

Article original : Atomics and Concurrency in C++
Par Zaid Humayun
La concurrence est un terme de programmation que vous devrez connaître si vous codez en C++. Elle est particulièrement pertinente si vous souhaitez tirer davantage parti de vos ressources de calcul disponibles.
Mais la concurrence vient avec certains problèmes. Certains d'entre eux peuvent être résolus en utilisant des mutex, bien que les mutex aient leur propre ensemble de défis.
C'est là que les atomics entrent en jeu. Cependant, les atomics nécessitent une compréhension du modèle de mémoire d'un ordinateur, ce qui est un sujet difficile à maîtriser complètement.
C'est ce que nous allons couvrir dans cet article. Espérons que vous acquerrez une bonne compréhension de la manière dont l'ordre de la mémoire fonctionne et comment utiliser les atomics en conjonction avec l'ordre de la mémoire pour construire une file d'attente sans verrou en C++.
Prérequis
Pour tirer le meilleur parti de ce guide, vous devez avoir écrit quelques programmes concurrents de base. Une expérience de programmation avec C++ aide.
Note : Si vous souhaitez réellement compiler le code et l'exécuter, assurez-vous de le faire avec le drapeau TSan activé pour le compilateur CLang. TSan est un moyen fiable de détecter les conditions de course dans votre code, au lieu d'essayer d'exécuter le code en boucle en espérant qu'une condition de course se produise.
Getting Started
Imaginez que vous avez un code concurrent opérant sur des données partagées en mémoire. Vous avez deux threads ou processus, l'un écrivant et l'autre lisant sur un morceau d'état partagé.
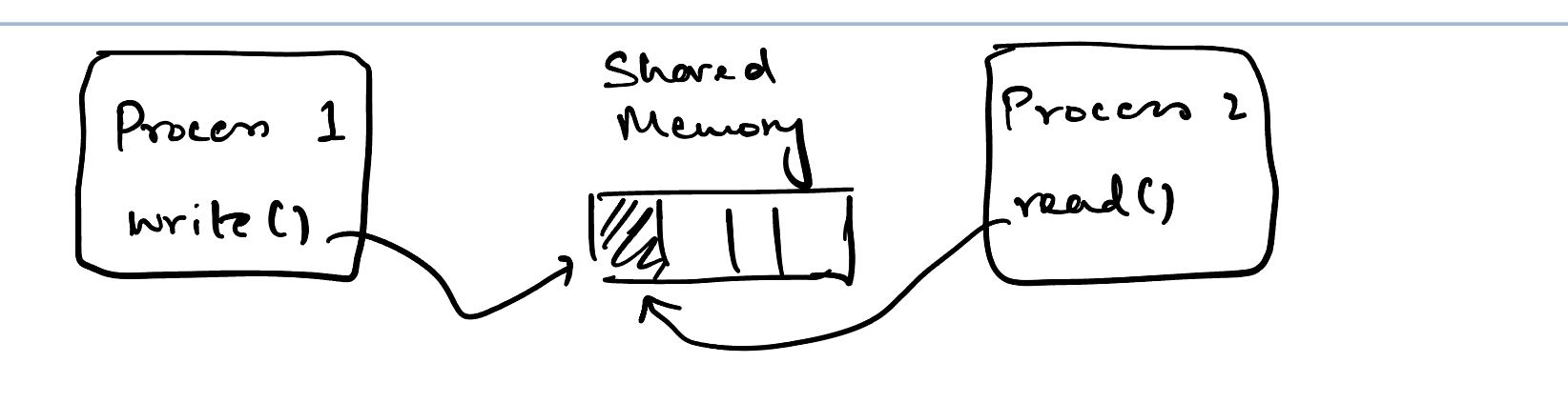 Processus partageant la mémoire
Processus partageant la mémoire
La manière "sûre" de gérer cela est d'utiliser des mutex. Mais les mutex tendent à ajouter des frais généraux. Les atomics sont une méthode plus performante mais beaucoup plus compliquée pour gérer les opérations concurrentes.
Qu'est-ce que les Atomics en C++ ?
Cette section est très simple. Les atomics sont simplement des opérations ou des instructions qui ne peuvent pas être divisées par le compilateur ou le CPU ou réordonnées de quelque manière que ce soit.
L'exemple le plus simple possible d'un atomic en C++ est un flag atomique. Cela ressemble à ceci :
#include <atomic>
std::atomic<bool> flag(false);
int main() {
flag.store(true);
assert(flag.load() == true);
}
Nous définissons un booléen atomique, l'initialisons, puis appelons store dessus. Cette méthode définit la valeur du flag. Vous pouvez ensuite load le flag depuis la mémoire et assert sa valeur.
Opérations avec les Atomics
Les opérations que vous pouvez effectuer avec les atomics sont simples :
- Vous pouvez stocker une valeur avec la méthode
store(). Il s'agit d'une opération d'écriture. - Vous pouvez charger une valeur avec la méthode
load(). Il s'agit d'une opération de lecture. - Vous pouvez effectuer un Compare-and-Set (CAS) avec eux en utilisant la méthode
compare_exchange_weak()oucompare_exchange_strong(). Il s'agit d'une opération de lecture-modification-écriture (RMW).
L'important à retenir est que chacune de ces opérations ne peut pas être divisée en instructions séparées.
Note : Il existe d'autres méthodes disponibles, mais c'est tout ce dont nous avons besoin pour l'instant.
Il existe divers atomics disponibles en C++ et vous pouvez les utiliser en combinaison avec des ordres de mémoire.
Ordre de la Mémoire
Cette section est beaucoup plus compliquée et constitue le cœur du sujet. Il existe quelques excellentes références pour vous aider à comprendre l'ordre de la mémoire plus en profondeur, que j'ai liées en bas.
Pourquoi l'Ordre de la Mémoire est Important
Le compilateur et le CPU sont capables de réordonner vos instructions de programme, souvent indépendamment l'un de l'autre. C'est-à-dire que votre compilateur peut réordonner les instructions et votre CPU peut réordonner les instructions à nouveau. Voir ce post pour plus de détails.
Mais cela n'est autorisé que si le compilateur ne peut définitivement pas établir de relation entre les deux ensembles d'instructions.
Par exemple, le code ci-dessous peut être réordonné car il n'y a pas de relation entre l'assignation à x et l'assignation à y. C'est-à-dire que le compilateur ou le CPU peut assigner y en premier puis x. Mais cela ne change pas la signification sémantique de votre programme.
int x = 10;
int y = 5;
En revanche, l'exemple de code suivant ne peut pas être réordonné car le compilateur ne peut pas établir l'absence de relation entre x et y. C'est assez facile à voir ici car y dépend de la valeur de x.
int x = 10;
int y = x + 1;
Cela ne semble pas être un gros problème – jusqu'à ce qu'il y ait du code multithread. Voyons ce que je veux dire avec un exemple.
Intuition pour l'Ordre
#include <cassert>
#include <thread>
int data = 0;
void producer() {
data = 100; // Write data
}
void consumer() {
assert(data == 100);
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
L'exemple multithread ci-dessus échouera à la compilation avec TSan car il y a une claire condition de course lorsque le thread 1 essaie de définir la valeur de data et que le thread 2 essaie de lire la valeur de data. La réponse facile ici est un mutex pour protéger l'écriture et la lecture de data, mais il y a une manière de faire cela avec un booléen atomique.
Nous bouclons sur le booléen atomique jusqu'à ce que nous trouvions qu'il est défini à la valeur que nous recherchons, puis nous vérifions la valeur de data.
#include <atomic>
#include <cassert>
#include <thread>
int data = 0;
std::atomic<bool> ready(false);
void producer() {
data = 100;
ready.store(true); // Set flag
}
void consumer() {
while (!ready.load())
;
assert(data == 100);
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
Lorsque vous compilez cela avec TSan, il ne se plaint pas des conditions de course. Note : Je vais revenir sur la raison pour laquelle TSan ne se plaint pas ici un peu plus loin.
Maintenant, je vais le casser en ajoutant une garantie d'ordre de mémoire. Remplacez simplement ready.store(true); par ready.store(true, std::memory_order_relaxed); et remplacez while (!ready.load()) par while (!ready.load(std::memory_order_relaxed)).
TSan se plaindra qu'il y a une condition de course. Mais pourquoi se plaint-il ?
Le problème ici est que nous n'avons plus d'ordre parmi les opérations des deux threads. Le compilateur ou le CPU est libre de réordonner les instructions dans les deux threads. Si nous revenons à notre visualisation abstraite de tout à l'heure, voici à quoi cela ressemble maintenant :
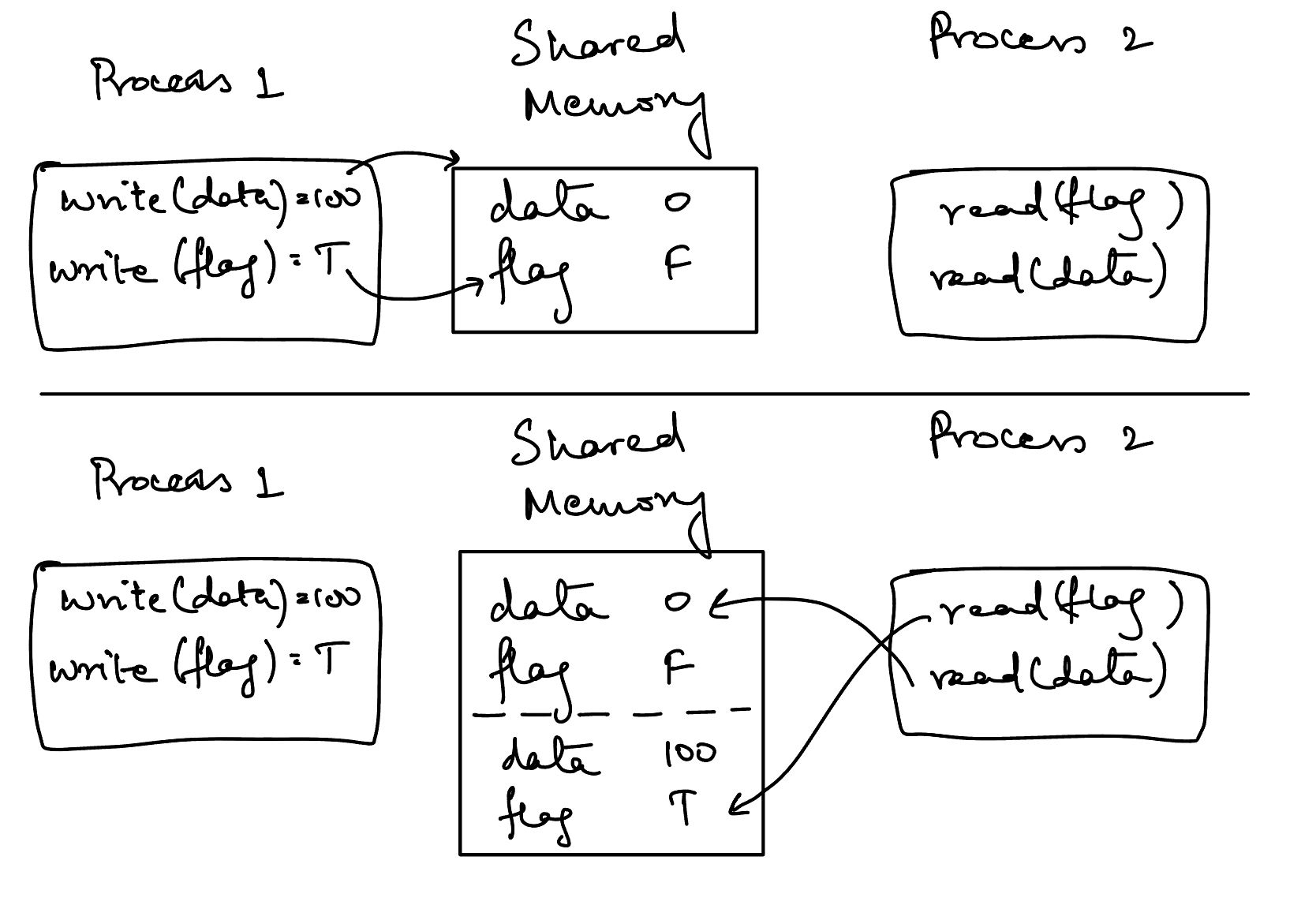 Ordre de modèle de mémoire relaxé
Ordre de modèle de mémoire relaxé
La visualisation ci-dessus nous montre que nos deux processus (threads) n'ont aucun moyen de s'accorder sur l'état actuel ou l'ordre dans lequel cet état a changé.
Une fois que le processus 2 détermine que le flag a été défini à vrai, il essaie de lire la valeur de data. Mais le thread 2 croit que la valeur de data n'a pas encore changé même s'il croit que la valeur de flag a été définie à vrai.
Cela est déroutant car le modèle classique d'entrelacement des opérations concurrentes ne s'applique pas ici. Dans le modèle classique des opérations concurrentes, il y a toujours un certain ordre qui peut être établi. Par exemple, nous pouvons dire que c'est un scénario possible d'opérations :
Thread 1 Memory Thread 2
--------- ------- ---------
| | |
| write(data, 100) | |
| -----------------------> | |
| | load(ready) == true |
| | <---------------------- |
| | |
| store(ready, true) | |
| -----------------------> | |
| | |
| | read(data) |
| | <---------------------- |
| | |
Mais le graphique ci-dessus suppose que les deux threads se sont mis d'accord sur un ordre global des événements, ce qui n'est plus du tout vrai ! Cela reste déroutant pour moi à comprendre.
Dans un mode memory_order_relaxed, deux threads n'ont aucun moyen de s'accorder sur l'ordre des opérations sur les variables partagées. Du point de vue du thread 1, les opérations qu'il a exécutées étaient les suivantes :
write(data, 100)
store(ready, true)
Cependant, du point de vue du thread 2, l'ordre des opérations qu'il a vu le thread 1 exécuter était :
store(ready, true)
write(data, 100)
Sans s'accorder sur l'ordre dans lequel les opérations se sont produites sur les variables partagées, il n'est pas sûr de faire des changements sur ces variables à travers les threads.
D'accord, corrigeons le code en remplaçant std::memory_order_relax par std::memory_order_seq_cst.
Donc, ready.store(true, std::memory_order_relaxed); devient ready.store(true, std::memory_order_seq_cst); et while (!ready.load(std::memory_order_relaxed)) devient while (!ready.load(std::memory_order_seq_cst)).
Si vous exécutez cela à nouveau avec TSan, il n'y a plus de conditions de course. Mais pourquoi cela l'a-t-il corrigé ?
Barrière de Mémoire
Nous avons vu que notre problème précédent concernait deux threads incapables de s'accorder sur une vue unique des événements et nous voulions empêcher cela. Nous avons donc introduit une barrière en utilisant la cohérence séquentielle.
Thread 1 Memory Thread 2
--------- ------- ---------
| | |
| write(data, 100) | |
| -----------------------> | |
| | |
| ================Memory Barrier=================== |
| store(ready, true) | |
| -----------------------> | |
| | load(ready) == true |
| | <---------------------- |
| ================Memory Barrier=================== |
| | |
| | read(data) |
| | <---------------------- |
| | |
La barrière de mémoire ici indique que rien avant l'opération de stockage et rien après l'opération de chargement ne peut être réordonné. C'est-à-dire que le thread 2 a maintenant la garantie que le compilateur ou le CPU ne placeront pas l'écriture vers data après l'écriture vers le flag dans le thread 1. De même, l'opération de lecture dans le thread 2 ne peut pas être réordonnée au-dessus de la barrière de mémoire.
La région à l'intérieur de la barrière de mémoire est similaire à une section critique qu'un thread doit verrouiller pour entrer. Nous avons maintenant un moyen de synchroniser les deux threads sur l'ordre des événements entre eux.
Cela nous ramène à notre modèle classique d'entrelacement dans la concurrence car nous avons maintenant un ordre d'événements sur lequel les deux threads sont d'accord.
Types d'Ordre de Mémoire
Il existe 3 principaux types d'ordre de mémoire :
- Modèle de mémoire relaxé (std::memory_order_relaxed)
- Modèle de mémoire release-acquire (std::memory_order_release et std::memory_order_acquire)
- Ordre de mémoire séquentiellement cohérent (std::memory_order_seq_cst)
Nous avons déjà couvert les points 1 et 3 dans les exemples ci-dessus. Le deuxième modèle de mémoire se situe littéralement entre les deux autres en termes de cohérence.
#include <atomic>
#include <cassert>
#include <iostream>
#include <thread>
int data = 0;
std::atomic<bool> ready(false);
void producer() {
data = 100;
ready.store(true, std::memory_order_release); // Set flag
}
void consumer() {
while (!ready.load(std::memory_order_acquire))
;
assert(data == 100);
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
L'exemple ci-dessus est le même que précédemment, sauf avec std::memory_order_release utilisé pour ready.store() et memory_order_acquire utilisé pour read.load(). L'intuition ici pour l'ordre est similaire à l'exemple précédent de barrière de mémoire.
Sauf que cette fois, la barrière de mémoire est formée sur la paire d'opérations ready.store() et ready.load() et ne fonctionnera que lorsqu'elle est utilisée sur la même variable atomique à travers les threads.
En supposant que vous avez une variable x modifiée à travers 2 threads, vous pourriez faire x.store(std::memory_order_release) dans le thread 1 et x.load(std::memory_order_acquire) dans le thread 2 et vous auriez un point de synchronisation à travers les deux threads sur cette variable.
La différence entre le modèle séquentiellement cohérent et le modèle release-acquire est que le premier impose un ordre global des opérations à travers tous les threads, tandis que le second impose un ordre uniquement parmi les paires d'opérations release et acquire.
Maintenant, nous pouvons revisiter pourquoi TSan ne s'est pas plaint d'une condition de course initialement lorsqu'aucun ordre de mémoire n'était spécifié. C'est parce que C++ suppose par défaut un std::memory_order_seq_cst lorsqu'aucun ordre de mémoire n'est spécifié. Comme il s'agit du mode mémoire le plus fort, aucune condition de course n'est possible.
Considérations Matérielles
Différents modèles de mémoire ont différentes pénalités de performance sur différents matériels.
Par exemple, l'ensemble d'instructions des architectures x86 implémente ce que l'on appelle le total store ordering (TSO). L'essentiel est que le modèle ressemble à tous les threads lisant et écrivant dans une mémoire partagée. Vous pouvez en lire plus à ce sujet [ici](https://research.swtch.com/hwmm#:~:text=x86%20Total%20Store%20Order%20(x86,in%20a%20local%20write%20queue.).
Cela signifie que les processeurs x86 peuvent fournir une cohérence séquentielle pour une pénalité computationnelle relativement faible.
De l'autre côté, la famille de processeurs ARM a une architecture d'ensemble d'instructions faiblement ordonnée. Cela est dû au fait que chaque thread ou processus lit et écrit dans sa propre mémoire. À nouveau, le lien ci-dessus fournit du contexte.
Cela signifie que les processeurs ARM fournissent une cohérence séquentielle pour une pénalité computationnelle beaucoup plus élevée.
Comment Construire une File d'Attente Concurrentielle
Je vais utiliser les opérations que nous avons discutées jusqu'à présent pour construire les opérations de base d'une file d'attente concurrentielle sans verrou. Cela n'est en aucun cas une implémentation complète, juste ma tentative de recréer quelque chose de basique en utilisant des atomics.
Je vais représenter la file d'attente en utilisant une liste liée et envelopper chaque nœud dans un atomic.
class lock_free_queue {
private:
struct node {
std::shared_ptr<T> data;
std::atomic<node*> next;
node() : next(nullptr) {} // initialise le nœud
};
std::atomic<node*> head;
std::atomic<node*> tail;
}
Maintenant, pour l'opération d'enqueue, voici à quoi cela va ressembler :
void enqueue(T value) {
std::shared_ptr<T> new_data = std::make_shared<T>(value);
node* new_node = new node();
new_node->data = new_data;
// faire une boucle infinie pour changer la queue
while (true) {
node* current_tail = this->tail.load(std::memory_order_acquire);
node* tail_next = current_tail->next;
// tout est correct jusqu'à présent, tenter l'échange
if (current_tail->next.compare_exchange_strong(
tail_next, new_node, std::memory_order_release)) {
this->tail = new_node;
break;
}
}
}
L'accent principal est mis sur les opérations load et compare_exchange_strong. Le load fonctionne avec un acquire et le CAS fonctionne avec un release afin que les lectures et écritures de la queue soient synchronisées.
De même pour l'opération de dequeue :
std::shared_ptr<T> dequeue() {
std::shared_ptr<T> return_value = nullptr;
// faire une boucle infinie pour changer la tête
while (true) {
node* current_head = this->head.load(std::memory_order_acquire);
node* next_node = current_head->next;
if (this->head.compare_exchange_strong(current_head, next_node,
std::memory_order_release)) {
return_value.swap(next_node->data);
delete current_head;
break;
}
}
return return_value;
}
Note : Cette file d'attente ne gère pas le problème ABA. Il est hors de la portée de ce tutoriel d'introduire les pointeurs de danger, donc je l'omets – mais vous pouvez vous renseigner si vous êtes curieux.
Conclusion
Voilà – les atomics en C++. Ils sont difficiles à comprendre mais vous offrent des avantages de performance massifs. Si vous souhaitez voir des implémentations de structures de données sans verrou de qualité professionnelle, vous pouvez en lire plus ici.
Typiquement, vous verriez des structures de données concurrentes basées sur des verrous mises en production, mais il y a une recherche croissante autour des implémentations sans verrou et sans attente des algorithmes concurrents pour améliorer l'efficacité du calcul.
Si vous souhaitez lire ceci et d'autres tutoriels, vous pouvez visiter mon site web ici.