

Article original : Get started with Quarkus and JPAStreamer
Par Julia Gustafsson
Dans le monde du développement logiciel, l'innovation arrive souvent sous la forme d'outils puissants qui transforment la manière dont nous construisons des applications - voici Quarkus, une plateforme de développement qui redessine le paysage Java.
Si vous êtes nouveau dans le Quarkiverse, ce tutoriel est une excellente façon de commencer à explorer comment il peut radicalement améliorer votre expérience de développement Java. Je vais vous montrer comment assembler rapidement une application REST sur la plateforme Quarkus, en tirant parti de la puissance de JPAStreamer, une extension Hibernate pour gérer les interactions avec la base de données avec l'élégance de l'API Java Stream.
À la fin de ce guide, vous aurez les connaissances nécessaires pour rationaliser sans effort vos futures applications Java pour le déploiement cloud. De plus, je ne serais pas surprise si vous découvriez que Java est bien plus agréable avec le rechargement de code en direct et les tests continus.
Si vous préférez un guide visuel, il existe une version vidéo de ce tutoriel disponible sur la chaîne YouTube de freeCodeCamp.org (environ 1 heure).
1. Ce que nous allons construire
Ce tutoriel sert de guide complet pour construire une application Quarkus robuste. Nous couvrirons tous les aspects essentiels, de la configuration de votre environnement de développement et de l'établissement d'une connexion à la base de données, à la définition des endpoints REST, à la maîtrise des Java Streams avec JPAStreamer pour des requêtes puissantes, aux tests continus sans effort et à la compilation native. Le résultat final est une application REST légère qui sert des informations à partir d'un film d'exemple en une fraction de seconde après un démarrage à froid, posant les bases de vos futurs projets Quarkus.
En surface, cela ressemble à un autre guide sur la façon de développer une application, mais en pratique, c'est aussi un aperçu de ce que le développement avec Quarkus ressent.
Pendant le développement, vous vous familiariserez avec les sujets suivants :
- Configuration d'un projet Quarkus
- Connexion à une instance MySQL Docker
- Utilisation du mode de développement Quarkus
- Expression des requêtes en tant que Java Streams avec JPAStreamer
- Exécution de tests continus
- Compilation native de l'application pour des temps de démarrage rapides et une consommation minimale de mémoire
1.1 Qu'est-ce qui rend Quarkus spécial ?
Quarkus est souvent décrit comme un framework cloud-native de pointe conçu pour les applications Java et Kotlin modernes. Sa mission est de relever les défis de longue date de Java, tels que les temps de démarrage prolongés, la consommation élevée de mémoire et une expérience de développement plutôt lente.
Il est capable d'atteindre cet objectif avec deux exploits de conception intelligents - un processus de construction amélioré qui effectue une grande partie du travail lourd au moment de la construction plutôt qu'au démarrage de l'application, et en tant qu'extension de cela - un mode développeur qui vous permet de lancer votre application et d'incorporer toute mise à jour de code à la volée.
Quatre ans après sa sortie initiale, Quarkus dispose d'une large gamme d'extensions, garantissant une intégration transparente avec toutes les principales bibliothèques Java comme Hibernate, Spring et JUnit.
1.2 Qu'est-ce que JPAStreamer ?
JPAStreamer est une bibliothèque légère conçue pour simplifier l'accès à la base de données dans les applications Java qui utilisent l'API Java Persistence (JPA). Sa puissance réside dans ses requêtes Stream expressives et typées qui aident à améliorer la précision du codage et la productivité.
JPAStreamer optimise les performances en traduisant les pipelines en requêtes Hibernate Query Language (HQL). Contrairement à l'utilisation de getResultStream() dans Hibernate, qui matérialise toutes les entités, JPAStreamer garantit que seules les entités pertinentes sont récupérées, comme l'utilisation directe de SQL.
Imaginez récupérer 10 films d'une base de données où chaque titre commence par "A" et dure au moins 1 heure. Avec JPAStreamer, la requête est aussi simple que :
List<Film> films = jpaStreamer.stream(Film.class)
.filter(Film$.title.startsWith("A")
.and(Film$.length.greaterThan(60))
.limit(10)
.collect(Collectors.toList());
2. Prérequis
Avant de retrousser nos manches et de commencer à coder, il est important de s'assurer que vous avez tout ce dont vous avez besoin. Même si ce guide couvre tous les détails nécessaires pour obtenir une application entièrement fonctionnelle, il est supposé que vous êtes :
- Familier avec Java de base
- Acquainté avec l'API Java Stream
- À l'aise avec les interactions de base de données utilisant JPA/Hibernate
Si vous prévoyez de suivre ce guide sur votre machine locale, assurez-vous que votre environnement de développement répond aux exigences suivantes :
- Java 11 ou ultérieur
- Un IDE de votre choix (le guide utilise IntelliJ)
- Maven (ou Gradle)
- Quarkus CLI
- Docker et Docker CLI (ou votre propre base de données)
- Optionnel - Installation de GraalVM
3. Configuration du projet
Une fois que vous avez vérifié la liste des prérequis, il est temps de créer un nouveau projet Quarkus. Il existe plusieurs façons de procéder, mais pour simplifier, j'utiliserai le configurateur de projet Quarkus trouvé à code.quarkus.io/. Cet outil vous permet d'assembler rapidement un fichier de construction complet avec les dépendances nécessaires.
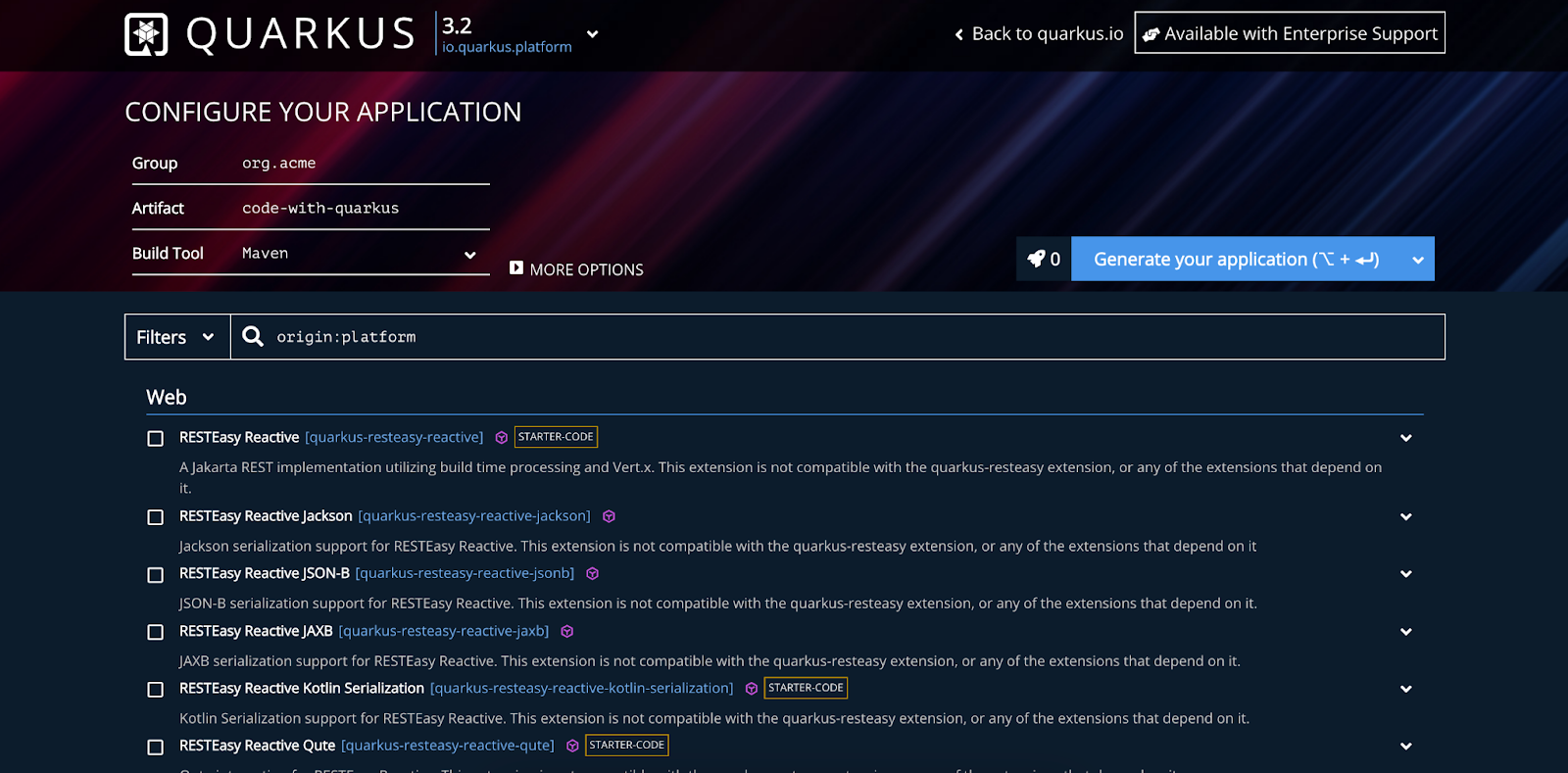
Commencez par sélectionner une version de Quarkus en haut de la page. Je recommande d'utiliser la dernière version ou de sélectionner une version LTS, par exemple 3.2 (la dernière au moment de la rédaction). Après avoir nommé votre projet de manière appropriée, sélectionnez les dépendances suivantes :
- Hibernate ORM avec Panache : Gère les interactions avec la base de données
- JPAStreamer : Extension Hibernate pour des requêtes intuitives et typées
- SmallRye OpenAPI : Active Swagger UI pour envoyer des requêtes de test
- RESTEasy Reactive Jackson : Facilite la configuration facile des endpoints REST
- Pilote JDBC - MySQL : Notre pilote de base de données
Appuyez simplement sur « Générer votre application » pour télécharger un fichier ZIP du projet. Vous pouvez télécharger un starter Quarkus avec mes paramètres exacts via ce lien.
À partir de là, ouvrez le projet dans l'IDE de votre choix. En jetant un rapide coup d'œil à la structure du projet, vous remarquerez que Quarkus a organisé le projet dans une structure Maven familière, avec un fichier pom.xml pour les dépendances et la configuration du projet.
quarkus-tutorial
|- src
| |- main
| | |- java
| | |- resources
|- src
Si vous jetez un coup d'œil au fichier pom.xml, vous y trouverez les dépendances sélectionnées. Notez également que JUnit a été automatiquement ajouté pour la phase de tests continus plus tard.
4. Configuration de la base de données
Alors que je plonge dans le domaine des nouvelles technologies, j'inclus souvent la base de données d'exemple Sakila d'Oracle dans mon environnement de développement, car elle est facilement disponible sous forme d'image Docker. Ce projet ne fait pas exception.
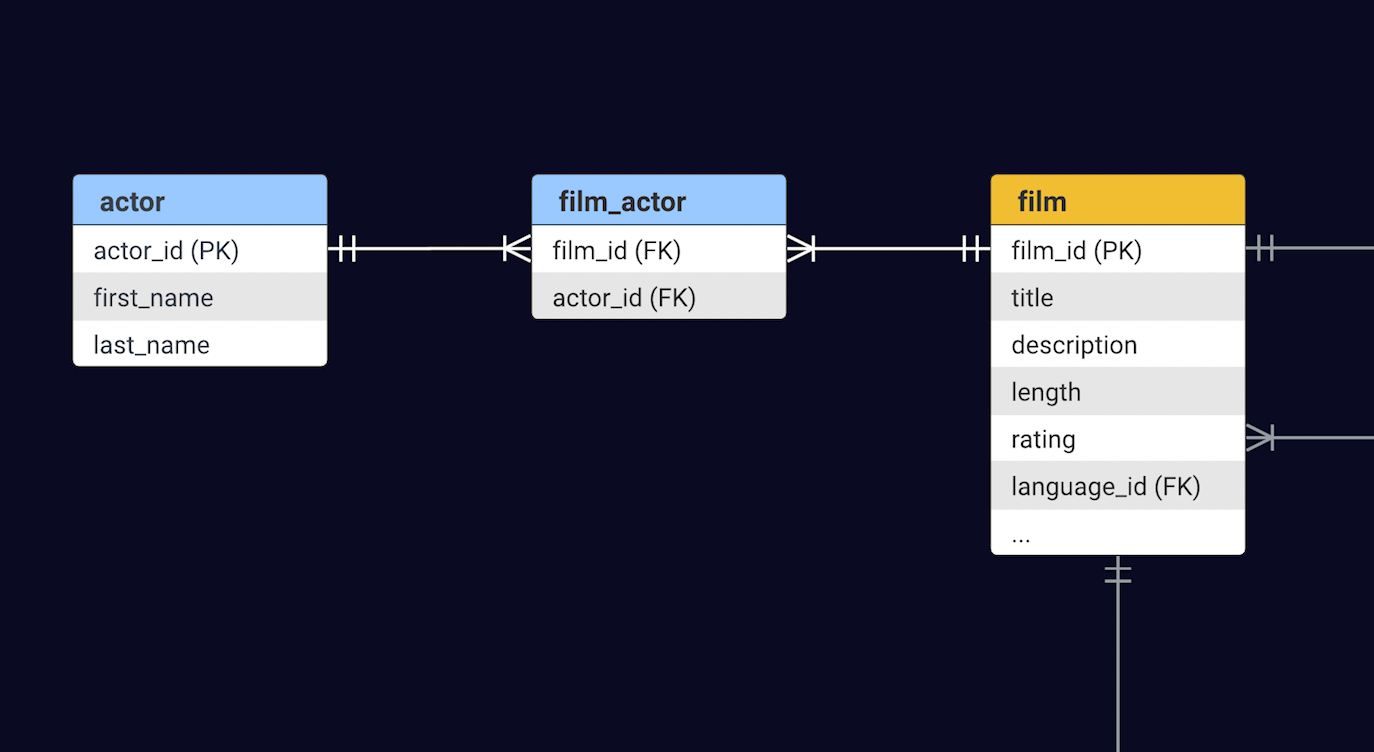
Sakila modélise un ancien magasin de location de vidéos, du genre où vous attendriez avec impatience un film sur cassette ou DVD. Naturellement, le cœur de cette base de données est centré autour de la table Film, complétée par diverses tables de support - pensez à Inventory, Customer et Payment. Pour cette démonstration, notre focus sera sur la fourniture d'informations sur les films et les acteurs jouant dans ces films. Les tables Film et Actor partagent une relation Many-to-Many - un film peut avoir de nombreux acteurs, et inversement, un acteur peut jouer dans de nombreux films.
Pour télécharger et initier la base de données sur le port 3306, utilisez la CLI Docker.
docker run --platform linux/amd64 -d --publish 3306:3306 --name sakila restsql/mysql-sakila
Le drapeau --platform indique à Docker d'accepter l'image Linux AMD64 de Sakila indépendamment de la plateforme locale. Dans mon expérience, elle fonctionne bien sur d'autres plateformes.
Après avoir exécuté cette commande, vous devriez observer le téléchargement et le lancement de l'image.
5. Configuration de Hibernate
Pour faciliter les interactions avec la base de données via Hibernate, une configuration est requise. Bien que Hibernate dans le domaine Quarkus se comporte beaucoup comme Hibernate standard dans toute application Java, vous configurerez Hibernate dans le fichier application.configuration. Deuxièmement, nous générerons le code standard JPA avec l'assistance d'IntelliJ.
5.1 Configuration de Hibernate
Le fichier application.configuration se trouve dans le dossier /resources du modèle de projet que vous avez initialement téléchargé. Ce fichier sert de hub, répondant à diverses dépendances et extensions potentielles de Quarkus. Cela signifie que notre configuration de base de données ne sera pas spécifique à Hibernate ; tout framework nécessitant une interaction avec la base de données peut utiliser cette configuration.
Pourtant, la configuration est similaire à la configuration standard de la base de données Hibernate. En supposant que vous exécutez la base de données Sakila comme indiqué, vous devez définir le pilote JDBC MySQL, spécifier l'URL JDBC pour localhost sur le port 3306, et fournir le nom d'utilisateur 'root' et le mot de passe 'sakila'.
quarkus.datasource.jdbc.driver=com.mysql.cj.jdbc.Driver
quarkus.datasource.jdbc.url=jdbc:mysql://localhost:3306/sakila
quarkus.datasource.username=root
quarkus.datasource.password=sakila
De plus, je recommande de définir hibernate-orm.log.sql sur true, car cela garantira que toutes les requêtes Hibernate sont journalisées, simplifiant l'inspection des requêtes JPAStreamer plus tard.
quarkus.hibernate-orm.log.sql=true
5.2 Création du métamodèle JPA
Pour manipuler les données, vous aurez besoin d'un modèle JPA avec une entité représentant chaque table. Comme ce n'est pas un guide approfondi sur Hibernate, je vais vous conseiller de prendre un raccourci et de générer un code standard JPA qui ne nécessite que des modifications mineures pour répondre à vos besoins. Si vous utilisez IntelliJ, vous pouvez suivre mes étapes, sinon, vous devrez consulter la documentation de votre IDE.
Commencez par vous connecter à la base de données dans IntelliJ en naviguant vers File > New > Data Source et en sélectionnant une instance MySQL. Ensuite, remplissez les champs de la boîte de dialogue avec la même URL de connexion, nom d'utilisateur et mot de passe que dans la section précédente Configuring Hibernate.
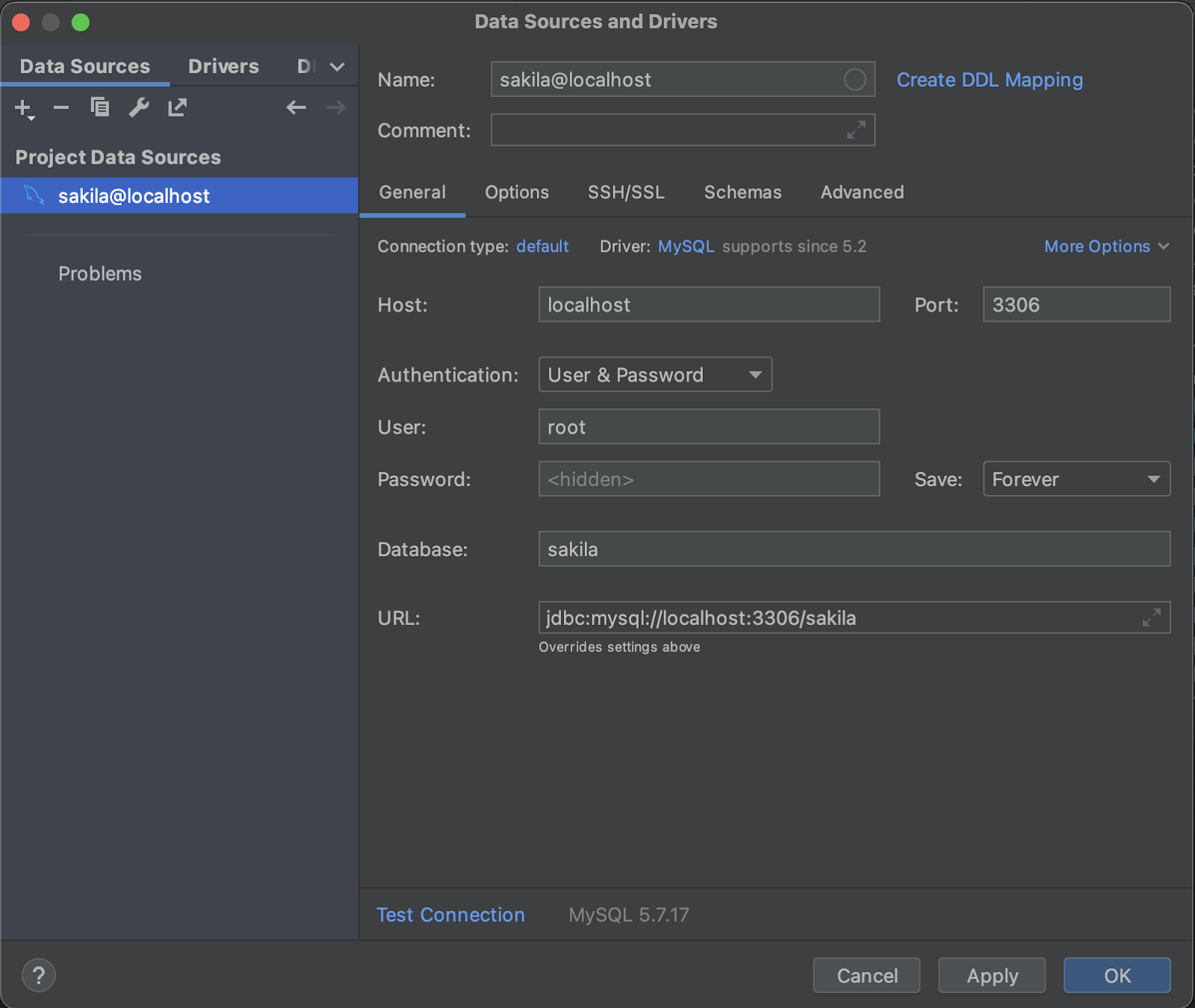
Après avoir appuyé sur OK, vous devriez pouvoir voir le contenu de la base de données pour confirmer que la connexion a été établie correctement. Si la base de données semble vide malgré la connexion, déclenchez un rechargement de la base de données pour vous assurer que les données de la table sont récupérées correctement.
Maintenant que notre base de données est liée à IntelliJ, la génération d'entités est simple. Un simple clic droit sur la base de données connectée vous mène à "Generate Persistence Mapping." Sélectionnez où placer vos entités générées (un package), et désélectionnez toutes les tables sauf Film et Actor, car ce sont les seules avec lesquelles nous travaillerons. Cliquez à nouveau sur OK, et les entités JPA pour ces tables sont générées en un clin d'œil.
Ensuite, vous devez apporter quelques modifications aux classes générées. JPA offre une myriade d'annotations pour affiner ces mappages, mais je ne couvrirai que ce qui est nécessaire pour les besoins de cette application.
Commencez par déclarer à quelles table et schéma les deux classes générées se mappent comme ceci :
@Table(name = "film", schema = "sakila")
public class Film { }
@Table(name = "actor", schema = "sakila")
public class Actor { }
Ensuite, supprimez les champs rating et _specialfeatures de la classe Film, ou améliorez les mappages pour imposer certaines contraintes sur les valeurs comme suit :
@Basic
@Column(name = "rating", columnDefinition = "enum('G','PG','PG-13','R','NC-17')")
private String rating;
@Basic
@Column(name = "special_features", columnDefinition = "set('Trailers', 'Commentaries', 'Deleted Scenes', 'Behind the Scenes')")
private String specialFeatures;
Vous devez également définir manuellement la relation Many-to-Many entre les tables Film et Actor. Cela nécessite quelques mises à jour dans les deux classes.
Tout d'abord, l'entité Film nécessite un champ nommé "actors", destiné à contenir des références aux acteurs présents dans un film spécifique. Ce lien est établi via le mappage @ManyToMany et l'annotation @JoinTable qui décrit la jointure. Rappelez-vous le nom de la join_table et les clés étrangères du schéma dans l'introduction de la base de données ci-dessus.
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
@JoinTable(
name = "film_actor",
joinColumns = { @JoinColumn(name = "film_id") },
inverseJoinColumns = { @JoinColumn(name = "actor_id") }
)
private List<Actor> actors = new ArrayList<>();
De même, la classe Actor a besoin d'un champ films pour contenir l'ensemble des films dans lesquels l'acteur a joué. Comme vous avez déjà décrit la jointure dans la classe Actor, ce champ n'a besoin que d'une référence au mappage ci-dessus comme suit :
@ManyToMany(mappedBy = "actors")
private Set<Film> films = new HashSet<>();
En tant qu'étape finale, allez-y et générez des getters et setters pour tous les champs dans les classes Film et Actor. Vous choisissez si vous le faites manuellement ou si vous les générez avec IntelliJ.
6. Configuration de JPAStreamer
JPAStreamer vous permet de créer des requêtes Java Stream complexes. Pour convertir de manière transparente ces Streams en requêtes SQL lors de l'exécution, JPAStreamer utilise son métamodèle dédié pour créer des prédicats intelligibles. Bien qu'une lambda standard puisse servir pour le filtrage, elle manque des détails nécessaires pour que JPAStreamer convertisse le pipeline Stream en une requête.
Dans l'exemple précédent, vous remarquerez l'utilisation d'une entité nommée Film$. Cette entité appartient au métamodèle JPAStreamer et vous permet d'articuler ces prédicats simples que JPAStreamer comprend.
List<Film> films = jpaStreamer.stream(Film.class)
.filter(Film$.title.startsWith("A")
.and(Film$.length.greaterThan(60))
.limit(10)
.collect(Collectors.toList());
Heureusement, le métamodèle JPAStreamer est créé automatiquement pour vous une fois que vous avez un métamodèle JPA en place. Ainsi, allez simplement de l'avant et reconstruisez votre application.
Le métamodèle se trouve dans le répertoire target, ce qui signifie qu'il ne sera pas détecté comme du code source par défaut. Pour remédier à cela, vous devez désigner le dossier generated-sources comme un "Generated Sources Root" en cliquant dessus avec le bouton droit. Si tout s'est bien passé, votre dossier generated-sources devrait contenir une classe Film$.class et Actor$.class.
Attention, si vous modifiez votre modèle JPA à un moment donné, vous devrez reconstruire le projet pour synchroniser les changements avec le métamodèle JPAStreamer. Il est également utile de mentionner que le nom et l'emplacement du métamodèle généré peuvent être personnalisés à l'aide des propriétés des variables d'environnement. Vous pouvez voir comment cela se fait dans la documentation de JPAStreamer.
7. Architecture de l'application
Il est maintenant temps de regarder l'architecture de l'application. L'objectif est d'établir des endpoints qui servent des informations liées aux films aux clients. Pour des raisons de clarté et de séparation des préoccupations, j'ai choisi d'adopter un modèle de dépôt simple.
Ci-dessous, un aperçu de la manière dont les pièces architecturales s'assembleront une fois que vous aurez terminé. La classe Resources prend la responsabilité de fournir du contenu dérivé de la base de données aux clients. Cependant, cette classe s'abstient de mener les interactions réelles avec la base de données ; au lieu de cela, cette tâche est confiée au Repository. Cette approche architecturale sépare proprement la couche de données des autres facettes de notre application.
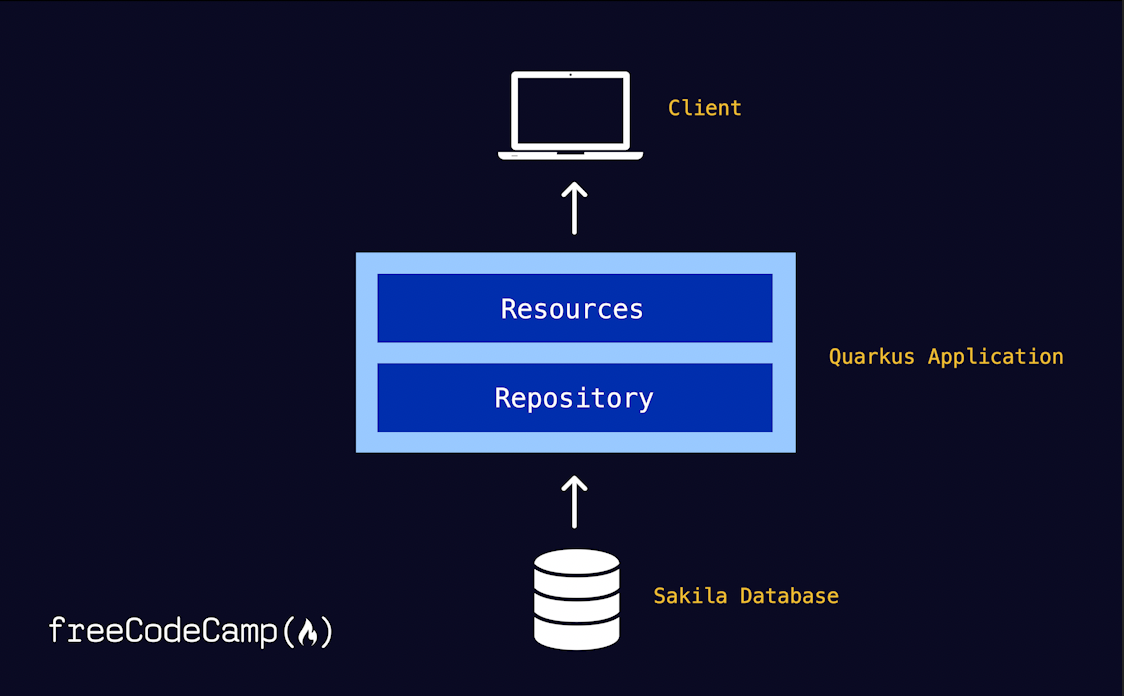
Cela se traduit par la hiérarchie de fichiers suivante dans votre dossier de projet une fois que vous avez terminé :
quarkus-tutorial
|- src
| |- main
| | |- java
| | | |- com.freecodecamp.app
| | | | |- FilmResource.java
| | | | |- model
| | | | |- Film.java
| | | | |- Actor.java
| | | | |- repository
| | | | |- FilmRepository.java
| | |- resources
| | | | |- application.properties
|- src
7. Hello World !
Pour comprendre le rythme du développement avec Quarkus, commençons par créer un endpoint classique "Hello World".
Commencez par établir la classe FilmResource, positionnée un niveau au-dessus de votre package de modèle de données :
@Path("/")
public class FilmResource {
@GET
@Path("/hello")
@Produces(MediaType.TEXT_PLAIN)
public String helloWorld() {
return "Hello world!";
}
}
L'annotation @Path garantit que votre servlet Resteasy est lancée au démarrage de l'application et ouvre l'endpoint /hello pour les requêtes.
8. Exécution en mode Dev Quarkus
Avec un endpoint simple en place, je vous suggère de démarrer l'application pour valider la fonctionnalité et profiter de l'expérience du mode dev Quarkus. Utilisez la commande suivante pour lancer l'application dans votre terminal :
quarkus dev
Lorsque votre application démarre, vous devriez être accueilli par l'invite Quarkus, indiquant que votre application s'exécute sur le port par défaut 8080 et que le codage en direct a été activé.
Listening for transport dt_socket at address: 5005
__ ____ __ _____ ___ __ ____ ______
--/ __ \/ / / / _ | / _ \/ //_/ / / / __/
-/ /_/ / /_/ / __ |/ , _/ ,< / /_/ /\ \
--\___\_\____/_/ |_/_/|_/_/|_|\____/___/
2023-08-14 14:14:01,731 INFO [io.quarkus] (Quarkus Main Thread) quarkus-tutorial 1.0.0-SNAPSHOT on JVM (powered by Quarkus 3.1.3.Final) started in 2.210s. Listening on: http://localhost:8080
2023-08-14 14:14:01,733 INFO [io.quarkus] (Quarkus Main Thread) Profile dev activated. Live Coding activated.
Vous pouvez maintenant visiter http://localhost:8080/hello pour confirmer que vous êtes accueilli par la réponse attendue « Hello world ! ».
Si c'est la première fois que vous utilisez le mode dev Quarkus, saisissez l'opportunité et faites une duplication de votre premier endpoint. Une petite modification, même aussi petite qu'un seul caractère, suffira à le distinguer de l'original. Ensuite, appuyez sur la touche [s] dans votre terminal pour redémarrer rapidement l'application. Le redémarrage a lieu en un clin d'œil, vous donnant accès à votre nouvel endpoint quelques instants plus tard dans le navigateur.
Cette approche dynamique empêche le scénario redouté d'accumuler des changements pour réaliser que l'application est non opérationnelle lors de la compilation. Vous n'avez plus non plus à subir de longs temps de compilation lorsque vous itérez sur de petites modifications d'algorithmes ou de fragments de code. C'est une méthode vraiment rapide et agile pour le développement interactif.
Avant de continuer, voici quelques commandes de base qu'il est bon de connaître :
[s] - Forcer le redémarrage
[h] - Afficher l'aide
[q] - Quitter
9. Récupération de films avec Java Streams et JPAStreamer
Jusqu'à présent, notre application n'a pas touché la base de données, mais c'est notre prochain mouvement. Nous commençons simplement et construisons progressivement des requêtes Stream plus puissantes.
Initiate this process by establishing a dedicated repository package adjacent to the existing model package. Inside this repository section, create a class named FilmRepository. As the name implies, this class will serve as the hub for our database queries. This class needs to be annotated with @ApplicationScoped for it to be injected into your FilmResource later.
Then, to start harnessing JPAStreamer, integrate it into the repository by injecting a JPAStreamer instance. This instance is your access point to the Stream query API. Here is what your class should look like at this point:
@ApplicationScoped
FilmRepository() {
@Inject
JPAStreamer jpaStreamer;
}
9.1 Récupération d'une entité par Id
Le premier endpoint récupérera le titre d'un film, donné un id. Ce sera votre première opportunité de tirer parti de JPAStreamer pour effectuer des requêtes. Vous pouvez penser à une requête Stream comme un pipeline virtuel qui est parcouru par tous les Films de la base de données. Les opérations ajoutées au pipeline décideront quelles entités sont autorisées à passer, et sous quelle forme. Par exemple, une opération de filtrage est l'équivalent d'une instruction WHERE car elle met une contrainte logique sur les entités résultantes.
Pour initier une requête Stream, vous appelez simplement la méthode JPAStreamer.stream() et lui fournissez une source de votre choix. Dans ce cas, notre source est la table Film, représentée par l'entité Film.class. La valeur de retour de cette opération est un Stream<Film> standard. Cela signifie que vous pouvez, en pratique, appliquer toute opération Stream disponible dans l'API Stream pour manipuler les entités Film.
Mais pas si vite - votre choix d'opérations Stream influence considérablement les performances, en particulier avec de grands ensembles de données ! Si vous êtes familier avec l'API Stream, vous avez probablement rencontré de nombreux exemples basés sur des lambdas pour les prédicats et les mappages tels que celui-ci :
.filter(f -> f.getFilmId().equals(filmId))
Cependant, ce prédicat ne peut pas être optimisé par JPAStreamer car la lambda anonyme contient trop peu de métadonnées pour effectuer une traduction SQL correcte. Par conséquent, prenez l'habitude d'exprimer les prédicats en utilisant le métamodèle JPAStreamer. Guidés par IntelliSense dans votre IDE, cela est simple :
.filter(Film$.id.equal(filmId))
Lors de l'exécution, cette opération sera en fait traduite en une opération SQL WHERE pour garantir que le filtrage est effectué dans la base de données, et non dans la JVM, pour plus d'efficacité.
Avec cette connaissance, vous pouvez créer une méthode qui récupère des films en fonction de leur id comme suit :
public Optional<Film> film(int filmId) {
return jpaStreamer.stream(Film.class)
.filter(Film$.filmId.equal(filmId))
.findFirst();
}
Comme avant, utilisez la touche [s] pour recharger votre application dans le terminal et naviguez vers :
En supposant que tout va bien, vous serez accueilli par le titre du film :
ANACONDA CONFESSIONS
Un rapide coup d'œil dans le journal de l'application révèle la requête Hibernate qui a été émise par JPAStreamer, confirmant la présence d'une opération WHERE.
Hibernate:
select
f1_0.film_id,
f1_0.description,
f1_0.language_id,
f1_0.last_update,
f1_0.length,
f1_0.original_language_id,
f1_0.rating,
f1_0.rental_duration,
f1_0.rental_rate,
f1_0.replacement_cost,
f1_0.special_features,
f1_0.title
from
film f1_0
where
f1_0.film_id=? limit ?
9.2 Requêtes paginées
Lorsque vous luttez avec un ensemble de données substantiel, envoyer aux utilisateurs l'intégralité des résultats peut s'avérer peu pratique ou même irréalisable. C'est là que la pagination entre en scène, limitant l'ensemble des résultats. En utilisant les requêtes Java Stream, la pagination devient une tâche sans effort. Vous pouvez facilement naviguer à travers les pages en sautant les données précédentes avec l'opérateur skip() et en contraignant les résultats à une taille de page prédéfinie avec limit().
En supposant une taille de page de 20, vous pouvez faciliter l'accès des clients aux films qui correspondent ou dépassent une longueur spécifiée tout en maintenant un ordre séquentiel basé sur la longueur. Voici comment :
private static final int PAGE_SIZE = 20;
...
public Stream<Film> paged(long page, int minLength) {
return jpaStreamer.stream(Film.class)
.filter(Film$.length.greaterThan(minLength))
.sorted(Film$.length)
.skip(page * PAGE_SIZE)
.limit(PAGE_SIZE);
}
Pour accommoder ce contenu paginé, votre FilmResource a besoin d'un nouvel endpoint :
@GET
@Path("/paged/{page}/{minLength}")
@Produces(MediaType.TEXT_PLAIN)
public String paged(long page, int minLength) {
return filmRepository.paged(page, minLength)
.map(f -> String.format("%s (%d min)", f.getTitle(), f.getLength()))
.collect(Collectors.joining("\n"));
}
Un simple appel à http://localhost:8080/paged/3/120 récupère les films de la troisième page, chacun durant un minimum de 2 heures, produisant une réponse attendue :
AMERICAN CIRCUS (129 min)
UNFORGIVEN ZOOLANDER (129 min)
...
CHOCOLATE DUCK (132 min)
STREAK RIDGEMONT (132 min)
Un rapide coup d'œil dans le terminal de développement Quarkus révèle que tous les opérateurs Stream ont été intégrés dans la requête en tant qu'opérateurs WHERE, ORDER BY et LIMIT avec une valeur inférieure et supérieure :
Hibernate:
select
f1_0.film_id,
f1_0.description,
f1_0.language_id,
f1_0.last_update,
f1_0.length,
f1_0.original_language_id,
f1_0.rating,
f1_0.rental_duration,
f1_0.rental_rate,
f1_0.replacement_cost,
f1_0.special_features,
f1_0.title
from
film f1_0
where
f1_0.length>?
order by
f1_0.length limit ?,
?
9.3 Projections
Vous avez probablement remarqué que vous récupérez l'ensemble des colonnes de la table Film, bien que vous n'incluiez que le titre et la longueur dans votre réponse. Vous pouvez économiser les ressources de l'application en utilisant une projection comme source de Stream au lieu de la table complète. L'filmId est requis car il s'agit de la clé primaire.
public Stream<Film> paged(long page, int minLength) {
return jpaStreamer.stream(Projection.select(Film$.filmId, Film$.title, Film$.length))
.filter(Film$.length.greaterThan(minLength))
.sorted(Film$.length)
.skip(page * PAGE_SIZE)
.limit(PAGE_SIZE);
}
Ce changement nécessite également que vous amélioriez l'entité Film avec un constructeur correspondant.
public Film(short filmId, String title, int length) {
this.filmId = filmId;
this.title = title;
this.length = length;
}
Maintenant, allez-y et faites une deuxième requête à l'endpoint paginé et observez comment la requête est limitée à trois colonnes.
http://localhost:8080/paged/3/120
Hibernate:
select
f1_0.film_id,
f1_0.title,
f1_0.length
from
film f1_0
where
f1_0.length>?
order by
3 limit ?,
?
9.3 Jointures
Passons maintenant à quelque chose de plus intéressant - effectuer une jointure Stream. Une jointure est une combinaison de plusieurs tables, traduite en requêtes Stream, ce qui signifie que vous devez mettre à jour la source Stream pour inclure des entités d'une table supplémentaire.
Dans la section 5.2, vous avez défini un mappage entre les tables Film et Actor via le champ List<Actor> actors. Avec JPAStreamer, vous pouvez réaliser une jointure des tables Film et Actor en créant une StreamConfiguration<Film> qui référence ce champ comme suit :
StreamConfiguration<Film> sc = StreamConfiguration.of(Film.class).joining(Film$.actors);
La configuration de stream remplace désormais Film.class en tant que source de stream. Pendant que nous y sommes, nous pourrions aussi bien ajouter un autre filtre et inverser l'ordre de tri. Remarquez comment plusieurs prédicats peuvent être combinés avec les opérateurs and/or.
public Stream<Film> actors(String startsWith, int minLength) {
final StreamConfiguration<Film> sc = StreamConfiguration
.of(Film.class).joining(Film$.actors);
return jpaStreamer.stream(sc)
.filter(Film$.title.startsWith(startsWith)
.and(Film$.length.greaterThan(minLength)))
.sorted(Film$.length.reversed());
}
En réponse aux clients, il semble approprié de présenter le titre des films, la durée des films (pour confirmer que l'ordre de tri est correct) et une liste des acteurs principaux :
@GET
@Path("/actors/{startsWith}/{minLength}")
@Produces(MediaType.TEXT_PLAIN)
public String actors(String startsWith, short minLength) {
return filmRepository.actors(startsWith, minLength)
.map(f -> String.format("%s (%d min): %s",
f.getTitle(),
f.getLength(),
f.getActors().stream()
.map(a -> String.format("%s %s", a.getFirstName(), a.getLastName()))
.collect(Collectors.joining(", "))))
.collect(Collectors.joining("\n"));
}
Maintenant, essayez d'appeler le nouvel endpoint avec un caractère de départ A et une longueur minimale de 2 heures : http://localhost:8080/actors/A/120. Vous devriez obtenir les résultats suivants :
ANALYZE HOOSIERS (181 min): TOM MCKELLEN, TOM MIRANDA, JESSICA BAILEY, GRETA MALDEN, ED GUINESS
ALLEY EVOLUTION (180 min): KARL BERRY, JUDE CRUISE, ALBERT JOHANSSON, GREGORY GOODING, JOHN SUVARI
...
ALAMO VIDEOTAPE (126 min): JOHNNY CAGE, SCARLETT DAMON, SEAN GUINESS, MICHAEL BENING
ARIZONA BANG (121 min): KARL BERRY, RAY JOHANSSON, RUSSELL BACALL, GRETA KEITEL
Ci-dessous se trouve la requête résultante, confirmant que la jointure a été appliquée.
Hibernate:
select
f1_0.film_id,
a1_0.film_id,
...
from
film f1_0
left join
(film_actor a1_0
join
actor a1_1
on a1_1.actor_id=a1_0.actor_id)
on f1_0.film_id=a1_0.film_id
where
f1_0.title like replace(?,'\\','\\\\')
and f1_0.length>?
order by
f1_0.length desc
9.4 Mise à jour des films
Bien que la force de JPAStreamer réside dans la lecture des données, vous pouvez également l'utiliser pour mettre à jour votre base de données. Supposons que le magasin de location de vidéos imaginé ait un modèle de prix basé sur la durée des films. Dans ce cas, vous souhaitez pouvoir ajuster le taux de location en fonction de la durée. Cela est facilement réalisé en filtrant les films pertinents et en appliquant l'opérateur forEach() pour définir un nouveau prix. En annotant la méthode avec @Transactional, vous garantissez que Hibernate persiste les modifications apportées à vos entités Film.
@Transactional
public void updateRentalRate(int minLength, int maxLength, BigDecimal rentalRate) {
jpaStreamer.stream(Film.class)
.filter(Film$.length.between(minLength, maxLength))
.forEach(f -> {
f.setRentalRate(rentalRate);
});
}
Je vous laisse créer un endpoint qui facilite l'initiation des mises à jour des taux de location par les clients.
10. Tests continus
Vous pouvez configurer Quarkus pour déclencher automatiquement l'exécution de votre suite de tests JUnit chaque fois que vous exécutez votre application. Ou alternativement, déclencher l'exécution manuellement en appuyant sur [r] dans le terminal de développement Quarkus. Auparavant, je comprenais la valeur du développement piloté par les tests (TDD), mais j'ai toujours eu l'impression que cela entrave la concentration sur la logique métier, car je ne les exécutais que de temps en temps. Cela ne signifie pas que Quarkus écrit les tests pour vous, mais ils sont faciles à exécuter et le mode dev vous rappelle constamment qu'ils sont là.
Les tests d'intégration et les tests unitaires.
Bien que j'aie initialement énoncé les exigences pour ce tutoriel, il y a quelques spécificités à connaître en ce qui concerne les tests continus. Si vous avez utilisé le configurateur de projet Quarkus comme décrit dans ce tutoriel, vous devriez déjà être configuré. Sinon, assurez-vous que vous :
- Dépendez du module Quarkus JUnit 5
- Définissez une version du plugin Maven Surefire (par exemple, 3.0.0) car la version par défaut ne prend pas en charge JUnit 5
- (Optionnel) Rest-assured pour des tests simples des endpoints REST
Pour répondre aux exigences ci-dessus, vérifiez que vous avez les dépendances et configurations de plugins suivantes dans votre pom.xml :
<dependencies>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-junit5</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<systemPropertyVariables>
<java.util.logging.manager>
org.jboss.logmanager.LogManager
</java.util.logging.manager>
<maven.home>${maven.home}</maven.home>
</systemPropertyVariables>
</configuration>
</plugin>
.
</plugins>
</build>
Les tests Quarkus sont placés comme vos tests JUnit réguliers dans le dossier de test standard, c'est-à-dire /src/test/java si votre outil de construction est Maven. La seule réelle différence est que vous devez annoter vos classes de test avec @QuarkusTest pour que les tests soient reconnus par Quarkus. Les sections suivantes contiennent des exemples sur la façon de créer des tests unitaires et d'intégration.
10.1 Tests unitaires
Il n'y a rien de spécial à propos de la création de tests unitaires avec Quarkus, à part le fait qu'ils peuvent être exécutés rapidement en mode développement. Pour tester le FilmRepository, vous pouvez simplement l'injecter dans votre classe de test comme vous l'avez fait dans le FilmResource et appeler vos méthodes CRUD.
Voici un exemple de test qui garantit que votre méthode getFilm() récupère un film avec le titre « AFRICAN EGG ».
@QuarkusTest
public class FilmRepositoryTest {
@Inject
FilmRepository filmRepository;
@Test
public void test() {
final Optional<Film> film = filmRepository.getFilm(5);
assertTrue(film.isPresent());
assertEquals("AFRICAN EGG", film.get().getTitle());
}
}
10.2 Tests d'intégration REST
Quarkus facilite également les tests d'intégration sans effort de vos endpoints REST. En tirant parti de la bibliothèque rest-assured, qui a été mentionnée dans la section précédente, vous accédez à une API riche conçue pour les tests REST.
L'exemple suivant rappelle le test unitaire précédent, mais sous la forme d'un test d'intégration. Lors de l'exécution, Quarkus émettra automatiquement une requête GET à votre endpoint de film, ciblant un film avec un ID de 5. Le test anticipe une réponse réussie (code de statut HTTP 200) et vérifie que le corps de la réponse contient le titre du film, "AFRICAN EGG."
@QuarkusTest
public class FilmResourceTest {
@Test
public void test() {
given()
.when().get("/film/5")
.then()
.statusCode(200)
.body(containsString("AFRICAN EGG"));
}
}
10.3 Exécution des tests
En supposant que vous êtes toujours en mode dev Quarkus, vous pouvez utiliser l'une de ces commandes pour contrôler la phase de test :
[r] - Réexécuter tous les tests
[f] - Réexécuter les tests échoués
[v] - Afficher les échecs du dernier test
Les résultats des tests seront enregistrés dans les journaux Quarkus :
Tous les 1 tests réussissent (0 ignorés), 1 test a été exécuté en 336ms. Tests terminés à 17:34:25 en raison des modifications apportées à FilmRepository.class.
Si vous souhaitez que les tests soient exécutés chaque fois qu'un changement d'application est détecté, vous pouvez définir quarkus.test.continuous-testing=enabled dans application.properties.
Vous avez également la possibilité d'exécuter vos tests chaque fois que vous n'êtes pas en mode dev en utilisant la commande :
mvn quarkus:test
11. Exécution du débogueur avec le mode Dev Quarkus
Fréquemment, un test peut échouer sans cause apparente, nous laissant perplexes (ou peut-être pas tant que ça). Ironiquement, je me surprends parfois à attribuer mes propres erreurs simples à des bugs sous-jacents dans des bibliothèques externes. Heureusement, le débogueur vient à notre rescousse, éclairant là où les choses ont mal tourné et m'humiliant souvent en révélant mes propres erreurs.
Si vous souhaitez utiliser le débogueur d'IntelliJ en conjonction avec le mode dev Quarkus, vous devez attacher le débogueur manuellement. Ce processus est simple mais implique la création d'une configuration d'exécution personnalisée. Allez dans Run > Edit Configurations et générez une nouvelle configuration Remote JVM Debug. Optez pour une étiquette claire comme "Debug Quarkus" pour la distinguer facilement des autres configurations. Comme Quarkus désigne le port 5005 pour les sessions de débogage, vous devez simplement spécifier que vous souhaitez vous connecter à un JVM distant à localhost:5005, comme illustré dans l'image ci-dessous.
Une fois cette configuration en place, redémarrez Quarkus en mode débogage dev comme suit :
./mvnw compile quarkus:dev -Ddebug
Ensuite, exécutez votre nouvelle configuration Debug Quarkus dans IntelliJ pour vous connecter au processus Quarkus et procédez à l'utilisation du débogueur comme d'habitude.
12. Construction de votre application
Bien que l'ensemble des fonctionnalités de notre application puisse être modeste à ce stade, elle est entièrement fonctionnelle et prête à offrir potentiellement aux utilisateurs l'accès à des informations liées aux films. Avec cela à l'esprit, c'est un moment opportun pour se préparer au déploiement.
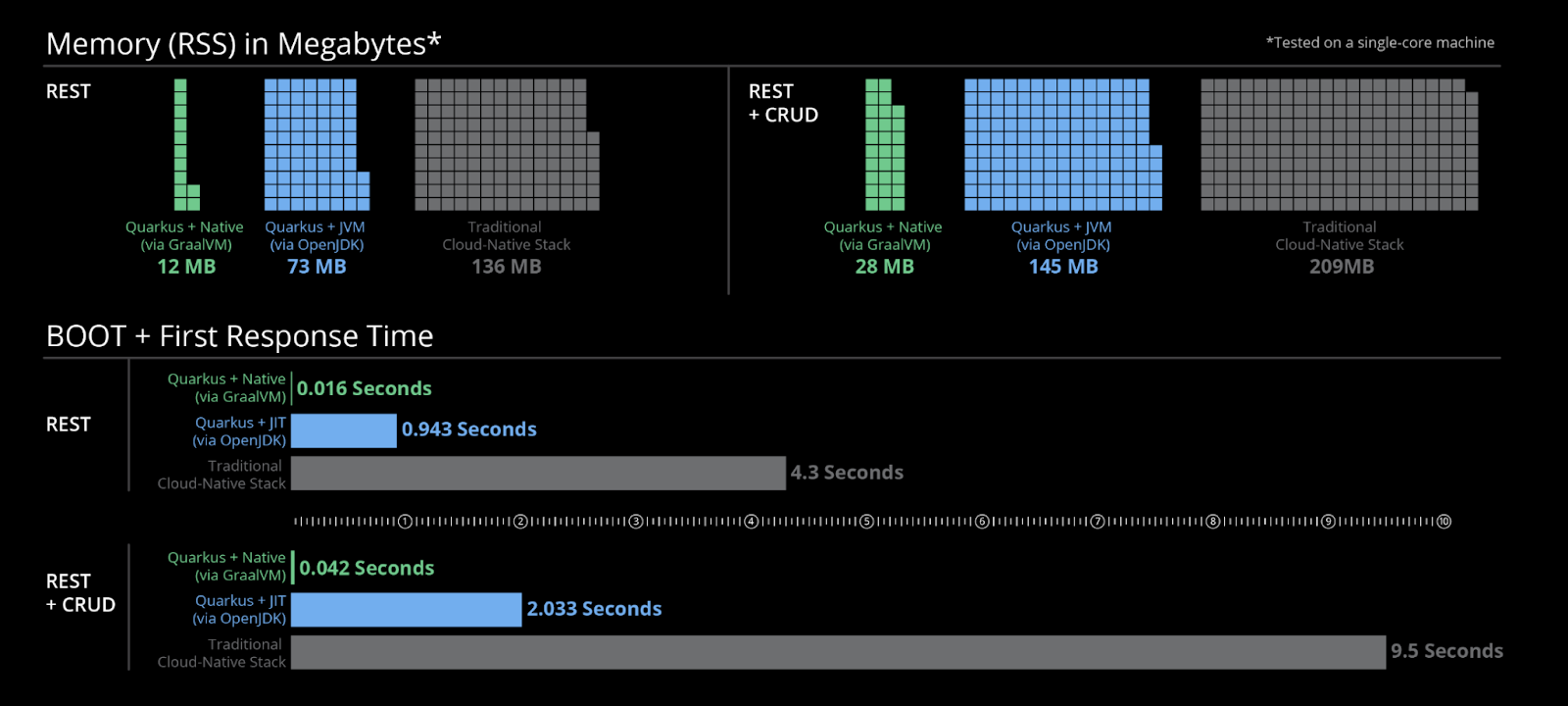
Quarkus propose deux options de construction distinctes : le compilateur Quarkus JIT HotSpot et la construction native Quarkus alimentée par Graal VM. Le premier améliore le compilateur Java JIT standard pour des performances optimales, tandis que le second capitalise sur la compilation à l'avance (AOT), maximisant l'efficacité de la construction au détriment de l'exécution. Bien que l'image ci-dessous soit un actif marketing fourni par Quarkus, mes propres expériences confirment les gains de performance tangibles qu'elle met en avant.
12.1 Construction JIT Quarkus via OpenJDK
Puisque vous avez déjà développé votre projet en utilisant la plateforme Quarkus, vous avez un accès immédiat au compilateur JIT sans aucune étape supplémentaire requise. L'illustration ci-dessus donne un aperçu des améliorations significatives que Quarkus a apportées au compilateur standard, répondant potentiellement à vos besoins d'optimisation.
Pour initier le processus de construction standard de Quarkus, exécutez simplement la commande :
quarkus build
La construction résultante est stockée dans /target/quarkus-app. Cependant, il est important de noter que le JAR généré n'est pas un über-jar et manque donc de fonctionnalité autonome. Pour un déploiement réussi, assurez-vous que l'ensemble du dossier quarkus-app est inclus, pour garantir la disponibilité de toutes les ressources nécessaires.
Lorsque vous êtes prêt à exécuter votre application, utilisez la commande suivante :
java -jar /target/quarkus-run.jar
Faites attention à l'invite Quarkus indiquant combien de temps il a fallu pour démarrer votre application. Pour référence, il m'a fallu environ 1,7s pour démarrer la version compilée JIT de cette application.
12.2 Construction native Quarkus via GraalVM
Maintenant, plongeons dans l'aspect le plus intéressant de Quarkus - le processus de construction native. Bien que la compilation native ne demande pas d'efforts supplémentaires de votre part en tant que développeur, elle nécessite un peu de patience. Effectuer une compilation à l'avance (AOT) prend considérablement plus de temps que la construction standard JVM HotSpot. La compilation native agit comme un compresseur puissant, mieux réservé pour lorsque vous préparez le déploiement d'une nouvelle itération de votre logiciel.
Comme Quarkus a introduit l'option de construire nativement en utilisant une variante conteneurisée de GraalVM, je ne m'attarderai pas sur les instructions d'installation de GraalVM. Pour exécuter une construction native en utilisant le conteneur Docker GraalVM, émettez la commande suivante :
./mvnw package -Pnative -Dquarkus.native.container-build=true
Alternativement, si vous possédez GraalVM localement, vous pouvez procéder avec la version locale :
./mvnw package -Pnative
Le fichier exécutable créé par la construction native fonctionne non pas comme une application basée sur JVM, mais comme une application native spécifique à la plateforme. Pour l'exécuter, il suffit d'exécuter le script runner situé à la racine du dossier target (Le nom du fichier correspond au nom de votre application) :
./target/quarkus-tutorial-1.0.0-SNAPSHOT-runner
Encore une fois, observez l'invite Quarkus pour voir combien de temps il a fallu pour démarrer la version native. Dans mon cas, j'étais descendu à environ un dixième de seconde !
13. Ressources
- Configurateur de projet Quarkus
- Documentation Quarkus
- Documentation JPAStreamer
- Code source complet du projet