autres machines du cluster doivent être similaires. Cela pourrait signifier que l'architecture mise en place est coûteuse.
L'autre défi auquel nous sommes confrontés est que notre cluster est censé gérer les transactions — les requêtes quotidiennes telles que le traitement des demandes. Nous ne voulons pas le surcharger avec le traitement de diverses itérations et permutations d'un modèle. Idéalement, nous voulons déleser cette charge ainsi que le travail analytique associé.
Si nous savons que les requêtes intensives qui vont avoir lieu sont en lecture seule, alors c'est une solution facile. Nous pouvons lancer des réplicas de lecture pour gérer la charge. Cela permet au cluster de se concentrer sur ce qu'il est censé faire, soutenir un système opérationnel et transactionnel.
Mais comment gérer les écritures dans le graphe opérationnel dans le cadre du traitement analytique ? Nous voulons ces résultats, tels que les recommandations, dès qu'ils sont disponibles.
Les réplicas de lecture sont, comme leur nom l'indique, pour les applications en lecture seule. Ils ne seront pas impliqués dans les élections des leaders dans le cluster, ni dans l'écriture. En utilisant Neo4j-streams, nous pouvons diffuser les résultats du réplica de lecture vers le cluster pour consommation.
Les grands avantages de cette approche incluent :
- Nous bénéficions de la haute disponibilité et de la reprise après sinistre offertes par le cluster.
- Les données seront identiques sur le réplica de lecture et sur le cluster. Nous n'avons pas à nous soucier de la mise à jour du réplica de lecture car le cluster s'en chargera pour nous.
- Les identifiants des nœuds et des relations seront identiques sur les serveurs du cluster et sur le réplica de lecture. Cela rend la mise à jour vraiment facile.
- Nous pouvons provisionner les ressources nécessaires au réplica de lecture, qui seront probablement très différentes de celles du cluster.
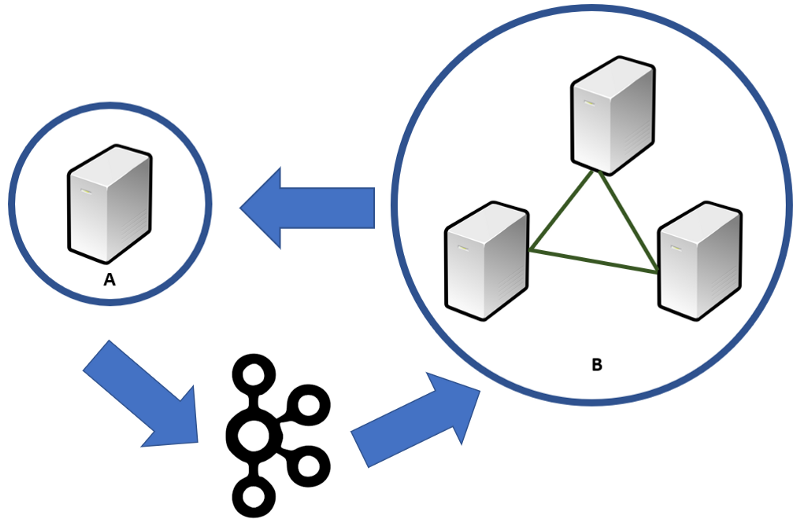
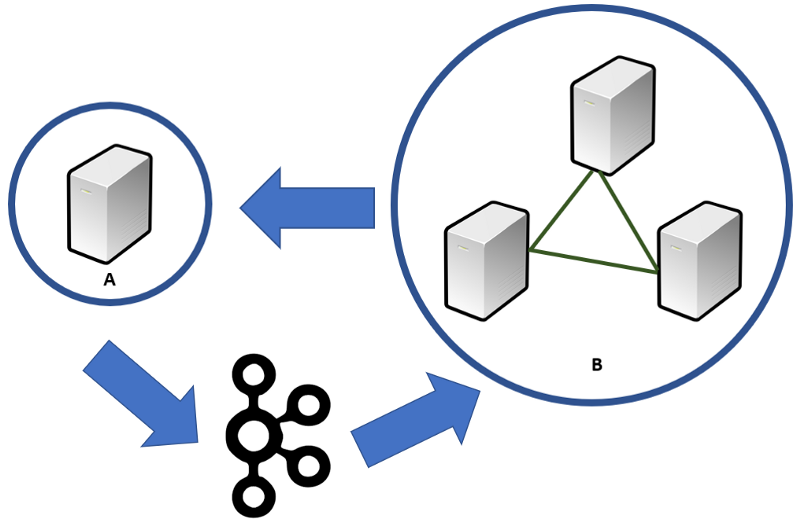
Notre architecture ressemblera à la figure ci-dessous. A est notre réplica de lecture, et B est notre cluster causal. A recevra les informations transactionnelles de B. Tous les résultats calculés par A seront diffusés vers B via des messages Kafka.
Avec notre nouveau modèle, continuons avec notre exemple simple.
L'ensemble de données d'exemple
Nous allons utiliser l'ensemble de données de la base de données de films disponible dans le guide :play movie-guide dans Neo4j Browser. Pour cet exemple, nous allons utiliser quatre instances Neo4j :
- L'instance d'analyse — ce sera notre réplica de lecture, et sur cette instance nous allons exécuter PageRank sur tous les nœuds Person dans l'ensemble de données. Nous appellerons la procédure
streams.publish()pour publier la sortie vers notre sujet Kafka. - Les instances opérationnelles — ce sera notre cluster causal à trois serveurs qui écoutera les changements sur le nœud person. Nous mettrons à jour au fur et à mesure que les changements arrivent.
Pour Kafka, nous suivrons les instructions du guide de démarrage rapide jusqu'à l'étape 2. Avant de lancer Kafka, nous devrons configurer les éléments consommateurs dans les fichiers de configuration de Neo4j. Nous configurerons également le cluster lui-même. Veuillez noter qu'à l'heure actuelle, neo4j-streams ne fonctionne qu'avec la version 3.4.x de Neo4j.
Pour configurer les trois serveurs du cluster et un réplica de lecture, nous suivrons les instructions fournies dans le manuel des opérations de Neo4j. Suivez les instructions pour les cœurs, ainsi que pour un réplica de lecture.
De plus, nous allons devoir ajouter ce qui suit à neo4j.config pour les serveurs du cluster causal :
#************# Kafka Config — Consommateur#************kafka.zookeeper.connect=localhost:2181kafka.bootstrap.servers=localhost:9092kafka.group.id=neo4j-core1streams.sink.enabled=truestreams.sink.topic.cypher.neorr=WITH event.payload as payload MATCH (p:Person) WHERE ID(p)=payload[0] SET p.pagerank = payload[1]
Notez que nous voulons changer kafka.group.id en neo4j-core2 et neo4j-core3 respectivement.
Pour le réplica de lecture, nous devrons ajouter ce qui suit à neo4j.config :
#************# Kafka Config - Procédure#************kafka.zookeeper.connect=localhost:2181kafka.bootstrap.servers=localhost:9092kafka.group.id=neo4j-read1
Vous devrez télécharger et enregistrer le fichier jar neo4j-streams dans le dossier plugins. Vous devez également ajouter la bibliothèque d'algorithmes de graphes, via Neo4j Desktop, ou manuellement.
Avec ces modifications apportées aux fichiers de configuration respectifs et enregistrées, et les plugins installés, nous allons tout démarrer, dans l'ordre suivant :
- Apache Zookeeper
- Apache Kafka
- Les trois instances pour le cluster causal Neo4j
- Le réplica de lecture
Une fois que toutes les instances Neo4j sont opérationnelles et que le cluster a découvert tous les membres, nous pouvons maintenant exécuter la requête suivante sur le réplica de lecture :
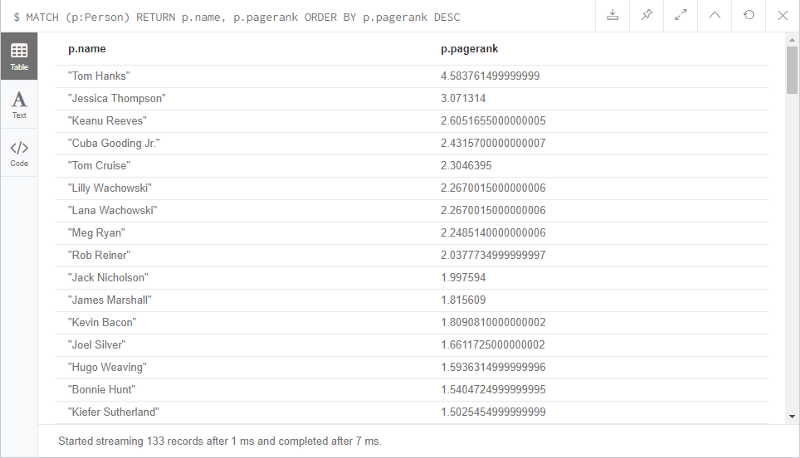
CALL algo.pageRank.stream('MATCH (p:Person) RETURN id(p) AS id','MATCH (p1:Person)-->()<--(p2:Person) RETURN distinct id(p1) AS source, id(p2) AS target',{graph:'cypher'}) YIELD nodeId, scoreWITH [nodeId,score] AS resCALL streams.publish('neorr',res)RETURN COUNT(*)
Cette requête Cypher appellera l'algorithme PageRank avec la configuration spécifiée. Une fois l'algorithme terminé, nous diffuserons les identifiants de nœuds retournés et le score PageRank vers le sujet spécifié.
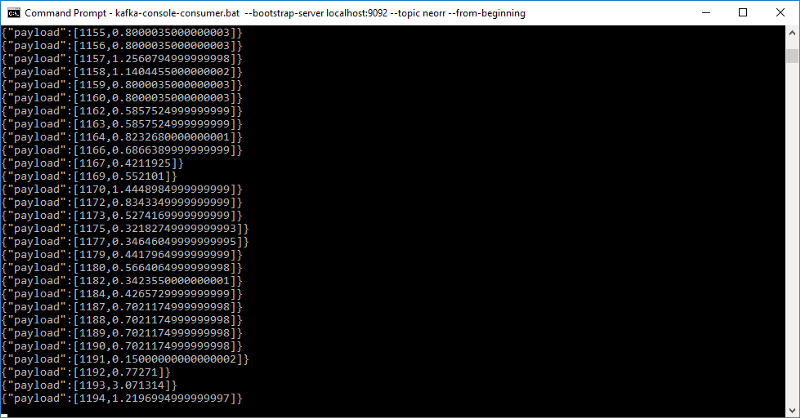
Nous pouvons voir à quoi ressemble le sujet neorr en exécutant l'étape 5 du guide de démarrage rapide d'Apache Kafka (en remplaçant test par neorr) :
Résumé
Dans cet article, nous avons démontré :
- La séparation des préoccupations des données transactionnelles et analytiques
- Le flux sans douleur des résultats analytiques pour une consommation en temps réel
Bien que nous ayons utilisé un exemple simple, vous pouvez voir comment des travaux analytiques complexes peuvent être réalisés, soutenant une architecture basée sur les événements.