


Article original : What to Know Before Taking Google's Machine Learning or Data Science Course
Que vous décidiez de suivre le cours de Machine Learning et de Deep Learning d'Andrew Ng sur YouTube ou tout bootcamp de Data Science, vous aurez besoin d'un certain niveau de connaissances mathématiques et statistiques.
Cela vous aidera non seulement à comprendre les concepts de base du ML/DS, mais aussi à construire une carrière durable et solide en tant que professionnel des données.
Ce guide est court et précis pour tous les développeurs autodidactes et les débutants dans le domaine de la Data Science et du Machine Learning.
Il y a une question courante qui revient dans tous mes programmes de formation, cours LinkedIn, vidéos YouTube ou newsletters. C'est que lorsque les gens commencent à apprendre le DS/ML, après un certain temps, ils se sentent perdus en mathématiques, statistiques et parfois en programmation.
Et j'ai toujours recommandé d'apprendre ou de rafraîchir certains concepts mathématiques qui sous-tendent le ML, car cela vous aide à construire une intuition qui maintient votre curiosité tout au long de votre parcours d'apprentissage.
Pour étayer cette affirmation, voici les préalables et prérequis que Google recommande avant de suivre leur Machine Learning Crash Course :

Préalables du cours Google ML
Je vous recommande de lire cet article en premier, puis de consulter tous les liens un par un et d'utiliser ce blog comme référence.
Après avoir parcouru la liste complète des concepts et compétences mentionnés dans l'article de Google, j'ai également consulté plusieurs livres (Deep Learning par Ian Goodfellow, Deep Learning with Python par François Chollet, et plusieurs autres).
À partir de ceux-ci, j'ai essayé de distiller l'essentiel en trois branches dont vous aurez besoin pour construire une base solide pour une carrière en tant que Data Analyst/Scientist/ML Engineer.
Voici les trois piliers ainsi qu'une liste de concepts qui constituent un bon programme de départ :

De mon cours ici.
Programmation pour les débutants complets en Data Science et Machine Learning
La programmation signifie donner à un ordinateur des règles prédéfinies qui l'aident à traiter les données d'entrée et à obtenir les résultats.
Le machine learning, en revanche, consiste à donner à la machine les résultats et les données pour trouver les règles qui approximient au mieux la relation entre les données et les résultats.
La programmation offre cette plateforme de base que vous pouvez utiliser pour automatiser, vérifier et résoudre des problèmes de toute envergure.
La question suivante est : quel langage devez-vous apprendre ?
Puisque la plupart des cours, bibliothèques et livres sont écrits pour soutenir l'infrastructure Python, je recommande d'apprendre Python, et c'est également ce que recommande le guide de Google. Le langage que vous utilisez est un choix personnel et dépend beaucoup du type de problème que vous essayez de résoudre.
La plupart des débutants préfèrent Python car c'est le meilleur moyen de développer des projets de bout en bout et il existe une très grande communauté de développeurs qui peuvent vous aider. Il est probable que ~90 % des problèmes que vous rencontrerez dans votre parcours (surtout dans la phase de début) soient déjà résolus et documentés pour vous.
1. Programmation Python essentielle pour le Machine Learning
La plupart des rôles liés aux données sont basés sur la programmation, à l'exception de quelques-uns comme le business intelligence, l'analyse de marché et l'analyse de produit.
Je vais me concentrer sur les emplois techniques liés aux données qui nécessitent une expertise dans au moins un langage de programmation. Je préfère personnellement Python à tout autre langage en raison de sa polyvalence et de sa facilité d'apprentissage – sans aucun doute un bon choix pour développer des projets de bout en bout.
Voici quelques-uns des sujets/bibliothèques que vous devriez étudier pour la data science/ML :
Structures de données courantes (types de données, listes, dictionnaires, ensembles, tuples), écriture de fonctions, logique, flux de contrôle, algorithmes de recherche et de tri, programmation orientée objet, et travail avec des bibliothèques externes.
Écriture de scripts Python pour extraire, formater et stocker des données dans des fichiers ou les renvoyer vers des bases de données.
Manipulation de tableaux multidimensionnels, indexation, découpage, transposition, diffusion et génération de nombres pseudo-aléatoires à l'aide de NumPy.
Effectuer des opérations vectorisées à l'aide de bibliothèques de calcul scientifique comme NumPy.
Manipuler des données avec Pandas – séries, dataframe, indexation dans un dataframe, opérateurs de comparaison, fusion de dataframes, mappage et application de fonctions.
Nettoyage de données avec pandas – vérifier les valeurs nulles, les imputer, regrouper les données, les décrire, effectuer une analyse exploratoire, etc.
Visualisation de données avec Matplotlib – la hiérarchie de l'API, ajout de styles, de couleurs et de marqueurs à un graphique, connaissance des différents types de graphiques et quand les utiliser, graphiques en ligne, graphiques en barres, graphiques de dispersion, histogrammes, boxplots, et seaborn pour des graphiques plus avancés.
2. Mathématiques essentielles pour la Data Science et le Machine Learning
Il existe des raisons pratiques pour lesquelles les mathématiques sont essentielles pour ceux qui veulent une carrière en tant que praticien du ML, Data Scientist ou Ingénieur en Deep Learning.
Utiliser l'algèbre linéaire pour représenter les données
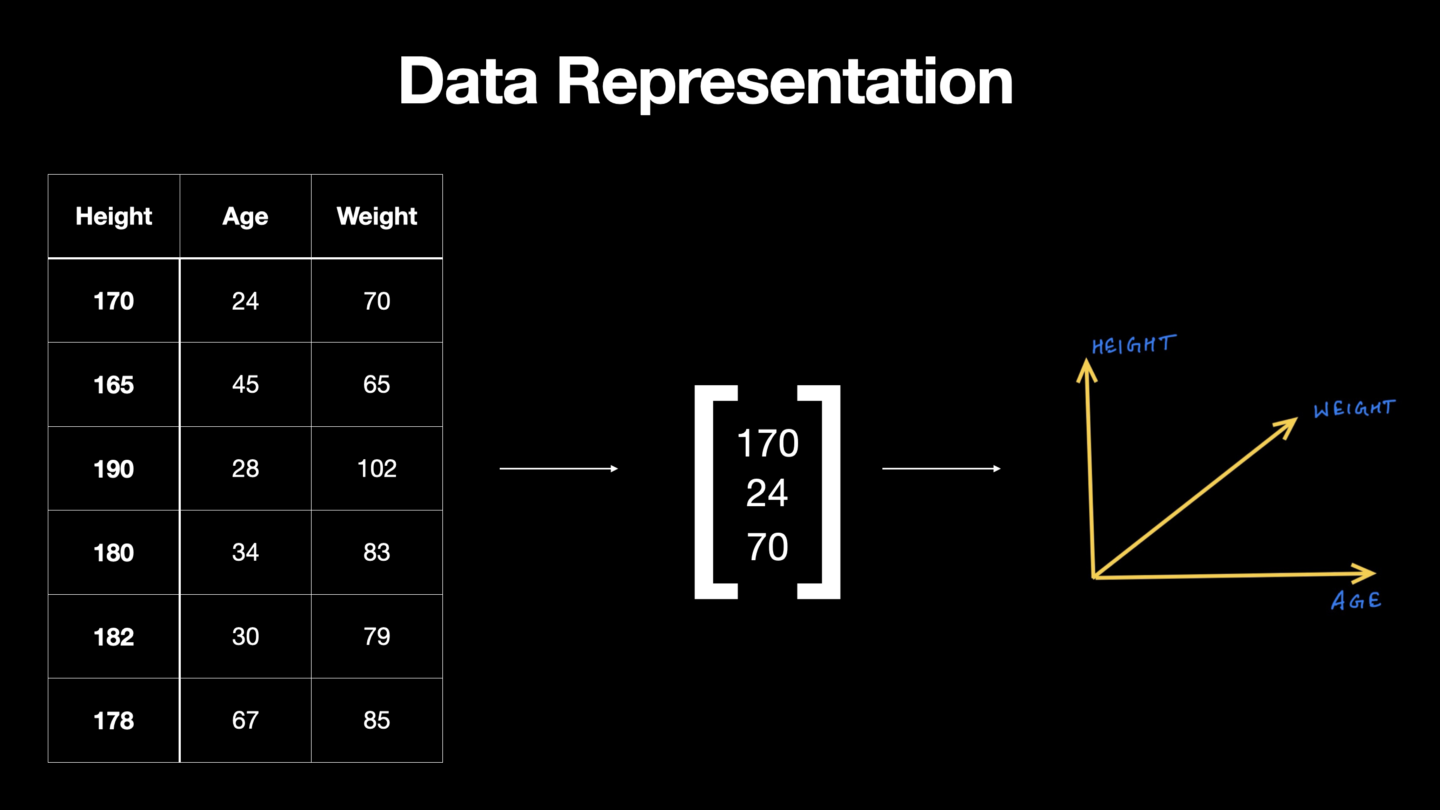
Une image du cours : https://www.wiplane.com/p/foundations-for-data-science-ml
Le ML est intrinsèquement basé sur les données – les données sont au cœur du machine learning. Nous pouvons considérer les données comme des vecteurs, un objet qui respecte les règles arithmétiques. Cela nous amène à comprendre comment les règles de l'algèbre linéaire opèrent sur des tableaux de données.
Utiliser le calcul pour entraîner les modèles ML

Image du cours : https://www.wiplane.com/p/foundations-for-data-science-ml
L'entraînement des modèles ne se fait pas « automatiquement ». Le calcul est ce qui permet l'apprentissage de la plupart des algorithmes ML et DL.
L'un des algorithmes d'optimisation les plus couramment utilisés (descente de gradient) est une application des dérivées partielles.
Un modèle est une représentation mathématique de certaines croyances et hypothèses. On dit qu'il apprend (approximation) le processus (linéaire, polynomial, etc.) de la manière dont les données sont fournies, ont été générées en premier lieu, puis fait des prédictions basées sur ce processus appris.
Les sujets importants incluent :
Algèbre de base – variables, coefficients, équations, fonctions—linéaires, exponentielles, logarithmiques, etc.
Algèbre linéaire – scalaires, vecteurs, tenseurs, normes (L1 & L2), produit scalaire, types de matrices, transformation linéaire, représentation d'équations linéaires en notation matricielle, résolution de problèmes de régression linéaire à l'aide de vecteurs et de matrices.
Calcul – dérivées et limites, règles de dérivation, règle de la chaîne (pour l'algorithme de rétropropagation), dérivées partielles (pour calculer les gradients), convexité des fonctions, minima locaux/globaux, les mathématiques derrière un modèle de régression, mathématiques appliquées pour entraîner un modèle à partir de zéro.
3. Statistiques essentielles pour la Data Science
Chaque organisation aujourd'hui s'efforce de devenir data-driven. Pour y parvenir, les analystes et les scientifiques doivent être capables d'utiliser les données de différentes manières afin de piloter la prise de décision.
Décrire les données—des données aux insights
Les données arrivent toujours brutes et désordonnées. L'exploration initiale vous indique ce qui manque, comment les données sont distribuées et quelle est la meilleure façon de les nettoyer pour atteindre l'objectif final.
Afin de répondre aux questions que vous avez définies, les statistiques descriptives vous permettent de transformer chaque observation de vos données en insights compréhensibles.
Quantifier l'incertitude
De plus, la capacité à quantifier l'incertitude est la compétence la plus précieuse, très appréciée dans toute entreprise de données. Connaître les chances de succès dans toute expérience/décision est crucial pour toutes les entreprises.
Voici quelques-uns des piliers principaux des statistiques qui constituent le minimum indispensable :
Image de la conférence sur la distribution de Poisson—https://www.wiplane.com/p/foundations-for-data-science-ml
Estimations de position – moyenne, médiane et autres variantes de celles-ci.
Estimations de variabilité
Corrélation et covariance
Variables aléatoires – discrètes et continues
Distributions de données – PMF, PDF, CDF
Probabilité conditionnelle – statistiques bayésiennes
Distributions statistiques couramment utilisées – Gaussienne, Binomiale, Poisson, Exponentielle.
Théorèmes importants – Loi des grands nombres et Théorème central limite.
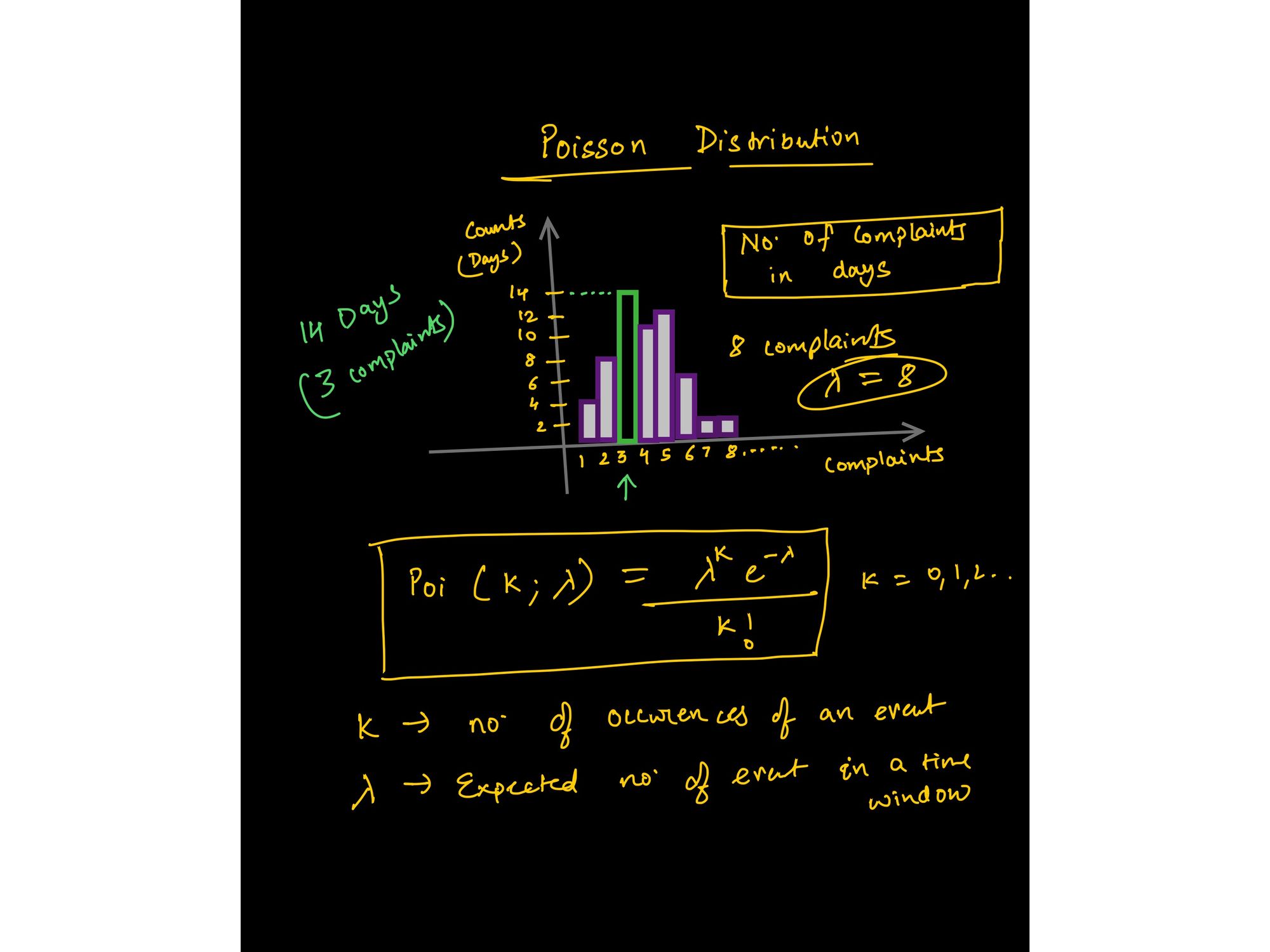
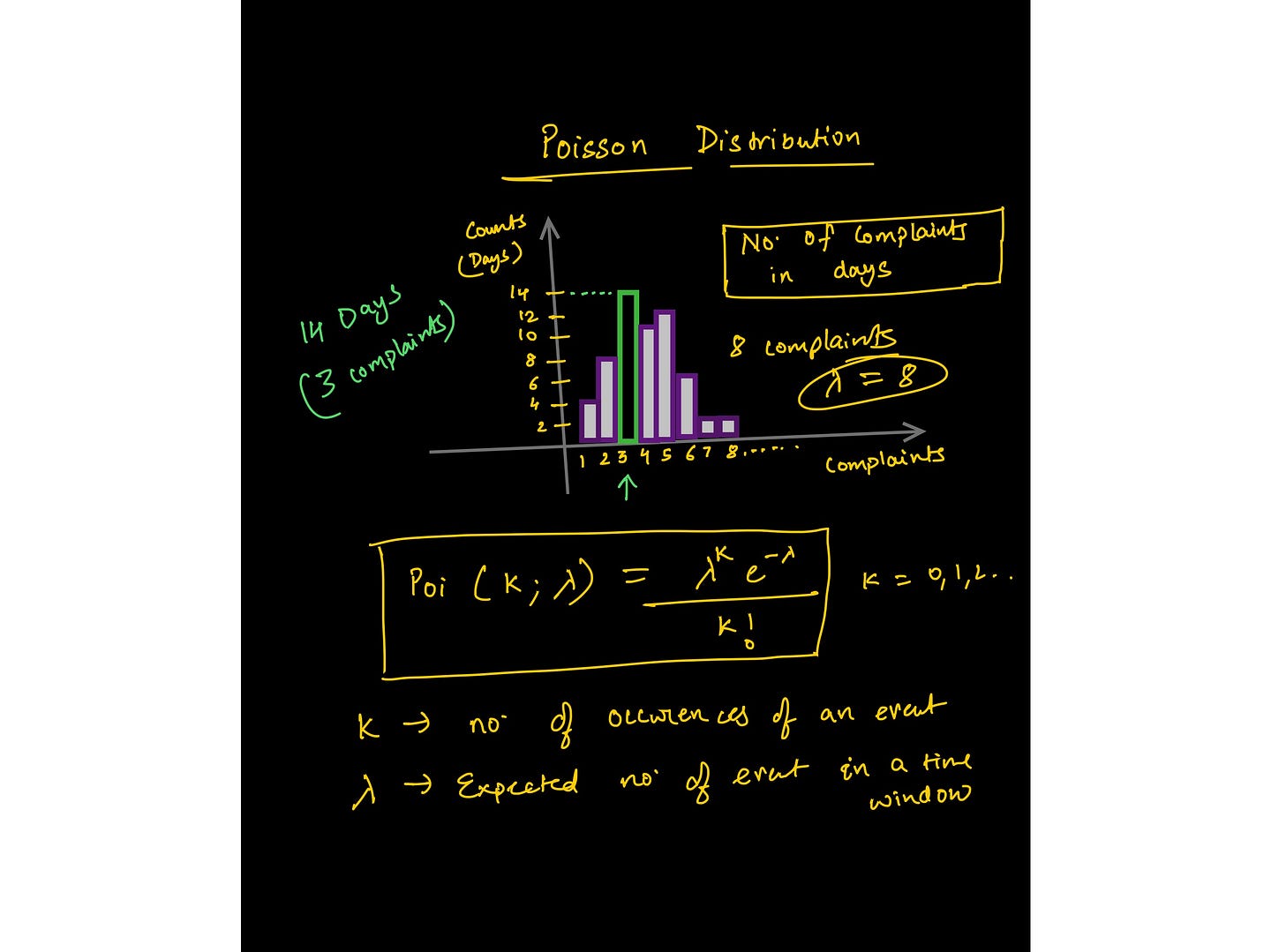
Image de la conférence sur la distribution de Poisson—https://www.wiplane.com/p/foundations-for-data-science-ml
Tout passionné de data science de niveau débutant devrait se concentrer sur ces trois piliers avant de plonger dans un cours de data science ou de ML.
Comment apprendre ces concepts fondamentaux de DS et ML
J'ai créé une feuille de route d'apprentissage que vous pouvez trouver ici. Elle vous indique également ce qu'il faut apprendre et est également chargée de ressources, de cours et de programmes que vous pouvez consulter.
Mais il y a quelques incohérences dans les ressources recommandées et la feuille de route que j'ai tracée.
Problèmes avec les cours de Data Science ou ML
Chaque cours de data science que j'ai listé dans cet article nécessite que les étudiants aient une compréhension décente de la programmation, des mathématiques ou des statistiques. Par exemple, le cours le plus célèbre sur le ML par Andrew Ng repose également fortement sur la compréhension de l'algèbre vectorielle et du calcul.
La plupart des cours qui couvrent les mathématiques et les statistiques pour la Data Science ne sont qu'une liste de concepts requis pour le DS/ML sans explication sur la manière dont ils sont appliqués et comment ils sont programmés dans une machine.
Il existe des ressources exceptionnelles pour approfondir les mathématiques, mais la plupart d'entre nous ne sont pas faits pour cela et vous n'avez pas besoin d'être médaillé d'or pour apprendre la data science.
En résumé : il vous manque une ressource qui couvre juste assez de mathématiques appliquées, de statistiques ou de programmation pour commencer avec la data science ou le ML.
Wiplane Academy—wiplane.com

https://www.wiplane.com
J'ai donc décidé de me lancer et de développer le cours moi-même. J'ai passé des mois à concevoir et à développer un programme qui fournira une base solide pour votre carrière en tant que...
Data Analyst
Data Scientist
Ou un praticien/ingénieur ML
Voici le cours – Fondamentaux pour la Data Science ou le ML—Premières étapes pour apprendre la Data Science et le ML
C'est un cours complet, compact et abordable qui couvre non seulement tous les essentiels, les préalables et le pré-travail, mais explique également comment chaque concept est utilisé de manière computationnelle et programmatique (en Python).
Et ce n'est pas tout – je continuerai à mettre à jour le contenu du cours chaque mois en fonction de vos retours. En savoir plus ici.