


Article original : Unicode Characters – What Every Developer Should Know About Encoding
Si vous développez une application internationale qui utilise plusieurs langues, vous devrez vous familiariser avec l'encodage. Ou même si vous êtes simplement curieux de savoir comment les mots s'affichent sur votre écran – oui, c'est aussi de l'encodage.
J'expliquerai brièvement l'histoire de l'encodage dans cet article (et je discuterai du peu de standardisation qu'il y avait), puis je parlerai de ce que nous utilisons aujourd'hui. Je couvrirai également une partie de la théorie de l'informatique que vous devez comprendre.
Introduction à l'encodage
Un ordinateur ne peut comprendre que le binaire. Le binaire est la langue des ordinateurs et se compose de 0 et de 1. Rien d'autre n'est autorisé. Un chiffre est appelé un bit, et un octet (byte) est composé de 8 bits. Ainsi, 8 0 ou 1 constituent un octet.
Tout finit par devenir du binaire – les langages de programmation, les mouvements de souris, la frappe au clavier et tous les mots à l'écran.
Si tout le texte que vous lisez était autrefois du binaire lui aussi, alors comment transformons-nous le binaire en texte ? Voyons ce que nous faisions au tout début.
Une brève histoire de l'encodage
Aux débuts d'Internet, tout était en anglais. Nous n'avions pas à nous soucier d'autres caractères et l'American Standard Code for Information Interchange (ASCII) était l'encodage de caractères qui répondait à ce besoin.
L'ASCII est un mappage, du binaire aux caractères alphanumériques. Ainsi, quand le PC reçoit du binaire :
01001000 01100101 01101100 01101100 01101111 00100000 01110111 01101111 01110010 01101100 01100100
Avec l'ASCII, il peut traduire cela en "Hello world".
Un octet (huit bits) était assez grand pour contenir chaque caractère anglais, ainsi que certains caractères de contrôle. Certains de ces caractères de contrôle étaient utilisés pour des instruments appelés téléscripteurs, ils étaient donc utiles à l'époque (plus tellement maintenant !)
Mais les caractères de contrôle étaient des choses comme 7 (111 en binaire) qui ferait retentir une cloche sur votre PC, 8 (1000 en binaire) qui imprimerait par-dessus le dernier caractère venant d'être imprimé, ou 12 (1100 en binaire) qui effacerait tout le texte venant d'être écrit sur un terminal vidéo.
Les ordinateurs de cette époque utilisaient 8 bits pour un octet (ce n'était pas toujours le cas), il n'y avait donc aucun problème. Nous pouvions stocker tous nos caractères de contrôle, tous nos chiffres, tous les caractères anglais et il nous en restait ! Parce qu'un octet peut encoder 255 caractères, et l'ASCII n'avait besoin que de 127 caractères. Nous avions donc 128 encodages inutilisés.
Jetons un œil à un tableau ASCII ici pour voir chaque caractère. Tous les A-Z minuscules et majuscules et les chiffres 0-9 étaient encodés en nombres binaires. Rappelez-vous que les 32 premiers sont des caractères de contrôle non imprimables.
Tableau des caractères ASCII
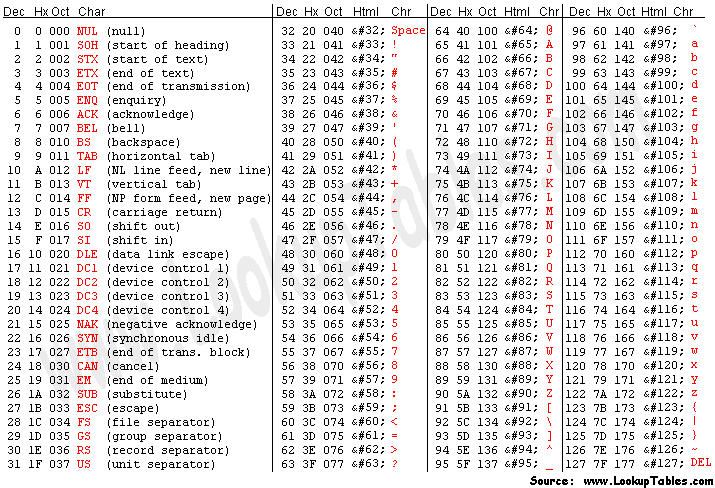
Voyez-vous comment il se termine à 127 ? Nous avons un peu d'espace libre à la fin.
Problèmes avec l'ASCII
Les caractères restants allaient de 127 à 255. Les gens ont commencé à réfléchir à la meilleure façon de remplir ces caractères restants. Mais tout le monde avait des idées différentes sur ce que devraient être ces derniers caractères.
L'American National Standards Institute (ANSI – ne pas confondre avec l'ASCII) est un organisme de normalisation qui établit des normes dans de nombreux domaines différents. Ils ont décidé de ce que tout le monde faisait avec 0-127, ce que l'ASCII faisait déjà. Mais le reste était libre.
Personne ne débattait de ce qu'était 0-127 dans l'encodage ASCII. Le problème venait des caractères restants.
Voici ci-dessous ce que les premiers ordinateurs IBM ont fait avec les encodages 128-255 pour l'ASCII.
 Quelques gribouillis, des icônes d'arrière-plan, des opérateurs mathématiques et certains caractères accentués comme é.
Quelques gribouillis, des icônes d'arrière-plan, des opérateurs mathématiques et certains caractères accentués comme é.
Mais les autres ordinateurs ne suivaient pas tous cela. Et tout le monde voulait implémenter ses propres encodages pour la fin de l'ASCII.
Ces différentes fins pour l'ASCII étaient appelées pages de code (code pages).
Que sont les pages de code ASCII ?
Voici une collection de plus de 465 pages de code différentes ! Vous pouvez voir qu'il y avait plusieurs pages de code MÊME pour la même langue. Le grec et le chinois en ont tous deux plusieurs, par exemple.
Alors, comment diable allions-nous un jour standardiser cela ? Ou le faire fonctionner entre différentes langues ? Entre la même langue avec différentes pages de code ? Dans une langue non anglaise ?
Le chinois compte plus de 100 000 caractères différents. Nous n'avons même pas assez de caractères restants pour le chinois, sans parler de se mettre d'accord sur le fait que les derniers caractères devraient être chinois. Cela ne s'annonce pas très bien.
Ce problème a même son propre terme : Mojibake.
C'est du texte illisible que vous pouvez parfois voir lors du décodage d'un texte, mais en utilisant le mauvais décodage. Cela signifie transformation de caractères en japonais.
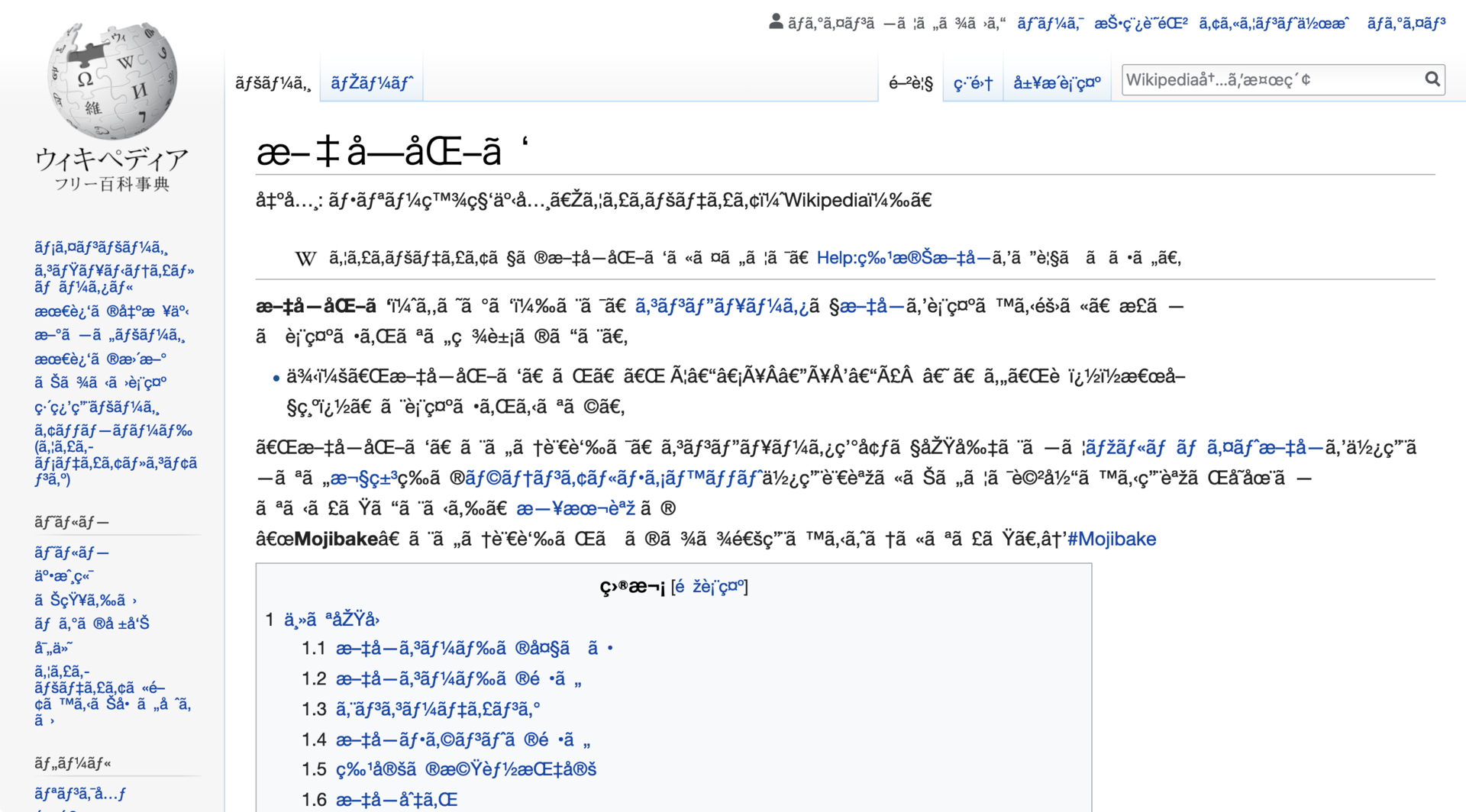 Exemple de texte complètement illisible (mojibake).
Exemple de texte complètement illisible (mojibake).
Cela semble un peu fou...
Exactement ! Nous n'aurons aucune chance d'échanger des données de manière fiable.
Internet n'est qu'une immense connexion d'ordinateurs à travers le monde. Imaginez si tous ces pays décidaient de ce que devraient être leurs propres normes. Si les ordinateurs grecs n'acceptaient que le grec et les ordinateurs anglais n'envoyaient que de l'anglais... ? Vous ne feriez que crier dans une grotte vide. Personne ne vous comprendrait. Et personne ne serait capable de décoder ce non-sens.
L'ASCII n'était pas adapté à une utilisation réelle. Dans un Internet mondial et connecté, nous devions évoluer, sous peine de devoir composer éternellement avec des centaines de pages de code.
À moins que vous n'ayez eu envie d'essayer de lire des paragraphes comme celui-ci. ֎ ֏ 0590 ׀ ׂ ׃ ׄ ׅ ׆ ׇ
L'arrivée d'Unicode
L'Unicode est parfois appelé le Jeu universel de caractères codés (UCS), ou même ISO/IEC 10646. Mais Unicode est son nom le plus courant.
C'est là qu'Unicode est entré en scène pour aider à résoudre les problèmes causés par l'encodage et les pages de code.
L'Unicode est composé de nombreux points de code (mappant de nombreux caractères du monde entier à une clé à laquelle tous les ordinateurs peuvent se référer). Une collection de points de code est appelée un jeu de caractères – ce qu'est l'Unicode.
Nous pouvons mapper quelque chose d'abstrait à une lettre que nous voulons référencer. Et il couvre chaque caractère ! Même les hiéroglyphes égyptiens.
Certaines personnes ont fait tout le travail difficile de mapper ce que chaque caractère serait (dans toutes les langues) à une clé à laquelle nous pourrions tous accéder. Ils ressemblent à ceci :
"Hello World"
U+0048 : LETTRE MAJUSCULE LATINE H
U+0065 : LETTRE MINUSCULE LATINE E U+006C : LETTRE MINUSCULE LATINE L U+006C : LETTRE MINUSCULE LATINE L U+006F : LETTRE MINUSCULE LATINE O U+0020 : ESPACE [SP] U+0057 : LETTRE MAJUSCULE LATINE W U+006F : LETTRE MINUSCULE LATINE O U+0072 : LETTRE MINUSCULE LATINE R U+006C : LETTRE MINUSCULE LATINE L U+0064 : LETTRE MINUSCULE LATINE D
Le U+ nous indique qu'il s'agit du standard Unicode, et le nombre est le résultat de la transformation du binaire en nombres. Il utilise la notation hexadécimale qui est juste une manière plus simple de représenter les nombres binaires. Vous n'avez pas à vous soucier trop de l'hexadécimal ici, cependant.
Voici un lien où vous pouvez taper ce que vous voulez dans la zone de texte et voir l'encodage de caractères Unicode. Ou consultez les 143 859 points de caractères Unicode ici. Vous pouvez également voir d'où vient chaque caractère dans le monde !
Je veux être clair. À ce stade, nous avons un grand dictionnaire de points de code mappés à des caractères. Un très grand jeu de caractères. Rien de plus.
Il reste un dernier ingrédient à ajouter à notre mélange.
Unicode Transform Protocol (UTF)
L'UTF est une manière d'encoder les points de code Unicode. Les encodages UTF sont définis par le standard Unicode et sont capables d'encoder chaque point de code Unicode dont nous avons besoin.
Mais il existe différents types de standards UTF. Ils diffèrent selon le nombre d'octets utilisés pour encoder un point de code. Cela dépend également si vous utilisez l'UTF-8 (un octet par point de code), l'UTF-16 (deux octets par point de code) ou l'UTF-32 (quatre octets par point de code).
Si nous avons ces différents encodages, comment savoir quel encodage un fichier utilisera ? Il existe une chose appelée Marque d'ordre des octets (BOM) – parfois appelée Signature d'encodage. Le BOM est un marqueur de deux octets au début d'un fichier qui indique l'encodage utilisé par le fichier.
L'UTF-8 est le plus utilisé sur Internet, et est également spécifié dans l'HTML5 comme l'encodage préféré pour les nouveaux documents, je vais donc passer le plus de temps à expliquer celui-ci.
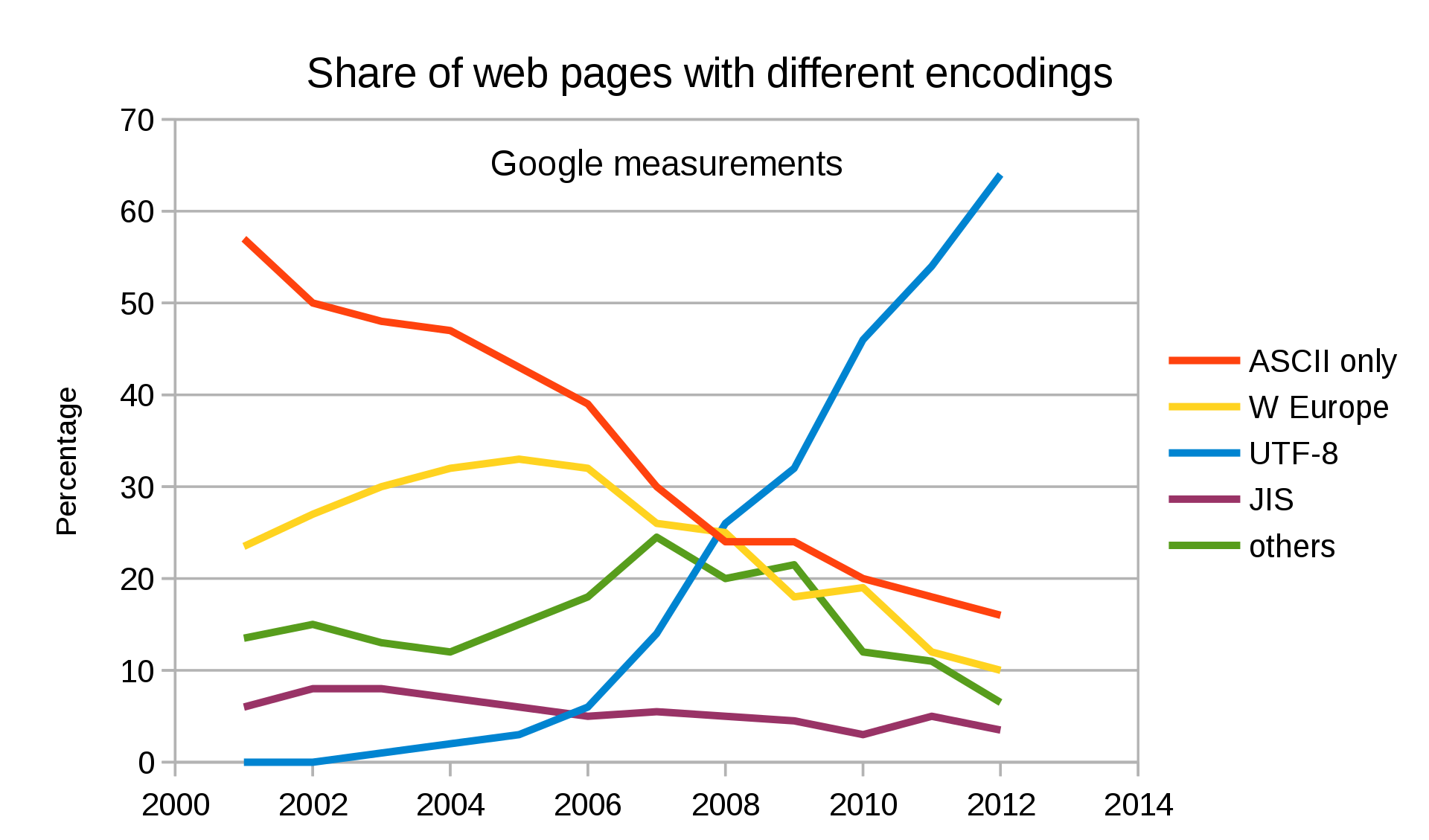 Vous pouvez voir dans le diagramme que même depuis 2012, l'UTF-8 devenait largement l'encodage le plus utilisé. Et pour le web, c'est toujours le cas.
Vous pouvez voir dans le diagramme que même depuis 2012, l'UTF-8 devenait largement l'encodage le plus utilisé. Et pour le web, c'est toujours le cas.
 _Le diagramme du W3 montre à quel point l'UTF-8 est utilisé sur une variété de sites web._
_Le diagramme du W3 montre à quel point l'UTF-8 est utilisé sur une variété de sites web._
Qu'est-ce que UTF-8 et comment ça marche ?
L'UTF-8 encode tous les points de code Unicode de 0 à 127 sur 1 octet (le même que l'ASCII). Cela signifie que si vous codiez votre programme en utilisant l'ASCII et que vos utilisateurs utilisaient l'UTF-8, ils ne remarqueraient rien d'anormal. Tout fonctionnerait simplement.
Rappelez-vous à quel point cet argument de vente est fort. Nous devions rester rétrocompatibles avec l'ASCII pendant que l'UTF-8 était implémenté et utilisé par tout le monde. Cela ne casse rien de ce qui est actuellement utilisé.
Comme il s'appelle UTF-8, n'oubliez pas que c'est le nombre minimum de bits (8 bits étant un octet !) qu'un point de code occupera. Il existe d'autres caractères Unicode qui sont stockés sur plusieurs octets (jusqu'à 6 octets selon le caractère). C'est ce que les gens veulent dire quand l'encodage est dit à longueur variable.
Cela peut être plus, selon la langue. L'anglais occupe 1 octet. Le latin (européen), l'hébreu et l'arabe sont représentés par 2 octets. 3 octets sont utilisés pour le chinois, le japonais, le coréen et d'autres caractères asiatiques. Vous voyez l'idée.
Lorsque vous avez besoin qu'un caractère s'étende sur plus d'un octet, vous avez une combinaison de bits pour identifier un signe de continuation, indiquant que ce caractère se poursuit sur les octets suivants. Ainsi, vous n'utiliserez toujours qu'un octet par caractère pour l'anglais, mais si vous avez besoin qu'un document contienne des caractères étrangers, vous pouvez le faire aussi.
Et maintenant, merveilleusement, nous pouvons tous être d'accord sur ce qu'est l'encodage des caractères cunéiformes sumériens (𠠵 𠑷𠒅 𠈤), ainsi que de certains emojis 😉😉 afin que nous puissions tous communiquer !
L'aperçu de haut niveau est le suivant : vous lisez d'abord le BOM pour connaître votre encodage. Vous décodez le fichier en points de code Unicode, puis vous représentez les caractères du jeu de caractères Unicode en caractères dessinés sur l'écran.
Un dernier mot sur l'UTF
Rappelez-vous, l'encodage est la clé. Si j'envoie un encodage complètement erroné, vous ne pourrez rien lire. Soyez-en conscient lors de la réception ou de l'envoi de données. Souvent, il est masqué par l'abstraction dans les outils que vous utilisez au quotidien, mais en tant que programmeurs, il est important de comprendre ce qui se passe sous le capot.
Comment spécifions-nous nos encodages, alors ? Comme l'HTML est écrit en anglais, et que presque tous les encodages peuvent gérer l'anglais correctement, nous pouvons l'intégrer directement en haut dans la section <head>.
<html lang="en">
<head>
<meta charset="utf-8">
</head>
Il est important de le faire dès le début du <head>, car le parsing de l'HTML pourrait devoir recommencer si l'encodage qu'il utilise actuellement est erroné.
Nous pouvons également obtenir l'encodage à partir de l'en-tête Content-Type de la requête/réponse HTTP.
Si un document HTML ne contient pas la balise d'encodage, la spécification HTML5 propose des méthodes intéressantes pour deviner l'encodage, appelées BOM sniffing. C'est là qu'il devine l'encodage à partir de la Marque d'ordre des octets (BOM) dont nous avons discuté plus tôt.
C'est tout ?
L'Unicode n'est pas terminé. Comme tout standard, nous ajoutons, supprimons et faisons de nouvelles propositions au standard. Aucune spécification n'est jamais considérée comme "complète".
Il y a généralement 1 ou 2 publications par an, et vous pouvez les trouver ici.
Récemment, j'ai lu un article sur un bug très intéressant concernant Twitter affichant incorrectement les caractères Unicode russes.
Si vous avez lu jusqu'ici, félicitations – c'est beaucoup à assimiler.
Je vous encourage à faire un dernier petit exercice.
Regardez à quel point les sites web peuvent être cassés lorsque l'encodage est erroné. J'ai utilisé cette extension Google Chrome, j'ai changé mon encodage et j'ai essayé de lire des pages web. Le message était totalement flou. Essayez de lire cet article. Essayez de naviguer sur Wikipedia. Voyez le Mojibake par vous-même.
Cela aide à voir à quel point l'encodage est véritablement important.

Conclusion
Pendant le temps passé à faire des recherches et à essayer de simplifier cet article, j'ai découvert Michael Everson. Depuis 1993, il a proposé plus de 200 changements à l'Unicode et a ajouté des milliers de caractères au standard. En 2003, il était crédité comme le principal contributeur des propositions Unicode. Il est l'une des raisons majeures pour lesquelles l'Unicode est ce qu'il est. Très impressionnant, et il a énormément fait pour l'Internet tel que nous le connaissons.
J'espère que cela vous a donné un bon aperçu de la raison pour laquelle nous avons besoin d'encodages, des problèmes que l'encodage résout et de ce qui se passe quand cela tourne mal.
Je partage mes écrits sur Twitter si vous avez apprécié cet article et souhaitez en voir plus.