
Article original : How you can access your “dark data” with Amazon Redshift Spectrum
Par Lars Kamp
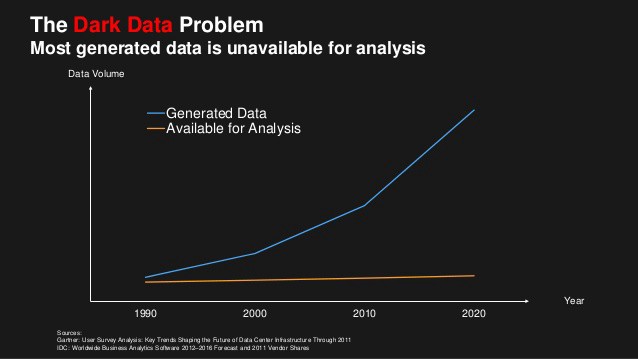
Le service de stockage simple d'Amazon (S3) existe depuis 2006. Les entreprises y ont stocké leurs données à un rythme effréné. En moins de 10 ans après son lancement, S3 stockait plus de 2 billions d'objets, chacun pouvant atteindre 5 térabits. Ces entreprises savent que leurs données sont précieuses et valent la peine d'être conservées. Mais une grande partie de ces données reste inactive, dans des « data lakes » froids, inaccessibles pour analyse, en tant que « dark data ».
Analyser les « Dark Data »
Alors, que se cache-t-il sous la surface des data lakes ? La première chose à faire pour les organisations est de découvrir quelles dark data elles ont accumulées. Ensuite, elles doivent les analyser pour en tirer des informations précieuses. Cela signifie que les analystes ont besoin de solutions leur permettant d'accéder à des pétaoctets de dark data.
Avec Amazon Redshift Spectrum, vous pouvez interroger des données dans Amazon S3 sans d'abord les charger dans Amazon Redshift. Pour des raisons de nomenclature, j'utiliserai « Redshift » pour « Amazon Redshift » et « Spectrum » pour « Amazon Redshift Spectrum ».
Il existe trois principales méthodes existantes pour accéder et analyser les données dans S3.
- Amazon Elastic MapReduce (EMR). EMR utilise des requêtes de style Hadoop pour accéder et traiter de grands ensembles de données dans S3.
- Amazon Athena. Athena offre une console pour interroger les données S3 avec du SQL standard et sans infrastructure à gérer. Athena dispose également d'une API.
- Amazon Redshift. Vous pouvez charger des données depuis S3 dans un cluster Amazon Redshift pour analyse.
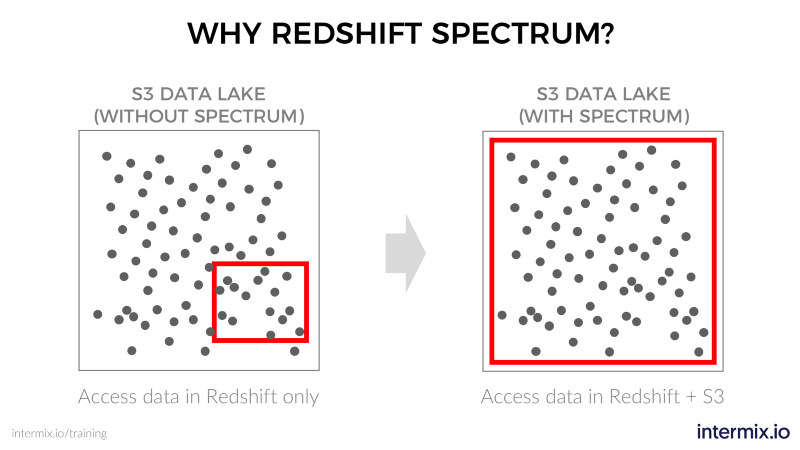
Alors pourquoi ne pas utiliser ces options existantes ? Par exemple, les entreprises utilisent déjà Amazon Redshift pour analyser leurs données « chaudes ». Alors pourquoi ne pas charger ces données froides depuis S3 dans Redshift et en rester là ?
Il y a deux raisons principales :
- Effort. Le chargement de données dans Amazon Redshift implique des étapes d'extraction, de transformation et de chargement (ETL). Ces étapes sont nécessaires pour convertir et structurer les données en vue de leur analyse. Amazon estime que la détermination du bon ETL consomme 70 % d'un projet d'analyse.
- Coût. Vous ne savez peut-être même pas quelles données extraire tant que vous ne les avez pas un peu analysées. Le téléchargement de nombreuses données froides de S3 pour analyse nécessite d'agrandir vos clusters. Cela se traduit par des coûts plus élevés, car la tarification de Redshift est basée sur la taille de votre cluster. Pendant ce temps, vous continuez à payer les frais de stockage S3 pour la conservation de vos données froides.
Redshift Spectrum offre le meilleur des deux mondes. Avec Spectrum, vous pouvez :
- Continuer à utiliser vos applications d'analyse, avec les mêmes requêtes que vous avez écrites pour Redshift.
- Laisser les données froides telles quelles dans S3 et les interroger via Amazon Redshift, sans traitement ETL. Cela inclut la jointure de données de votre data lake avec des données dans Redshift, en utilisant une seule requête.
- Découpler le traitement du stockage. Comme il n'est pas nécessaire d'augmenter la taille du cluster, vous pouvez économiser sur le stockage Redshift.
- Ne payer que lorsque vous exécutez des requêtes sur les données S3. Les requêtes Spectrum coûtent un tarif raisonnable de 5 $/térabits de données traitées.
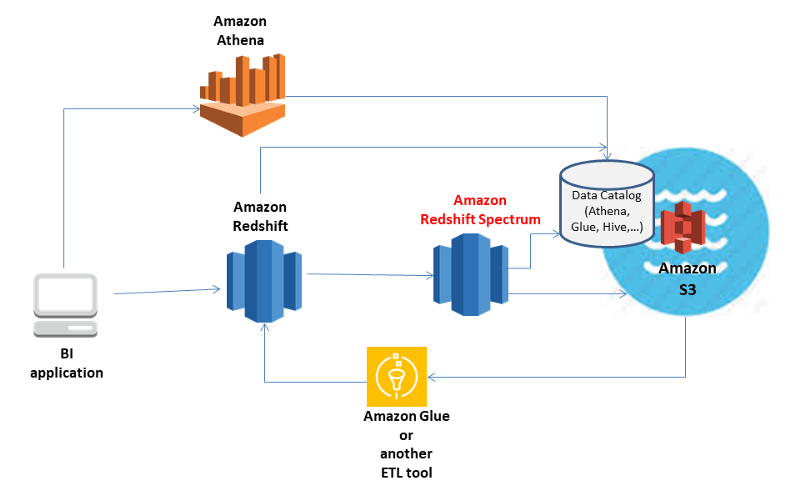
Spectrum est la couche de « colle » ou de « pont » qui fournit à Redshift une interface vers les données S3. Redshift devient la couche d'accès pour vos applications métiers. Spectrum est la couche de traitement des requêtes pour les données accédées depuis S3. L'image ci-dessus illustre la relation entre ces services.
Un regard plus attentif sur Redshift Spectrum
D'un point de vue déploiement, Spectrum est « sous le capot ». Il s'agit d'un groupe de nœuds gérés dans votre VPC, disponible pour tous vos clusters Redshift qui sont activés pour Spectrum. Il pousse les tâches intensives en calcul vers la couche Redshift Spectrum. Cette couche est indépendante de votre cluster Amazon Redshift.
Il y a trois concepts clés à comprendre pour exécuter des requêtes avec Redshift Spectrum :
- Catalogue de données externe
- Schémas externes
- Tables externes
Le catalogue de données externe contient les définitions de schéma pour les données que vous souhaitez accéder dans S3. Il s'agit d'un dépôt central de métadonnées pour vos actifs de données.
Le schéma externe contient vos tables. Les tables externes vous permettent d'interroger des données dans S3 en utilisant la même syntaxe SELECT que pour les autres tables Amazon Redshift. Les tables externes sont en lecture seule, c'est-à-dire que vous ne pouvez pas écrire dans une table externe.
Vous pouvez continuer à écrire vos requêtes Redshift habituelles. Le principal changement avec Spectrum est que les requêtes contiennent désormais également une référence aux données stockées dans S3.
Jointure de tables internes et externes
Le moteur de requête Redshift traite les tables internes et externes de la même manière. Vous pouvez effectuer les opérations typiques comme des requêtes et des jointures sur l'un ou l'autre type de table ou une combinaison des deux. Interrogez une table externe et joignez ses données avec celles d'une table interne.
Par exemple, supposons que vous utilisez Redshift pour analyser les données des visiteurs de votre site de commerce électronique. Quelles pages ils visitent, combien de temps ils restent, ce qu'ils achètent (ou non), et ainsi de suite. Vous conservez une année de données dans vos clusters Redshift. Les données plus anciennes sont déplacées vers S3.
Ensuite, vous remarquez une variation saisonnière étrange. Vous voulez voir si cela était également vrai pour les années passées, ou si c'était une aberration pour cette année. Heureusement, vous avez sauvegardé des données historiques de clickstream dans S3, remontant à de nombreuses années. Vous pouvez maintenant accéder à ces données historiques via une table externe avec Spectrum, et exécuter les mêmes requêtes que vous exécutez dans Amazon Redshift. Ou vous pouvez créer de nouvelles perspectives en joignant d'autres données passées avec les données de cette année.
Redshift analyse, compile et distribue une requête SQL aux nœuds d'un cluster de la manière habituelle. La partie de la requête qui référence une source de données externe est envoyée à Spectrum. Spectrum traite les données pertinentes dans S3 et envoie le résultat à Redshift. Redshift collecte les résultats partiels de ses nœuds et de Spectrum, les concatène et les joint (et ainsi de suite), et retourne le résultat complet.
Résumé
Voici quelques points à garder à l'esprit lorsque vous travaillez avec Spectrum :
- Vos applications métiers restent inchangées et ne savent pas comment ou où une requête est exécutée. Le seul changement pour l'analyste métier est lors de la définition de l'accès aux tables externes.
- Les données externes restent dans S3 — il n'y a pas d'ETL pour les charger dans votre cluster Redshift. Cela découple votre couche de stockage dans S3 de votre couche de traitement avec Redshift et Spectrum.
- Vous n'avez pas besoin d'augmenter la taille de votre cluster Redshift pour traiter les données dans S3. Vous ne payez que pour les données S3 que vos requêtes accèdent réellement.
- Redshift fait tout le travail difficile de minimiser le nombre de nœuds Spectrum nécessaires pour accéder aux données S3. Il rend également le traitement entre Redshift et Spectrum efficace.
Vous devez également faire vos devoirs pour vous assurer que le traitement des données dans S3 est économique et efficace. Vous pouvez économiser sur les coûts et obtenir de meilleures performances si vous partitionnez les données, les compressez ou les convertissez en formats colonnaires tels qu'Apache Parquet.
En résumé, Spectrum ajoute un outil supplémentaire à votre investissement dans l'entrepôt de données basé sur Redshift. Vous pouvez maintenant utiliser sa puissance pour sonder et analyser votre data lake au besoin pour un prix très bas par requête.
Je suis le cofondateur d'intermix.io. Si vous souhaitez le découvrir, vous pouvez le faire ici.
_Publié à l'origine sur www.intermix.io._